↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image-to-video models rely heavily on user-provided text and image prompts, yet there’s a lack of comprehensive datasets studying these prompts. This limits progress in understanding user preferences and creating safer models. Existing datasets either focus on text-to-video or text-to-image tasks, failing to capture the nuances of image-to-video.
The paper introduces TIP-I2V, a large-scale dataset with over 1.7 million unique user prompts (text and image) and corresponding videos generated by five state-of-the-art models. This allows researchers to analyze user preferences, improve model safety by addressing misinformation, and build more comprehensive benchmarks. TIP-I2V’s unique structure, scale, and scope significantly advance image-to-video research and its practical applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for a dedicated dataset in image-to-video prompt research. Existing datasets lack the specific focus on user-provided text and image prompts alongside generated videos, hindering advancements in model safety and user experience. TIP-I2V facilitates research on user preference analysis, model safety enhancement, and improved benchmark creation, thus significantly advancing image-to-video technology.
Visual Insights#

🔼 Figure 1 shows the TIP-I2V dataset, which contains over 1.7 million unique text and image prompts created by real users. These prompts were used to generate videos using five different state-of-the-art image-to-video models: Pika, Stable Video Diffusion, Open-Sora, I2VGen-XL, and CogVideoX-5B. The figure visually represents a small sample of these prompts and resulting videos to illustrate the dataset’s diversity and scale. The TIP-I2V dataset aims to advance the development of improved and safer image-to-video generation models.
read the caption
Figure 1: TIP-I2V is the first dataset comprising over 1.70 million unique user-provided text and image prompts. Besides the prompts, TIP-I2V also includes videos generated by five state-of-the-art image-to-video models (𝙿𝚒𝚔𝚊𝙿𝚒𝚔𝚊\mathtt{Pika}typewriter_Pika [5], 𝚂𝚝𝚊𝚋𝚕𝚎𝚂𝚝𝚊𝚋𝚕𝚎\mathtt{Stable}typewriter_Stable 𝚅𝚒𝚍𝚎𝚘𝚅𝚒𝚍𝚎𝚘\mathtt{Video}typewriter_Video 𝙳𝚒𝚏𝚏𝚞𝚜𝚒𝚘𝚗𝙳𝚒𝚏𝚏𝚞𝚜𝚒𝚘𝚗\mathtt{Diffusion}typewriter_Diffusion [8], 𝙾𝚙𝚎𝚗-𝚂𝚘𝚛𝚊𝙾𝚙𝚎𝚗-𝚂𝚘𝚛𝚊\mathtt{Open\text{-}Sora}typewriter_Open - typewriter_Sora [73], 𝙸𝟸𝚅𝙶𝚎𝚗-𝚇𝙻𝙸𝟸𝚅𝙶𝚎𝚗-𝚇𝙻\mathtt{I2VGen\text{-}XL}typewriter_I2VGen - typewriter_XL [71], and 𝙲𝚘𝚐𝚅𝚒𝚍𝚎𝚘𝚇-𝟻𝙱𝙲𝚘𝚐𝚅𝚒𝚍𝚎𝚘𝚇-5𝙱\mathtt{CogVideoX\text{-}5B}typewriter_CogVideoX - typewriter_5 typewriter_B [69]). The TIP-I2V contributes to the development of better and safer image-to-video models.
In-depth insights#
I2V Prompt Gallery#
An “I2V Prompt Gallery” would be a valuable resource for researchers and developers in the image-to-video field. It would likely be a curated collection of text and image prompts, along with corresponding generated videos, offering a unique lens into how users interact with and direct image-to-video models. The gallery’s value lies in its ability to reveal trends and patterns in prompt design, highlighting effective prompting strategies and common pitfalls. Analyzing this data could inform the development of more user-friendly and efficient models, potentially improving both the quality and safety of image-to-video generation. A well-organized gallery could also facilitate comparisons between various models’ responses to the same prompts, fostering a deeper understanding of each model’s strengths and weaknesses. The gallery could even help researchers to identify potential biases or safety concerns in the generated videos, paving the way for improved model training and responsible AI development. Ultimately, a comprehensive I2V Prompt Gallery could greatly advance the field’s progress.
I2V Model Analysis#
An ‘I2V Model Analysis’ section in a research paper would critically examine the performance and characteristics of image-to-video generation models. This would involve a multifaceted evaluation, assessing factors beyond simple visual quality. Quantitative metrics such as FID, LPIPS, and structural similarity would be employed, but the analysis should also delve into qualitative aspects like temporal coherence, object fidelity, and artifact presence. A rigorous comparison of different I2V models, highlighting their respective strengths and weaknesses across various metrics, is crucial. Further analysis might investigate the influence of different input prompts (text and image) on model output, revealing potential biases or limitations. Finally, a discussion on the ethical considerations and potential societal impact of the technology, including potential for misinformation, is essential for a comprehensive analysis.
Safety & Misinfo#
The heading ‘Safety & Misinfo’ highlights crucial concerns in the field of image-to-video generation. Misinformation is a major risk, as models can easily manipulate images to create videos depicting events that never occurred, potentially spreading false narratives. This necessitates the development of robust detection mechanisms to distinguish between real and generated videos. Safety is equally important, requiring careful consideration of user-generated prompts that could lead to harmful or inappropriate content. The research emphasizes the need for responsible AI development, including strategies for filtering unsafe prompts and building models that prioritize ethical considerations. Data bias within training sets must be addressed to prevent the creation of biased or harmful outputs, which could perpetuate societal problems. Addressing these challenges through both technical solutions (e.g. detection algorithms) and ethical guidelines (e.g., user prompt moderation) is vital for the responsible advancement of image-to-video technology.
TIP-I2V Datasets#
The hypothetical TIP-I2V dataset, as described, presents a substantial advancement in image-to-video prompt research. Its million-scale size, comprising real user-generated text and image prompts alongside corresponding videos from various state-of-the-art models, offers unprecedented potential. Diversity in prompt types (ranging from basic descriptions to intricate instructions) and the inclusion of metadata (e.g., NSFW scores, embeddings) enriches its analytical value. Compared to existing datasets, its focus on the image-to-video generation paradigm makes it unique and highly relevant. This detailed collection will fuel research in improving model performance, user experience, and especially in addressing safety and misinformation issues inherent to image-to-video technology. The availability of generated videos directly from several models is a notable advantage, providing researchers with a valuable ground truth for analysis and model comparison. This should lead to significant improvements in the field.
Future Directions#
Future research directions in image-to-video generation, building upon datasets like TIP-I2V, are multifaceted. Improving user experience is key, requiring deeper analysis of user preferences to tailor model outputs. This involves understanding the nuances of prompt phrasing and generating results aligned with user intent. Enhanced model safety necessitates addressing the issue of misinformation. Techniques for detecting AI-generated videos and tracing the source image become crucial. Beyond this, improving evaluation methodologies is vital. Current benchmarks lack comprehensiveness and often fail to capture the real-world user experience. New metrics, focusing on aspects like temporal consistency and semantic accuracy, are needed. Finally, developing more sophisticated prompt techniques is crucial. Research into meaning-preserving prompt refinement and unsafe prompt filtering can ensure better quality and safer applications.
More visual insights#
More on figures

