↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current LLM agent systems are limited by their reliance on predefined actions, hindering their flexibility and applicability to real-world scenarios. This limitation necessitates significant manual effort to enumerate and implement all potential actions. This paper addresses these limitations by proposing a new framework.
The proposed framework, DynaSaur, allows LLM agents to dynamically create and compose actions as Python functions, overcoming the constraints of predefined actions. It introduces an action retrieval mechanism to efficiently manage the growing set of generated actions, promoting reusability and enhanced performance. Experimental results on the GAIA benchmark demonstrate DynaSaur’s superior flexibility and performance compared to existing methods, highlighting its potential for broader applications in complex real-world environments.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel LLM agent framework that surpasses existing methods by enabling dynamic action creation and composition. This significantly advances LLM agent capabilities, particularly in complex, real-world scenarios, and opens new avenues for research in flexible and adaptive AI agents. The results are very promising, holding the top spot on the GAIA leaderboard, a benchmark that stresses generality and adaptability. This directly addresses the limitations of existing LLM agent systems which rely on fixed sets of actions.
Visual Insights#

🔼 The DynaSaur agent framework is illustrated in this figure. The agent starts by receiving a task and a set of predefined actions. It then generates an action as a Python code snippet, which is executed within an environment containing an IPython kernel. This kernel can interact with various resources depending on the action, including an action retriever for previously generated actions, the internet for web searches, and the local operating system for other tasks. The agent is not limited in its interactions; this list is illustrative. After executing the action, the environment returns an observation to the agent, which may be the result of the action or an error message.
read the caption
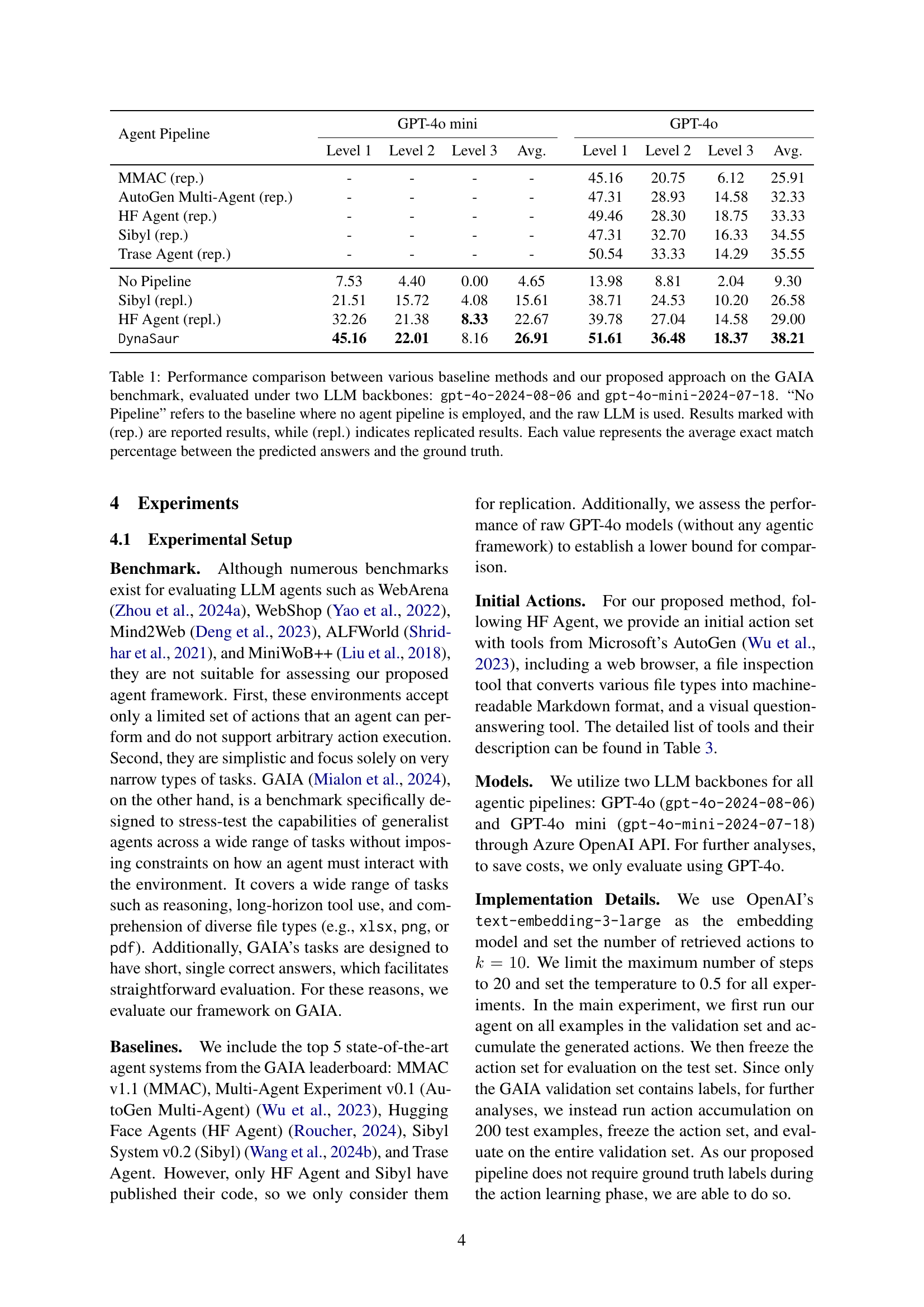
