TL;DR#
Current multi-hop question answering (MQA) datasets lack explicit reasoning structures, hindering analysis of Large Language Model (LLM) reasoning capabilities. This limits our understanding of how LLMs tackle different reasoning complexities, and makes it difficult to evaluate their performance beyond just the final answer. This paper addresses these issues by introducing GRS-QA, a new dataset that includes reasoning graphs illustrating the logical steps for each question-answer pair.
GRS-QA provides a fine-grained analysis of LLM performance across varying reasoning structures. By explicitly capturing reasoning pathways, it facilitates the development of new evaluation metrics focusing on the reasoning process itself, not just the answer accuracy. The findings reveal that LLMs struggle with questions involving complex reasoning structures, prompting a call for more advanced models capable of handling intricate reasoning tasks and opening new avenues for research in structural analysis of LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in natural language processing and question answering. It introduces a novel dataset, GRS-QA, with explicit reasoning structures, enabling a deeper understanding of how LLMs handle complex reasoning. This resource facilitates more precise evaluation and analysis of LLM reasoning capabilities, opening avenues for developing more robust and explainable AI systems. The findings challenge the existing methods and offers a valuable contribution to the field by offering novel research directions.
Visual Insights#

🔼 This figure shows how reasoning graphs are constructed for a question-answer pair from the HotpotQA dataset. The left side displays the positive reasoning graph, a visual representation of the logical steps needed to answer the question, built using sentences from the original dataset’s supporting paragraphs. The right side demonstrates two types of negative reasoning graphs. These are created by either modifying the connections (edges) between sentences in the original graph or by adding extra sentences (nodes) that are not relevant to answering the question. This illustrates how the structure of the reasoning path impacts the LLM’s ability to answer the question, and will be investigated in the paper.
read the caption
Figure 1: Reasoning graphs constructed based on one QA instance from HotpotQA dataset Yang et al. (2018) that maps out the logical steps required to arrive at the answer. The left-hand side illustrates the positive reasoning graph, which is constructed from the supporting paragraphs provided in the original dataset. This graph represents the gold reasoning path needed to answer the question. On the right-hand side, two types of negative reasoning graphs are derived from the original positive reasoning graphs by either perturbing the edges (e.g., inversing the edge direction in this case) or adding additional nodes with irrelevant sentences.
| Graph | Type | Question | Decomposition |
|---|---|---|---|
 | Comparison_2_1 (C-2-1) | Between Athlete and Fun, which band has more members? Athlete | 1. How many members are in Athlete? Four members 2. How many members are in Fun? Three members |
 | Bridge_2_1 (B-2-1) | Who beat the player that won the 2017 Australian men’s open tennis single title in the US open? Novak Djokovic | 1. Who wins the 2017 australian men’s open tennis single title? Roger Federer 2. Who beat Roger Federer in the us open? Novak Djokovic |
 | Comparison_3_1 (C-3-1) | In which country is the administrative territorial entity for the city where Charlie Harper was born? United Kingdom | 1. Where was Charlie Harper born? Hackney 2. In which administrative territorial entity is Hackney located? Middlesex 3. Which country is Middlesex located in? United Kingdom |
 | Bridge_3_1 (B-3-1) | In which country is the administrative territorial entity for the city where Charlie Harper was born? United Kingdom | 1. Where was Charlie Harper born? Hackney 2. In which administrative territorial entity is Hackney located? Middlesex 3. Which country is Middlesex located in? United Kingdom |
 | Compositional_3_2 (CO-3-2) | In which country is Midway, in the same county as McRae in the same state as KAGH-FM? U.S. | 1. What state is KAGH-FM located? Arkansas 2. In which administrative territorial entity is McRae located? White County 3. Which country is Midway (near Pleasant Plains), White County, Arkansas located in? U.S. |
