↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for generating 3D and 4D scenes from images face limitations in controllability and realism. Existing video diffusion models struggle to directly reconstruct 3D/4D scenes due to limited spatial and temporal control during generation. Also, there is a lack of large-scale 3D and 4D video datasets.
DimensionX overcomes these limitations by introducing ST-Director, which decouples spatial and temporal factors in video diffusion. This enables precise manipulation of spatial structure and temporal dynamics. Additional techniques like trajectory-aware mechanisms and identity-preserving denoising further enhance the realism of generated 3D and 4D scenes. The results demonstrate DimensionX’s superior performance compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework, DimensionX, that allows for the generation of highly realistic 3D and 4D scenes from a single image using controllable video diffusion. This addresses a critical gap in current technology, enabling researchers to explore new avenues in visual content creation and manipulation. The proposed ST-Director method offers improved controllability over spatial and temporal factors in video generation, leading to more realistic and consistent outputs. DimensionX’s superior performance in video, 3D, and 4D generation opens doors for advancements in virtual and augmented reality, computer graphics, and other related fields.
Visual Insights#

🔼 Figure 1 showcases DimensionX’s capabilities. Given a single input image (top left), DimensionX generates a diverse range of outputs. These include: videos with controlled camera movement or object motion (middle); full 3D scene renderings from novel viewpoints (bottom left); and 4D scene representations illustrating changes over time from new perspectives (bottom right). This demonstrates the model’s ability to understand and generate both spatial and temporal aspects of scenes from a single image.
read the caption
Figure 1: With just a single image as input, our proposed DimensionX can generate highly realistic videos and 3D/4D environments that are aware of spatial and temporal dimensions.
| Methods | Tank and Temples | Tank and Temples | Tank and Temples | MipNeRF360 | MipNeRF360 | MipNeRF360 | LLFF | LLFF | LLFF | DL3DV | DL3DV | DL3DV | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Single-View | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | ||
| ZeroNVS [38] | 12.31 | 0.301 | 0.567 | 15.84 | 0.327 | 0.536 | 15.62 | 0.497 | 0.354 | 12.39 | 0.251 | 0.559 | ||
