↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current visual content editing systems often rely on physical interaction which can be cumbersome, especially for users with physical disabilities. Traditional methods also lack personalization and seamless integration, leading to inefficient workflows and suboptimal user experiences. There is a need for more intuitive, accessible and personalized systems that leverage natural human behaviors for visual content creation and manipulation.
GazeGen directly addresses these issues by using real-time gaze estimation to enable intuitive and precise visual content generation. Its core innovation is the DFT Gaze agent, an ultra-lightweight model that provides accurate and personalized gaze predictions on resource-constrained devices. The integration of advanced AI techniques enables a range of gaze-driven editing functions, making visual content creation accessible and efficient for all users, regardless of their physical capabilities. The system’s performance on benchmark datasets proves its effectiveness and versatility.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel gaze-driven visual content generation system, addressing the need for more intuitive and accessible interfaces in AR/VR. Its lightweight model and real-time capabilities open new avenues for research in human-computer interaction and generative AI, particularly in areas such as personalized AR experiences and hands-free design tools. The innovative combination of gaze estimation and content generation paves the way for more immersive and natural interactions with digital environments.
Visual Insights#

🔼 Figure 1 illustrates the GazeGen system, showing the user’s perspective, real-time gaze estimation, and gaze-driven visual content generation. The User’s View shows the user’s visual field and the system’s input. Real-time Gaze Estimation displays the DFT Gaze Agent’s process of predicting gaze, comparing it to ground truth. Gaze-driven Visual Content Generation/Detection demonstrates how predicted gaze drives actions like object editing, detection, and animation creation. GazeGen improves user experience by making visual content generation more accessible and intuitive.
read the caption
Figure 1: GazeGen. (1) User’s View: Overview of the user’s view, setting the context for gaze estimation (input: user’s eye images) and visual editing (inputs: user’s view and predicted gaze point). (2) Real-Time Gaze Estimation: The DFT Gaze Agent (281KB storage) predicts the user’s gaze point (green) aligned with the ground-truth gaze (red). (3) Gaze-Driven Visual Content Generation/Detection: Predicted gaze is used for editing () objects, detecting () objects, or creating animations () based on the user’s focus (). GazeGen sets a new standard for gaze-driven visual content generation, enhancing user experience and positioning users as visual creators.
| Track | Detections |
|---|---|
 |  |
🔼 This table compares the performance of several state-of-the-art generalized gaze estimation methods. The comparison is based on within-dataset evaluation using the AEA and OpenEDS2020 datasets. To ensure a fair comparison, the authors reimplemented the methods, using the same K-means clustering (with 15 groups) and hyperparameter settings as their proposed DFT Gaze method. The table shows the number of parameters, the number of tunable parameters, and the mean angular error (in degrees) achieved by each method on the specified datasets.
read the caption
Table 1: Comparison of state-of-the-art methods for generalized gaze estimation using within-dataset evaluation. To ensure a fair comparison, we reimplement these methods and apply the same K-means clustering with 15 groups as DFT Gaze during training. We follow the original hyperparameter settings specified in these methods.
In-depth insights#
Gaze-driven Editing#
Gaze-driven editing, as presented in the research paper, offers a novel approach to visual content manipulation. The system leverages real-time gaze tracking to allow for intuitive and precise control, eliminating the need for traditional input devices. This method allows for seamless addition, deletion, and repositioning of objects within an image or video. The use of AI-powered object detection and generative models enables the system to understand user intent from their gaze, significantly enhancing the speed and ease of visual content creation and editing. Personalization features adapt to individual user’s gaze patterns, increasing the accuracy and user experience. While promising, there are limitations. Issues with lighting, closed eyes, and the accuracy of object 3D spatial understanding present challenges. Overall, gaze-driven editing, using the described techniques, presents a potential paradigm shift in visual content creation. It’s a significant advancement in accessibility and ease of use, particularly for individuals with physical limitations.
