↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current research focuses on 1-bit Large Language Models (LLMs) to reduce inference costs, but these models face challenges with outlier activation values causing quantization errors. This often leads to performance degradation. Existing solutions for handling outliers often add complexity or are not suitable for 1-bit LLMs.
BitNet a4.8 tackles these issues using a hybrid approach. It combines 4-bit activation quantization with sparsification, focusing on specific layers to mitigate quantization errors caused by outlier activations. The results show that BitNet a4.8 achieves performance comparable to existing 1-bit LLMs with significantly faster inference speed, only using 55% of parameters. This hybrid approach improves the efficiency of large-scale LLM deployment and inference.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances the efficiency of large language models (LLMs). By achieving comparable performance to existing 1-bit LLMs while using 4-bit activations, it offers a substantial improvement in inference speed. This is crucial for deploying LLMs in resource-constrained environments, making them more accessible for wider applications. The research opens up new avenues for exploring hybrid quantization and sparsification techniques in model optimization, contributing to future developments in LLM efficiency.
Visual Insights#

🔼 BitNet a4.8 uses a hybrid approach to quantization, combining both weight and activation quantization. The weights are ternary (1.58 bits), as in its predecessor BitNet b1.58. However, activations are handled differently. Inputs to the attention and feed-forward network (FFN) layers utilize 4-bit quantization. To manage potential errors caused by outlier values in certain Transformer sub-layers, intermediate states undergo a sparsification process followed by 8-bit quantization. This combination aims to balance quantization efficiency with accuracy.
read the caption
Figure 1: The overview of BitNet a4.8 with both weight and activation quantization. All the parameters are ternery (i.e., 1.58-bit as in BitNet b1.58 [12]). We use a hybrid quantization and sparsification strategy to deal with outlier activations in certain Transformer sub-layers.
| Models | Size | PPL↓ | ARCc↑ | ARCe↑ | HS↑ | PQ↑ | WGe↑ | Avg↑ |
|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 11.44 | 27.13 | 43.27 | 44.70 | 68.12 | 53.99 | 47.44 |
| BitNet b1.58 | 12.32 | 25.00 | 42.68 | 42.08 | 66.97 | 54.14 | 46.17 | |
| BitNet a4.8 (FP4) | 12.40 | 25.17 | 42.68 | 42.36 | 66.27 | 52.96 | 45.89 | |
| BitNet a4.8 | 12.40 | 25.17 | 41.58 | 42.44 | 66.38 | 53.04 | 45.72 | |
| LLaMA LLM | 1.3B | 10.82 | 27.90 | 45.16 | 47.65 | 69.91 | 53.35 | 48.79 |
| BitNet b1.58 | 11.27 | 27.65 | 45.33 | 46.86 | 68.39 | 54.06 | 48.46 | |
| BitNet a4.8 (FP4) | 11.38 | 28.50 | 44.36 | 47.03 | 68.61 | 54.06 | 48.51 | |
| BitNet a4.8 | 11.35 | 28.50 | 44.15 | 46.98 | 68.34 | 54.14 | 48.42 | |
| LLaMA LLM | 3B | 9.61 | 29.95 | 48.11 | 55.25 | 71.76 | 57.46 | 52.51 |
| BitNet b1.58 | 9.97 | 29.27 | 49.41 | 54.42 | 70.89 | 57.54 | 52.30 | |
| BitNet a4.8 (FP4) | 9.99 | 29.10 | 49.24 | 54.60 | 71.38 | 56.12 | 52.08 | |
| BitNet a4.8 | 9.97 | 28.33 | 49.58 | 54.62 | 71.16 | 54.38 | 51.61 | |
| LLaMA LLM | 7B | 9.20 | 33.36 | 51.22 | 58.33 | 73.34 | 58.41 | 54.93 |
| BitNet b1.58 | 9.24 | 32.00 | 50.88 | 59.79 | 72.96 | 59.83 | 55.09 | |
| BitNet a4.8 (FP4) | 9.42 | 31.57 | 51.22 | 58.20 | 72.47 | 59.59 | 54.61 | |
| BitNet a4.8 | 9.37 | 31.66 | 50.88 | 58.78 | 73.01 | 59.35 | 54.74 |
🔼 This table presents a comparison of the performance of three different language models: BitNet a4.8, BitNet b1.58, and LLaMA, across various sizes (700M, 1.3B, 3B, and 7B parameters). For each model size, it shows the perplexity (PPL) score on a held-out dataset and zero-shot accuracy scores on several downstream tasks: ARC-Challenge (ARCc), ARC-Easy (ARCe), HellaSwag (HS), PIQA (PQ), Winogrande (WGe). The average of these downstream task scores is also provided. The table highlights the comparable performance of BitNet a4.8 to BitNet b1.58, despite BitNet a4.8 using 4-bit activations, suggesting improved efficiency.
read the caption
Table 1: Perplexity and results of BitNet a4.8, BitNet b1.58 and LLaMA LLM on the end tasks. The standard variance of error for average scores is 1.06%.