🔼 The figure displays a sample data point from the TIP-I2V dataset. It shows the various components included for each data point: a unique identifier (UUID), a timestamp indicating when the data was collected, the text prompt provided by the user, the image prompt used, the subject of the prompt, NSFW (Not Safe For Work) status flags for both the text and image, embeddings representing the text and image prompts, and finally, the corresponding videos generated by five different image-to-video models. This comprehensive structure makes the dataset valuable for researching user prompts and improving image-to-video models.
read the caption
Figure 2: A data point in our TIP-I2V includes UUID, timestamp, text and image prompt, subject, NSFW status of text and image, text and image embedding, and the corresponding generated videos.

🔼 This table compares the TIP-I2V dataset with two other popular datasets, VidProM and DiffusionDB, highlighting key differences in their scope and focus. All three datasets are large-scale, but TIP-I2V is unique in its concentration on image-to-video generation, using both text and image prompts, unlike VidProM (text-to-video) and DiffusionDB (text-to-image). The table provides a detailed breakdown of the number of unique prompts, embedding methods, prompt length, data collection time span, and number of generation sources. This comparison emphasizes the unique characteristics of TIP-I2V and its contribution to the field of image-to-video research.
read the caption
Table 1: Comparison of our TIP-I2V (image-to-video) with popular VidProM (text-to-video) and DiffusionDB (text-to-image) in terms of basic information. Our TIP-I2V is comparable in scale to these datasets but focuses on different aspects of visual generation.

