↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many existing studies use simple instructions to train embodied AI agents, neglecting the richness and diversity of human communication. This paper addresses this gap by investigating how different types of language informativeness (feedback on past behaviors and future guidance) and diversity (variation in language expressions) affect agent learning. The study highlights a critical limitation in current AI training methods and points to improvements needed for more natural and effective human-AI interactions.
The researchers used Decision Transformer (DT), a popular offline RL model, and created a new Language-Teachable DT (LTDT) that incorporates diverse and informative language feedback. They found that agents trained with diverse and informative language significantly outperformed those trained with simple instructions or no language at all. Specifically, combining hindsight (feedback on past mistakes) and foresight (guidance for future actions) proved especially beneficial. This work introduces a novel, human-centered approach to AI training that leads to more robust and adaptable agents, and provides a valuable framework for future research in this field.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances our understanding of how language influences reinforcement learning agents. It introduces a novel approach to teaching embodied agents by using diverse and informative language, improving their learning efficiency and adaptability. The findings are relevant to current trends in human-AI interaction and open avenues for creating more robust and generalizable AI systems.
Visual Insights#

🔼 This figure provides a visual overview of the four experimental environments used in the paper: HomeGrid, ALFWorld, Messenger, and MetaWorld. For each environment, it displays: 1. The task(s) to be learned: A brief description of the goal the agent needs to achieve in each environment. 2. Examples of language feedback: Illustrations of both hand-crafted and GPT-4 generated language feedback, categorized as either ‘hindsight’ (comments on past actions) or ‘foresight’ (guidance for future actions). The hand-crafted templates are represented by the gear icon, while the GPT-4 generated feedback is indicated by the GPT icon. 3. Low-level actions: A list of the basic actions the agent can take within each specific environment to interact with it and achieve the tasks. This provides context for understanding how the language feedback influences the agent’s actions. The figure aims to show the diversity of tasks and the different types of language used to guide agent learning in different settings.
read the caption
Figure 1: An overview of four environments used for experiments. It shows tasks to be learned in each environment; examples of hindsight (marked H) and foresight (F) language feedback (next to the gear icon are hand-crafted templates and next to the GPT icon are GPT-4 generated feedback); as well as low-level actions in each environment.
| Env | Image Observation | Instruction Manual | Text State Description |
|---|---|---|---|
| HomeGrid | Yes | No | No |
| AlfWorld | No | No | Yes |
| Messenger | No | Yes | No |
| MetaWorld | No | No | No |
🔼 This table details the type of information each environment provides to the agents, regardless of whether they are trained with language or not. It shows whether each environment offers image observation data, instruction manuals, text descriptions, and state information, to provide a comprehensive view of available sensory input for agents during both training and testing phases.
read the caption
Table 1: Information provided by each environment.
In-depth insights#
Language Teachability#
The research explores the concept of ‘Language Teachability’ within the context of embodied reinforcement learning agents. It investigates how the informativeness (hindsight and foresight feedback) and diversity of language instructions impact an agent’s learning and adaptation. The study reveals that agents trained with diverse and informative language feedback exhibit significantly improved performance and generalization compared to agents trained with simpler instructions or no language at all. Combining hindsight and foresight feedback is particularly beneficial, enhancing the agent’s understanding of both past mistakes and future guidance. Furthermore, the use of a GPT-augmented language pool to increase diversity leads to even better results. This highlights the crucial role of rich, human-like language in teaching embodied agents complex tasks, offering a promising avenue for enhancing their learning efficiency and robustness in open-world scenarios.
RL Agent Training#
The research explores offline reinforcement learning (RL) agent training using diverse and informative language feedback. Decision Transformer (DT) serves as the backbone architecture, extended to a multi-modal Language-Teachable DT (LTDT). Training leverages expert agent trajectories and hand-crafted language templates augmented with GPT-4 for diversity. Informativeness is controlled through hindsight (feedback on past actions) and foresight (guidance for future actions). The study demonstrates that agents trained with diverse and informative language significantly outperform those trained with simple instructions or no language. Enhanced generalization and rapid adaptation to new tasks are observed as key benefits of this approach, highlighting the importance of rich language in embodied agent learning.