 | Comparison_4_1 (C-4-1) | Did Albrecht Alt and Asli Hassan Abade have the same occupation? no | 1. [“Asli Hassan Abade”, “occupation”, “pilot”] 2. [“Asli Hassan Abade”, “occupation”, “military figure”], 3. [“Asli Hassan Abade”, “occupation”, “civil activist”] 4. [“Albrecht Alt”, “occupation”, “theologian”] 5. [“Albrecht Alt”, “occupation”, “lecturer”] 6. [“Albrecht Alt”, “occupation”, “professor”] “supporting_facts”: [[“Asli Hassan Abade”, 0], [“Albrecht Alt”, 0],[“Albrecht Alt”, 2], [“Albrecht Alt”, 6]] |
 | Bridge_4_1 (B-4-1) | When did Ukraine gain independence from the first Allied nation to reach the German city where the director of The Man from Morocco was born? 1917 | 1. Who is the director of The Man from Morocco? Mutz Greenbaum 2. What is the place of birth of Mutz Greenbaum? Berlin 3. What allied nation was the first to reach the german capitol of Berlin? Soviet Union 4. When did Ukraine gain independence from Soviet Union? 1917 |
 | Compositional_4_2 (CO-4-2) | Where is the place of death of the man who became leader of the largest country in Europe in square miles after the collapse of the nation Germany agreed to sign a non-aggression pact with in 1939? Moscow | 1. What is the largest country in europe by square miles? Russia 2. In 1939 Germany agreed to sign a non-aggression pact with which country? the Soviet Union 3. Who became leader of Russia after the collapse of the Soviet Union? Boris Yeltsin 4. Where did Boris Yeltsin die? Moscow |
 | Compositional_4_3 (CO-4-3) | In what country is Tuolumne, which is within a county that borders the county containing Jamestown, and is located within the state where Some Like It Hot was filmed? United States | 1. In which administrative territorial entity is Jamestown located? Tuolumne County 2. Which entities share a border with Tuolumne County? Stanislaus County 3. Where did they film some like it hot? in California 4. Which country is Tuolumne, Stanislaus County, in California located in?? United States |
 | Bridge_Comparison_4_1 (BC-4-1) | Are both directors of films The Blue Bird (1940 Film) and Bharya Biddalu from the same country? no | 1. [’The Blue Bird (1940 film)’, ’director’, ’Walter Lang’] 2. [’Bharya Biddalu’, ’director’, ’Tatineni Rama Rao’] 3. [’Walter Lang’, ’country of citizenship’, ’American’] 4. [’Tatineni Rama Rao’, ’country of citizenship’, ’India’] |
 | Comparison_5_1 (CO-5-1) | Which film has more directors, Red Cow (Film) or Chillerama? Chillerama | 1. [“Red Cow (film)”, “director”, “Tsivia Barkai Yacov”] 2. [“Chillerama”, “director”, “Adam Rifkin”] 3. [“Chillerama”, “director”, “Tim Sullivan”] 4. [“Chillerama”, “director”, “Adam Green”] 5. [“Chillerama”, “director”, “Joe Lynch”] |
 | Bridge_Comparison_5_1 (BC-5-1) | “Do both films The Falcon (Film) and Valentin The Good have the directors from the same country? no | 1. [“The Falcon (film)”, “director”, “Vatroslav Mimica”] 2. [“Valentin the Good”, “director”, “Martin Fri0̆10d”] 3. [“Vatroslav Mimica”, “country of citizenship”, “Croatian”] 4. [“Vatroslav Mimica”, “country of citizenship”, “Yugoslavia”] 5. [“Martin Fri0̆10d”, “country of citizenship”, “Czech”] |
🔼 Table 1 presents examples of reasoning graphs from the GRS-QA dataset. Each row shows a question-answer pair, its corresponding reasoning graph (visualizing the logical steps to reach the answer), and a decomposition of the question into simpler sub-questions. The decomposition utilizes relevant context and entities from multiple datasets to create a more granular understanding of the reasoning process. The rightmost column illustrates different forms of this decomposition, including both more granular questions and entity triples. This detailed representation of the reasoning pathway helps researchers evaluate and understand how Large Language Models perform on different reasoning structures.
read the caption
Table 1: This table shows the Reasoning graphs of GRS-QA. The reasoning graphs demonstrate the decomposition of the larger question and the reasoning paths to approach the answer. Each of these is constructed using the context and relevant entities for each question. The decomposition is shown with varying formats in the right-most column of the graph, including more questions derived from the original question as well as triples that represent the relations between entities and, in turn, provide subsets of the context. This is consistent with the multiple datasets that each of the question types are extracted from.
In-depth insights#
LLM Reasoning Gaps#
