↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current LLM web agents heavily rely on costly proprietary APIs, while open LLMs lack decision-making capabilities. This paper introduces WEBRL, a novel framework addressing this issue by training high-performing web agents using open LLMs. WEBRL tackles challenges like limited training tasks and sparse feedback through a self-evolving curriculum that generates new tasks from failed attempts, a robust reward model, and adaptive learning strategies.
WEBRL successfully transforms open Llama-3.1 and GLM-4 models into proficient web agents. Its performance surpasses proprietary LLMs like GPT-4-Turbo and achieves state-of-the-art results on the WebArena-Lite benchmark. This work demonstrates WEBRL’s effectiveness in bridging the gap between open and proprietary LLM-based web agents, making autonomous web interactions more accessible and powerful.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs and web agents. It bridges the gap between open and proprietary LLMs for web-based tasks, opening avenues for more accessible and powerful autonomous systems. Its novel self-evolving curriculum and adaptive learning strategies offer significant improvements to the current state-of-the-art and inspire future work in online reinforcement learning.
Visual Insights#

🔼 Figure 1a presents a comparison of success rates achieved by various LLMs on WebArena-Lite. It showcases the performance gap between proprietary LLMs (like GPT-4-Turbo and GPT-40) and open-source LLMs (such as GLM-4 and Llama-3) on several representative websites. The figure visually demonstrates the significant performance improvement achieved by enhancing open-source LLMs (specifically GLM-4) with the WEBRL framework, surpassing even the proprietary LLMs in success rate on multiple websites.
read the caption
((a))
| Models | #Params | Gitlab | CMS | Map | OSS | Avg. SR | |
|---|---|---|---|---|---|---|---|
| Proprietary LLMs | |||||||
| GPT-4-Turbo | N/A | 10.5 | 16.7 | 14.3 | 36.7 | 13.3 | 17.6 |
| GPT-4o | N/A | 10.5 | 10.0 | 20.0 | 20.0 | 11.1 | 13.9 |
| AWM + GPT-4-0613* [2024] | N/A | 50.9 | 31.8 | 29.1 | 43.3 | 30.8 | 35.5 |
| WebPilot + GPT-4o* [2024f] | N/A | 65.1 | 39.4 | 24.7 | 33.9 | 36.9 | 37.2 |
| Open-sourced LLMs | |||||||
| AutoWebGLM [2024] | 6B | 9.4 | 15.0 | 28.6 | 24.8 | 17.1 | 18.2 |
| GLM-4-Chat [2024] | 9B | 5.3 | 10.0 | 6.7 | 3.3 | 6.7 | 6.1 |
| GLM-4 + SFT (BC) | 9B | 47.4 | 13.3 | 31.4 | 23.3 | 13.3 | 22.4 |
| GLM-4 + Filtered BC | 9B | 52.6 | 10.0 | 31.4 | 26.7 | 20.0 | 24.8 |
| GLM-4 + AWR [2019] | 9B | 52.6 | 16.7 | 34.3 | 30.0 | 22.2 | 27.9 |
| GLM-4 + DigiRL [2024] | 9B | 63.2 | 30.0 | 34.3 | 26.7 | 26.7 | 31.5 |
| GLM-4 + WebRL (ours) | 9B | 57.9 | 50.0 | 48.6 | 36.7 | 37.8 | 43.0 |
| Llama3.1-Instruct [2024] | 8B | 0.0 | 3.3 | 2.9 | 3.3 | 11.1 | 4.8 |
| Llama3.1 + SFT (BC) | 8B | 36.8 | 6.7 | 20.0 | 33.3 | 17.8 | 20.6 |
| Llama3.1 + Filtered BC | 8B | 52.6 | 20.0 | 31.4 | 23.3 | 8.9 | 23.0 |
| Llama3.1 + AWR [2019] | 8B | 57.9 | 26.7 | 31.4 | 26.7 | 17.8 | 28.5 |
| Llama3.1 + DigiRL [2024] | 8B | 57.9 | 26.7 | 37.1 | 33.3 | 17.8 | 30.3 |
| Llama3.1 + WebRL (ours) | 8B | 63.2 | 46.7 | 54.3 | 36.7 | 31.1 | 42.4 |
| Llama3.1-Instruct [2024] | 70B | 10.5 | 16.7 | 17.1 | 20.0 | 4.4 | 12.7 |
| Llama3.1 + SFT (BC) | 70B | 52.6 | 20.0 | 20.0 | 26.7 | 13.3 | 23.0 |
| Llama3.1 + WebRL (ours) | 70B | 78.9 | 50.0 | 54.3 | 40.0 | 44.4 | 49.1 |
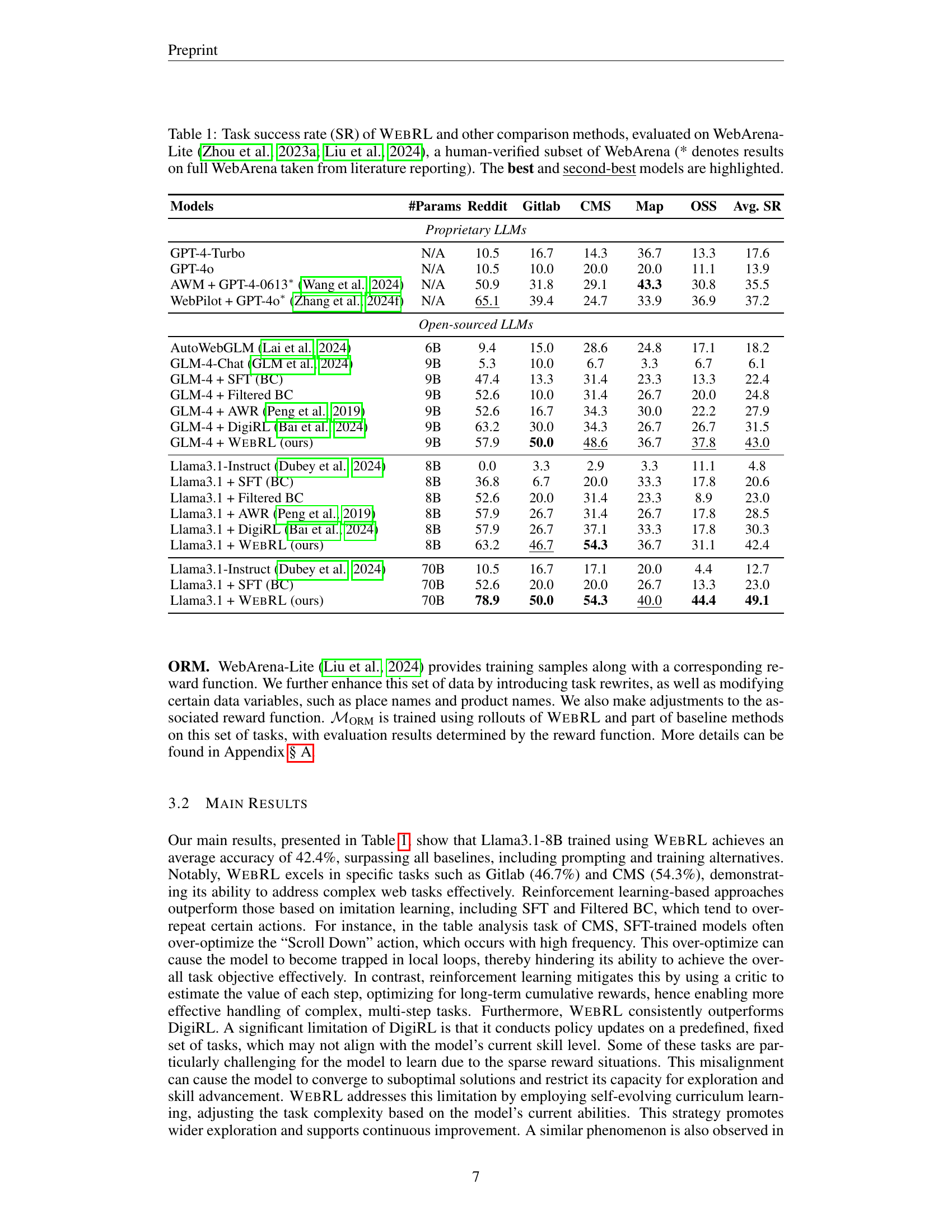
🔼 This table presents a comparison of the task success rate (SR) achieved by different Large Language Models (LLMs) on the WebArena-Lite benchmark. WebArena-Lite is a human-verified subset of the larger WebArena dataset, focusing on web-based tasks. The models compared include both open-source LLMs (e.g., Llama-3.1, GLM-4) and proprietary LLMs (e.g., GPT-4-Turbo, GPT-40). The table highlights the significant performance improvements gained by using the WebRL framework to train open-source LLMs for web-based tasks. Results are broken down by individual website within WebArena-Lite (Reddit, GitLab, CMS, Map, and OSS) and an average SR across all websites. Models marked with an asterisk (*) used data from the full WebArena dataset.
