↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current Retrieval-Augmented Generation (RAG) systems typically convert HTML web pages to plain text before feeding them to Large Language Models (LLMs). This process loses crucial structural and semantic information present in the HTML, potentially leading to less accurate and more hallucinated outputs. This paper addresses this limitation by proposing HtmlRAG, a novel approach.
HtmlRAG uses HTML as the knowledge format in RAG systems. To overcome the challenges of processing long HTML sequences containing irrelevant information (e.g. CSS, JavaScript), the authors introduce HTML cleaning and compression strategies, followed by a two-step pruning method that leverages both text embedding and a generative model to select relevant HTML blocks. Extensive experiments on six different QA datasets demonstrate that HtmlRAG significantly outperforms existing text-based methods. The paper thus suggests a paradigm shift in how external knowledge is processed within RAG pipelines.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in information retrieval and natural language processing. It challenges the conventional approach of using plain text in RAG systems and demonstrates the benefits of leveraging HTML’s structural information. This opens new avenues for improving knowledge retrieval and generation accuracy, impacting various applications like question answering and document summarization. The proposed HTML pruning techniques also offer valuable insights into efficient data processing for LLMs.
Visual Insights#

🔼 The figure illustrates the loss of structural and semantic information that occurs when converting HTML to plain text. The left side shows an HTML table with clear structure and semantic meaning (indicated by tags and formatting). The right side displays the same information rendered as plain text, where the original table structure and semantic cues (like
tags or tags) are lost. This loss makes the information less precise and less easily understandable by LLMs, which rely heavily on structural information and semantic cues to process and understand text effectively.read the caption