Figure 1: Illustration of the DynaSaur agent framework. In the first step, the agent receives a list of human-designed actions 𝒜usuperscript𝒜𝑢\mathcal{A}^{u}caligraphic_A start_POSTSUPERSCRIPT italic_u end_POSTSUPERSCRIPT and a task t𝑡titalic_t as input. It then proposes an action a𝑎aitalic_a, implemented as a Python snippet. The function is executed by the environment, which internally contains an IPython kernel. Depending on the generated action a𝑎aitalic_a, the kernel may interact with either the action retriever, to retrieve relevant generated actions in 𝒜gsuperscript𝒜𝑔\mathcal{A}^{g}caligraphic_A start_POSTSUPERSCRIPT italic_g end_POSTSUPERSCRIPT; the internet, for information retrieval from the web; or the local operating system for any other tasks. We do not impose any constraints on which entities the agent can interact with, so the list shown in this figure is not exhaustive and is mainly for illustration purposes. After executing the action a𝑎aitalic_a, the environment returns an observation o𝑜oitalic_o to the agent. The observation can either be the result of executing a𝑎aitalic_a or an error message if the kernel fails to execute a𝑎aitalic_a.
| Agent Pipeline | GPT-4o mini | GPT-4o | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Level 1 | Level 2 | Level 3 | Avg. | Level 1 | Level 2 | Level 3 | |||
| — | — | — | — | — | — | — | — | — | — |
| MMAC (rep.) | - | - | - | - | 45.16 | 20.75 | 6.12 | ||
| AutoGen Multi-Agent (rep.) | - | - | - | - | 47.31 | 28.93 | 14.58 | ||
| HF Agent (rep.) | - | - | - | - | 49.46 | 28.30 | 18.75 | ||
| Sibyl (rep.) | - | - | - | - | 47.31 | 32.70 | 16.33 | ||
| Trase Agent (rep.) | - | - | - | - | 50.54 | 33.33 | 14.29 | ||
| No Pipeline | 7.53 | 4.40 | 0.00 | 4.65 | 13.98 | 8.81 | 2.04 | ||
| Sibyl (repl.) | 21.51 | 15.72 | 4.08 | 15.61 | 38.71 | 24.53 | 10.20 | ||
| HF Agent (repl.) | 32.26 | 21.38 | 8.33 | 22.67 | 39.78 | 27.04 | 14.58 | ||
| DynaSaur | 45.16 | 22.01 | 8.16 | 26.91 | 51.61 | 36.48 | 18.37 |
🔼 This table compares the performance of DynaSaur against several baseline methods on the GAIA benchmark. Two different LLM backbones were used for evaluation: gpt-4o-2024-08-06 and gpt-4o-mini-2024-07-18. The results show the average exact match percentage between the model’s predictions and the ground truth. The ‘No Pipeline’ row represents the performance of the raw LLM without any agent pipeline, providing a baseline for comparison. Results marked with (rep.) are from previously reported studies, while (repl.) signifies that the experiments were replicated by the authors.
