↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current top-tier code LLMs are largely closed-source, hindering open scientific investigation and community progress. This limits reproducibility, understanding of model strengths and weaknesses, and exploration of better training methodologies. This lack of transparency also contributes to resource inequality within the AI research community.
OpenCoder directly addresses these issues by providing a fully open-source code LLM. This includes not only the model weights and inference code but also the training data, complete data processing pipeline, detailed training protocols, and rigorous experimental results. The paper identifies key factors contributing to the model’s success: improved data cleaning heuristics, high-quality synthetic data, and effective text corpus recall. This transparency promotes reproducibility and fosters faster advancements in code AI research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for high-quality, reproducible code LLMs. By open-sourcing a top-tier model along with its training data and methodology, it accelerates research and fosters collaboration within the code AI community. It sets a new standard for transparency in code LLM research, potentially prompting others to follow suit and further democratizing access to cutting-edge technologies. This also opens avenues for improving training data, model architectures and training processes.
Visual Insights#

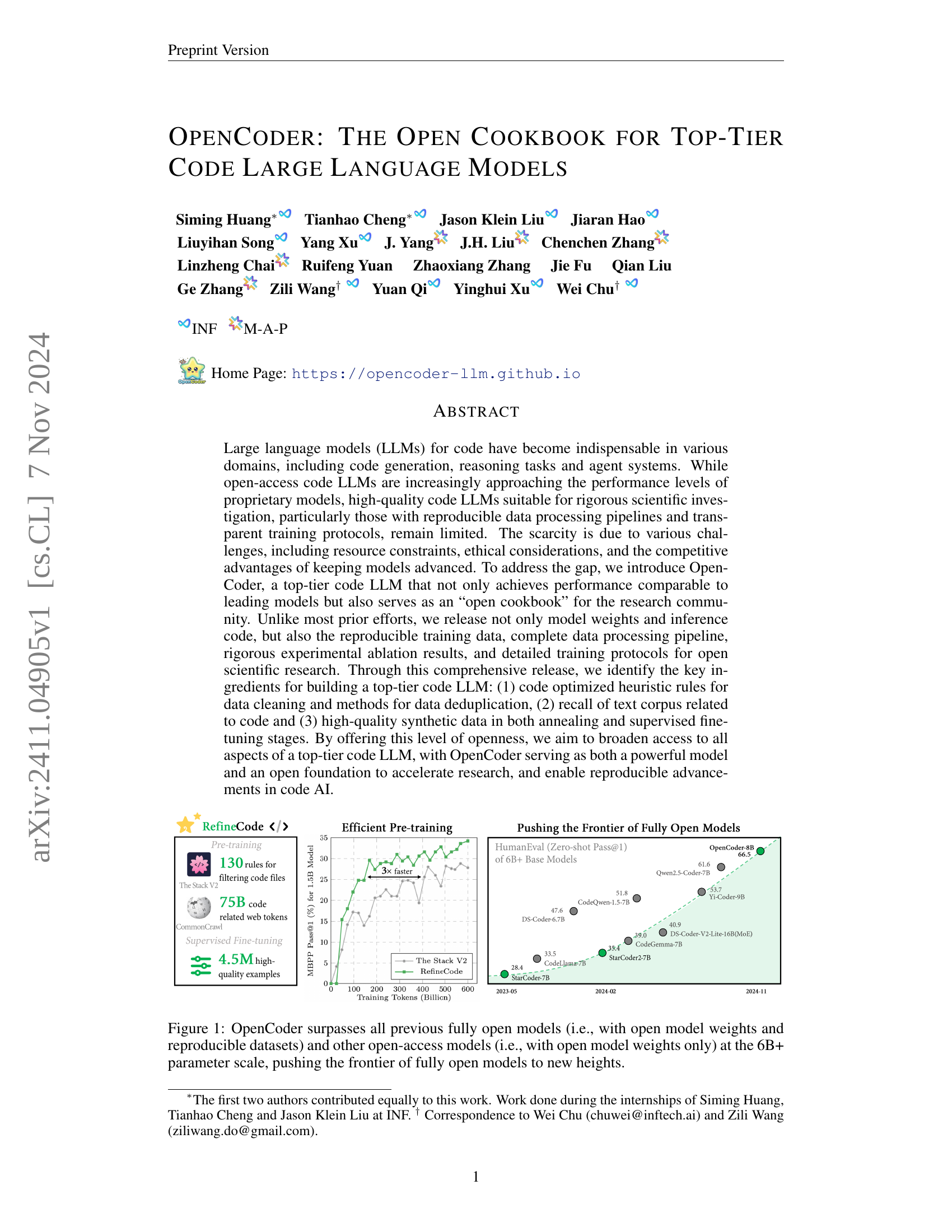
🔼 The figure shows a graph comparing the performance of OpenCoder with other large language models (LLMs) for code. The x-axis represents the number of training tokens (in billions), and the y-axis represents the MBPP Pass@1 (%) metric for a 1.5B parameter model and HumanEval (Zero-shot Pass@1) for 6B+ parameter models. OpenCoder significantly outperforms other fully open models (those with both open weights and reproducible datasets) and open-access models (those with only open weights) in both metrics, indicating its superior performance and the value of its fully open nature. The graph visually demonstrates OpenCoder pushing the frontier of fully open models to new heights.
read the caption
Figure 1: OpenCoder surpasses all previous fully open models (i.e., with open model weights and reproducible datasets) and other open-access models (i.e., with open model weights only) at the 6B+ parameter scale, pushing the frontier of fully open models to new heights.
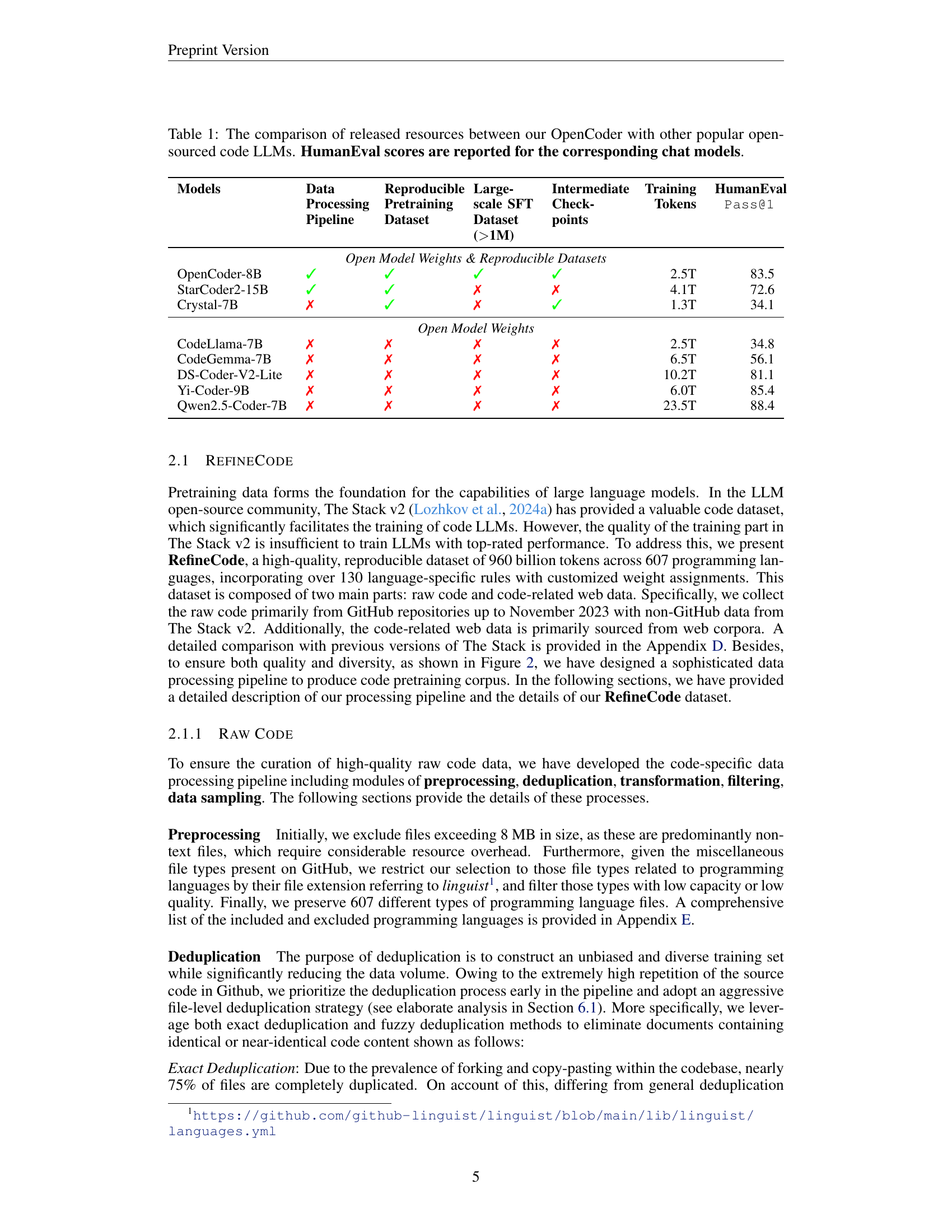
| Models | Data Processing Pipeline | Reproducible Pretraining Dataset | Large-scale SFT Dataset (>1M) | Intermediate Checkpoints | Training Tokens | HumanEval Pass@1 |
|---|---|---|---|---|---|---|
| Open Model Weights & Reproducible Datasets | ||||||
| OpenCoder-8B | ✓ | ✓ | ✓ | ✓ | 2.5T | 83.5 |
| StarCoder2-15B | ✓ | ✓ | ✗ | ✗ | 4.1T | 72.6 |
| Crystal-7B | ✗ | ✓ | ✗ | ✓ | 1.3T | 34.1 |
| Open Model Weights | ||||||
| CodeLlama-7B | ✗ | ✗ | ✗ | ✗ | 2.5T | 34.8 |
| CodeGemma-7B | ✗ | ✗ | ✗ | ✗ | 6.5T | 56.1 |
| DS-Coder-V2-Lite | ✗ | ✗ | ✗ | ✗ | 10.2T | 81.1 |
| Yi-Coder-9B | ✗ | ✗ | ✗ | ✗ | 6.0T | 85.4 |
| Qwen2.5-Coder-7B | ✗ | ✗ | ✗ | ✗ | 23.5T | 88.4 |
🔼 This table compares the resources released by the OpenCoder large language model (LLM) with those of other popular open-source code LLMs. The comparison includes whether the model weights, intermediate checkpoints, the training dataset, the data processing pipeline, and a large-scale supervised fine-tuning (SFT) dataset are publicly available. HumanEval Pass@1 scores (a measure of code generation performance) for the corresponding chat models are also provided. This allows for a comprehensive assessment of the openness and reproducibility of each LLM and allows researchers to easily compare the performance and capabilities of different models.
read the caption
Table 1: The comparison of released resources between our OpenCoder with other popular open-sourced code LLMs. HumanEval scores are reported for the corresponding chat models.