Figure 1. Information loss in HTML to plain text conversion.
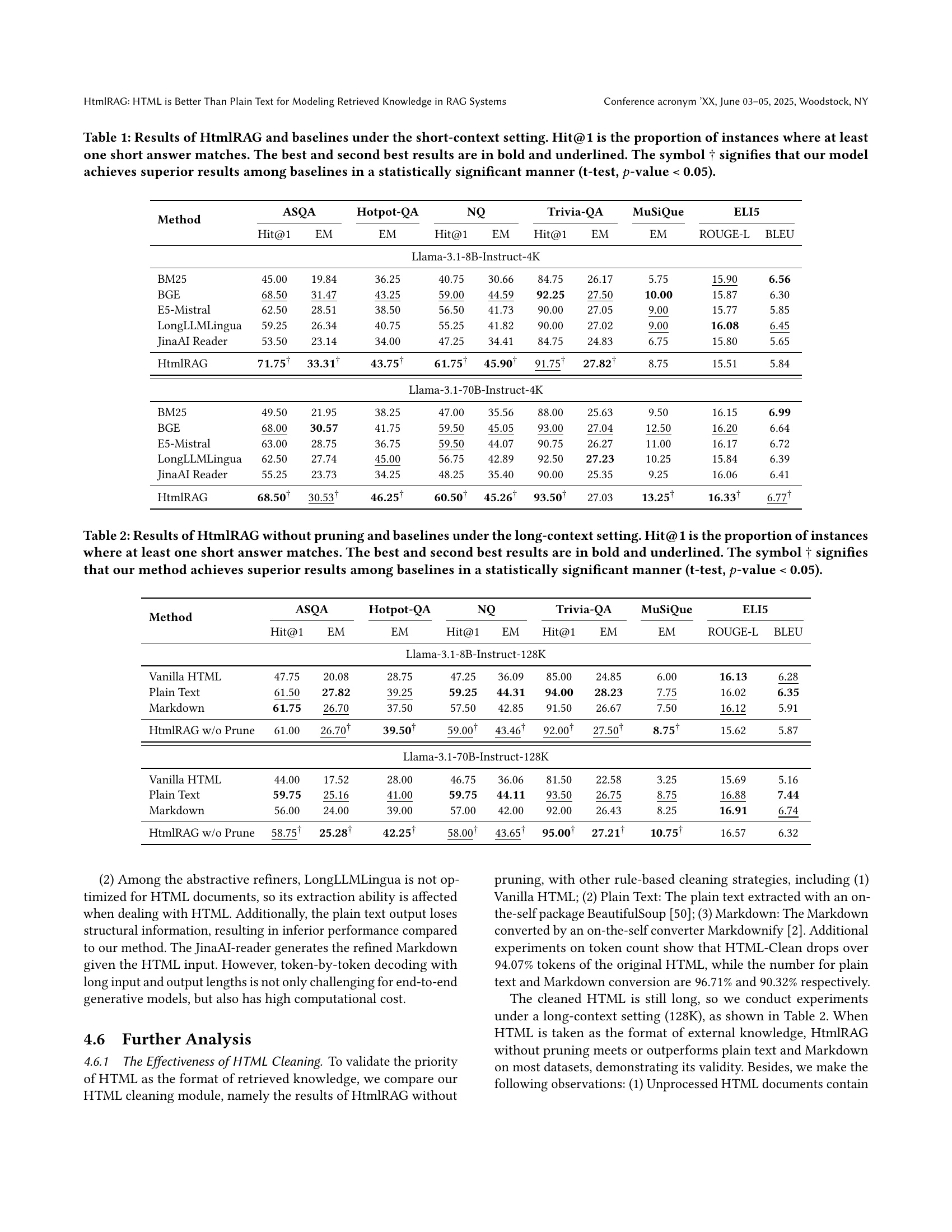
| Method | ASQA Hit@1 | ASQA EM | Hotpot-QA EM | NQ Hit@1 | NQ EM | Trivia-QA Hit@1 | Trivia-QA EM | MuSiQue ROUGE-L | ELI5 BLEU | ELI5 Hit@1 |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct-4K | ||||||||||
| BM25 | 45.00 | 19.84 | 36.25 | 40.75 | 30.66 | 84.75 | 26.17 | 5.75 | 15.90 | 6.56 |
| BGE | 68.50 | 31.47 | 43.25 | 59.00 | 44.59 | 92.25 | 27.50 | 10.00 | 15.87 | 6.30 |
| E5-Mistral | 62.50 | 28.51 | 38.50 | 56.50 | 41.73 | 90.00 | 27.05 | 9.00 | 15.77 | 5.85 |
| LongLLMLingua | 59.25 | 26.34 | 40.75 | 55.25 | 41.82 | 90.00 | 27.02 | 9.00 | 16.08 | 6.45 |
| JinaAI Reader | 53.50 | 23.14 | 34.00 | 47.25 | 34.41 | 84.75 | 24.83 | 6.75 | 15.80 | 5.65 |
| HtmlRAG | 71.75† | 33.31† | 43.75† | 61.75† | 45.90† | 91.75† | 27.82† | 8.75 | 15.51 | 5.84 |
| Llama-3.1-70B-Instruct-4K | ||||||||||
| BM25 | 49.50 | 21.95 | 38.25 | 47.00 | 35.56 | 88.00 | 25.63 | 9.50 | 16.15 | 6.99 |
| BGE | 68.00 | 30.57 | 41.75 | 59.50 | 45.05 | 93.00 | 27.04 | 12.50 | 16.20 | 6.64 |
| E5-Mistral | 63.00 | 28.75 | 36.75 | 59.50 | 44.07 | 90.75 | 26.27 | 11.00 | 16.17 | 6.72 |
| LongLLMLingua | 62.50 | 27.74 | 45.00 | 56.75 | 42.89 | 92.50 | 27.23 | 10.25 | 15.84 | 6.39 |
| JinaAI Reader | 55.25 | 23.73 | 34.25 | 48.25 | 35.40 | 90.00 | 25.35 | 9.25 | 16.06 | 6.41 |
| HtmlRAG | 68.50† | 30.53† | 46.25† | 60.50† | 45.26† | 93.50† | 27.03 | 13.25† | 16.33† | 6.77† |
🔼 Table 1 presents a comparison of HtmlRAG’s performance against several baseline methods for question answering under short-context conditions. It shows the Exact Match (EM) and Hit@1 scores (the percentage of instances where at least one short answer correctly matches the model’s response) across six different datasets (ASQA, Hotpot-QA, NQ, TriviaQA, MuSiQue, and ELI5). The results highlight HtmlRAG’s superior performance, indicated by bold and underlined scores, and statistically significant improvements over baseline methods in many cases (denoted by †). The datasets vary in their question types and difficulty, allowing for a comprehensive evaluation of the model’s capabilities.