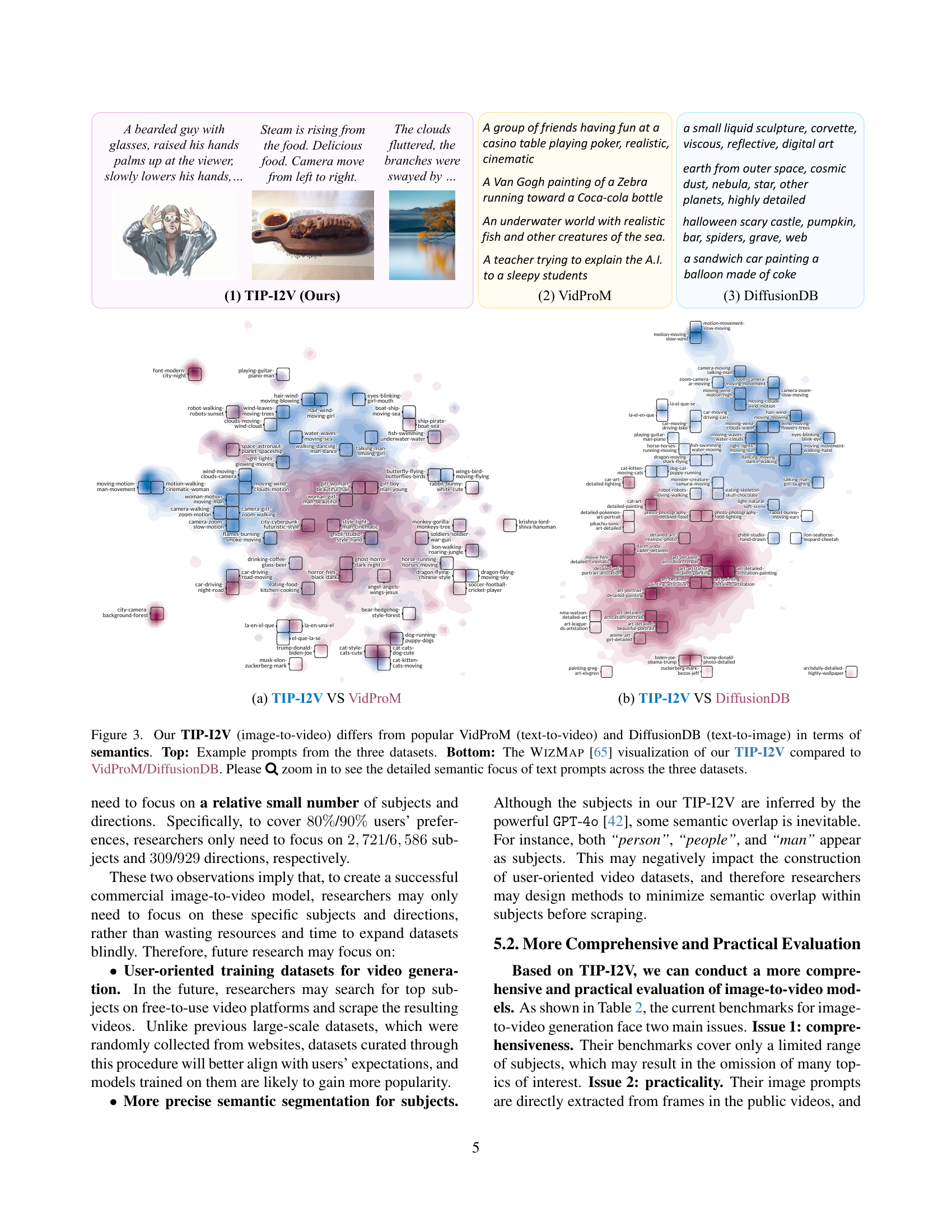
🔼 Figure 3 demonstrates the key differences between TIP-I2V and two other popular prompt datasets: VidProM (text-to-video) and DiffusionDB (text-to-image). The top part of the figure shows example prompts from each dataset, highlighting the varying levels of specificity and semantic focus. The bottom part utilizes a WizMap visualization to compare the semantic distributions of the text prompts across the three datasets. This visual representation allows for a deeper understanding of how the prompts in TIP-I2V differ semantically from prompts in VidProM and DiffusionDB, showcasing a different style of prompt crafting oriented around animating elements within an existing image.
read the caption
Figure 3: Our TIP-I2V (image-to-video) differs from popular VidProM (text-to-video) and DiffusionDB (text-to-image) in terms of semantics. Top: Example prompts from the three datasets. Bottom: The WizMap [65] visualization of our TIP-I2V compared to VidProM/DiffusionDB. Please \faSearch zoom in to see the detailed semantic focus of text prompts across the three datasets.

