↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Self-supervised learning in video has seen limited success, partly due to the difficulty and expense of obtaining large-scale natural video data. This is particularly problematic when considering the challenges of obtaining diverse and unbiased data. The scarcity of high-quality video data hinders the development of truly effective and robust video models.
This paper proposes a novel approach using synthetically generated video data and static images for pre-training video representation models. By creating a progression of synthetic video datasets, gradually increasing the complexity, the researchers demonstrate that a VideoMAE model can achieve nearly the same performance as models trained with real-world video data. The addition of natural image crops further enhances performance. This novel method is both more efficient and more transparent, representing a significant advancement in video representation learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional wisdom that natural videos are essential for training effective video representation models. It opens new avenues for research into more efficient and controllable pre-training methods, particularly relevant given the high cost and difficulty of obtaining large-scale, high-quality video datasets. The findings also have implications for other computer vision tasks, potentially leading to improvements in action recognition and related fields.
Visual Insights#

🔼 Figure 1 visualizes the progression of video datasets generated synthetically, culminating in datasets that incorporate natural image crops. Each dataset models increasingly complex aspects of natural videos (e.g., motion, acceleration, texture). Four frames (t=0, 10, 20, 30) from a randomly selected video of each synthetic dataset and a sample video from the UCF101 dataset are displayed for comparison, illustrating the increasing realism of the generated videos. The progression demonstrates the evolution from simple static shapes to more dynamic and textured videos, which are increasingly similar in appearance to real-world video data.
read the caption
Figure 1: Samples from our progression of video generation models and additionally included image datasets. We present 4 frames from timestamps t∈{0,10,20,30}𝑡0102030t\in\{0,10,20,30\}italic_t ∈ { 0 , 10 , 20 , 30 } of a randomly sampled video from each of our generated datasets, and UCF101 (left to right).
| HMDB51 | UCF101 | UCF101 | |
|---|---|---|---|
| fine-tune | lin. prob | fine-tune | |
| Random initialization | 18.2 | 8.9 | 51.4 |
| Static circles | 29.2 | 13.2 | 67.8 |
| Moving circles | 52.0 | 15.5 | 85.2 |
| Moving shapes | 56.1 | 20.4 | 86.9 |
| Moving and transforming shapes | 57.6 | 18.8 | 87.7 |
| Acc. and transforming shapes | 58.9 | 18.9 | 88.1 |
| Acc. and transforming textures | 62.4 | 20.9 | 89.4 |
| Acc. and transforming StyleGAN crops | 64.1 | 25.2 | 90.2 |
| Acc. and transforming image crops | 64.1 | 24.8 | 91.3 |
| UCF101 | 63.0 | 48.0 | 91.3 |
🔼 This table presents the classification accuracy achieved on two action recognition datasets, HMDB51 and UCF101, using a VideoMAE model (ViT-B). The model was pre-trained on a series of synthetic video datasets with increasing complexity, reflecting a progression from simple to more realistic video characteristics. The table shows the performance after fine-tuning on HMDB51 and after either fine-tuning or linear probing on UCF101. This allows for a comparison of the model’s performance across different levels of synthetic data realism and training methods, and a comparison to baseline models (random initialization and UCF101 pre-training).
read the caption
Table 1: Additional action recognition results (ViT-B). We present the classification accuracy on HMDB51 after fine-tuning and on UCF101 after linear probing/fine-tuning for all the pre-training datasets in our progression and the two baselines.
In-depth insights#
Synthetic Video#
The research explores the viability of training video representation models using solely synthetic data, bypassing the need for extensive natural video datasets. The core idea revolves around a progressive generation of synthetic videos, starting with simple static shapes and gradually increasing complexity to incorporate motion, acceleration, and realistic textures. This progression allows for a controlled study of how different video properties impact downstream performance. Key findings reveal that models trained on these increasingly complex synthetic videos demonstrate surprisingly strong performance on action recognition tasks, approaching and sometimes exceeding the performance of models trained with real-world video data. The study reveals important correlations between properties of the synthetic videos and downstream performance; higher frame diversity and similarity to natural video data correlate with better results. This study significantly contributes to efficient and controlled video pre-training by suggesting that high-quality synthetic videos can serve as a viable alternative to large-scale natural video datasets.