read the caption
Table 1. Results of HtmlRAG and baselines under the short-context setting. Hit@1 is the proportion of instances where at least one short answer matches. The best and second best results are in bold and underlined. The symbol ††\dagger† signifies that our model achieves superior results among baselines in a statistically significant manner (t-test, p𝑝pitalic_p-value ¡ 0.05).
In-depth insights#
HTML in RAG#
The use of HTML in Retrieval Augmented Generation (RAG) systems presents a compelling approach to enhance knowledge representation and retrieval. Traditional RAG systems often convert HTML to plain text, resulting in a significant loss of structural and semantic information. This loss can negatively impact the LLM’s ability to accurately comprehend and generate responses based on the retrieved knowledge. The core idea of leveraging HTML directly is to preserve the rich structure inherent in web pages. This structure, encompassing headings, tables, and other formatting elements, provides invaluable context that aids LLM understanding. However, challenges remain; HTML often includes extraneous elements (JavaScript, CSS) which could introduce noise and increase the computational load. The paper’s approach in handling this is by employing techniques like HTML cleaning and pruning, which is aimed at streamlining the HTML by removing irrelevant content while retaining critical semantic information. The strategy involves a two-step block-tree based pruning method, leveraging both embedding-based and generative model approaches to achieve optimal efficiency and performance. In essence, this exploration into using HTML in RAG showcases a powerful paradigm that could greatly enhance the capabilities of LLMs and overcome some limitations associated with conventional text-based retrieval methods.
HTML Cleaning#
The process of “HTML Cleaning” in this research paper is crucial for effectively leveraging HTML in Retrieval Augmented Generation (RAG) systems. The core objective is to reduce noise and irrelevant information from raw HTML documents which are frequently very lengthy and contain non-semantic elements like CSS, JavaScript, and comments. These elements unnecessarily inflate the input length for LLMs while offering minimal semantic value. Therefore, this cleaning phase significantly prepares the HTML for further processing by removing these elements. This process is rule-based, not model-based, ensuring efficiency and avoiding potential errors arising from nuanced semantic interpretation of HTML. The cleaning process also includes structural compression techniques such as merging multiple layers of nested tags and removing empty tags. This stage ensures semantic information remains preserved while significantly compressing the HTML document, making it more manageable and computationally efficient for LLMs to process. The lossless nature of the cleaning process is critical, ensuring that no vital semantic content is lost and only the noise and excessive elements are removed, thereby directly impacting the efficiency of the RAG system.
Block Tree Pruning#
The core of the proposed HtmlRAG system lies in its innovative ‘Block Tree Pruning’ method. This technique efficiently manages the excessive length of HTML documents retrieved from the web, a common challenge in Retrieval Augmented Generation (RAG). Instead of directly pruning the HTML’s Document Object Model (DOM) tree which is too granular and computationally expensive, HtmlRAG constructs a more manageable block tree. This hierarchical structure groups DOM nodes into blocks, allowing for a more efficient pruning strategy that minimizes information loss. The pruning process is a two-stage approach; the first leverages a text embedding model to prune coarse-grained blocks based on their relevance to the user query, while the second stage employs a generative model to refine the pruning process at a finer granularity. This two-step process balances computational cost and effectiveness, ensuring that crucial semantic information is retained. The generative model, in particular, proves invaluable in handling finer-grained blocks that might be overlooked by the embedding model, resulting in a more accurate and concise HTML representation suitable for processing by LLMs. The whole approach highlights the benefits of maintaining HTML’s structural information, ultimately enhancing LLM performance and reducing the risk of hallucinations.