| ViewCrafter [61] | 15.18 | 0.499 | 0.319 | 15.65 | 0.404 | 0.378 | 17.56 | 0.620 | 0.337 | 14.78 | 0.422 | 0.417 | ||
| Ours | 17.11 | 0.613 | 0.199 | 18.91 | 0.527 | 0.333 | 20.38 | 0.744 | 0.200 | 18.28 | 0.642 | 0.215 | ||
| Sparse-View | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | ||
| DNGaussian [22] | 12.13 | 0.292 | 0.511 | 15.21 | 0.127 | 0.632 | 17.51 | 0.586 | 0.409 | 14.99 | 0.286 | 0.432 | ||
| InstantSplat [10] | 18.70 | 0.634 | 0.258 | 16.80 | 0.574 | 0.296 | 22.33 | 0.818 | 0.149 | 18.30 | 0.691 | 0.222 | ||
| ViewCrafter [61] | 18.76 | 0.637 | 0.216 | 18.49 | 0.691 | 0.212 | 21.60 | 0.823 | 0.155 | 19.19 | 0.686 | 0.196 | ||
| Ours | 20.42 | 0.668 | 0.185 | 20.21 | 0.713 | 0.184 | 25.11 | 0.913 | 0.067 | 21.69 | 0.780 | 0.124 |
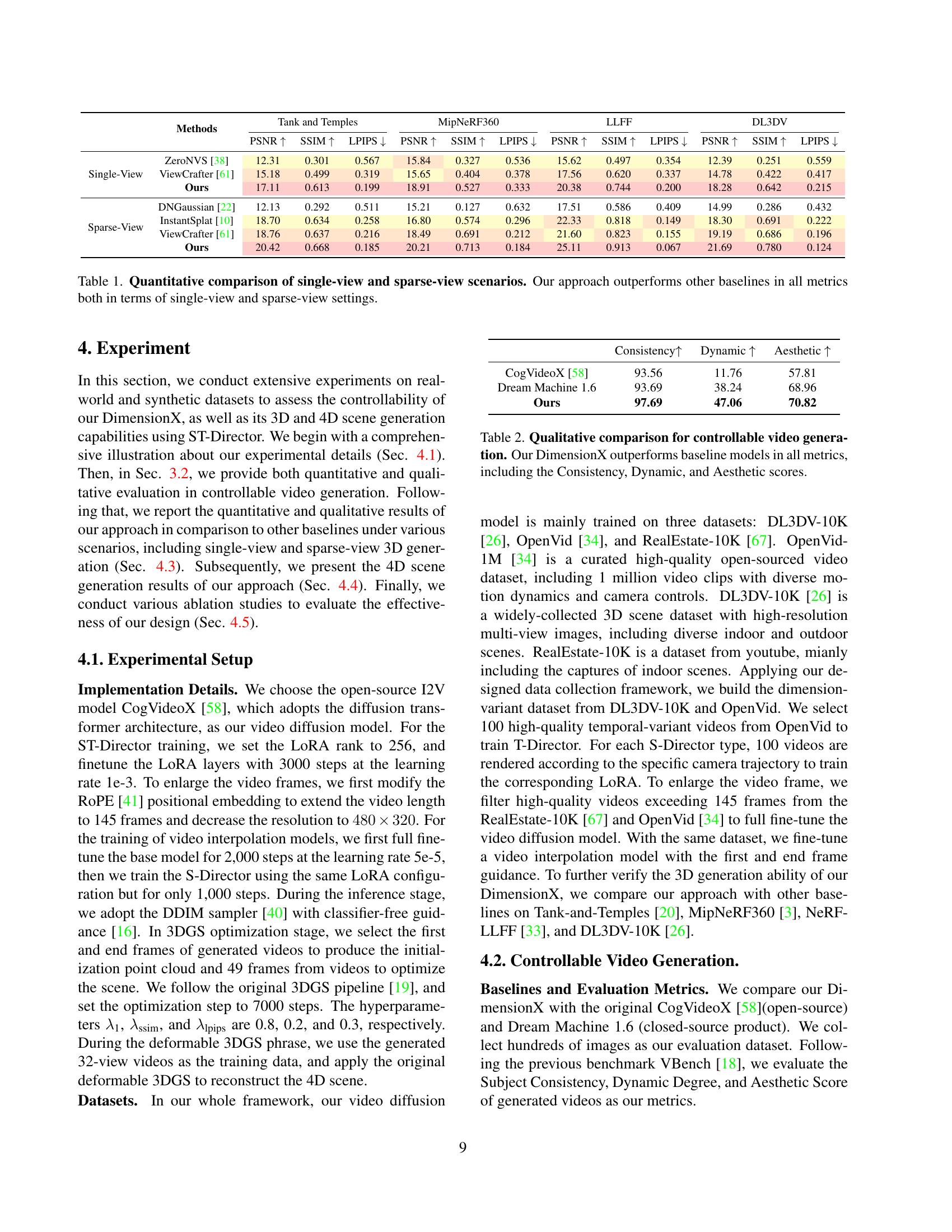
🔼 This table presents a quantitative comparison of different methods for 3D scene generation from single and sparse views. The methods are evaluated using three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Higher PSNR and SSIM values indicate better image quality, while a lower LPIPS value signifies higher perceptual similarity to the ground truth. The results show that the proposed method consistently outperforms other state-of-the-art techniques in both single-view and sparse-view scenarios across all three metrics.
read the caption
Table 1: Quantitative comparison of single-view and sparse-view scenarios. Our approach outperforms other baselines in all metrics both in terms of single-view and sparse-view settings.
In-depth insights#
ST-Director: Core#
The conceptual core of ST-Director lies in its decomposition of spatial and temporal factors within video diffusion. This is crucial because traditional approaches struggle to independently control these aspects during video generation, hindering the creation of precise 3D/4D reconstructions. By decoupling these elements, ST-Director allows for finer-grained manipulation of both spatial structure (via S-Director) and temporal dynamics (via T-Director). This is achieved through dimension-aware LoRAs, trained on datasets specifically designed to isolate spatial and temporal variations. The framework’s ingenuity lies in enabling these directors to operate orthogonally, offering a flexible approach for controlling individual dimensions or their combined effect. This approach allows for the generation of highly realistic videos that exhibit consistent spatial and temporal coherence, ultimately paving the way for high-quality, controllable 3D and 4D scene reconstruction.
