↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current object detection models face challenges in complex scenarios. While impressive advancements exist, understanding how visual perception tasks (depth and saliency) correlate with detection accuracy is crucial for system optimization. This study explores this relationship using state-of-the-art models, on standard datasets.
This research reveals that visual saliency correlates more strongly with object detection accuracy compared to depth prediction. The effect varies across object categories; correlations are significantly higher for larger objects. This suggests that incorporating visual saliency features into object detection models could be highly beneficial, particularly for specific categories. The findings are important for improving both model architecture and dataset design.
Key Takeaways#
Why does it matter?#
This paper is important because it provides empirical evidence on the correlation between visual saliency, depth estimation, and object detection accuracy. This is crucial for improving model design, optimizing computational efficiency, and guiding dataset creation in computer vision. The findings also suggest new avenues for targeted feature engineering and dataset design improvements. The category-specific analysis provides direction for more efficient and accurate object detection systems.
Visual Insights#

🔼 Figure 1 displays a comparative analysis of visual saliency and depth prediction models’ outputs. It presents the original image from the COCO dataset alongside its ground truth annotations (mask), corresponding depth maps generated by Depth Anything and DPT-Large models, and saliency maps produced by Itti’s model and DeepGaze IIE. This visual comparison helps illustrate the differences in the information captured by each model and how these might relate to the original image and ground truth.
read the caption
Figure 1: Comparison of outputs generated from various saliency and depth prediction models alongside the original image and annotations.
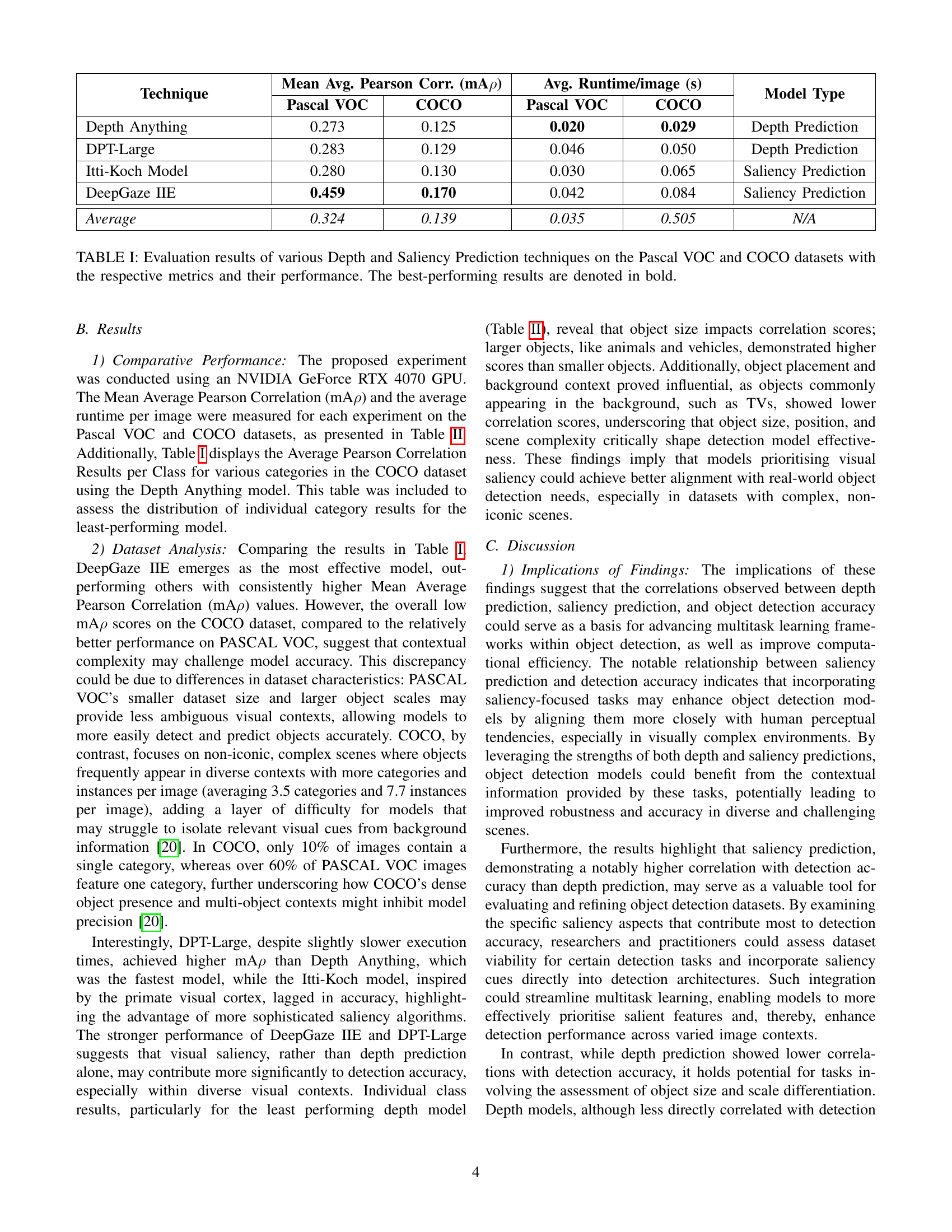
| Technique | Mean Avg. Pearson Corr. (mAρ) - Pascal VOC | Mean Avg. Pearson Corr. (mAρ) - COCO | Avg. Runtime/image (s) - Pascal VOC | Avg. Runtime/image (s) - COCO | Model Type |
|---|---|---|---|---|---|
| Depth Anything | 0.273 | 0.125 | 0.020 | 0.029 | Depth Prediction |
| DPT-Large | 0.283 | 0.129 | 0.046 | 0.050 | Depth Prediction |
| Itti-Koch Model | 0.280 | 0.130 | 0.030 | 0.065 | Saliency Prediction |
| DeepGaze IIE | 0.459 | 0.170 | 0.042 | 0.084 | Saliency Prediction |
| Average | 0.324 | 0.139 | 0.035 | 0.057 | N/A |
🔼 Table I presents a comprehensive comparison of four different visual prediction models (two depth prediction models and two saliency prediction models) evaluated on two benchmark object detection datasets, Pascal VOC and COCO. The evaluation metrics include the Mean Average Pearson Correlation (mAp), reflecting the overall correlation between the model predictions and ground truth, and the average runtime per image in seconds. The table clearly shows the superior performance of saliency prediction models compared to depth prediction models, particularly on the Pascal VOC dataset. The best-performing results for each dataset and model are highlighted in bold, allowing for a direct comparison of model efficacy.