In-depth insights#
4-bit Activation#
The concept of “4-bit activation” in the context of large language models (LLMs) represents a significant advancement in efficient model design. Reducing the bit-width of activations from the typical 8-bit or even higher precision to 4-bit drastically decreases computational costs and memory usage. This is especially crucial for inference, where latency and resource consumption are primary concerns. However, simply truncating the precision of activations leads to significant information loss and performance degradation. The research likely explores sophisticated quantization techniques to minimize this loss, potentially involving methods like hybrid quantization and sparsification. These techniques cleverly combine different quantization strategies across layers or parts of the model, for example, using 4-bit quantization only on certain input layers and switching to lower or higher bit-widths in other layers. Sparsification, which involves setting a significant number of activation values to zero, reduces computational complexity further. The effectiveness of such hybrid approaches lies in cleverly addressing the challenges posed by outlier activations, which disproportionately affect model accuracy when aggressively quantized. The paper likely benchmarks the performance of these methods against full-precision models and demonstrates a satisfactory accuracy/efficiency trade-off.
Hybrid Quantization#
Hybrid quantization, as discussed in the context of the research paper, presents a sophisticated approach to address the challenges of low-bit quantization in large language models (LLMs). It strategically combines different quantization techniques to leverage their respective strengths while mitigating their weaknesses. The core idea is to selectively apply various bit-widths to different parts of the model based on the characteristics of the data or the layer’s function. This adaptive approach is crucial because activations in LLMs often exhibit a long-tailed distribution, with outlier values causing significant quantization errors. By employing a hybrid scheme, the technique can effectively quantize typical activations with lower bit-widths (e.g., 4-bit) while handling outliers using a higher bit-width (e.g., 8-bit) or sparsification to improve accuracy. The results demonstrate the effectiveness of this method in maintaining model performance and significantly reducing computational costs, offering a powerful trade-off between efficiency and accuracy. Hybrid quantization represents a step forward in optimizing LLMs for real-world deployment, allowing for faster inference without sacrificing performance. The technique’s adaptability makes it particularly well-suited for diverse model architectures and datasets.
Sparsification Strategy#
The effectiveness of a sparsification strategy hinges on its ability to selectively remove less-important activations without significantly impacting model performance. A successful strategy must carefully consider the distribution of activations. Simply removing activations based on magnitude alone might prove insufficient, as it could inadvertently discard crucial information. The paper’s hybrid approach is intriguing, combining quantization with sparsification to address this challenge. By targeting outlier channels, which while sparse in number exert disproportionate influence, the strategy aims to minimize quantization errors. The choice of 8-bit quantization for intermediate states, while sparsifying, suggests a balance between accuracy preservation and computational savings. The strategy’s efficacy is further enhanced by its integration within the training process, using a two-stage recipe to adapt the model to the lower-bit activations, ensuring a seamless transition.
Training Efficiency#
Training efficiency is a crucial aspect of large language model (LLM) development, impacting both time and resource consumption. The paper’s focus on BitNet a4.8 highlights strategies to enhance this efficiency. Continue-training from a pre-trained model (BitNet b1.58) is employed, reducing the need for extensive training from scratch. A two-stage training recipe further streamlines the process by first training with 8-bit activations and then transitioning to the target 4-bit activations. This approach minimizes training time and computational costs. The use of straight-through estimator (STE) for gradient approximation simplifies the training process by bypassing non-differentiable functions. Finally, mixed-precision training, which combines different precision levels during the training, allows efficient utilization of hardware resources. This combination of techniques demonstrates that significant gains in training efficiency can be achieved without sacrificing model performance.
LLM Deployment#
Efficient Large Language Model (LLM) deployment is crucial for realizing their full potential. Reducing inference costs is paramount, and techniques like quantization (reducing the numerical precision of model weights and activations) and sparsification (reducing the number of non-zero parameters) are vital. The paper highlights BitNet a4.8’s efficiency gains through 4-bit activations and a hybrid quantization/sparsification strategy, targeting outlier channels to mitigate quantization errors. Faster inference is achieved using 4-bit kernels. Furthermore, the model’s reduced parameter count (55% activation) and support for 3-bit KV cache significantly lower memory demands and improve deployment efficiency in large-scale scenarios. These optimizations are critical for deploying LLMs on resource-constrained devices or within cost-effective cloud infrastructures.
