↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating realistic 3D and 4D scenes from images is challenging due to the lack of large-scale datasets and effective model designs. Current methods struggle with dynamic content creation and handling varying numbers of input images. This paper tackles these issues by proposing GenXD, a unified model for high-quality 3D and 4D scene generation. It also introduces a new large-scale dataset, CamVid-30K, specifically designed to improve the training and evaluation of 4D generation models.
GenXD employs innovative multiview-temporal modules to efficiently disentangle camera and object movements, enabling seamless learning from both 3D and 4D data. Masked latent conditions provide flexibility, allowing for the use of any number of conditioning views without modifying the model. Extensive evaluations demonstrate GenXD’s effectiveness in generating realistic videos and 3D-consistent views, showcasing its superiority over existing methods in both single and multi-view scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and generative modeling due to its introduction of GenXD, a novel unified model for high-quality 3D and 4D scene generation. It addresses the scarcity of large-scale 4D datasets by introducing CamVid-30K, which enables significant advancements in dynamic scene generation. The innovative multiview-temporal modules and masked latent conditions allow for flexible and high-quality content generation from varied input views. This opens promising new directions for research on 3D and 4D generative models and their applications in virtual reality, video games, and other domains.
Visual Insights#

🔼 This figure showcases the GenXD model’s capabilities in generating high-quality 3D and 4D scenes from various numbers of input images. The model takes condition images (marked with a star icon) as input and can be controlled to generate outputs with different degrees of motion (indicated by dashed lines representing the time dimension). The significance lies in GenXD’s ability to handle both 3D (static) and 4D (dynamic) generation tasks within a single unified framework, adapting seamlessly to diverse application needs without requiring any model adjustments. The four subfigures illustrate the model’s performance across different scenarios: single-view 3D generation, multi-view 3D generation, single-view 4D generation, and multi-view 4D generation.
read the caption
