↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Existing video-based large multimodal models (LMMs) struggle with precise, pixel-level grounding of video content based on textual input. This is largely due to the complex spatial and temporal dynamics inherent in videos. They typically handle basic conversations but fail to pinpoint objects and regions in the video precisely. This lack of fine-grained understanding restricts their practical applications in advanced video analysis tasks.
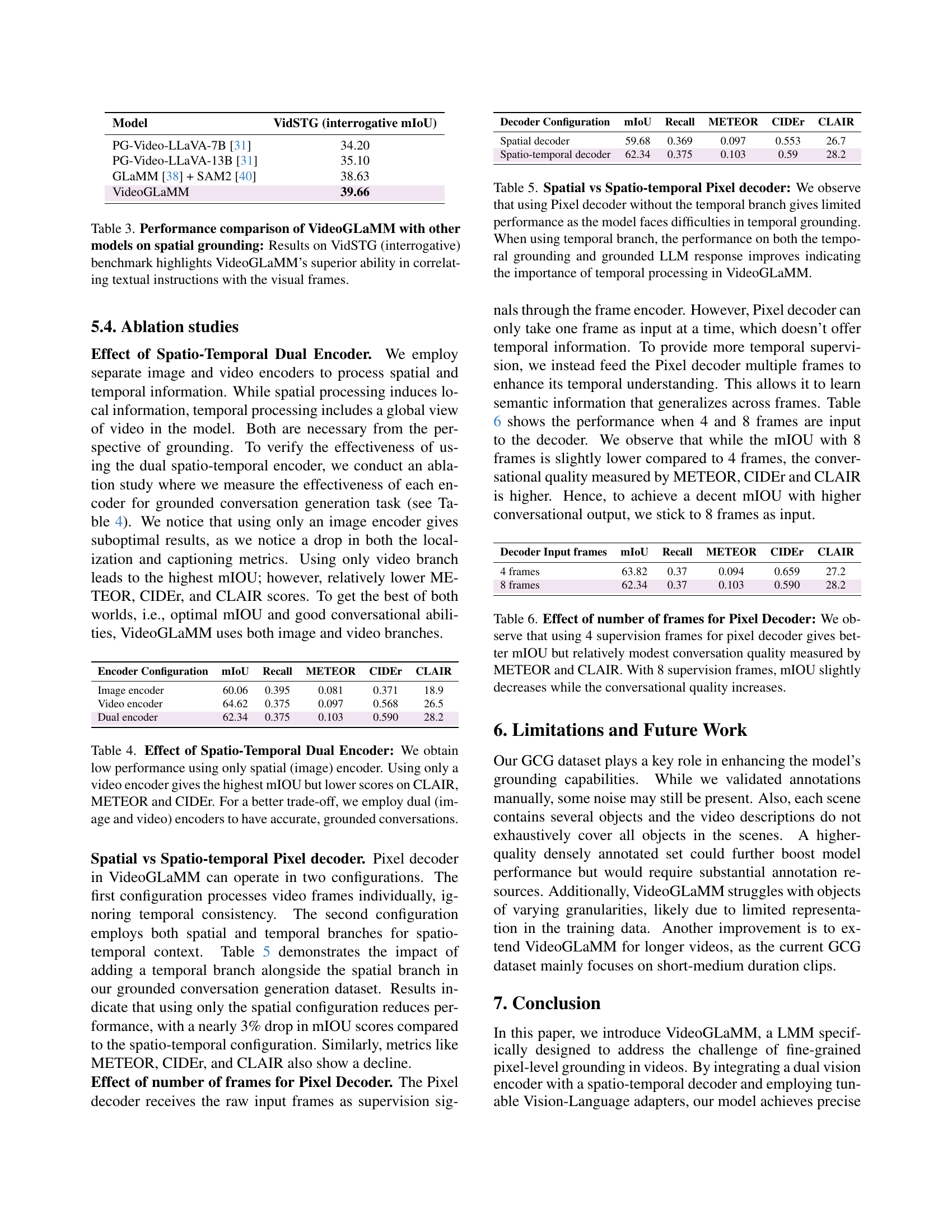
To overcome this, the authors introduce VideoGLaMM, a novel LMM designed for fine-grained pixel-level grounding. VideoGLaMM uses a unique architecture comprising three key components: a Large Language Model (LLM), a dual vision encoder capturing spatial and temporal details, and a spatio-temporal decoder for generating precise object masks. These components are interconnected via adapters which ensure close Vision-Language alignment. VideoGLaMM is trained on a meticulously curated multimodal dataset featuring detailed, visually grounded conversations. Evaluation across three challenging tasks shows VideoGLaMM outperforming existing approaches, demonstrating its efficacy in grounded conversation generation, visual grounding, and referring video segmentation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces VideoGLaMM, a novel approach to pixel-level visual grounding in videos, a crucial task with implications for various applications like video question answering and referring video segmentation. The work addresses the limitations of existing models by incorporating a dual vision encoder for spatial-temporal features and using tunable adapters for efficient vision-language alignment. The introduction of a new benchmark dataset and its superior performance on three challenging tasks showcase the significance of this research and open avenues for further exploration in multimodal video understanding. The proposed method bridges a gap in the field by achieving fine-grained visual grounding, advancing the capabilities of large multimodal models for video analysis.