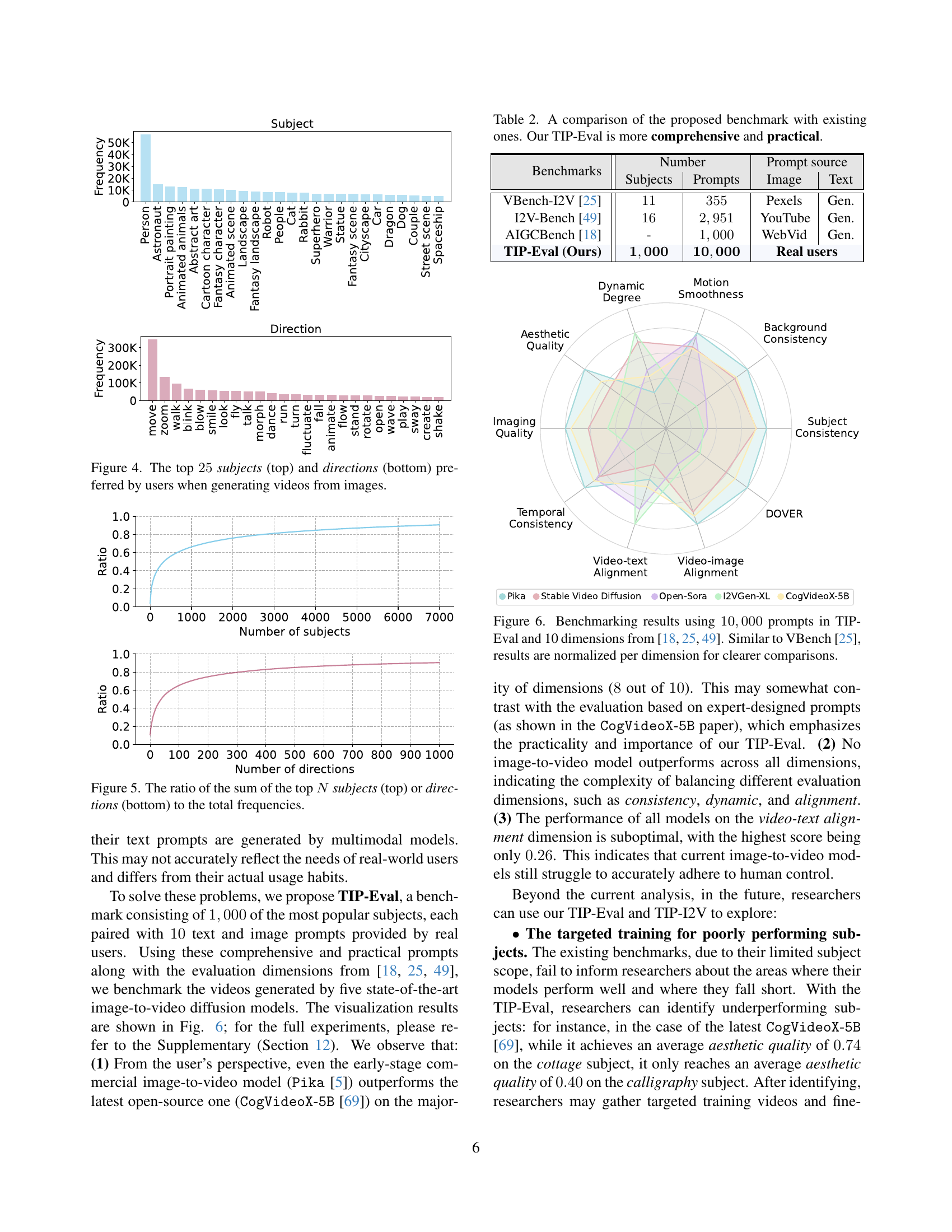
🔼 This figure shows the top 25 most frequent subjects and directions chosen by users when using the TIP-I2V dataset for image-to-video generation. The top panel displays a bar chart representing the frequency of subjects (categories of objects/scenes), while the bottom panel shows the frequency of directions (actions or movements applied to the subjects). This visualization helps to understand user preferences and biases in terms of what kinds of scenes and actions are commonly requested for image-to-video synthesis, informing the design and evaluation of image-to-video models.
read the caption
Figure 4: The top 25252525 subjects (top) and directions (bottom) preferred by users when generating videos from images.

