↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating unit tests automatically is a significant challenge in software development due to the high computational cost of training large language models (LLMs). This paper investigates the use of parameter-efficient fine-tuning (PEFT), a technique that fine-tunes only a small subset of a model’s parameters, as a more cost-effective alternative. The research highlights a critical limitation in the current approaches to automate unit test generation, which predominantly use expensive full model fine-tuning methods.
The study compares three popular PEFT methods (LoRA, (IA)³, and Prompt Tuning) against full fine-tuning, using ten LLMs of varying sizes. The results show that PEFT methods can significantly reduce resource needs without sacrificing much accuracy. LoRA shows consistent reliability, often matching full fine-tuning’s performance, while prompt tuning stands out as the most resource-efficient approach, although its performance varied across models. The findings provide valuable insights into choosing the optimal PEFT technique for different scenarios and model sizes in the context of unit test generation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates the effectiveness of parameter-efficient fine-tuning (PEFT) for unit test generation, a resource-intensive task. It provides practical guidelines for researchers, showing which PEFT methods (LoRA, Prompt Tuning) are most effective for different model sizes. This opens avenues for more accessible and cost-effective automated testing, a critical area for software development.
Visual Insights#

🔼 This figure shows a diagram of the LoRA (Low-Rank Adaptation) method for parameter-efficient fine-tuning. It illustrates how LoRA works by adding low-rank updates to the weight matrices of the pre-trained model’s attention layers, instead of fine-tuning all parameters. The diagram highlights the original weight matrices (K and V projection matrices), the low-rank matrices (WA and WB) added by LoRA, and how they are combined. The other modules of the pre-trained model remain unchanged.
read the caption
(a) Diagram of LoRA (based on [15]).
| Hyperparameter | Method | Value |
|---|---|---|
| Common | ||
| Optimizer | - | AdamW |
| LR schedule | - | Linear |
| LR warmup ratio | - | 0.1 |
| Batch size | - | 1 |
| Gradient accumulation steps | - | 8 |
| # Epochs | - | 3 |
| Precision | - | Mixed |
| Learning rate | Full fine-tuning | 5E-5 |
| LoRA | 3E-4 | |
| (IA)3 | 3E-4 | |
| Prompt tuning | 3E-3 | |
| Method specific | ||
| Alpha | LoRA | 32 |
| Dropout | LoRA | 0.1 |
| Rank | LoRA | 16 |
| Virtual tokens | Prompt tuning | 20 |
🔼 This table lists the hyperparameters used during the training process, excluding those specific to individual models. It shows settings common to all training methods, including the optimizer used (AdamW), the learning rate schedule (linear), the learning rate warmup ratio, batch size, gradient accumulation steps, number of epochs, and the precision used. It also includes the specific learning rates used for each of the training methods: full fine-tuning, LoRA, (IA)³, and prompt tuning.
read the caption
TABLE I: Model-agnostic hyperparameters for training.
In-depth insights#
PEFT for Unit Tests#
The exploration of Parameter-Efficient Fine-Tuning (PEFT) methods for unit test generation represents a significant advancement in software engineering. PEFT offers a compelling solution to the computational cost and resource limitations associated with fine-tuning large language models (LLMs) for specialized tasks like unit testing. This approach strategically fine-tunes only a subset of model parameters, thereby reducing the computational burden while maintaining performance comparable to full fine-tuning. The study’s findings highlight the effectiveness of PEFT techniques such as LoRA and prompt tuning, showcasing their ability to deliver performance comparable to full fine-tuning, but with significantly reduced resource requirements. Prompt tuning emerges as particularly effective due to its efficiency, while LoRA approaches the performance of full fine-tuning. These findings suggest that PEFT makes specialized LLM fine-tuning more accessible and cost-effective for unit test generation. The research underscores the importance of carefully selecting the appropriate PEFT method based on model architecture and size, as different approaches demonstrate varying effectiveness depending on the specific LLM used. Overall, this approach presents a promising path towards more accessible and efficient automated unit test generation, a crucial area for improving software quality and development processes.