read the caption
Table 1: Task success rate (SR) of WebRL and other comparison methods, evaluated on WebArena-Lite (Zhou et al., 2023a; Liu et al., 2024), a human-verified subset of WebArena (* denotes results on full WebArena taken from literature reporting). The best and second-best models are highlighted.
In-depth insights#
Online Curriculum RL#
The research paper section on “Online Curriculum RL” introduces WEBRL, a novel framework for training large language model (LLM) web agents. It directly tackles the challenges of limited training data, sparse feedback, and policy drift inherent in online reinforcement learning. WEBRL innovatively uses a self-evolving curriculum that generates new tasks from past failures, improving data efficiency. A robust outcome-supervised reward model (ORM) addresses sparse feedback by automatically evaluating task success. Finally, adaptive reinforcement learning strategies, including a KL-divergence constraint on policy updates and an actor confidence-filtered experience replay buffer, ensure stable and continuous improvement, preventing catastrophic forgetting. This approach significantly enhances the performance of open-source LLMs as web agents, bridging the gap with proprietary models.
WebAgent Training#
The research paper section on ‘WebAgent Training’ details a novel framework, WEBRL, designed to overcome challenges in training effective web agents using open LLMs. WEBRL employs self-evolving online curriculum reinforcement learning, addressing limitations like scarce training data and sparse feedback. A key innovation is its self-evolving curriculum, which generates new tasks from past failures, dynamically adjusting difficulty. The framework also incorporates a robust outcome-supervised reward model (ORM) to accurately assess task success. To ensure continual improvement, adaptive reinforcement learning strategies and a KL-divergence constraint prevent policy distribution drift. Experimental results demonstrate WEBRL’s superior performance compared to state-of-the-art methods, significantly bridging the gap between open and proprietary LLM-based web agents.
LLM-based Agents#
The research paper section on “LLM-based Agents” explores the capabilities and limitations of large language models (LLMs) in autonomous agent applications, specifically focusing on web-based tasks. It highlights the significant potential of LLMs as agents but notes the heavy reliance of current systems on expensive proprietary APIs, limiting accessibility. A key challenge identified is the lack of decision-making capabilities in open-source LLMs, hindering their effectiveness in complex web interactions. The authors emphasize the need for innovative solutions to overcome the scarcity of training tasks, sparse feedback signals, and policy distribution drift, inherent in online LLM agent training. This section sets the stage for introducing the proposed framework as a solution to these challenges, paving the way for creating more powerful and accessible autonomous web agents based on open-source LLMs.
Open LLM Success#
The provided text does not contain a heading titled ‘Open LLM Success’. Therefore, a summary cannot be generated. To provide a summary, please provide the relevant text from the research paper.
Future of WebRL#
The provided text does not contain a section specifically titled ‘Future of WebRL’. Therefore, it’s impossible to generate a summary of such a heading. To provide a meaningful summary, please provide the relevant text from the research paper’s ‘Future of WebRL’ section. A thoughtful and in-depth analysis requires access to the original content. Once the text is provided, I can deliver a summary that is approximately 800 characters long and highlights key insights with bold formatting as requested.
More visual insights#
More on figures