read the caption
Table 1: Performance comparison between various baseline methods and our proposed approach on the GAIA benchmark, evaluated under two LLM backbones: gpt-4o-2024-08-06 and gpt-4o-mini-2024-07-18. “No Pipeline” refers to the baseline where no agent pipeline is employed, and the raw LLM is used. Results marked with (rep.) are reported results, while (repl.) indicates replicated results. Each value represents the average exact match percentage between the predicted answers and the ground truth.
In-depth insights#
LLM Agent Limits#
The research paper section on “LLM Agent Limits” highlights two critical shortcomings of existing large language model (LLM) agent systems. First, confining LLM agents to choosing actions from a pre-defined set severely restricts their problem-solving capabilities. This limitation prevents agents from adapting to unforeseen circumstances and exploring novel solution strategies. Second, creating and implementing a comprehensive set of predefined actions requires significant human effort, rendering the process impractical for complex real-world scenarios with numerous potential actions. These limitations necessitate the development of more adaptable and flexible agent systems. The paper argues that dynamic action creation and composition, where the agent generates and executes programs in real-time, offers a more robust approach that overcomes the inherent limitations of pre-defined action sets, thus enabling LLM agents to perform more effectively in open-ended environments.
DynaSaur Framework#
The DynaSaur framework introduces dynamic action creation for LLM agents, overcoming limitations of existing systems that rely on predefined action sets. It models actions as Python functions, enabling the agent to generate and execute programs at each step. This allows for greater flexibility and adaptability in complex, real-world environments where the space of possible actions is vast and unknown. Actions are accumulated over time, building a library of reusable functions, and the agent dynamically composes complex actions from simpler ones. The framework’s Python-based action representation offers both generality and composability, facilitated by leveraging Python’s extensive ecosystem of third-party libraries and tools. This dynamic approach enhances the agent’s ability to learn from past experiences and improve efficiency, significantly outperforming existing methods on benchmarks like GAIA, especially on complex, long-horizon tasks.
Action Representation#
The ‘Action Representation’ section in the DynaSaur research paper tackles the crucial problem of how to represent actions within an LLM agent framework to enable both generality and composability. The authors cleverly choose Python functions as the representation, arguing that this choice offers the flexibility to handle a vast range of tasks, unlike limited predefined action sets used in previous approaches. This enables the agent to dynamically create new actions as needed, by generating Python code snippets, adding a significant advantage of on-the-fly adaptability. The selection of Python also leverages the extensive existing Python libraries, empowering the agent to interact with diverse systems and tools seamlessly. This novel approach moves beyond restricting actions to predefined sets and opens the door to more sophisticated, complex behaviors in LLM agents.
GAIA Benchmarking#
The GAIA benchmark provides a rigorous evaluation for LLM agents, pushing beyond simplistic tasks. It assesses the agents’ ability to handle diverse tasks and file types (xlsx, png, pdf) without predefined action sets, demanding adaptability and generalization. DynaSaur’s strong performance on GAIA, surpassing existing methods, highlights its capacity for dynamic action creation and flexible interaction with the environment. This benchmark demonstrates the framework’s capacity to learn and adapt in complex, real-world scenarios, exceeding the limitations of systems confined to pre-defined actions. The superior performance underscores the benefits of dynamically generating actions, leading to greater versatility and problem-solving abilities in open-ended tasks.
