↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating high-fidelity videos, especially long ones, is computationally expensive. Recent advancements in Diffusion Transformers (DiTs) have improved video quality but increased the computational burden. This necessitates faster inference methods without sacrificing video quality. Existing solutions often involve retraining models or require significant architecture changes, limiting their wide adoption.
AdaCache, a training-free method, accelerates video DiTs by adaptively caching computations based on video content. It introduces a caching schedule tailored to each video, and Motion Regularization, controlling computation allocation based on motion content. AdaCache showed significant speedups (up to 4.7x) in experiments across several DiT baselines, without affecting video quality. This plug-and-play approach makes AdaCache easily adaptable to existing models and represents a significant advancement in efficient video generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AdaCache, a novel, training-free method for accelerating video generation using diffusion transformers. This addresses a critical bottleneck in current video generation research—the high computational cost—opening new avenues for efficient long-video generation and commercial applications. The adaptive caching strategy is particularly relevant, given the variability in video complexity, and its plug-and-play nature makes it readily applicable to existing models.
Visual Insights#

🔼 This figure demonstrates the effectiveness of Adaptive Caching (AdaCache) in accelerating video generation. It presents a qualitative comparison of video clips generated using Open-Sora, a baseline Diffusion Transformer (DiT), and Open-Sora enhanced with AdaCache. The comparison shows that AdaCache significantly speeds up the generation process (4.7 times faster) while maintaining comparable video quality. Both the Open-Sora and AdaCache generated videos are 720p resolution and 2 seconds long. The figure also highlights that AdaCache adapts the number of computational steps required for each video, demonstrating its efficiency. The prompts used to generate these videos are provided in the supplementary material.
read the caption