🔼 This figure shows two line graphs. The top graph displays the cumulative proportion of the top N subjects, indicating the percentage of total subject frequency accounted for by the top N most frequent subjects. The bottom graph presents the same analysis but for the top N most frequent directions used in video generation prompts. Both graphs illustrate the uneven distribution of subject and direction preferences among users, showing that a relatively small number of subjects and directions represent a significant portion of all prompts.
read the caption
Figure 5: The ratio of the sum of the top N𝑁Nitalic_N subjects (top) or directions (bottom) to the total frequencies.

🔼 Table 2 compares the proposed TIP-Eval benchmark with existing benchmarks (VBench-I2V, I2V-Bench, AIGCBench) in terms of comprehensiveness and practicality for evaluating image-to-video models. TIP-Eval uses 1000 subjects and 10,000 real user prompts, providing a more comprehensive and practical evaluation than previous benchmarks, which had limited subjects and/or prompts generated by algorithms rather than real users.
read the caption
Table 2: A comparison of the proposed benchmark with existing ones. Our TIP-Eval is more comprehensive and practical.

🔼 Figure 6 presents a radar chart visualizing the performance of five different image-to-video diffusion models across ten evaluation dimensions. The models are compared using TIP-Eval, a new benchmark dataset comprising 10,000 prompts, which ensures a more practical and real-world evaluation compared to existing benchmarks. Each dimension represents a different aspect of video quality, such as temporal consistency, aesthetic quality, and alignment between the video and its text or image prompts. The results are normalized across dimensions for ease of comparison, allowing for a direct visual assessment of the relative strengths and weaknesses of each model in various aspects of video generation.
read the caption
Figure 6: Benchmarking results using 10,0001000010,00010 , 000 prompts in TIP-Eval and 10 dimensions from [25, 49, 18]. Similar to VBench [25], results are normalized per dimension for clearer comparisons.