Future of LLM Agents#
The provided text does not contain a section specifically titled ‘Future of LLM Agents’. Therefore, it’s impossible to generate a summary for this heading. To provide a relevant summary, please provide the full text of the research paper’s section on ‘Future of LLM Agents’.
More visual insights#
More on figures

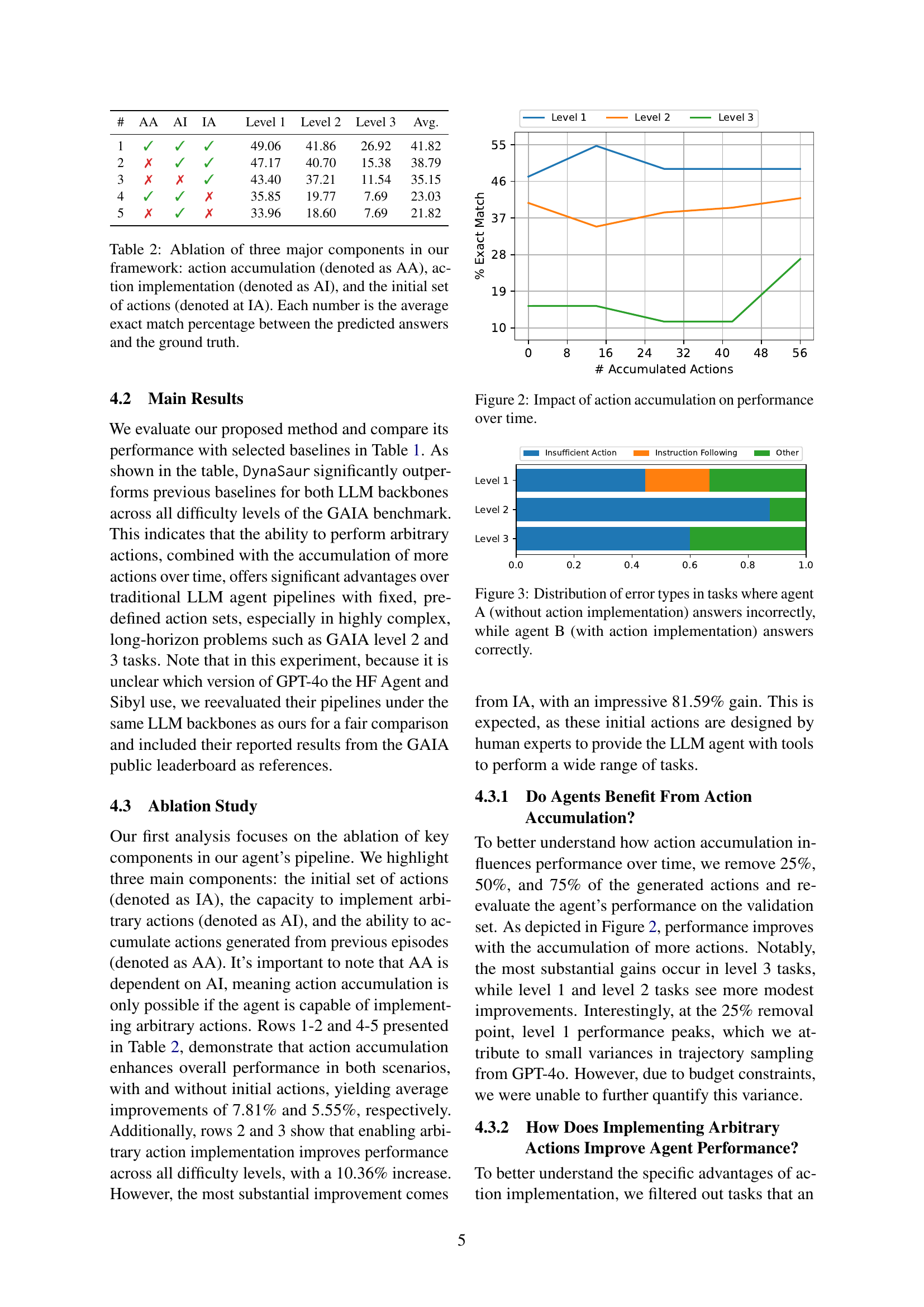
🔼 This figure shows how the model’s performance improves over time as more actions are accumulated. The x-axis represents the number of accumulated actions, and the y-axis represents the percentage of exact matches between the model’s predictions and ground truth. The figure shows separate lines for different difficulty levels (Level 1, Level 2, Level 3) of the GAIA benchmark. It demonstrates the positive impact of dynamic action creation and accumulation on the model’s performance, especially for more complex tasks.