Figure 1: Gen𝒳𝒳\mathcal{X}caligraphic_XD is a unified model for high-quality 3D and 4D generation from any number of condition images. By controlling the motion strength and condition masks, Gen𝒳𝒳\mathcal{X}caligraphic_XD can support various application without any modification. The condition images are shown with star icon and the time dimension is illustrated with dash line.
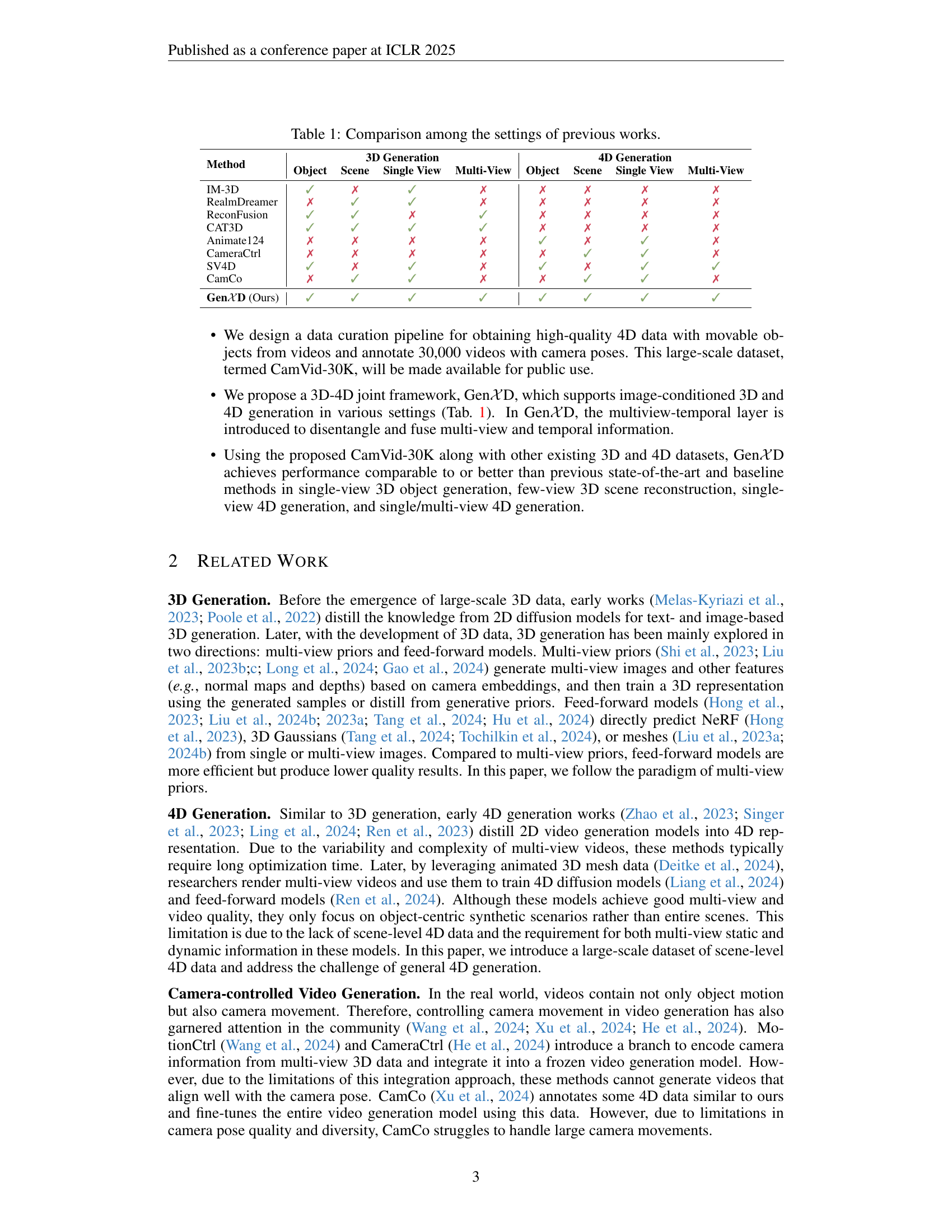
| Method | 3D Generation | 4D Generation | ||||||
|---|---|---|---|---|---|---|---|---|
| Object | Scene | Single View | Multi-View | Object | Scene | Single View | Multi-View | |
| — | — | — | — | — | — | — | — | — |
| IM-3D | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| RealmDreamer | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| ReconFusion | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| CAT3D | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Animate124 | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ |
| CameraCtrl | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| SV4D | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| CamCo | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| Gen𝒳D (Ours) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares the capabilities of various existing methods for 3D and 4D scene generation. It shows which methods support generation with object-level detail, scene-level detail, single-view generation, and multi-view generation for both 3D and 4D scenarios.
read the caption
Table 1: Comparison among the settings of previous works.
In-depth insights#
4D Scene Synthesis#
The research paper introduces GenXD, a novel framework for high-quality 3D and 4D scene generation. A key contribution is its ability to handle 4D scene synthesis from various numbers of conditional images. GenXD leverages a data curation pipeline that estimates camera poses and object motion from videos, creating the CamVid-30K dataset for training. The model incorporates multiview-temporal modules to disentangle camera and object movements, leading to more realistic and consistent 4D outputs. Masked latent conditioning allows GenXD to adapt to different numbers of input views without modification, further enhancing flexibility. The results demonstrate GenXD’s effectiveness in generating videos that faithfully follow camera trajectories and exhibit realistic object motion, surpassing the performance of other existing methods in both 3D and 4D generation tasks.
