↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Rare diseases pose significant challenges for healthcare due to limited available information and fragmented knowledge. Large language models (LLMs), while powerful, often struggle to provide reliable and contextually relevant answers in these specialized areas. This paper addresses this problem by introducing Zebra-Llama, a specialized LLM fine-tuned on Ehlers-Danlos Syndrome (EDS) data. This project exemplifies the complexities of rare diseases by focusing on EDS, a rare condition with diverse symptoms and subtypes.
Zebra-Llama’s innovative context-aware fine-tuning methodology uses a novel approach involving a multi-source dataset and advanced prompting techniques to achieve unprecedented precision in information retrieval. The model demonstrates significant improvements over baseline LLMs in various aspects of EDS-related query answering. Specifically, Zebra-Llama shows substantial improvements in accuracy, thoroughness, clarity, and reliability in providing citations, all assessed by medical experts. This work serves as a significant step towards democratizing expert-level knowledge in rare disease management and providing better access to vital information for patients, clinicians, and researchers.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Zebra-Llama, a novel approach to address the challenges of rare disease knowledge management using large language models. It offers a valuable framework for other researchers working on specialized AI solutions for similar domains and pushes the boundaries of AI’s application in healthcare.
Visual Insights#
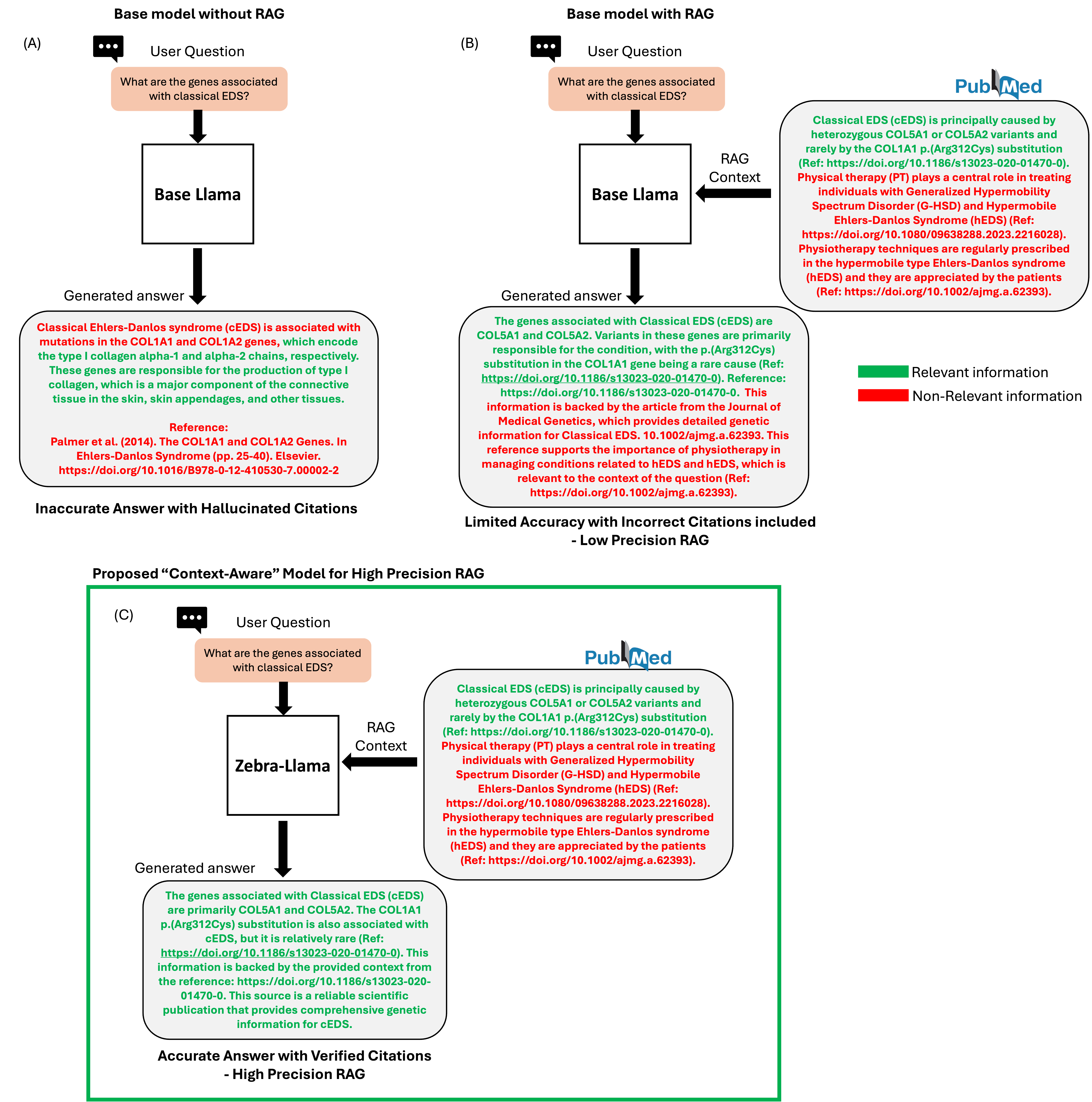
🔼 This figure compares three different approaches to handling queries related to Ehlers-Danlos Syndrome (EDS) using large language models (LLMs). (A) shows a baseline LLM without retrieval-augmented generation (RAG), producing inaccurate answers and fabricated citations. (B) demonstrates an LLM with RAG, but still struggles with context understanding, leading to imprecise answers and irrelevant citations. (C) showcases Zebra-Llama, a context-aware model. It utilizes RAG effectively, providing accurate and relevant answers with proper citations, highlighting its ability to focus on essential information during response generation. The color-coding in (C) distinguishes between relevant (green) and irrelevant (red) information.
