↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multimodal LLMs (MLLMs) show impressive performance but suffer from data contamination during training, affecting benchmark reliability and fair comparisons. Existing detection methods for single-modal LLMs are ineffective for MLLMs due to their multiple training phases and different modalities. This poses challenges in assessing the true performance of MLLMs and hinders progress in the field.
The paper introduces MM-Detect, a novel framework designed to detect contamination in MLLMs. It uses two innovative methods (Option Order Sensitivity Test and Slot Guessing for Perturbation Captions) to detect different types of contamination. MM-Detect is evaluated on various MLLMs across several datasets, showcasing its effectiveness in identifying contamination from various sources (pre-training, fine-tuning, and test data). The research reveals that contamination significantly enhances model performance on test sets. Furthermore, MM-Detect reveals potential contamination sources beyond multimodal training, originating from the pre-training phase of the LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because data contamination significantly impacts the reliability of multimodal large language model (MLLM) benchmarks and model evaluations. The proposed MM-Detect framework directly addresses this critical issue, offering a novel approach to detect contamination in MLLMs. This work enhances the trustworthiness of MLLM research and opens avenues for improving model training and evaluation methods. The findings are highly relevant to researchers working on MLLMs, model evaluation, and data quality assurance. It encourages more rigorous evaluation practices and better data management strategies within the field.
Visual Insights#

🔼 The figure is composed of two parts. The left part illustrates the concept of multimodal data contamination in large language models (LLMs). It shows how contamination can originate from two sources: unimodal contamination (pure text pre-training data) and cross-modal contamination (multimodal post-training data). Both sources can lead to contamination accumulation, affecting the performance and fairness of the MLLMs. The right part provides an overview of the proposed MM-Detect framework, which is designed to detect such contamination. The framework consists of two main steps: generation of perturbed datasets using two novel methods (Option Order Sensitivity Test and Slot Guessing for Perturbation Captions), and detection of contamination using atomic metrics. Different components are visually represented, including the input (VQA benchmark samples), data perturbation methods, the MLLM under testing, and the output (results evaluated using atomic metrics).