CamVid-3D Dataset#
The provided text does not contain a heading titled ‘CamVid-3D Dataset’. Instead, it describes a ‘CamVid-30K’ dataset, a large-scale real-world 4D scene dataset created by curating video data. The process involves estimating camera poses via Structure-from-Motion (SfM) and identifying moving objects using instance segmentation. A key innovation is the introduction of ‘motion strength’, a metric that quantifies object movement, which is used to filter out static scenes. This meticulous approach ensures only dynamic scenes with detectable object motion are included, resulting in approximately 30,000 high-quality 4D video samples. The dataset’s significance lies in addressing the scarcity of real-world 4D data, crucial for advancing the field of 4D scene generation and related dynamic 3D tasks.
GenXD Framework#
The GenXD framework is a unified model for high-quality 3D and 4D scene generation from any number of condition images. It leverages a mask latent conditioned diffusion model to handle various conditioning views without modification. GenXD’s core innovation lies in its multiview-temporal modules, which disentangle camera and object movements, enabling seamless learning from both 3D and 4D data. These modules use an α-fusing strategy to merge spatial and temporal information for 4D data, while removing temporal information for 3D data. Object motion strength estimated from the CamVid-30K dataset is incorporated to better control object motion in video generation. The model’s ability to effectively manage and combine multi-view and temporal data makes it a powerful tool for a range of 3D and 4D generation tasks.
Ablation Studies#
The ablation study in the research paper investigates the impact of motion disentanglement and camera conditioning on the model’s performance. Results reveal that disentangling camera and object motion is crucial for high-quality 3D and 4D generation. Removing this disentanglement significantly reduces performance. Furthermore, the study highlights the importance of the motion strength parameter in controlling the magnitude of object movement, demonstrating that accurately representing object motion improves generation quality. The effectiveness of the proposed mask latent conditioning approach for handling multiple input views is also validated. The results emphasize the model’s sensitivity to data representation and the importance of careful data curation and model design choices for effective 3D and 4D generation.
Future Directions#
The provided text does not include a section or heading explicitly titled “Future Directions.” Therefore, it’s impossible to provide a summary of such a section. To generate the requested summary, please provide the relevant text from the research paper’s “Future Directions” section.
More visual insights#
More on figures

🔼 This figure illustrates the data curation pipeline used to create the CamVid-30K dataset. The pipeline consists of two main stages: camera pose estimation and object motion estimation. Camera pose estimation starts by using Structure-from-Motion (SfM) on masked images to reconstruct 3D point clouds from the static elements in the scene. This process leverages masks that highlight the static areas. Next, relative depth is estimated, aligned with the sparse depth obtained from SfM, and used to project the tracking keypoints onto consecutive frames. Object motion estimation involves identifying moving objects, calculating their motion field in the 2D video frames using keypoint tracking. The motion field helps determine the true object motion, removing static scenes from the data, and finally resulting in the CamVid-30K dataset.
read the caption
Figure 2: The pipeline for CamVid-30K data curation, including (a) camera pose estimation and (b) object motion estimation. We first leverage mask-based SfM (masks are overlayed to images in (a) for visualization) to estimate camera pose and reconstruct 3D point clouds of static parts. Then relative depth is aligned with the sparse depth and project the tracking keypoints to consecutive frame for object motion estimation.

🔼 Figure 3 illustrates object motion estimation using motion strength, a metric multiplied by 100 for visualization. The left panel shows a scenario where a girl is dancing while the camera also moves; this results in a relatively high motion strength value. The right panel presents a case where the camera zooms in on a static object. Here, the motion strength is significantly lower, as the object itself is not moving, despite camera movement.
read the caption
Figure 3: Examples for object motion estimation. The motion strength is multiplied by 100. In the first example, the girl is dancing, together with the camera moving. In the second example, the camera is zooming in (red rectangle for better illustration) but the object is static. In this case, the motion strength is much smaller.