More visual insights#
More on figures

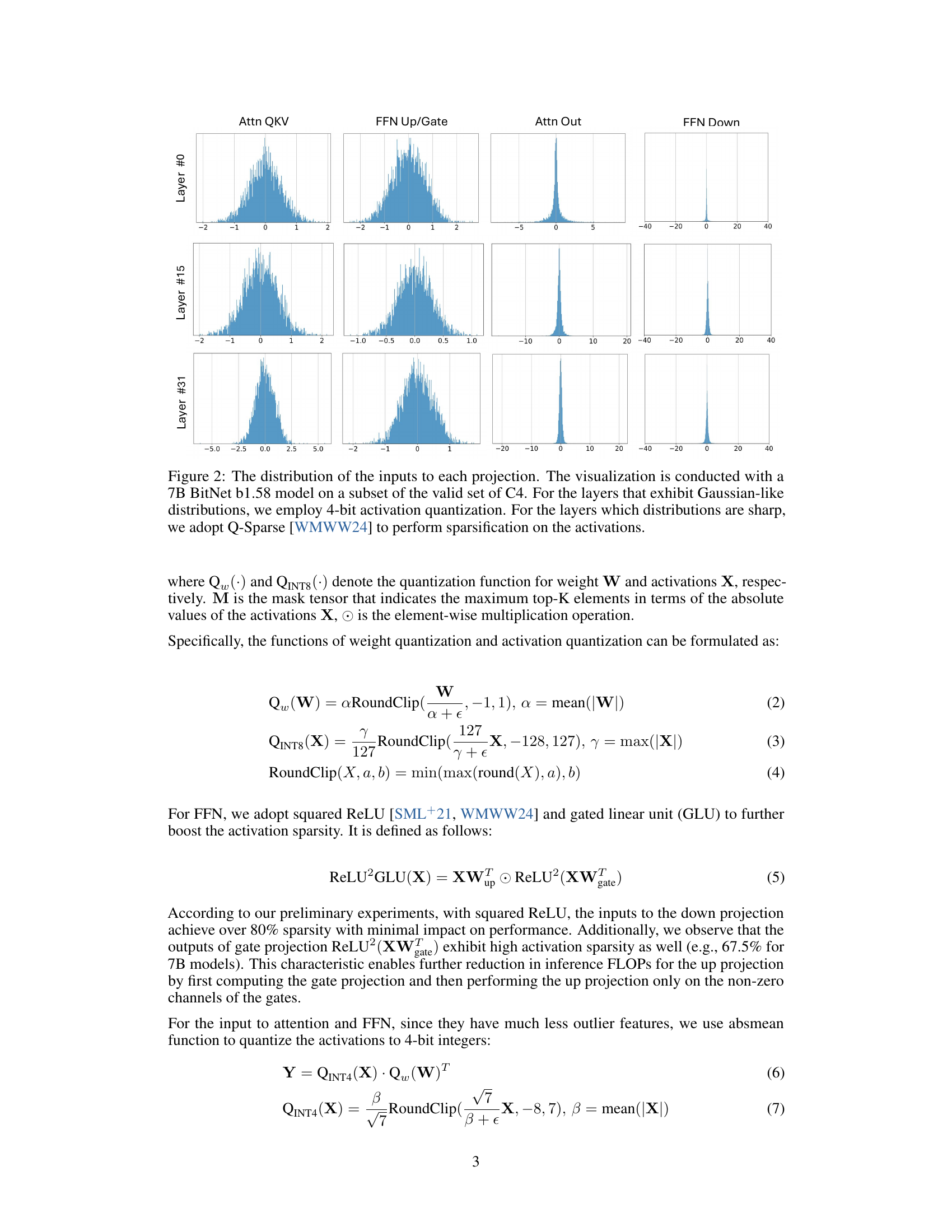
🔼 Figure 2 presents the distribution patterns of inputs for different projections within a 7B parameter BitNet b1.58 model, using a subset of the C4 validation dataset. The visualizations reveal that some layers exhibit Gaussian-like distributions, leading to the application of 4-bit activation quantization. Other layers, however, show sharp distributions, prompting the use of Q-Sparse (a technique described in reference [18] of the paper) for sparsification of the activations. This figure highlights the model’s adaptive quantization strategy based on the input distribution characteristics.
read the caption
Figure 2: The distribution of the inputs to each projection. The visualization is conducted with a 7B BitNet b1.58 model on a subset of the valid set of C4. For the layers that exhibit Gaussian-like distributions, we employ 4-bit activation quantization. For the layers which distributions are sharp, we adopt Q-Sparse [18] to perform sparsification on the activations.