In-depth insights#
Open Code LLMs#
Open Code LLMs represent a significant advancement in the field of artificial intelligence, offering the potential for more accessible and reproducible research. Openness is key, as it facilitates collaboration, allows for scrutiny of model architectures and training data, and promotes further development by the broader research community. However, challenges remain in achieving performance parity with closed-source models. These challenges include the cost and effort required to collect, clean, and curate high-quality training datasets, which often involve significant computational resources and specialized expertise. Furthermore, the need for transparency and reproducibility must be balanced with the competitive landscape of the AI industry, where proprietary models often hold an advantage. Despite these challenges, ongoing research is actively addressing these issues, with the ultimate aim of creating open LLMs that are not only comparable in performance to their closed-source counterparts but also serve as robust platforms for advancing the field of AI in a more ethical and collaborative manner.
Data Deduplication#
Data deduplication plays a crucial role in optimizing large language model (LLM) training, particularly for code LLMs. The paper highlights the significant impact of deduplication on both data efficiency and model performance. Aggressive deduplication strategies, such as file-level deduplication, are shown to be superior to repository-level methods in terms of improving downstream task performance on benchmarks like HumanEval and MBPP. This is because repository-level deduplication retains a higher volume of redundant data, ultimately hindering model efficiency. File-level deduplication followed by fuzzy deduplication is identified as an effective and efficient process. The authors demonstrate that chunk-level deduplication doesn’t offer additional benefits, while excessive deduplication can lead to data sparsity and negatively impact model performance. Therefore, a carefully balanced approach to deduplication, prioritizing data quality and diversity, is essential for optimal LLM training.
Annealing Impact#
The concept of ‘Annealing Impact’ in the context of large language models (LLMs) training refers to the effect of the annealing phase on the model’s performance. Annealing, a gradual reduction in the learning rate, is a crucial post-pretraining stage designed to refine the model’s abilities and improve generalization. The impact of annealing is multifaceted. The choice of high-quality annealing data significantly enhances performance, demonstrating the importance of curating datasets with diverse yet relevant examples. Data deduplication strategies, employed during both pretraining and annealing phases, play a significant role in determining the effectiveness of the process. File-level deduplication, as shown in the study, is more beneficial than repository-level deduplication. In essence, the annealing phase allows for a fine-tuning of the model’s initial learning, improving its capacity to handle varied tasks with higher accuracy. The results suggest that a well-defined annealing stage, incorporating high-quality data and effective deduplication, is a key ingredient in training top-tier LLMs.
Two-Stage Tuning#
The concept of “Two-Stage Tuning” in the context of large language model (LLM) training for code generation is a powerful technique. It involves a two-phased approach: Stage 1 focuses on broad capability acquisition, using a diverse and extensive instruction dataset. This allows the model to grasp general programming concepts and a wide array of coding styles, establishing a strong foundation. Stage 2 then refines this foundation, concentrating on higher-quality, code-specific data to enhance performance on precise, practical tasks. This approach combines the benefits of breadth and depth, resulting in a model that is both versatile and proficient. By initially building a strong, generalized understanding, Stage 1 prepares the model for targeted improvements in Stage 2. This strategy is demonstrably superior to a single-stage approach, resulting in models that achieve better performance on various benchmarks that test both general knowledge and focused skill. The two-stage strategy helps avoid catastrophic forgetting; knowledge from Stage 1 isn’t lost during Stage 2’s specialization. Therefore, adopting a two-stage tuning strategy is crucial for achieving superior LLMs, especially in complex domains like code generation where both theoretical and practical expertise are vital.
Future Research#
Future research directions for OpenCoder should prioritize improving the model’s reasoning and problem-solving capabilities, particularly for complex, multi-step tasks. This could involve exploring advanced training techniques like reinforcement learning or incorporating external knowledge bases. Expanding the model’s multilingual capabilities is crucial, focusing on supporting a wider range of programming languages and addressing the nuances of different coding styles and conventions. Enhanced data curation methods are needed to improve data quality and diversity. Investigating techniques for efficient data deduplication and strategies for integrating diverse data sources, like code repositories and documentation, are vital. Further research should also focus on mitigating bias in the training data and improving the model’s reliability and safety. This includes designing robust evaluation methods that specifically target potential biases and vulnerabilities. Finally, investigating the efficiency of the training process and exploring methods for training even larger and more powerful models while maintaining resource efficiency is essential for future advancements in code LLMs. By addressing these research avenues, the OpenCoder project can continue to push the boundaries of code AI and contribute meaningfully to the broader software development community.
More visual insights#
More on figures

🔼 This figure shows the data processing pipeline for the pretraining stage of the OpenCoder model. It details the steps involved in creating a high-quality dataset for training, starting from raw code data and code-related web data. The pipeline involves several key stages, including preprocessing, deduplication, transformation, filtering, and data sampling, each designed to improve data quality and remove undesirable elements. The left panel focuses on processing the raw code data, while the right panel demonstrates the processing of code-related web data. This figure helps illustrate the comprehensive approach OpenCoder takes to creating a reliable and effective pretraining dataset.
read the caption
Figure 2: The illustration of our pretraining data processing workflow.

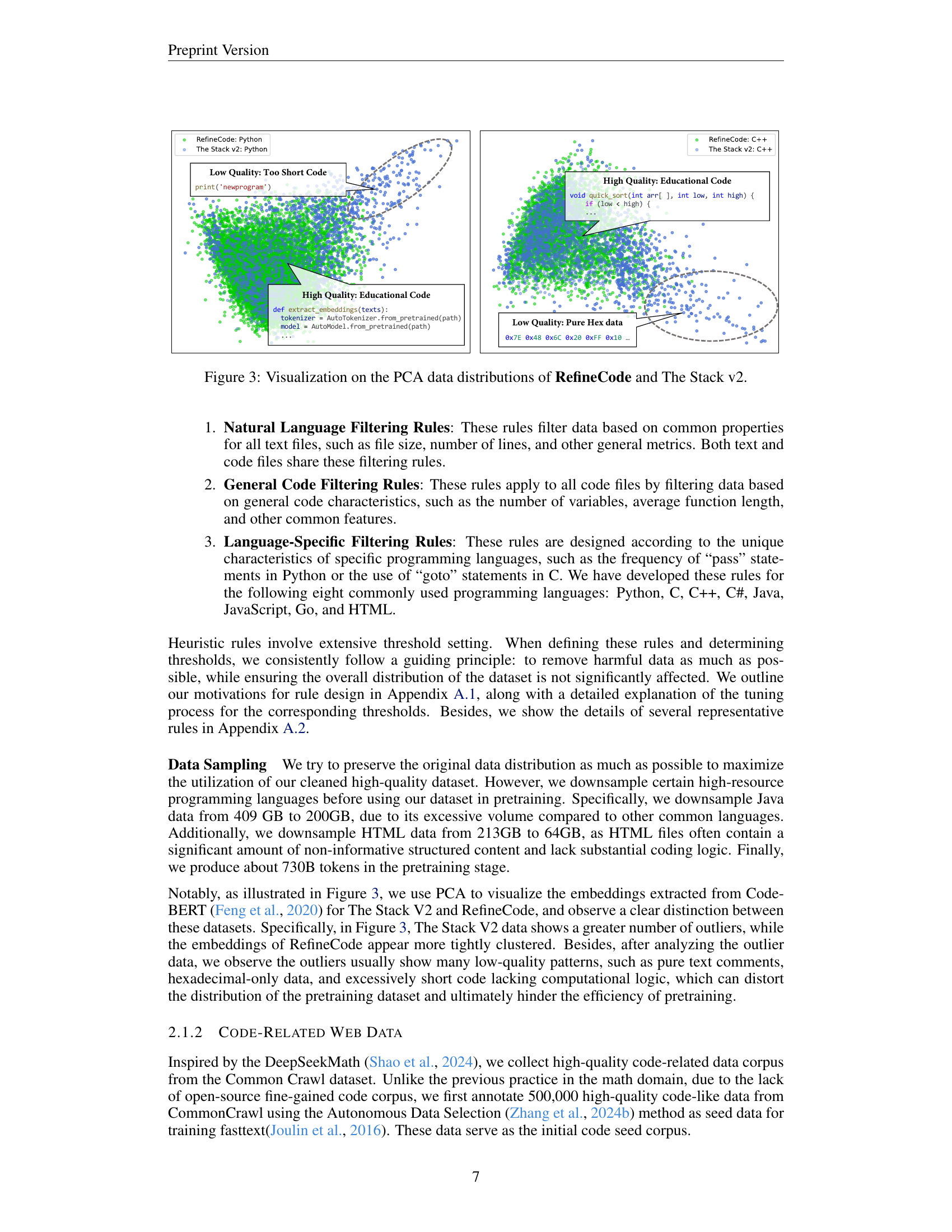
🔼 This figure uses Principal Component Analysis (PCA) to visualize the differences in data distribution between the RefineCode dataset and the Stack v2 dataset. RefineCode, a dataset created by the authors, is designed to be higher quality than Stack v2. The PCA plot shows distinct clusters for the two datasets, indicating that they have different characteristics. RefineCode’s data points are more tightly clustered, suggesting greater homogeneity and higher quality, while Stack v2’s points are more scattered, suggesting greater heterogeneity and potentially lower quality. The plot helps illustrate the authors’ claim of creating a more refined and homogenous dataset suitable for training high-performing code LLMs.
read the caption
Figure 3: Visualization on the PCA data distributions of RefineCode and The Stack v2.