The research paper section “LLM Reasoning Gaps” highlights crucial limitations in current Large Language Models’ (LLMs) reasoning capabilities. It emphasizes that existing multi-hop question answering (M-QA) datasets lack explicit reasoning structures, hindering a fine-grained analysis of LLMs’ reasoning processes. The authors argue that the entanglement of diverse reasoning structures within these datasets obscures the impact of structural complexity on LLM performance. This lack of explicit structure prevents the isolation and evaluation of individual reasoning steps, impeding a deeper understanding of where LLMs succeed or fail. The section sets the stage for the introduction of a new dataset, GRS-QA, designed to address these limitations by explicitly incorporating reasoning structures for improved LLM performance analysis and to facilitate the exploration of the interplay between textual structures and semantic understanding in complex reasoning tasks.
GRS-QA Dataset#
The GRS-QA dataset is a novel resource for evaluating multi-hop question answering, uniquely incorporating explicit reasoning graph structures for each question-answer pair. Unlike existing datasets that entangle reasoning structures, GRS-QA represents the logical steps to the answer with reasoning graphs, where nodes are sentences and edges show logical flow. This design allows fine-grained analysis of LLM reasoning capabilities across various structures, including comparison, bridge, and compositional types. Furthermore, GRS-QA provides comprehensive metadata (reasoning steps, types) and negative reasoning graphs (structural perturbations of the positive graphs) to enable a deeper understanding of the impact of structural complexity on LLM performance. This dataset facilitates the development of new evaluation metrics, enabling a more nuanced assessment of LLM reasoning abilities beyond simple answer correctness.
Retrieval Analysis#
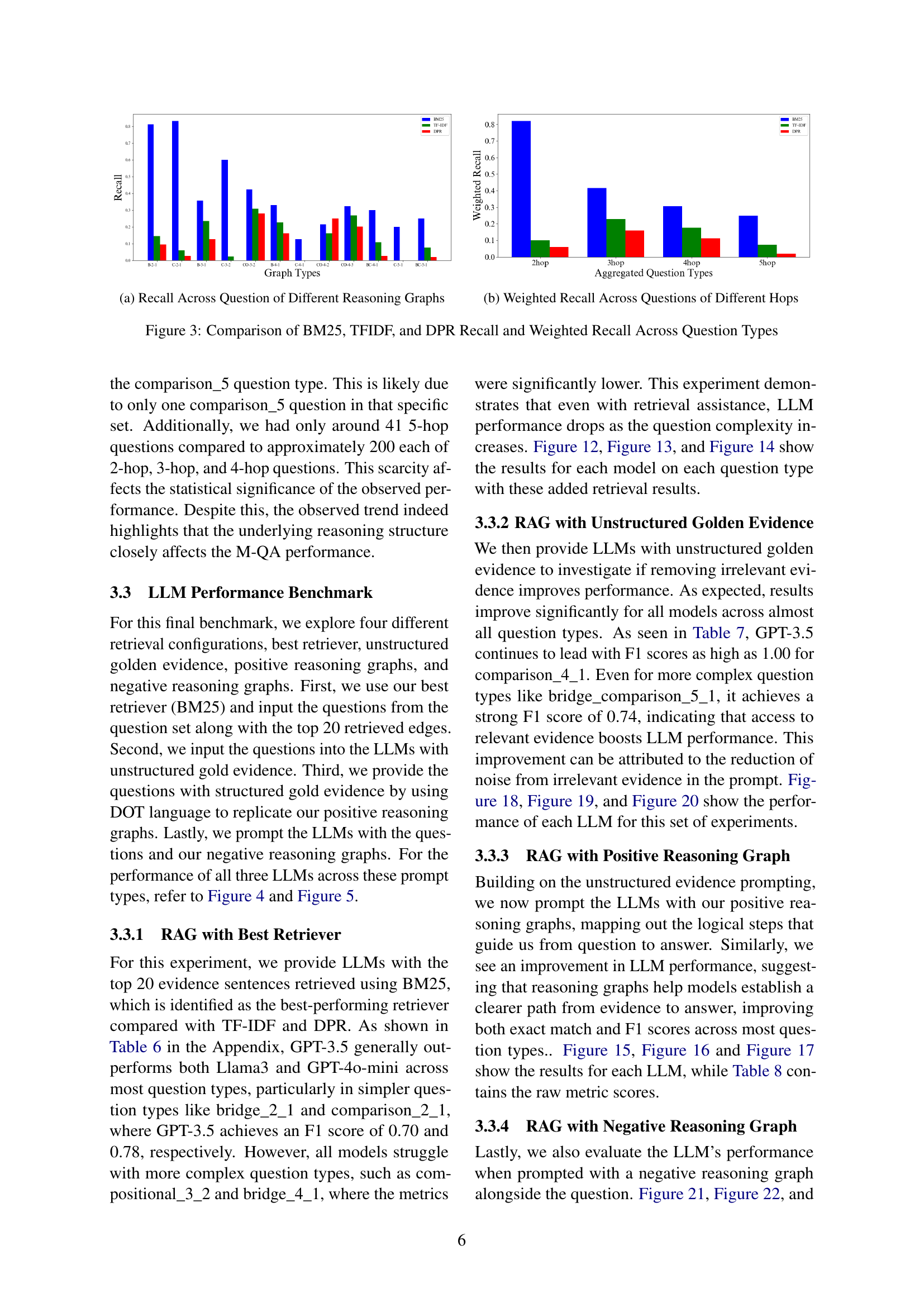
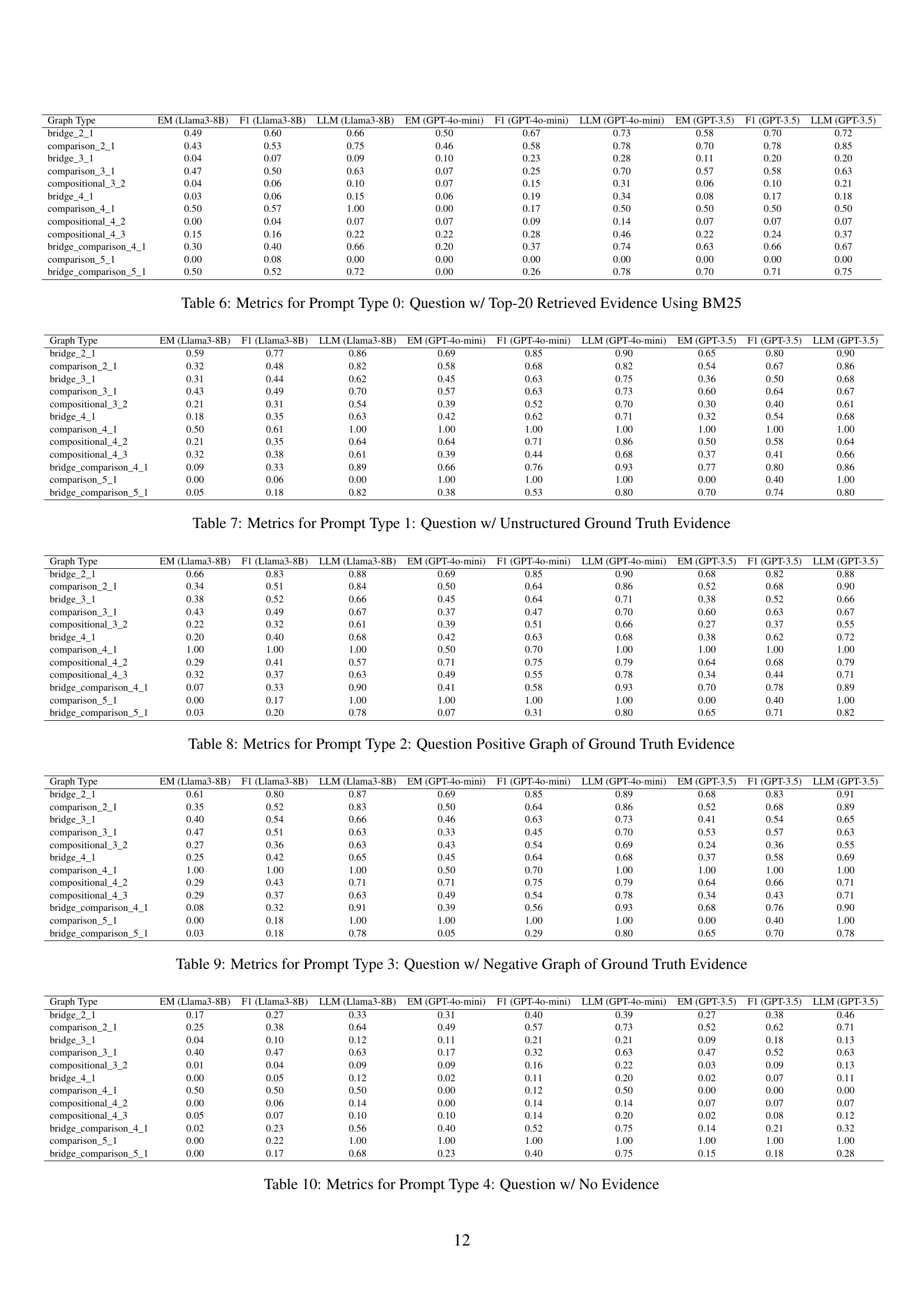
The retrieval analysis section evaluates the effectiveness of three different methods (BM25, DPR, and TF-IDF) in retrieving relevant sentences for multi-hop question answering. The results indicate that BM25 outperforms DPR and TF-IDF, achieving better recall and F1 scores across various question types. This highlights the importance of selecting an appropriate retrieval method for optimal performance in multi-hop question answering. While BM25 shows overall effectiveness, its performance still drops as question complexity increases, which is expected. The study also emphasizes the variability in retrieval performance across different question types, suggesting the need for more nuanced approaches that consider specific reasoning structures to improve retrieval effectiveness for complex question answering scenarios.
LLM QA Benchmarks#
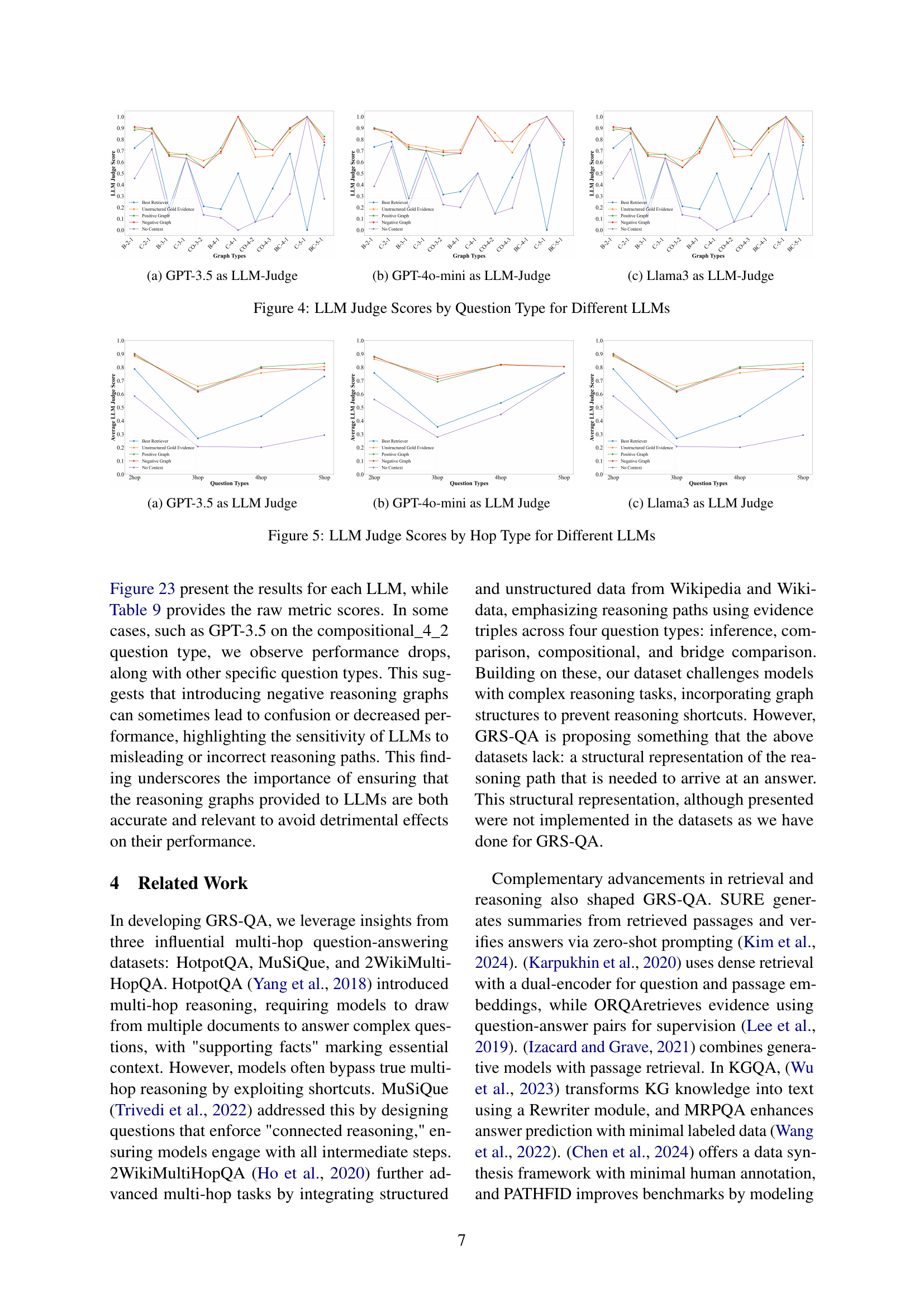
The LLM QA Performance Benchmark section evaluates three LLMs (Llama-3, GPT-3.5, and GPT-4-mini) on question-answering tasks using GRS-QA. The evaluation metrics include exact match, F1 score, and LLM-as-Judge. The results show that GPT-3.5 generally outperforms the other two models, highlighting its superior reasoning capabilities. Importantly, the study reveals a correlation between question complexity and LLM performance, indicating that as the reasoning complexity of the questions increases, the accuracy of the LLMs generally decreases. This is a critical finding, demonstrating the challenges posed by GRS-QA’s intricate reasoning structures for even the most advanced LLMs. The findings underline the need for further improvements in LLM reasoning capabilities, particularly when addressing complex multi-hop reasoning questions.
Future Directions#
The paper’s “Future Directions” section highlights several key areas for improvement and expansion of the GRS-QA dataset. Addressing the dataset’s class imbalance is crucial, potentially through synthetic data generation to better represent complex reasoning structures. Domain segmentation is proposed to improve model performance in specific fields, suggesting the creation of domain-adapted models or exploration of domain-specific knowledge bases. Further research should investigate the impact of negative reasoning graph diversity, potentially uncovering hidden patterns and biases in LLM reasoning. Finally, the authors encourage benchmarking across a broader range of model architectures, particularly Graph Neural Networks (GNNs) and retrieval-augmented models, to provide a more complete understanding of which model types best handle graph-structured reasoning. This multifaceted approach aims to enhance the robustness and generalizability of LLMs for complex reasoning tasks.
More visual insights#
More on figures