read the caption
Figure 2: Impact of action accumulation on performance over time.

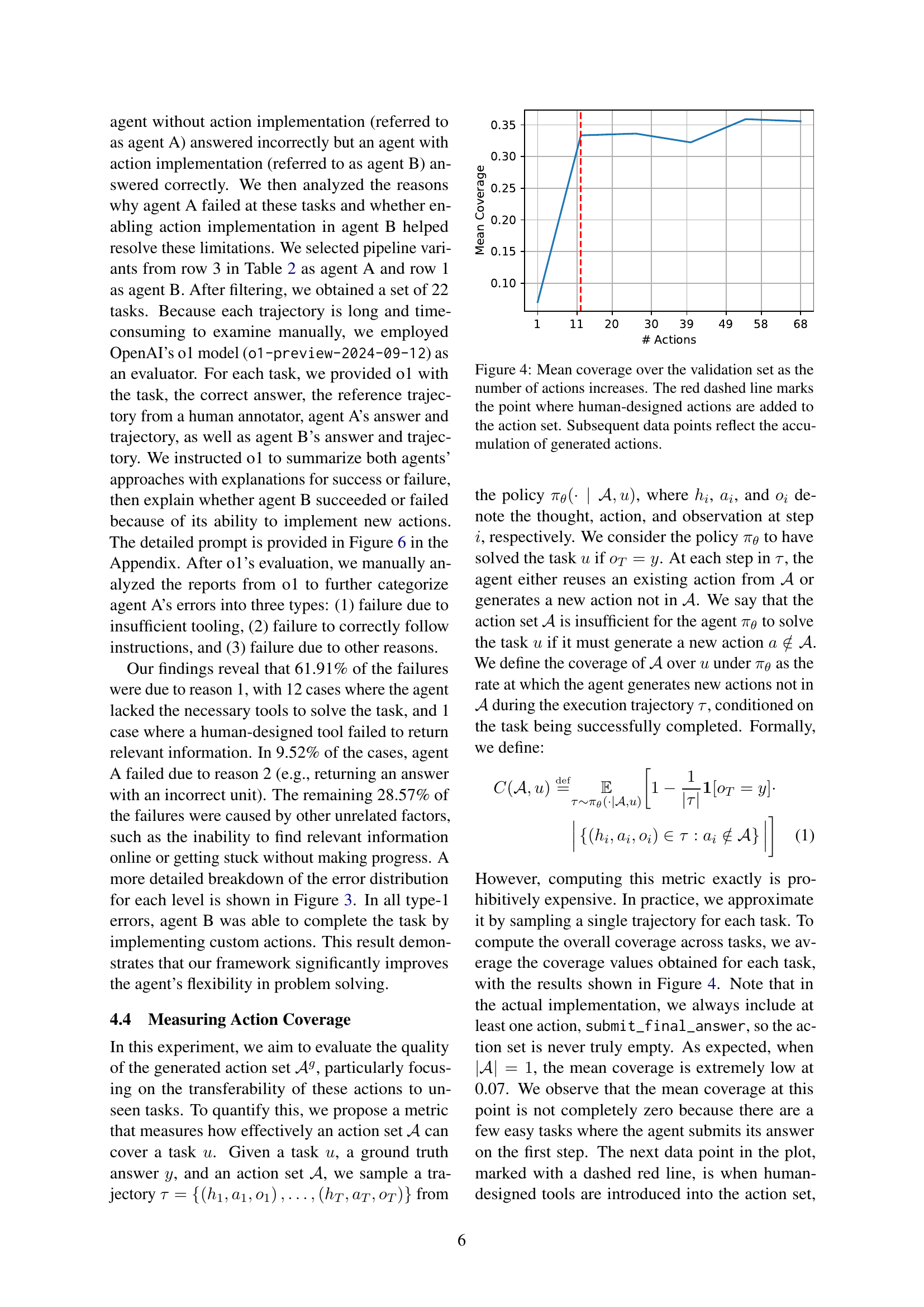
🔼 This figure shows a breakdown of the reasons why Agent A (without the ability to create new actions) failed on tasks where Agent B (with the ability to create new actions) succeeded. The error types are categorized as follows: 1. Insufficient tooling: Agent A lacked the necessary tools to solve the problem. 2. Failure to follow instructions: Agent A failed to correctly interpret or follow the instructions. 3. Other reasons: Agent A failed due to factors not directly related to the lack of action implementation. The chart visually represents the proportion of errors falling under each category.