Diverse Language#
The research explores the impact of diverse language on embodied reinforcement learning agents. It finds that training agents with diverse language significantly improves performance, surpassing models trained with only simple, repetitive instructions or no language at all. This enhanced performance stems from the agents’ improved ability to generalize and adapt to new, unseen tasks. The study leverages GPT-4 to augment hand-crafted language templates, generating a wider range of expressions for the same instruction, thus creating a richer learning experience. Diversity in language, therefore, acts as a crucial factor in facilitating a more robust and adaptable agent. The results consistently demonstrate the importance of moving beyond simple instruction sets to encompass the nuanced and varied nature of human communication in training these AI agents. This richer language input allows for better generalization and faster adaptation to new scenarios, highlighting the pivotal role of natural language use in teaching embodied agents. The findings suggest that future research should focus on creating more realistic and complex language interactions, rather than relying on simplistic instructions, to unlock the full potential of language-guided reinforcement learning.
Informative Feedback#
The research explores the impact of informative language feedback on embodied reinforcement learning agents. Hindsight feedback, commenting on past actions, and foresight feedback, guiding future actions, are investigated. Results show that agents trained with both types of feedback significantly outperform those trained with only one or no feedback. Combining hindsight and foresight proved particularly effective, enhancing generalization and adaptability to novel tasks. The study highlights the importance of rich, informative language feedback in training embodied agents, moving beyond simple instructions towards more nuanced and human-like communication strategies for improved performance. Diversity in language expression, also explored, further boosted agent performance, emphasizing the value of varied phrasing in teaching complex tasks.
Future Research#
Future research directions identified in the paper include extending the work to more realistic and complex environments that incorporate real-world visual inputs and challenges. The authors plan to evaluate agents in settings that involve real-life visual inputs and challenges beyond simulated game-based environments. Addressing the limitations of current language models is also a priority, aiming to incorporate a broader spectrum of language variations and test agents in scenarios involving more diverse linguistic inputs to capture nuances like idioms and dialects missed by current models. Ethical considerations are highlighted, suggesting future work to ensure that the teachable nature of the AI agents promotes safer and more ethical interactions. Investigating the influence of language frequency on agent performance is another suggested area of future research. Finally, the authors aim to expand on multi-turn human-machine dialogues by refining the current system to create more realistic and natural interactions.
More visual insights#
More on figures

🔼 This figure illustrates the process of generating both hindsight and foresight language feedback within a reinforcement learning framework. An agent (π) interacts with an environment, taking actions. Simultaneously, an expert agent (π*) with complete knowledge of the environment’s state generates feedback based on the agent’s actions. Hindsight feedback comments on the agent’s past action at time t-1, by comparing it to the expert agent’s corresponding action at t-1. Foresight feedback, on the other hand, guides the agent’s future action at time t by suggesting an action based on the expert agent’s action at time t. To enhance the diversity of feedback, the system employs a pool of GPT-augmented language templates, randomly selecting one to deliver instructions.
read the caption
Figure 2: A demonstration of hindsight and foresight language feedback generation. In our framework, the agent π𝜋\piitalic_π executes the trajectory, while the expert agent π∗superscript𝜋\pi^{*}italic_π start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT, with access to privileged ground truth knowledge, is used solely to provide information for generating language feedback to π𝜋\piitalic_π. At time step t𝑡titalic_t, hindsight language is generated by comparing the agent’s action at−1subscript𝑎𝑡1a_{t-1}italic_a start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT with the expert agent’s action at−1∗superscriptsubscript𝑎𝑡1a_{t-1}^{*}italic_a start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT, whereas foresight language is generated by referring to the expert agent’s action at∗superscriptsubscript𝑎𝑡a_{t}^{*}italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT to guide the agent on the next step. To increase the diversity of language feedback, we construct a pool of language templates comprising GPT-augmented languages, and sample candidate instructions as online language feedback.

🔼 The Language-Teachable Decision Transformer (LTDT) architecture takes as input a sequence of states, rewards, actions, and language feedback. The task description is provided at the beginning of the sequence. All inputs are embedded and then processed by a causal transformer, which maintains the order of the sequence. The output of the transformer predicts the next action, conditioned on the prior sequence.
read the caption
Figure 3: Language-Teachable Decision Transformer.