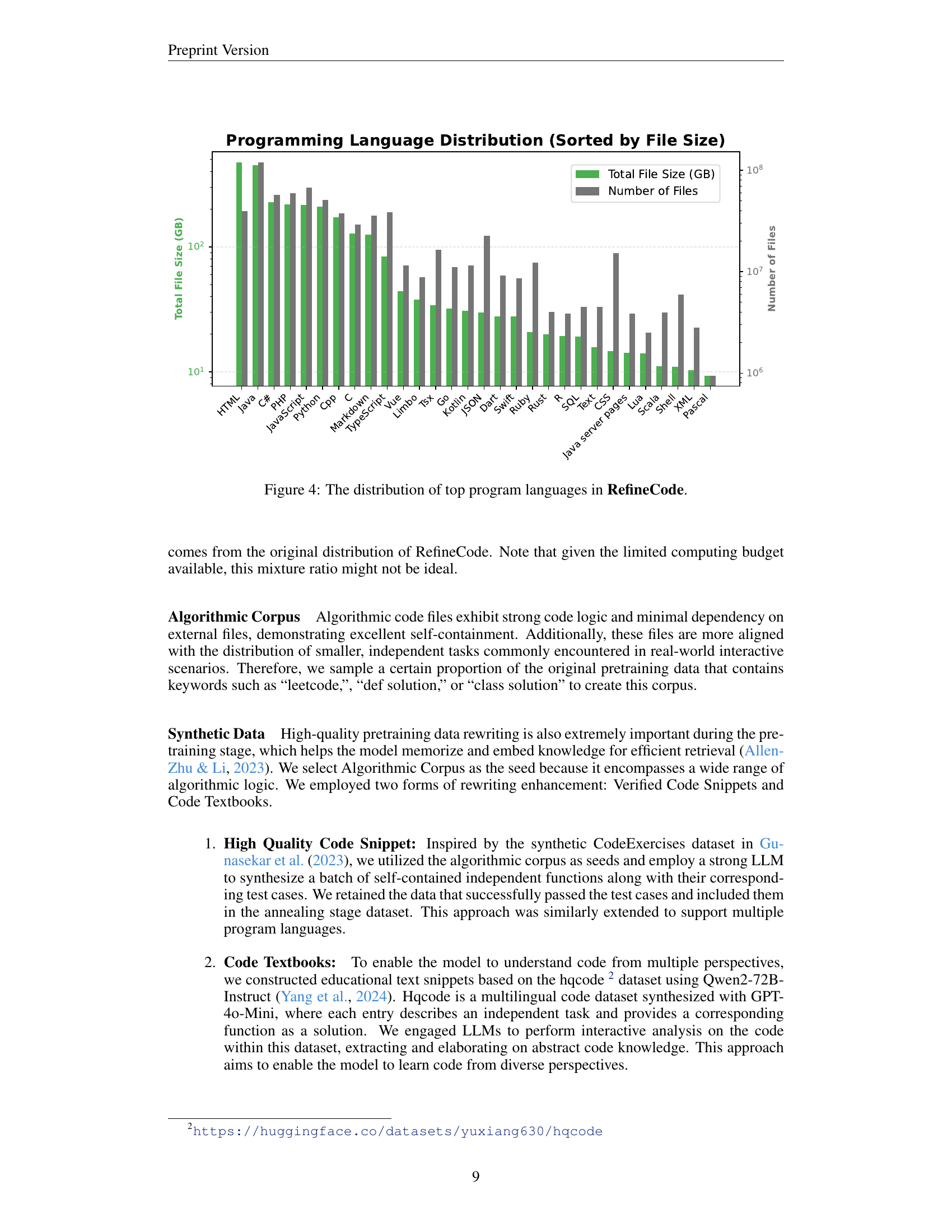
🔼 This bar chart visualizes the distribution of the top programming languages included in the RefineCode dataset, a crucial component of the OpenCoder large language model. The x-axis lists the programming languages, and the y-axis displays two metrics: the total file size (in gigabytes) and the number of files for each language. This illustrates the relative prevalence of different languages within the dataset, providing insights into the dataset’s composition and potential biases or strengths that could influence the model’s capabilities in various programming languages.
read the caption
Figure 4: The distribution of top program languages in RefineCode.

🔼 This figure illustrates the three different methods used to synthesize the instruction data for training OpenCoder. (a) shows large-scale diverse instruction synthesis, leveraging a filtered web corpus, task-specific prompt engineering, and answer generation from an LLM. (b) details educational instruction synthesis, starting from a seed corpus, incorporating LLM prompt engineering, test case generation, code verification, and ultimately creating educational instructions. Finally, (c) illustrates package-related instruction synthesis that leverages pretraining and package corpora, employing retrieval, prompt engineering, and generating package instructions.
read the caption
Figure 5: The illustration of our instruction data synthesis workflow.

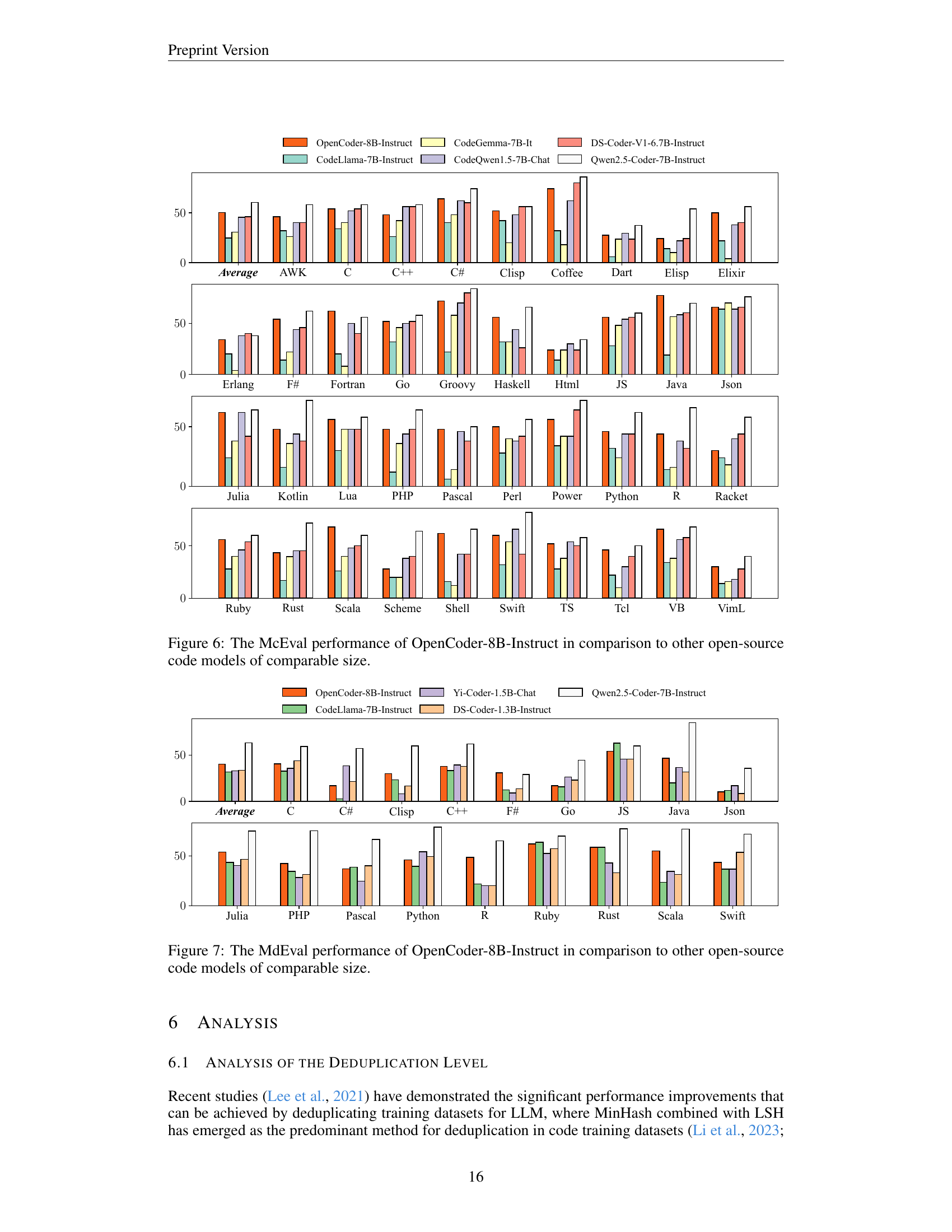
🔼 Figure 6 presents a detailed comparison of the performance of OpenCoder-8B-Instruct against other open-source, similarly sized code models on the McEval benchmark. McEval is a comprehensive multilingual code evaluation benchmark that assesses various coding capabilities across 40 programming languages. The figure provides a visual representation of each model’s performance across different languages, allowing for a direct comparison of their strengths and weaknesses in various coding contexts. This is particularly useful for identifying potential areas for improvement or specialization in multilingual code generation.
read the caption
Figure 6: The McEval performance of OpenCoder-8B-Instruct in comparison to other open-source code models of comparable size.

🔼 This figure presents a bar chart comparing the performance of various open-source code large language models (LLMs) on the MdEval benchmark. MdEval is a multilingual code debugging benchmark that assesses a model’s ability to identify and fix bugs in code across different programming languages. The chart shows the average performance across multiple languages, with separate bars for each language highlighting the relative strengths and weaknesses of each LLM. OpenCoder-8B-Instruct is included, and its performance is compared to that of other models of similar size. The chart visually demonstrates the relative performance of OpenCoder-8B-Instruct compared to competing LLMs on a challenging, multilingual code debugging task.
read the caption
Figure 7: The MdEval performance of OpenCoder-8B-Instruct in comparison to other open-source code models of comparable size.