Figure 1: Effectiveness of Adaptive Caching: We show a qualitative comparison of AdaCache (right) applied on top of Open-Sora (Zheng et al., 2024) (left), a baseline video DiT. Here, we consider generating 720p - 2s video clips, and report VBench (Huang et al., 2024) quality and average latency (on a single A100 GPU) on the benchmark prompts from Open-Sora gallery. AdaCache generates videos significantly faster (i.e., 4.7×\times× speedup) with a comparable quality. Also, the number of computed steps varies for each video. Best-viewed with zoom-in. Prompts given in supplementary.
| Method | VBench (%) ↑ | PSNR ↑ | LPIPS ↓ | SSIM ↑ | FLOPs (T) | Latency (s) | Speedup |
|---|---|---|---|---|---|---|---|
| Open-Sora (Zheng et al., 2024) | 79.22 | – | – | – | 3230.24 | 54.02 | 1.00× |
- Δ-DiT (Chen et al., 2024d) | 78.21 | 11.91 | 0.5692 | 0.4811 | 3166.47 | – | –
- T-GATE (Zhang et al., 2024a) | 77.61 | 15.50 | 0.3495 | 0.6760 | 2818.40 | 49.11 | 1.10×
- PAB-fast (Zhao et al., 2024c) | 76.95 | 23.58 | 0.1743 | 0.8220 | 2558.25 | 40.23 | 1.34×
- PAB-slow (Zhao et al., 2024c) | 78.51 | 27.04 | 0.0925 | 0.8847 | 2657.70 | 44.93 | 1.20×
- AdaCache-fast | 79.39 | 24.92 | 0.0981 | 0.8375 | 1331.97 | 24.16 | 2.24×
- AdaCache-fast (w/ MoReg) | 79.48 | 25.78 | 0.0867 | 0.8530 | 1383.66 | 25.71 | 2.10×
- AdaCache-slow | 79.66 | 29.97 | 0.0456 | 0.9085 | 2195.50 | 37.01 | 1.46× Open-Sora-Plan (Lab and etc., 2024) | 80.39 | – | – | – | 12032.40 | 129.67 | 1.00×
- Δ-DiT (Chen et al., 2024d) | 77.55 | 13.85 | 0.5388 | 0.3736 | 12027.72 | – | –
- T-GATE (Zhang et al., 2024a) | 80.15 | 18.32 | 0.3066 | 0.6219 | 10663.32 | 113.75 | 1.14×
- PAB-fast (Zhao et al., 2024c) | 71.81 | 15.47 | 0.5499 | 0.4717 | 8551.26 | 89.56 | 1.45×
- PAB-slow (Zhao et al., 2024c) | 80.30 | 18.80 | 0.3059 | 0.6550 | 9276.57 | 98.50 | 1.32×
- AdaCache-fast | 75.83 | 13.53 | 0.5465 | 0.4309 | 3283.60 | 35.04 | 3.70×
- AdaCache-fast (w/ MoReg) | 79.30 | 17.69 | 0.3745 | 0.6147 | 3473.68 | 36.77 | 3.53×
- AdaCache-slow | 80.50 | 22.98 | 0.1737 | 0.7910 | 4983.30 | 58.88 | 2.20× Latte (Ma et al., 2024b) | 77.40 | – | – | – | 3439.47 | 32.45 | 1.00×
- Δ-DiT (Chen et al., 2024d) | 52.00 | 8.65 | 0.8513 | 0.1078 | 3437.33 | – | –
- T-GATE (Zhang et al., 2024a) | 75.42 | 19.55 | 0.2612 | 0.6927 | 3059.02 | 29.23 | 1.11×