🔼 This bar chart visualizes the distribution of questions across different reasoning graph types within the GRS-QA dataset. The x-axis represents the various graph types, categorized based on their structural complexity and logical flow (e.g., comparison, bridge, compositional). The y-axis displays the number of questions belonging to each graph type. The chart provides insights into the frequency of each reasoning structure within the dataset, indicating the balance or imbalance of different question complexities in the GRS-QA dataset.
read the caption
(a) Number of Questions by Graph types in all dataset splits

🔼 This figure visualizes the average number of nodes and edges present in the positive reasoning graphs for various question types within the GRS-QA dataset. Nodes represent sentences, and edges represent the logical relationships between sentences in the reasoning path. The graph provides insights into the complexity of different question types, showing how many sentences and relationships are typically involved in reaching the correct answer for each type.
read the caption
(b) Average number of nodes and edges in each question type Positive Graphs

🔼 This figure shows the average number of tokens (words and punctuation marks) used in the positive reasoning graphs for different types of questions. A positive reasoning graph represents the ideal path of reasoning to arrive at the answer. The x-axis lists the different question types in GRS-QA. Each question type has various levels of reasoning complexity. The y-axis represents the average number of tokens. This visualization helps understand the relationship between question complexity and the length of the textual content needed to answer the question.
read the caption
(c) Average number of tokens in each question type’s Positive Graphs

🔼 This figure presents a statistical analysis of the GRS-QA dataset, illustrating the distribution of various aspects. Panel (a) shows the number of questions categorized by their graph types. Panel (b) displays the average number of nodes and edges within each question type’s positive graphs, offering insights into the complexity of the reasoning paths involved. Panel (c) shows the average token count in each question type’s positive graphs, providing information on the length and textual complexity of the questions.
read the caption
Figure 2: Statistical Analysis of the Distribution of GRS-QA.

🔼 This figure shows the recall performance of three different retrieval methods (BM25, TF-IDF, and DPR) across various question types categorized by their reasoning graph structures. The x-axis represents the different question types based on their reasoning graph complexity (e.g., bridge_2_1, comparison_2_1, etc.), while the y-axis represents the recall score. The bars illustrate the recall achieved by each retrieval method for each question type. The figure helps to visualize how the retrieval performance varies depending on both the retrieval method and the complexity of the reasoning structure inherent in the question.
read the caption
(a) Recall Across Question of Different Reasoning Graphs

🔼 This figure shows the weighted average recall across questions grouped by the number of reasoning hops (steps). It compares the performance of three different retrieval methods (BM25, TF-IDF, and DPR) in retrieving relevant sentences for questions of varying hop lengths. The higher the hop count, the more complex the reasoning chain, and potentially the more challenging the retrieval task for the models.
read the caption
(b) Weighted Recall Across Questions of Different Hops

🔼 This figure compares the recall performance of three different retrieval methods (BM25, TF-IDF, and DPR) across various question types categorized by their reasoning complexity (number of hops). The bar chart visually represents the recall achieved by each method for each question type. A second chart presents a weighted average recall score across all question types, again broken down by the number of reasoning hops. This allows for a direct comparison of the effectiveness of the retrieval methods in handling different question complexities.
read the caption
Figure 3: Comparison of BM25, TFIDF, and DPR Recall and Weighted Recall Across Question Types
🔼 This figure displays the LLM Judge scores for different question types, specifically focusing on the performance of GPT-3.5 as the LLM judge. The x-axis represents various question types categorized by their reasoning graph complexity (e.g., bridge_2_1, comparison_2_1, etc.), while the y-axis shows the LLM Judge score. The bars in the chart visually represent the performance of GPT-3.5 on these different question types, illustrating the model’s ability to judge the correctness of answers based on the varying complexities of the questions. The chart helps analyze how well GPT-3.5 can assess answers considering the nuances of the question’s structure.
read the caption
(a) GPT-3.5 as LLM-Judge

🔼 This figure shows the performance of the GPT-4o-mini large language model (LLM) as a judge in evaluating the performance of other LLMs on various question types. The x-axis represents the different types of questions, categorized by their complexity. The y-axis displays the LLM judge scores which reflect the accuracy of the LLM’s answers. Different bars within each question type represent different prompting methods used by the model (best retriever, unstructured gold evidence, positive reasoning graph, negative reasoning graph, no context). The chart helps to visualize how the model’s performance varies based on both question type and prompting approach.
read the caption
(b) GPT-4o-mini as LLM-Judge

🔼 This figure shows the LLM Judge scores for the Llama 3 model across different question types in the LLM QA performance benchmark. It displays the exact match, F1 score, and LLM Judge scores for Llama 3 for each of the various question types, categorized by the complexity of their reasoning graphs (2-hop to 5-hop). The chart helps visualize how Llama 3’s performance changes based on the different question types and complexity.
read the caption
(c) Llama3 as LLM-Judge
🔼 This figure displays the performance of three different Large Language Models (LLMs) – GPT-3.5, GPT-4-mini, and Llama 3 – as judged by another LLM (GPT-4-mini) on various question types within the GRS-QA dataset. Each question type represents different levels of reasoning complexity, allowing for the assessment of LLMs’ ability to handle questions with varying reasoning structures. The bars represent the LLM Judge scores (a combined metric of the performance) for each LLM on each question type. The x-axis shows the various question types within the GRS-QA dataset, and the y-axis displays the LLM Judge Scores, showing how each model performs on different question types with different complexities.
read the caption
Figure 4: LLM Judge Scores by Question Type for Different LLMs

🔼 This figure displays the LLM Judge scores generated by GPT-3.5 for various question types within the GRS-QA dataset. The x-axis represents different question types categorized by their reasoning graph structure (e.g., bridge, comparison, compositional). The y-axis shows the LLM Judge score, a metric reflecting the overall quality of the LLMs’ answers as assessed by GPT-3.5. The bars illustrate the performance for each question type, providing insights into how well different LLMs perform based on the complexity and structure of the reasoning involved in answering questions.
read the caption
(a) GPT-3.5 as LLM Judge