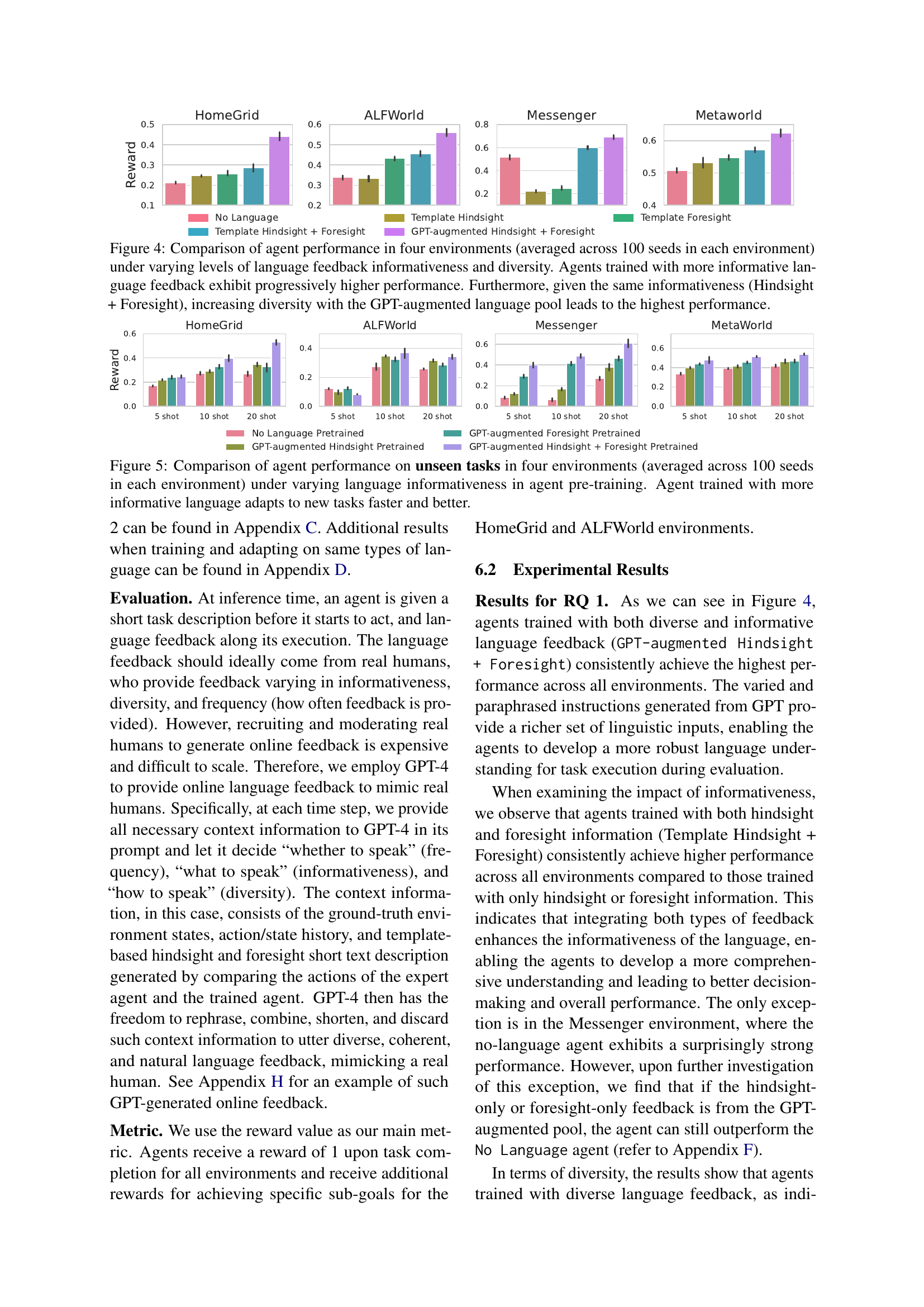
🔼 This figure displays the performance of reinforcement learning agents across four distinct environments (HomeGrid, ALFWorld, Messenger, and MetaWorld). The performance is evaluated under different conditions of language feedback: no language, only foresight language, only hindsight language, both hindsight and foresight using hand-crafted templates, and finally both hindsight and foresight using GPT-augmented language templates. The results demonstrate that agents trained with increasingly more informative language feedback (hindsight and foresight being most informative) achieve higher performance. Furthermore, when comparing agents with the same level of informativeness (hindsight + foresight), the agents trained with the diverse GPT-generated language templates significantly outperformed those trained with hand-crafted templates, highlighting the positive impact of language diversity on agent learning.
read the caption
Figure 4: Comparison of agent performance in four environments (averaged across 100 seeds in each environment) under varying levels of language feedback informativeness and diversity. Agents trained with more informative language feedback exhibit progressively higher performance. Furthermore, given the same informativeness (Hindsight + Foresight), increasing diversity with the GPT-augmented language pool leads to the highest performance.