🔼 The figure shows the performance changes of the GLM-4-9B model when trained using WEBRL and several baseline methods on the WebArena-Lite benchmark. It highlights the significant improvement in success rate achieved by WEBRL compared to other approaches, such as GLM-4-SFT, GLM-4+AWR, GLM-4+Filtered BC, and GLM-4+DigiRL. The chart visually represents the differences in performance across these methods, demonstrating the effectiveness of the WEBRL framework in enhancing the capabilities of open-source LLMs for web-based tasks.
read the caption
((b))

🔼 Figure 1 presents a comparison of the performance of various large language models (LLMs) as web agents on the WebArena-Lite benchmark. Subfigure (a) shows a bar chart comparing the success rates of several proprietary LLMs (like GPT-4-Turbo and GPT-40) against open-source LLMs (such as GLM-4 and Llama) enhanced with WebRL. This highlights that GLM-4-9B with WebRL surpasses all others, demonstrating the effectiveness of the WebRL training framework. Subfigure (b) provides a radar chart illustrating the performance improvements of GLM-4-9B specifically when trained with WebRL compared to various baseline methods (other training approaches for the same LLM) across five different websites within the WebArena-Lite environment. The chart clearly shows WebRL significantly boosts GLM-4-9B’s performance.
read the caption
Figure 1: (a) Compared with all proprietary and open-sourced LLMs, GLM-4-9B with WebRL achieves the best results. (b) The performance of GLM-4-9B on WebArena-Lite (Zhou et al., 2023a; Liu et al., 2024), trained using WebRL, shows significant improvement over other baselines across all five evaluated websites.

🔼 WebRL is a novel framework for training large language model (LLM) web agents using online reinforcement learning. It addresses three key challenges: the scarcity of training tasks, sparse feedback, and policy distribution drift. The figure illustrates WebRL’s self-evolving curriculum, where new tasks are dynamically generated from past failures. This curriculum adapts to the agent’s current skill level and uses a robust outcome-supervised reward model. Adaptive reinforcement learning strategies, including a KL-divergence constrained policy update, and an experience replay buffer with actor confidence filtering further enhance continuous improvements. The diagram shows the flow of information and interactions between components like the agent, the environment, a reward model, and a replay buffer, highlighting the iterative nature of the self-evolving curriculum and the continuous learning process.
read the caption
Figure 2: Overview of WebRL. WebRL is a self-evolving online curriculum reinforcement learning framework for LLM-based web agents, yielding consistent continual improvements throughout the iterative self-evolution.