read the caption
Figure 1: A description of Multimodal Data Contamination (left) and the overview of proposed MM-Detect framework (right).
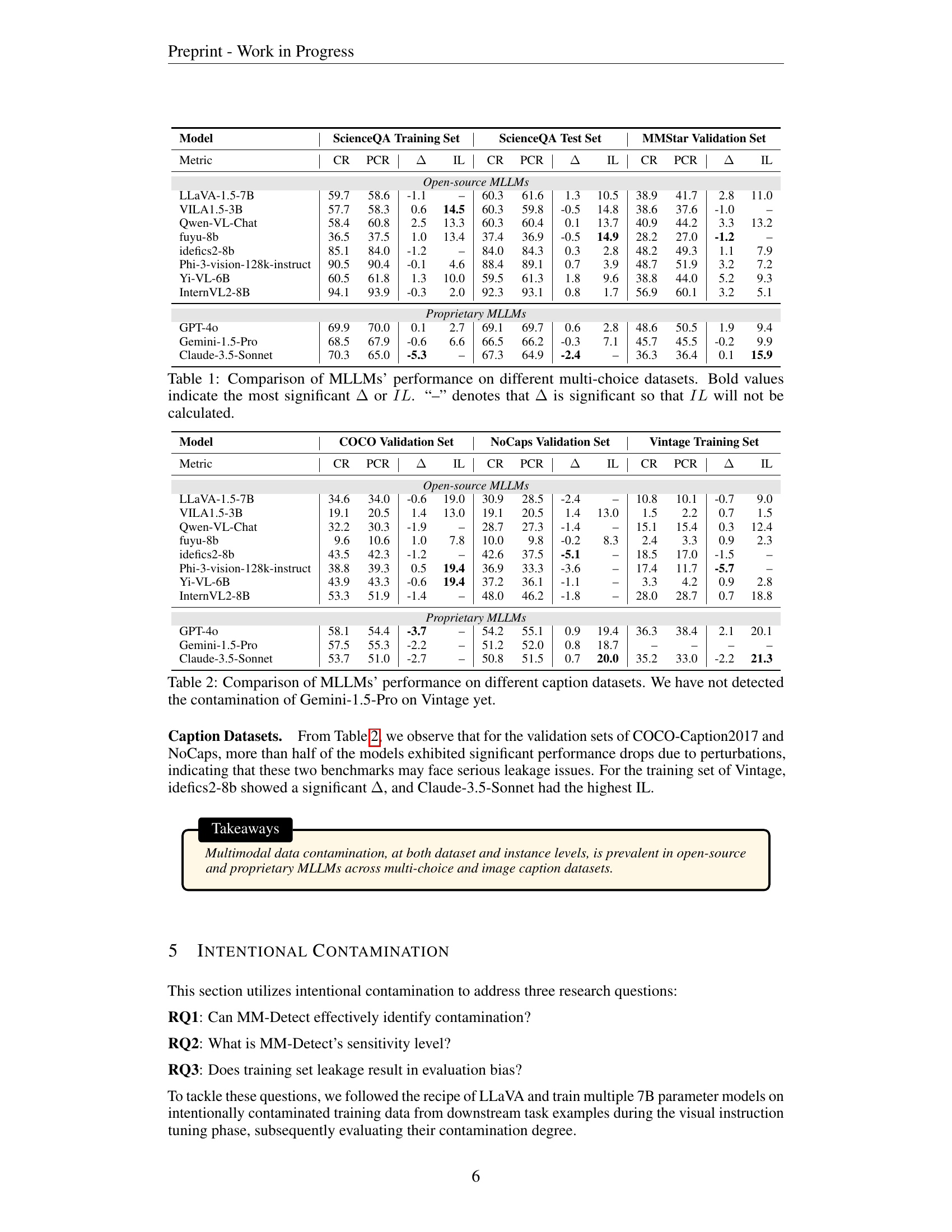
| Model | ScienceQA Training Set | ScienceQA Test Set | MMStar Validation Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | CR | PCR | Δ | IL | CR | PCR | Δ | IL | CR | PCR | Δ | IL |
| Open-source MLLMs | ||||||||||||
| LLaVA-1.5-7B | 59.7 | 58.6 | -1.1 | – | 60.3 | 61.6 | 1.3 | 10.5 | 38.9 | 41.7 | 2.8 | 11.0 |
| VILA1.5-3B | 57.7 | 58.3 | 0.6 | 14.5 | 60.3 | 59.8 | -0.5 | 14.8 | 38.6 | 37.6 | -1.0 | – |
| Qwen-VL-Chat | 58.4 | 60.8 | 2.5 | 13.3 | 60.3 | 60.4 | 0.1 | 13.7 | 40.9 | 44.2 | 3.3 | 13.2 |
| fuyu-8b | 36.5 | 37.5 | 1.0 | 13.4 | 37.4 | 36.9 | -0.5 | 14.9 | 28.2 | 27.0 | -1.2 | – |
| idefics2-8b | 85.1 | 84.0 | -1.2 | – | 84.0 | 84.3 | 0.3 | 2.8 | 48.2 | 49.3 | 1.1 | 7.9 |
| Phi-3-vision-128k-instruct | 90.5 | 90.4 | -0.1 | 4.6 | 88.4 | 89.1 | 0.7 | 3.9 | 48.7 | 51.9 | 3.2 | 7.2 |
| Yi-VL-6B | 60.5 | 61.8 | 1.3 | 10.0 | 59.5 | 61.3 | 1.8 | 9.6 | 38.8 | 44.0 | 5.2 | 9.3 |
| InternVL2-8B | 94.1 | 93.9 | -0.3 | 2.0 | 92.3 | 93.1 | 0.8 | 1.7 | 56.9 | 60.1 | 3.2 | 5.1 |
| Proprietary MLLMs | ||||||||||||
| GPT-4o | 69.9 | 70.0 | 0.1 | 2.7 | 69.1 | 69.7 | 0.6 | 2.8 | 48.6 | 50.5 | 1.9 | 9.4 |
| Gemini-1.5-Pro | 68.5 | 67.9 | -0.6 | 6.6 | 66.5 | 66.2 | -0.3 | 7.1 | 45.7 | 45.5 | -0.2 | 9.9 |
| Claude-3.5-Sonnet | 70.3 | 65.0 | -5.3 | – | 67.3 | 64.9 | -2.4 | – | 36.3 | 36.4 | 0.1 | 15.9 |
🔼 This table presents a comparison of the performance of various Multimodal Large Language Models (MLLMs) on two different multi-choice datasets: ScienceQA and MMStar. For each MLLM and dataset, the table shows the Correct Rate (CR) before and after applying a perturbation, the Perturbed Correct Rate (PCR), the difference between them (Δ), and the Instance Leakage (IL). The Δ value indicates the change in accuracy due to the perturbation, revealing the model’s sensitivity to potential data contamination. A large negative Δ value indicates a high level of contamination. The IL metric, calculated only when the Δ value is not significant, represents the proportion of instances where the model was correct before perturbation but incorrect after. A higher IL value also points to contamination. The ‘-’ symbol indicates that the Δ value was significant, making the IL calculation unnecessary. The table helps analyze the level of data contamination in different MLLMs and datasets. The bold values indicate the most significant Δ or IL for each dataset.