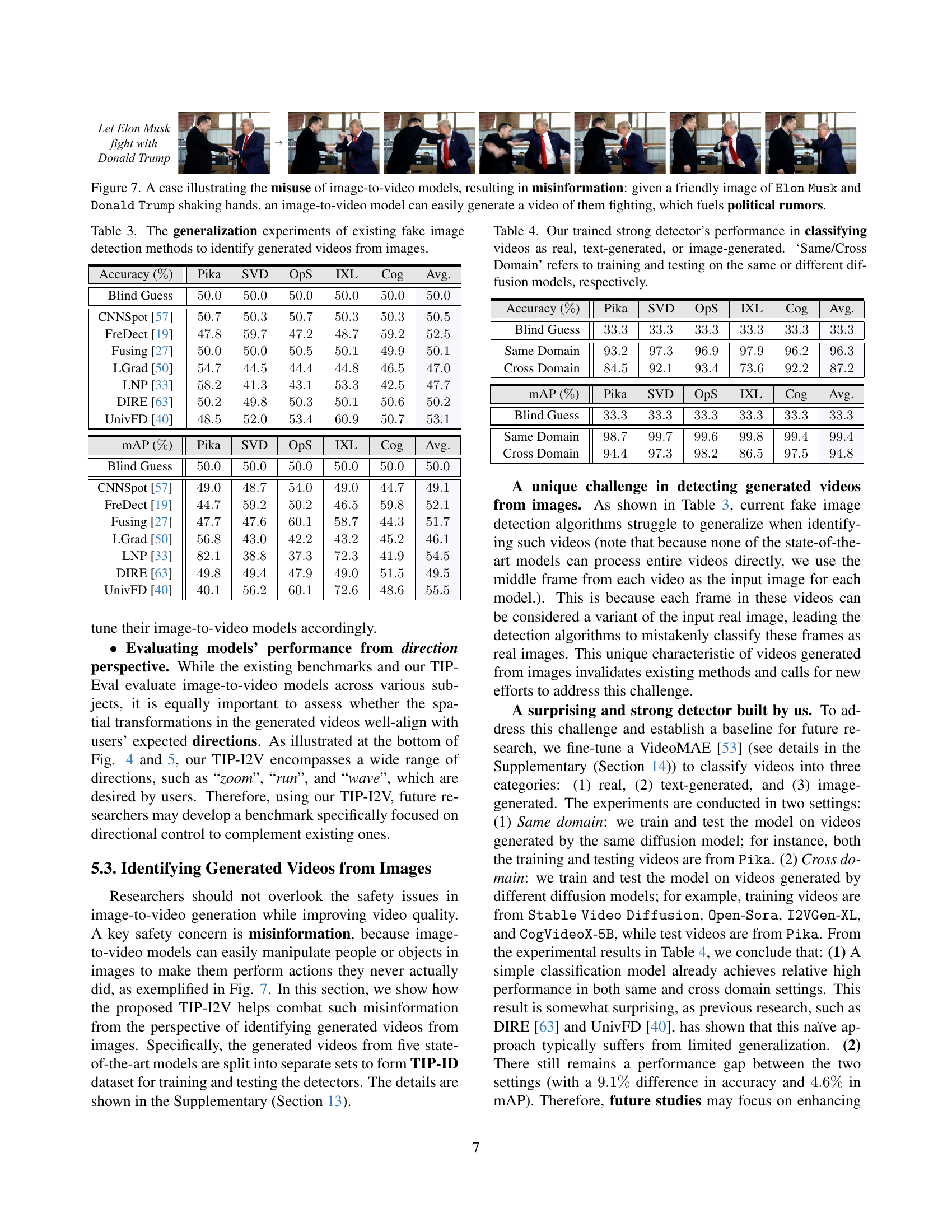
🔼 The figure shows an example of how image-to-video models can generate misinformation. A friendly image of Elon Musk and Donald Trump shaking hands is used as input. An image-to-video model easily creates a video of them fighting, which can spread false narratives and fuel political rumors. This highlights the risk of using these models to manipulate the meaning of images and generate misleading content.
read the caption
Figure 7: A case illustrating the misuse of image-to-video models, resulting in misinformation: given a friendly image of 𝙴𝚕𝚘𝚗𝙴𝚕𝚘𝚗\mathtt{Elon}typewriter_Elon 𝙼𝚞𝚜𝚔𝙼𝚞𝚜𝚔\mathtt{Musk}typewriter_Musk and 𝙳𝚘𝚗𝚊𝚕𝚍𝙳𝚘𝚗𝚊𝚕𝚍\mathtt{Donald}typewriter_Donald 𝚃𝚛𝚞𝚖𝚙𝚃𝚛𝚞𝚖𝚙\mathtt{Trump}typewriter_Trump shaking hands, an image-to-video model can easily generate a video of them fighting, which fuels political rumors.

🔼 This table presents the results of evaluating several existing fake image detection methods on videos generated from images. It demonstrates the generalization ability of these methods by testing their performance across videos created by different image-to-video models. The results are expressed as accuracy percentages, showing how well each method can distinguish between real and generated video frames. The inclusion of ‘Blind Guess’ provides a baseline for comparison.
read the caption
Table 3: The generalization experiments of existing fake image detection methods to identify generated videos from images.

🔼 This table presents the performance of a trained model designed to distinguish between real videos and videos generated using text or image prompts by diffusion models. The results are categorized by whether the model was trained and tested on the same diffusion model (‘Same Domain’) or different diffusion models (‘Cross Domain’). The table shows the accuracy (in percentage) achieved by the model in classifying videos into these three categories.
read the caption
Table 4: Our trained strong detector’s performance in classifying videos as real, text-generated, or image-generated. ‘Same/Cross Domain’ refers to training and testing on the same or different diffusion models, respectively.
Full paper#