Dimension-aware Control#
The concept of ‘Dimension-aware Control’ in the context of video generation using diffusion models is a significant advancement. It addresses the limitations of existing methods that struggle with precise manipulation of both spatial and temporal aspects within generated videos. Dimension-aware control, as described in the paper, achieves this precision by decoupling spatial and temporal factors. This decoupling allows for independent control over camera movement (spatial) and object motion/temporal evolution (temporal). This is achieved through the use of dimension-aware LoRAs (Low-Rank Adaptation), effectively learning separate representations for spatial and temporal variations from specialized datasets. The training of these separate LoRAs enables fine-grained manipulation of each dimension, creating a powerful tool to reconstruct both 3D and 4D representations from sequential frames. The framework introduces a training-free composition method for seamless integration of the spatially and temporally controlled outputs, further enhancing the quality and realism of the generated videos. The effectiveness of this approach hinges on the careful curation of datasets with controlled variation in spatial and temporal elements, providing the necessary data for the LoRAs to learn meaningful, dimension-specific representations. Ultimately, dimension-aware control is not just a technique, but a paradigm shift. It moves beyond simple conditional generation towards a more nuanced and powerful form of control over the generative process, unlocking unprecedented flexibility in creating highly realistic and controllable videos and 3D/4D scenes.
Hybrid-Dimension Control#
The concept of ‘Hybrid-Dimension Control’ in the context of video generation using diffusion models presents a novel approach to manipulating both spatial and temporal aspects simultaneously. Instead of treating spatial and temporal dimensions as separate entities, this method seeks to decouple and then recombine them for precise control during the generation process. This decoupling, achieved through dimension-aware components (e.g., LoRAs), allows independent control over spatial elements (camera position, object placement) and temporal elements (motion, dynamics) of a scene. The strategic recombination of these independently controlled dimensions enables the creation of videos and 3D/4D scenes with a level of realism and coherence previously unattainable. This is particularly important in handling complex real-world scenarios where both spatial and temporal consistency are crucial for faithful scene reconstruction. Furthermore, the framework leverages a training-free composition strategy, which is particularly valuable for efficiently achieving control without demanding additional extensive training on massive datasets. This approach shows promising results in enhancing the realism of generated 3D and 4D video, creating high-fidelity, dynamic virtual environments with precise control over every detail.
3D/4D Scene Generation#
The paper introduces a novel framework, DimensionX, for generating high-fidelity 3D and 4D scenes from a single image. A core contribution is ST-Director, which decouples spatial and temporal factors in video diffusion, enabling precise control over each dimension. This is achieved by training dimension-aware LoRAs on specialized datasets exhibiting spatial and temporal variations. For 3D generation, DimensionX employs a trajectory-aware mechanism, handling diverse camera movements by training multiple S-Directors. In 4D generation, an identity-preserving denoising strategy ensures consistency across spatial variations in temporally evolving scenes. The framework leverages a training-free composition method, enabling flexible hybrid spatial-temporal control. DimensionX demonstrates significant improvements over existing methods in controllable video and 3D/4D scene generation, showcasing its potential for creating realistic and dynamic visual content from minimal input.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of video diffusion models is crucial, as the current computational cost limits broader applications. This might involve investigating more efficient architectures or training strategies, potentially leveraging advancements in model compression techniques. Expanding the controllability of the framework is another key area. While DimensionX offers considerable control over spatial and temporal factors, enhancing fine-grained manipulation of specific objects or events within a scene would significantly increase its versatility. Addressing the challenges of generating high-fidelity 4D scenes from limited input data presents another opportunity. Exploring innovative data augmentation or synthesis techniques, potentially combined with improved implicit 3D representation methods, could enhance scene realism and detail. Finally, exploring different diffusion model architectures or integrating other generative models could lead to advancements in generation quality, speed, and versatility. Integrating physics-based simulation into the framework could allow for the creation of more realistic and physically plausible dynamic scenes.