🔼 This figure presents a comparison of different error types across various methods for training large language model (LLM) web agents. The error types analyzed include failures to recover from errors, getting stuck during task execution, stopping at the wrong web page, and failing to even make a reasonable attempt at the task. The methods compared include WebRL (the proposed method), and several baselines such as Supervised Fine-tuning (SFT), Filtered Behavior Cloning (Filtered BC), Advantage Weighted Regression (AWR), and DigiRL. By visualizing the distribution of these error types for each method, the figure helps to illustrate the relative strengths and weaknesses of different training approaches in terms of robustness and efficiency in completing web-based tasks.
read the caption
Figure 3: Distribution analysis of error types for WebRL and baseline methods.

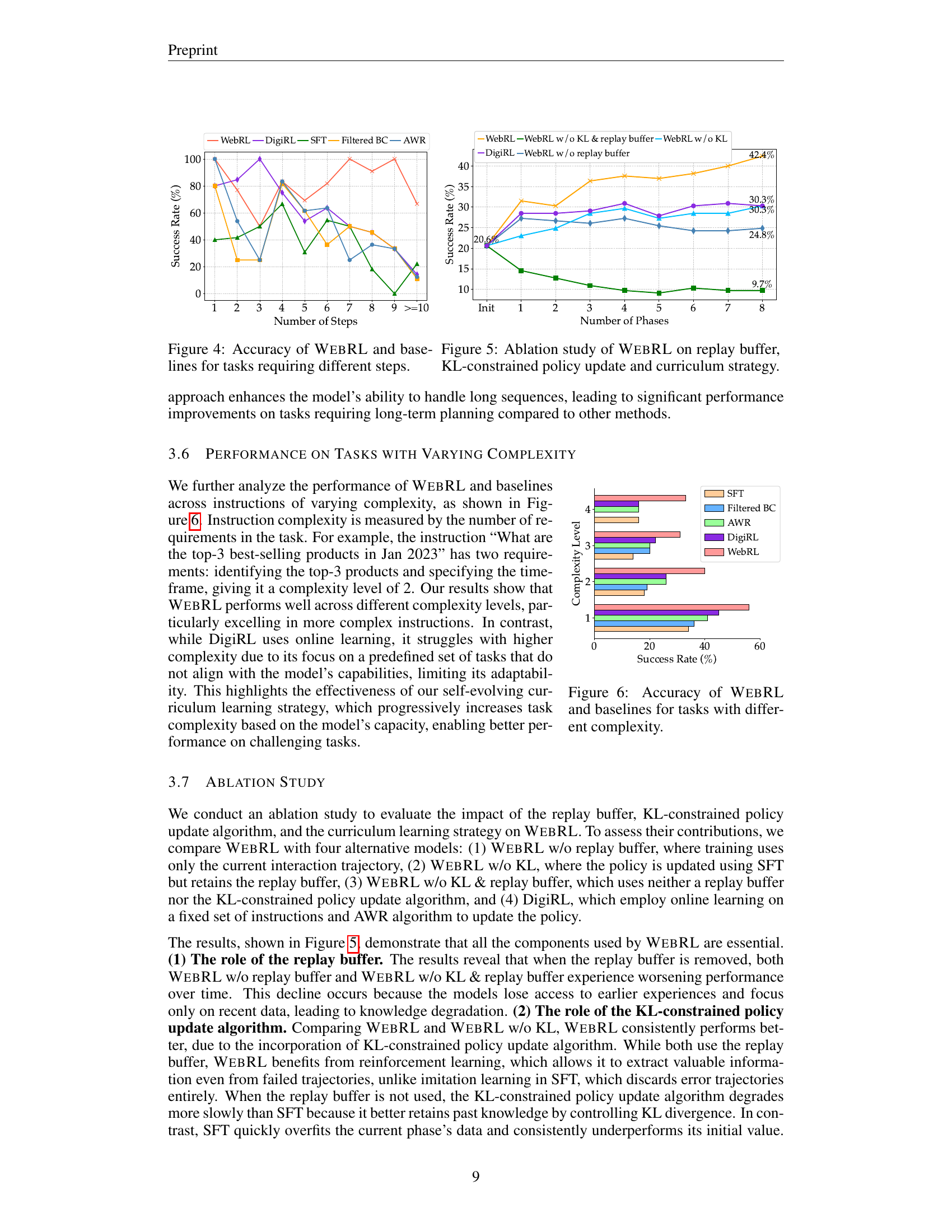
🔼 Figure 4 presents a graph comparing the performance of WEBRL and several baseline methods across tasks with varying step requirements. The x-axis represents the number of steps needed to complete the tasks, while the y-axis indicates the success rate (accuracy) of each method. The graph shows that WEBRL significantly outperforms baselines (SFT, Filtered BC, AWR, DigiRL) as the number of steps increases, highlighting its effectiveness in handling more complex, multi-step tasks. Baselines struggle more as task complexity increases, while WEBRL’s performance remains robust.
read the caption
Figure 4: Accuracy of WebRL and baselines for tasks requiring different steps.