Experimental Results#
The ‘Experimental Results’ section of a research paper is crucial for demonstrating the validity and effectiveness of the proposed approach. A strong presentation would involve a clear comparison of the novel method (e.g., HtmlRAG) against several established baselines across multiple datasets. Quantitative metrics, such as Exact Match, Hit@1, ROUGE-L, and BLEU scores, should be reported to enable precise comparisons and highlight statistically significant improvements. It is vital to carefully select datasets representing diverse scenarios and complexities to demonstrate the robustness of the method. The discussion should not just present numbers, but also offer a thorough analysis of trends and patterns, explaining any unexpected results or limitations. Visualizations, such as bar charts or tables, can significantly enhance readability and facilitate the understanding of the results. Finally, a comprehensive discussion on the implications and limitations of the experimental setup is essential for responsible and insightful reporting.
Future Research#
Future research directions stemming from this HtmlRAG work could explore several key areas. First, investigating alternative HTML pruning strategies beyond the two-step approach presented here would be valuable. Exploring more sophisticated methods, potentially incorporating LLMs more deeply into the pruning process itself, might yield better results while maintaining efficiency. Second, extending the framework to handle other document formats beyond HTML is crucial. While HTML is a common format, integrating with PDF, DOCX, and other types would vastly broaden applicability. This would require research into robust conversion methods that minimize information loss. Third, a more thorough investigation into the interplay between HTML structure and LLM understanding is needed. Further analysis could reveal optimal ways to leverage HTML features to improve LLM performance and reduce reliance on extensive pre-processing. Fourth, focus on robustness and generalization. The current study primarily focuses on specific types of QA datasets and search engines. Broadening testing to different data sources, question styles, and LLMs would build stronger confidence and help uncover limitations.
More visual insights#
More on tables
| Method | ASQA Hit@1 | ASQA EM | Hotpot-QA Hit@1 | NQ EM | NQ Hit@1 | Trivia-QA EM | Trivia-QA EM | MuSiQue ROUGE-L | ELI5 BLEU | ELI5 |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct-128K | ||||||||||
| Vanilla HTML | 47.75 | 20.08 | 28.75 | 47.25 | 36.09 | 85.00 | 24.85 | 6.00 | 16.13 | 6.28 |
| Plain Text | 61.50 | 27.82 | 39.25 | 59.25 | 44.31 | 94.00 | 28.23 | 7.75 | 16.02 | 6.35 |
| Markdown | 61.75 | 26.70 | 37.50 | 57.50 | 42.85 | 91.50 | 26.67 | 7.50 | 16.12 | 5.91 |
| HtmlRAG w/o Prune | 61.00 | 26.70† | 39.50† | 59.00† | 43.46† | 92.00† | 27.50† | 8.75† | 15.62 | 5.87 |
| Llama-3.1-70B-Instruct-128K | ||||||||||
| Vanilla HTML | 44.00 | 17.52 | 28.00 | 46.75 | 36.06 | 81.50 | 22.58 | 3.25 | 15.69 | 5.16 |
| Plain Text | 59.75 | 25.16 | 41.00 | 59.75 | 44.11 | 93.50 | 26.75 | 8.75 | 16.88 | 7.44 |
| Markdown | 56.00 | 24.00 | 39.00 | 57.00 | 42.00 | 92.00 | 26.43 | 8.25 | 16.91 | 6.74 |
| HtmlRAG w/o Prune | 58.75† | 25.28† | 42.25† | 58.00† | 43.65† | 95.00† | 27.21† | 10.75† | 16.57 | 6.32 |
🔼 Table 2 presents a comparison of HtmlRAG (without pruning) and several baseline methods using long-context settings (128K tokens). The evaluation metrics are Hit@1 (percentage of instances where at least one short answer in the LLM’s output matched the gold standard answers), Exact Match (EM) for short answers, and ROUGE-L and BLEU for long answers. Results across six QA datasets are shown, highlighting the performance of different methods in answering different question types and the statistically significant improvements achieved by HtmlRAG in various metrics.