read the caption
Figure 3: Distribution of error types in tasks where agent A (without action implementation) answers incorrectly, while agent B (with action implementation) answers correctly.

🔼 This figure illustrates the relationship between the number of actions available to the DynaSaur agent and its performance on the GAIA validation set. The x-axis represents the number of actions, starting from a small initial set and increasing as the agent generates new actions during training. The y-axis shows the mean coverage, which measures how effectively the current set of actions allows the agent to solve tasks successfully. The red dashed line indicates the point at which human-designed actions are added to the initial action set; data points after this line demonstrate the agent’s improved performance due to the accumulation of generated actions over time. The plot shows the general trend of increased coverage as the number of actions available to the agent grows, suggesting the benefit of dynamic action creation and accumulation within the DynaSaur framework.
read the caption
Figure 4: Mean coverage over the validation set as the number of actions increases. The red dashed line marks the point where human-designed actions are added to the action set. Subsequent data points reflect the accumulation of generated actions.

🔼 This figure showcases a comparative analysis of two agent models, Agent A and Agent B, tackling the same problem. Agent A represents a DynaSaur variant without the capability for dynamic action creation. Agent B, on the other hand, embodies the proposed DynaSaur framework, allowing it to generate and implement its own actions. Both agents start with identical initial steps. The figure highlights how Agent B’s dynamic action generation capabilities enable it to overcome obstacles Agent A encounters, ultimately leading to a successful task completion. Due to layout constraints, the image only displays Agent B’s trajectory from a later stage.
read the caption
Figure 5: A case study demonstrates the difference in problem-solving flexibility between Agent A (a variant of DynaSaur without action implementation) and Agent B (the proposed agent framework). Both agents begin with the same initial step, but only Agent B, equipped with the ability to implement its own actions, successfully completes the task. Due to space constraints, the first step taken by Agent B is not shown.

🔼 This figure shows the prompt used for qualitative analysis with OpenAI’s 01 model. The prompt provides the evaluator with the task, the correct answer, the ground truth trajectory from a human, agent A’s predicted answer and trajectory, agent B’s predicted answer and trajectory. It then asks the evaluator to write a report that includes a summary of the task, summaries of both agents’ trajectories, which agent performed better and why, and whether agent B’s ability to implement its own actions impacted its performance.
read the caption
Figure 6: Prompt for OpenAI’s o1 to perform qualitative evaluation.

🔼 This figure shows the system prompt used to instruct the DynaSaur LLM agent. The prompt details the agent’s role as a problem-solving assistant with access to a Python interpreter, internet, and operating system functionalities. It outlines the step-by-step process for solving tasks, emphasizing the need for clear reasoning (Thought), well-structured Python code (Code) that leverages relevant libraries, and iterative refinement based on the results. The prompt also provides guidelines for writing reusable, modular functions and for analyzing outputs, stressing real-world data usage and the importance of persistence until a solution is found or the iteration limit is reached. Sections on available functions and guidelines are included to aid the agent’s interaction and code generation.
read the caption
Figure 7: The system prompt of our DynaSaur agent framework.