read the caption
TABLE I: Evaluation results of various Depth and Saliency Prediction techniques on the Pascal VOC and COCO datasets with the respective metrics and their performance. The best-performing results are denoted in bold.
In-depth insights#
Saliency’s Strong Link#
The heading “Saliency’s Strong Link” suggests a significant correlation between visual saliency and another factor, likely object detection performance, as explored in the research paper. A thoughtful analysis would delve into the strength and nature of this correlation. Does high saliency consistently predict accurate object detection, or are there exceptions? The study likely investigates variations in this relationship, considering factors such as object size, category, and background complexity. Quantitative metrics such as Pearson correlation coefficients would be crucial, revealing the degree of association. The research would likely also explore the underlying mechanisms driving the connection, investigating how the brain’s attentional processes in perceiving salient regions and computer vision’s methods for highlighting salient areas align or diverge. Understanding this relationship offers insights for improving object detection models by incorporating saliency information as a guide, possibly addressing detection limitations in complex scenes or with less visually striking objects. The analysis would also provide insights into the design of more effective datasets for object detection, particularly focusing on balanced representation of salient and non-salient objects to reduce biases in model training and enhance generalizability.
Depth’s Limited Role#
The heading “Depth’s Limited Role” suggests an analysis within a research paper investigating the contribution of depth estimation to object detection performance. A thoughtful exploration would likely reveal that while depth information provides contextual clues, its impact is less significant than other visual cues like saliency. The analysis might demonstrate that depth, while useful in certain scenarios (e.g., disambiguating occluded objects or discerning object size), fails to consistently improve object detection accuracy across diverse datasets and object categories. This limitation could be due to several factors: noise and inaccuracies in depth estimation, especially with monocular methods, the limited expressiveness of depth maps in conveying essential visual features like texture and color, and the redundancy of depth relative to already informative features used in state-of-the-art detectors. The research would probably offer concrete examples of where depth fails to add significant value compared to scenarios where it’s indeed useful. Such examples could help identify the specific situations and data characteristics where depth proves most helpful, thus guiding future model design and dataset construction. This work could conclude that a more balanced approach, integrating multiple complementary cues, is needed for robust object detection systems. The findings suggest that a holistic vision system, incorporating visual saliency as well as other contextual information, would likely outperform those relying heavily on depth alone.