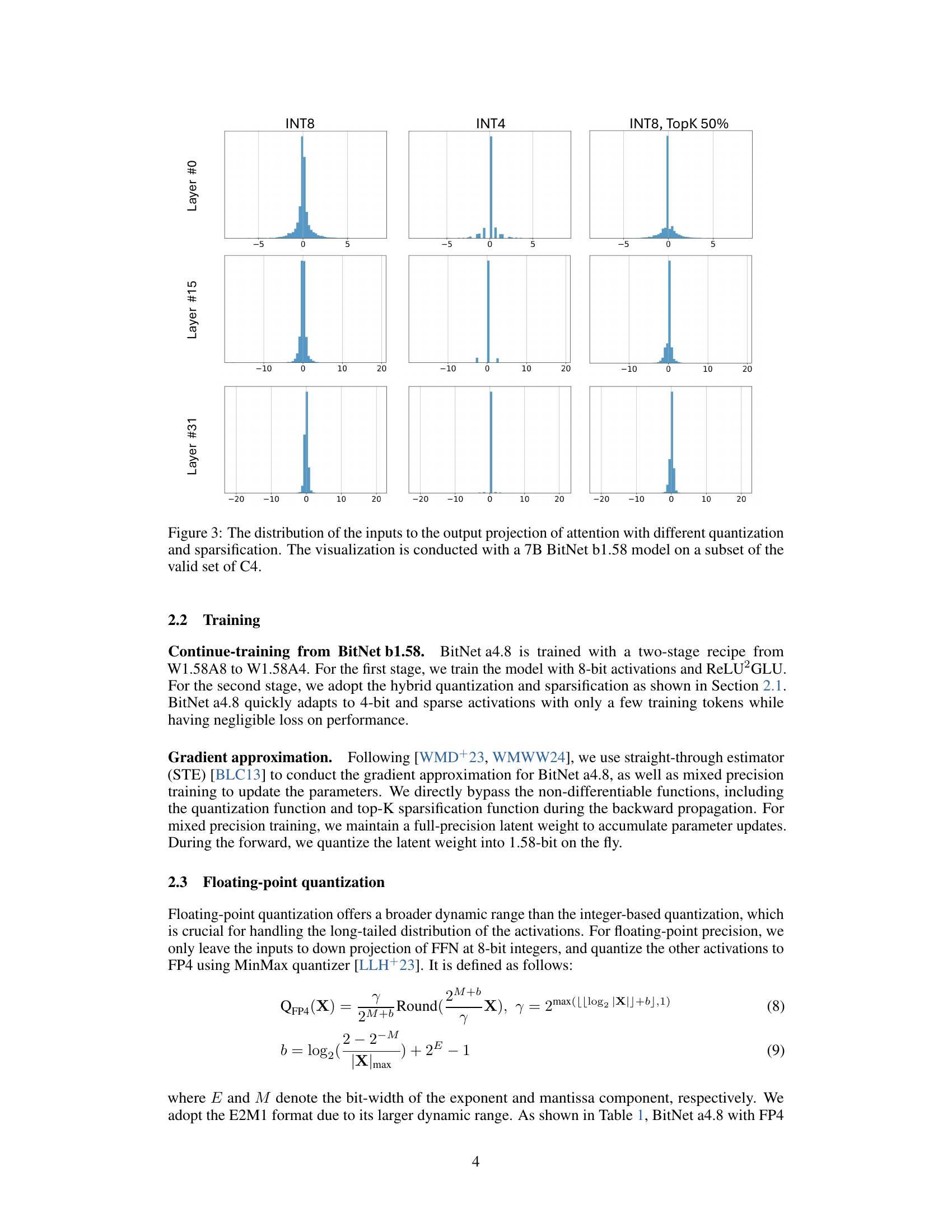
🔼 This figure compares the distribution of inputs to the output projection of the attention mechanism in a 7B parameter BitNet b1.58 model under different quantization and sparsification strategies. It visualizes the impact of these techniques on the distribution of activation values. The three subplots show how using INT8 (8-bit integer) quantization, INT4 (4-bit integer) quantization, and a combined INT8 quantization with TopK 50% sparsification affects the activation value distribution. This helps illustrate the effectiveness of the hybrid quantization and sparsification approach in managing outliers and maintaining performance. The data is from a subset of the valid set of C4.
read the caption
Figure 3: The distribution of the inputs to the output projection of attention with different quantization and sparsification. The visualization is conducted with a 7B BitNet b1.58 model on a subset of the valid set of C4.