LLM Test Generation#
The application of Large Language Models (LLMs) to automated unit test generation presents a significant opportunity to improve software development efficiency and quality. Research indicates that LLMs can generate tests with high syntactic correctness, often exceeding 80%, but their effectiveness varies depending on the model architecture, size, and fine-tuning method. Parameter-efficient fine-tuning (PEFT) techniques offer a compelling approach, significantly reducing computational costs while maintaining comparable performance to full fine-tuning. Different PEFT methods, such as LoRA and prompt tuning, demonstrate varying degrees of effectiveness across different LLMs, highlighting the need for careful consideration in selecting the optimal technique. Prompt tuning exhibits the most efficiency in terms of resource utilization, but its performance can be inconsistent, while LoRA often achieves performance comparable to full fine-tuning with significantly fewer parameters. Future research should focus on further optimizing PEFT methods for test generation, exploring techniques that mitigate catastrophic forgetting, and developing more robust evaluation metrics beyond syntactic correctness to fully capture the quality of generated unit tests. Ultimately, the goal is to create cost-effective and reliable LLM-based unit test generators that can be readily adopted by developers to enhance software quality and productivity.
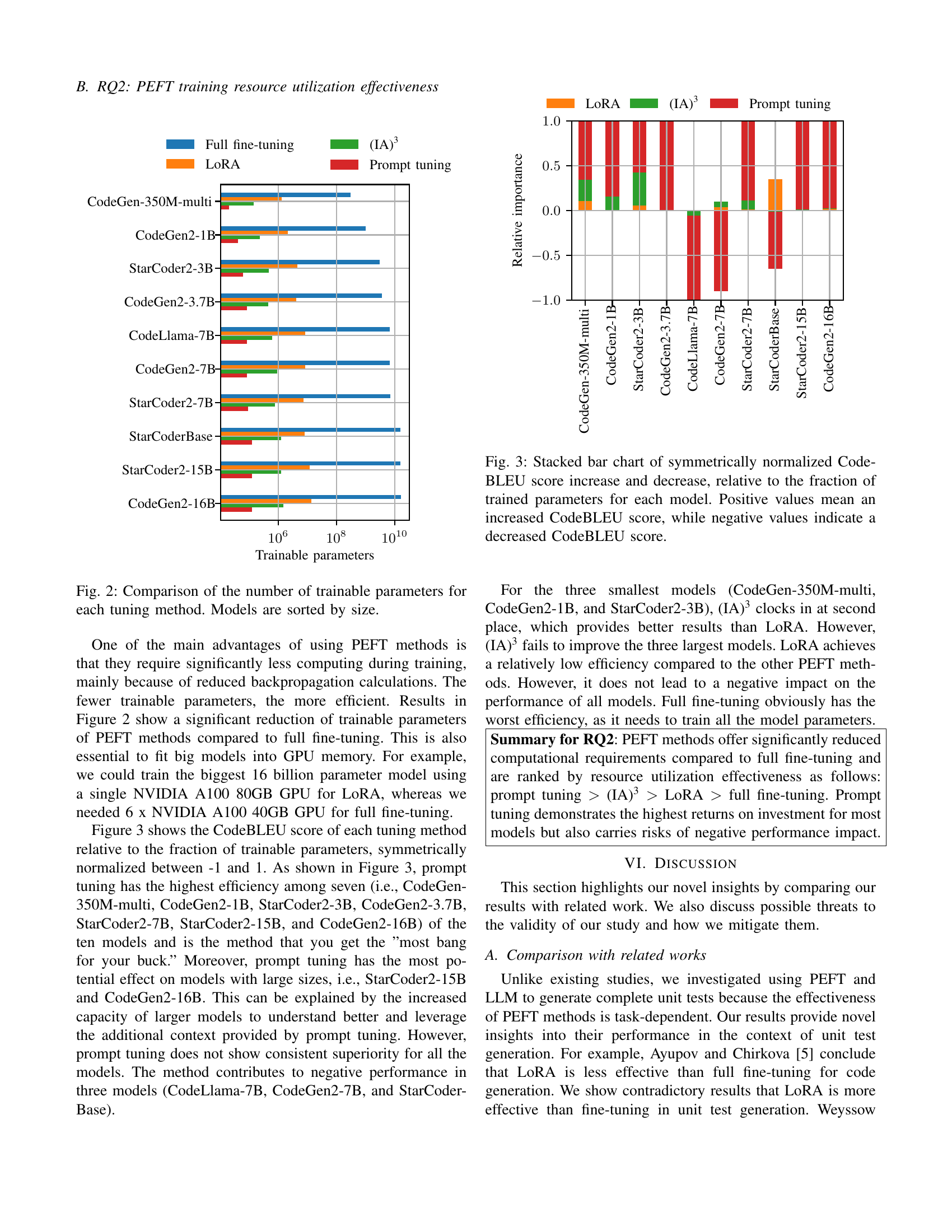
PEFT Efficiency#
The research reveals that parameter-efficient fine-tuning (PEFT) methods offer a compelling alternative to traditional full fine-tuning, especially when considering resource constraints. While full fine-tuning achieves high performance, its computational cost is substantial. Prompt tuning stands out as the most resource-efficient PEFT method, often delivering comparable results with significantly fewer trainable parameters. However, its performance variability across different models highlights the need for careful model selection. LoRA provides a more reliable alternative, consistently approaching the effectiveness of full fine-tuning in several cases and demonstrating robustness. (IA)³ appears to be the least effective PEFT method, demonstrating lower efficiency and generally poorer performance. Therefore, the choice of PEFT method should depend on the specific requirements of the task and available resources. The findings suggest that a thoughtful selection of PEFT techniques can greatly improve the cost-effectiveness of fine-tuning LLMs for unit test generation.
Catastrophic Forgetting#