Lightweight Gaze#
The concept of “Lightweight Gaze” in the context of a gaze-estimation system for visual content generation is crucial for real-time performance and resource efficiency. A lightweight model, as opposed to a large, computationally expensive one, is essential for deployment on devices with limited processing power, such as mobile phones, AR/VR headsets, or embedded systems. The benefits of a lightweight gaze estimation model include reduced latency, lower power consumption, and smaller storage footprint. This is particularly important in interactive applications, where fast and responsive gaze tracking is crucial for a seamless user experience. The tradeoff, however, is a potential decrease in accuracy. Careful model design and training techniques, such as knowledge distillation and model compression, are necessary to minimize this accuracy loss while maintaining the desired lightness. Therefore, a thoughtful design and appropriate evaluation metrics are important to consider when creating such a “Lightweight Gaze” model to ensure it meets the performance demands of the application without sacrificing the user’s overall experience.
Diffusion in AR#
Augmented reality (AR) overlays digital information onto the real world, creating immersive experiences. Diffusion models, known for their ability to generate realistic images and videos from noise, are a natural fit for AR applications. The core idea is to leverage the user’s gaze, captured in real-time via a gaze estimation system, to specify regions of interest within the AR scene. These selected areas can then be modified using diffusion processes; for example, adding new objects, changing textures, or removing existing elements. The result is an intuitive, gaze-controlled system for generating and manipulating visual content within the AR environment. Real-time performance is crucial; diffusion models must be lightweight and efficient enough to ensure a seamless user experience. Personalization is another key aspect; the system should adapt to individual user’s gaze patterns for optimal accuracy. Challenges remain, however, especially in handling occlusions, lighting variations, and ensuring the generated content remains consistent with the surrounding real-world environment. The integration of diffusion models into AR paves the way for highly intuitive and immersive applications.
Model Distillation#
Model distillation, in the context of the research paper, is a crucial technique for creating a lightweight, efficient gaze estimation model. The process involves transferring knowledge from a large, complex teacher model (ConvNeXt V2-A) to a smaller, more efficient student model (DFT Gaze). This is achieved through self-supervised learning and a masked autoencoder approach. The smaller model maintains a high level of accuracy while drastically reducing computational demands, making it ideal for real-time applications on resource-constrained edge devices. This efficiency is paramount for the real-time gaze tracking essential to the functionality of GazeGen. The use of adapters further enhances performance by fine-tuning the student model to individual users’ gaze patterns, ensuring accurate, personalized predictions. Overall, model distillation is a key innovation enabling GazeGen’s real-time performance and broad accessibility.
System Limits#
The system’s limitations primarily revolve around real-time gaze estimation, particularly concerning lighting conditions and closed eyes. Bright spots or glare from reflective surfaces can confuse the gaze estimation model, leading to inaccurate predictions. Similarly, the system struggles when eyes are closed due to the lack of visible features needed for precise gaze tracking. Addressing these limitations might involve integrating improved image preprocessing techniques to mitigate the effects of glare and exploring alternative methods that can provide estimations even with eyes closed. Furthermore, the visual content generation aspect faces challenges in accurately representing the 3D angles and orientations of objects being manipulated or added. This could lead to visual inconsistencies in the generated scenes. Improving the integration of 3D modeling and perspective correction techniques would enhance the realism and accuracy of the visual editing. The system relies on advanced models like MLLM and FastSAM, whose performance also contributes to system limitations.
More visual insights#
More on figures

🔼 Figure 2 illustrates the four main applications enabled by GazeGen’s gaze-driven user interaction. It showcases real-time gaze tracking for precise estimation (1), object detection based on gaze direction (2), dynamic image manipulation through gaze-controlled addition, deletion, replacement, repositioning, and material transfer (3), and finally, gaze-driven video generation and manipulation (4).
read the caption
Figure 2: Extended applications of gaze-driven interaction with GazeGen. (1) Real-Time Gaze Estimation: Continuous tracking of eye movements for precise gaze estimation. (2) Gaze-Driven Detection: Detecting and identifying objects based on where the user is looking. (3) Gaze-Driven Image Editing: Dynamic editing tasks such as Addition (adding objects based on the user’s gaze), Deletion/Replacement (removing or replacing objects based on the user’s gaze), Reposition (move objects by first gazing at the initial position, then the new position), and Material Transfer (change an object’s style or texture by first gazing at a reference object, then applying the style to the target object). (4) Gaze-Driven Video Generation: Creating and manipulating video content driven by the user’s gaze.