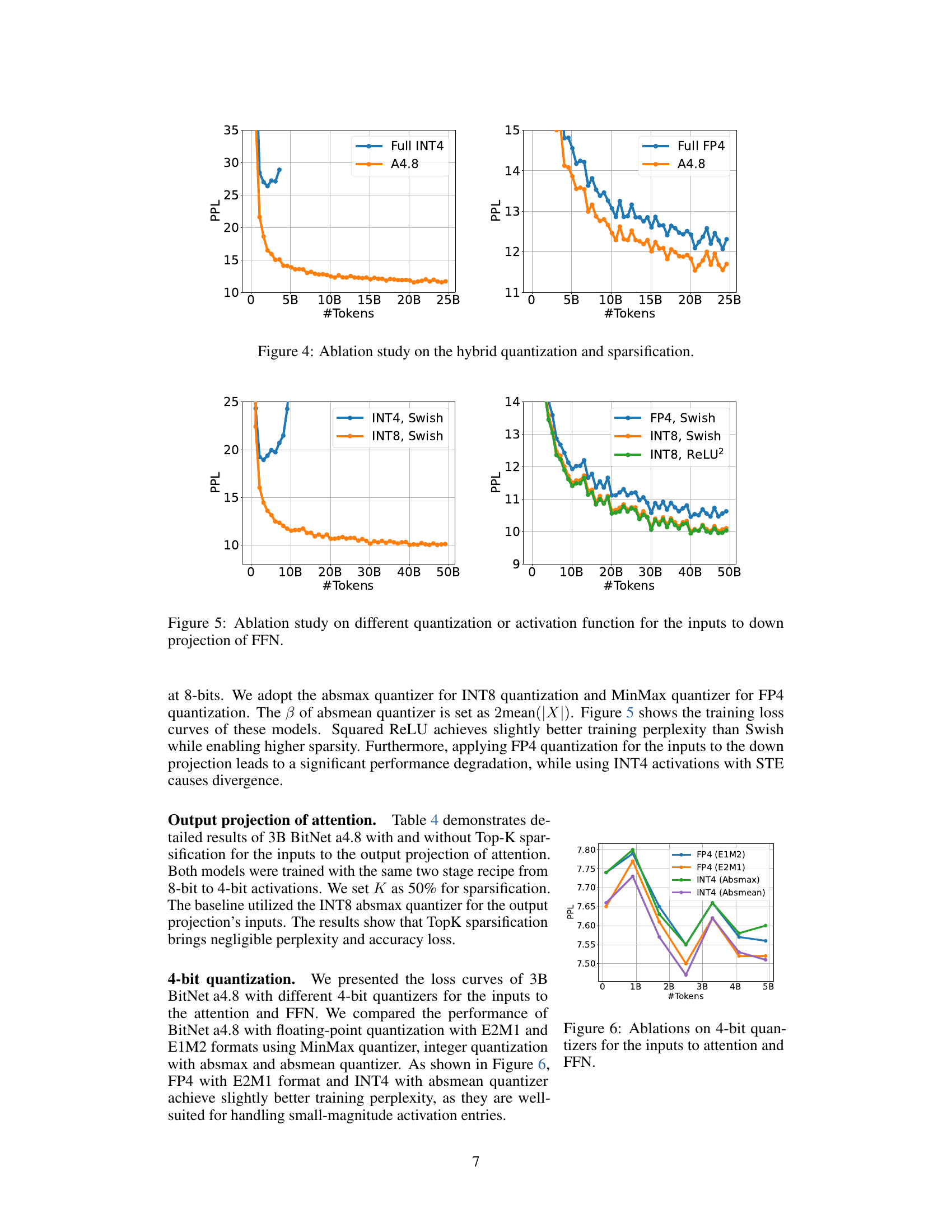
🔼 This figure presents an ablation study comparing the performance of different quantization strategies on a language model. It shows the training loss curves for a model trained with full 4-bit integer (INT4) quantization, full 4-bit floating-point (FP4) quantization, and the hybrid quantization and sparsification approach (A4.8) proposed in the paper. The graph visualizes how the training loss changes over the number of training tokens used, allowing comparison of the different approaches.
read the caption
Figure 4: Ablation study on the hybrid quantization and sparsification.

🔼 This ablation study investigates the impact of various quantization methods (INT4, FP4, INT8) and activation functions (Swish, ReLU2) on the inputs to the feed-forward network’s (FFN) down projection. The figure displays the training loss curves for different configurations, allowing for a comparison of their performance in terms of training perplexity. It helps determine the optimal combination of quantization and activation function for this specific layer of the model.
read the caption
Figure 5: Ablation study on different quantization or activation function for the inputs to down projection of FFN.

🔼 This figure presents an ablation study comparing different 4-bit quantization methods for the inputs of the attention and feed-forward network (FFN) layers. It shows the training loss curves for various quantization techniques, including floating-point quantization with different exponent and mantissa bit configurations (E1M2 and E2M1 formats using MinMax quantizer), and integer quantization using absmax and absmean quantizers. The goal is to determine which 4-bit quantization approach yields the best training performance for these critical layers in the model.
read the caption
Figure 6: Ablations on 4-bit quantizers for the inputs to attention and FFN.