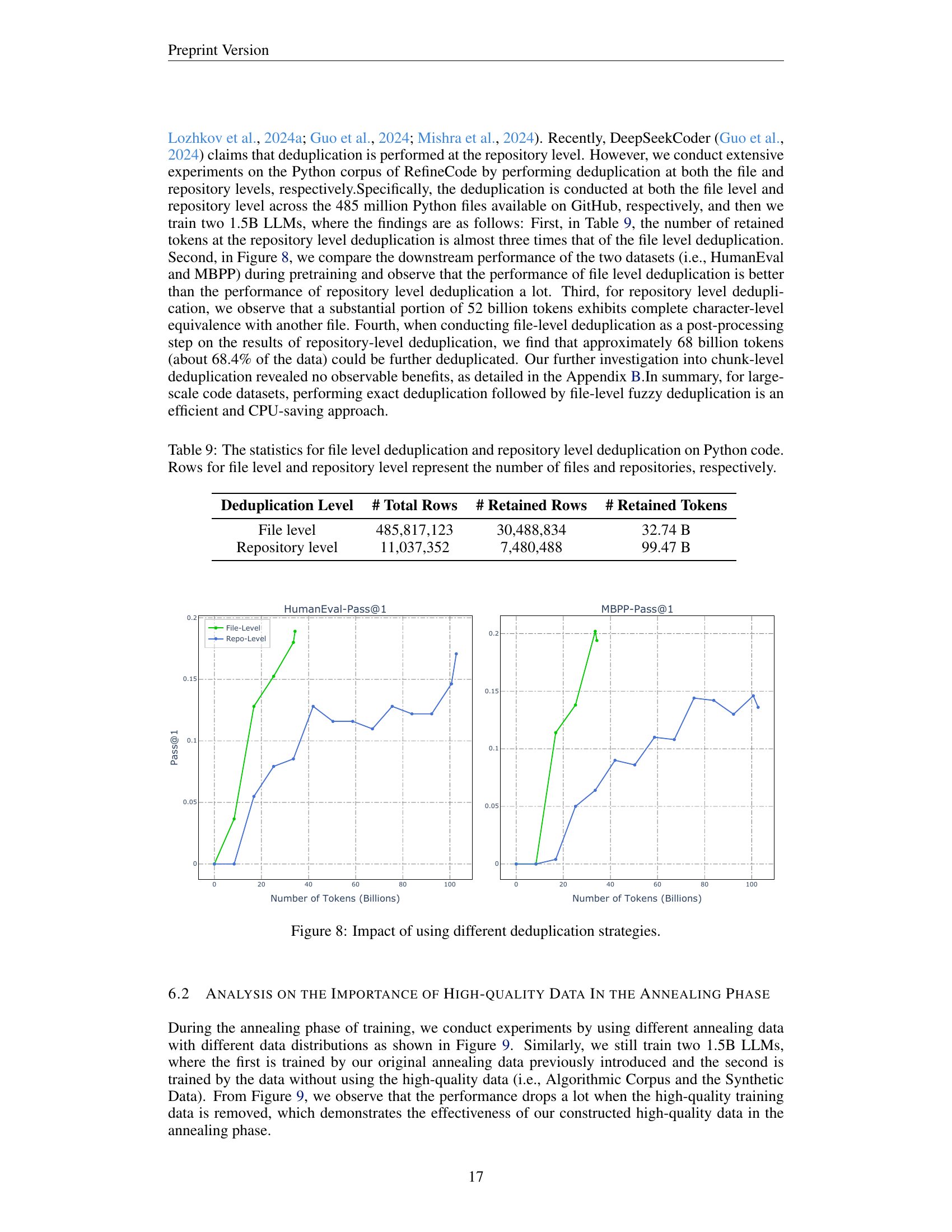
🔼 This figure compares the performance of different deduplication strategies on code datasets used for training large language models. Two different metrics (HumanEval and MBPP) measuring code generation performance are shown, plotted against the number of training tokens used after applying either file-level or repository-level deduplication. The results illustrate the impact of the chosen deduplication method on the final model’s performance.
read the caption
Figure 8: Impact of using different deduplication strategies.

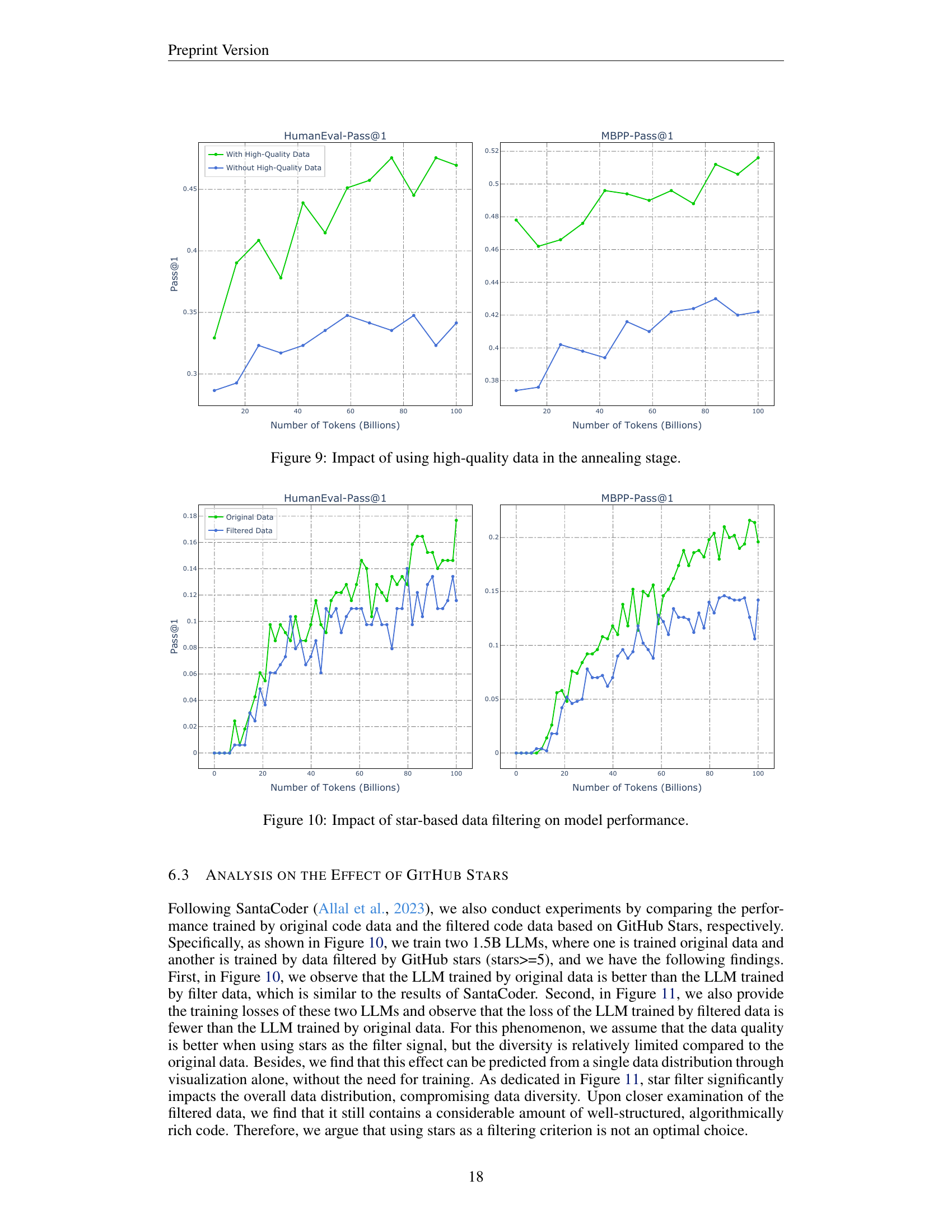
🔼 This figure displays the impact of incorporating high-quality data during the annealing phase of the model’s training. Two 1.5B parameter LLMs were trained, one with the original annealing data and another without the high-quality components (Algorithmic Corpus and Synthetic Data). The plots show the performance of both models on the HumanEval and MBPP benchmarks as a function of the number of tokens processed during the annealing phase. The results clearly demonstrate a significant performance drop for the model trained without high-quality data, underscoring its importance in the annealing stage.
read the caption
Figure 9: Impact of using high-quality data in the annealing stage.

🔼 This figure displays the impact of filtering data based on GitHub stars on the performance of a language model. Two 1.5B parameter models were trained, one using the original data and the other using data where only repositories with 5 or more stars were included. The graph shows the performance of each model on HumanEval and MBPP over the course of training. It reveals that using the original data, without filtering by stars, produced better results compared to the filtered data. Although filtering data by stars led to lower training losses, the performance was worse, suggesting that prioritizing repositories with high stars counts decreases the diversity and quality of the data which ultimately reduces the model’s performance.
read the caption
Figure 10: Impact of star-based data filtering on model performance.

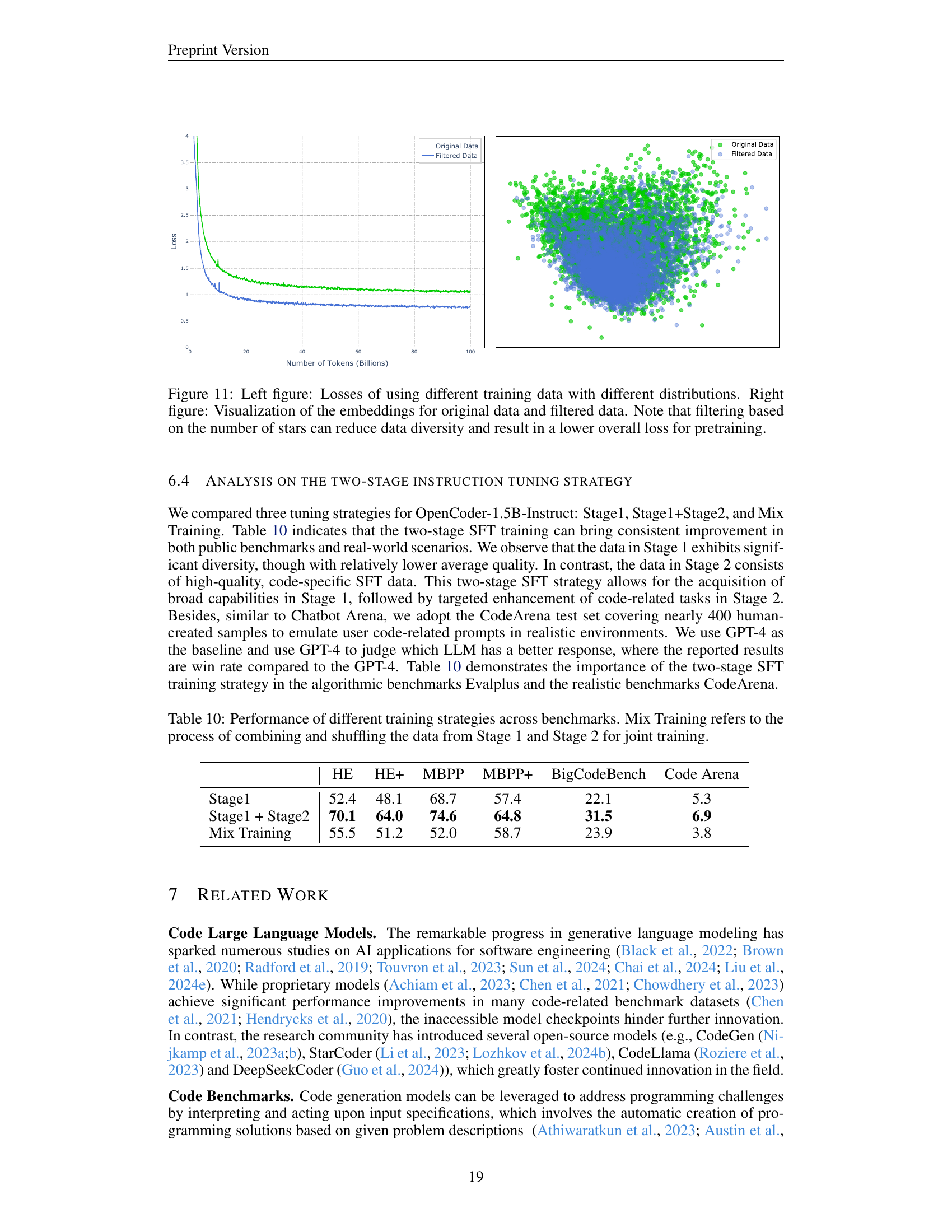
🔼 Figure 11 presents a comparative analysis of training loss and embedding distribution using different datasets. The left panel displays the training loss curves for models trained on datasets with different characteristics. The original data, representing a more diverse dataset with both high-quality and lower-quality code, shows a higher loss compared to the filtered data. The filtered data, containing only high-quality code (filtered by the number of Github stars), exhibits a lower training loss. This indicates that using a filter reduces training loss but is likely at the cost of reduced data diversity. The right panel visualizes the embedding distributions of these original and filtered datasets using PCA (Principal Component Analysis), showing a clear distinction between them. This further confirms that filtering based on the number of Github stars leads to a less diverse dataset, despite potentially improving model training efficiency.