🔼 This figure displays the performance of agents pre-trained with varying levels of language informativeness when adapting to unseen tasks. Four different environments (HomeGrid, ALFWorld, Messenger, and MetaWorld) were used, with results averaged across 100 random seeds for each. The agents were pre-trained using either no language, hindsight language, foresight language, or both. The x-axis represents the number of shots (5, 10, or 20) provided during the adaptation phase, and the y-axis indicates the average reward achieved. The results clearly demonstrate that pre-training with more informative language (hindsight and foresight) leads to significantly better adaptation performance on unseen tasks, outperforming agents trained with less informative feedback.
read the caption
Figure 5: Comparison of agent performance on unseen tasks in four environments (averaged across 100 seeds in each environment) under varying language informativeness in agent pre-training. Agent trained with more informative language adapts to new tasks faster and better.

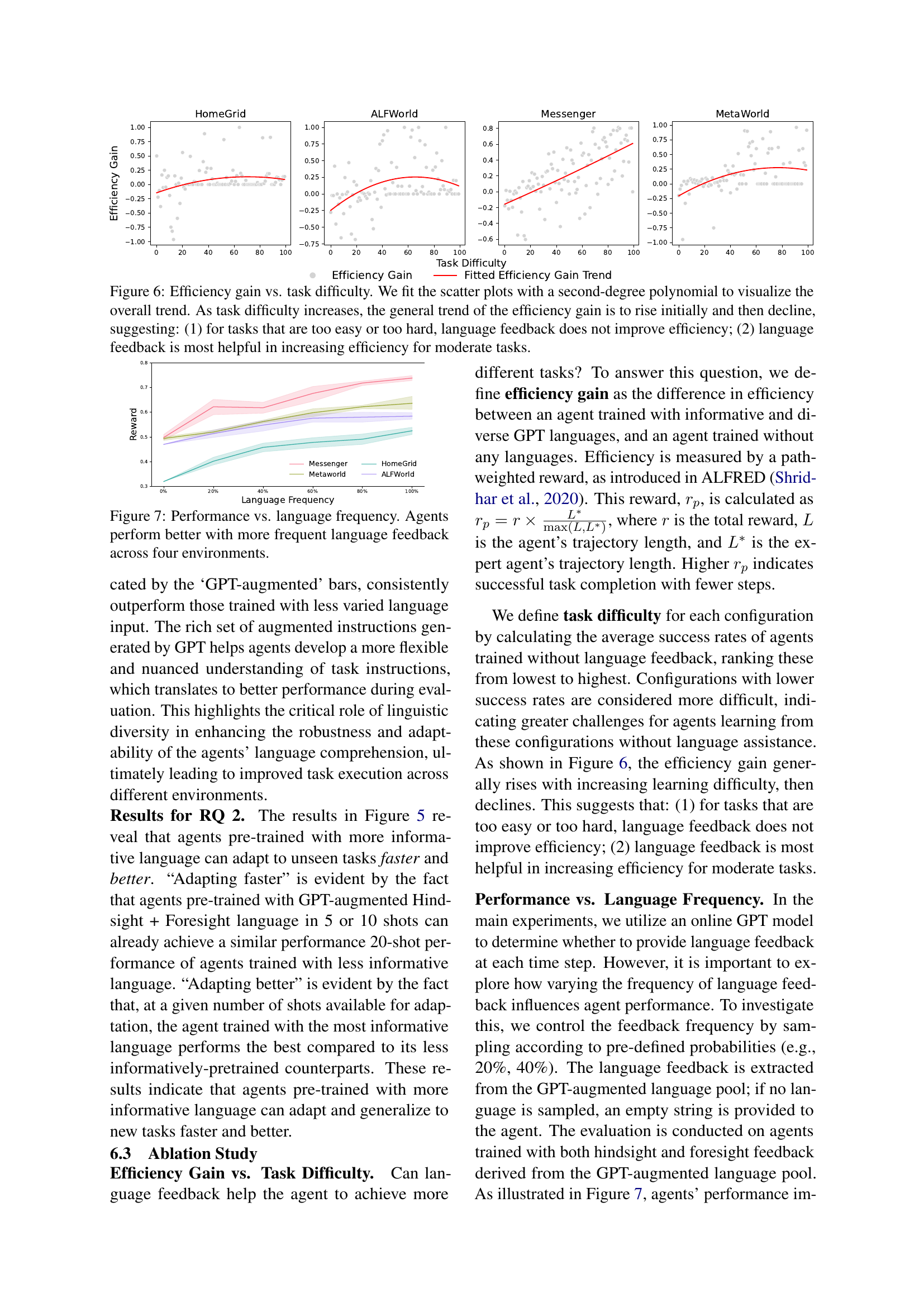
🔼 This figure shows the relationship between task difficulty and the efficiency gain achieved by using language feedback in reinforcement learning. The x-axis represents task difficulty, with easier tasks on the left and harder tasks on the right. Task difficulty is measured by the success rate of agents without language feedback. The y-axis shows the efficiency gain, which is calculated as the difference in efficiency between agents trained with informative and diverse language feedback and agents trained without any language feedback. Efficiency is measured by a path-weighted reward. The plot shows that the efficiency gain increases initially as task difficulty rises, reaching a peak at a moderate level of difficulty. Beyond that moderate point, the efficiency gain begins to decrease as tasks become harder. This suggests that language feedback is most beneficial for tasks of moderate difficulty. For very easy tasks, language feedback provides little additional benefit, and for very hard tasks, the challenges may be too significant for language feedback to substantially improve performance.
read the caption
Figure 6: Efficiency gain vs. task difficulty. We fit the scatter plots with a second-degree polynomial to visualize the overall trend. As task difficulty increases, the general trend of the efficiency gain is to rise initially and then decline, suggesting: (1) for tasks that are too easy or too hard, language feedback does not improve efficiency; (2) language feedback is most helpful in increasing efficiency for moderate tasks.