More visual insights#
More on figures

🔼 DimensionX’s framework is composed of three main stages: controllable video generation using ST-Director (decomposing spatial and temporal parameters via dimension-aware LoRAs); 3D scene generation from a single view’s video frames using S-Director; and 4D scene generation by first generating a temporal-variant video with T-Director, selecting a keyframe to produce a spatial-variant reference video with S-Director, and refining this with multiple iterations of T-Director to create consistent multi-view videos for 4D scene optimization.
read the caption
Figure 2: Pipeline of DimensionX. Our framework is mainly divided into three parts. (a) Controllable Video Generation with ST-Director. We introduce ST-Director to decompose the spatial and temporal parameters in video diffusion models by learning dimension-aware LoRA on our collected dimension-variant datasets. (b) 3D Scene Generation with S-Director. Given one view, a high-quality 3D scene is recovered from the video frames generated by S-Director. (c) 4D Scene Generation with ST-Director. Given a single image, a temporal-variant video is produced by T-Director, from which a key frame is selected to generate a spatial-variant reference video. Guided by the reference video, per-frame spatial-variant videos are generated by S-Director, which are then combined into multi-view videos. Through the multi-loop refinement of T-Director, consistent multi-view videos are then passed to optimize the 4D scene.

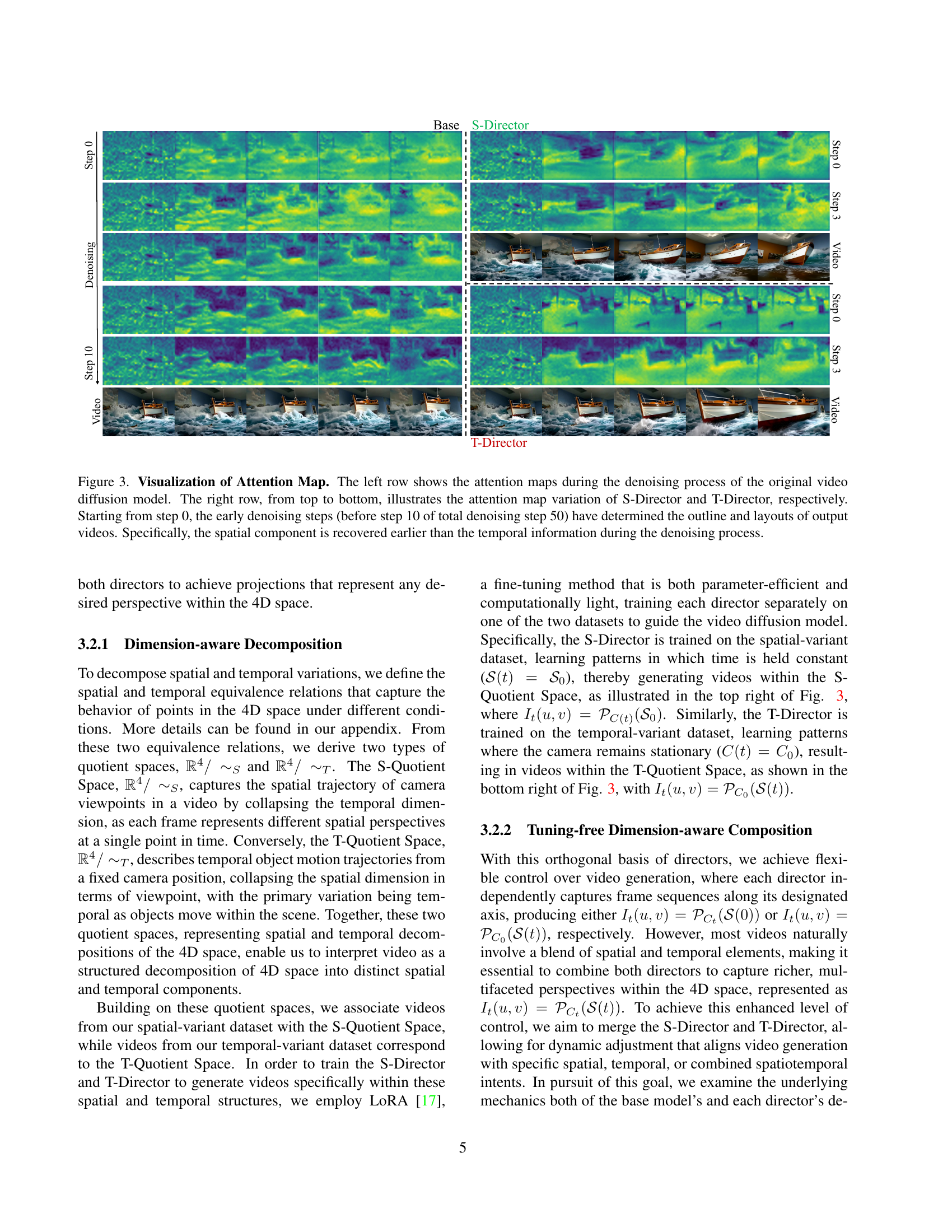
🔼 This figure visualizes attention maps during the video denoising process. The left side shows the attention maps from the original video diffusion model, while the right side displays how the S-Director (spatial) and T-Director (temporal) affect the attention maps. Analysis reveals that the spatial component of the video is defined earlier in the process than the temporal component. The early steps of denoising (before step 10 out of 50) largely determine the overall structure and layout of the generated videos. This highlights how the model prioritizes spatial information before focusing on temporal details.
read the caption
Figure 3: Visualization of Attention Map. The left row shows the attention maps during the denoising process of the original video diffusion model. The right row, from top to bottom, illustrates the attention map variation of S-Director and T-Director, respectively. Starting from step 0, the early denoising steps (before step 10 of total denoising step 50) have determined the outline and layouts of output videos. Specifically, the spatial component is recovered earlier than the temporal information during the denoising process.