read the caption
Figure 11: Left figure: Losses of using different training data with different distributions. Right figure: Visualization of the embeddings for original data and filtered data. Note that filtering based on the number of stars can reduce data diversity and result in a lower overall loss for pretraining.

🔼 Figure 12 illustrates the impact of different deduplication strategies on the performance of a language model. Three strategies were compared: file-level deduplication, repository-level deduplication, and a combined repository and chunk-level approach. The x-axis represents the number of tokens (in billions) processed, while the y-axis shows the Pass@1 score on the HumanEval and MBPP benchmarks. The results demonstrate that file-level deduplication yields the best performance, outperforming both repository-level deduplication and the combined approach.
read the caption
Figure 12: Comparison of Pass@1 performance on HumanEval & MBPP for different dedup strategies (File-Level, Repo-Level, and Repo-level + Chunk-Level) across RefineCode Python corpus.
More on tables
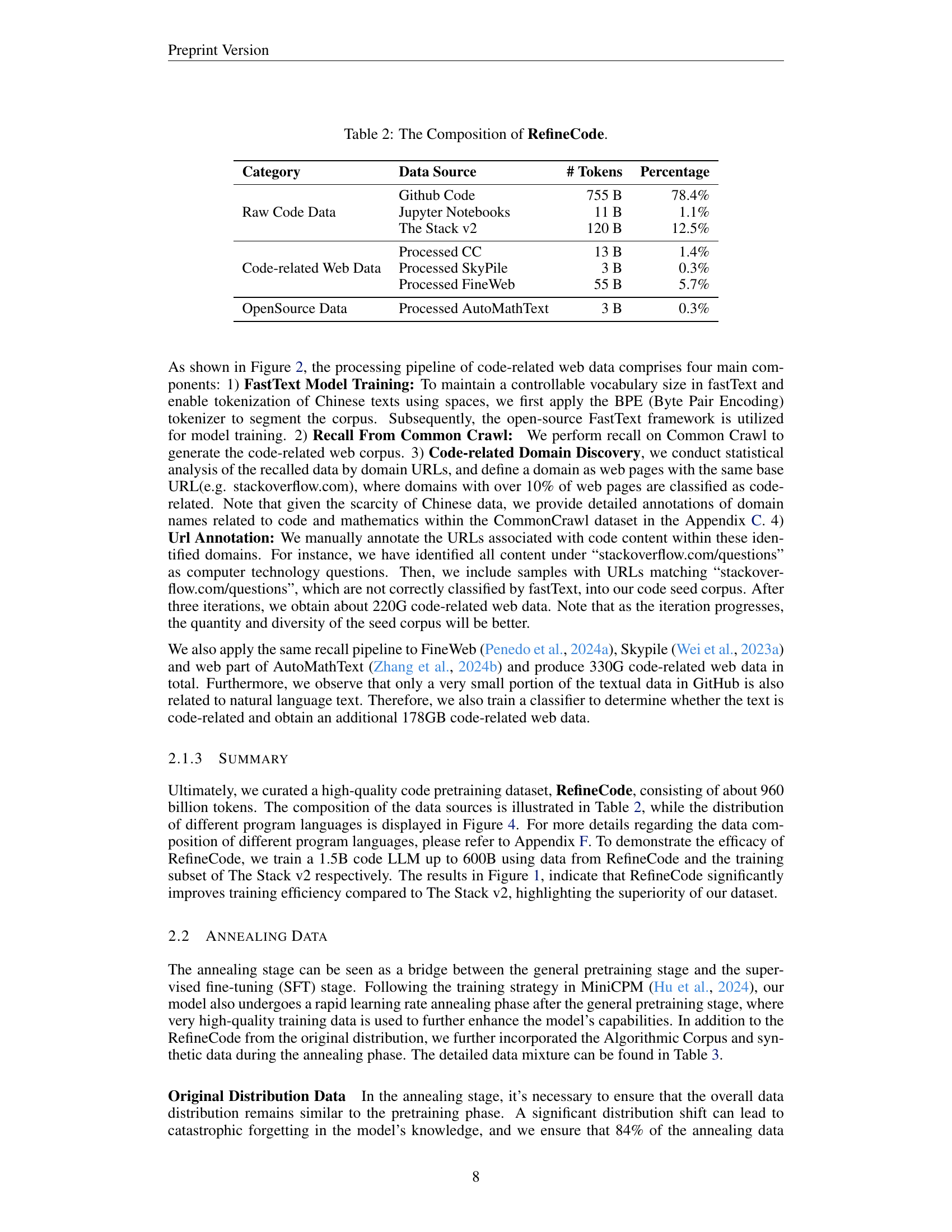
| Category | Data Source | # Tokens | Percentage |
|---|---|---|---|
| Raw Code Data | Github Code | 755 B | 78.4% |
| Jupyter Notebooks | 11 B | 1.1% | |
| The Stack v2 | 120 B | 12.5% | |
| Code-related Web Data | Processed CC | 13 B | 1.4% |
| Processed SkyPile | 3 B | 0.3% | |
| Processed FineWeb | 55 B | 5.7% | |
| OpenSource Data | Processed AutoMathText | 3 B | 0.3% |
🔼 Table 2 presents a breakdown of the RefineCode dataset, detailing the composition of its different data sources and their respective sizes (in tokens and percentage). It shows how much of RefineCode comes from GitHub code, Jupyter Notebooks, The Stack v2 dataset, and different processed web corpora. This provides crucial context for understanding the dataset’s scale and diversity, and how various sources contributed to the final dataset.
read the caption
Table 2: The Composition of RefineCode.
| Category | Dataset | # Token |
|---|---|---|
| Original Data | RefineCode | 84.21 B |
| Algorithmic Corpus | 12.44 B | |
| Synthetic Data | High Quality Code Snippet | 2.71 B |
| Code Textbooks | 0.91 B |
🔼 This table details the composition of the data used in the annealing phase of the OpenCoder model’s training. It breaks down the total number of tokens contributed by different data sources: the original RefineCode dataset, algorithmically generated code, high-quality synthetic code snippets, and code textbooks. The proportions of each dataset are shown to illustrate the mixture of data used to fine-tune the model during the annealing stage.
read the caption
Table 3: Detailed data mixture for annealing data.
| Model Parameter | OpenCoder-1.5B | OpenCoder-8B |
|---|---|---|
| Layers | 24 | 32 |
| Model Dimension | 2240 | 4096 |
| Attention Heads | 14 | 32 |
| Key / Value Heads | 14 | 8 |
| Activation Function | SwiGLU | SwiGLU |
| Vocab Size | 96640 | 96640 |
| Positional Embedding | RoPE(θ=10000) | RoPE(θ=500000) |
| Context Window Size | 4096 | 8192 |
🔼 This table details the key architectural hyperparameters of the two OpenCoder models: the 1.5 billion parameter model and the 8 billion parameter model. It provides a comparison of their configurations, including the number of layers, hidden dimension size, number of attention heads, activation function used, vocabulary size, and context window size. This information is crucial for understanding the differences in model capacity and computational requirements between the two variants.
read the caption
Table 4: Overview of the key hyperparameters of OpenCoder, including 1.5B and 8B.
| Stage | Data Source | # Examples |
|---|---|---|
| Stage1 | RealUser-Instruct | 0.7 M |
| Large-scale Diverse-Instruct | 2.3 M | |
| Filtered Infinity-Instruct | 1.0 M | |
| Stage2 | McEval-Instruct | 36 K |
| Evol-Instruct | 111 K | |
| Educational-Instruct | 110 K | |
| Package-Instruct | 110 K |
🔼 This table details the data used in the two-stage instruction tuning process for the OpenCoder model. Stage 1 focuses on general theoretical computer science concepts, while Stage 2 concentrates on practical coding tasks using high-quality code from GitHub. The table lists the data source and the number of examples for each stage of the tuning process. This two-stage approach aims to enhance the model’s abilities in both theoretical understanding and practical code generation.
read the caption
Table 5: Detailed data composition of our two-stage instruction-tuning.