Visual Insights#

🔼 VideoGLaMM, a new multimodal video conversational model, generates pixel-level grounded text descriptions. Unlike previous models, VideoGLaMM provides fine-grained descriptions detailing various levels of granularity (person, objects, scene attributes) and spatio-temporally consistent masks across video frames. This allows for a more nuanced understanding of the video content than previously possible with existing Video-LMMs.
read the caption
Figure 1: Grounded Conversation with VideoGLaMM. Our proposed multimodal video conversational model provides text responses grounded at the pixel level in the input video. The generated masks are spatio-temporally consistent across frames. The fine-grained grounded outputs from VideoGLaMM describe different levels of granularity, e.g., person, objects (bike), stuff (road), and explain object and scene attributes. Existing Video-LMMs do not offer pixel-level grounded conversational capability.
| Model | mIoU | Recall | METEOR | CIDEr | CLAIR |
|---|---|---|---|---|---|
| PG-Video-LLaVA [31] | 24.03 | 0.093 | 0.10 | 0.01 | 15.0 |
| GLaMM [38] + SAM2 [40] | 28.60 | 0.117 | 0.097 | 0.15 | 22.9 |
| VideoGLaMM | 62.34 | 0.375 | 0.103 | 0.59 | 28.2 |
🔼 This table presents a quantitative comparison of VideoGLaMM against two baseline models (PG-Video-LLaVA and GLaMM+SAM2) on the Grounded Conversation Generation (GCG) task. The metrics used are mIOU (mean Intersection over Union) and Recall, evaluating the accuracy of generated segmentation masks; and METEOR, CIDEr, and CLAIR, assessing the quality of the generated video-level captions. Higher scores indicate better performance in both mask generation and caption description quality, demonstrating the model’s ability to accurately generate descriptive video captions aligned with precise pixel-level segmentations. VideoGLaMM shows significant improvement over the baseline models across all metrics.
read the caption
Table 1: Evaluation on grounded conversation generation (GCG): VideoGLaMM shows superior performance in generating accurate video-level captions which are tied to corresponding segmentation masks in the video frames.
In-depth insights#
Video-LLM Grounding#
Video-LLM grounding presents a significant challenge and opportunity in bridging the gap between visual understanding and language processing. Existing methods often struggle with fine-grained alignment, especially in handling complex spatio-temporal dynamics within videos. This necessitates the development of advanced models capable of precise pixel-level grounding, allowing for detailed and accurate descriptions directly tied to specific visual elements. The success of such models hinges upon the ability to effectively align visual features with language representations at a granular level. This could involve innovative encoder-decoder architectures, optimized training strategies, and potentially novel datasets featuring detailed visual annotations. A key aspect is the creation of robust benchmark datasets with fine-grained annotations including spatio-temporal masks and corresponding captions, enabling proper evaluation and further advancements. Future research should focus on developing more efficient and scalable techniques to achieve robust pixel-level grounding for a wider range of video understanding tasks.
Dual Encoding Design#
A dual encoding design in a multimodal video model, like the one described, is a crucial architectural choice for effectively handling the complexities of video data. By employing separate encoders for spatial and temporal features, the model avoids the limitations of a single encoder that struggles to capture both local details and global temporal context simultaneously. The spatial encoder focuses on extracting detailed information from individual frames, identifying specific objects and their attributes. Concurrently, the temporal encoder processes sequences of frames, capturing dynamic changes and interactions over time. This dual approach allows the model to achieve a more nuanced understanding of the video content, enabling it to ground visual information accurately in both space and time. The fusion of these distinct representations is key, requiring a carefully designed mechanism for effective integration before feeding them into subsequent processing stages, usually including an LLM. This design enhances the model’s capability to align the visual inputs with textual queries, resulting in more precise and contextually relevant responses. This is essential for tasks like video question answering and grounded conversation generation where fine-grained visual grounding is critical.
