↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Fine-tuning large language models (LLMs) is crucial for enhancing their performance but often involves redundant data, increasing computational costs. Existing methods usually focus on a single optimization stage and can be computationally expensive. This poses a significant challenge for efficient and effective LLM adaptation. Researchers need an efficient method to select optimal subsets that are useful across all stages of fine-tuning.
DELIFT addresses these issues by systematically optimizing data selection across all three key stages of fine-tuning using a novel pairwise utility metric. This metric quantifies how beneficial a data sample is for improving the model’s performance on other samples. Leveraging submodular functions, DELIFT efficiently selects diverse and optimal data subsets across different fine-tuning stages. Experimental results show that DELIFT reduces fine-tuning data size by up to 70% without compromising performance, providing significant computational savings and outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in natural language processing and machine learning because it offers a novel and efficient solution to the problem of data redundancy in large language model fine-tuning. Its findings directly address the high computational cost of LLM training and offer significant time and resource savings. The proposed method is versatile and easily adaptable to various tasks and model sizes, making it a valuable tool for researchers in diverse areas. The method’s effectiveness opens up new research avenues for optimizing data selection and improving efficiency in LLM training. The provided codebase facilitates broader adoption and further investigation into this vital area of AI research.
Visual Insights#
| Dimension | Score of 1 | Score of 2 | Score of 3 | Score of 4 | Score of 5 |
|---|---|---|---|---|---|
| Instruction Following | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Accuracy | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Relevance | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Completeness | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Depth | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Clarity | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Creativity | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