More on tables
| Models | Activated | QKV | Out | Up | Gate | Down | Overall |
|---|---|---|---|---|---|---|---|
| LLaMA LLM | 679M | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| BitNet b1.58 | 638M | 1.2 | 5.9 | 1.2 | 1.2 | 21.8 | 6.2 |
| BitNet a4.8 | 390M | 12.1 | 50.0 | 66.2 | 12.1 | 80.9 | 42.5 |
| LLaMA LLM | 1.2B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| BitNet b1.58 | 1.1B | 1.3 | 5.8 | 1.2 | 1.2 | 22.8 | 6.4 |
| BitNet a4.8 | 0.7B | 12.0 | 50.0 | 65.9 | 12.1 | 81.8 | 42.7 |
| LLaMA LLM | 3.2B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| BitNet b1.58 | 3.0B | 1.4 | 7.1 | 1.3 | 1.3 | 30.0 | 8.2 |
| BitNet a4.8 | 1.8B | 12.1 | 50.0 | 70.7 | 12.1 | 85.6 | 44.7 |
| LLaMA LLM | 6.5B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| BitNet b1.58 | 6.0B | 1.7 | 11.2 | 1.4 | 1.4 | 24.2 | 7.3 |
| BitNet a4.8 | 3.4B | 12.1 | 50.0 | 71.4 | 12.0 | 84.2 | 44.5 |
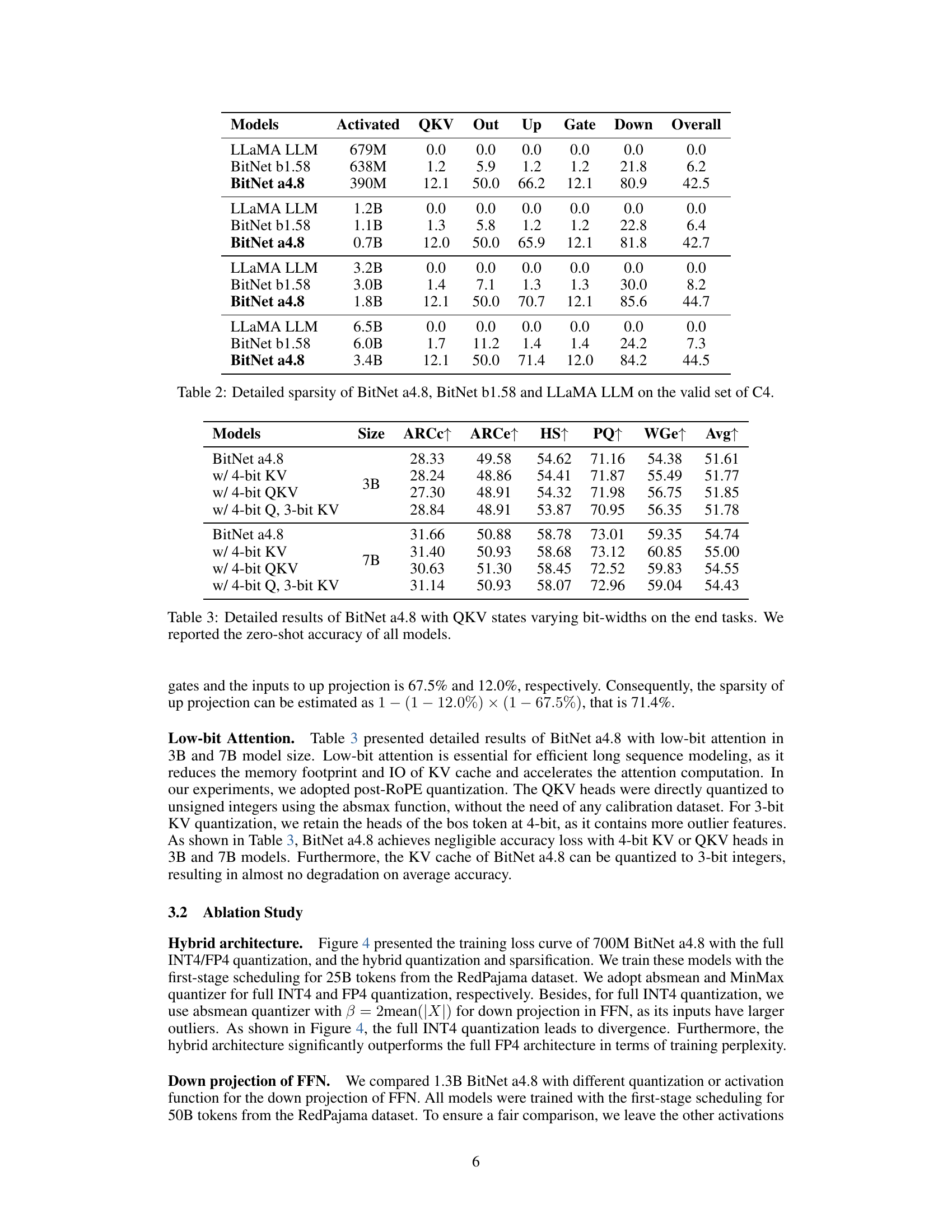
🔼 This table presents a detailed breakdown of the sparsity (percentage of inactive parameters) observed in different components of three large language models (LLMs): BitNet a4.8, BitNet b1.58, and LLaMA LLM. Sparsity is calculated for various model sizes (700M, 1.3B, 3B, and 7B parameters). The components analyzed include the Query, Key, Value (QKV) projections in the self-attention mechanism, the output projection of the attention, the feed-forward network’s (FFN’s) up and gate projections, the FFN’s down projection, and an overall sparsity measure that aggregates all components. The data reflects the sparsity levels observed on the validation set of the C4 dataset.
