↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) are rapidly evolving, but most open-source models use dense architectures, limiting their efficiency and scalability. Mixture-of-Experts (MoE) models offer an alternative, distributing computation across specialized submodels, but often lack scale and robust training methods. This research addresses these issues by introducing Hunyuan-Large.
Hunyuan-Large is a massive open-source MoE model exceeding other open-source LLMs in size and performance across various benchmarks. Its success is attributed to several key innovations, including extensive synthetic training data, a mixed-expert routing strategy, and techniques to improve efficiency. The paper also investigates the scaling laws of MoE models, providing valuable guidance for future model development and optimization.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents Hunyuan-Large, a significant advancement in open-source large language models (LLMs). Its massive scale and innovative MoE architecture address limitations of existing models, opening avenues for research on efficient scaling and improved performance. The release of the model’s code and checkpoints directly benefits the research community, accelerating progress in LLM development and application. This work also offers insights into the scaling laws of MoE models, guiding future development.
Visual Insights#

🔼 This figure illustrates the four-step data synthesis process used in the pre-training of Hunyuan-Large. First, instructions are generated using various sources like web pages and books. Second, these instructions are evolved by refining them, expanding low-resource domains, and increasing the difficulty level. Third, responses to these evolved instructions are generated by specialized models. Finally, the generated instruction-response pairs are filtered to ensure high quality and consistency, removing low-quality or inconsistent data. This process is crucial for creating high-quality and diverse training data for the model.
read the caption
Figure 1: The four-step process of data synthesis in Hunyuan-Large’s pre-training: (1) Instruction generation, (2) Instruction evolution, (3) Response generation, and (4) Response filtering.
| Configuration | Hunyuan-Large |
|---|---|
| # Layers | 64 |
| # Attention Heads | 80 |
| # Key/Value Heads | 8 |
| # Shared Experts | 1 |
| # Specialized Experts | 16 |
| # Activated Specialized Experts | 1 |
| # Trained Tokens | 7T |
| Activation Function | SwiGLU |
| Vocabulary Size | 128K |
| Hidden Size | 6,400 |
🔼 Table 1 presents a detailed breakdown of the Hunyuan-Large model’s architecture and key hyperparameters. It highlights the model’s impressive scale, with 389 billion total parameters and 52 billion activated parameters. The table clarifies the model’s structure, specifying the number of layers, attention heads, key/value heads, and the unique configuration of experts (1 shared and 1 specialized expert activated per token). This level of detail is crucial for understanding the model’s complexity and resource requirements.
read the caption
Table 1: Overview of the architecture and key hyper-parameters of Hunyuan-Large. This model has 389B total parameters and 52B activated parameters. There are 1 shared expert and 1 specialized expert activated for each token.
In-depth insights#
MoE Model Scaling#
The research explores Mixture-of-Experts (MoE) model scaling, focusing on the relationship between model size, training data, and performance. They investigate scaling laws, revealing that optimal performance is achieved with a specific balance between activated parameters and training data. The study highlights the importance of high-quality synthetic data, significantly exceeding previous literature, for effective MoE training. Furthermore, they introduce and analyze the efficiency gains from strategies such as mixed expert routing, KV cache compression, and expert-specific learning rates, demonstrating practical techniques to optimize MoE model training and deployment. These findings offer valuable insights for future MoE model development and optimization, guiding researchers toward more efficient and powerful large language models.
Synthetic Data Power#
The research paper does not have a specific heading titled ‘Synthetic Data Power’. However, the paper extensively discusses the crucial role of high-quality synthetic data in training the Hunyuan-Large model. A significant portion of the training data (1.5T tokens out of 7T) consists of synthetic data, generated through a four-step process including generation, evolution, response generation, and filtering. This approach improves data quality and diversity, enabling the model to learn richer representations and generalize better to unseen data. The use of synthetic data is highlighted as a key innovation differentiating Hunyuan-Large from previous models, particularly in its massive scale and focus on diverse, educational fields like mathematics and coding. The effectiveness of this synthetic data strategy is supported by the model’s superior performance on various benchmarks.
KV Cache Efficiency#
To address the memory constraints and computational costs associated with key-value (KV) caching in large language models (LLMs), especially those with Mixture-of-Experts (MoE) architectures, the authors implemented two crucial compression strategies: Grouped-Query Attention (GQA) and Cross-Layer Attention (CLA). GQA groups KV heads, reducing the overall cache size. CLA shares the KV cache across adjacent layers, further enhancing efficiency. This combined approach resulted in a remarkable 95% reduction in total KV cache memory compared to the standard multi-head attention mechanism. This optimization significantly improved inference speed without significantly impacting the model’s performance, demonstrating the effectiveness of their combined strategy for efficient and scalable LLM deployment.