🔼 This figure displays the LLM judge scores for different question types, specifically focusing on the performance of the GPT-4o-mini model. The x-axis represents various question types categorized by their reasoning graph complexity (e.g., bridge_2_1, comparison_2_1, etc.), and the y-axis shows the LLM judge score. The graph allows for a visual comparison of GPT-4o-mini’s performance across different question types and complexities.
read the caption
(b) GPT-4o-mini as LLM Judge

🔼 This figure displays the performance of Llama3, one of three LLMs (Large Language Models) tested in the study, as evaluated by LLM-as-Judge. The LLM-as-Judge metric assesses the quality of responses generated by other LLMs by comparing them to the responses of Llama3, specifically focusing on the accuracy and relevance of answers given by Llama3 for various question types. The x-axis shows different types of questions with varying levels of complexity and hop counts, while the y-axis represents the LLM Judge scores, showing how well Llama3’s answers align with the ground truth, for each type of question.
read the caption
(c) Llama3 as LLM Judge

🔼 This figure displays the LLM Judge scores for different Large Language Models (LLMs) across various hop types in questions. It provides a visual comparison of the performance of three LLMs (GPT-3.5, GPT-40-mini, and Llama3) when evaluating the quality of answers generated for questions with varying levels of complexity (measured by the number of hops or reasoning steps required). The x-axis represents the hop type, while the y-axis indicates the LLM Judge Score, a metric used to assess the quality of the LLM’s generated answers.
read the caption
Figure 5: LLM Judge Scores by Hop Type for Different LLMs

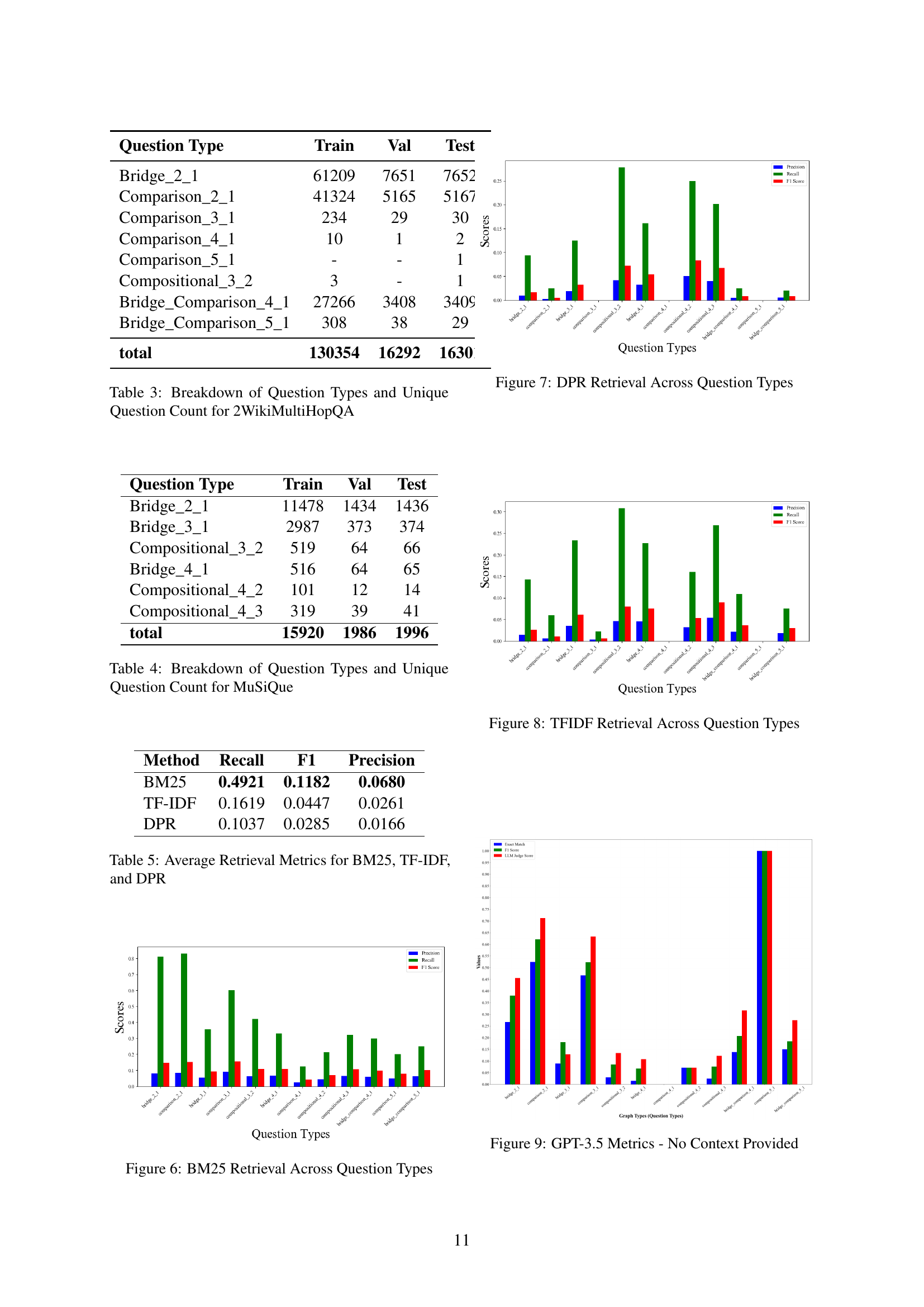
🔼 This figure shows the performance of BM25 retrieval across different question types in the GRS-QA dataset. The x-axis represents the different question types, categorized by their reasoning complexity (e.g., bridge_2_1, comparison_2_1, etc.). The y-axis displays the BM25 retrieval metrics, specifically precision, recall, and F1-score. The bars for each question type represent the corresponding values for each metric. The figure illustrates how the effectiveness of BM25 varies depending on the complexity and structure of the questions.
read the caption
Figure 6: BM25 Retrieval Across Question Types

🔼 This bar chart visualizes the performance of Dense Passage Retrieval (DPR) across different question types in the GRS-QA dataset. Each bar represents a question type, categorized by hop count and structure (e.g., bridge, comparison, compositional). The height of each bar shows the F1 score, precision, and recall achieved by DPR for that specific question type. The chart allows for a comparison of DPR’s effectiveness in retrieving relevant information for questions with varying complexities and structures.
read the caption
Figure 7: DPR Retrieval Across Question Types

🔼 This bar chart visualizes the performance of TF-IDF retrieval across different question types within the GRS-QA dataset. Each bar represents a question type, broken down by the metrics Precision, Recall and F1-Score. The height of each segment within a bar indicates the achieved score for that specific metric on that question type. This allows for a direct comparison of TF-IDF’s effectiveness in retrieving relevant information for various reasoning complexities.
read the caption
Figure 8: TFIDF Retrieval Across Question Types