🔼 This figure illustrates the GazeGen system’s workflow for gaze-driven visual content generation. It begins with the user’s eye image, which is processed by a gaze estimation agent to pinpoint the user’s gaze. This gaze point then defines an editing region, selectable as either a box or a mask. The selected region and the user’s gaze are then fed into Text-to-Image (T2I) and Text-to-Video (T2V) modules which generate new visual content based on that selected region. The user can switch between box and mask selection using On/Off toggles, providing flexibility in the editing process.
read the caption
Figure 3: Gaze-driven visual content generation. This diagram shows the process starting from the user’s eye, where the gaze estimation agent determines the gaze point. The gaze point is used to get the editing region, which can be toggled to use either a box or a mask. The T2I (Text-to-Image) and T2V (Text-to-Video) modules then generate visual content based on the selected editing region. The On/Off switches indicate whether the box or mask is used for gaze-driven editing.

🔼 This figure illustrates the process of self-supervised knowledge distillation used to create a compact gaze estimation model. A large, complex teacher model (ConvNeXt V2-A) is used to train a smaller, faster student model. The student model’s architecture is simplified by reducing the channel dimensions in later stages. Importantly, the student model learns to reconstruct both the original input images and the intermediate feature representations from the teacher network. This dual reconstruction process allows the student model to mimic the teacher’s understanding of visual data without needing to train on the same large dataset. The diagram simplifies the visualization by focusing only on the feature reconstruction aspect of the process.
read the caption
Figure 4: Self-supervised distillation for a compact model. Using ConvNeXt V2-A (Woo et al. 2023) as the teacher network, we create a downsized student network. The first stage of the student model inherits weights from the teacher, while stages 2 to 4 reduce the channel dimensions to one-fourth. Distinct decoders are used to reconstruct both input images and the teacher’s intermediate features. The student processes masked inputs, allowing it to emulate the teacher’s deep understanding of visual data and align with how the teacher perceives and interprets these images. For simplicity, the diagram only illustrates the reconstruction of the teacher’s features to emulate knowledge.

🔼 Figure 5 presents qualitative results obtained using the AEA dataset. The first row shows images of a user’s eye. The second row displays two key aspects: on the left, real-time eye tracking showing the user’s gaze; on the right, objects being detected based on the user’s gaze, with the predicted gaze highlighted in green and the ground-truth gaze in red. For a more dynamic viewing experience, the authors suggest viewing the figure using Acrobat Reader, where clicking on the images will play embedded animations.
read the caption
Figure 5: Qualitative results on AEA dataset. First row: user’s eye. Second row: eye tracking (left) and gaze-driven object detection (right). Predicted gaze (green), ground-truth gaze (red). Best viewed in Acrobat Reader; click images to play animations.
![]()
🔼 Figure 6 presents qualitative results demonstrating gaze-driven image editing capabilities. The figure showcases four distinct types of image manipulations controlled solely by the user’s gaze: Addition involves adding new objects (like a lantern, basket, or photo) to the scene. Deletion/Replacement allows for replacing existing objects with entirely different ones (a curtain replacing a window, an aquarium replacing a bookshelf, or a galaxy replacing a painting). Reposition enables users to move objects within the scene simply by gazing at the desired new location (for example, shifting wall decorations, books, or a phone to a different corner). Lastly, Material Transfer lets users change the texture or material appearance of objects (e.g., applying the texture of polished wood to a fridge, woven wicker to a washing machine, or polished metal to a cutting board). All actions are directly driven by the user’s gaze, providing an intuitive and hands-free method of image editing.