| Model | Size | HumanEvalHE | HumanEvalHE+ | MBPP | MBPP+ | MBPP3-shot | MBPPFull | BigCodeBenchHard | BigCodeBench |
|---|---|---|---|---|---|---|---|---|---|
| 1B+ Models | |||||||||
| DeepSeek-Coder-1.3B-Base | 1.3B | 34.8 | 26.8 | 55.6 | 46.9 | 46.2 | 26.1 | 3.4 | |
| Yi-Coder-1.5B | 1.5B | 41.5 | 32.9 | 27.0 | 22.2 | 51.6 | 23.5 | 3.4 | |
| CodeGemma-2B | 2B | 31.1 | 16.5 | 51.1 | 43.1 | 45.4 | 23.9 | 7.4 | |
| Qwen2.5-Coder-1.5B | 1.5B | 43.9 | 36.6 | 69.2 | 58.6 | 59.2 | 34.6 | 9.5 | |
| StarCoder2-3B | 3B | 31.7 | 27.4 | 60.2 | 49.1 | 46.4 | 21.4 | 4.7 | |
| OpenCoder-1.5B-Base | 1.5B | 54.3 | 49.4 | 70.6 | 58.7 | 51.8 | 24.5 | 5.4 | |
| 6B+ Models | |||||||||
| CodeLlama-7B | 7B | 33.5 | 26.2 | 55.3 | 46.8 | 41.4 | 28.7 | 5.4 | |
| CodeGemma-7B | 7B | 39.0 | 32.3 | 50.5 | 40.7 | 55.0 | 38.3 | 10.1 | |
| DS-Coder-6.7B-Base | 6.7B | 47.6 | 39.6 | 70.2 | 56.6 | 60.6 | 41.1 | 11.5 | |
| DS-Coder-V2-Lite-Base(MoE) | 16B | 40.9 | 34.1 | 71.9 | 59.4 | 62.6 | 30.6 | 8.1 | |
| CodeQwen1.5-7B-Base | 7B | 51.8 | 45.7 | 72.2 | 60.2 | 61.8 | 45.6 | 15.6 | |
| Yi-Coder-9B | 9B | 53.7 | 46.3 | 48.4 | 40.7 | 69.4 | 42.9 | 14.2 | |
| Qwen2.5-Coder-7B-Base | 7B | 61.6 | 53.0 | 76.9 | 62.9 | 68.8 | 45.8 | 16.2 | |
| Crystal-7B | 7B | 22.6 | 20.7 | 38.6 | 31.7 | 31.0 | 10.8 | 4.1 | |
| StarCoder2-7B | 7B | 35.4 | 29.9 | 54.4 | 45.6 | 55.2 | 27.7 | 8.8 | |
| StarCoder2-15B | 15B | 46.3 | 37.8 | 66.2 | 53.1 | 15.2 | 38.4 | 12.2 | |
| OpenCoder-8B-Base | 8B | 68.9 | 63.4 | 79.9 | 70.4 | 60.6 | 40.5 | 9.5 |
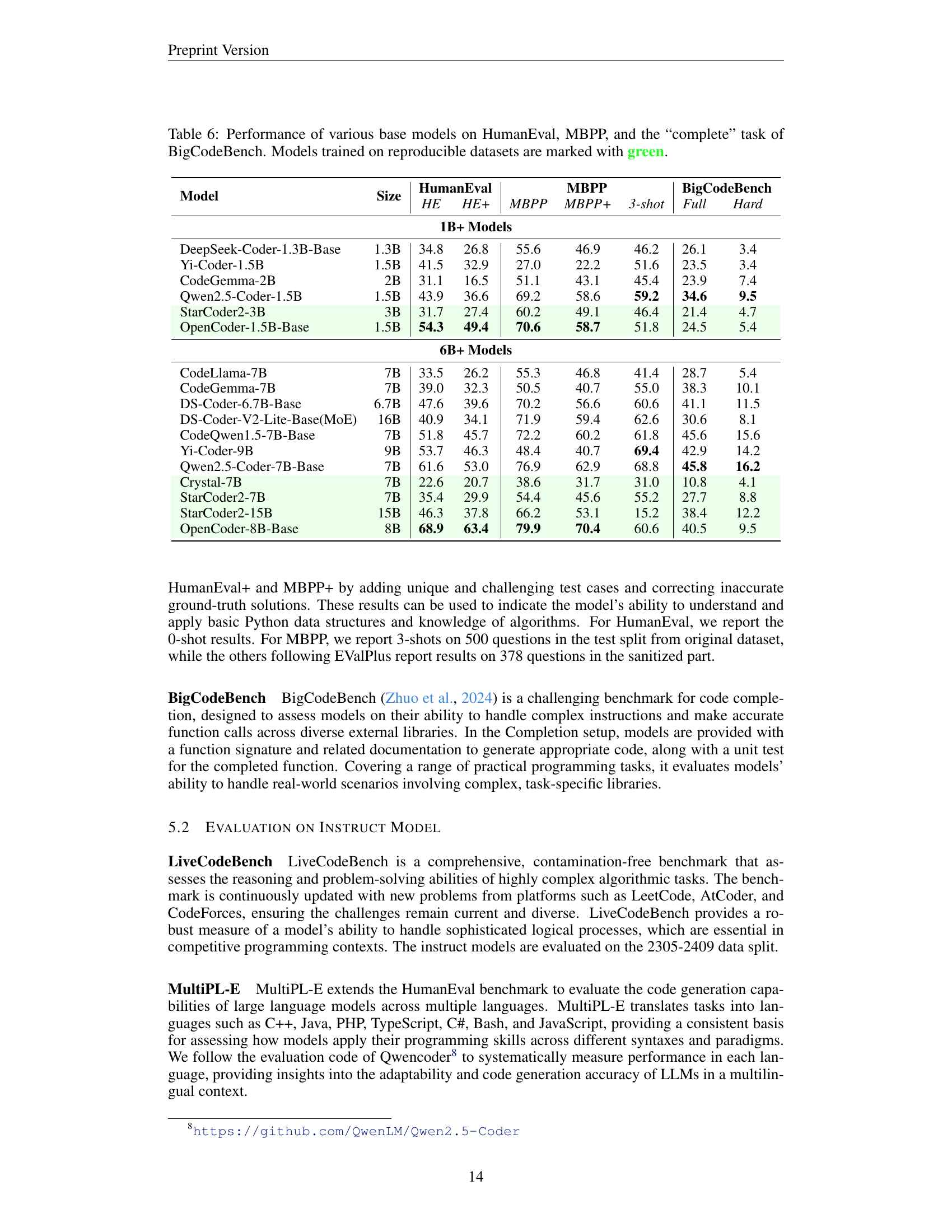
🔼 Table 6 presents a comparative analysis of various base code language models’ performance on three prominent benchmarks: HumanEval, MBPP, and BigCodeBench’s ‘complete’ task. The table highlights the performance scores achieved by each model across these benchmarks. Models trained using openly accessible and reproducible datasets are visually distinguished with a green marker, emphasizing the importance of transparency and reproducibility in model development. This comparison allows for a nuanced understanding of the relative strengths and weaknesses of different code models and the impact of data availability on model performance.
read the caption
Table 6: Performance of various base models on HumanEval, MBPP, and the “complete” task of BigCodeBench. Models trained on reproducible datasets are marked with green.
| Model | Size | HumanEval HE | HumanEval HE+ | MBPP MBPP | MBPP MBPP+ | BigCodeBench Full | BigCodeBench Hard | LiveCodeBench Avg |
|---|---|---|---|---|---|---|---|---|
| 1B+ Models | ||||||||
| DS-coder-1.3B-Instruct | 1.3B | 65.2 | 61.6 | 61.6 | 52.6 | 22.8 | 3.4 | 9.3 |
| Qwen2.5-Coder-1.5B-Instruct | 1.5B | 70.7 | 66.5 | 69.2 | 59.4 | 32.5 | 6.8 | 15.7 |
| Yi-Coder-1.5B-Chat | 1.5B | 67.7 | 63.4 | 68.0 | 59.0 | 24.0 | 6.8 | 11.6 |
| OpenCoder-1.5B-Instruct | 1.5B | 72.5 | 67.7 | 72.7 | 61.9 | 33.3 | 11.5 | 12.8 |
| 6B+ Models | ||||||||
| DS-Coder-V2-Lite-Instruct | 16B | 81.1 | 75.0 | 82.3 | 68.8 | 36.8 | 16.2 | 24.3 |
| CodeLlama-7B-Instruct | 7B | 45.7 | 39.6 | 39.9 | 33.6 | 21.9 | 3.4 | 2.8 |
| CodeGemma-7B-It | 7B | 59.8 | 47.0 | 69.8 | 59.0 | 32.3 | 7.4 | 14.7 |
| DS-Coder-6.7B-Instruct | 6.7B | 78.6 | 70.7 | 75.1 | 66.1 | 35.5 | 10.1 | 20.5 |
| Yi-Coder-9B-Chat | 9B | 82.3 | 72.6 | 81.5 | 69.3 | 38.1 | 11.5 | 23.4 |
| CodeQwen1.5-7B-Chat | 7B | 86.0 | 79.3 | 83.3 | 71.4 | 39.6 | 18.9 | 20.1 |
| Qwen2.5-Coder-7B-Instruct | 7B | 88.4 | 84.1 | 83.5 | 71.7 | 41.0 | 18.2 | 37.6 |
| CrystalChat-7B | 7B | 34.1 | 31.7 | 39.1 | 32.7 | 26.7 | 2.3 | 6.1 |
| StarCoder2-15B-Instruct-v0.1 | 15B | 72.6 | 63.4 | 75.2 | 61.2 | 37.6 | 12.2 | 20.4 |
| OpenCoder-8B-Instruct | 8B | 83.5 | 78.7 | 79.1 | 69.0 | 40.3 | 16.9 | 23.2 |
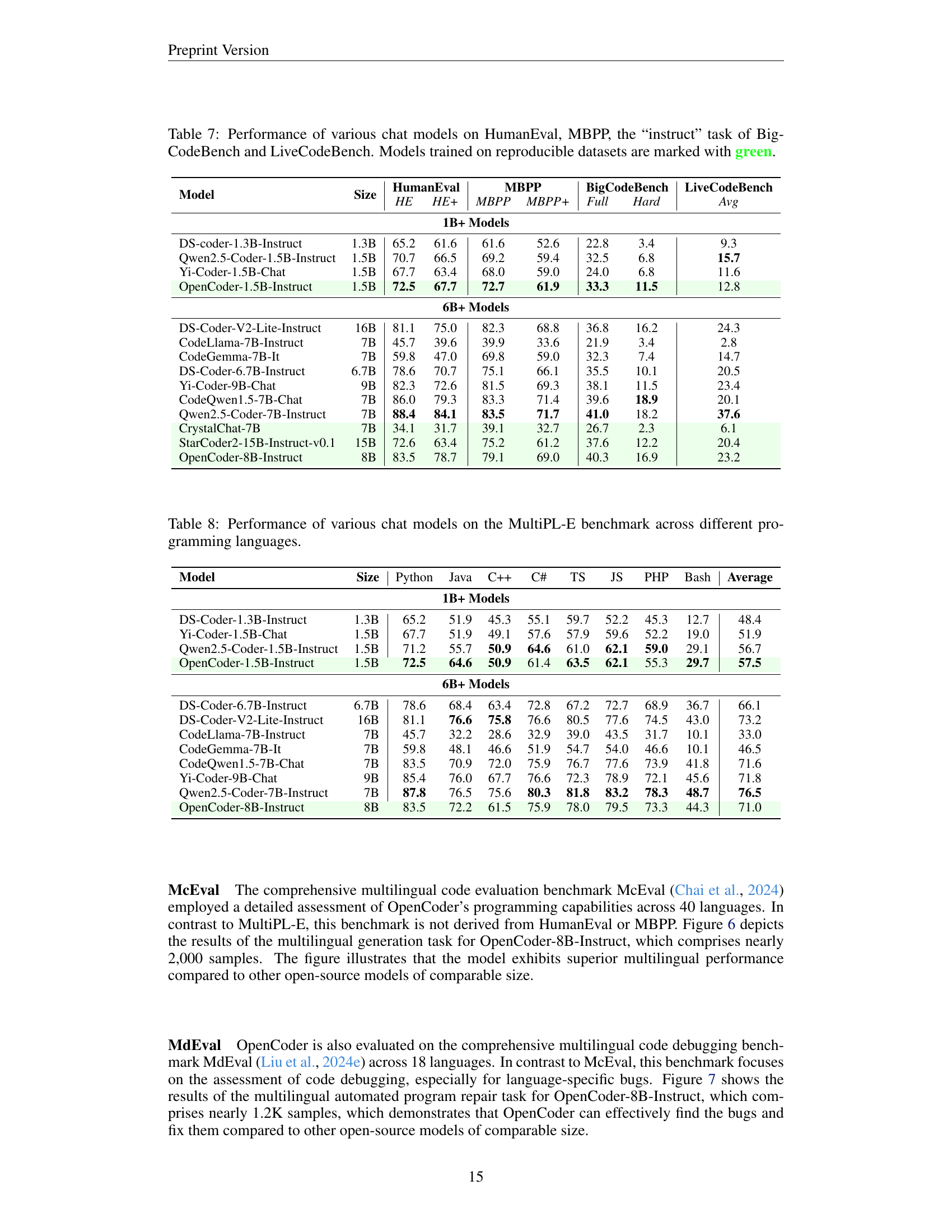
🔼 This table compares the performance of different chat models on four code-related benchmarks: HumanEval, MBPP, BigCodeBench’s ‘instruct’ task, and LiveCodeBench. It shows the Pass@1 scores (percentage of correctly solved problems) for each model across these benchmarks. The table highlights models trained using publicly available data (reproducible datasets) in green to emphasize the transparency and reproducibility of their training processes. The benchmarks cover different aspects of code understanding and generation ability.
read the caption
Table 7: Performance of various chat models on HumanEval, MBPP, the “instruct” task of BigCodeBench and LiveCodeBench. Models trained on reproducible datasets are marked with green.
| Model | Size | Python | Java | C++ | C# | TS | JS | PHP | Bash | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| 1B+ Models | ||||||||||
| DS-Coder-1.3B-Instruct | 1.3B | 65.2 | 51.9 | 45.3 | 55.1 | 59.7 | 52.2 | 45.3 | 12.7 | 48.4 |
| Yi-Coder-1.5B-Chat | 1.5B | 67.7 | 51.9 | 49.1 | 57.6 | 57.9 | 59.6 | 52.2 | 19.0 | 51.9 |
| Qwen2.5-Coder-1.5B-Instruct | 1.5B | 71.2 | 55.7 | 50.9 | 64.6 | 61.0 | 62.1 | 59.0 | 29.1 | 56.7 |
| OpenCoder-1.5B-Instruct | 1.5B | 72.5 | 64.6 | 50.9 | 61.4 | 63.5 | 62.1 | 55.3 | 29.7 | 57.5 |
| 6B+ Models | ||||||||||
| DS-Coder-6.7B-Instruct | 6.7B | 78.6 | 68.4 | 63.4 | 72.8 | 67.2 | 72.7 | 68.9 | 36.7 | 66.1 |
| DS-Coder-V2-Lite-Instruct | 16B | 81.1 | 76.6 | 75.8 | 76.6 | 80.5 | 77.6 | 74.5 | 43.0 | 73.2 |
| CodeLlama-7B-Instruct | 7B | 45.7 | 32.2 | 28.6 | 32.9 | 39.0 | 43.5 | 31.7 | 10.1 | 33.0 |
| CodeGemma-7B-It | 7B | 59.8 | 48.1 | 46.6 | 51.9 | 54.7 | 54.0 | 46.6 | 10.1 | 46.5 |
| CodeQwen1.5-7B-Chat | 7B | 83.5 | 70.9 | 72.0 | 75.9 | 76.7 | 77.6 | 73.9 | 41.8 | 71.6 |
| Yi-Coder-9B-Chat | 9B | 85.4 | 76.0 | 67.7 | 76.6 | 72.3 | 78.9 | 72.1 | 45.6 | 71.8 |
| Qwen2.5-Coder-7B-Instruct | 7B | 87.8 | 76.5 | 75.6 | 80.3 | 81.8 | 83.2 | 78.3 | 48.7 | 76.5 |
| OpenCoder-8B-Instruct | 8B | 83.5 | 72.2 | 61.5 | 75.9 | 78.0 | 79.5 | 73.3 | 44.3 | 71.0 |