Post-Training Methods#
The research paper’s “Post-Training Methods” section details techniques to enhance the pre-trained Hunyuan-Large model. Supervised Fine-Tuning (SFT) refines the model using high-quality instruction data encompassing diverse tasks like mathematical problem-solving and code generation. This process focuses on data collection, balancing instruction types, and quality control through rule-based and model-based filtering, alongside human review. Reinforcement Learning from Human Feedback (RLHF) further improves the model using a single-stage training strategy combining offline and online methods. This involves utilizing a pre-compiled preference dataset and a reward model to select and optimize responses, preventing issues like reward hacking. The combination of SFT and RLHF is designed to align the model better with human preferences while enhancing its performance and addressing practical application needs.
Long-Context Limits#
The provided text does not contain a heading specifically titled ‘Long-Context Limits’. However, sections discussing the model’s ability to handle long sequences of text are present. Hunyuan-Large is demonstrated to successfully process sequences up to 256K tokens, showcasing significant advancements in long-context capabilities. This is achieved through a combination of strategies including the use of Rotary Position Embeddings (RoPE) and scaling of the RoPE base frequency, which enhances the model’s ability to manage long-range dependencies within the text. The paper also reports experimental results on benchmarks designed to assess long-context understanding, such as RULER and LV-Eval. While the exact limits aren’t explicitly defined as a ‘Long-Context Limit’, the results across various benchmarks show that performance does not significantly degrade even with very long input sequences, suggesting that the model effectively handles long-range dependencies. The introduction of a custom dataset, PenguinScrolls, further tests the model’s limits within realistic long-context scenarios. Overall, the paper strongly suggests that Hunyuan-Large pushes the boundaries of current long-context processing capabilities of large language models.
More visual insights#
More on figures

🔼 In traditional top-k routing, tokens are assigned to the top k experts based on their scores. If an expert exceeds its maximum capacity, the excess tokens are dropped. This can lead to information loss and inefficiency.
read the caption