VideoMAE Pre-train#
The research paper section on “VideoMAE Pre-train” details the methodology of pre-training a VideoMAE model, a masked autoencoder for video, using synthetically generated video data instead of natural videos. The core idea is to progressively increase the complexity of the synthetic data, starting from simple shapes and gradually introducing motion, acceleration, textures, and finally, incorporating real-world image crops. This progression allows the model to learn increasingly complex video representations. The effectiveness of this approach is evaluated by fine-tuning the pre-trained VideoMAE model on standard action recognition benchmarks like UCF101 and HMDB51, demonstrating performance comparable to models trained with natural videos. The study highlights the importance of data properties such as frame diversity, dynamics, and similarity to real video data for effective pre-training. Furthermore, the use of real-world image crops significantly improved the model’s performance, suggesting that natural image statistics, even without the temporal dynamics of natural videos, remain crucial components for learning effective video representations.
Out-of-Distrib. Robust#
The provided text does not contain a heading titled ‘Out-of-Distrib. Robust’. Therefore, I cannot provide a summary for that specific heading. Please provide the relevant text from the PDF research paper.
Data Prop. Analysis#
The Data Properties Analysis section delves into the correlation between various video dataset characteristics and downstream task performance. Frame diversity shows a positive correlation with accuracy, suggesting that more diverse datasets lead to better results. The spectral properties of the frames, particularly those resembling natural image spectra, contribute to improved accuracy. Interestingly, while frame similarity to natural videos (measured using FID) demonstrates a negative correlation with accuracy, video similarity (FVD) shows a weaker, less conclusive relationship. This highlights the significance