read the caption
Table 2: Detailed sparsity of BitNet a4.8, BitNet b1.58 and LLaMA LLM on the valid set of C4.
| Models | Size | ARCc↑ | ARCe↑ | HS↑ | PQ↑ | WGe↑ | Avg↑ |
|---|---|---|---|---|---|---|---|
| BitNet a4.8 | 3B | 28.33 | 49.58 | 54.62 | 71.16 | 54.38 | 51.61 |
| w/ 4-bit KV | 28.24 | 48.86 | 54.41 | 71.87 | 55.49 | 51.77 | |
| w/ 4-bit QKV | 27.30 | 48.91 | 54.32 | 71.98 | 56.75 | 51.85 | |
| w/ 4-bit Q, 3-bit KV | 28.84 | 48.91 | 53.87 | 70.95 | 56.35 | 51.78 | |
| BitNet a4.8 | 7B | 31.66 | 50.88 | 58.78 | 73.01 | 59.35 | 54.74 |
| w/ 4-bit KV | 31.40 | 50.93 | 58.68 | 73.12 | 60.85 | 55.00 | |
| w/ 4-bit QKV | 30.63 | 51.30 | 58.45 | 72.52 | 59.83 | 54.55 | |
| w/ 4-bit Q, 3-bit KV | 31.14 | 50.93 | 58.07 | 72.96 | 59.04 | 54.43 |
🔼 This table presents a detailed comparison of BitNet a4.8’s performance on various downstream tasks using different bit-widths for the Query, Key, and Value (QKV) states within the attention mechanism. It shows zero-shot accuracy results for the model, varying the precision of the QKV states (4-bit or 3-bit) to analyze the effect on overall model performance. This helps to understand the trade-off between model accuracy and efficiency by reducing the precision of the QKV states.
read the caption
Table 3: Detailed results of BitNet a4.8 with QKV states varying bit-widths on the end tasks. We reported the zero-shot accuracy of all models.
| Quantization | Sparsification | PPL↓ | ARCc↑ | ARCe↑ | HS↑ | PQ↑ | WGe↑ | Avg↑ |
|---|---|---|---|---|---|---|---|---|
| INT8 | - | 9.95 | 28.33 | 48.53 | 54.90 | 72.31 | 56.51 | 52.11 |
| INT8 | TopK 50% | 9.97 | 28.33 | 49.58 | 54.62 | 71.16 | 54.38 | 51.61 |
🔼 This table presents ablation study results focusing on the impact of TopK sparsification applied to the input features before the output projection within the attention mechanism. It compares the performance (PPL, ARCc, ARCe, HS, PQ, WGe, Avg) of models with and without TopK sparsification, providing insights into the effectiveness of this sparsification technique in improving efficiency without sacrificing accuracy.
read the caption
Table 4: Ablations on the TopK sparsification for the inputs to the output projection of attention.
| Models | HS | PQ | WGe | OBQA | Lambada | MMLU | ARCc | ARCe | Avg |
|---|---|---|---|---|---|---|---|---|---|
| BitNet b1.58 2B | 68.66 | 77.09 | 62.58 | 41.40 | 63.36 | 50.29 | 47.61 | 70.74 | 60.22 |
| BitNet a4.8 2B | 68.21 | 76.55 | 64.40 | 40.60 | 63.75 | 50.30 | 46.59 | 70.00 | 60.05 |
🔼 This table presents a comparison of the performance of BitNet a4.8 and BitNet b1.58, both with 2 billion parameters, trained using 2 trillion tokens. It showcases their performance across multiple downstream tasks, including HellaSwag (HS), PIQA (PQ), Winogrande (WGe), OBQA, Lambada, MMLU, ARC-Challenge (ARCC), and ARC-Easy (ARCe), offering a comprehensive evaluation of their capabilities with a large training dataset.
read the caption
Table 5: Results of BitNet a4.8 and BitNet b1.58 with 2B parameters and 2T training tokens.