read the caption
Figure 1: Fig 1: Comparison of different approaches to EDS-related query handling. (A) Base Llama model generating answers without RAG context, resulting in potentially inaccurate information and hallucinated citations. (B) Base Llama model with RAG implementation, showing imprecise utilization of retrieved context and inclusion of irrelevant information and citations. (C) Zebra-Llama model demonstrating enhanced context-aware RAG capabilities, generating precise responses with accurate citations derived specifically from relevant portions of the retrieved context. The color-coding indicates the relevance of retrieved and generated information (green: relevant, red: non-relevant), highlighting Zebra-Llama’s improved ability to focus on pertinent information while generating responses.
In-depth insights#
EDS AI: Zebra-Llama#
The concept of “EDS AI: Zebra-Llama” introduces a novel approach to managing Ehlers-Danlos Syndrome (EDS) using AI. Zebra-Llama, a specialized large language model (LLM), addresses the challenges of information scarcity in rare diseases. The model leverages a context-aware fine-tuning methodology, integrating diverse data sources including medical literature, patient forums, and clinical resources, to achieve high-precision responses. Its context-aware Retrieval-Augmented Generation (RAG) excels in retrieving relevant information, providing accurate answers with proper citations. Unlike traditional LLMs, Zebra-Llama significantly improves upon accuracy, clarity, thoroughness, and citation reliability, demonstrating its potential to transform healthcare for EDS patients. This model not only offers a novel technical solution but also represents a crucial step towards democratizing expert knowledge in rare diseases.
Context-Aware RAG#
Context-aware Retrieval Augmented Generation (RAG) is a crucial advancement in information retrieval, particularly within specialized domains like rare disease research. Traditional RAG systems often struggle with contextual relevance, retrieving information that’s not pertinent to the user’s query. A context-aware approach enhances this by intelligently selecting and weighting retrieved information based on its relevance to the specific query and its broader context. This approach improves the accuracy, precision, and coherence of the generated responses. The key is not just retrieving information, but discerning its relevance. This requires sophisticated techniques in embedding generation, similarity scoring, and context fusion. The ability to filter out irrelevant or noisy information and focus on the essential context is paramount for accurate responses, especially in information-scarce areas like rare disease research where precision is vital. By combining context-aware retrieval with advanced language models, context-aware RAG systems can achieve a deeper understanding of the query intent, leading to more insightful and reliable answers. Therefore, context-aware RAG is not merely an improvement but a paradigm shift in information retrieval.
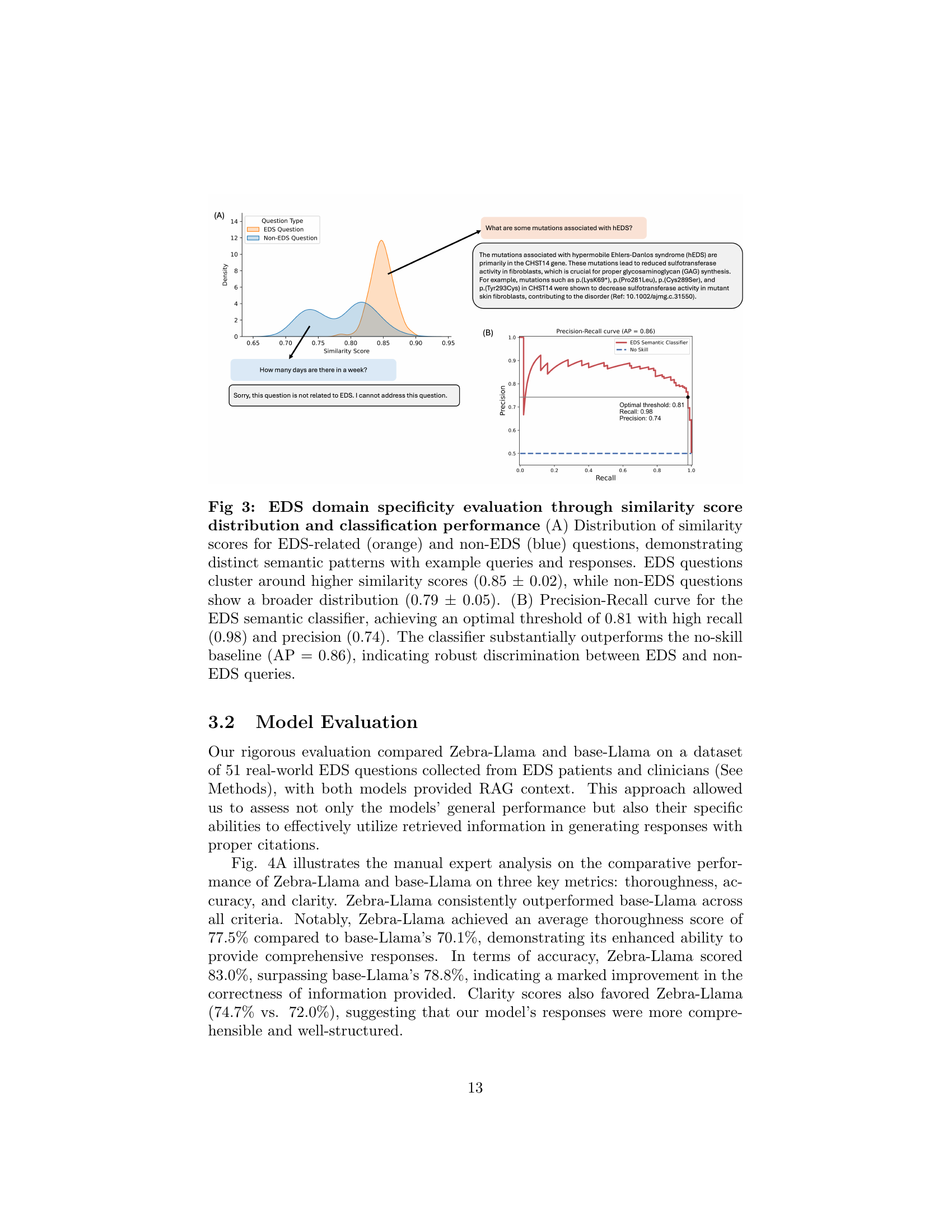