of considering diverse low-level features beyond simple visual similarity when designing synthetic datasets for video representation learning. Color similarity to natural video data also plays a role in model performance, suggesting that datasets with similar color distributions perform better. This analysis underscores the importance of meticulously evaluating low-level properties and incorporating natural image characteristics to create more effective training data for video models.
Future Work#
The authors outline several key areas for future research. Extending the approach to other tasks and training regimes beyond action recognition is crucial to demonstrate broader applicability. They also plan to explore the performance of their method with different model architectures, acknowledging that the current findings are specific to VideoMAE. A key area of investigation involves a deeper understanding of the optimal type and quantity of natural image data for integration with synthetic datasets, going beyond simple image crops. Finally, the potential of using the synthetic data as augmentations within existing pre-training methods will be explored. This multifaceted approach to future work underscores a commitment to rigorous validation and expansion of the presented findings.
More visual insights#
More on figures

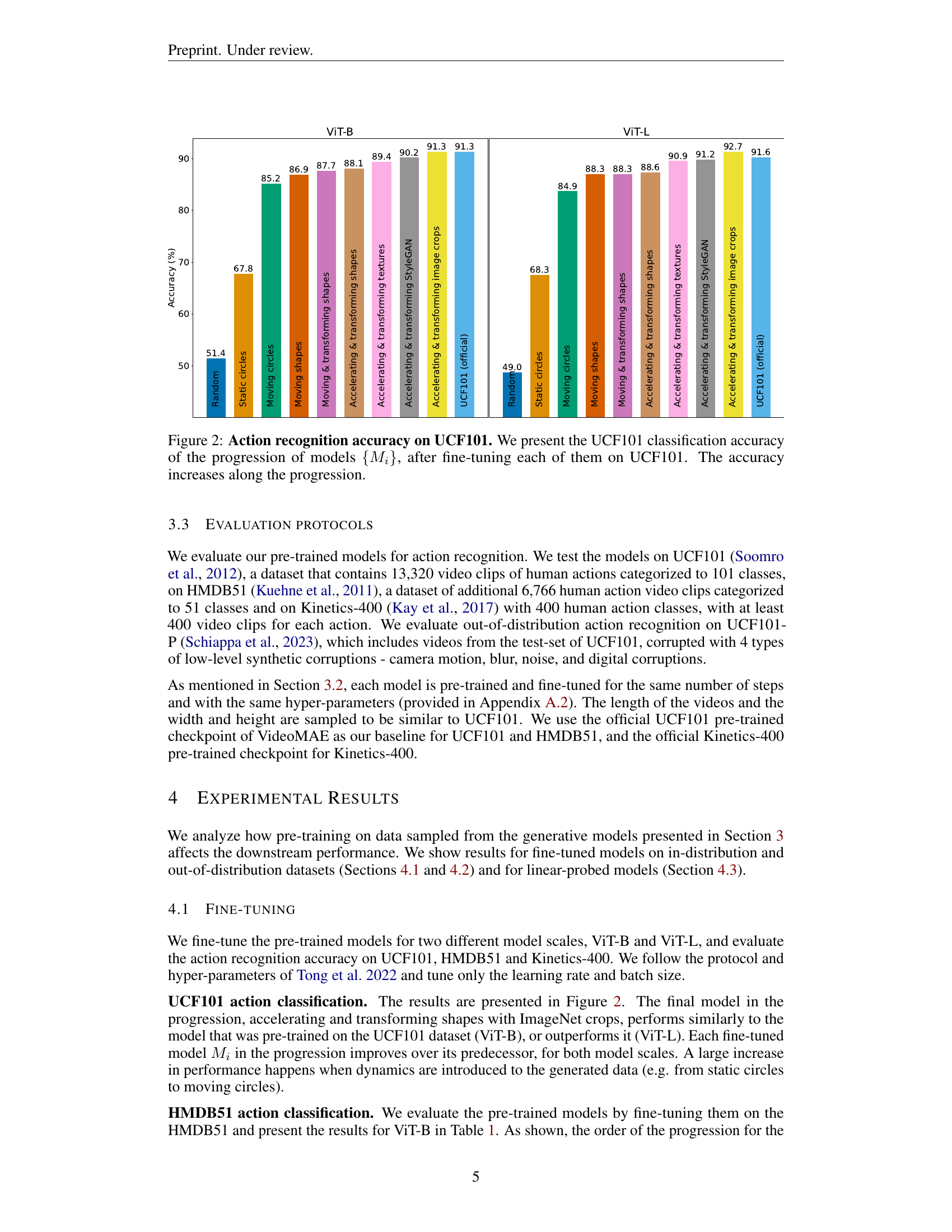
🔼 This figure displays the UCF101 action recognition accuracy for a series of models (Mi). Each model (Mi) in the series was trained on a different synthetic dataset, designed with increasing complexity and realism (see figure 1). The x-axis represents the different datasets used to pre-train the models, beginning with simple static circles and culminating in datasets incorporating dynamic transformations and natural image crops. The y-axis shows the classification accuracy achieved on the UCF101 benchmark after fine-tuning each model. The graph clearly demonstrates that as the complexity and realism of the training dataset increase, the accuracy on UCF101 also improves.