🔼 This ablation study analyzes the impact of three key components of the WebRL framework on its overall performance: the replay buffer, the KL-constrained policy update, and the curriculum learning strategy. The figure likely shows a comparison of WebRL’s performance against versions of the model where one or more of these components have been removed, illustrating their individual and combined contributions to the model’s success rate in completing online web tasks. This helps determine the relative importance of each component.
read the caption
Figure 5: Ablation study of WebRL on replay buffer, KL-constrained policy update and curriculum strategy.

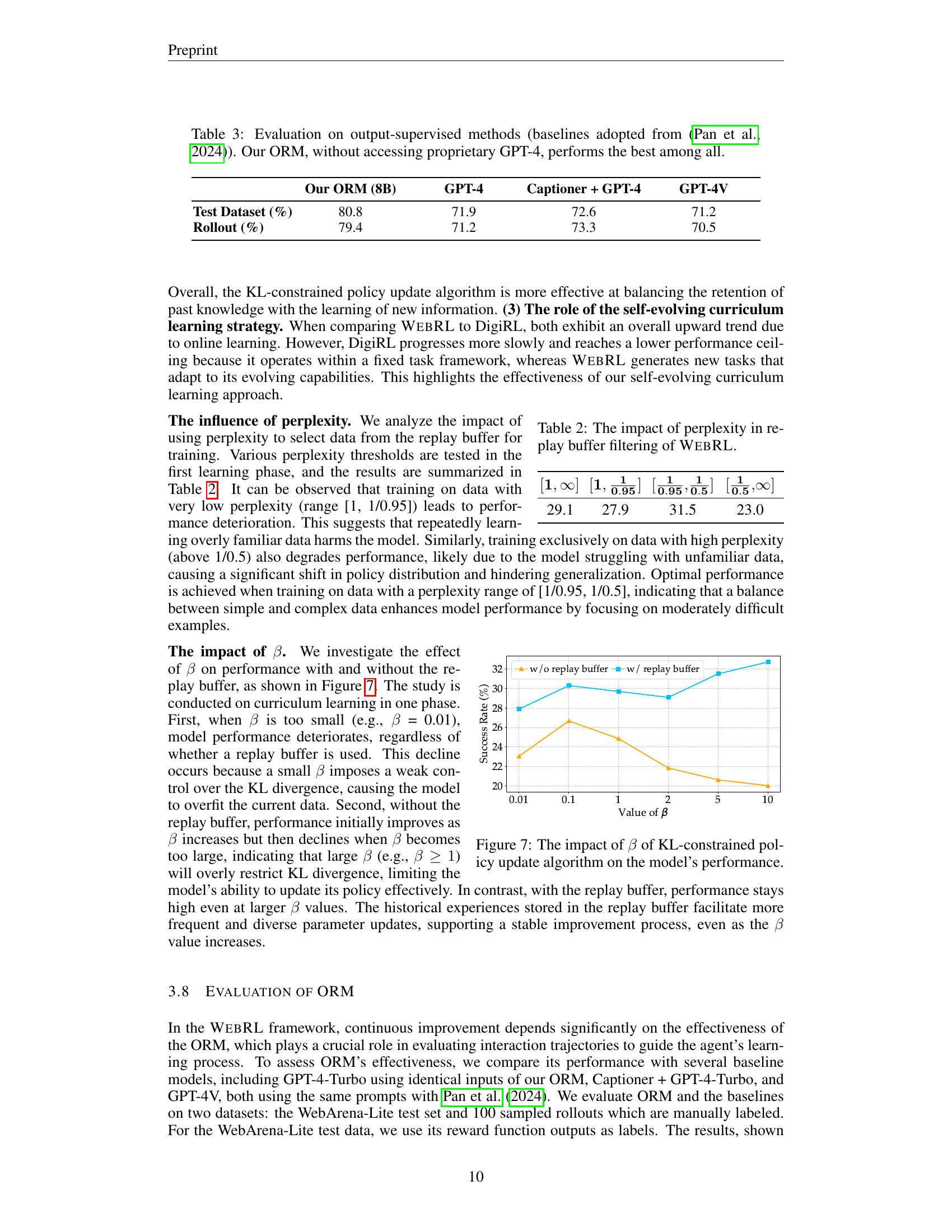
🔼 This figure presents a bar chart comparing the performance of WebRL against several baseline methods across tasks of varying complexity. Task complexity is defined by the number of requirements within each task’s instruction. The chart shows the success rate (accuracy) for each method at different complexity levels (e.g., tasks with one requirement, two requirements, etc.). This visual representation helps to understand how well each method handles tasks with increasing complexity. The purpose is to demonstrate WebRL’s superior performance and ability to scale across various levels of task difficulty.
read the caption
Figure 6: Accuracy of WebRL and baselines for tasks with different complexity.