Benchmark Dataset#
The creation of a new benchmark dataset is a critical contribution of this research. The paper highlights the lack of existing datasets suitable for evaluating fine-grained pixel-level visual grounding in videos, a limitation that hinders progress in this area. The newly constructed dataset addresses this gap by providing detailed, visually-grounded conversations with corresponding spatio-temporal masks. This annotation is not trivial, requiring a semi-automatic pipeline to efficiently generate high-quality data. The scale of the dataset (38k video-QA triplets, 83k objects, and 671k masks) is significant and suggests a robust benchmark for future research. The dataset’s diversity and the semi-automatic pipeline’s efficiency represent a considerable advance over previous methodologies. The dataset’s multimodal nature is key, incorporating video data, textual annotations, and precise pixel-level masks, allowing for comprehensive evaluation of models’ capabilities in aligning these modalities. This detailed approach to data collection promises to be a valuable tool for researchers to further advance the field of video understanding and visual grounding.
Ablation Experiments#
Ablation experiments systematically remove components of a model to understand their individual contributions. In the context of a multimodal video grounding model, this would involve progressively disabling features like the spatial encoder, temporal encoder, or attention mechanisms. Results would show the impact of each component on performance metrics, such as mIOU for mask generation or various language evaluation scores. For example, removing the spatial encoder might drastically reduce the accuracy of localizing objects, while removing the temporal encoder could impair understanding of temporal relationships within the video. A well-designed ablation study should reveal which components are crucial for the model’s success and which are less important. Analyzing these results allows for refinements, such as optimizing less critical components for efficiency or identifying areas where additional complexity might yield better results. Such experiments are vital in guiding the model’s development and demonstrating a deep understanding of its inner workings. The ablation should compare several variants, including a full model, and those lacking key components, providing quantitative and qualitative evidence on the contribution of each part. This would strengthen the claims about the effectiveness of the model’s architecture.
Future of Video-LLMs#
The future of Video-LLMs hinges on several key advancements. Improved multimodal alignment is crucial; current methods struggle with precise spatiotemporal grounding, limiting the model’s ability to understand nuanced video content. Developing more sophisticated architectures that seamlessly integrate vision and language, perhaps moving beyond simple projection layers, is vital. Larger and more diverse datasets are needed to overcome current limitations in data representation, especially concerning fine-grained annotations and diverse video styles. Enhanced training methodologies should address efficient alignment and prevent overfitting, incorporating techniques like self-supervised learning or reinforcement learning for better generalization. Finally, ethical considerations surrounding bias, transparency, and potential misuse must guide future development. Addressing these challenges will pave the way for Video-LLMs that truly understand and interact with videos at a human level, opening up many new applications in education, healthcare, entertainment, and beyond.
More visual insights#
More on figures

🔼 VideoGLaMM processes user queries by first encoding video content into spatial (local details) and temporal (global context) features using a dual spatio-temporal encoder. These features are then aligned with textual information via Vision-to-Language (V→L) adapters. The combined spatial, temporal, and textual data is fed into a Large Language Model (LLM), which generates a response and corresponding segmentation masks. A Language-to-Vision (L→V) projector aligns the LLM’s response with the visual space of the pixel decoder. Finally, the aligned LLM features, along with frame features from a separate frame encoder, are input to a grounded pixel decoder which outputs fine-grained object masks that precisely match the objects mentioned in the LLM’s response.
read the caption
Figure 2: Working of VideoGLaMM. VideoGLaMM consists of a dual spatio-temporal encoder for encoding image and video level features. The spatial features represent the local information and the temporal features represent global information. The spatial and temporal tokens are passed through V-L adapters and concatenated with the text tokens, before feeding to LLM. A L-V projector is employed to align LLM’s response with the visual space of pixel decoder. Finally, the aligned LLM features along with the frame features from a frame encoder are passed to a grounded pixel decoder, to obtain the fine-grained object masks corresponding to the LLM response.

🔼 This figure illustrates the semi-automatic annotation pipeline used to create the Grounded Conversation Generation (GCG) dataset. The pipeline handles three types of video data: 1) Videos with only masks, where object patches are extracted, processed by the Gemini model for initial descriptions, refined for detailed captions, and then fed back into Gemini with the masks to create dense, grounded captions. 2) Videos with bounding box annotations and captions, where frames are processed by a Video-LMM for a comprehensive caption, combined with the original caption and fed to GPT-4 to generate dense captions, and masks are created using the SAM model with frames and bounding boxes. 3) Videos with bounding boxes and referring expressions, where frames, bounding boxes, and referring expressions are input to GPT-4 for dense captions, and masks are generated using the SAM model with frames and bounding boxes.
read the caption
Figure 3: Proposed Semi-automatic Annotation Pipeline. Our dataset for grounded conversation generation (GCG) is built from three video dataset types: i) Videos having masks only: Object patches are extracted from video frames using masks and processed by the Gemini model for initial object descriptions, which are then refined to produce detailed object captions. These refined captions and masks are used again with the Gemini model to create dense, grounded captions. ii) Videos having bbox annotations and captions: Frames are first processed with a Video-LMM to generate a comprehensive caption which is combined with the original caption and fed to GPT-4o to obtain dense grounded captions. Masks are generated using frames and ground-truth bounding boxes with the SAM model. iii) Videos having object bboxes and referring expressions: Frames, bounding boxes, and referring expressions are input to GPT-4o for dense grounded captions, while masks are generated by feeding frames and bounding boxes to the SAM model.