Catastrophic forgetting, in the context of fine-tuning large language models (LLMs), refers to the phenomenon where a model, after being trained on a new task, loses its performance on previously learned tasks. This is a significant challenge in LLM adaptation, particularly with parameter-efficient fine-tuning (PEFT) methods, as these methods aim to minimize changes to the model’s weights. The study’s findings suggest that PEFT methods are generally robust against catastrophic forgetting. While some performance degradation was observed in a few cases when comparing PEFT to the baseline, the negative impact was not severe. This resilience to forgetting is a key advantage of PEFT, as it allows for efficient adaptation to multiple tasks without substantial loss of prior knowledge. The paper highlights the importance of choosing the appropriate PEFT method (e.g., LoRA vs. prompt tuning) based on the specific task and model characteristics, further emphasizing that carefully chosen PEFT strategies can largely prevent catastrophic forgetting. This is crucial for practical applications where LLMs need to be adapted to multiple tasks without retraining from scratch.
Future Research#
Future research should explore the integration of PEFT with other code-related tasks, such as code completion or bug detection, to evaluate its broader applicability. Investigating the effectiveness of PEFT across different programming languages beyond Java is crucial for wider adoption. It would also be valuable to compare different PEFT methods on diverse codebases with varying levels of complexity and structure to assess their robustness and generalizability. Furthermore, research into the development of novel PEFT techniques optimized for unit test generation and tailored to the specific characteristics of LLMs could significantly enhance performance. Finally, a deeper investigation into the trade-off between resource utilization and the quality of generated unit tests is vital for practical applications and deployment of these techniques in real-world scenarios. These future avenues of research could help to refine and enhance the application of parameter-efficient fine-tuning methods in unit test generation.
More visual insights#
More on figures

🔼 This figure shows the architecture of the Infused Adapter by Inhibiting and Amplifying Inner Activations (IA)³ method. It’s a type of parameter-efficient fine-tuning (PEFT) technique. The diagram illustrates how (IA)³ works by adding three small adapter modules to the pre-trained language model. These adapters (represented by magenta colored blocks) are trained, while the rest of the pre-trained model’s parameters (striped blocks) remain frozen. Each adapter module modifies the flow of information through a specific part of the model, making it more efficient and less computationally expensive compared to full fine-tuning.
read the caption
(b) Diagram of (IA)3 (based on [16]).