read the caption
Table 1: Comparison of MLLMs’ performance on different multi-choice datasets. Bold values indicate the most significant ΔΔ\Deltaroman_Δ or IL𝐼𝐿ILitalic_I italic_L. “–” denotes that ΔΔ\Deltaroman_Δ is significant so that IL𝐼𝐿ILitalic_I italic_L will not be calculated.
In-depth insights#
MM-Detect Framework#
The MM-Detect framework, designed for detecting data contamination in Multimodal Large Language Models (MLLMs), is a significant contribution because it addresses the limitations of existing methods. Its innovative approach tackles the unique challenges posed by the multi-modality and multi-stage training of MLLMs. By incorporating two novel methods – Option Order Sensitivity Test and Slot Guessing for Perturbation Captions – MM-Detect offers a nuanced approach to contamination detection tailored to different VQA task types (multiple-choice and caption-based). The framework’s sensitivity to varying contamination degrees is a key strength, as it enables a more granular understanding of the extent of contamination. Furthermore, its exploration into contamination origins, examining pre-training and fine-tuning phases, offers valuable insights into the contamination lifecycle within MLLMs. This is crucial for developing effective mitigation strategies. The framework’s evaluation using atomic metrics at both dataset and instance levels ensures a comprehensive assessment, enhancing its reliability and impact on the field of MLLM development and evaluation.
Multimodal Contamination#
Multimodal contamination, in the context of large language models (LLMs), presents a unique challenge due to the interaction of various data modalities during training. Unlike unimodal contamination (text-only or image-only), multimodal contamination involves the leakage of training data encompassing both text and visual elements. This presents more complex challenges in detection, because traditional methods designed for single modalities often fail to capture the nuanced interplay of text and image data. The paper highlights the sensitivity of model performance to the degree and type of contamination, suggesting even small amounts of contamination can significantly inflate performance metrics. The source of contamination is also crucial, as it can originate from both pre-training phases (where foundational LLMs may already have encountered similar data), and fine-tuning phases (where MLLMs are specifically trained on multimodal datasets). This necessitates a multi-faceted approach to contamination detection, one that accounts for the interaction of modalities and the different training stages, as exemplified by the proposed MM-Detect framework. The impact on benchmarking and fair comparison of MLLMs underscores the necessity for robust contamination detection methods, particularly given the opaque nature of many LLM training processes.