- PAB-fast (Zhao et al., 2024c) | 73.13 | 17.16 | 0.3903 | 0.6421 | 2576.77 | 24.33 | 1.33×
- PAB-slow (Zhao et al., 2024c) | 76.32 | 19.71 | 0.2699 | 0.7014 | 2767.22 | 26.20 | 1.24×
- AdaCache-fast | 76.26 | 17.70 | 0.3522 | 0.6659 | 1010.33 | 11.85 | 2.74×
- AdaCache-fast (w/ MoReg) | 76.47 | 18.16 | 0.3222 | 0.6832 | 1187.31 | 13.20 | 2.46×
- AdaCache-slow | 77.07 | 22.78 | 0.1737 | 0.8030 | 2023.65 | 20.35 | 1.59×
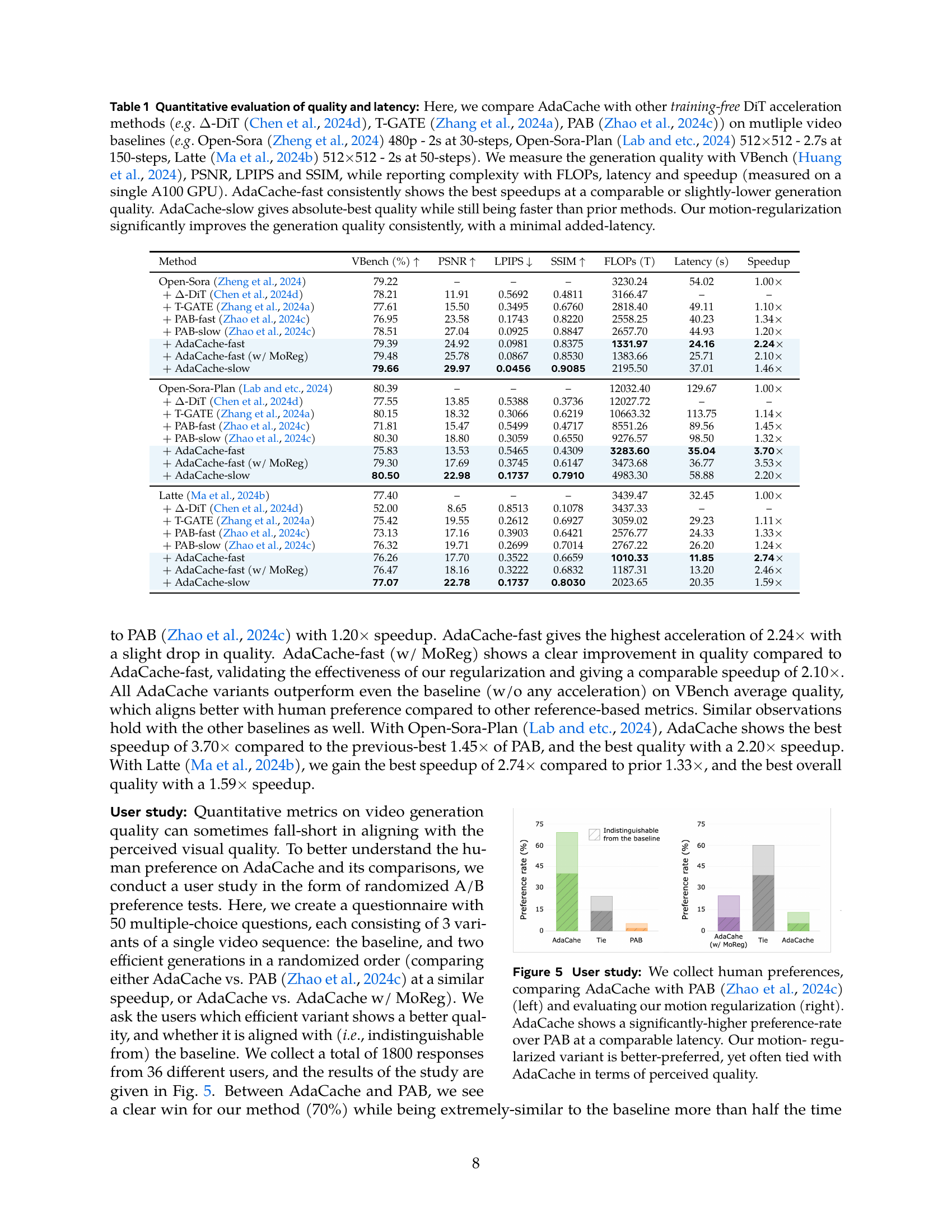
🔼 Table 1 presents a quantitative comparison of AdaCache against other training-free methods for accelerating video Diffusion Transformers (DiTs). Multiple video DiT baselines are evaluated: Open-Sora (480p, 2-second videos, 30 denoising steps), Open-Sora-Plan (512x512, 2.7-second videos, 150 steps), and Latte (512x512, 2-second videos, 50 steps). Generation quality is assessed using VBench, PSNR, LPIPS, and SSIM. Computational complexity is evaluated using FLOPs, latency (measured on a single A100 GPU), and speedup. The results show that AdaCache-fast achieves the best speedups with comparable or slightly lower quality compared to other methods. AdaCache-slow provides the best quality while remaining faster than the alternatives. Finally, the inclusion of motion regularization in AdaCache consistently improves quality with minimal latency increase.
read the caption
Table 1: Quantitative evaluation of quality and latency: Here, we compare AdaCache with other training-free DiT acceleration methods (e.g. ΔΔ\Deltaroman_Δ-DiT (Chen et al., 2024d), T-GATE (Zhang et al., 2024a), PAB (Zhao et al., 2024c)) on mutliple video baselines (e.g. Open-Sora (Zheng et al., 2024) 480p - 2s at 30-steps, Open-Sora-Plan (Lab and etc., 2024) 512×\times×512 - 2.7s at 150-steps, Latte (Ma et al., 2024b) 512×\times×512 - 2s at 50-steps). We measure the generation quality with VBench (Huang et al., 2024), PSNR, LPIPS and SSIM, while reporting complexity with FLOPs, latency and speedup (measured on a single A100 GPU). AdaCache-fast consistently shows the best speedups at a comparable or slightly-lower generation quality. AdaCache-slow gives absolute-best quality while still being faster than prior methods. Our motion-regularization significantly improves the generation quality consistently, with a minimal added-latency.