🔼 This figure presents a performance comparison of the GPT-3.5 language model on various question types within the GRS-QA dataset. Specifically, it shows the model’s performance without providing any supporting context or retrieved evidence. The performance is evaluated using three metrics: Exact Match, F1 Score, and LLM-as-Judge. The x-axis represents the different question types (categorized by reasoning structure complexity), and the y-axis represents the achieved score for each metric. The graph visually demonstrates how the model’s accuracy varies across different question types, highlighting the challenges posed by more complex reasoning structures when no external context is provided.
read the caption
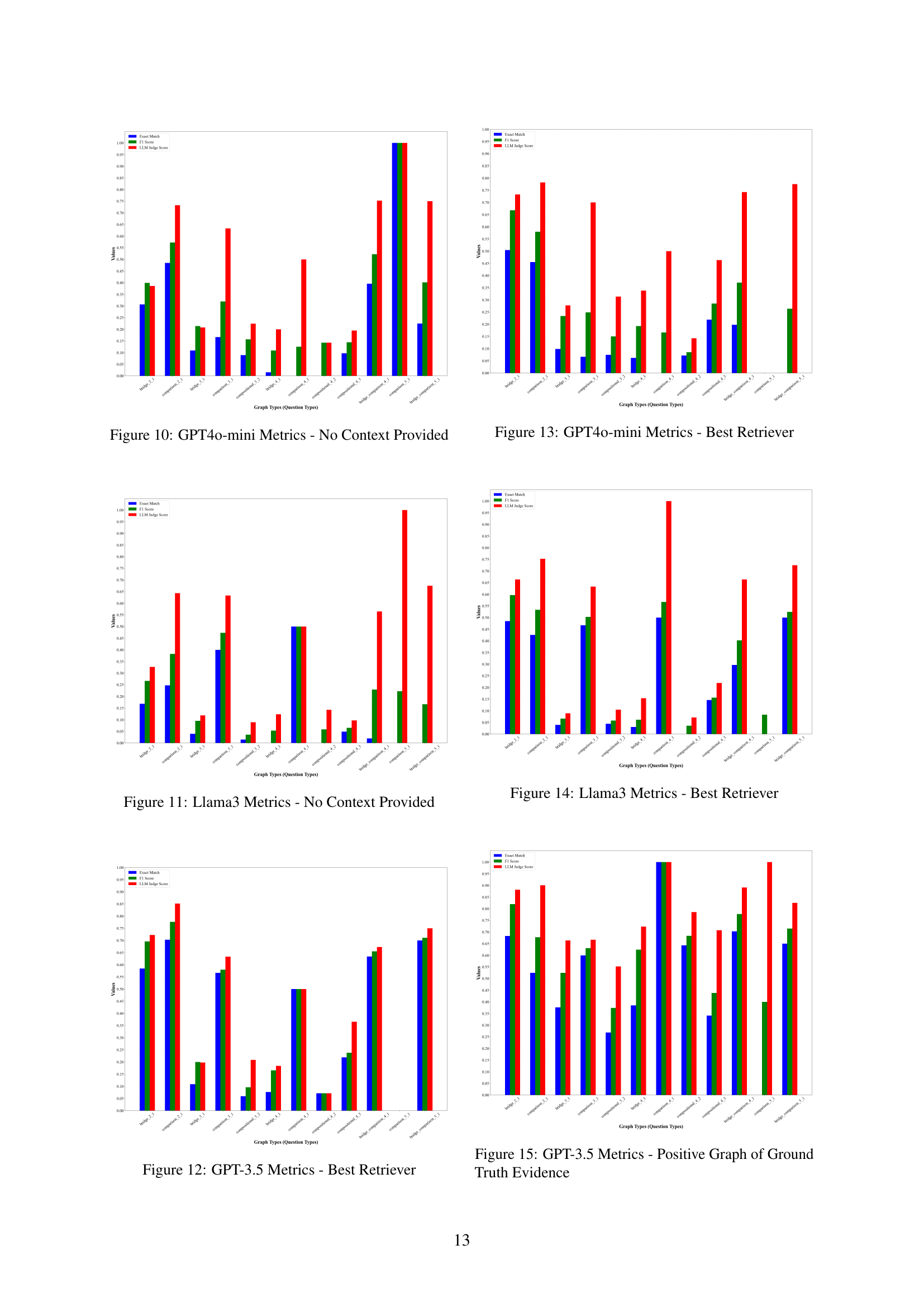
Figure 9: GPT-3.5 Metrics - No Context Provided

🔼 This figure displays the performance of the GPT4o-mini language model on various question types within the GRS-QA dataset, without providing any context. The performance is measured using three metrics: Exact Match, F1 score, and LLM-as-Judge. Each bar represents a different question type, categorized by their complexity (number of hops and type of reasoning). The height of each bar indicates the score achieved by the model on that question type for each metric.
read the caption
Figure 10: GPT4o-mini Metrics - No Context Provided

🔼 This figure displays the performance of Llama3 language model on various question types within the GRS-QA dataset when no contextual information is provided. The metrics displayed likely include Exact Match, F1 Score, and LLM Judge score across different question types (categorized by their reasoning graph complexity, such as bridge_2_1, comparison_2_1 etc.). Each bar represents one question type and the height of each bar shows the score for that metric. The figure helps visualize the model’s ability to answer questions with varying reasoning complexities when there is no provided context.
read the caption
Figure 11: Llama3 Metrics - No Context Provided

🔼 This figure displays the performance of the GPT-3.5 large language model (LLM) when using the best retriever (BM25) to obtain relevant information for answering questions. It shows the exact match accuracy, F1 score, and LLM judge scores across various question types within the GRS-QA dataset. Each bar represents a different question type, categorized by their reasoning graph complexity. The different colors in the bars show the three different metrics used for the evaluation. This visualization helps understand how effectively GPT-3.5 performs on questions with different reasoning structures when provided with optimal retrieved evidence.
read the caption
Figure 12: GPT-3.5 Metrics - Best Retriever

🔼 This figure presents the performance metrics of the GPT-4o-mini language model when using the best retriever (BM25) to retrieve relevant evidence for answering questions. The x-axis represents different question types categorized by reasoning graph structure complexity (e.g., bridge_2_1, comparison_2_1, etc.), while the y-axis displays the metrics: Exact Match, F1 Score, and LLM Judge score. The different colored bars within each question type show the performance across various metrics. The chart illustrates how the model’s performance varies across different question types and reasoning graph complexity levels when provided with top evidence retrieved by the BM25.
read the caption
Figure 13: GPT4o-mini Metrics - Best Retriever

🔼 This figure presents the performance metrics of the Llama 3 language model when using the best retriever (BM25) to retrieve relevant evidence for answering questions. The x-axis represents the various question types within the GRS-QA dataset, categorized by their reasoning structure complexity. The y-axis displays the evaluation metrics (Exact Match, F1 score, and LLM Judge score) for each question type. This visualization showcases how well Llama 3 performs on different question complexities when assisted by the best performing retrieval method. The varying heights of the bars for each metric across the different question types demonstrate the model’s performance variability with varying reasoning structure complexities. The overall trend and specific performance details regarding each metric across the diverse question types are presented in the figure.
read the caption
Figure 14: Llama3 Metrics - Best Retriever

🔼 This figure displays the performance of GPT-3.5 on the GRS-QA dataset when provided with positive reasoning graphs as context. It shows the exact match accuracy, F1 score, and LLM judge score across different question types categorized by the complexity of their reasoning graph structure (number of hops/complexity). The x-axis represents various question types, and the y-axis shows the performance metrics. The figure helps visualize how the explicit provision of the correct reasoning pathways impacts the model’s ability to accurately answer questions with varying reasoning complexities.
read the caption
Figure 15: GPT-3.5 Metrics - Positive Graph of Ground Truth Evidence