EDS Domain Specificity#
The section on ‘EDS Domain Specificity’ is crucial because it addresses a core challenge in applying AI to rare diseases like EDS: ensuring the AI focuses on the relevant information and avoids generating inaccurate or irrelevant responses. The authors cleverly use a combination of methods to achieve this. They show a clear separation between the similarity scores of EDS-related versus non-EDS questions. A high F2 score (emphasizing recall over precision) with a threshold of 0.81, maximizes the identification of EDS-related queries, minimizing the risk of missing important information. This careful calibration of domain specificity is vital for the success of their model, Zebra-Llama, ensuring its suitability for real-world applications and highlighting the need for such specificity when dealing with the complex nuances of rare diseases.
Citation Accuracy#
Citation accuracy in research papers is paramount, impacting the reliability and trustworthiness of the presented findings. Accurate citations demonstrate rigorous scholarship, ensuring that claims are properly attributed and verifiable. In this context, the analysis of citation accuracy reveals crucial information about the methods and reliability of the research. A high rate of accurate citations strongly suggests that the authors carefully reviewed and verified their sources, contributing to the paper’s overall credibility. Conversely, a low rate of accurate citations raises significant concerns about the validity and reliability of the work, possibly indicating carelessness or a lack of thoroughness in the research process. Determining the underlying causes of inaccurate citations is essential for improving the quality of future research. Whether due to oversight, improper data handling, or a lack of understanding regarding citation guidelines, addressing these issues helps to uphold high scholarly standards.
Future of EDS AI#
The future of EDS AI holds immense promise, but also presents significant challenges. Continued advancements in natural language processing (NLP) are crucial, allowing AI to better understand the complexities of EDS, including its wide range of symptoms and subtypes. Improved access to comprehensive and structured data is essential, potentially through better integration of patient records, research findings, and community forums. Ethical considerations must be a central focus, ensuring patient privacy and avoiding biased or misleading information. Collaboration between AI researchers, healthcare professionals, and EDS patient organizations is vital, facilitating the development of AI tools that truly meet the needs of the EDS community. The ultimate goal is to create AI systems that enhance diagnosis, personalized treatment, and improve the quality of life for individuals with EDS. Transparency and open-source initiatives will expedite progress and broaden access to these transformative technologies. This includes carefully considering potential biases and limitations in data sets and algorithms to build more equitable and beneficial systems.