In-depth insights#
AdaCache: Core Idea#
AdaCache’s core idea centers on accelerating video diffusion transformers without retraining by leveraging the fact that not all videos demand the same computational resources. It does so by selectively caching residual computations within transformer blocks during the diffusion process. A key innovation is the content-dependent caching schedule, which dynamically decides when to recompute based on a distance metric measuring the rate of change between stored and current representations. This adaptive strategy, coupled with Motion Regularization (MoReg) that prioritizes computations for high-motion content, maximizes the quality-latency trade-off, resulting in significant speedups without compromising video quality. Essentially, AdaCache intelligently allocates computational resources based on the complexity of each video sequence, optimizing performance across a wide range of video generation tasks.
MoReg: Motion Focus#
The research paper introduces Motion Regularization (MoReg) to enhance Adaptive Caching, addressing the challenge that video generation quality significantly depends on motion content. MoReg leverages a noisy latent motion score, calculated from residual frame differences to dynamically adjust the caching strategy. Instead of a fixed schedule, computations are allocated proportionally to motion content, caching less and recomputing more frequently for high-motion videos to prevent inconsistencies. This content-aware approach helps avoid issues like artifacts or color inaccuracies often seen in high-speed video generations, maximizing the quality-latency tradeoff. MoReg proves particularly beneficial in high-motion content videos, granting substantial gains in generation quality without sacrificing significant speed.
Empirical Validation#
The provided text does not contain a section or heading explicitly titled ‘Empirical Validation’. Therefore, it’s impossible to provide a summary of such a section. To generate a summary, please provide the relevant text from the PDF’s ‘Empirical Validation’ section.
Multi-GPU Speedups#
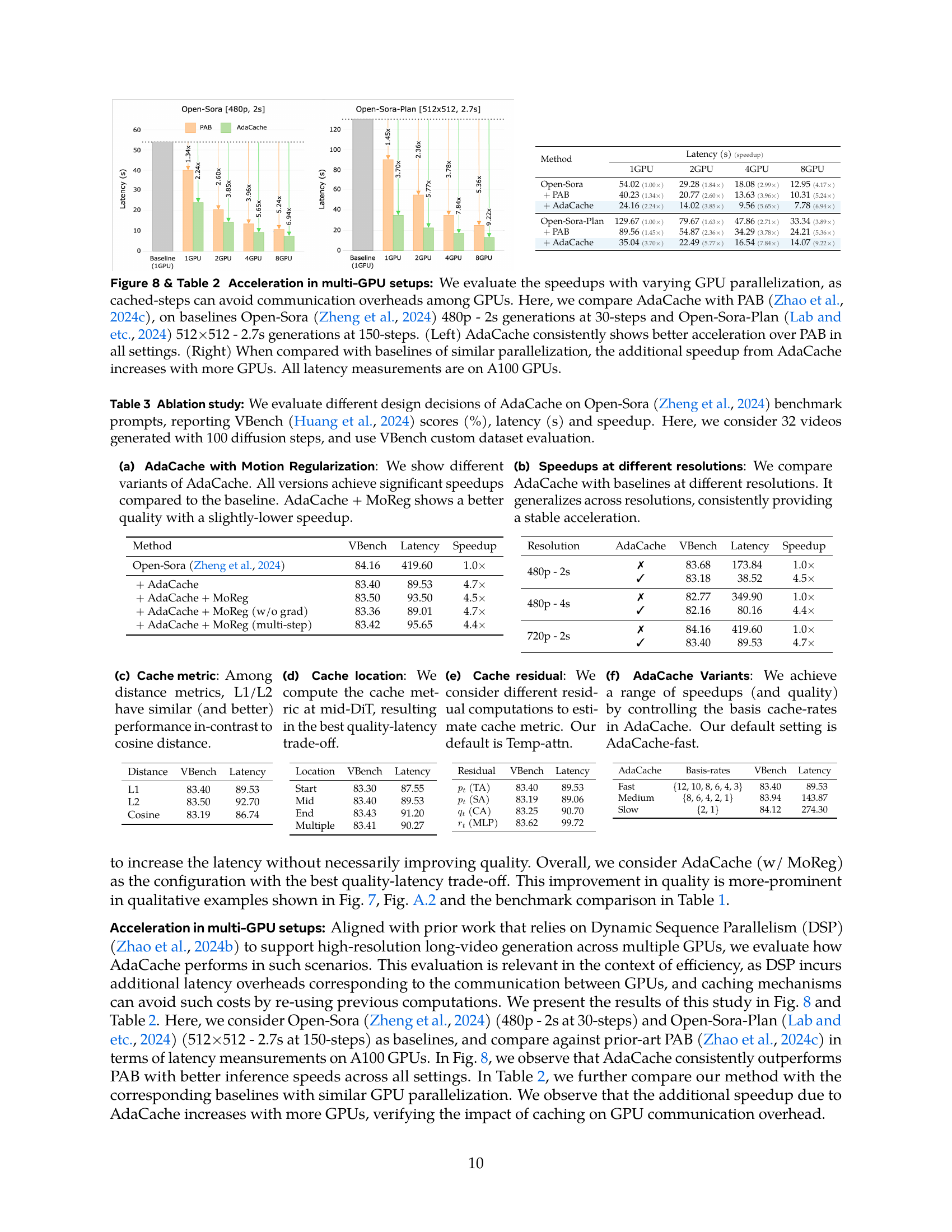