🔼 This table presents a comprehensive comparison of different large language models (LLMs) on their ability to generate code in multiple programming languages. The MultiPL-E benchmark evaluates the models’ performance across various languages, providing insights into their cross-lingual code generation capabilities and identifying strengths and weaknesses in handling different programming paradigms and syntaxes. The table shows the performance metrics for each model across various languages, offering a detailed analysis of the models’ proficiency in multilingual code generation.
read the caption
Table 8: Performance of various chat models on the MultiPL-E benchmark across different programming languages.
| Deduplication Level | # Total Rows | # Retained Rows | # Retained Tokens |
|---|---|---|---|
| File level | 485,817,123 | 30,488,834 | 32.74 B |
| Repository level | 11,037,352 | 7,480,488 | 99.47 B |
🔼 This table presents a comparison of file-level and repository-level deduplication techniques applied to a Python code dataset. It shows the initial number of files and repositories, the number of files and repositories retained after deduplication, and the total number of tokens retained. This comparison highlights the impact of different deduplication strategies on data size and potentially on model training performance. The results are crucial for understanding the trade-offs between data size reduction and data diversity in building code large language models (LLMs).
read the caption
Table 9: The statistics for file level deduplication and repository level deduplication on Python code. Rows for file level and repository level represent the number of files and repositories, respectively.
| HE | HE+ | MBPP | MBPP+ | BigCodeBench | Code Arena | |
|---|---|---|---|---|---|---|
| Stage1 | 52.4 | 48.1 | 68.7 | 57.4 | 22.1 | 5.3 |
| Stage1 + Stage2 | 70.1 | 64.0 | 74.6 | 64.8 | 31.5 | 6.9 |
| Mix Training | 55.5 | 51.2 | 52.0 | 58.7 | 23.9 | 3.8 |
🔼 This table compares the performance of three different instruction tuning strategies for a 1.5B parameter language model: training only on Stage 1 data, training on both Stage 1 and Stage 2 data sequentially, and training on a mixture of both Stage 1 and Stage 2 data. The comparison is made across multiple code generation benchmarks (HumanEval, HumanEval+, MBPP, MBPP+, BigCodeBench, and Code Arena). The results show the impact of different data compositions and training approaches on the model’s ability to generate high-quality code.
read the caption
Table 10: Performance of different training strategies across benchmarks. Mix Training refers to the process of combining and shuffling the data from Stage 1 and Stage 2 for joint training.
| Description | Explanation | Filtering Quota |
|---|---|---|
| The proportion of lines in strings with a word count exceeding. | Files with too many long strings indicate a lack of code logic. | score “>” 0.2 |
| The proportion of characters in words from strings with a character count exceeding 20. | String variables containing long sequences of characters are often indicative of meaningless content such as base64 data, Hash encoding, url, etc. | score “>” 0.4 |
| The proportion of hexadecimal characters. | Files with two many hexadecimal characters indicate a lack of code logic. | score “>” 0.4 |
| The proportion of lines like “you code here”, “TODO” or “FIXME”. | We found that these elements tend to be excessively repeated in the dataset, which increases the likelihood that the model, during code completion, will output placeholders like the ones mentioned above instead of generating actual code. | score “>” 0.01 |
| The proportion of lines containing an “assert” statement. | Files containing a large number of ’assert’ statements are often test files, which tend to have relatively simple and repetitive code patterns. | score “>” 0.4 |
🔼 Table 11 presents examples of general heuristic filtering rules used in the data cleaning pipeline. These rules are not language-specific and apply to various code files. The table details the specific criteria used in the filtering process, along with an explanation and the filtering threshold value used for each rule. These rules aim to remove low-quality code, such as those with excessive long strings, hexadecimal characters, or comments like ‘You code here’. The filtering quota is a score that helps to evaluate how well the rule performs. The goal is to identify and remove code that contains low-quality or non-informative elements to improve overall data quality for model training.
read the caption
Table 11: Examples of general code filtering rules.
| Description | Explanation | Filtering Quota |
|---|---|---|
| The proportion of the number of python functions to the total number of lines. | A higher number of Python functions in a file may indicate that the functions are overly simple, with limited code logic, or have a bad code format. | score > 0.2 |
| Whether the file can be parsed into an python abstract syntax tree (AST). | Files that cannot be parsed into an AST contain syntax errors and should be filtered out. | score == False |
| The proportion of lines that are “import” statements. | A file with exceeding prportion of “import” statements indicates to have sparse code logic. | score > 0.3 |
🔼 Table 12 presents examples of filtering rules specifically designed for Python code within the data preprocessing pipeline. These rules leverage Python-specific syntax and characteristics to identify and remove low-quality code snippets, improving the overall quality of the training dataset. Each rule includes a description of the characteristic being checked, an explanation of why that characteristic is indicative of low-quality code, and the filtering threshold applied.