🔼 This figure shows an illustration of the prompt tuning method. In prompt tuning, a small set of trainable parameters, often referred to as ‘soft prompts’, are prepended to the input embeddings of the language model. Only these additional parameters are trained during the fine-tuning process, while the original model weights remain frozen. This approach enables adaptation to a specific task without adjusting all the model parameters, thus improving efficiency and potentially reducing the risk of overfitting or catastrophic forgetting. The diagram depicts the addition of these ‘soft prompt’ parameters to the input before processing by the main language model.
read the caption
(c) Diagram of prompt tuning (based on [17]).
More on tables
| Hyperparameter | Method | Model | Value |
|---|---|---|---|
| Targeted attention modules | LoRA, (IA)3 | codegen-350M-multi | qkv_proj |
| Salesforce/codegen2-1B_P | qkv_proj | ||
| Salesforce/codegen2-3_7B_P | qkv_proj | ||
| Salesforce/codegen2-7B_P | qkv_proj | ||
| Salesforce/codegen2-16B_P | qkv_proj | ||
| meta-llama/CodeLlama-7b-hf | q_proj, v_proj | ||
| bigcode/starcoderbase | c_attn | ||
| bigcode/starcoder2-3b | q_proj, v_proj | ||
| bigcode/starcoder2-7b | q_proj, v_proj | ||
| bigcode/starcoder2-15b | q_proj, v_proj | ||
| Targeted feedforward modules | (IA)3 | codegen-350M-multi | fc_out |
| Salesforce/codegen2-1B_P | fc_out | ||
| Salesforce/codegen2-3_7B_P | fc_out | ||
| Salesforce/codegen2-7B_P | fc_out | ||
| Salesforce/codegen2-16B_P | fc_out | ||
| meta-llama/CodeLlama-7b-hf | down_proj | ||
| bigcode/starcoderbase | mlp.c_proj | ||
| bigcode/starcoder2-3b | q_proj, c_proj | ||
| bigcode/starcoder2-7b | q_proj, c_proj | ||
| bigcode/starcoder2-15b | q_proj, c_proj |
🔼 This table details the model-specific hyperparameters used during the training phase of the experiment. It shows which specific modules within each model architecture were targeted for modification by the different parameter-efficient fine-tuning (PEFT) methods used in the study. Specifically, it indicates which attention and feed-forward modules were adjusted for LoRA and (IA)³ methods. The table is crucial for reproducibility as it provides the exact configurations used in the PEFT training process for each model, allowing researchers to recreate the experimental setup.
read the caption
TABLE II: Model-specific hyperparameters for training.
| Hyperparameters | Value |
|---|---|
| Do sample | False |
| Temperature | 0 |
| Top p | 0 |
| Frequency penalty | 0 |
| Max length | 2048 |
🔼 This table lists the hyperparameters used during the unit test generation phase of the experiment. It includes parameters such as whether sampling is enabled (
Do sample), temperature, top p, frequency penalty, and the maximum sequence length allowed. These hyperparameters control the randomness and length of the generated unit tests.read the caption
TABLE III: Hyperparameters for generation.
