↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-image models struggle with complex prompts, especially those describing intricate spatial relationships between multiple objects. Existing methods often require retraining or rely on additional modules. This limits their flexibility and efficiency.
This paper introduces a training-free solution called Regional Prompting FLUX. It cleverly manipulates the attention mechanism within the diffusion transformer model, allowing for fine-grained control over image generation using regional prompts and masks. This method achieves high-quality compositional images without needing additional training or modules, improving both efficiency and flexibility.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel training-free method for enhancing the compositional generation capabilities of diffusion transformers like FLUX. It addresses the current limitations of text-to-image models in handling complex spatial layouts and nuanced prompts, offering a flexible and efficient solution. The research opens new avenues for improving text-to-image synthesis and inspires further exploration of attention manipulation techniques in diffusion models. The training-free nature is particularly significant, as it reduces computational costs and widens accessibility.
Visual Insights#

🔼 This figure illustrates the architecture of the proposed Regional Prompting FLUX method for fine-grained compositional text-to-image generation. It contrasts a naive approach with the authors’ method. The naive attempt shows a single global prompt being used to generate the entire image. The Regional Prompting FLUX method, however, breaks down the user-defined or LLM-generated prompt into multiple regional prompts, each paired with a corresponding mask specifying the area of the image it affects. These regional prompts and masks allow for finer control over the composition of the generated image, enabling the creation of complex scenes with distinct regions possessing different characteristics. The process involves enriching the prompt using LLM to extract key features and concepts, then using a FLUX diffusion transformer to generate the image through a process that combines global and regional prompts.
read the caption
Figure 1: Overview of our method. Given user-defined or LLM-generated regional prompt-mask pairs, we can effectively achieve fine-grained compositional text-to-image generation.
In-depth insights#
Regional Prompting#
The research paper introduces a novel training-free method for enhancing compositional text-to-image generation in diffusion transformers, specifically focusing on the FLUX model. Regional prompting is achieved by manipulating the attention mechanism to incorporate user-defined or LLM-generated regional prompt-mask pairs. This allows for fine-grained control over different image regions, enabling the generation of complex scenes with diverse attributes and spatial relationships. The method cleverly utilizes a region-aware attention manipulation module to selectively control cross and self-attention within the model. Key advantages include its training-free nature and applicability to various similar model architectures, making it a flexible and efficient approach. While the method demonstrates impressive results, it acknowledges challenges in handling numerous regions, where balancing aesthetic coherence with precise regional control becomes increasingly complex.
DiT Attention Control#
The research paper section on “DiT Attention Control” details a training-free method for enhancing compositional image generation in Diffusion Transformers (DiTs). The core approach involves manipulating the attention mechanism within the DiT architecture to achieve fine-grained control over image generation based on user-defined or LLM-generated regional prompts and masks. This region-aware attention manipulation carefully modifies cross and self-attention weights to ensure that each region’s text prompt appropriately influences only its corresponding image area. The technique elegantly combines these modified attention maps to seamlessly integrate regional features with the global image context, resulting in images that adhere to the desired spatial composition. A key strength is the training-free nature, making it adaptable to various DiT models. However, the process involves careful tuning of hyperparameters, particularly as the number of regions increases, to balance regional fidelity with overall image coherence. The method shows promise in achieving complex compositional generation, offering a valuable strategy for enhancing the capabilities of DiT models.
Training-Free Method#
The research paper introduces a training-free method for enhancing compositional text-to-image generation in diffusion transformers, specifically focusing on the FLUX model. The core of the approach involves region-aware attention manipulation, which modulates attention maps to align image regions with corresponding textual descriptions. This is achieved without additional training by constructing a unified attention mask, combining cross and self-attention masks, to guide the attention mechanism in a region-specific manner. The process allows for the precise generation of multiple image regions according to user-defined textual prompts and masks, leading to fine-grained compositional generation. A key aspect of the method is its flexibility, as it does not require model retraining or additional data, making it highly adaptable to different models. The approach uses an attention manipulation module to control the attention between image features and regional prompts, ensuring that each region is accurately represented in the generated image. Furthermore, the method leverages a balancing coefficient to optimize aesthetic fidelity and prompt adherence, resulting in images that are both visually appealing and consistent with the textual descriptions.
Compositional Generation#
The section on “Compositional Generation” delves into methods for creating images with precise spatial layouts, acknowledging that current prompt adherence, while improved, still falls short of real-world demands. The discussion highlights two main categories of approaches: training-based and training-free. Training-based methods often involve adding modules to handle regional masks or bounding boxes, requiring additional training. In contrast, training-free methods manipulate attention mechanisms to guide object placement and generation within specified regions without needing retraining. Examples include using attention modulation to direct object appearance according to layout guidance or leveraging a multi-modal large language model (MLLM) for decomposition into simpler sub-tasks. These methods offer advantages in flexibility and ease of application. The overall challenge emphasized is achieving precise control over spatial relationships while maintaining visual coherence and semantic accuracy.
Limitations and Future#
The research paper’s ‘Limitations and Future’ section likely discusses challenges in scaling the proposed training-free regional prompting method to handle a large number of regions. Increased complexity in tuning hyperparameters like base ratio, injection steps, and blocks becomes a significant issue as the number of regions grows. This leads to trade-offs between maintaining semantic alignment with the prompt and ensuring visual coherence across different regions. Future work may focus on improving the robustness and ease of use of the method by addressing this scaling limitation. Developing more sophisticated strategies for managing regional interactions and optimizing parameter tuning for complex scenes is crucial. This could involve incorporating advanced techniques in attention manipulation or exploring alternative model architectures that are better suited for handling intricate spatial layouts. The section might also suggest further exploration of different LLM architectures for prompt generation and investigation into integrating the approach with other generative models.
More visual insights#
More on figures