🔼 This figure displays the performance metrics of the GPT-4o-mini language model when evaluated using a positive reasoning graph as the context. The metrics shown likely include precision, recall, F1 score, and potentially exact match, assessing the model’s ability to correctly answer questions when the reasoning steps are explicitly provided. The graph likely displays performance across different types of reasoning graph structures or complexity levels.
read the caption
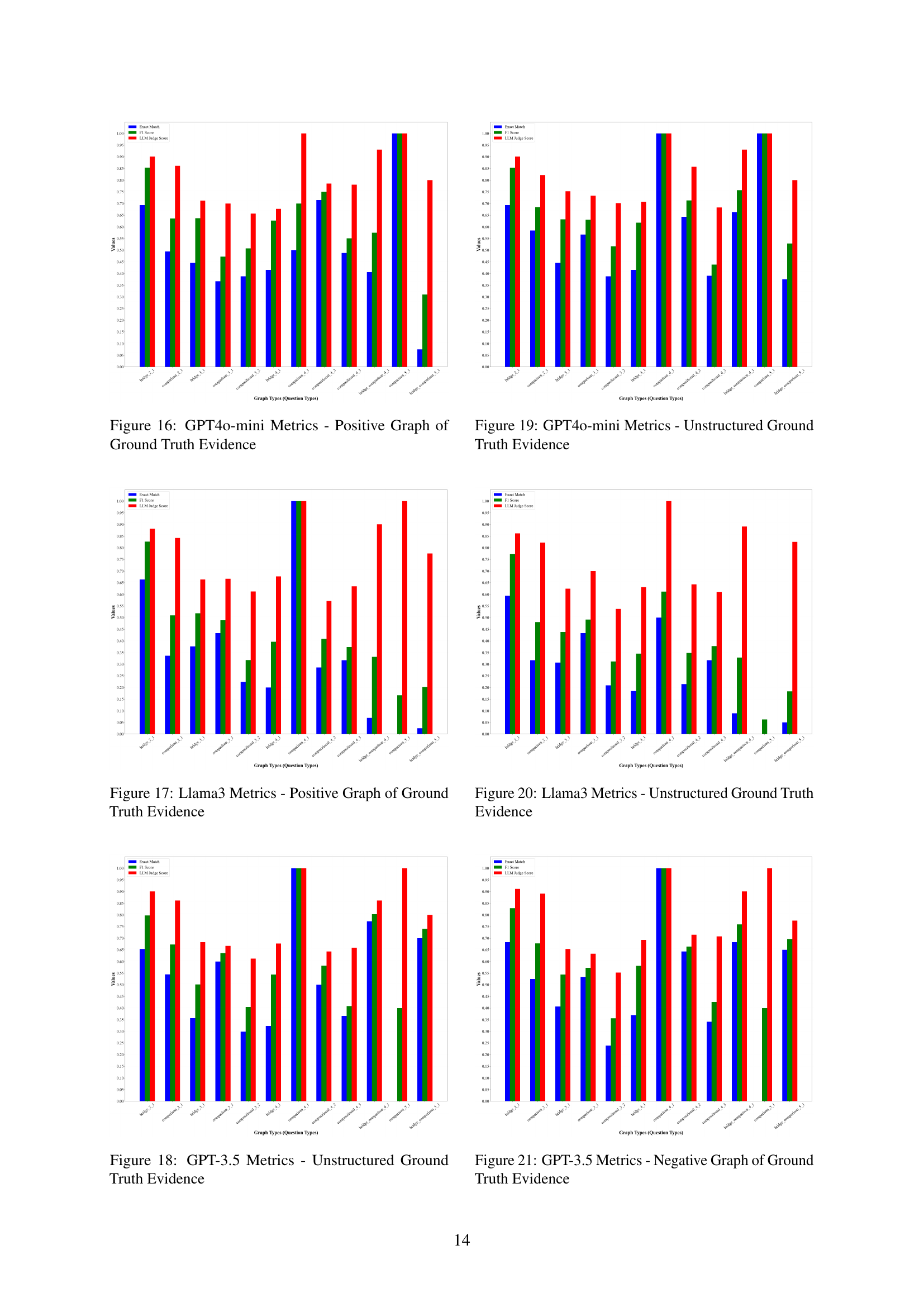
Figure 16: GPT4o-mini Metrics - Positive Graph of Ground Truth Evidence

🔼 This figure displays the performance metrics of the Llama 3 language model on the GRS-QA dataset when using positive reasoning graphs as input. The metrics shown likely include Exact Match (EM), F1 score, and LLM Judge score. The x-axis represents the different question types within the GRS-QA dataset, categorized by their reasoning graph complexity (e.g., bridge_2_1, comparison_2_1, etc.). The y-axis represents the metric scores, indicating the model’s accuracy and performance for each question type. This visualization allows for a detailed comparison of Llama 3’s performance across various reasoning complexities when provided with the correct reasoning pathways (positive graphs).
read the caption
Figure 17: Llama3 Metrics - Positive Graph of Ground Truth Evidence

🔼 This figure presents the performance metrics of the GPT-3.5 large language model (LLM) when prompted with unstructured ground truth evidence for various question types in the GRS-QA dataset. The metrics displayed likely include Exact Match, F1-score, and an LLM Judge score (a metric used to assess the quality of the LLM’s response). The x-axis represents different question types categorized by their reasoning graph complexity (e.g., bridge_2_1 indicates a bridge-type question with 2 reasoning steps and 1 node). The y-axis represents the values for each of the metrics. The graph visually compares the model’s performance across different question types based on the complexity of their reasoning pathways, showing how the performance varies with the complexity of the task.
read the caption
Figure 18: GPT-3.5 Metrics - Unstructured Ground Truth Evidence

🔼 This figure displays the performance metrics of the GPT-40-mini language model when provided with unstructured ground truth evidence for question answering. It shows the exact match accuracy, F1 score, and LLM Judge score across different question types, categorized by their reasoning graph complexity (number of hops). The goal is to evaluate the model’s ability to answer questions when given the correct context but without the structured reasoning pathways presented in the reasoning graphs.
read the caption
Figure 19: GPT4o-mini Metrics - Unstructured Ground Truth Evidence

🔼 This figure displays the performance metrics of the Llama 3 language model when provided with unstructured ground truth evidence for question answering. It shows the exact match accuracy, F1 score, and LLM judge score for Llama 3 across various question types with varying levels of reasoning complexity. The x-axis represents different question types (categorized by the number of reasoning steps and their structure), and the y-axis represents the performance metrics. The purpose is to evaluate the model’s ability to answer questions when given access to all relevant context without any structured guidance or organization. The graph helps researchers to understand how the model’s performance changes with the structural complexity of the question.
read the caption
Figure 20: Llama3 Metrics - Unstructured Ground Truth Evidence