Intentional Contamination#
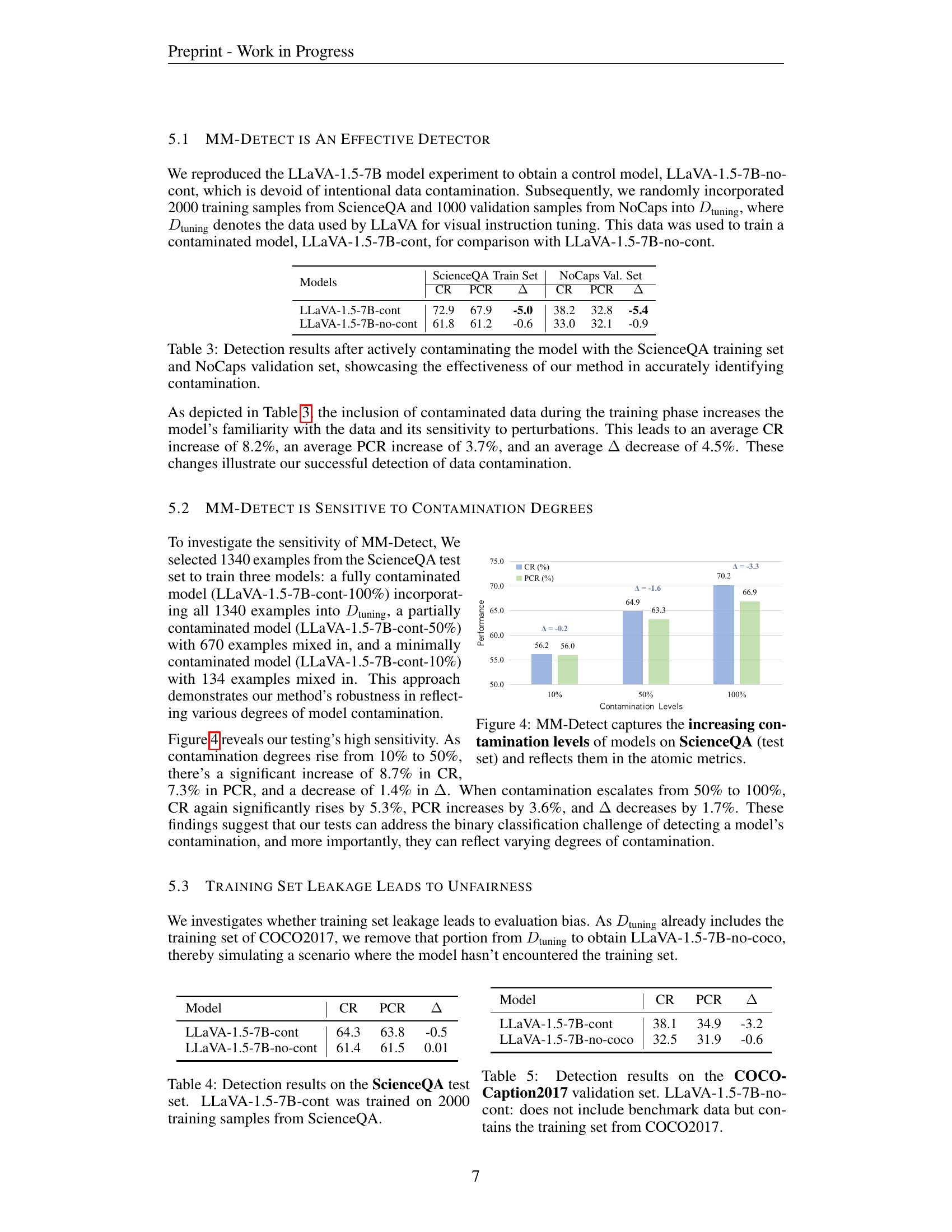
The section on “Intentional Contamination” likely details experiments where the researchers deliberately introduced known contamination into the training data of multimodal LLMs. This is a crucial methodology for validating the effectiveness of their proposed MM-Detect framework. By controlling the degree and type of contamination, they can precisely assess the sensitivity of MM-Detect in identifying and quantifying contamination. The results from these controlled experiments would demonstrate whether MM-Detect can accurately pinpoint the introduced contamination, regardless of its magnitude or source (training set or test set leakage). Furthermore, this section may explore the impact of intentional contamination on various model performance metrics, establishing a baseline understanding of how data contamination affects the model output. This approach allows the researchers to go beyond simply detecting contamination and investigate the implications of contamination for downstream model performance. The experiments likely involve varying degrees of contamination, testing the detection limits of MM-Detect. This rigorous testing enhances the reliability and robustness of the conclusions, providing stronger evidence for the framework’s validity and practicality. The section might conclude by discussing potential implications of the findings for building more resilient and robust multimodal LLMs.
Contamination Sources#
The study’s exploration of contamination sources is insightful, revealing that data leakage isn’t limited to the MLLM’s fine-tuning phase, but can originate from earlier pre-training stages of the underlying LLMs. This finding significantly complicates the problem, as it suggests that the issue isn’t simply a matter of careful dataset curation for the MLLM’s specific training, but also necessitates examination of the vast pre-training data used to build the foundation models. The analysis of contamination across different model architectures and benchmark datasets reinforces this complexity. The researchers demonstrate that different models exhibit varying degrees of susceptibility, highlighting the need for a nuanced approach to detection and mitigation strategies tailored to individual models and training pipelines. The study underscores the importance of a comprehensive analysis, moving beyond simplistic views of contamination and investigating how it might originate from both unimodal and multimodal sources at different stages of the MLLM development lifecycle. This comprehensive analysis emphasizes that future research should focus on tracing contamination throughout the entire training process, from initial data collection to final model deployment, necessitating a more holistic approach towards ensuring data integrity and reliability in MLLM development.