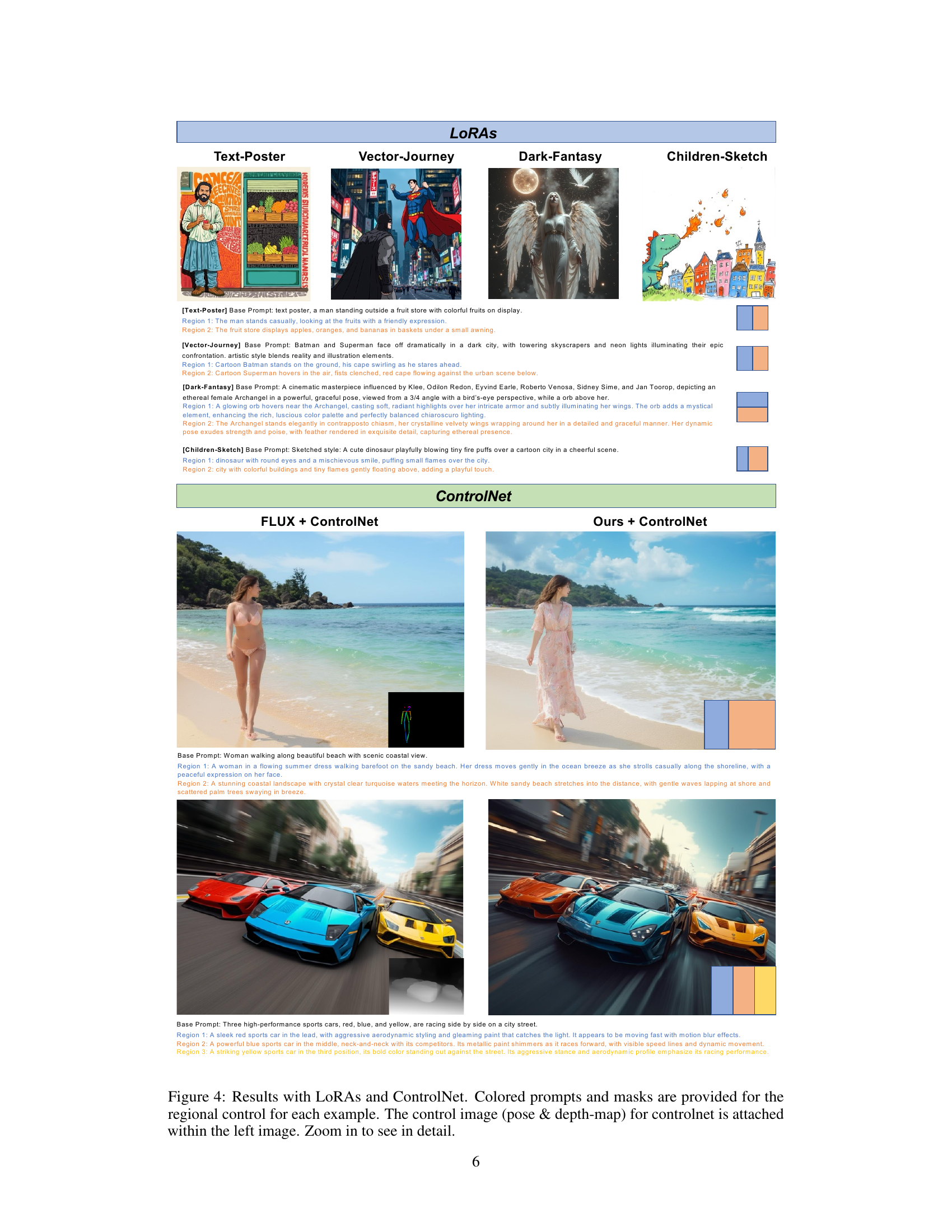
🔼 Figure 2 showcases the results of the proposed method on several example images. Each image is generated using regional prompts, meaning different parts of the image are controlled by different text descriptions. The simplified regional prompts shown in the figure are color-coded according to their corresponding regions in the image layout. However, the authors note that the actual regional prompts used during generation are more detailed than what is shown in the figure. Each example demonstrates how fine-grained control is possible, generating different parts of a single image based on various detailed descriptions. The examples shown include varied scenes and styles from surreal landscapes to more realistic depictions.
read the caption
Figure 2: Main results. Simplified regional prompts are colored according to the layout mask. In practice, we input more detailed regional prompt about each region.