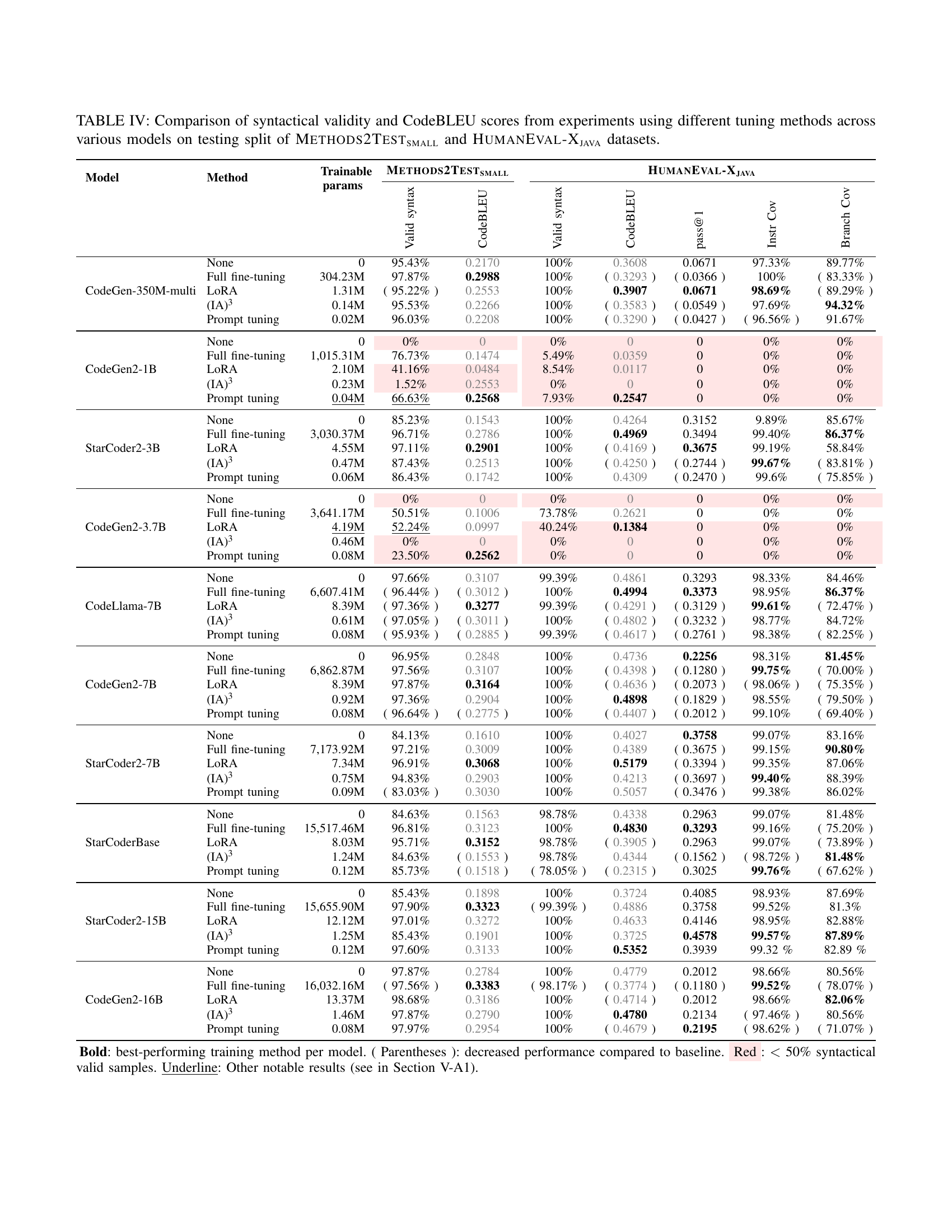
🔼 Table IV presents a detailed comparison of the performance of various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning for unit test generation. It assesses performance across ten different large language models (LLMs) of varying sizes and architectures, utilizing two benchmark datasets: METHODS2Testsmall and HumanEval-Xjava. The table shows the syntactical validity of the generated unit tests (percentage of syntactically correct tests), the CodeBLEU scores (measuring similarity to reference tests), pass@1 (the percentage of tests that passed), instruction coverage, and branch coverage for each LLM and tuning method (LoRA, (IA)³, prompt tuning, and full fine-tuning). This provides a comprehensive analysis of the effectiveness and efficiency of each method for unit test generation.
read the caption
TABLE IV: Comparison of syntactical validity and CodeBLEU scores from experiments using different tuning methods across various models on testing split of Methods2Testsmall and HumanEval-Xjava datasets.
Full paper#