| Helpfulness | The response fails to meet expectations across most or all criteria. It does not follow the instruction, contains significant errors or misinformation, lacks relevance, is incomplete or shallow, unclear, unoriginal, and unhelpful. | The response shows major deficiencies across several criteria. It partially follows the instruction but includes significant inaccuracies, is often irrelevant, incomplete, or lacks depth, clarity, creativity, and helpfulness. | The response is average, meeting some but not all criteria. It follows the instruction but may fall short in terms of accuracy, depth, relevance, or helpfulness. Improvements in clarity and insightfulness may be needed. | The response is strong, performing well across most criteria. It follows the instruction closely, is mostly accurate and relevant, provides good depth, and is well-structured. Minor improvements could enhance clarity, creativity, or helpfulness. | The response excels in all or nearly all criteria. It fully follows the instruction, is highly accurate, directly relevant, complete, and demonstrates depth and insight. The response is well-organized, creative where appropriate, and very helpful in addressing the user’s needs. |
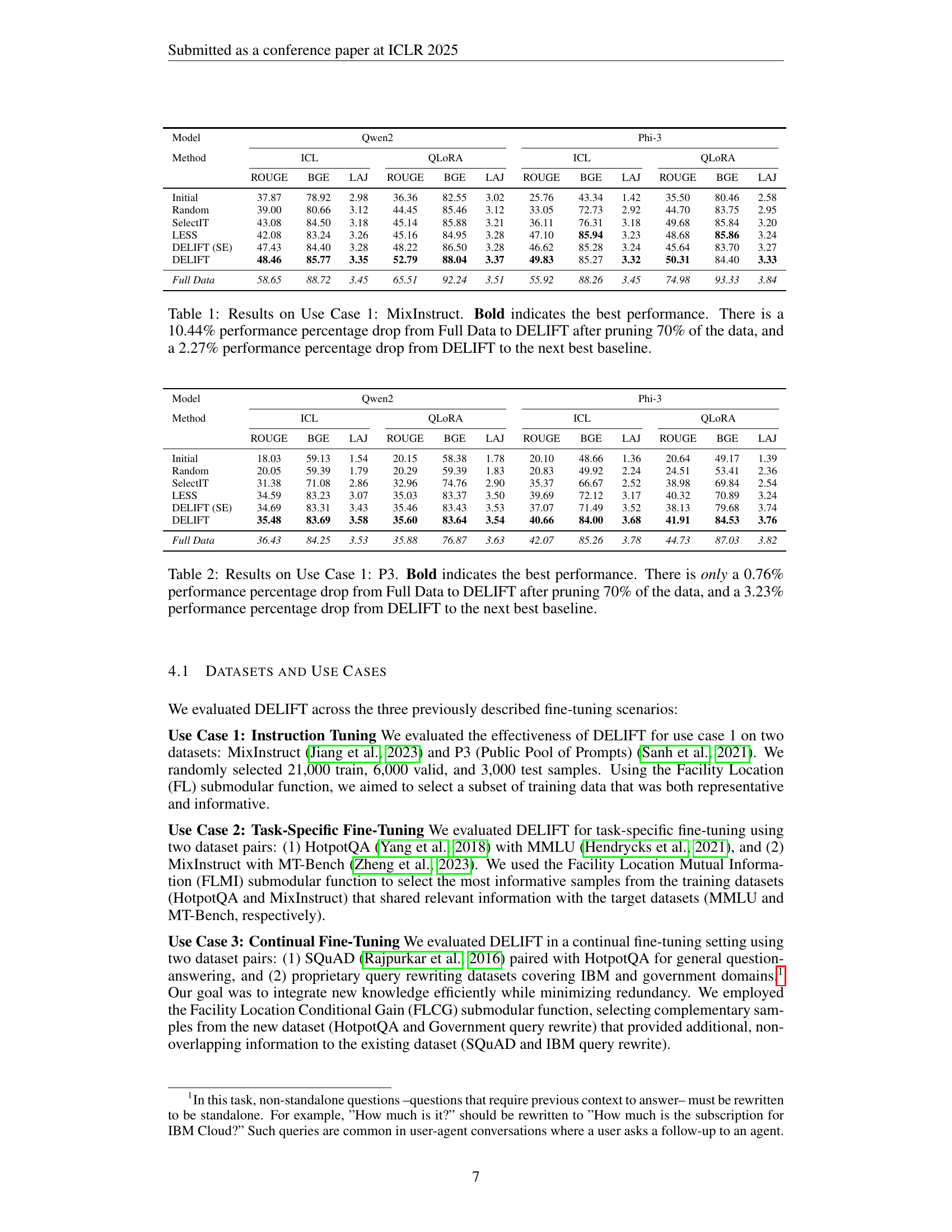
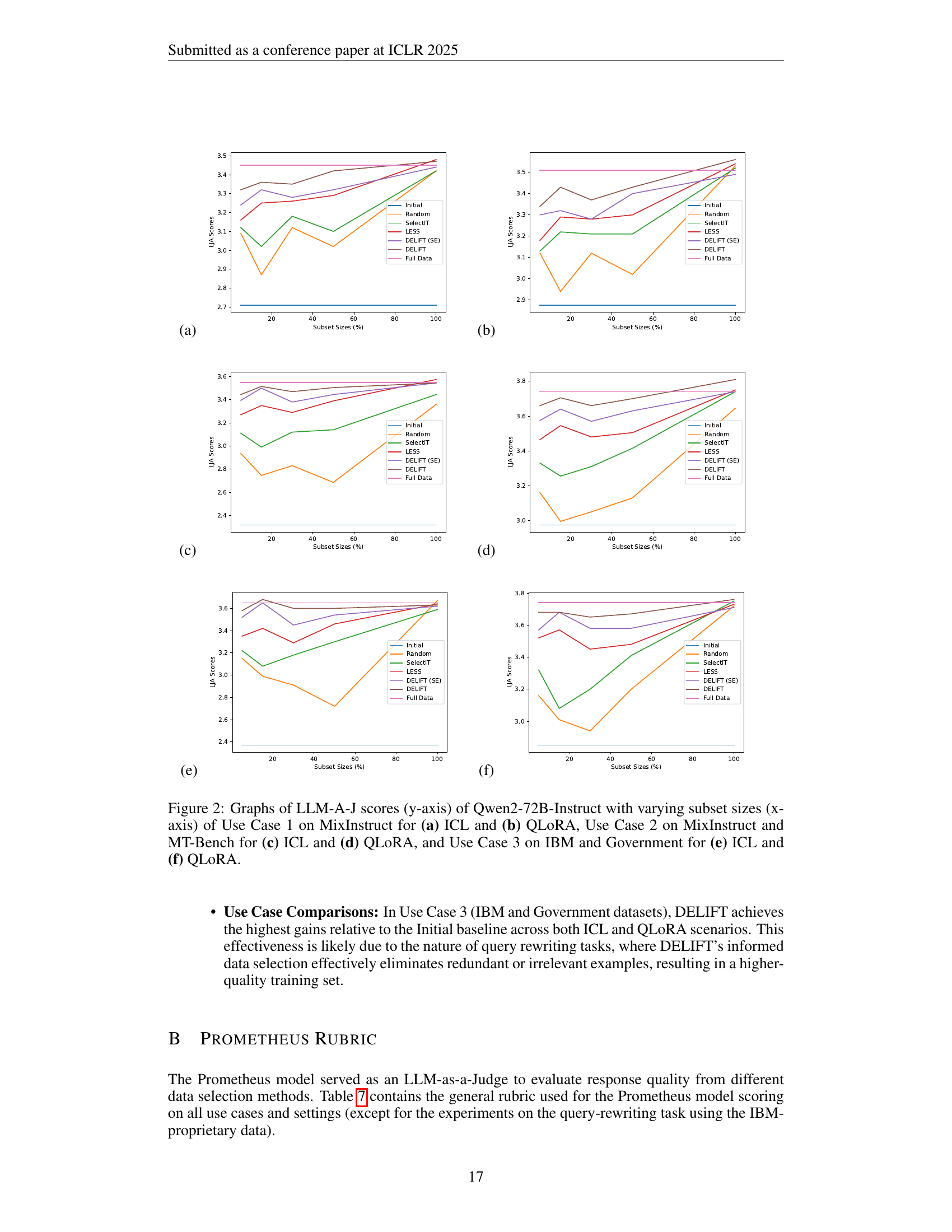
🔼 This table presents the results of the DELIFT model on the MixInstruct dataset for Use Case 1 (Instruction Tuning). It compares the performance of DELIFT against several baselines: Initial (the model’s performance before fine-tuning), Random (randomly selecting a subset of data), SelectIT, LESS, DELIFT (SE) (DELIFT using sentence embeddings instead of the utility-based kernel), and Full Data (using the entire dataset). Performance is measured using three metrics: ICL, QLORA, and ROUGE, along with their sub-metrics (BGE and LAJ). The bold values indicate the best-performing method for each metric. Key findings highlighted in the caption are that DELIFT, after pruning 70% of the data, shows only a 10.44% drop in performance from the full dataset and only a 2.27% drop in performance compared to the next-best performing baseline.
read the caption
Table 1: Results on Use Case 1: MixInstruct. Bold indicates the best performance. There is a 10.44% performance percentage drop from Full Data to DELIFT after pruning 70% of the data, and a 2.27% performance percentage drop from DELIFT to the next best baseline.
Full paper#