The research explores the impact of AdaCache on multi-GPU setups, aiming for significant speedups in video generation. AdaCache consistently demonstrates superior acceleration compared to the baseline and a prior method (PAB) across various GPU configurations (1, 2, 4, and 8 GPUs). The speed improvements are more pronounced with a higher number of GPUs, suggesting that AdaCache effectively mitigates the communication overhead typically associated with multi-GPU parallelism. This is achieved by reducing redundant computations through the caching mechanism, enabling better scaling efficiency. The results showcase a notable quality-latency trade-off, highlighting AdaCache’s potential for high-performance video generation in resource-rich environments.
Future Work: DiT#
The provided text does not contain a section specifically titled ‘Future Work: DiT’. Therefore, I cannot generate a summary about that heading. To provide the requested summary, please provide the relevant text from the research paper’s ‘Future Work: DiT’ section.
More visual insights#
More on figures

🔼 This figure demonstrates the varying complexity of videos and how this impacts the efficiency of video generation. The left panel shows that reducing the number of diffusion steps during video generation affects different videos differently. Some videos maintain good quality even with fewer steps (robust), while others degrade significantly (fragile). The right panel visualizes the differences in computed representations (features) between consecutive steps in the diffusion process. The significant variability across videos suggests that a fixed computational schedule is inefficient. This observation motivates the use of a content-adaptive method, Adaptive Caching, to optimize the denoising process by tailoring it to the complexity of each individual video.
read the caption
Figure 2: Not all videos are created equal: We show frames from 720p - 2s video generations based on Open-Sora (Zheng et al., 2024). (Left) We try to break each generation by reducing the number of diffusion steps. Interestingly, not all videos have the same break point. Some sequences are extremely robust (e.g. first-two columns), while others break easily. (Right) When we plot the difference between computed representations in subsequent diffusion steps, we see unique variations (Feature distance vs. #steps). If we are to reuse similar representations, it needs to be tailored to each video. Both these observations suggest the need for a content-dependent denoising process, which is the founding motivation of Adaptive Caching. Best-viewed with zoom-in. Prompts given in supplementary.