(a) Traditional Top-k Routing.

🔼 This figure shows the Recycle Routing strategy used in Hunyuan-Large. In traditional Top-k routing, tokens from overloaded experts are dropped. However, the Recycle Routing strategy reassigns these tokens to other experts that are not overloaded, preventing loss of information and improving training efficiency. The illustration compares the traditional approach with the new recycle routing.
read the caption
(b) Recycle Routing.

🔼 This figure illustrates the difference between the traditional top-k routing strategy and the novel recycle routing strategy used in Hunyuan-Large. In the traditional approach (a), when an expert’s capacity is reached, excess tokens are dropped, potentially leading to information loss. The recycle routing strategy (b) addresses this by randomly reassigning tokens initially sent to overloaded experts to other experts that are not at capacity. This ensures no information is lost and maintains efficiency.
read the caption
Figure 2: An illustration of the recycle routing strategy in Hunyuan-Large, where each expert’s maximum capacity is set to 2. Token D, which was initially allocated to the overloaded Expert 1, is reassigned to a randomly selected Expert 4. This approach helps alleviate the potential loss of valuable information. In traditional routing strategies, tokens from overloaded experts would be dropped as shown in (a). However, our strategy involves randomly reassigning these tokens to other experts, as demonstrated in (b), where Token D is routed to Expert 4.

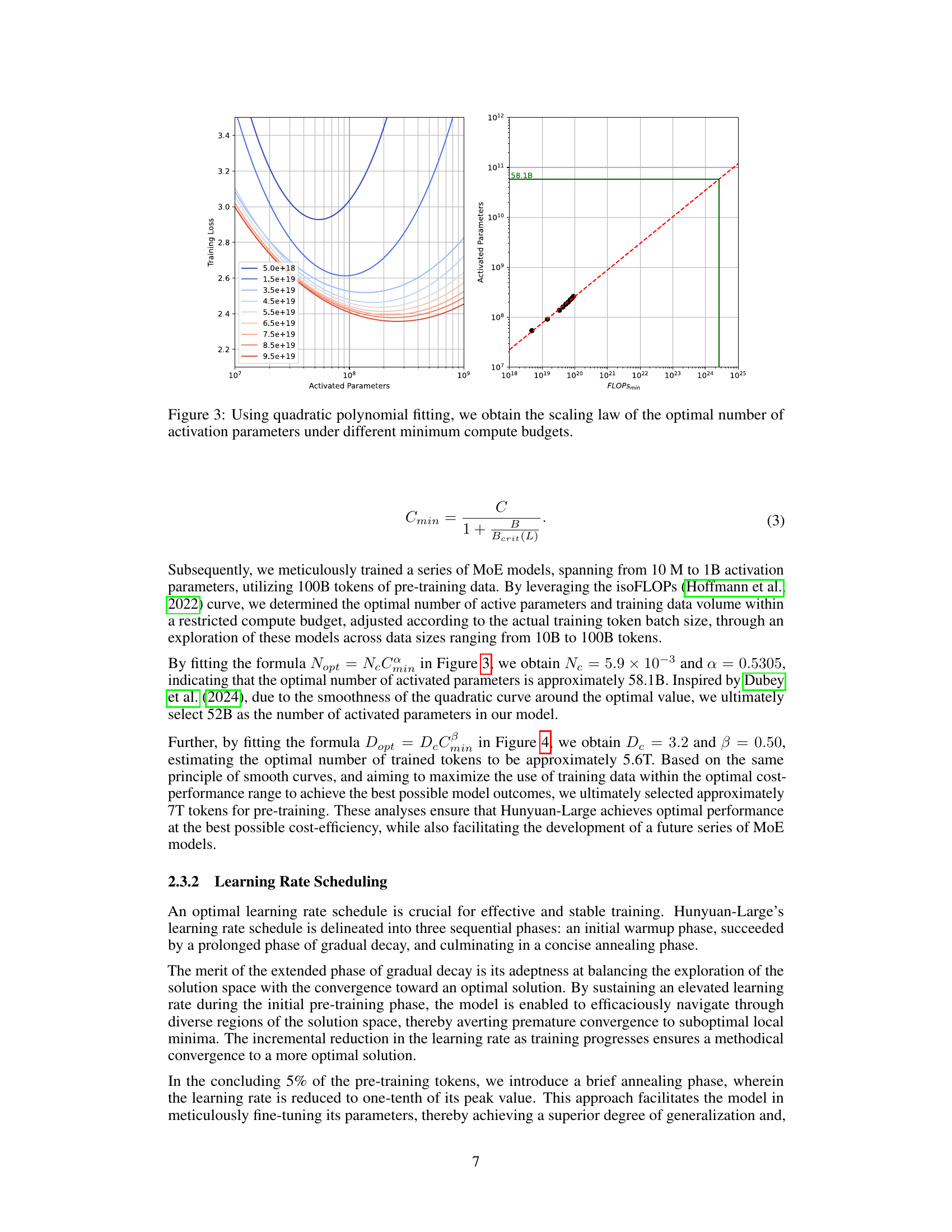
🔼 This figure shows the relationship between the optimal number of activated parameters in a Mixture of Experts (MoE) model and the minimum compute budget. By using quadratic polynomial fitting on data from experiments with varying numbers of activated parameters and training data, the authors derived a scaling law. This law helps guide the choice of the optimal model size based on available computational resources. The x-axis represents the minimum compute budget (FLOPSmin), and the y-axis represents the optimal number of activated parameters. The curves represent the scaling law at different training loss values, providing insights for effective and efficient model training with limited resources.
read the caption
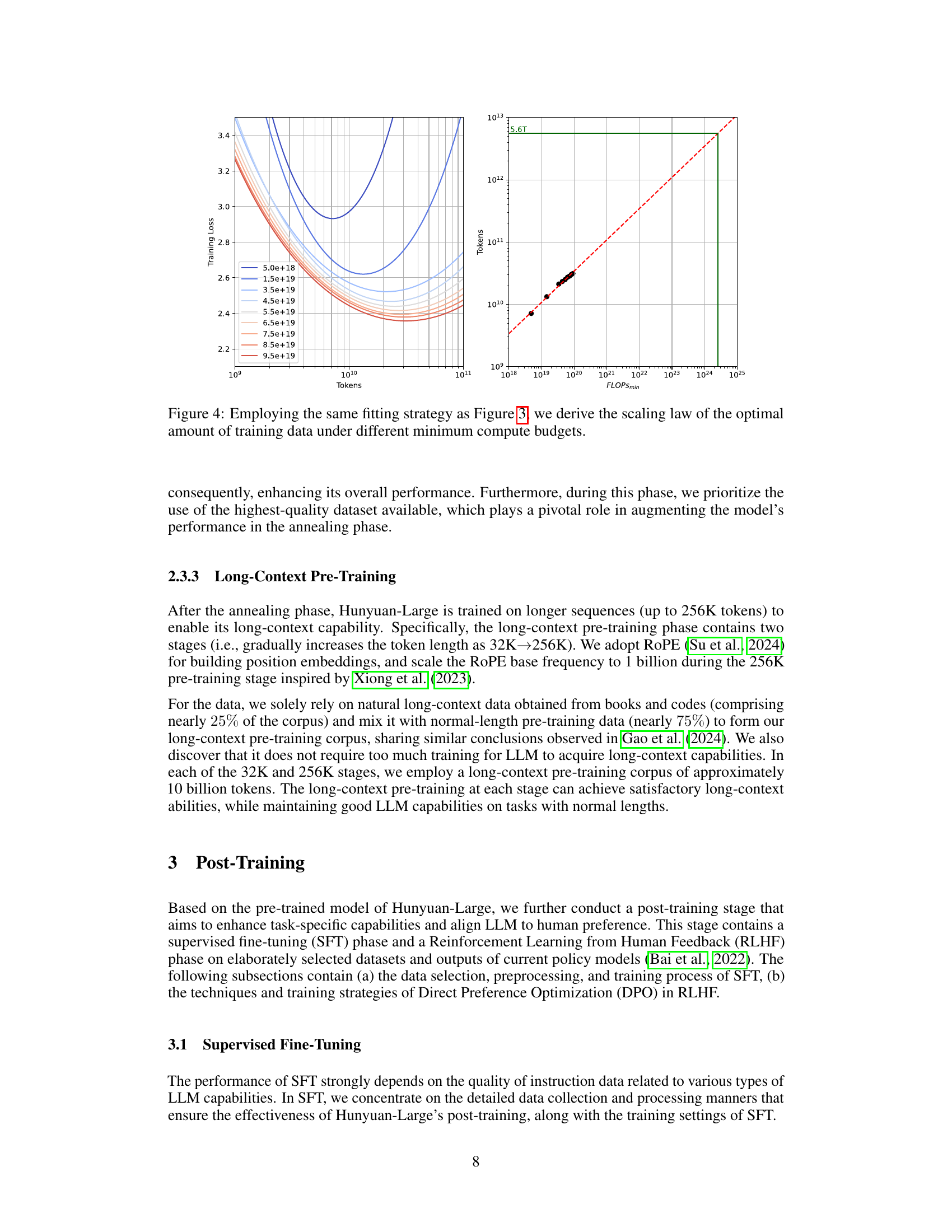
Figure 3: Using quadratic polynomial fitting, we obtain the scaling law of the optimal number of activation parameters under different minimum compute budgets.