🔼 This figure illustrates the architecture of the GenXD model, a unified framework for generating 3D and 4D scenes from various input conditions. The core of the model is a masked latent conditioned diffusion model, which processes both camera pose information (represented as a colorful map) and image content (as a binary map) to produce 3D and 4D outputs. The model incorporates multiview-temporal modules that effectively separate camera and object movements within the scene and combine the spatial and temporal information via alpha-fusing, allowing for consistent generation of dynamic scenes across multiple viewpoints.
read the caption
Figure 4: The framework of Gen𝒳𝒳\mathcal{X}caligraphic_XD. We leverage mask latent conditioned diffusion model to generate 3D and 4D samples with both camera (colorful map) and image (binary map) conditions. In addition, multiview-temporal modules together with α𝛼\alphaitalic_α-fusing are proposed to effectively disentangle and fuse multiview and temporal information.

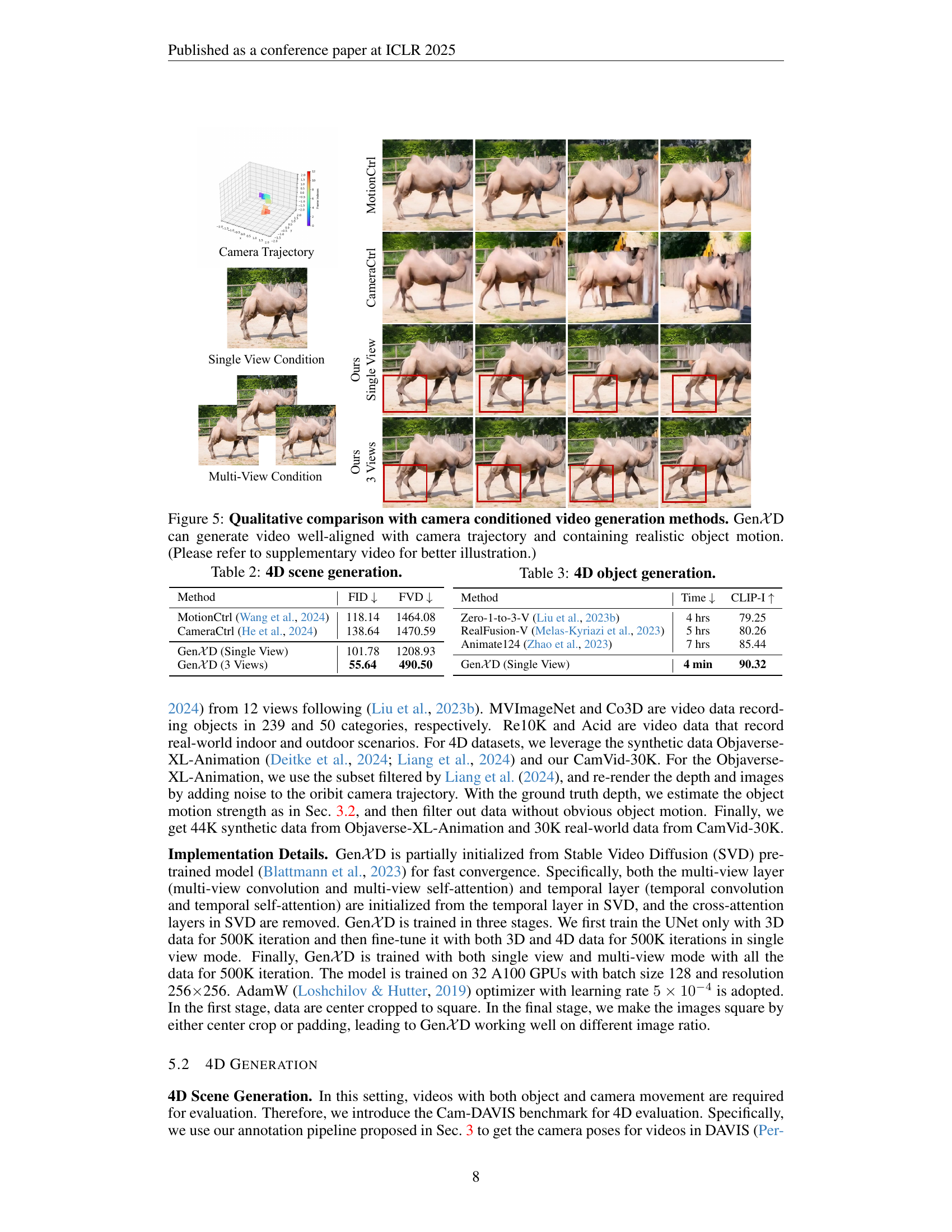
🔼 Figure 5 presents a qualitative comparison of GenXD against other camera-conditioned video generation methods (CameraCtrl and MotionCtrl). It showcases GenXD’s ability to generate videos where the object motion is realistic and aligns well with the camera’s trajectory. The figure visually demonstrates GenXD’s superior performance in handling both camera movement and object motion simultaneously, resulting in more natural and coherent video sequences compared to the other methods. The caption encourages viewers to consult the supplementary video for a more detailed comparison.