🔼 This figure demonstrates the impact of computational budget constraints on video generation quality. Different video generation configurations were tested, all with a similar computational cost (latency). This was achieved by varying the number of denoising steps while maintaining a constant number of computed representations (by reusing some computations). The results reveal a substantial variation in the final video quality across these different configurations, highlighting the importance of efficient resource allocation to achieve high-quality video generation.
read the caption
Figure 3: Videos generated at a capped-budget: There exist different configurations for generating videos at an approximately-fixed latency (e.g. having an arbitrary #denoising-steps, yet only computing a fixed #representations and reusing otherwise). We observe a significant variance in quality in such videos. Best-viewed with zoom-in. Prompts given in supplementary.

🔼 Figure 4 illustrates Adaptive Caching, a method for accelerating video generation using Diffusion Transformers (DiTs). The left panel shows the caching process. Residual computations within the DiT’s blocks are selectively cached based on a content-dependent schedule. This schedule is determined by a metric (ct) that quantifies the change between the current and previously computed representations. A larger ct indicates a greater change, leading to less caching and more recomputation. The right panel details the caching strategy within a DiT block, showing only the residuals (skip-connections) are cached and reused. The main video representation (ft+k, ft) is always updated with either a newly computed or a cached residual.
read the caption
Figure 4: Overview of Adaptive Caching: (Left) During the diffusion process, we choose to cache residual computations within selected DiT blocks. The caching schedule is content-dependent, as we decide when to compute the next representation based on a distance metric (ctsubscript𝑐𝑡c_{t}italic_c start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT). This metric measures the rate-of-change from previously-computed (and, stored) representation to the current one, and can be evaluated per-layer or the DiT as-a-whole. Each computed residual can be cached and reused across multiple steps. (Right) We only cache the residuals (i.e., skip-connections) which amount to the actual computations (e.g. spatial-temporal/cross attention, MLP). The iteratively denoised representation (i.e., ft+ksubscript𝑓𝑡𝑘f_{t+k}italic_f start_POSTSUBSCRIPT italic_t + italic_k end_POSTSUBSCRIPT, ftsubscript𝑓𝑡f_{t}italic_f start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT) always gets updated either with computed or cached residuals.

🔼 This figure presents the results of a user study comparing AdaCache and PAB (Zhao et al., 2024c), two training-free video generation acceleration methods. The left side shows the comparison between AdaCache and PAB, demonstrating that AdaCache receives significantly higher preference from users, despite having a similar latency (processing speed). The right side shows a comparison between the standard AdaCache and an enhanced version that includes motion regularization. While the motion-regularized AdaCache is preferred, the difference in preference is not as significant as between AdaCache and PAB; the user often rates them as tied in perceived quality.
read the caption
Figure 5: User study: We collect human preferences, comparing AdaCache with PAB (Zhao et al., 2024c) (left) and evaluating our motion regularization (right). AdaCache shows a significantly-higher preference-rate over PAB at a comparable latency. Our motion- regularized variant is better-preferred, yet often tied with AdaCache in terms of perceived quality.