More on tables
| Attention Mechanism | KV Cache Memory |
|---|---|
| MHA | 4nhdhl |
| GQA | 4ngdhl |
| MQA | 4dhl |
| CLA | 2nhdhl |
| GQA+CLA | 2ngdhl |
🔼 This table compares the memory usage (in bytes, using bf16 precision) of different attention mechanisms used in Transformer models. The comparison includes Multi-Head Attention (MHA), Grouped-Query Attention (GQA), Multi-Query Attention (MQA), and Cross-Layer Attention (CLA). It also shows the combined effect of GQA and CLA, which is used in the Hunyuan-Large model. The table shows how the memory usage scales with the number of attention heads (nh), dimension per head (dh), number of layers (l), and number of groups in GQA (ng, where ng < nh). Cross-Layer Attention (CLA) is implemented by sharing the KV cache every 2 layers. The table helps illustrate the memory savings achieved by using GQA+CLA in Hunyuan-Large compared to traditional MHA.
read the caption
Table 2: Comparisons of KV cache memory (in bytes on bf16) for different attention mechanisms. The attention mechanisms include Multi-Head Attention (MHA), Grouped-Query Attention (GQA), Multi-Query Attention (MQA), Cross-Layer Attention (CLA), and GQA+CLA (the final setting in Hunyuan-Large). nhsubscript𝑛ℎn_{h}italic_n start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT, dhsubscript𝑑ℎd_{h}italic_d start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT, l𝑙litalic_l, and ngsubscript𝑛𝑔n_{g}italic_n start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT represent the number of attention heads, the dimension per head, the number of layers, and the number of groups in GQA (ngsubscript𝑛𝑔n_{g}italic_n start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT
| Model | LLama3.1-405B | LLama3.1-70B | Mixtral-8x22B | DeepSeek-V2 | Hunyuan-Large |
|---|---|---|---|---|---|
| Architecture | Dense | Dense | MoE | MoE | MoE |
| # Activated Params | 405B | 70B | 39B | 21B | 52B |