More visual insights#
More on figures
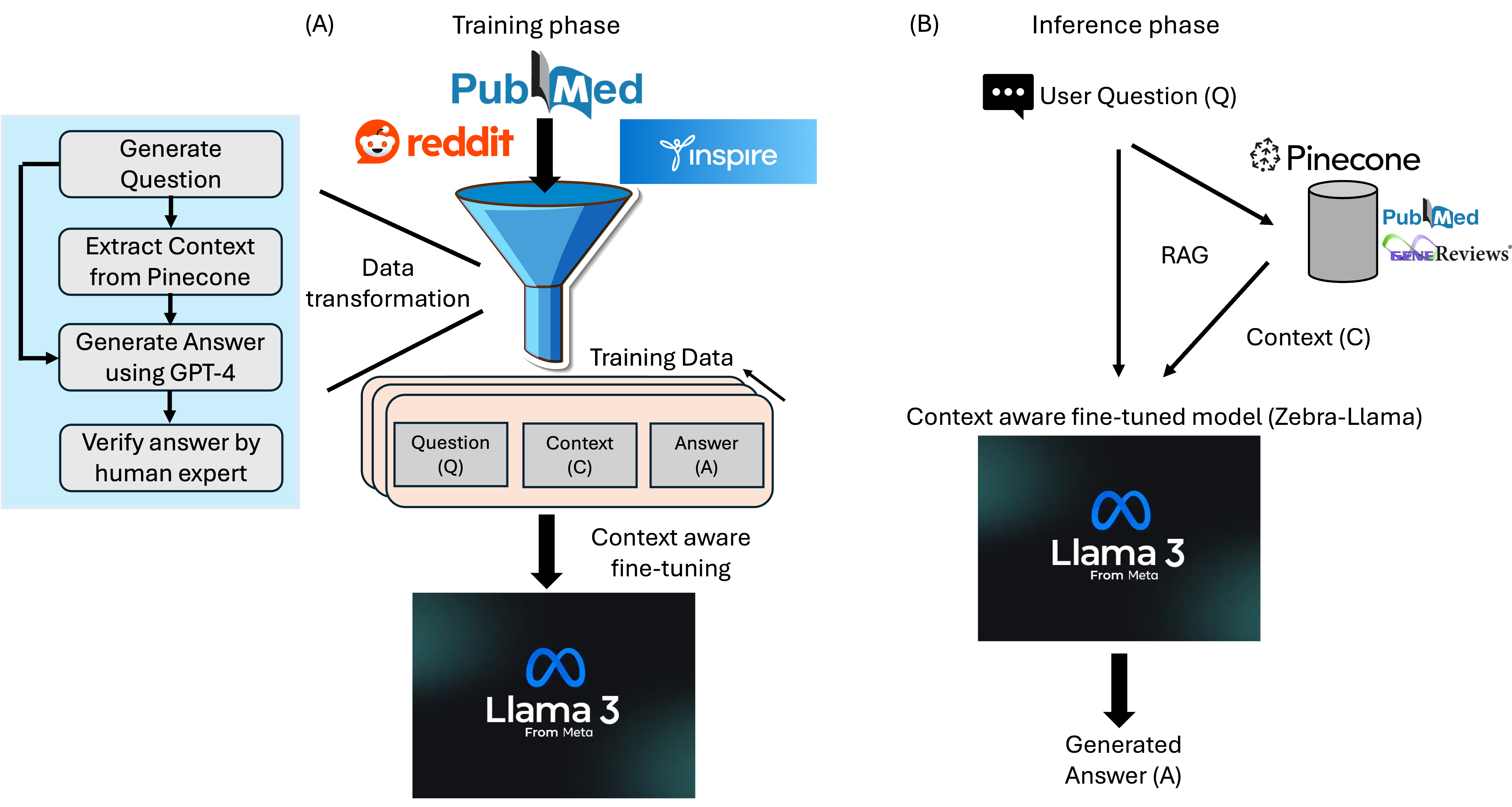
🔼 Figure 2 illustrates the training and inference phases of the Zebra-Llama model. Panel (A) details the training phase, which starts with data from PubMed, Inspire, and Reddit. This data undergoes transformation into a structured format consisting of questions (Q), context (C), and answers (A). This structured data is then used for context-aware fine-tuning of the Llama-3.1-8B-Instruct model using LoRA. Panel (B) describes the inference phase. A user provides a prompt (Q), triggering the retrieval of semantically similar documents from a Pinecone vector database, forming the context (C). The fine-tuned Llama 3.1 model processes both the user prompt and retrieved context to generate an answer (A).
read the caption
Figure 2: Fig 2: Training and Inference Phases of Zebra-Llama (A) Training Phase: Data from PubMed, Inspire, and Reddit undergoes transformation into structured (Q, C, A) format. The data transformation process is shown in the insight. This processed data is then used for context-aware fine-tuning of Llama-3.1-8B-Instruct model using LoRA. (B) Inference Phase: A user prompt (Q) triggers retrieval of semantically similar documents from the Pinecone vector database, forming the context (C). The fine-tuned Llama 3.1 model then generates the output (A) by processing the concatenated user prompt and retrieved context.