Future Work#
The authors outline crucial future directions. Standardizing multimodal datasets and transparently reporting contamination levels are paramount. This would enable more reliable benchmarking and fairer comparisons between models. Creating a dynamic, continuously updated system for evaluating models is also key. This would allow the community to track progress over time and address emerging contamination issues proactively. Addressing the limitations of the current work, such as expanding beyond visual modalities and incorporating a broader range of benchmarks, will significantly enhance the framework’s generality and impact. Finally, investigating how contamination interacts with different model architectures and training techniques will be important for developing robust defenses and improving model robustness.
More visual insights#
More on figures

🔼 This figure illustrates the Option Order Sensitivity Test, a method used to detect contamination in models. It shows two versions of a multiple-choice question. The first shows the original order of options, and the second shows the options in a shuffled order. A contaminated model, having memorized the correct answer’s position in the original order, will likely produce a different answer when the order is shuffled. This difference highlights potential data contamination.
read the caption
Figure 2: An example of Option Order Sensitivity Test applied to a contaminated model.

🔼 This figure illustrates the Slot Guessing for Perturbation Caption method used in the MM-Detect framework. It shows an example where a caption describing an image is back-translated (e.g., from English to Chinese and back to English), and then key words are masked. The model is then tested to see if it can predict the masked words. The ability of the model to predict the masked words in the original caption, but not in the back-translated version, suggests that the model may have memorized the original caption during training, indicating potential data contamination.
read the caption
Figure 3: An example of Slot Guessing for Perturbation Caption.

🔼 Figure 4 illustrates the sensitivity of the MM-Detect framework to varying degrees of data contamination. Three versions of the LLaVA-1.5-7B model were trained, each with a different level of contamination from the ScienceQA test set (10%, 50%, and 100%). The graph shows how the correct rate (CR) and perturbed correct rate (PCR) change with the increasing contamination levels. The difference between CR and PCR (Δ), a key metric in MM-Detect, also decreases as contamination increases. This demonstrates that MM-Detect effectively captures the extent of data contamination and reflects this contamination in its atomic metrics. The figure provides visual evidence supporting the claim that MM-Detect is not just a binary contamination detector but can also quantify the degree of contamination.
read the caption
Figure 4: MM-Detect captures the increasing contamination levels of models on ScienceQA (test set) and reflects them in the atomic metrics.
More on tables
| Model | COCO Validation Set | NoCaps Validation Set | Vintage Training Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | CR | PCR | Δ | IL | CR | PCR | Δ | IL | CR | PCR | Δ | IL |
| Open-source MLLMs | ||||||||||||
| LLaVA-1.5-7B | 34.6 | 34.0 | -0.6 | 19.0 | 30.9 | 28.5 | -2.4 | – | 10.8 | 10.1 | -0.7 | 9.0 |
| VILA-1.5-3B | 19.1 | 20.5 | 1.4 | 13.0 | 19.1 | 20.5 | 1.4 | 13.0 | 1.5 | 2.2 | 0.7 | 1.5 |
| Qwen-VL-Chat | 32.2 | 30.3 | -1.9 | – | 28.7 | 27.3 | -1.4 | – | 15.1 | 15.4 | 0.3 | 12.4 |
| fuyu-8b | 9.6 | 10.6 | 1.0 | 7.8 | 10.0 | 9.8 | -0.2 | 8.3 | 2.4 | 3.3 | 0.9 | 2.3 |