read the caption
Figure 2: Action recognition accuracy on UCF101. We present the UCF101 classification accuracy of the progression of models {Mi}subscript𝑀𝑖\{M_{i}\}{ italic_M start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT }, after fine-tuning each of them on UCF101. The accuracy increases along the progression.

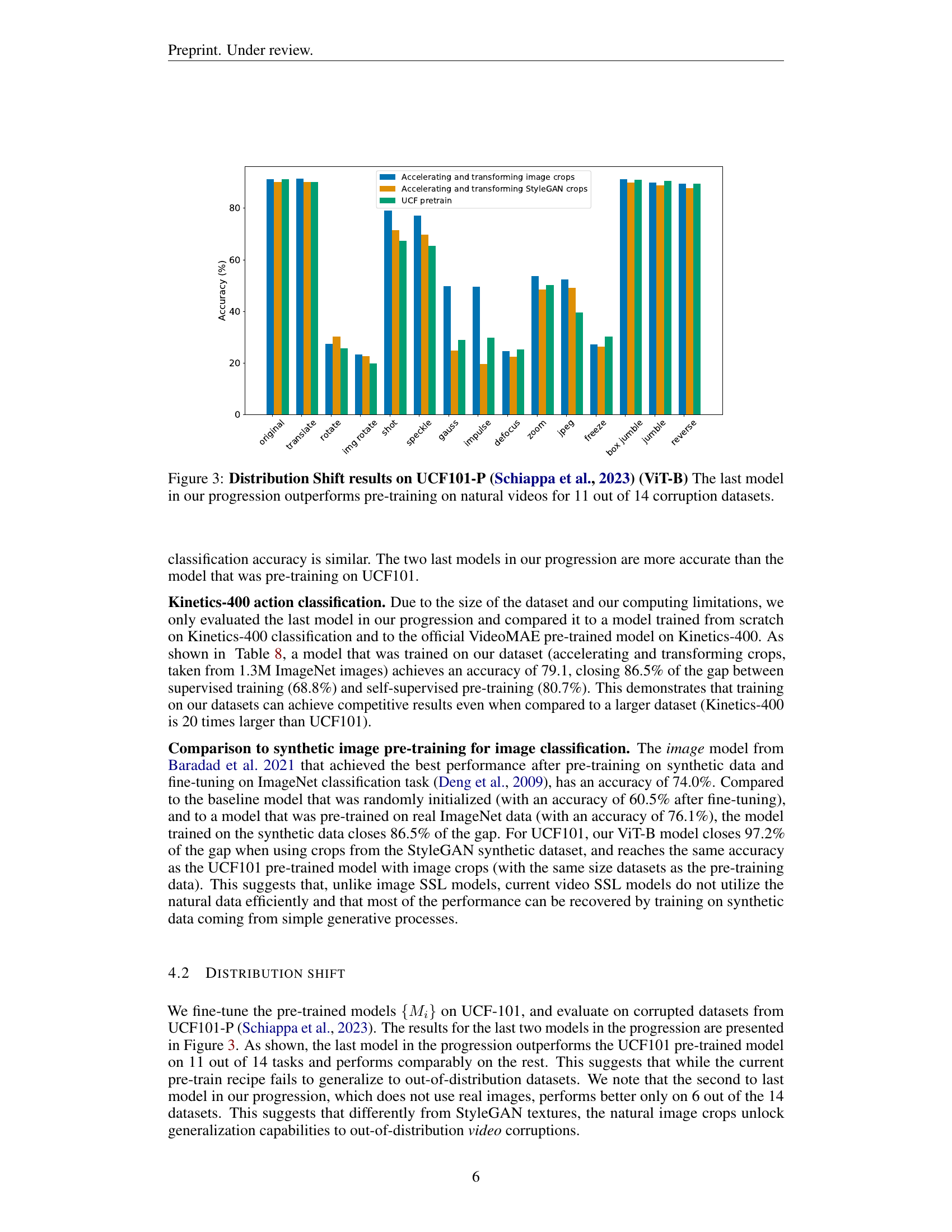
🔼 This figure presents the performance comparison of different video models on the UCF101-P dataset, which contains corrupted versions of UCF101 videos. The models tested include those pre-trained on synthetic datasets created using a progression of generative models and a VideoMAE model pre-trained on natural UCF101 videos (a standard baseline). The x-axis shows the different types of corruptions applied to the UCF101-P videos (e.g., blur, noise, camera motion). The y-axis shows the accuracy of each model on these corrupted videos. The key observation is that the model pre-trained on the final synthetic dataset in the progression significantly outperforms the model pre-trained on natural videos in 11 out of the 14 corruption types. This demonstrates the effectiveness of the synthetic data approach in learning robust video representations that generalize well to noisy or corrupted data.
read the caption
Figure 3: Distribution Shift results on UCF101-P (Schiappa et al., 2023) (ViT-B) The last model in our progression outperforms pre-training on natural videos for 11 out of 14 corruption datasets.

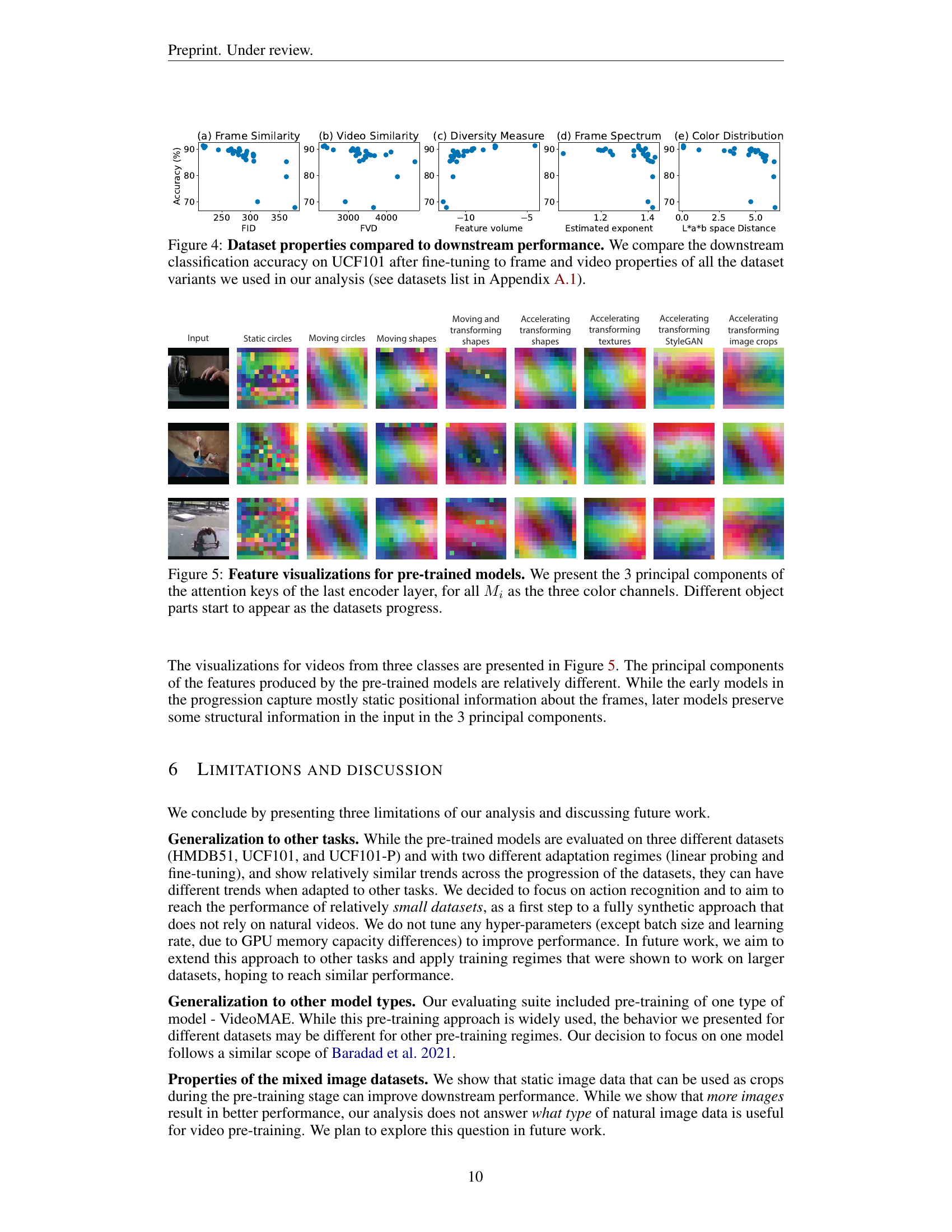
🔼 This figure visualizes the correlation between various properties of the synthetic video datasets and their corresponding downstream performance on the UCF101 action recognition task. The datasets, generated using different generative processes and incorporating increasing levels of realism, are evaluated on several metrics reflecting frame and video properties: Frame Similarity (FID score measuring visual similarity to UCF101 frames), Video Similarity (FVD score measuring video-level similarity to UCF101 videos), Frame Diversity (measuring diversity within each dataset), Frame Spectrum (analyzing the frequency distribution of the frames), and Color Distribution (comparing color distributions to that of UCF101). Scatter plots illustrate the relationship between each dataset’s performance (measured as accuracy on UCF101 after fine-tuning) and its value on the different metrics. The analysis aims to identify which low-level video properties are most strongly correlated with achieving high accuracy, providing insights into the design of effective synthetic video datasets for pre-training.
read the caption
Figure 4: Dataset properties compared to downstream performance. We compare the downstream classification accuracy on UCF101 after fine-tuning to frame and video properties of all the dataset variants we used in our analysis (see datasets list in Section A.1).

🔼 This figure visualizes the learned representations from the VideoMAE model’s encoder after training on a series of synthetic video datasets. Each dataset progressively incorporates more realistic video properties, such as object movement, shape transformation, and texture. The visualization uses the three principal components of the attention keys from the last encoder layer as red, green, and blue color channels. By observing the changes across the different datasets (represented as M subscript i), we can see how the model’s understanding of the video content evolves. In the earlier datasets, representations are relatively simple; however, they become increasingly complex as the datasets reflect more realistic properties and incorporate natural images. The appearance of different object parts in the visualization highlights this improvement.
read the caption
Figure 5: Feature visualizations for pre-trained models. We present the 3 principal components of the attention keys of the last encoder layer, for all Misubscript𝑀𝑖M_{i}italic_M start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT as the three color channels. Different object parts start to appear as the datasets progress.