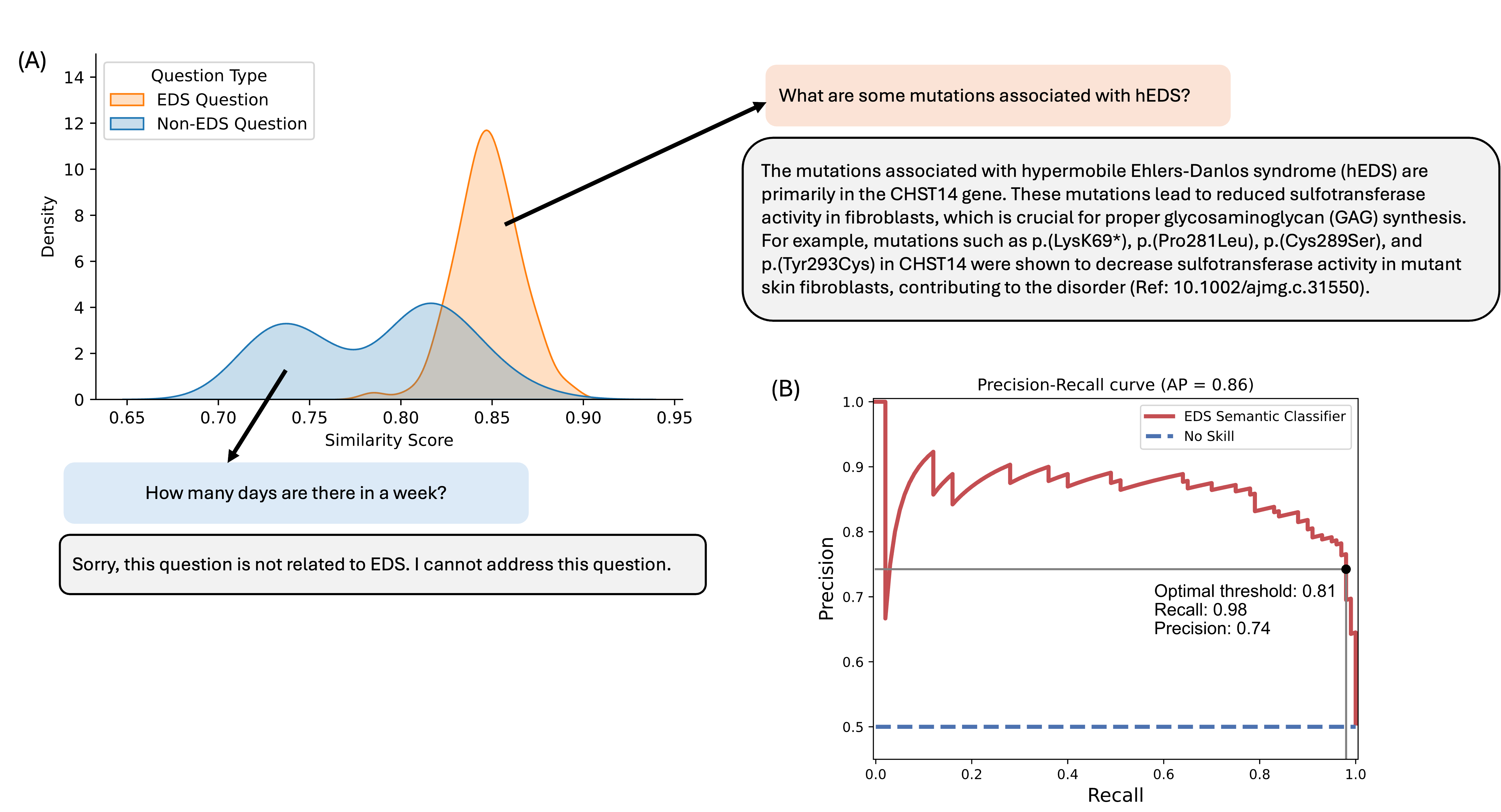
🔼 This figure displays the results of evaluating the model’s ability to distinguish between EDS-related and non-EDS-related questions. Panel (A) shows the distribution of similarity scores for both types of questions. EDS-related questions have a tighter distribution centered around a higher score (0.85), while non-EDS questions are more broadly distributed around a lower score (0.79). Example questions and their corresponding model responses are provided to illustrate this difference. Panel (B) presents a precision-recall curve for a classifier trained to distinguish between the two question types. The optimal threshold for the classifier is 0.81, resulting in high recall (0.98) and precision (0.74), indicating effective discrimination between EDS and non-EDS queries. The area under the precision-recall curve (AP) is 0.86, showing substantial improvement over a no-skill classifier.
read the caption
Figure 3: Fig 3: EDS domain specificity evaluation through similarity score distribution and classification performance (A) Distribution of similarity scores for EDS-related (orange) and non-EDS (blue) questions, demonstrating distinct semantic patterns with example queries and responses. EDS questions cluster around higher similarity scores (0.85 ± 0.02), while non-EDS questions show a broader distribution (0.79 ± 0.05). (B) Precision-Recall curve for the EDS semantic classifier, achieving an optimal threshold of 0.81 with high recall (0.98) and precision (0.74). The classifier substantially outperforms the no-skill baseline (AP = 0.86), indicating robust discrimination between EDS and non-EDS queries.