read the caption
Table 12: Examples of python-specific filtering rules.
| Level | # Total Lines | # Retained Lines | # Retained Tokens |
|---|---|---|---|
| Chunk-level | 333,007,812 | 79,272,460 | 324.70 B |
| File-level | 485,817,123 | 30,488,834 | 32.74 B |
| File-level + Chunk-level | 333,007,812 | 7,993,164 | 32.70 B |
| Repo-level | 11,037,352 | 7,480,488 | 99.47 B |
| Repo-level + Chunk-level | 333,007,812 | 17,675,781 | 72.40 B |
🔼 This table compares different deduplication methods used on Python code data for model training. It shows the total number of lines of code before deduplication, the number of lines retained after applying various deduplication strategies (file-level, repository-level, and chunk-level), and the resulting number of tokens. The key difference is how deduplication is performed: file-level considers individual files, repository-level treats all files within a repository as one unit, and chunk-level works on 4096-token segments of code. The table clarifies the line count units for each strategy to avoid ambiguity.
read the caption
Table 13: Comparison of deduplication strategies on Python data. At the File level, 'Lines' refers to the number of lines in individual files; at the Repo level, it indicates the line count of aggregated strings; Note that for all deduplication strategies involving the Chunk level, 'Lines' specifically refers to 4096-token chunks.
| Domain | Prefix | Tag |
|---|---|---|
| cloud.tencent.com | %cloud.tencent.com/developer/article% | Code |
| cloud.tencent.com | %cloud.tencent.com/ask% | Code |
| cloud.tencent.com | %cloud.tencent.com/developer/information% | Code |
| cloud.tencent.com | %cloud.tencent.com/document% | Code |
| my.oschina.net | %my.oschina.net%blog% | Code |
| ask.csdn.net | %ask.csdn.net/questions% | Code |
| www.cnblogs.com | %www.cnblogs.com% | Code |
| forum.ubuntu.org.cn | %forum.ubuntu.org.cn% | Code |
| q.cnblogs.com | %q.cnblogs.com/q% | Code |
| segmentfault.com | %segmentfault.com/q% | Code |
| segmentfault.com | %segmentfault.com/a% | Code |
| woshipm.com | %woshipm.com/data-analysis% | Code |
| zgserver.com | %zgserver.com/server% | Code |
| zgserver.com | %zgserver.com/linux% | Code |
| zgserver.com | %zgserver.com/ubuntu% | Code |
| juejin.cn | %juejin.cn/post% | Code |
| jiqizhixin.com | %jiqizhixin.com/articles% | Code |
| help.aliyun.com | %help.aliyun.com/zh% | Code |
| jyeoo.com | %jyeoo.com% | Math |
| www.haihongyuan.com | %haihongyuan.com%shuxue% | Math |
| www.03964.com | %www.03964.com% | Math |
| www.nbhkdz.com | %www.nbhkdz.com% | Math |
| 9512.net | %9512.net% | Math |
| lanxicy.com | %lanxicy.com% | Math |
| bbs.emath.ac.cn | %bbs.emath.ac.cn% | Math |
| math.pro | %math.pro% | Math |
| mathschina.com | %mathschina.com% | Math |
| shuxue.chazidian.com | %shuxue.chazidian.com% | Math |
| shuxue.ht88.com | %shuxue.ht88.com% | Math |
🔼 This table details the manually annotated Chinese web domains categorized as either code-related or math-related. The annotation uses the ‘%’ symbol as a wildcard to match URL patterns, allowing for flexible identification of relevant domains. For example, the pattern ‘%my.oschina.net%blog%’ would match URLs like ‘https://my.oschina.net/u/4/blog/11'. This list of domains was used as seed data for identifying similar web pages during data collection.
read the caption
Table 14: We manually annotate code-like and math-like Chinese domains, utilizing the ’%’ symbol as a wildcard in our pattern matching. For example, the URL ’https://my.oschina.net/u/4/blog/11’ is matched by the pattern ’%my.oschina.net%blog%’.
| Model | # Tokens | # Languages | # Web Data Tokens | # Rules | LS Rules |
|---|---|---|---|---|---|
| The Stack v1 | 200 B | 88 | \ | ~15 | ✗ |
| The Stack v2 | 900 B | 619 | ~30 B | ~15 | ✗ |
| RefineCode | 960 B | 607 | ~75 B | ~130 | ✓ |
🔼 This table compares the training data used in RefineCode with that of two previous versions of The Stack dataset. It highlights key differences in the size of the datasets (measured in tokens and the number of programming languages included), and details the number of filtering rules applied during dataset creation. Importantly, it notes whether language-specific rules were used in the process, indicating a more sophisticated approach to data refinement in RefineCode compared to The Stack.
read the caption
Table 15: The Comparison of training data between RefineCode and series of The Stack. “LS” denotes “Language Specific”.
| Language | # Files (After deduplication) | Vol(GB) (After deduplication) | Ratio(%) (After deduplication) | # Files (After filtering) | Vol(GB) (After filtering) | Ratio(%) (After filtering) |
|---|---|---|---|---|---|---|
| html | 141,081,897 | 3,175.4 | 8.56 | 45,100,466 | 582.4 | 18.08 |
| java | 215,177,833 | 706.8 | 1.90 | 124,751,295 | 474.3 | 14.72 |
| python | 109,725,362 | 493.3 | 1.33 | 58,640,346 | 271.1 | 8.41 |
| csharp | 88,825,202 | 364.2 | 0.98 | 57,910,485 | 232.4 | 7.21 |
| javascript | 190,670,421 | 1,925.0 | 5.19 | 69,579,517 | 226.9 | 7.04 |
| php | 84,378,361 | 374.4 | 1.01 | 60,089,397 | 222.7 | 6.91 |
| cpp | 51,362,503 | 375.2 | 1.01 | 38,037,406 | 176.9 | 5.49 |
| go | 35,649,865 | 301.1 | 0.81 | 26,723,829 | 153.7 | 4.77 |
| typescript | 40,211,985 | 287.4 | 0.77 | 20,621,755 | 140.4 | 4.35 |
| ruby | 15,735,042 | 244.5 | 0.66 | 8,285,561 | 122.7 | 3.81 |
| perl | 16,354,543 | 121.7 | 0.33 | 9,532,620 | 65.6 | 2.04 |
| rust | 10,605,421 | 63.6 | 0.17 | 6,086,150 | 39.9 | 1.24 |
| r | 6,132,978 | 92.5 | 0.25 | 4,803,109 | 34.7 | 1.08 |
| swift | 4,238,754 | 47.9 | 0.13 | 2,938,498 | 31.8 | 0.99 |
| kotlin | 4,493,548 | 56.4 | 0.15 | 3,123,156 | 29.8 | 0.94 |
| dart | 4,087,329 | 33.0 | 0.09 | 2,161,462 | 18.5 | 0.57 |
| java-pages | 6,174,654 | 31.0 | 0.08 | 4,145,336 | 15.4 | 0.48 |
| css | 39,822,744 | 241.5 | 0.65 | 15,771,061 | 15.3 | 0.47 |
| lua | 4,027,221 | 116.0 | 0.31 | 2,538,234 | 14.4 | 0.45 |
| xml | 61,171,289 | 1,934.2 | 5.21 | 3,173,128 | 12.8 | 0.40 |
| scala | 5,897,567 | 19.7 | 0.05 | 4,204,979 | 11.7 | 0.36 |
| shell | 12,054,632 | 23.0 | 0.06 | 6,043,070 | 11.2 | 0.35 |
| pascal | 1,306,130 | 27.8 | 0.07 | 960,497 | 9.5 | 0.29 |
| fortran | 2,274,663 | 39.7 | 0.10 | 1,218,491 | 8.6 | 0.27 |
| perl6 | 1,943,430 | 16.4 | 0.04 | 1,034,748 | 8.6 | 0.27 |
| rmarkdown | 1,317,760 | 14.0 | 0.04 | 827,951 | 7.9 | 0.25 |
| html+erb | 7,618,377 | 11.4 | 0.03 | 4,452,355 | 7.8 | 0.24 |
| smali | 3,457,531 | 37.9 | 0.10 | 1,408,274 | 7.4 | 0.23 |
| scss | 18,061,278 | 35.6 | 0.10 | 7,705,822 | 7.4 | 0.23 |
| gettext catalog | 1,100,044 | 51.3 | 0.14 | 442,385 | 6.3 | 0.19 |
| haskell | 1,746,444 | 24.0 | 0.06 | 1,218,491 | 6.8 | 0.27 |
| tcl | 253,345 | 4.2 | 0.01 | 136,171 | 1.0 | 0.03 |
| gradle | 2,431,985 | 2.9 | 0.01 | 724,609 | 1.0 | 0.03 |
| scheme | 357,909 | 4.7 | 0.01 | 201,170 | 1.0 | 0.03 |
| qml | 354,756 | 1.8 | 0.01 | 252,621 | 1.0 | 0.03 |
| mdx | 795,525 | 6.4 | 0.17 | 222,013 | 1.0 | 0.03 |
| classic asp | 220,344 | 2.8 | 0.08 | 141,236 | 0.9 | 0.03 |
| xbase | 192,780 | 2.5 | 0.07 | 80,396 | 0.9 | 0.03 |
| ini | 7,232,136 | 19.1 | 0.05 | 1,517,099 | 1.3 | 0.04 |
| objective-c++ | 197,416 | 2.4 | 0.01 | 149,223 | 1.3 | 0.04 |
| motorola68k | 1,066,095 | 26.5 | 0.07 | 220,218 | 1.2 | 0.04 |
| gap | 752,261 | 2.6 | 0.01 | 510,420 | 1.2 | 0.04 |
🔼 Table 16 presents a detailed breakdown of the composition of the RefineCode dataset, specifically focusing on the top 85 programming languages. It shows the number of files and the volume (in GB) before and after deduplication and filtering for each language. The languages are listed in descending order based on their file volume after the filtering process, offering insights into the data’s distribution and the impact of data cleaning steps.
read the caption
Table 16: Overview of the data composition of in RefineCode. The items in the table are sorted in descending order according to the file volume after filtering.
Full paper#