read the caption
Figure 5: Qualitative comparison with camera conditioned video generation methods. Gen𝒳𝒳\mathcal{X}caligraphic_XD can generate video well-aligned with camera trajectory and containing realistic object motion. (Please refer to supplementary video for better illustration.)

🔼 This table presents a quantitative comparison of different methods for 4D scene generation. It shows the Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD) scores for several methods, including MotionCtrl, CameraCtrl, Animate124, and GenXD (both single-view and multi-view). Lower FID and FVD scores indicate better performance. The results demonstrate the superior performance of GenXD, particularly in the multi-view setting, compared to existing state-of-the-art methods.
read the caption
Table 2: 4D scene generation.

🔼 This table presents a quantitative comparison of different methods for 4D object generation. It compares the methods across two metrics: generation time and CLIP-I (a measure of image quality). The methods being compared include several existing 4D object generation approaches as well as the authors’ proposed method, GenXD, in both single-view and multi-view configurations. This allows for a quantitative assessment of GenXD’s performance compared to state-of-the-art methods.
read the caption
Table 3: 4D object generation.

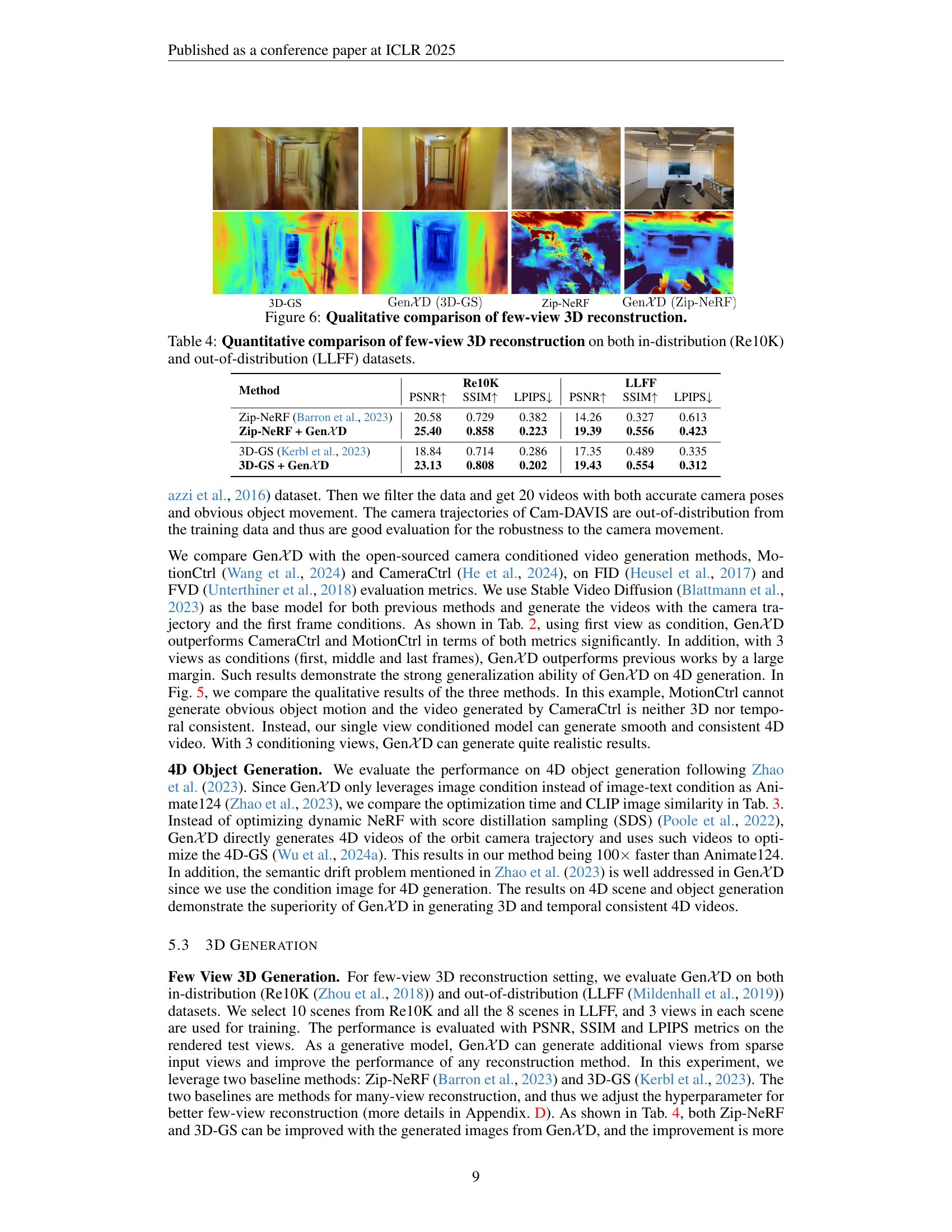
🔼 This figure displays a qualitative comparison of 3D reconstruction results from various methods using only a few input views. It visually demonstrates the differences in reconstruction quality achieved by different approaches, showcasing the impact of limited input data on the resulting 3D models. The image showcases several methods’ performance on the task, illustrating how different techniques might handle the challenges of reconstructing a complete 3D scene from sparse viewpoints.
read the caption
Figure 6: Qualitative comparison of few-view 3D reconstruction.

🔼 This figure displays a qualitative evaluation of how the ‘motion strength’ parameter affects the results of 3D and 4D generation. It showcases the effect of varying motion strength on the generated videos, demonstrating the controllability offered by this parameter. Different levels of motion strength are compared across several generated video sequences, showing how the intensity of motion changes as motion strength increases. The videos generated with varied motion strength show the varying degrees of movement of the objects within the scene, ranging from almost static to intense motion. Reference to a supplementary video is provided for detailed visual understanding.
read the caption
Figure 7: Qualitative evaluation on the influence of motion strength. (Please refer to supplementary video for better illustration.)

🔼 Figure 8 presents a visualization of 4D videos generated using the GenXD model. The figure showcases several examples, each featuring a sequence of frames illustrating the dynamic evolution of a scene over time. Due to the limitations of a static image format, it is highly recommended to refer to the supplementary video provided in the paper for a complete and more effective illustration of the generated 4D videos. The supplementary video allows for dynamic viewing of the generated content.
read the caption
Figure 8: The visualization of the generated 4D videos. (Please refer to supplementary video for better illustration.)