🔼 Figure 7 shows the effects of the KL-divergence constraint’s strength (β) on the model’s performance in the WEBRL framework. It compares performance with and without the experience replay buffer. The results indicate that an optimal β value exists; too small a value leads to overfitting, while too large a value restricts the model’s ability to adapt. The presence of the replay buffer mitigates the negative effects of large β values, maintaining high performance even with stronger constraints.
read the caption
Figure 7: The impact of β𝛽\betaitalic_β of KL-constrained policy update algorithm on the model’s performance.

🔼 Figure 8 showcases examples of instructions generated by WEBRL’s self-evolving curriculum learning strategy across different phases. It illustrates how the difficulty and specificity of instructions progressively increase as the training process advances. The early phases feature simpler tasks, and as the agent learns, the instructions become more complex and nuanced, reflecting the growing capabilities of the model.
read the caption
Figure 8: Examples of instructions generated in different phases under self-evolving curriculum learning.

🔼 Figure 9 illustrates the data flow and format in the WebRL framework and its baselines. The input to the agent consists of three parts: the original task instruction (shown in green), the history of actions the agent has already taken (in blue), and the HTML content of the current web page (in orange). The agent processes this information and outputs the next action it intends to perform on the webpage (in red). This figure clearly shows the input and output structure used for training and evaluation in the WebRL system and how information is passed between different components of the framework.
read the caption
Figure 9: The input and output format of WebRL and baselines, where the input is composed of task instruction (in green), action history (in blue), and HTML of the current webpage (in orange). The output (in red) is the action taken on the current webpage.

🔼 This figure displays the performance of a Llama 3.1-8B language model trained using the WebRL method across various websites. The x-axis represents the training phase number, and the y-axis shows the success rate (percentage of tasks successfully completed) on each website. Each line represents a different website: Reddit, GitLab, CMS, Map, and OSS. The graph illustrates the model’s performance improvement over training phases and the variation in success rates among different websites.
read the caption
Figure 10: Performance variation curves of Llama3.1-8B on each website under WebRL training.

🔼 Figure 11 displays the simple prompt used for several baseline models in the paper. The prompt instructs the model to act as a web browsing agent, following instructions provided in a Python-like pseudocode format. It defines specific actions (Click, Type, Search, etc.) and arguments for those actions, including element IDs from the HTML. The prompt emphasizes brevity, only allowing one line of code at a time and avoiding loops, and also notes specific instructions like using specific element selectors and avoiding the address bar. The intent is to create a standardized interaction with the models, facilitating comparison of their web browsing abilities.
read the caption
Figure 11: The simple prompt employed in baselines.

🔼 Figure 12 shows the prompts used to generate new instructions for the self-evolving curriculum learning strategy employed in WEBRL. The prompt instructs the model to create diverse, realistic, and appropriately challenging tasks within the same domain as a given example task. It emphasizes avoiding the use of specific keywords from the example task and maintaining consistency in variable names (place names, product names, etc.). The goal is to produce tasks that incrementally increase in complexity, pushing the agent’s capabilities and promoting continual improvement.
read the caption
Figure 12: Prompts for instruction generation.

🔼 The figure displays prompts used for the Outcome-Supervised Reward Model (ORM). The ORM is a crucial component of WEBRL, which automatically evaluates the agent’s trajectory and provides reward signals to guide learning. The prompts include the user instruction, the agent’s action history, and the final state of the webpage. The ORM’s role is to determine whether the agent successfully completed the task based on the provided information. The prompts are formatted to be input into a large language model (LLM) to generate a binary “YES” or “NO” response, indicating success or failure.
read the caption
Figure 13: Prompts for ℳORMsubscriptℳORM\mathcal{M}_{\text{ORM}}caligraphic_M start_POSTSUBSCRIPT ORM end_POSTSUBSCRIPT to assess the completion of Instructions.

🔼 This figure showcases a sequence of screenshots illustrating the WEBRL agent’s interaction with a CMS website. Each screenshot captures a step in a task, where the agent successfully navigates the website, selects elements, inputs data, and ultimately achieves the task of retrieving specific information. The screenshots are accompanied by corresponding actions and notes from the agent, demonstrating its ability to carry out complex web interactions, such as identifying specific elements on the page, providing inputs in text fields, and interpreting web page structure and elements to complete the task.
read the caption
Figure 14: CMS Example.