read the caption
Table 2. Results of HtmlRAG without pruning and baselines under the long-context setting. Hit@1 is the proportion of instances where at least one short answer matches. The best and second best results are in bold and underlined. The symbol ††\dagger† signifies that our method achieves superior results among baselines in a statistically significant manner (t-test, p𝑝pitalic_p-value ¡ 0.05).
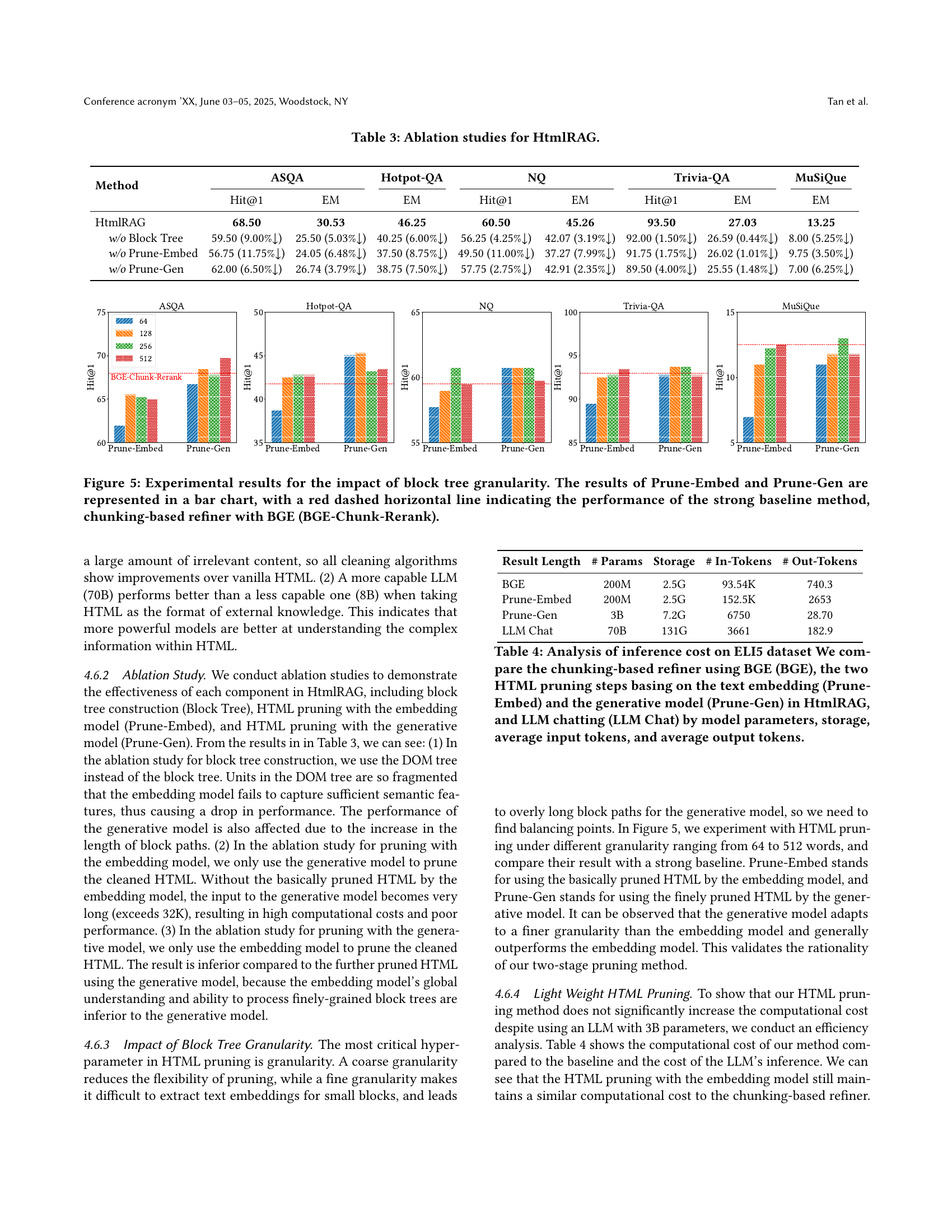
| Method | ASQA Hit@1 | ASQA EM | Hotpot-QA EM | NQ Hit@1 | NQ EM | Trivia-QA Hit@1 | Trivia-QA EM | MuSiQue EM |
|---|---|---|---|---|---|---|---|---|
| HtmlRAG | 68.50 | 30.53 | 46.25 | 60.50 | 45.26 | 93.50 | 27.03 | 13.25 |
| w/o Block Tree | 59.50 (9.00% ↓) | 25.50 (5.03% ↓) | 40.25 (6.00% ↓) | 56.25 (4.25% ↓) | 42.07 (3.19% ↓) | 92.00 (1.50% ↓) | 26.59 (0.44% ↓) | 8.00 (5.25% ↓) |
| w/o Prune-Embed | 56.75 (11.75% ↓) | 24.05 (6.48% ↓) | 37.50 (8.75% ↓) | 49.50 (11.00% ↓) | 37.27 (7.99% ↓) | 91.75 (1.75% ↓) | 26.02 (1.01% ↓) | 9.75 (3.50% ↓) |
| w/o Prune-Gen | 62.00 (6.50% ↓) | 26.74 (3.79% ↓) | 38.75 (7.50% ↓) | 57.75 (2.75% ↓) | 42.91 (2.35% ↓) | 89.50 (4.00% ↓) | 25.55 (1.48% ↓) | 7.00 (6.25% ↓) |
🔼 This table presents the ablation study results for the HtmlRAG model. It shows the impact of removing key components of the model, such as the block tree structure, the text embedding-based pruning, and the generative model-based pruning. By comparing the performance of HtmlRAG with and without each component, we can understand the individual contributions of each component to the overall effectiveness of the system. The results are presented in terms of different metrics across six different question answering datasets.