More on tables
| Method | FID ↓ | FVD ↓ |
|---|---|---|
| MotionCtrl Wang et al. (2024) | 118.14 | 1464.08 |
| CameraCtrl He et al. (2024) | 138.64 | 1470.59 |
| GenXD (Single View) | 101.78 | 1208.93 |
| GenXD (3 Views) | 55.64 | 490.50 |
🔼 This table presents a quantitative comparison of the performance of few-view 3D reconstruction methods on two datasets: Re10K (in-distribution) and LLFF (out-of-distribution). It shows the PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity) scores for each method on each dataset. Higher PSNR and SSIM scores indicate better reconstruction quality, while lower LPIPS scores indicate that the reconstructed images are perceptually more similar to the ground truth. The comparison allows for assessment of how well the methods generalize to unseen data.
read the caption
Table 4: Quantitative comparison of few-view 3D reconstruction on both in-distribution (Re10K) and out-of-distribution (LLFF) datasets.
| Method | Time ↓ | CLIP-I ↑ |
|---|---|---|
| Zero-1-to-3-V Liu et al. (2023b) | 4 hrs | 79.25 |
| RealFusion-V Melas-Kyriazi et al. (2023) | 5 hrs | 80.26 |
| Animate124 Zhao et al. (2023) | 7 hrs | 85.44 |
| Gen𝒳D (Single View) | 4 min | 90.32 |
🔼 This table presents the results of ablation studies conducted to evaluate the effectiveness of the motion disentanglement module in the GenXD model. The ablation studies assess the impact of removing the motion disentanglement component on the model’s performance in generating both 3D and 4D scenes, specifically examining metrics like PSNR, SSIM, LPIPS, FID, and FVD across different datasets (Cam-DAVIS and Re10K). The results help quantify the contribution of the motion disentanglement technique to the overall quality of generated images and videos.
read the caption
Table 5: Ablation studies on motion disentangle.
| Method | Re10K PSNR↑ | Re10K SSIM↑ | Re10K LPIPS↓ | LLFF PSNR↑ | LLFF SSIM↑ | LLFF LPIPS↓ |
|---|---|---|---|---|---|---|
| Zip-NeRF [Barron et al. (2023)] | 20.58 | 0.729 | 0.382 | 14.26 | 0.327 | 0.613 |
| Zip-NeRF + GenXD | 25.40 | 0.858 | 0.223 | 19.39 | 0.556 | 0.423 |
| 3D-GS [Kerbl et al. (2023)] | 18.84 | 0.714 | 0.286 | 17.35 | 0.489 | 0.335 |
| 3D-GS + GenXD | 23.13 | 0.808 | 0.202 | 19.43 | 0.554 | 0.312 |
🔼 This table presents a quantitative comparison of different methods for generating 3D models from a single image. The comparison is based on examples from the Wang & Shi (2023) paper and uses the CLIP-I (Image-text similarity) metric to evaluate the quality of the generated 3D models. It shows the model type (3D or 3D&4D), the generation time in minutes, and the CLIP-I score for each method, allowing for a direct comparison of performance across different approaches.
read the caption
Table 6: Quantitative comparison of image-to-3D generation on examples from Wang & Shi (2023).