🔼 This figure shows a sequence of screenshots from a GitLab web page interaction. The agent is performing a task that involves finding who has access to a specific repository. The screenshots illustrate the agent’s actions (clicks, searches, etc.) and how it navigates the webpage to find the necessary information and complete the task. Each screenshot shows the agent’s interaction, the state of the webpage, and the action(s) performed by the agent in that step.
read the caption
Figure 15: Gitlab Example.

🔼 This figure showcases an example of WEBRL’s application on OpenStreetMap (Map) from the WebArena-Lite benchmark. It visually depicts a sequence of interactions, starting with the user’s task instruction and progressing through several steps of agent actions (clicks, typing, etc.) and intermediate web page states. The visual representation highlights how WEBRL guides the LLM agent to successfully complete the complex task of comparing travel times between two locations using different transportation modes (driving and walking) on OpenStreetMap. The final step displays the agent’s successful completion of the task and the resulting information extracted from the map.
read the caption
Figure 16: MAP Example.

🔼 This figure showcases a sequence of screenshots illustrating the steps taken by the agent to successfully answer a query on Reddit. The agent interacts with Reddit’s interface to access the Showerthoughts forum, locate a specific post, and analyze comments for their upvote/downvote ratios, eventually providing a numerical response to the user’s query. The example demonstrates the agent’s ability to navigate a complex website and perform specific actions to extract the requested information.
read the caption
Figure 17: Reddit Example.
More on tables
| [1,∞] | [1,1/0.95] | [1/0.95,1/0.5] | [1/0.5,∞] |
|---|---|---|---|
| 29.1 | 27.9 | 31.5 | 23.0 |
🔼 This table shows how different perplexity thresholds for filtering data in the replay buffer affect the performance of the WebRL model. Perplexity is a measure of how surprising or unexpected the data is to the model. Lower perplexity indicates the data is more familiar to the model, while higher perplexity indicates the data is more unexpected. The table demonstrates the optimal perplexity range for effective model training, highlighting the trade-off between using overly familiar data and overly unexpected data. Using a narrow range of perplexity values results in the best model performance.
read the caption
Table 2: The impact of perplexity in replay buffer filtering of WebRL.
| Test Dataset (%) | Our ORM (8B) | GPT-4 | Captioner + GPT-4 | GPT-4V |
|---|---|---|---|---|
| 80.8 | 71.9 | 72.6 | 71.2 | |
| Rollout (%) | 79.4 | 71.2 | 73.3 | 70.5 |
🔼 This table presents a comparison of the performance of different outcome-supervised reward models on a specific task. The models being compared include those using proprietary GPT-4 models as well as a new model proposed by the authors (Our ORM). The key finding is that the authors’ model outperforms all others without needing access to the costly GPT-4 APIs, highlighting its efficiency and effectiveness.