🔼 This figure displays a qualitative comparison of DimensionX’s dimension-aware video generation capabilities. Three rows demonstrate different controlled video generations using the same image and text prompt. The first row shows a temporal-variant video where only the content changes, keeping the camera static. The second row illustrates spatial-variant video generation, with the camera zooming out while the content remains relatively unchanged. Finally, the third row showcases a combination of spatial and temporal variations in video generation, featuring a camera orbiting the subject. This figure highlights DimensionX’s ability to control both the spatial and temporal aspects of video generation independently and together.
read the caption
Figure 4: Qualitative comparison in dimension-aware video generation. Given the same image and text prompt, the first row is the temporal-variant video generation (camera static), the second row is the spatial-variant video generation (camera zoom out), and the third row is the spatial- and temporal-variant video generation (camera orbit right).

🔼 This figure compares the 3D reconstruction results of different methods using only two wide-angle input views. DimensionX, the authors’ method, is shown to produce significantly better results than the other baselines (ViewCrafter and InstantSplat) in terms of overall 3D scene quality and fidelity.
read the caption
Figure 5: Qualitative Comparison in sparse-view 3D generation. Given two large-angle views, our approach obviously outperforms other baselines.

🔼 Figure 6 presents qualitative results demonstrating DimensionX’s 4D scene generation capabilities. Starting with a single real-world or synthetic image as input, the model generates a sequence of videos representing dynamic scenes with intricate details and coherent visual features. The figure showcases examples of these generated 4D scenes, highlighting the model’s ability to produce complex, photorealistic outputs from minimal input.
read the caption
Figure 6: Qualitative results of 4D scene generation. Given a real-world or synthetic single image, our DimensionX produces coherent and intricate 4D scenes with rich features.

🔼 This ablation study analyzes the impact of the S-Director on sparse-view 3D scene generation. Two sets of results are presented, one where the S-Director is included and one where it is excluded. The figures show input images, the ground truth 3D scene, and the generated 3D scenes. The inclusion of the S-Director leads to a significant improvement in the quality of the reconstructed 3D scene. The absence of the S-Director results in lower reconstruction quality, indicated by noticeable artifacts and reduced detail. Quantitative metrics, such as PSNR, SSIM, and LPIPS, are provided to support these observations.
read the caption
Figure 7: Ablation study on the sparse-view 3D generation: The absence of S-Director results in lower reconstruction quality.
Full paper#