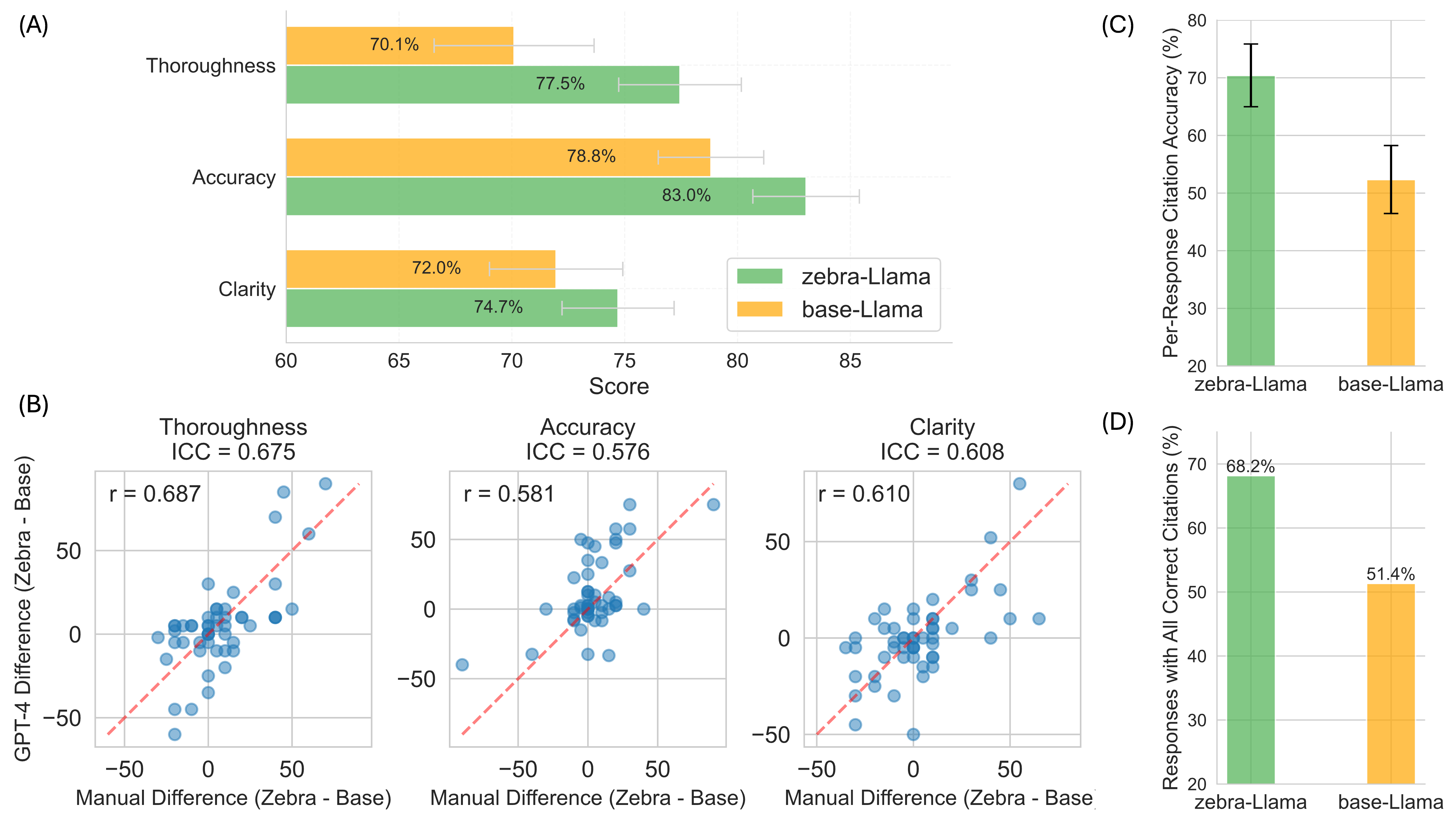
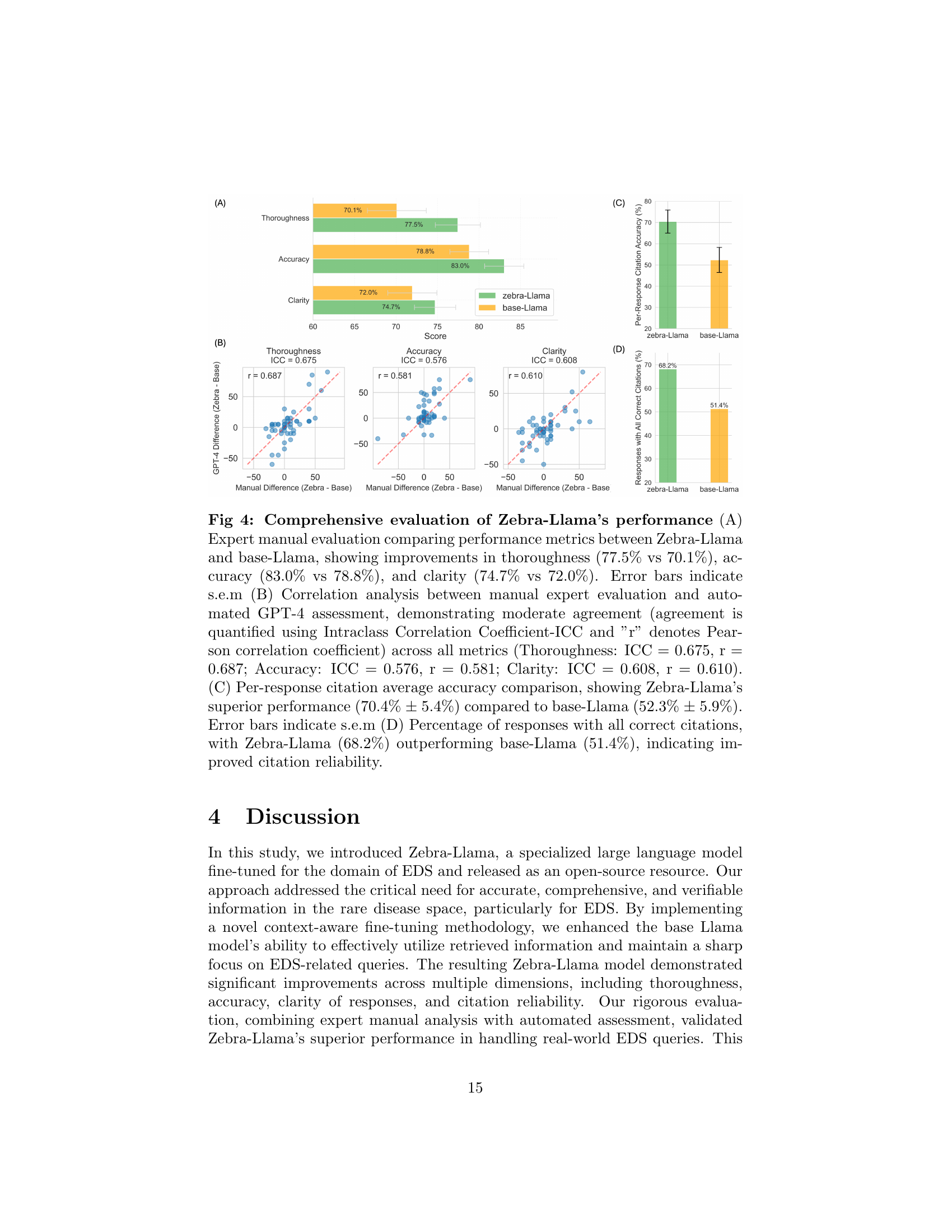
🔼 Figure 4 presents a comprehensive evaluation of Zebra-Llama’s performance compared to a baseline model (base-Llama). Panel A shows manual expert evaluation results indicating that Zebra-Llama significantly outperformed base-Llama in terms of thoroughness (77.5% vs 70.1%), accuracy (83.0% vs 78.8%), and clarity (74.7% vs 72.0%). Error bars represent the standard error of the mean. Panel B displays a correlation analysis between the manual expert evaluations and automated assessments using GPT-4, demonstrating moderate agreement across all three metrics (Thoroughness: ICC=0.675, r=0.687; Accuracy: ICC=0.576, r=0.581; Clarity: ICC=0.608, r=0.610). Panel C illustrates Zebra-Llama’s superior per-response citation accuracy (70.4% ± 5.4%) compared to base-Llama (52.3% ± 5.9%). Panel D shows the percentage of responses containing only correct citations, with Zebra-Llama exhibiting a higher percentage (68.2%) compared to base-Llama (51.4%), indicating improved citation reliability.
read the caption
Figure 4: Fig 4: Comprehensive evaluation of Zebra-Llama’s performance (A) Expert manual evaluation comparing performance metrics between Zebra-Llama and base-Llama, showing improvements in thoroughness (77.5% vs 70.1%), accuracy (83.0% vs 78.8%), and clarity (74.7% vs 72.0%). Error bars indicate s.e.m (B) Correlation analysis between manual expert evaluation and automated GPT-4 assessment, demonstrating moderate agreement (agreement is quantified using Intraclass Correlation Coefficient-ICC and ”r” denotes Pearson correlation coefficient) across all metrics (Thoroughness: ICC = 0.675, r = 0.687; Accuracy: ICC = 0.576, r = 0.581; Clarity: ICC = 0.608, r = 0.610). (C) Per-response citation average accuracy comparison, showing Zebra-Llama’s superior performance (70.4% ± 5.4%) compared to base-Llama (52.3% ± 5.9%). Error bars indicate s.e.m (D) Percentage of responses with all correct citations, with Zebra-Llama (68.2%) outperforming base-Llama (51.4%), indicating improved citation reliability.