| # Total Params | 405B | 70B | 141B | 236B | 389B |
| Context Length | 128k | 128k | 64k | 128k | 256k |
| English | |||||
| MMLU | 85.2 | 79.3 | 77.8 | 78.5 | 88.4 |
| MMLU-Pro | 61.6 | 53.8 | 49.5 | - | 60.2 |
| BBH | 85.9 | 81.6 | 78.9 | 78.9 | 86.3 |
| HellaSwag | - | - | 88.7 | 87.8 | 86.8 |
| CommonsenseQA | 85.8 | 84.1 | 82.4 | - | 92.9 |
| WinoGrande | 86.7 | 85.3 | 85.0 | 84.9 | 88.7 |
| PIQA | - | - | 83.6 | 83.7 | 88.3 |
| NaturalQuestions | - | - | 39.6 | 38.7 | 52.8 |
| DROP | 84.8 | 79.6 | 80.4 | 80.1 | 88.9 |
| ARC-C | 96.1 | 92.9 | 91.2 | 92.4 | 95.0 |
| TriviaQA | - | - | 82.1 | 79.9 | 89.2 |
| Chinese | |||||
| CMMLU | - | - | 60.0 | 84.0 | 90.2 |
| C-Eval | - | - | 59.6 | 81.7 | 91.9 |
| C3 | - | - | 71.4 | 77.4 | 82.3 |
| Math | |||||
| GSM8K | 89.0 | 83.7 | 83.7 | 79.2 | 92.8 |
| MATH | 53.8 | 41.4 | 42.5 | 43.6 | 69.8 |
| CMATH | - | - | 72.3 | 78.7 | 91.3 |
| Code | |||||
| HumanEval | 61.0 | 58.5 | 53.1 | 48.8 | 71.4 |
| MBPP | 73.4 | 68.6 | 64.2 | 66.6 | 72.6 |
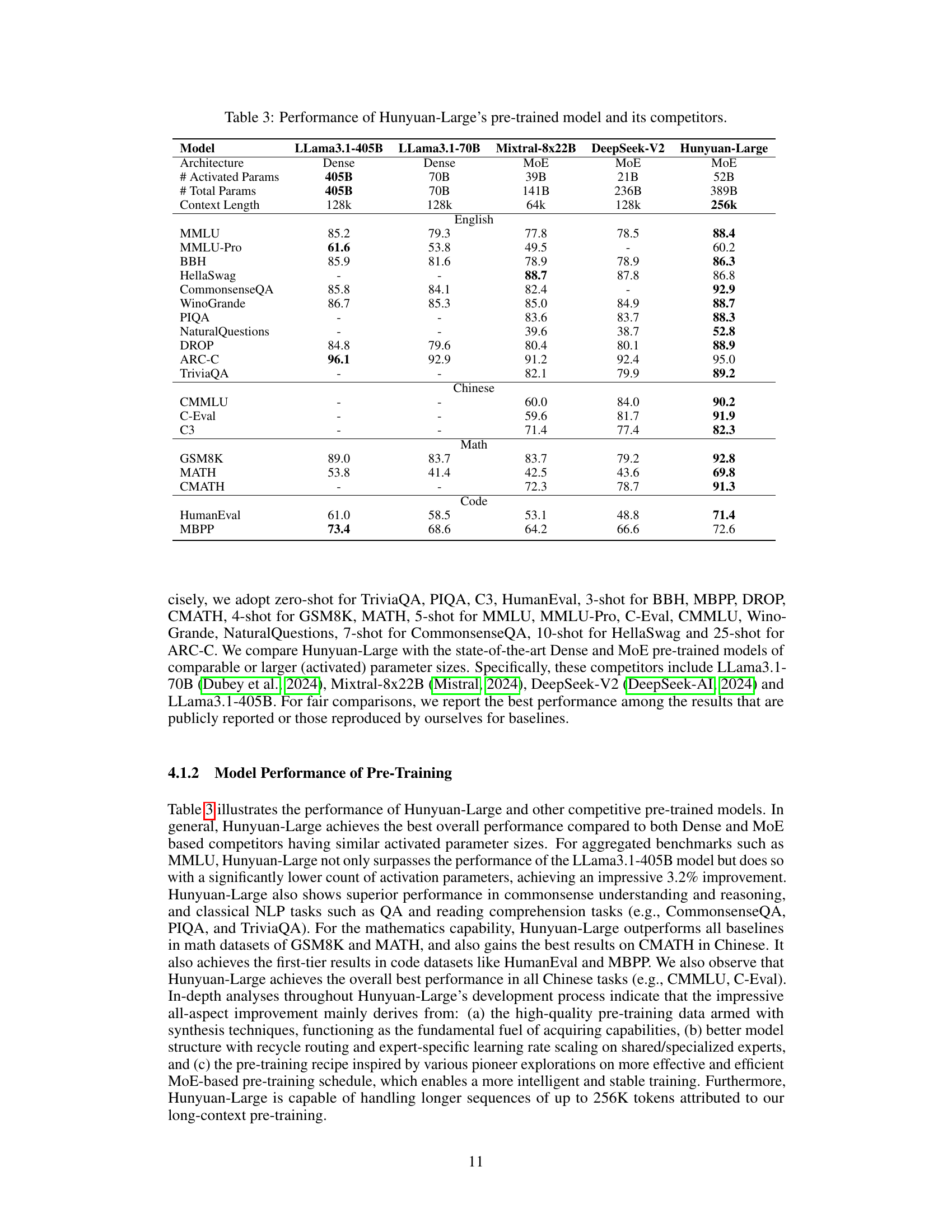
🔼 This table compares the performance of Tencent’s Hunyuan-Large pre-trained model against several other leading large language models (LLMs), including LLaMA3.1-70B, Mistral-8x22B, and DeepSeek-V2. The comparison encompasses various benchmark tasks across English and Chinese languages, covering areas like language understanding, reasoning, math, coding, and commonsense. Key metrics are presented for each model to demonstrate the relative strengths and weaknesses of each LLM on different task types. The table highlights Hunyuan-Large’s performance relative to other models of similar scale, and also includes information on the number of parameters and activated parameters for each model. The context length each model can handle is also included.
read the caption
Table 3: Performance of Hunyuan-Large’s pre-trained model and its competitors.