| Method | Re10K PSNR ↑ | Re10K SSIM ↑ | Re10K LPIPS ↓ | LLFF PSNR ↑ | LLFF SSIM ↑ | LLFF LPIPS ↓ | Cam-DAVIS FID ↓ | Cam-DAVIS FVD ↓ |
|---|---|---|---|---|---|---|---|---|
| w.o. Motion Disentangle | 20.75 | 0.635 | 0.362 | 16.89 | 0.397 | 0.560 | 122.73 | 1488.47 |
| GenXD | 22.96 | 0.774 | 0.341 | 17.94 | 0.463 | 0.546 | 101.78 | 1208.93 |
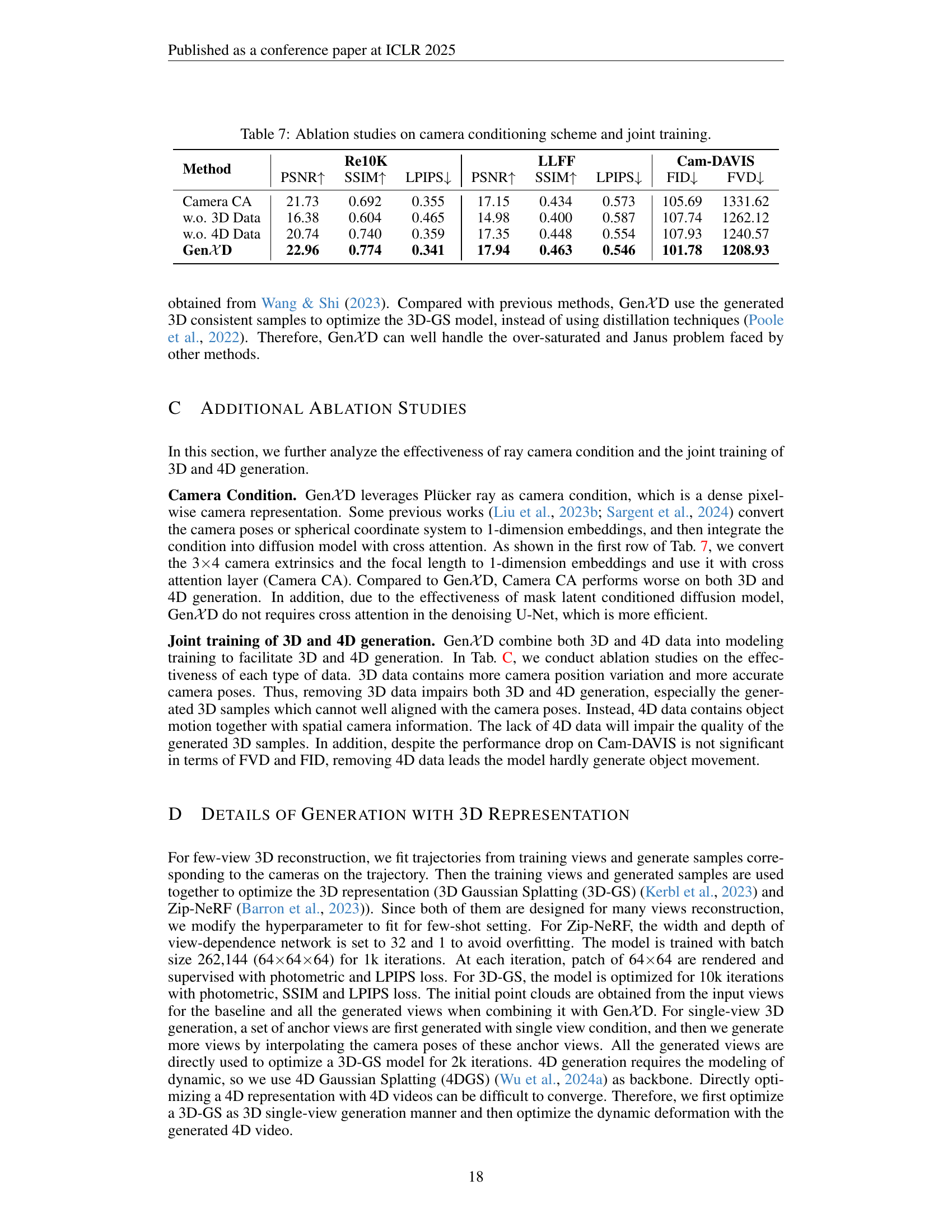
🔼 This table presents the results of ablation experiments conducted to evaluate the impact of different design choices within the GenXD model on its performance. Specifically, it examines the effectiveness of using camera poses as conditions and the effect of jointly training the model on both 3D and 4D data. The metrics used to assess performance include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Fréchet Inception Distance (FID), and Kinetic Fréchet Inception Distance (K-FID) on the Re10k and LLFF datasets and the Cam-DAVIS benchmark.
read the caption
Table 7: Ablation studies on camera conditioning scheme and joint training.
Full paper#