🔼 Figure 3 details the Region-Aware Attention Manipulation module, a key component of the proposed method. The figure illustrates how the unified self-attention mechanism within the FLUX model is decomposed into four distinct attention processes: cross-attention from image features to text embeddings, cross-attention from text embeddings to image features, and two self-attention processes (one for image features and one for text embeddings). These individual attention mechanisms are each modified using specific masks. Finally, these individual attention masks are combined to create a unified attention mask which is then used to modulate the standard attention process, thereby achieving fine-grained control over how different regions of the image interact with their corresponding textual descriptions. This approach enables the model to effectively generate images that accurately reflect the spatial and semantic relationships specified in complex prompts.
read the caption
Figure 3: Illustration of our Region-Aware Attention Manipulation module. The unified self-attention in FLUX can be broken down into four parts: cross-attention from image to text, cross-attention from text to image, and self-attention between image. After calculating the attention manipulation mask, we merge them to get the overall attention mask that is later fed into the attention calculation process.

🔼 Figure 4 showcases the results of applying the proposed regional prompting method in conjunction with LoRAs (Low-Rank Adaptation) and ControlNet. Each example demonstrates the effects of regional prompting on the generated images. Colored prompts and masks highlight how different image regions correspond to specific textual descriptions. The left-most image in each set includes an inset showing the pose and depth map used as ControlNet input. The caption encourages closer examination of the images for details.
read the caption
Figure 4: Results with LoRAs and ControlNet. Colored prompts and masks are provided for the regional control for each example. The control image (pose & depth-map) for controlnet is attached within the left image. Zoom in to see in detail.

🔼 This ablation study investigates the impact of three key hyperparameters on the performance of the regional prompting method: the base ratio (β), the number of control steps (T), and the number of control blocks (B). Each hyperparameter is varied systematically across several settings while keeping the others constant. The results showcase how different values of β, T, and B affect the balance between maintaining regional distinctions and ensuring global image coherence. The figure visually demonstrates the impact of these hyperparameters on the final generated image, highlighting trade-offs between precise regional control and overall image quality.
read the caption
Figure 5: Ablation results with base ratio β𝛽\betaitalic_β, control steps T𝑇Titalic_T and control blocks B𝐵Bitalic_B.

🔼 Figure 6 presents a comparison of inference speed and GPU memory consumption among three different methods for image generation: the standard FLUX.1-dev model, FLUX.1-dev enhanced with RPG-based regional control, and the proposed method. The x-axis shows the number of masks (regions) used in the image generation, while the y-axis represents inference time in seconds. The bars also indicate the GPU memory used during inference. This comparison demonstrates the efficiency gains of the proposed method over other approaches, particularly as the number of regions increases. The graph provides insights into the computational resource requirements of each approach for generating images with varying levels of compositional complexity.
read the caption
Figure 6: Inference speed and gpu memory consumption comparison with standard FLUX.1-dev, FLUX equipped with RPG-based regional control, and our method.
Full paper#