| Model | LLAMA 3.1 405B Inst. | LLAMA 3.1 70B Inst. | Mixtral 8x22B Inst. | DeepSeek V2.5 Chat | Hunyuan-Large Inst. |
|---|---|---|---|---|---|
| MMLU | 87.3 | 83.6 | 77.8 | 80.4 | 89.9 |
| CMMLU | - | - | 61.0 | - | 90.4 |
| C-Eval | - | - | 60.0 | - | 88.6 |
| BBH | - | - | 78.4 | 84.3 | 89.5 |
| ARC-C | 96.9 | 94.8 | 90.0 | - | 94.6 |
| GPQA_diamond | 51.1 | 46.7 | - | - | 42.4 |
| MATH | 73.8 | 68.0 | 49.8 | 74.7 | 77.4 |
| HumanEval | 89.0 | 80.5 | 75.0 | 89.0 | 90.0 |
| AlignBench | 6.0 | 5.9 | 6.2 | 8.0 | 8.3 |
| MT-Bench | 9.1 | 8.8 | 8.1 | 9.0 | 9.4 |
| IFEval strict-prompt | 86.0 | 83.6 | 71.2 | - | 85.0 |
| Arena-Hard | 69.3 | 55.7 | - | 76.2 | 81.8 |
| AlpacaEval-2.0 | 39.3 | 34.3 | 30.9 | 50.5 | 51.8 |
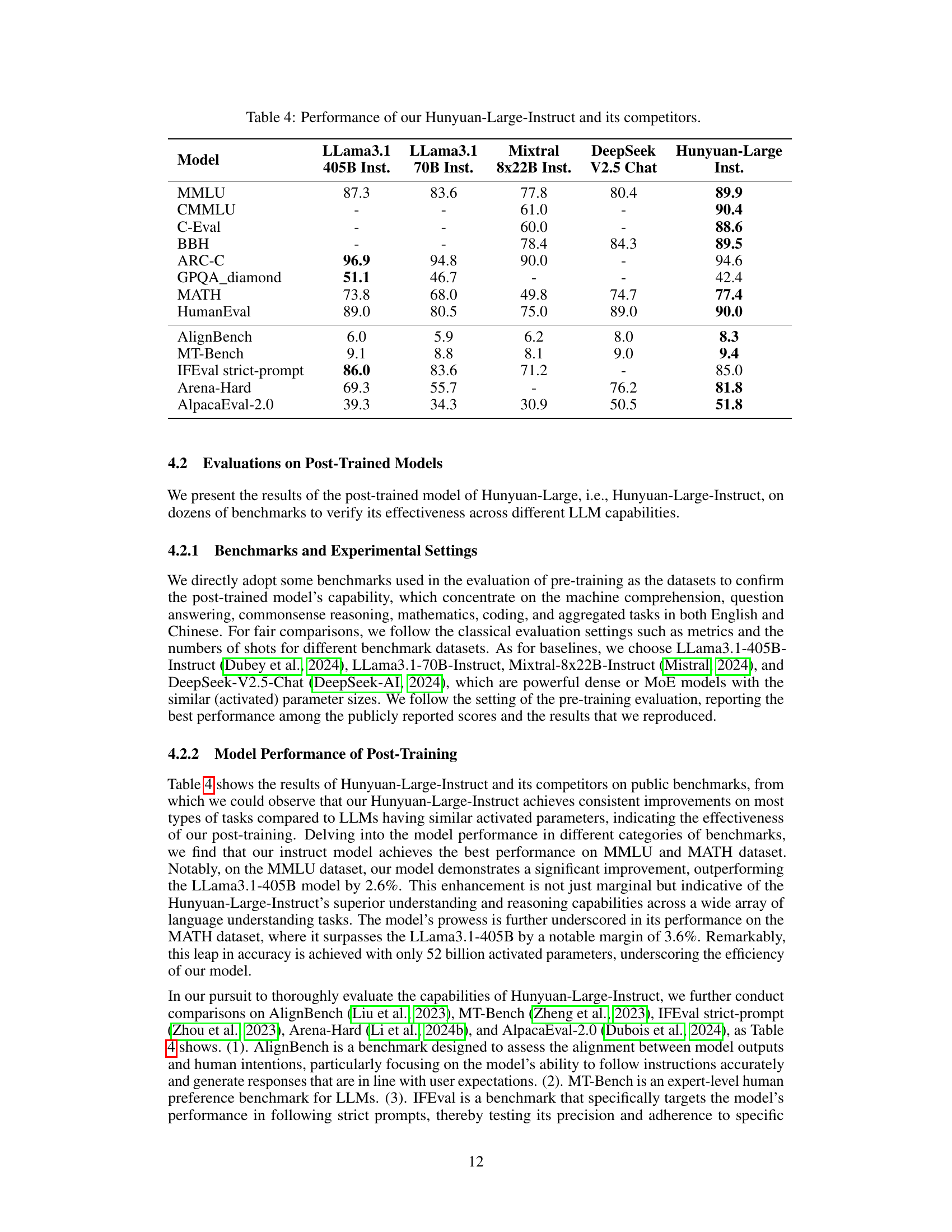
🔼 This table presents a comparison of the performance of Tencent’s Hunyuan-Large-Instruct model against several other leading large language models (LLMs) across a range of benchmark tasks. The benchmarks cover diverse areas such as commonsense reasoning, knowledge-based question answering, mathematical problem-solving, coding ability, and more. The table allows readers to quickly evaluate the relative strengths and weaknesses of Hunyuan-Large-Instruct compared to its competitors, including models like LLaMA and Mixtral, by showing each model’s performance score on each benchmark task. The inclusion of different instruction types for some benchmarks further enriches the comparative analysis.
read the caption
Table 4: Performance of our Hunyuan-Large-Instruct and its competitors.