Size Matters#
The concept of “Size Matters” in object detection highlights a crucial observation: object size significantly impacts the correlation between visual cues (depth and saliency) and detection accuracy. Larger objects tend to exhibit stronger correlations, implying that readily available visual features are more easily extracted and matched with ground truth data. This suggests that current models might be over-reliant on readily available features, particularly for larger objects. Further investigation into this size-based discrepancy is needed to develop models less sensitive to this bias. The disproportionate impact of size indicates a need for improving dataset design, potentially by incorporating a more balanced representation of object scales to address this inherent limitation. This might involve oversampling smaller objects, refining annotation techniques for more precise bounding boxes, or even designing specialized architectures that handle various size ranges more effectively. Ultimately, understanding the relationship between object size and model performance is crucial for building more robust and generally applicable object detection systems.
Dataset Influence#
The choice of dataset significantly influences the results and conclusions of the research. The discrepancy in performance between COCO and Pascal VOC highlights the importance of dataset characteristics. COCO’s complexity, with diverse scenes and dense object arrangements, poses a challenge compared to the less complex Pascal VOC dataset. The variance in object sizes and background contexts within each dataset further impacts model performance. This suggests that future research should carefully consider dataset design, ensuring adequate representation of various object scales, backgrounds, and levels of visual clutter to yield more generalizable and robust results. Dataset bias, particularly in saliency prediction models, is another crucial factor affecting the reliability of the findings. Models trained on specific datasets might prioritize certain visual cues over others, ultimately limiting the ability to generalize to real-world scenarios. Therefore, a balanced dataset is paramount for robust conclusions, allowing for better generalization and more reliable insights into the relationship between visual tasks and object detection performance. Further investigation into dataset biases and their impact on the various models is recommended.
Future Directions#
Future research should explore the integration of visual saliency and depth information within unified object detection models, moving beyond simple correlation analysis. Investigating how different model architectures handle the fusion of these cues is crucial. Furthermore, dataset design requires careful consideration: the creation of datasets with varied object sizes, scales, and contexts (particularly challenging non-iconic scenes) is vital for training robust and generalizable models. Incorporating human perception studies to understand the interaction of visual attention mechanisms with object detection could inform the development of more biologically plausible and effective algorithms. Additionally, research should investigate the interplay between saliency, depth, and other visual features, like texture and color, to create a richer and more complete representation of a scene for improved object detection performance. Finally, assessing model performance across various demographic groups will ensure that the developed models avoid potential biases and are truly inclusive.
More visual insights#
More on figures

🔼 Figure 2 presents a visual comparison of the Depth Anything model’s performance on the COCO dataset. It displays several sample images from the dataset alongside their corresponding ground truth segmentation masks (showing the true object boundaries). Next to each image is the depth map produced by the Depth Anything model, illustrating its estimation of depth at each pixel. Finally, a Pearson correlation value is provided for each image, quantifying the similarity between the model’s generated depth map and the ground truth mask. This figure demonstrates how well the model’s predictions align with the actual depth information in the images, and provides a visual way to understand the model’s accuracy on different types of images within the COCO dataset.
read the caption
Figure 2: Sample images from the COCO dataset along with their corresponding ground truth masks, depth maps generated by the Depth Anything Model, and Pearson correlation values.

🔼 Figure 3 shows example images from the Pascal VOC dataset. For each image, it displays the original image, the ground truth segmentation mask (highlighting the object boundaries), a saliency map produced by the DeepGaze IIE model (showing areas of visual importance), and the Pearson correlation coefficient calculated between the saliency map and ground truth mask. The Pearson correlation coefficient quantifies the similarity between the model’s prediction of visually salient areas and the actual locations of the objects.
read the caption
Figure 3: Sample images from the Pascal VOC dataset along with their corresponding ground truth masks, saliency maps generated by the DeepGaze IIE Model, and Pearson correlation values.
Full paper#