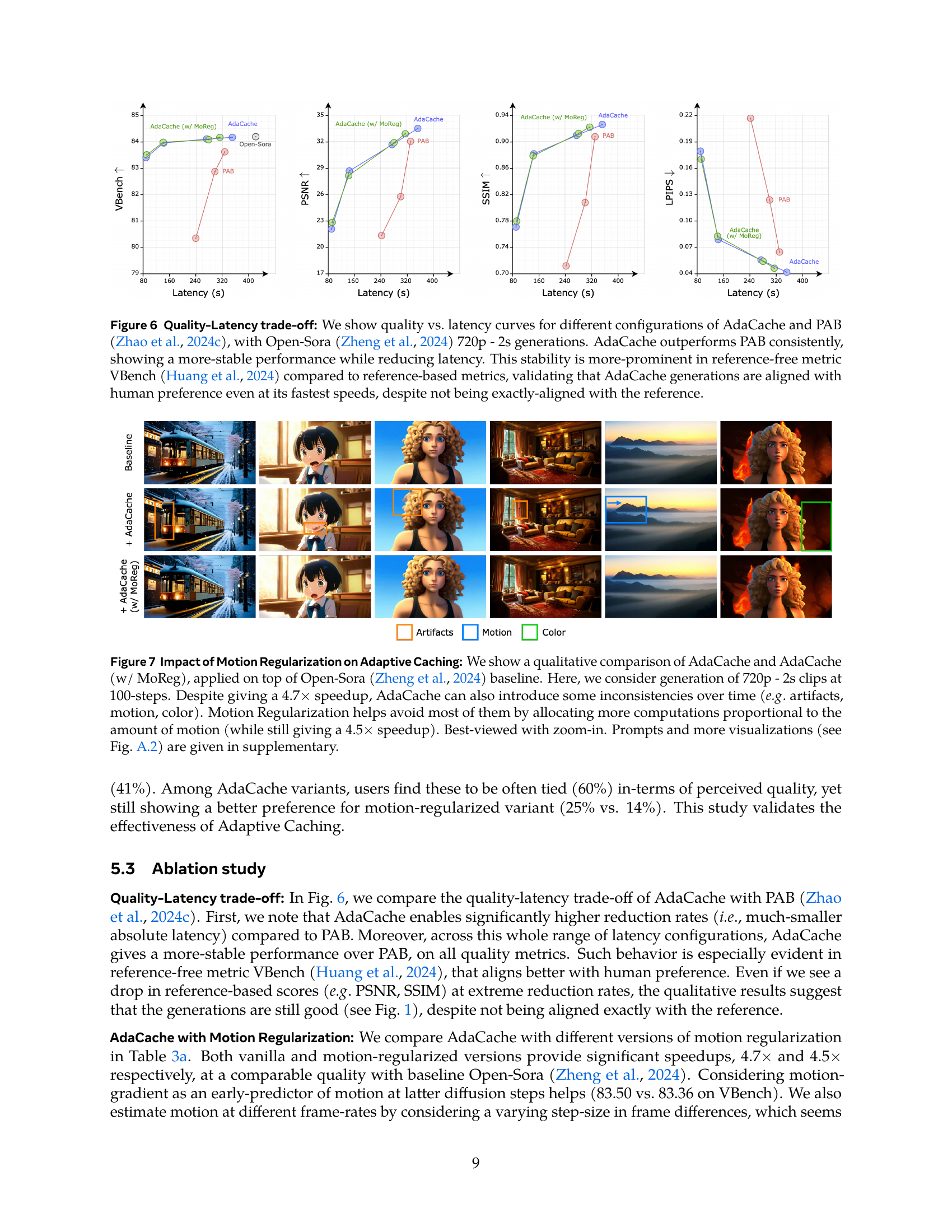
🔼 Figure 6 presents a comparison of AdaCache and PAB (a prior method) in terms of their quality-latency trade-off, using Open-Sora to generate 720p videos of 2 seconds. The graph plots quality metrics (including VBench, a reference-free metric, and reference-based metrics like PSNR, SSIM, and LPIPS) against latency. AdaCache consistently outperforms PAB across various latency levels, showing significantly better quality-latency trade-off. Notably, the stability of AdaCache performance is more noticeable when using the reference-free VBench metric, indicating that AdaCache results align well with human perception of video quality, even at the faster generation speeds, despite not perfectly matching the reference metrics.
read the caption
Figure 6: Quality-Latency trade-off: We show quality vs. latency curves for different configurations of AdaCache and PAB (Zhao et al., 2024c), with Open-Sora (Zheng et al., 2024) 720p - 2s generations. AdaCache outperforms PAB consistently, showing a more-stable performance while reducing latency. This stability is more-prominent in reference-free metric VBench (Huang et al., 2024) compared to reference-based metrics, validating that AdaCache generations are aligned with human preference even at its fastest speeds, despite not being exactly-aligned with the reference.