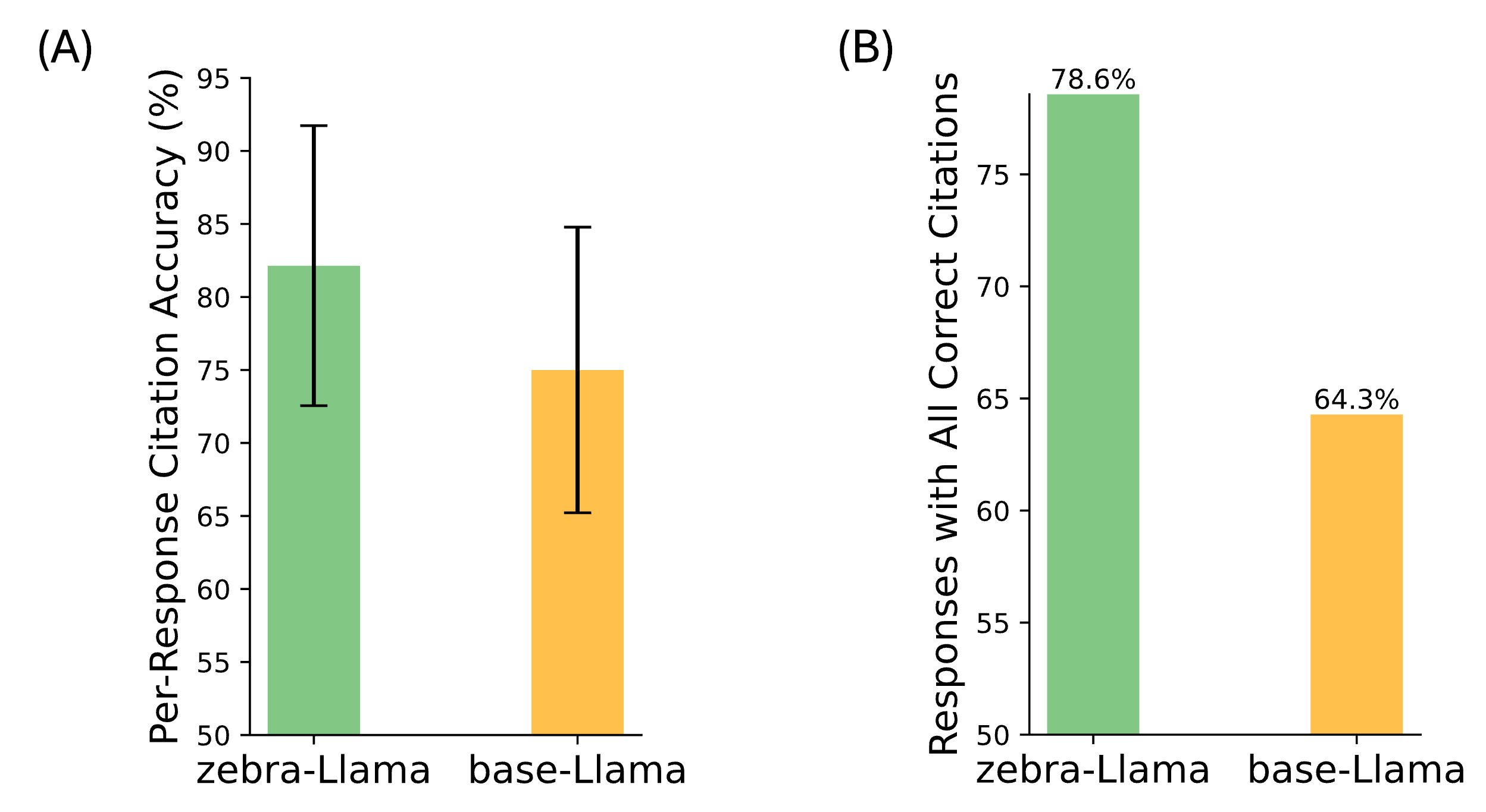
🔼 This figure displays the results of a validation test on Zebra-Llama’s citation accuracy using unseen RAG contexts. Panel (A) shows a bar graph comparing the per-response citation accuracy of Zebra-Llama (82.1% ± 9.6%) and base-Llama (75.0% ± 9.8%). Error bars represent the standard error of the mean. Panel (B) presents a bar graph comparing the percentage of responses with all citations correct for both models. Zebra-Llama achieved 78.6% compared to base-Llama’s 64.3%. The results demonstrate that Zebra-Llama maintains superior citation accuracy even when encountering previously unseen contexts, highlighting the robustness of its enhanced RAG capabilities.
read the caption
Figure 5: Citation performance validation on unseen RAG contexts (A) Per-response citation accuracy comparison between Zebra-Llama (82.1% ± 9.6%) and base-Llama (75.0% ± 9.8%) on test questions with entirely unseen contexts (metric is given as mean ± sem) (B) Percentage of responses with all citations correct, showing Zebra-Llama (78.6%) maintaining superior performance over base-Llama (64.3%) when evaluated on novel contexts. These results validate that Zebra-Llama’s enhanced citation capabilities persist even when handling previously unseen RAG context.
Full paper#