🔼 Figure 4 showcases VideoGLaMM’s performance on Grounded Conversation Generation (GCG). The model receives user queries about videos. In response, it produces detailed textual descriptions. Importantly, these descriptions are not just general summaries but pinpoint specific objects and phrases within the video using pixel-level segmentation masks. The masks visually highlight the precise parts of the video the model is referring to in its text. The figure provides several examples demonstrating VideoGLaMM’s capability to accurately identify and label objects, illustrating its in-depth understanding of the video content.
read the caption
Figure 4: Qualitative results of VideoGLaMM on grounded conversation generation (GCG). Given user queries, the VideoGLaMM generates textual responses and grounds objects and phrases using pixel-level masks, showing its detailed understanding of the video.
More on tables
| Model | \mathcal{J} | \mathcal{F} | \mathcal{J&F} |
|---|---|---|---|
| PG-Video-LLaVA [31] | 18.35 | 19.39 | 18.87 |
| GLaMM [38] + SAM2 [40] | 35.80 | 41.50 | 38.66 |
| VideoLISA [5] | 41.30 | 47.60 | 44.40 |
| VideoGLaMM | 42.07 | 48.23 | 45.15 |
🔼 This table presents an ablation study evaluating the impact of using different encoder configurations in the VideoGLaMM model on the task of grounded conversation generation. The study compares three setups: using only the spatial (image) encoder, using only the temporal (video) encoder, and using both spatial and temporal encoders (the full VideoGLaMM model). The results show that relying solely on the spatial encoder leads to significantly worse performance across all metrics (mIOU, Recall, METEOR, CIDEr, and CLAIR). While using only the temporal encoder achieves the highest mIOU (indicating better object localization), it performs poorly in terms of the conversational quality metrics (METEOR, CIDEr, and CLAIR). The table concludes that using both encoders provides the best balance, achieving high accuracy in object grounding while maintaining strong conversational quality.
read the caption
Table 4: Effect of Spatio-Temporal Dual Encoder: We obtain low performance using only spatial (image) encoder. Using only a video encoder gives the highest mIOU but lower scores on CLAIR, METEOR and CIDEr. For a better trade-off, we employ dual (image and video) encoders to have accurate, grounded conversations.
| Model | VidSTG (interrogative mIoU) |
|---|---|
| PG-Video-LLaVA-7B [31] | 34.20 |
| PG-Video-LLaVA-13B [31] | 35.10 |
| GLaMM [38] + SAM2 [40] | 38.63 |
| VideoGLaMM | 39.66 |
🔼 This ablation study investigates the impact of incorporating temporal information into the pixel decoder of the VideoGLaMM model. The table compares the model’s performance on grounded conversation generation when using only a spatial pixel decoder versus a spatio-temporal pixel decoder. The results demonstrate that including the temporal branch significantly improves both the accuracy of temporal grounding (as measured by mIOU) and the quality of the generated language responses (as measured by METEOR, CIDEr, and CLAIR). This highlights the crucial role of temporal context for effective visual grounding in video.
read the caption
Table 5: Spatial vs Spatio-temporal Pixel decoder: We observe that using Pixel decoder without the temporal branch gives limited performance as the model faces difficulties in temporal grounding. When using temporal branch, the performance on both the temporal grounding and grounded LLM response improves indicating the importance of temporal processing in VideoGLaMM.
| Encoder Configuration | mIoU | Recall | METEOR | CIDEr | CLAIR |
|---|---|---|---|---|---|
| Image encoder | 60.06 | 0.395 | 0.081 | 0.371 | 18.9 |
| Video encoder | 64.62 | 0.375 | 0.097 | 0.568 | 26.5 |
| Dual encoder | 62.34 | 0.375 | 0.103 | 0.590 | 28.2 |
🔼 This table presents an ablation study analyzing the impact of the number of input frames to the pixel decoder on the performance of the VideoGLaMM model. The study reveals a trade-off between mask accuracy (mIOU) and conversational quality (METEOR, CIDEr, CLAIR). Using 4 frames yields a slightly better mIOU, but lower conversational quality scores, compared to using 8 frames. Using 8 frames achieves a somewhat lower mIOU score, but significantly improves the conversational quality metrics.
read the caption
Table 6: Effect of number of frames for Pixel Decoder: We observe that using 4 supervision frames for pixel decoder gives better mIOU but relatively modest conversation quality measured by METEOR and CLAIR. With 8 supervision frames, mIOU slightly decreases while the conversational quality increases.
Full paper#