🔼 This figure displays the results of an experiment comparing the performance of reinforcement learning agents trained with varying frequencies of language feedback. The x-axis represents the percentage of timesteps during training where language feedback was provided, ranging from 0% to 100%. The y-axis represents the average reward achieved by the agents across four different environments (HomeGrid, ALFWorld, Messenger, and MetaWorld). The graph shows a positive correlation between language feedback frequency and agent performance across all four environments, indicating that more frequent feedback leads to better learning outcomes. The results suggest that continuous interaction and guidance, through frequent language feedback, significantly benefits the learning process of embodied reinforcement learning agents.
read the caption
Figure 7: Performance vs. language frequency. Agents perform better with more frequent language feedback across four environments.

🔼 This figure displays the results of an ablation study that investigates the impact of corrupted language feedback on agent performance. Two scenarios are considered: (1) no language feedback is provided during evaluation and (2) at each step, disturbed language feedback is given. The results demonstrate that agents trained with GPT-augmented language consistently outperform agents trained without any language, even when dealing with disturbed feedback. Interestingly, in some environments, the GPT-augmented agents still perform better even when no feedback is given, highlighting the robustness and effectiveness of this language training approach.
read the caption
Figure 8: We investigate two special evaluation settings: (1) no language feedback is provided during evaluation and (2) disturbed language feedback is given at every step. Results show that agents trained with the GPT-augmented language still outperform the no-language agent (the black dotted line) in the disturbed setting, and also achieve better performance in some environments while no language is given.

🔼 This figure displays the results of an experiment conducted in the Messenger environment, which is a grid world where an agent must retrieve a message from one entity and deliver it to another, avoiding enemies. The experiment compared the performance of agents trained with varying degrees of informativeness and diversity in their language feedback, showing that agents trained with more diverse and informative language (both foresight and hindsight) perform significantly better than those trained without language. The graph shows reward performance for agents trained under four language conditions: no language, GPT-augmented hindsight only, GPT-augmented foresight only, and GPT-augmented hindsight and foresight together. The combined hindsight and foresight training results in the best performance, highlighting the importance of both types of feedback for improving agents’ ability to learn and perform the task.
read the caption
Figure 9: In the Messenger environment, when trained with more diverse foresight and hindsight languages, the agents can perform better than those trained without languages. Furthermore, agents trained with more informative languages demonstrate stronger performance.