More on tables
| Configuration | Accuracy (%) |
|---|---|
| 300k images | 90.5 |
| 150k images & 150k StyleGAN | 90.6 |
| 300k StyleGAN | 90.2 |
| 300k statistical textures | 89.4 |
| 1.3M images | 91.3 |
| Replacing 5% of videos w/ static images | 88.5 |
🔼 This table presents the results of experiments evaluating different methods for incorporating natural images into the training process of a ViT-B (Vision Transformer - Base) model. The goal is to determine the impact of various amounts and ways of including natural images on the model’s performance when evaluated on the UCF101 action recognition dataset. The table shows the accuracy achieved by the model trained with varying configurations, such as different numbers of natural images (300k, 150k, etc.), and in combination with StyleGAN-generated synthetic textures.
read the caption
Table 2: Incorporating natural images into training (ViT-B). We ablate different approaches for incorporating natural images during training, and evaluate them on UCF101.
| Configuration | Accuracy (%) |
|---|---|
| Static StyleGAN crops | 90.2 |
| Dynamic StyleGAN crops | 89.2 |
| Dynamic StyleGAN videos | 68.7 |
🔼 This table presents the results of pre-training a ViT-B VideoMAE model on datasets using synthetic StyleGAN textures, comparing static textures to those with added dynamics. The goal was to determine if introducing movement to the textures improved the model’s performance on downstream tasks. The results show that adding dynamics to the StyleGAN textures did not lead to performance improvements, indicating that static StyleGAN textures are sufficient for pre-training in this context.
read the caption
Table 3: Incorporating synthetic textures into training (ViT-B). Introducing dynamics to the StyleGAN textures does not improve performance.
| Hyperparameter | Value |
|---|---|
| masking ratio | 0.75 |
| training epochs | 3200 |
| optimizer | AdamW |
| base learning | 3e-4 |
| weight decay | 0.05 |
| optimizer momentum | β₁=0.9, β₂=0.95 |
| batch size | 256 |
| learning rate schedule | cosine decay |
| warmup epochs | 40 |
| augmentation | MultiScaleCrop |
🔼 This table details the hyperparameters used for pre-training the ViT-B (Vision Transformer - Base) model using the VideoMAE (Video Masked Autoencoder) method. It lists the values for parameters such as masking ratio, number of training epochs, optimizer, base learning rate, weight decay, momentum, batch size, learning rate schedule, warmup epochs, and augmentation techniques.
read the caption
Table 4: Pre-training settings (ViT-B).
| Hyperparameter | Value |
|---|---|
| training epochs | 100 |
| optimizer | AdamW |
| base learning | 1e-3 |
| weight decay | 0.05 |
| optimizer momentum | (\beta_{1}=0.9,\beta_{2}=0.95) |
| batch size | 256 |
| learning rate schedule | cosine decay |
| warmup epochs | 5 |
| flip augmentation | yes |
| RandAug | (9, 0.5) |
| label smoothing | 0.1 |
| mixup | 0.8 |
| cutmix | 1.0 |
| drop path | 0.2 |
| dropout | 0.0 |
| layer-wise lr decay | 0.7 |
| test clips | 5 |
| test crops | 3 |
🔼 This table details the hyperparameters used for fine-tuning the ViT-B model on the UCF101 dataset. It includes settings for the optimizer (AdamW), learning rate, weight decay, batch size, learning rate schedule, and data augmentation techniques (flip, RandAug, label smoothing, mixup, cutmix, drop path, and dropout). These settings were used to evaluate the performance of the VideoMAE model pre-trained on the synthetic datasets.
read the caption
Table 5: Fine-tuning settings (ViT-B)
| Hyperparameter | Value |
|---|---|
| training epochs | 100 |
| optimizer | AdamW |
| base learning | 1e-2 |
| weight decay | 0.0 |
🔼 This table details the hyperparameters used for the linear probing experiment on the ViT-B model. Linear probing is a method used to evaluate the quality of pre-trained models by adding a linear layer on top of the pre-trained model and training only that new layer. It shows the settings for the optimization process (optimizer, learning rate, weight decay, etc.), data augmentation, and other relevant parameters used during the linear probing phase.
read the caption
Table 6: Linear probing settings (ViT-B)
| Hyperparameter | Value |
|---|---|
| Initial speed range | (1.2, 3.0) |
| Acceleration speed range | (-0.06, 0.06) |
| Rotation speed range | (-π/100, π/100) |
| Scale X speed range | (-0.005, 0.005) |
| Scale Y speed range | (-0.005, 0.005) |
| Shear X speed range | (-0.005, 0.005) |
| Shear Y speed range | (-0.005, 0.005) |
🔼 Table 7 presents the hyperparameters used in generating the synthetic video datasets. It details the ranges or values for parameters such as initial speed, acceleration, rotation, scaling, and shearing, which control the visual characteristics (movement, transformations) of the objects within the generated videos. These settings are crucial for creating the progression of datasets used in the experiments, offering a controllable and transparent method for studying the effect of progressively complex video features on downstream task performance.