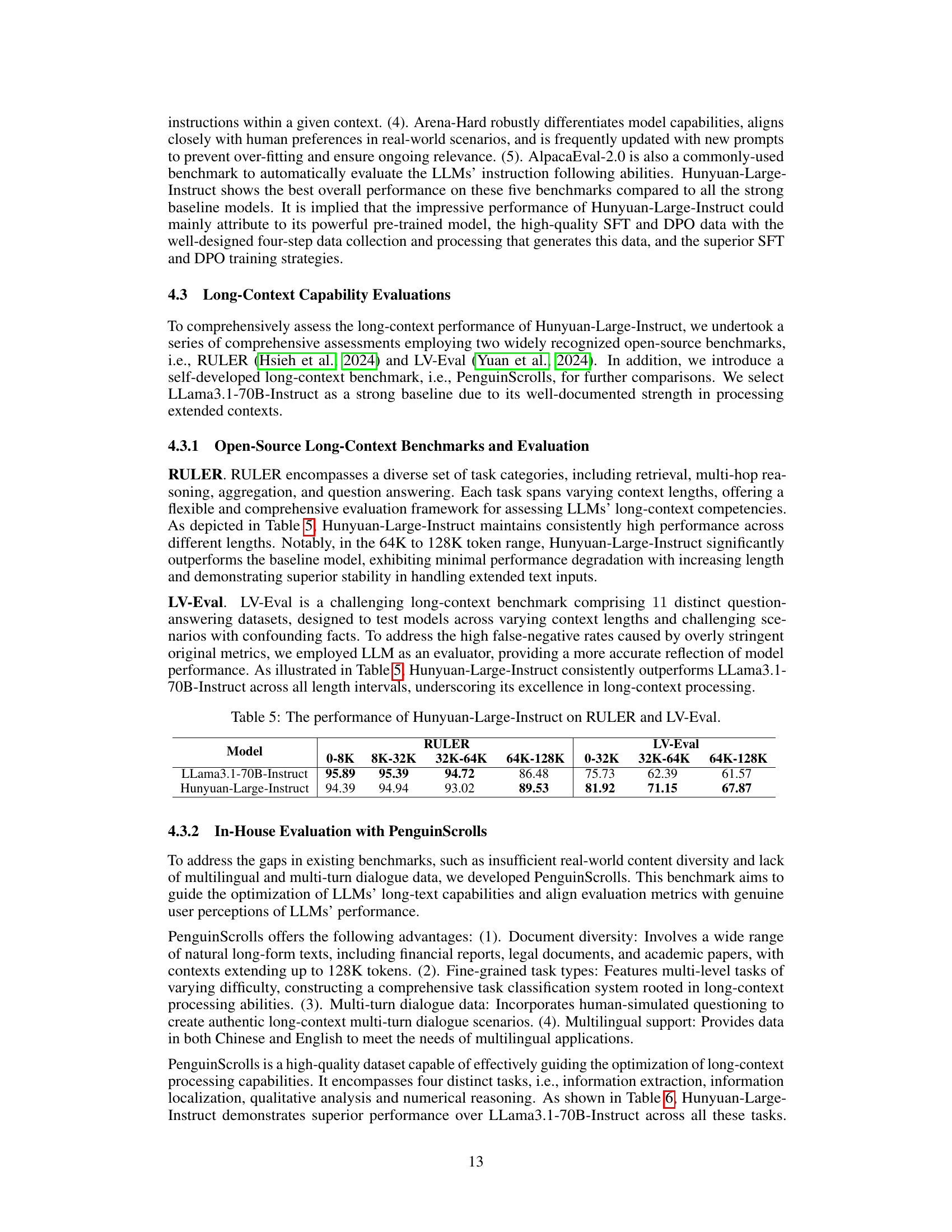
| Model | 0-8K | 8K-32K | 32K-64K | 64K-128K | 0-32K | 32K-64K | 64K-128K |
|---|---|---|---|---|---|---|---|
| LLama3.1-70B-Instruct | 95.89 | 95.39 | 94.72 | 86.48 | 75.73 | 62.39 | 61.57 |
| Hunyuan-Large-Instruct | 94.39 | 94.94 | 93.02 | 89.53 | 81.92 | 71.15 | 67.87 |
🔼 This table presents the performance comparison of the Hunyuan-Large-Instruct model and the LLama3.1-70B-Instruct model on two long-context benchmarks: RULER and LV-Eval. RULER assesses performance across various tasks and context lengths, while LV-Eval focuses on question-answering with varying complexities and context lengths. The table shows the accuracy scores for each model across different context length ranges (0-8K, 8K-32K, 32K-64K, 64K-128K tokens). This allows for an analysis of how the model’s performance changes as the context length increases.
read the caption
Table 5: The performance of Hunyuan-Large-Instruct on RULER and LV-Eval.