🔼 Figure 10 presents three examples illustrating how the online GPT model generates language feedback during evaluation. In the first example, both hindsight (commenting on past actions) and foresight (guidance for future actions) information are combined into a single, fluent sentence. The second example shows GPT prioritizing foresight feedback and omitting the hindsight feedback. The third example demonstrates a scenario where GPT chooses not to provide feedback because it judges that the agent does not currently need assistance.
read the caption
Figure 10: Examples for language feedback generated by online GPT in evaluation.
More on tables
| Env | # Hind Templates | # Fore Templates | # AUG |
|---|---|---|---|
| HomeGrid | 20 | 9 | 70 |
| AlfWorld | 4 | 4 | 200 |
| Messenger | 4 | 4 | 80 |
| MetaWorld | 2 | 6 | 180 |
🔼 This table shows the number of hand-crafted templates for hindsight and foresight feedback used in each of the four simulated environments for the reinforcement learning experiments. It also indicates the number of augmented sentences generated by GPT-4 for each template, increasing the diversity of language feedback used to train the agents.
read the caption
Table 2: Number of templates and augmented sentences for each environment, where ’# Hind Templates’ refers to the number of hindsight templates, ’# Fore Templates’ refers to the number of foresight templates, and ’# AUG’ refers to the number of GPT-augmented sentences per template.
| HomeGrid Env on RQ 1 | Aligned Eval | Online GPT Eval |
|---|---|---|
| Training Language | Aligned Eval | Online GPT Eval |
| No Lang | 0.235 | 0.212 |
| Template H | 0.260 | 0.246 |
| Template F | 0.305 | 0.262 |
| Template H + F | 0.325 | 0.285 |
| GPT-augmented H + F | 0.472 | 0.442 |
| Messenger Env on RQ 2 (20 Shots) | ||
| Training Language | Aligned Adapt & Eval | Online GPT Eval |
| No Lang | 0.323 | 0.270 |
| GPT-augmented H | 0.450 | 0.378 |
| GPT-augmented F | 0.512 | 0.464 |
| GPT-augmented H + F | 0.623 | 0.608 |
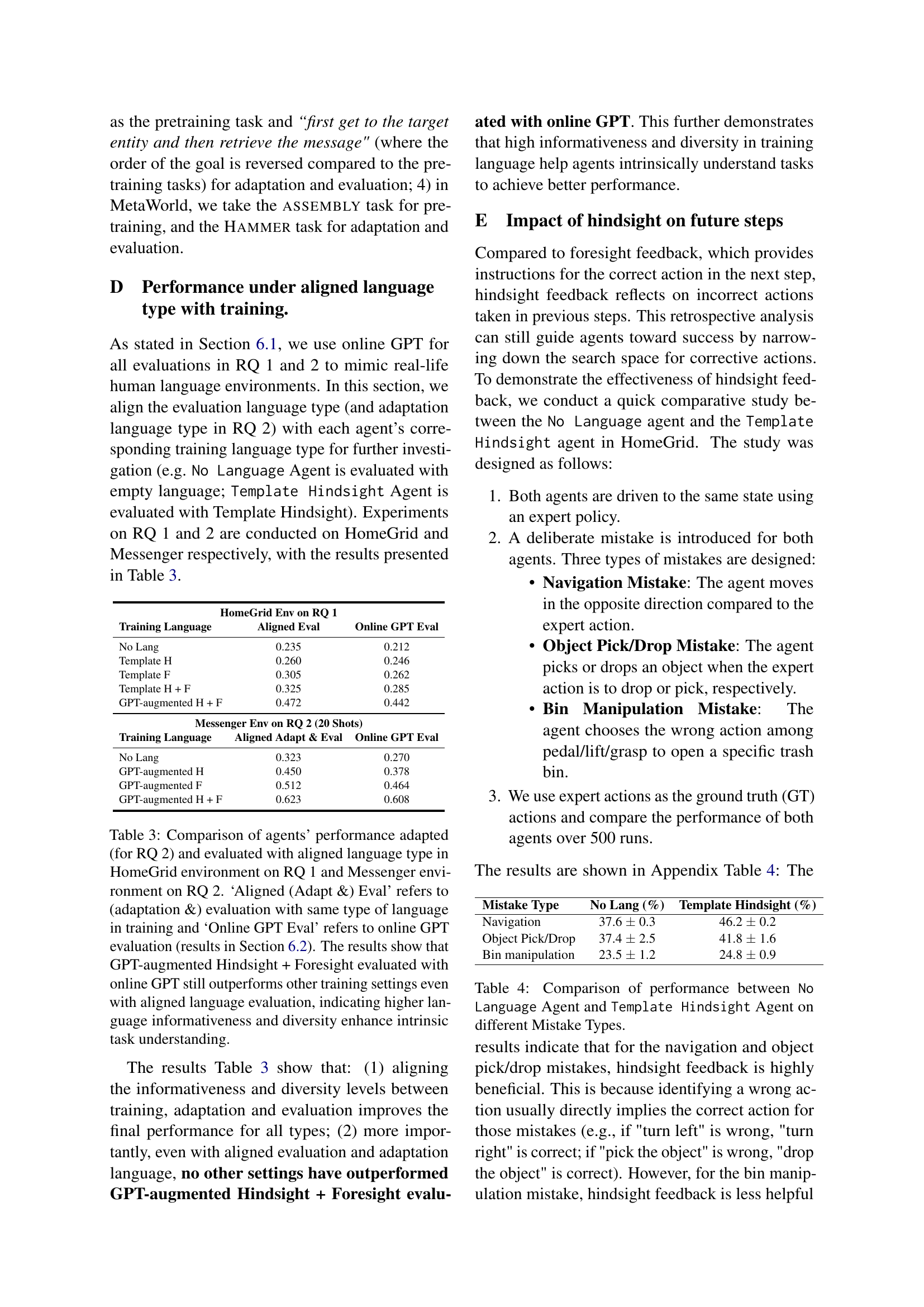