| idefics2-8b | 43.5 | 42.3 | -1.2 | – | 42.6 | 37.5 | -5.1 | – | 18.5 | 17.0 | -1.5 | – |
| Phi-3-vision-128k-instruct | 38.8 | 39.3 | 0.5 | 19.4 | 36.9 | 33.3 | -3.6 | – | 17.4 | 11.7 | -5.7 | – |
| Yi-VL-6B | 43.9 | 43.3 | -0.6 | 19.4 | 37.2 | 36.1 | -1.1 | – | 3.3 | 4.2 | 0.9 | 2.8 |
| InternVL2-8B | 53.3 | 51.9 | -1.4 | – | 48.0 | 46.2 | -1.8 | – | 28.0 | 28.7 | 0.7 | 18.8 |
| Proprietary MLLMs | ||||||||||||
| GPT-4o | 58.1 | 54.4 | -3.7 | – | 54.2 | 55.1 | 0.9 | 19.4 | 36.3 | 38.4 | 2.1 | 20.1 |
| Gemini-1.5-Pro | 57.5 | 55.3 | -2.2 | – | 51.2 | 52.0 | 0.8 | 18.7 | – | – | – | – |
| Claude-3.5-Sonnet | 53.7 | 51.0 | -2.7 | – | 50.8 | 51.5 | 0.7 | 20.0 | 35.2 | 33.0 | -2.2 | 21.3 |
🔼 This table presents a comparison of the performance of various Multimodal Large Language Models (MLLMs) on three different image captioning datasets: COCO-Caption2017, NoCaps, and Vintage. For each MLLM and dataset, the table shows the correct rate (CR) before and after applying a perturbation (PCR), the difference between those two rates (Δ), and a contamination leakage metric (IL). The Δ value helps to determine how sensitive the model is to the perturbation, indicating the presence and extent of data contamination. The IL metric provides a measure of instance-level contamination, showing if individual training examples from the benchmark datasets might have leaked into the model’s training data. Note that contamination for Gemini-1.5-Pro on the Vintage dataset was not detected.
read the caption
Table 2: Comparison of MLLMs’ performance on different caption datasets. We have not detected the contamination of Gemini-1.5-Pro on Vintage yet.
| Models | ScienceQA Train Set | NoCaps Val. Set | ||||
|---|---|---|---|---|---|---|
| CR | PCR | Δ | CR | PCR | Δ | |
| LLaVA-1.5-7B-cont | 72.9 | 67.9 | -5.0 | 38.2 | 32.8 | -5.4 |
| LLaVA-1.5-7B-no-cont | 61.8 | 61.2 | -0.6 | 33.0 | 32.1 | -0.9 |
🔼 This table presents the results of an experiment designed to evaluate the effectiveness of the MM-Detect framework in identifying data contamination. Two versions of the LLaVA-1.5-7B model were trained: one without contamination (LLaVA-1.5-7B-no-cont) and one with contamination introduced by incorporating data from the ScienceQA training set and the NoCaps validation set (LLaVA-1.5-7B-cont). The table displays the correct rate (CR), perturbed correct rate (PCR), and the difference between them (Δ) for both models on the ScienceQA training set and the NoCaps validation set. The results demonstrate the impact of contamination on model performance, and highlight MM-Detect’s ability to detect these performance changes accurately.
read the caption
Table 3: Detection results after actively contaminating the model with the ScienceQA training set and NoCaps validation set, showcasing the effectiveness of our method in accurately identifying contamination.
| Model | CR | PCR | Δ |
|---|---|---|---|
| LLaVA-1.5-7B-cont | 64.3 | 63.8 | -0.5 |
| LLaVA-1.5-7B-no-cont | 61.4 | 61.5 | 0.01 |
🔼 Table 6 presents the contamination rates observed in various Large Language Models (LLMs) that serve as the foundation for several multimodal models. The contamination rate indicates the percentage of image-related questions correctly answered by the LLM without the image being provided. A higher rate suggests a greater likelihood of the LLM having memorized information from the multimodal benchmark datasets during its pre-training phase. The table also includes the instance leakage metric (ILM) for each corresponding multimodal model, which further quantifies the degree of contamination.
read the caption
Table 6: Contamination rates of the LLMs used by multimodal models. ILM denotes the IL of the corresponding MLLMs.