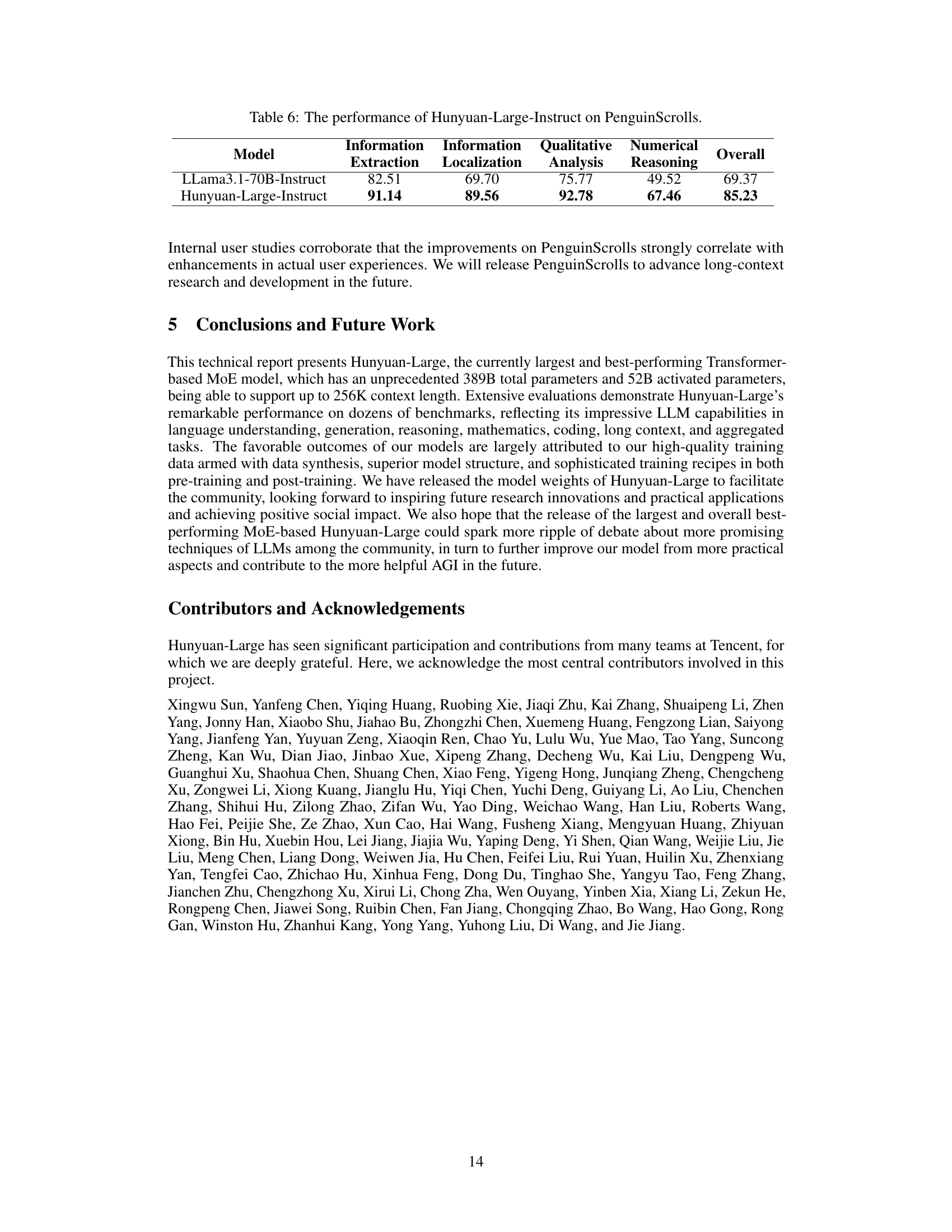
| Model | Information Extraction | Information Localization | Qualitative Analysis | Numerical Reasoning | Overall |
|---|---|---|---|---|---|
| LLama3.1-70B-Instruct | 82.51 | 69.70 | 75.77 | 49.52 | 69.37 |
| Hunyuan-Large-Instruct | 91.14 | 89.56 | 92.78 | 67.46 | 85.23 |
🔼 This table presents the performance of the Hunyuan-Large-Instruct model on the PenguinScrolls benchmark. PenguinScrolls is a newly introduced, in-house long-context benchmark designed to evaluate LLMs’ performance on real-world, diverse long-form text data. The table shows the model’s performance across four key sub-tasks within the benchmark: Information Extraction, Information Localization, Qualitative Analysis, and Numerical Reasoning. The results are presented to show the model’s capabilities and efficiency in handling extended text inputs across different task types.
read the caption
Table 6: The performance of Hunyuan-Large-Instruct on PenguinScrolls.
Full paper#