🔼 This table compares the performance of agents trained with different types of language feedback (no language, template-based hindsight, template-based foresight, template-based hindsight and foresight, GPT-augmented hindsight and foresight) when evaluated using either the same type of language used during training or online GPT-generated language. The results demonstrate the superior performance of agents trained with GPT-augmented hindsight and foresight language feedback, regardless of the evaluation language used. This highlights the importance of informative and diverse language for improving agent performance and intrinsic task understanding.
read the caption
Table 3: Comparison of agents’ performance adapted (for RQ 2) and evaluated with aligned language type in HomeGrid environment on RQ 1 and Messenger environment on RQ 2. ‘Aligned (Adapt &) Eval’ refers to (adaptation &) evaluation with same type of language in training and ‘Online GPT Eval’ refers to online GPT evaluation (results in Section 6.2). The results show that GPT-augmented Hindsight + Foresight evaluated with online GPT still outperforms other training settings even with aligned language evaluation, indicating higher language informativeness and diversity enhance intrinsic task understanding.
| Mistake Type | No Lang (%) | Template Hindsight (%) |
|---|---|---|
| Navigation | 37.6 ± 0.3 | 46.2 ± 0.2 |
| Object Pick/Drop | 37.4 ± 2.5 | 41.8 ± 1.6 |
| Bin manipulation | 23.5 ± 1.2 | 24.8 ± 0.9 |
🔼 This table presents a comparison of the performance of two agent types, ‘No Language Agent’ and ‘Template Hindsight Agent’, across three distinct error scenarios in the HomeGrid environment. The error scenarios are: navigation mistakes (incorrect directional movement), object pick/drop mistakes (incorrectly picking up or dropping an object), and bin manipulation mistakes (incorrect interaction with bins). The table quantifies the success rate (percentage) of each agent in each error scenario, demonstrating the impact of hindsight language feedback on correcting specific error types.
read the caption
Table 4: Comparison of performance between No Language Agent and Template Hindsight Agent on different Mistake Types.