🔼 This figure compares the performance of AdaCache and AdaCache with Motion Regularization (MoReg) against the baseline Open-Sora model for video generation. It shows that while AdaCache significantly speeds up video generation (4.7x), it can sometimes lead to inconsistencies in terms of artifacts, motion, and color. The addition of MoReg addresses these issues by dynamically allocating more computational resources to video segments with higher motion content, resulting in improved consistency while maintaining a substantial speedup (4.5x). The supplementary materials include additional visualizations and prompts.
read the caption
Figure 7: Impact of Motion Regularization on Adaptive Caching: We show a qualitative comparison of AdaCache and AdaCache (w/ MoReg), applied on top of Open-Sora (Zheng et al., 2024) baseline. Here, we consider generation of 720p - 2s clips at 100-steps. Despite giving a 4.7×\times× speedup, AdaCache can also introduce some inconsistencies over time (e.g. artifacts, motion, color). Motion Regularization helps avoid most of them by allocating more computations proportional to the amount of motion (while still giving a 4.5×\times× speedup). Best-viewed with zoom-in. Prompts and more visualizations (see Fig. A.2) are given in supplementary.

🔼 This figure demonstrates the impact of AdaCache on video generation speed across various GPU configurations. It compares AdaCache’s performance against PAB, another acceleration method. Two video models, Open-Sora and Open-Sora-Plan, are used with different video settings (resolution and frame rate). The left panel shows that AdaCache consistently outperforms PAB in terms of speedup regardless of the number of GPUs. The right panel highlights that the additional speedup provided by AdaCache over the baselines increases as the number of GPUs used increases. All measurements were conducted using A100 GPUs.
read the caption
Figure 8: Acceleration in multi-GPU setups: We evaluate the speedups with varying GPU parallelization, as cached-steps can avoid communication overheads among GPUs. Here, we compare AdaCache with PAB (Zhao et al., 2024c), on baselines Open-Sora (Zheng et al., 2024) 480p - 2s generations at 30-steps and Open-Sora-Plan (Lab and etc., 2024) 512×\times×512 - 2.7s generations at 150-steps. (Left) AdaCache consistently shows better acceleration over PAB in all settings. (Right) When compared with baselines of similar parallelization, the additional speedup from AdaCache increases with more GPUs. All latency measurements are on A100 GPUs.

🔼 This figure shows a qualitative comparison of video generation results using different methods. It visually demonstrates the effectiveness of AdaCache in accelerating video generation while maintaining comparable quality. The left side displays the baseline video generation, and the right side shows the improved results achieved using AdaCache. The image showcases multiple video clips with different scenes and levels of complexity to highlight AdaCache’s performance across various scenarios.
read the caption
(a)

🔼 This figure shows a qualitative comparison of AdaCache and AdaCache with Motion Regularization. The experiments were performed on Open-Sora, generating 720p videos that are 2 seconds long using 100 denoising steps. AdaCache, despite its speedup (4.7x), may introduce inconsistencies in the video. However, incorporating Motion Regularization helps maintain consistency while still providing a speedup of 4.5x. This visualization is designed to highlight the impact of motion regularization on video quality.
read the caption
(b)

🔼 This figure shows the impact of different cache metrics on the quality and latency of video generation. The experiment uses various distance metrics to assess the rate of change between representations in consecutive diffusion steps. It compares the effectiveness of different metrics, showing that L1 and L2 distances yield better results than cosine distance in terms of quality and latency.
read the caption
(c)

🔼 This figure shows the ablation study on the location where the cache metric is computed within the DiT (Diffusion Transformer) model. The metric is used to determine when to re-compute representations (residual computations) and when to reuse cached ones. It compares the effectiveness of computing the metric at different locations within the DiT layers: at the start, in the middle, and at the end. The results demonstrate that computing the metric in the middle of the layers provides similar performance (and often better) compared to computing it at the start or end, indicating a computationally efficient strategy for adaptive caching.
read the caption
(d)
Full paper#