🔼 This figure showcases a comparative analysis of two agents: Agent A, representing a version of DynaSaur without dynamic action creation, and Agent B, embodying the proposed DynaSaur framework. Both agents tackle the same task—identifying a counterexample to prove that a binary operation is not commutative. Agent A relies solely on predefined actions, hindering its ability to solve the problem effectively. In contrast, Agent B leverages its dynamic action generation capabilities, allowing it to create and execute a custom function to reach the solution. This directly demonstrates how the ability to create actions on-demand significantly enhances problem-solving flexibility and efficiency within the framework.
read the caption
Figure 8: A case study demonstrates the difference in problem-solving flexibility between Agent A (a variant of DynaSaur without action implementation) and Agent B (the proposed agent framework).
More on tables
| # | AA | AI | IA | Level 1 | Level 2 | Level 3 | Avg. | |
|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✓ | ✓ | 49.06 | 41.86 | 26.92 | 41.82 | |
| 2 | ✗ | ✓ | ✓ | 47.17 | 40.70 | 15.38 | 38.79 | |
| 3 | ✗ | ✗ | ✓ | 43.40 | 37.21 | 11.54 | 35.15 | |
| 4 | ✓ | ✓ | ✗ | 35.85 | 19.77 | 7.69 | 23.03 | |
| 5 | ✗ | ✓ | ✗ | 33.96 | 18.60 | 7.69 | 21.82 |
🔼 This table presents the results of an ablation study conducted to analyze the impact of three key components on the performance of the DynaSaur framework. The components evaluated are action accumulation (AA), action implementation (AI), and the initial set of actions (IA). Each row represents a different combination of these components, with ‘✓’ indicating inclusion and ‘✗’ indicating exclusion. The average exact match percentage between the model’s predictions and ground truth across various difficulty levels of the GAIA benchmark is reported for each configuration. This allows for a quantitative assessment of the relative contributions of AA, AI, and IA to the overall system’s success in solving diverse tasks.
read the caption
Table 2: Ablation of three major components in our framework: action accumulation (denoted as AA), action implementation (denoted as AI), and the initial set of actions (denoted at IA). Each number is the average exact match percentage between the predicted answers and the ground truth.
| # | Action Header | Description |
|---|---|---|
| 1 | submit_final_answer | Submits the final answer to the given problem. |
| 2 | get_relevant_actions | Retrieve k most relevent generated actions given a query. |
| 3 | informational_web_search | Perform an informational web search query then return the search results. |
| 4 | navigational_web_search | Perform a navigational web search query then immediately navigate to the top result. |
| 5 | visit_page | Visit a webpage at a given URL and return its text. |
| 6 | download_file | Download a file at a given URL. |
| 7 | page_up | Scroll the viewport up in the current webpage and return the new viewport content. |
| 8 | page_down | Scroll the viewport down in the current webpage and return the new viewport content. |
| 9 | find_on_page_ctrl_f | Scroll the viewport to the first occurrence of the search string. |
| 10 | find_next | Scroll the viewport to next occurrence of the search string. |
| 11 | find_archived_url | Given a url, searches the Wayback Machine and returns the archived version of the url that’s closest in time to the desired date. |
| 12 | visualizer | Answer question about a given image. |
| 13 | inspect_file_as_text | Read a file and return its content as Markdown text. |
🔼 This table lists the initial actions provided to the DynaSaur agent at the beginning of each task. These actions are pre-defined functions, mostly interacting with external resources like web pages or files, enabling the agent to perform basic operations in various domains. They serve as the foundation upon which the agent can build and expand its capabilities dynamically by generating and executing its own functions.
read the caption
Table 3: List of initial actions used in this project.
Full paper#