read the caption
Figure 6: Qualitative results for gaze-driven image editing. The tasks include: Addition (first row): Adding objects like a lantern, basket, or photo. Deletion/Replacement (second row): Replacing objects with items like a curtain, aquarium, or galaxy. Reposition (third row): Moving objects such as a wall decoration to the upper left corner, books to the lower left corner, or a phone upward. Material Transfer (last row): Changing an object’s style, such as polished wood to the fridge, woven wicker to the washing machine, or polished metal to the chopping board. All edits are based on the user’s gaze.
![]()
🔼 Figure 7 showcases the dynamic video generation capabilities of GazeGen. The system replaces static objects within a scene with animated counterparts, driven entirely by the user’s gaze. Four examples are presented: a river, a starry night sky, a vibrant aquarium, and a tranquil underwater scene. Each image shows how GazeGen interprets the user’s gaze and seamlessly integrates animated replacements, illustrating its real-time responsiveness and ability to produce engaging visual content. The animation effect is best observed using Acrobat Reader.
read the caption
Figure 7: Qualitative results for gaze-driven video generation. Objects are replaced based on users’ gaze with animated objects. Best viewed in Acrobat Reader; click images to play animations. Zoom in for a better view.

🔼 This figure showcases the performance comparison of two gaze estimation models, ConvNeXt V2-A and DFT Gaze, on a Raspberry Pi 4. ConvNeXt V2-A, the larger model, exhibits a latency of 928.84 milliseconds (ms), while DFT Gaze, a smaller model, achieves a significantly reduced latency of 426.66 ms. The comparison highlights the efficiency of the DFT Gaze model for real-time applications on resource-constrained devices like the Raspberry Pi 4.
read the caption
Figure 8: Model latency comparison on Raspberry Pi 4. The figure compares the latency of two gaze estimation models: ConvNeXt V2-A (Teacher) and DFT Gaze (Student). ConvNeXt V2-A shows a latency of 928.84 ms, while DFT Gaze reduces latency to 426.66 ms, demonstrating its efficiency for real-time applications on edge devices.
More on tables
| (Eye Tracking) | (Object Detection) |