read the caption
Table 3: Evaluation on output-supervised methods (baselines adopted from (Pan et al., 2024)). Our ORM, without accessing proprietary GPT-4, performs the best among all.
| Method | Hyperparameter | Value |
|---|---|---|
| SFT | learning rate | 1e-5 |
| lr scheduler type | cosine | |
| warmup ratio | 0.1 | |
| batch size | 128 | |
| training epoch | 1 | |
| cutoff length | 16384 | |
| Filtered BC | learning rate | 1e-6 |
| lr scheduler type | constant | |
| batch size | 128 | |
| training epoch | 1 | |
| cutoff length | 16384 | |
| filtering threshold | 70th percentile | |
| AWR | actor learning rate | 1e-6 |
| actor lr scheduler type | constant | |
| critic learning rate | 1e-6 | |
| critic lr scheduler type | constant | |
| batch size | 128 | |
| discount factor | 0.9 | |
| actor training epoch | 1 | |
| critic training epoch | 1 | |
| DigiRL | actor learning rate | 1e-6 |
| actor lr scheduler type | constant | |
| critic learning rate | 1e-6 | |
| critic lr scheduler type | constant | |
| instruction value function lr | 1e-6 | |
| instruction value function lr scheduler type | constant | |
| batch size | 128 | |
| discount factor | 0.9 | |
| actor training epoch | 1 | |
| critic training epoch | 1 | |
| instruction value function epoch | 1 | |
| rollout temperature | 1 | |
| replay buffer size | 100000 | |
| WebRL | actor learning rate | 1e-6 |
| actor lr scheduler type | constant | |
| critic learning rate | 1e-6 | |
| critic lr scheduler type | constant | |
| batch size | 128 | |
| discount factor | 0.9 | |
| actor training epoch | 1 | |
| critic training epoch | 1 | |
| rollout temperature | 1 |
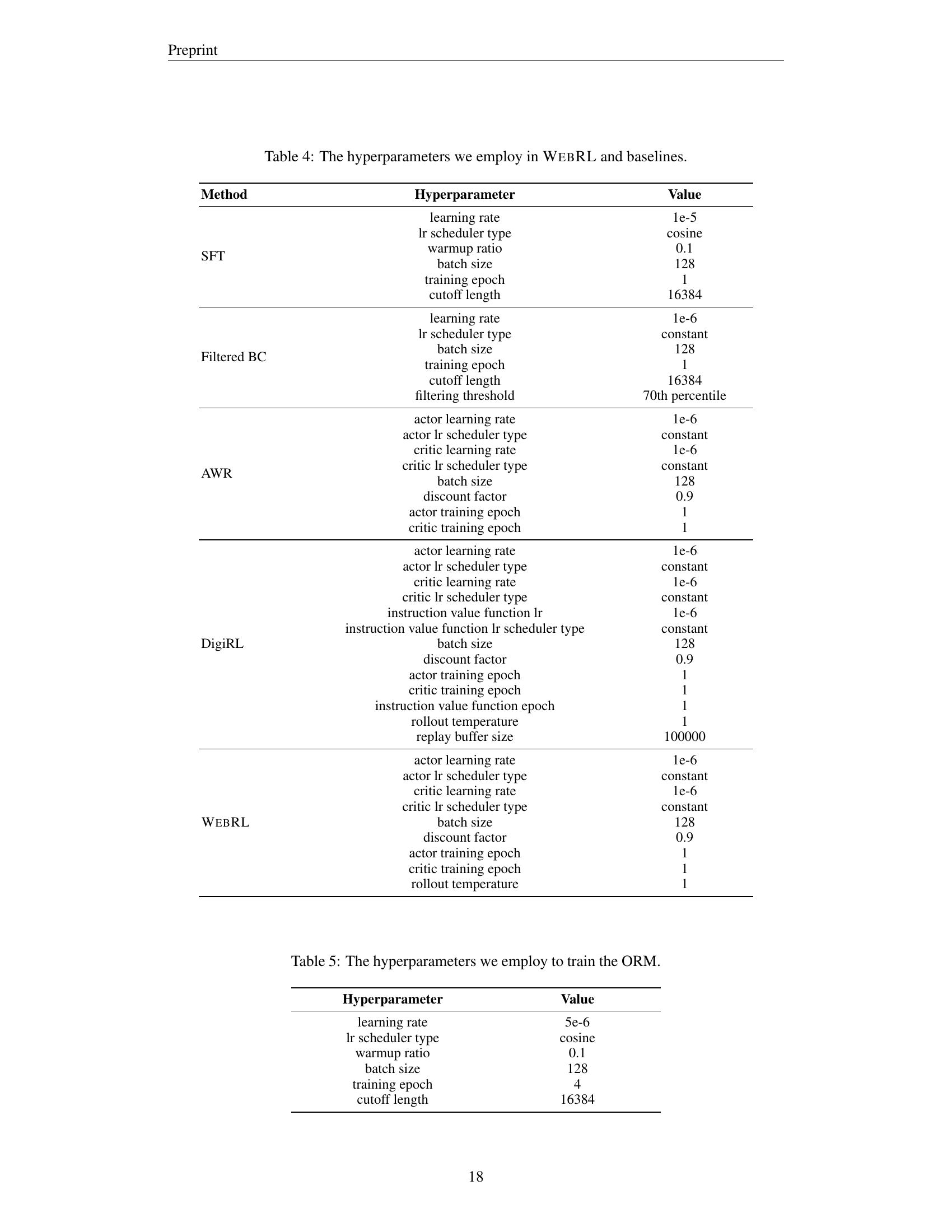
🔼 This table details the hyperparameter settings used for training the WebRL model and several baseline models. It lists the specific hyperparameters (e.g., learning rate, scheduler type, batch size, etc.) and their corresponding values for each of the training methods: Supervised Fine-Tuning (SFT), Filtered Behavior Cloning (Filtered BC), Advantage Weighted Regression (AWR), DigiRL, and WebRL. This information allows for comparison of the training procedures used to generate the results and analysis of their impact on model performance.
read the caption
Table 4: The hyperparameters we employ in WebRL and baselines.
| Hyperparameter | Value |
|---|---|
| learning rate | 5e-6 |
| lr scheduler type | cosine |
| warmup ratio | 0.1 |
| batch size | 128 |
| training epoch | 4 |
| cutoff length | 16384 |
🔼 This table details the hyperparameters used during the training of the Outcome-Supervised Reward Model (ORM). The ORM is a crucial component of the WEBRL framework, responsible for evaluating the success or failure of an agent’s actions in completing web-based tasks. The hyperparameters shown influence various aspects of the training process, such as the learning rate, optimizer, batch size, and the number of training epochs.
read the caption
Table 5: The hyperparameters we employ to train the ORM.
Full paper#