| Hyperparameters | Value |
|---|---|
| Number of transformer layers | 3 |
| Number of attention heads | 1 |
| Embedding dimension | 128 |
| Nonlinearity function | ReLU |
| Batch size | 64 |
| Context length K | 10 |
| Return-to-go conditioning | 1.5 |
| Dropout | 0.1 |
| Optimizer | AdamW |
| Learning Rate | 1e-4 |
| Grad norm clip | 0.25 |
| Weight decay | 1e-4 |
| Learning rate decay | Linear warmup for first 1e5 training steps |
🔼 This table lists the hyperparameters used in training the Language-Teachable Decision Transformer model for the HomeGrid environment. It details the settings for various aspects of the model architecture and training process, such as the number of transformer layers, attention heads, embedding dimensions, activation functions, batch size, context length, optimizer, learning rate, and other regularization parameters. These hyperparameters were tuned to optimize the model’s performance on the HomeGrid tasks. The table provides a comprehensive overview of the specific configurations used for this particular experiment.
read the caption
Table 5: Hyperparameters of Language-Teachable Decision Transformer for HomeGrid experiments.
| Hyperparameters | Value |
|---|---|
| Number of transformer layers | 3 |
| Number of attention heads | 1 |
| Embedding dimension | 128 |
| Nonlinearity function | ReLU |
| Batch size | 64 |
| Context length K | 10 |
| Return-to-go conditioning | 1.5 |
| Dropout | 0.1 |
| Optimizer | AdamW |
| Learning Rate | 1e-3 |
| Grad norm clip | 0.25 |
| Weight decay | 1e-4 |
| Learning rate decay | Cosine Annealing with minimum lr=1e-5 |
🔼 This table lists the hyperparameters used for training the Language-Teachable Decision Transformer model on the ALFWorld environment. It details the settings for various aspects of the model’s architecture and training process, including the number of transformer layers, attention heads, embedding dimension, nonlinearity function, batch size, context length (K), return-to-go conditioning, dropout rate, optimizer, learning rate, gradient norm clipping, weight decay, and learning rate decay schedule. These hyperparameters are crucial in determining the model’s performance and efficiency during training.
read the caption
Table 6: Hyperparameters of Language-Teachable Decision Transformer for ALFWorld experiments.
| Hyperparameters | Value |
|---|---|
| Number of transformer layers | 5 |
| Number of attention heads | 2 |
| Embedding dimension | 128 |
| Nonlinearity function | ReLU |
| Batch size | 128 for pertaining and 1 for adaptation |
| Context length K | 10 |
| Return-to-go conditioning | 1.5 |
| Dropout | 0.1 |
| Optimizer | AdamW |
| Learning Rate | 1e⁻³ for pretraining and 1e⁻⁴ for adaptation |
| Grad norm clip | 0.25 |
| Weight decay | 1e⁻⁴ |
| Learning rate decay | Linear warmup for first 1e⁵ training steps |
🔼 This table lists the hyperparameters used to configure the Language-Teachable Decision Transformer model during the Messenger experiments. It details the settings for various aspects of the model’s architecture and training process, such as the number of transformer layers, attention heads, embedding dimensions, optimizer used, learning rate, and more. These hyperparameters are crucial for optimizing the model’s performance on the Messenger task.
read the caption
Table 7: Hyperparameters of Language-Teachable Decision Transformer for Messenger experiments.
| Hyperparameters | Value |
|---|---|
| Number of transformer layers | 5 |
| Number of attention heads | 2 |
| Embedding dimension | 256 |
| Nonlinearity function | ReLU |
| Batch size | 128 for pertaining and 5 for adaptation |
| Context length K | 12 |
| Return-to-go conditioning | 20 |
| Return scale | 10 |
| Dropout | 0.1 |
| Optimizer | AdamW |
| Learning Rate | 1e-5 for pertaining and 1e-6 for adaptation |
| Weight decay | 1e-4 |
| Learning rate decay | Linear warmup for first 1e5 training steps |
🔼 This table lists the hyperparameters used for training the Language-Teachable Decision Transformer model on the MetaWorld environment. It details the settings for various parameters that control the model’s architecture, training process, and optimization strategy. These parameters include those related to the transformer network itself (e.g., number of layers, attention heads, embedding dimension), the training process (e.g., batch size, learning rate, optimizer), and regularization techniques (e.g., dropout, weight decay). The specific values chosen for each hyperparameter are crucial for the model’s performance and generalization ability on the MetaWorld tasks.
read the caption
Table 8: Hyperparameters of Language-Teachable Decision Transformer for MetaWorld experiments.
Full paper#