read the caption
Table 7: Dataset generation settings
| Pre-training Dataset | Accuracy |
|---|---|
| Scratch | 68.8 |
| Accelerating and transforming image crops | 79.1 |
| Kinetics-400 | 80.7 |
🔼 Table 8 presents the results of the Kinetics-400 action recognition task. The performance of a model fine-tuned on the Kinetics-400 dataset after pre-training on the final synthetic video dataset (accelerating and transforming image crops) is compared to the performance of a model trained from scratch and a model using the official pre-trained VideoMAE weights on Kinetics-400. This comparison demonstrates the effectiveness of the synthetic video dataset in closing the gap between training from scratch and using natural video data for pre-training.
read the caption
Table 8: Results on Kinetics-400 test set (Kay et al., 2017). The kinetics-400 result is obtained by fine-tuning from the official pretrained VideoMAE checkpoint (Tong et al., 2022).
| Dataset configuration | UCF101 |
|---|---|
| Moving circles | 84.9 |
| Moving shapes | 88.3 |
| Moving and transforming shapes | 88.3 |
| Accelerating and transforming shapes | 88.6 |
| Accelerating and transforming textures | 90.9 |
🔼 This table presents the results of experiments using Vision Transformer - base (ViT-B) model pre-trained on variations of synthetic video datasets, focusing on the impact of slower object speeds. The datasets are similar to those described in the main progression of the paper but with object speeds reduced by 50%. The accuracy is measured on the UCF101 action recognition task after fine-tuning the pre-trained model. This allows for a comparison of performance with the original, faster-moving object datasets, showing the effect of this specific parameter change.
read the caption
Table 9: Additional datasets (ViT-B). Moving objects with slower speed
| Dataset configuration | UCF101 |
|---|---|
| Dynamic StylaGAN high-greq | 68.7 |
| Replacing 5% of videos w/ StyleGAN | 88.2 |
| 150k images & 150k statistical textures | 89.7 |
| 300k images w/ colored background | 89.9 |
| 300k images w/ image background | 91.0 |
🔼 This table presents additional experimental results obtained using variations of the ViT-B model, focusing on the impact of different texture types and background diversity on the model’s performance. Specifically, it explores various configurations, including the use of Dynamic StyleGAN textures, combinations of real images and synthetic textures, and the effect of colored or image backgrounds, highlighting their contributions to action recognition accuracy on the UCF101 dataset.
read the caption
Table 10: Additional datasets (ViT-B). More texture types and more diverse background
| Dataset configuration | UCF101 |
|---|---|
| Accelerating and transforming shapes, 25% w/ UCF101 | 90.4 |
| Accelerating and transforming shapes, 75% w/ UCF101 | 90.6 |
| Accelerating and transforming image crops, 50% w/ UCF101 | 92.0 |
🔼 This table presents the results of additional experiments conducted to evaluate the impact of mixing real-world video data from the UCF101 dataset with synthetic data during the pre-training phase. Three different combinations of real and synthetic data are tested, varying the proportion of real video data included. The experiments aim to assess whether including real video clips alongside synthetic videos improves downstream performance on the action recognition task using the ViT-B model.
read the caption
Table 11: Additional datasets (ViT-B). Mix with real videos
| Dataset configuration | UCF101 |
|---|---|
| Statistical textures | 88.9 |
| Statistical textures w/ colored background | 87.8 |
| Moving Dynamic StyleGAN crops | 87.5 |
| 300k image crops | 90.1 |
| 150k image crops & 150 statistical textures | 89.2 |
| 300k image crops w/ colored background | 89.5 |
| 300k image crops w/ image background | 89.5 |
| 1.3M image crops | 89.8 |
🔼 This table presents the UCF101 classification accuracy achieved by fine-tuning a ViT-B model pre-trained on various datasets with saturated textures. These datasets explore different texture types and image background variations to assess their impact on model performance. The results highlight the effect of altering texture saturation and the inclusion of colored or image backgrounds on downstream action recognition accuracy.
read the caption
Table 12: Additional datasets (ViT-B). Saturated textures
Full paper#