|---|
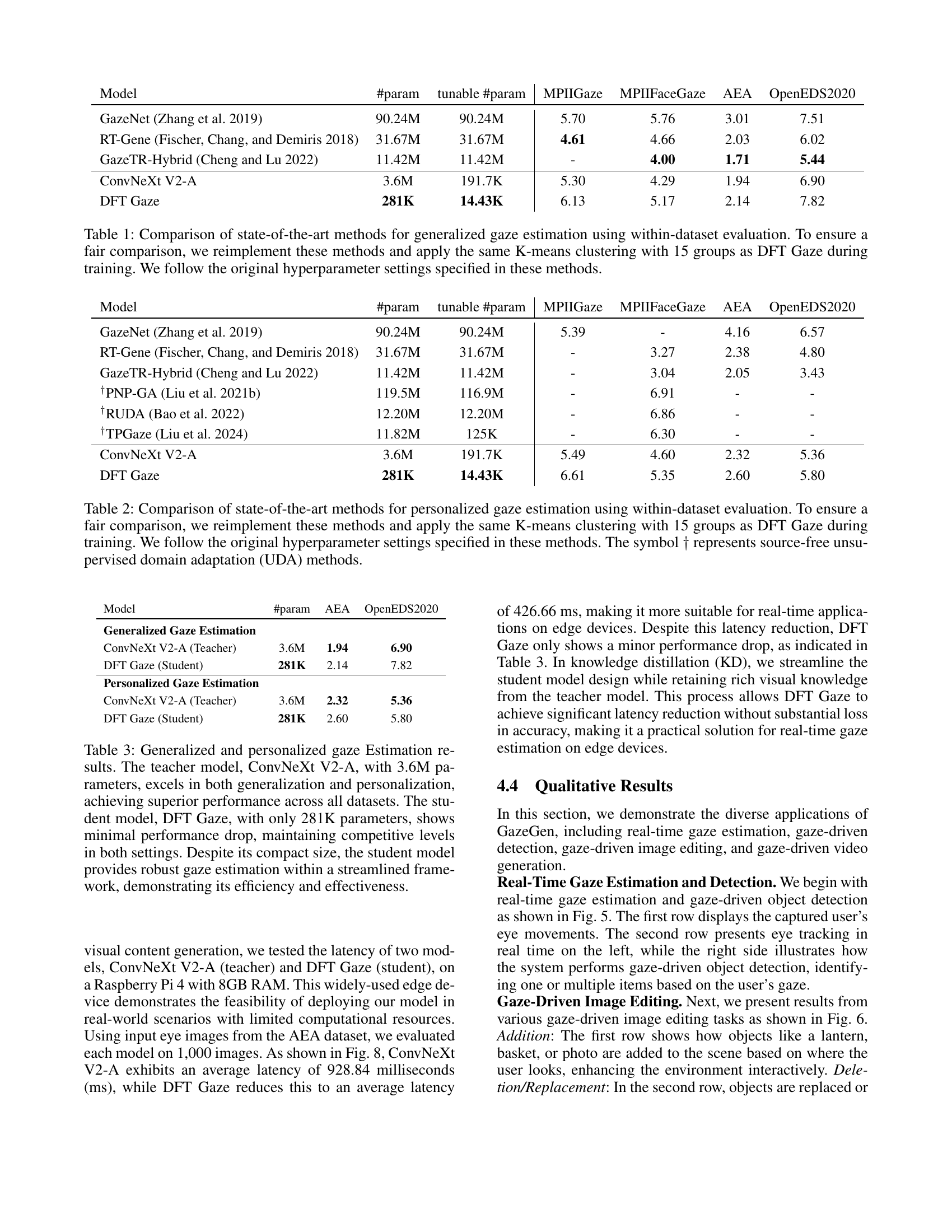
🔼 This table compares the performance of several state-of-the-art methods for personalized gaze estimation. The methods were re-implemented to ensure a fair comparison by using the same K-means clustering (15 groups) and hyperparameters as the DFT Gaze method. Results are shown for the within-dataset evaluation. The dagger symbol (†) indicates methods that utilize source-free unsupervised domain adaptation (UDA). The table facilitates a quantitative assessment of DFT Gaze’s performance relative to existing techniques in personalized gaze estimation.
read the caption
Table 2: Comparison of state-of-the-art methods for personalized gaze estimation using within-dataset evaluation. To ensure a fair comparison, we reimplement these methods and apply the same K-means clustering with 15 groups as DFT Gaze during training. We follow the original hyperparameter settings specified in these methods. The symbol ††\dagger† represents source-free unsupervised domain adaptation (UDA) methods.
🔼 This table presents a comparison of the performance of two gaze estimation models: the teacher model (ConvNeXt V2-A) and the student model (DFT Gaze). It shows the mean angular error (in degrees) for both generalized (trained on a large, general dataset) and personalized (fine-tuned on a small, user-specific dataset) gaze estimation on two benchmark datasets (AEA and OpenEDS2020). The results demonstrate that the significantly smaller student model (DFT Gaze, 281K parameters) achieves comparable accuracy to the larger teacher model (ConvNeXt V2-A, 3.6M parameters) in both generalized and personalized settings, highlighting its efficiency and robustness.
read the caption
Table 3: Generalized and personalized gaze Estimation results. The teacher model, ConvNeXt V2-A, with 3.6M parameters, excels in both generalization and personalization, achieving superior performance across all datasets. The student model, DFT Gaze, with only 281K parameters, shows minimal performance drop, maintaining competitive levels in both settings. Despite its compact size, the student model provides robust gaze estimation within a streamlined framework, demonstrating its efficiency and effectiveness.
Full paper#