read the caption
Table 3. Ablation studies for HtmlRAG.
| Result Length | # Params | Storage | # In-Tokens | # Out-Tokens |
|---|---|---|---|---|
| BGE | 200M | 2.5G | 93.54K | 740.3 |
| Prune-Embed | 200M | 2.5G | 152.5K | 2653 |
| Prune-Gen | 3B | 7.2G | 6750 | 28.70 |
| LLM Chat | 70B | 131G | 3661 | 182.9 |
🔼 Table 4 compares the computational resource requirements and the performance of four different methods for processing text in a Retrieval Augmented Generation (RAG) system using the ELI5 dataset. The methods compared are: a chunking-based refiner using the BGE embedding model (BGE), the text embedding-based pruning step (Prune-Embed), the generative model-based pruning step (Prune-Gen), both from the HtmlRAG method, and using a Large Language Model directly for chatting (LLM Chat). The comparison is based on model parameters, storage space used, average number of input tokens, and average number of output tokens.
read the caption
Table 4. Analysis of inference cost on ELI5 dataset We compare the chunking-based refiner using BGE (BGE), the two HTML pruning steps basing on the text embedding (Prune-Embed) and the generative model (Prune-Gen) in HtmlRAG, and LLM chatting (LLM Chat) by model parameters, storage, average input tokens, and average output tokens.
Full paper#