| Model | CR | PCR | Δ |
|---|---|---|---|
| LLaVA-1.5-7B-cont | 38.1 | 34.9 | -3.2 |
| LLaVA-1.5-7B-no-coco | 32.5 | 31.9 | -0.6 |
🔼 Table 7 shows the degree of overlap between the training data used for various Multimodal Large Language Models (MLLMs) and three benchmark datasets: ScienceQA, COCO Captions, and NoCaps. The table also presents the contamination degree (Δ) for each MLLM on each benchmark dataset. The color-coding helps visualize the level of overlap: green indicates no overlap, yellow suggests potential overlap, and red signifies a partial or complete overlap between the MLLM’s training data and the benchmark dataset. This table helps to analyze the sources of contamination in MLLMs, indicating whether contamination might stem from the inclusion of benchmark data during the training process.
read the caption
Table 7: Depiction of the overlap between the training data of MLLMs and the benchmarks, as well as the contamination degree ΔΔ\Deltaroman_Δ of MLLMs on benchmarks. Green signifies no overlap, yellow suggests potential overlap, and Red indicates partial or entire overlap.
| Model | ContRate | ILM |
|---|---|---|
| LLaMA2-7b (LLaVA-1.5 & VILA) | 25.6 | 11.0 |
| Qwen-7B (Qwen-VL) | 13.2 | 13.2 |
| InternLM2-7B (InternVL2) | 11.0 | 5.1 |
| Mistral-7B-v0.1 (idefics2) | 10.7 | 7.9 |
| Phi-3-small-128k-instruct (Phi-3-vision) | 6.1 | 7.2 |
| Yi-6B (Yi-VL) | 3.4 | 9.3 |
🔼 Table 8 presents the perplexity scores achieved by the LLaVA-1.5-13b model on various multimodal benchmark datasets. Perplexity is a measure of how well a probability model predicts a sample. Lower perplexity indicates better prediction accuracy. The table shows the perplexity for both the training and validation sets of four different datasets: ScienceQA, MMStar, COCO-Caption2017, and NoCaps. Each dataset’s perplexity score reflects the model’s performance on that dataset. The results are based on 100 randomly selected samples from each dataset, providing a representative measure of the model’s overall performance on each dataset.
read the caption
Table 8: Perplexity of LLaVA-1.5-13b on various multimodal benchmarks (100 samples randomly selected from each dataset).
| Model | ScienceQA | COCO Caption | Nocaps |
|---|---|---|---|
| Phi-3-Vision | 0.7 | 0.5 | -3.6 |
| VILA | -0.5 | 1.4 | 1.4 |
| Idefics2 | 0.3 | -1.2 | -5.1 |
| LLaVA-1.5 | 1.3 | -0.6 | -2.4 |
| Yi-VL | 1.8 | -0.6 | -1.1 |
| Qwen-VL-Chat | 0.1 | -1.9 | -1.4 |
| InternVL2 | 0.8 | -1.4 | -1.8 |
🔼 This table presents the results of contamination detection experiments using the TS-Guessing method on the LLaVA-1.5-13b model. TS-Guessing is a question-based approach to detecting contamination. The experiment involved evaluating the model’s performance on three different multimodal benchmark datasets: COCO-Caption2017, NoCaps, and ScienceQA. For each dataset, 100 samples were randomly selected to assess the model’s ability to correctly answer questions after the order of options or keywords has been altered. The table displays the model’s performance using Exact Match, ROUGE-L, and F1 scores for each dataset, providing insights into the level of contamination present.
read the caption
Table 9: Contamination detection of LLaVA-1.5-13b using TS-Guessing (question-based) on various multimodal benchmarks (100 samples randomly selected from each dataset).
| Dataset | Perplexity | Split |
|---|---|---|
| ScienceQA | 1.4498 | Training Set |
| MMStar | 1.4359 | Validation Set |
| COCO-Caption2017 | 1.7530 | Validation Set |
| NoCaps | 1.8155 | Validation Set |
🔼 Table 10 presents the results of contamination detection performed on the LLaVA-1.5-13b model using the Contamination Detection via output Distribution (CDD) method. The CDD method assesses contamination by comparing the similarity between a model’s outputs and benchmark data. The table shows the contamination level detected (as a percentage) for three different multimodal benchmark datasets: COCO-Caption2017, NoCaps, and ScienceQA. For each dataset, 100 samples were randomly selected to perform the contamination detection. This table highlights the challenges of using comparison-based methods for contamination detection in multimodal models.
read the caption
Table 10: Contamination detection of LLaVA-1.5-13b using CDD (Contamination Detection via output Distribution) on various multimodal benchmarks (100 samples randomly selected from each dataset).
Full paper#