🔼 This figure displays the performance metrics of the GPT-3.5 large language model (LLM) when prompted with questions paired with negative reasoning graphs. Negative reasoning graphs are altered versions of the ground truth reasoning graphs, introducing structural errors to isolate the impact of structure on LLM performance. The metrics shown likely include exact match accuracy, F1 score (harmonic mean of precision and recall), and an LLM judge score (a measure of how well the LLM’s response aligns with human judgment). The graph likely visualizes these metrics across different types of questions categorized by their reasoning graph complexity (number of reasoning steps, graph structure, etc.). This helps assess how sensitive the LLM’s reasoning capabilities are to structural inaccuracies in the provided information.
read the caption
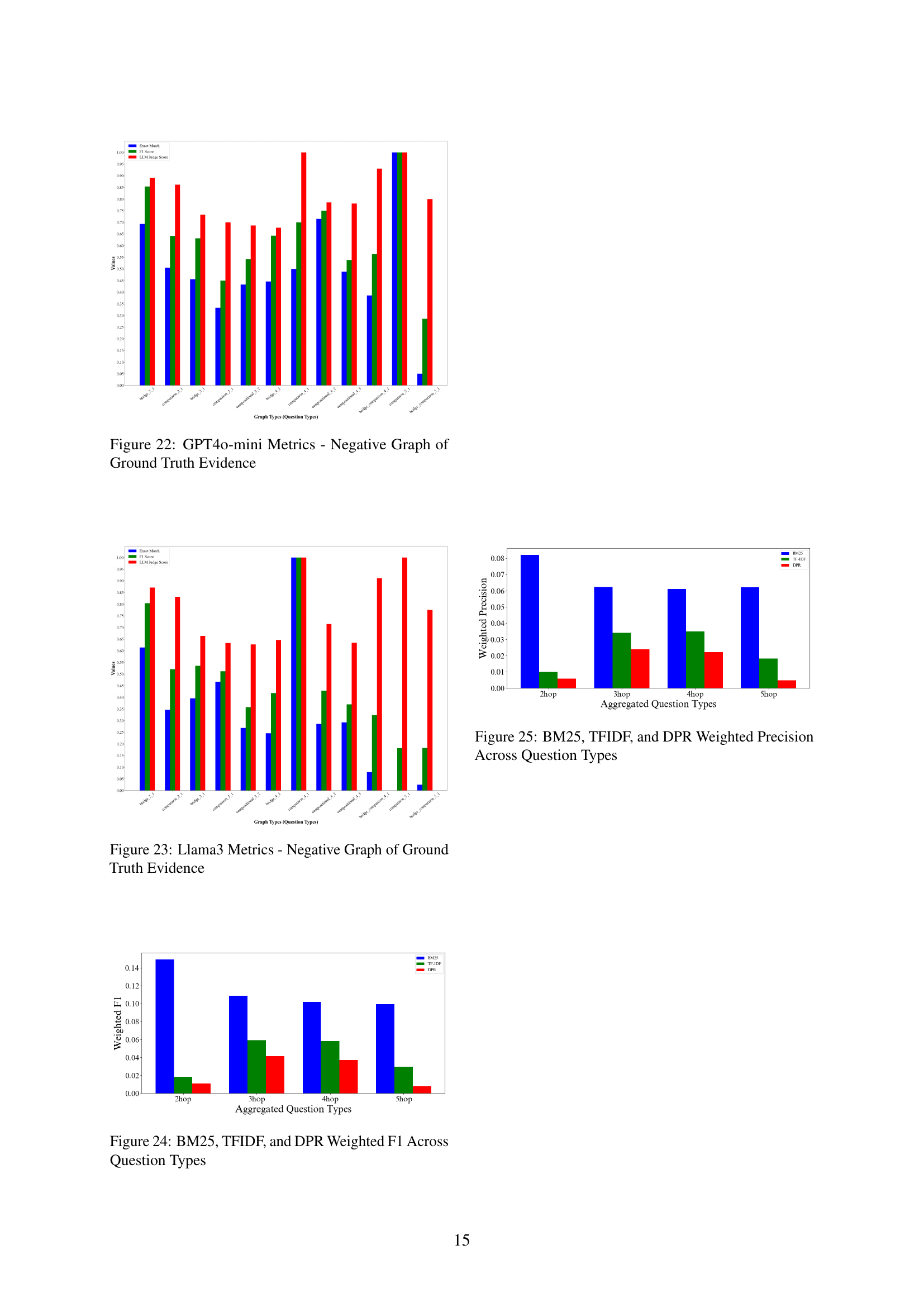
Figure 21: GPT-3.5 Metrics - Negative Graph of Ground Truth Evidence
More on tables
| Question Type | Train | Val | Test |
|---|---|---|---|
| Bridge_2_1 | 58384 | 7298 | 7298 |
| Comparison_2_1 | 13964 | 1745 | 1747 |
| total | 72348 | 9043 | 9045 |
🔼 This table presents a breakdown of the question types and their counts within the HotpotQA dataset. It shows how many questions of each type (e.g., Bridge_2_1, Comparison_2_1) are present in the training, validation, and testing sets of the dataset. This provides insight into the distribution of question complexities within the dataset.
read the caption
Table 2: Breakdown of Question Types and Unique Question Count for HotpotQA
| Question Type | Train | Val | Test |
|---|---|---|---|
| Bridge_2_1 | 61209 | 7651 | 7652 |
| Comparison_2_1 | 41324 | 5165 | 5167 |
| Comparison_3_1 | 234 | 29 | 30 |
| Comparison_4_1 | 10 | 1 | 2 |
| Comparison_5_1 | - | - | 1 |
| Compositional_3_2 | 3 | - | 1 |
| Bridge_Comparison_4_1 | 27266 | 3408 | 3409 |
| Bridge_Comparison_5_1 | 308 | 38 | 29 |
| total | 130354 | 16292 | 16301 |
🔼 This table presents a detailed breakdown of the question types and their counts within the 2WikiMultiHopQA dataset. It shows the distribution of questions across various categories, specifically highlighting the number of unique questions in the training, validation, and testing sets for each question type. This breakdown is crucial for understanding the dataset’s composition and ensuring a balanced evaluation of different question complexities.
read the caption
Table 3: Breakdown of Question Types and Unique Question Count for 2WikiMultiHopQA
| Question Type | Train | Val | Test |
|---|---|---|---|
| Bridge_2_1 | 11478 | 1434 | 1436 |
| Bridge_3_1 | 2987 | 373 | 374 |
| Compositional_3_2 | 519 | 64 | 66 |
| Bridge_4_1 | 516 | 64 | 65 |
| Compositional_4_2 | 101 | 12 | 14 |
| Compositional_4_3 | 319 | 39 | 41 |
| total | 15920 | 1986 | 1996 |
🔼 Table 4 presents a breakdown of the question types and their counts within the MuSiQue dataset. It details the distribution of questions across different categories, such as ‘Bridge_2_1,’ ‘Bridge_3_1,’ etc., providing the number of training, validation, and test instances for each question type. This table helps to illustrate the composition of the MuSiQue dataset used in the study, which is crucial for evaluating the model’s performance on diverse question types and complexities.
read the caption
Table 4: Breakdown of Question Types and Unique Question Count for MuSiQue
| Method | Recall | F1 | Precision |
|---|---|---|---|
| BM25 | 0.4921 | 0.1182 | 0.0680 |
| TF-IDF | 0.1619 | 0.0447 | 0.0261 |
| DPR | 0.1037 | 0.0285 | 0.0166 |
🔼 This table presents the average retrieval performance metrics for three different methods: BM25, TF-IDF, and DPR. For each method, it shows the average recall, F1 score, and precision across all question types in the GRS-QA dataset. These metrics provide a quantitative evaluation of the effectiveness of each retrieval method in identifying relevant evidence sentences for answering questions with varying reasoning structures.
read the caption
Table 5: Average Retrieval Metrics for BM25, TF-IDF, and DPR
Full paper#