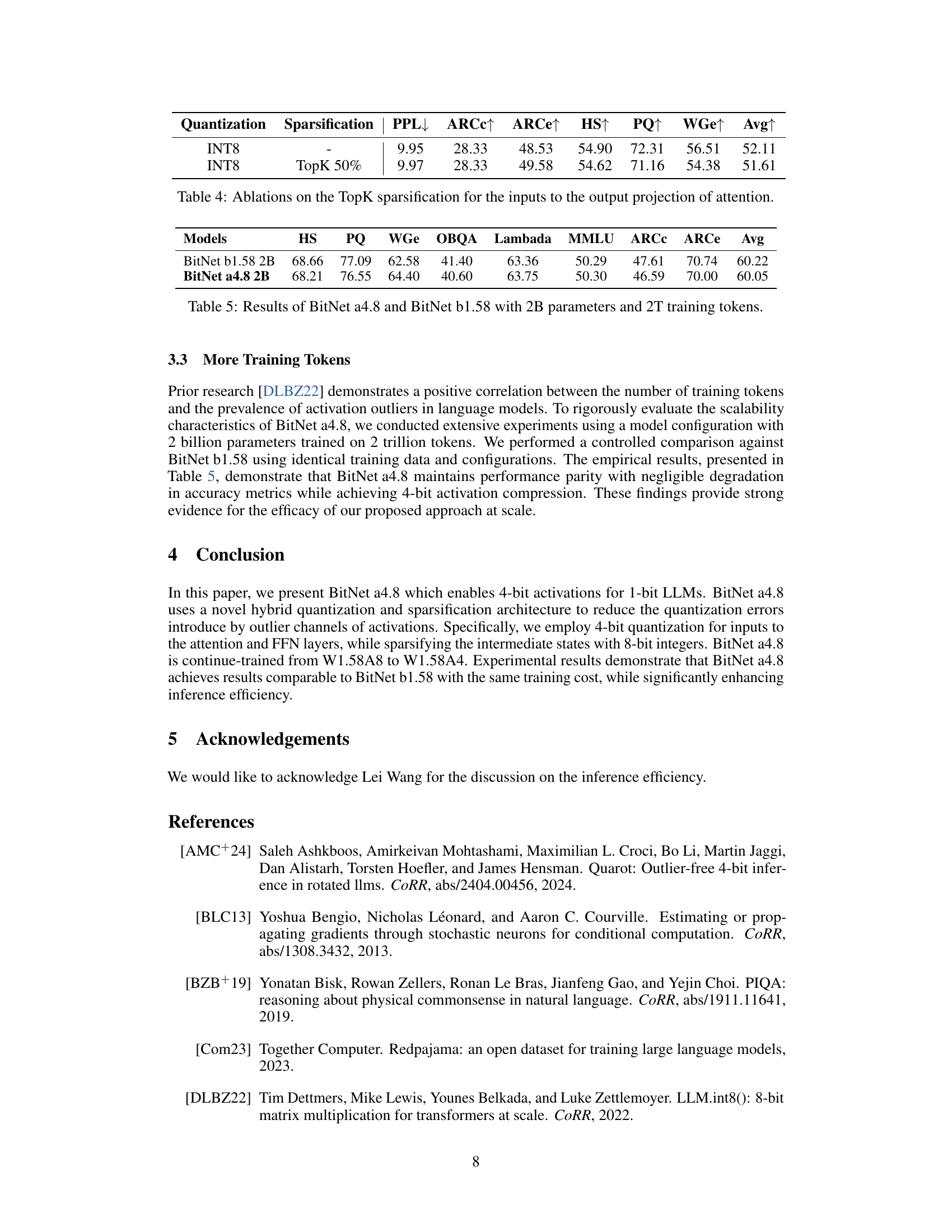
| Size | Hidden Size | GLU Size | #Heads | #Layers | Batch Size | # Tokens | Seq Length |
|---|---|---|---|---|---|---|---|
| 700M | 1536 | 4096 | 24 | 24 | 1M | 100B | 2048 |
| 1.3B | 2048 | 5460 | 32 | 24 | 1M | 100B | 2048 |
| 3B | 3200 | 8640 | 32 | 26 | 1M | 100B | 2048 |
| 7B | 4096 | 11008 | 32 | 32 | 1M | 100B | 2048 |
🔼 This table details the architectural hyperparameters for three large language models: BitNet a4.8, BitNet b1.58, and LLaMA. For each model, it lists the model size, hidden layer size, GLU (Gated Linear Unit) size, number of attention heads, number of layers, batch size used during training, the number of training tokens, and the sequence length.
read the caption
Table 6: Model configurations for both BitNet a4.8, BitNet b1.58 and LLaMA LLM.
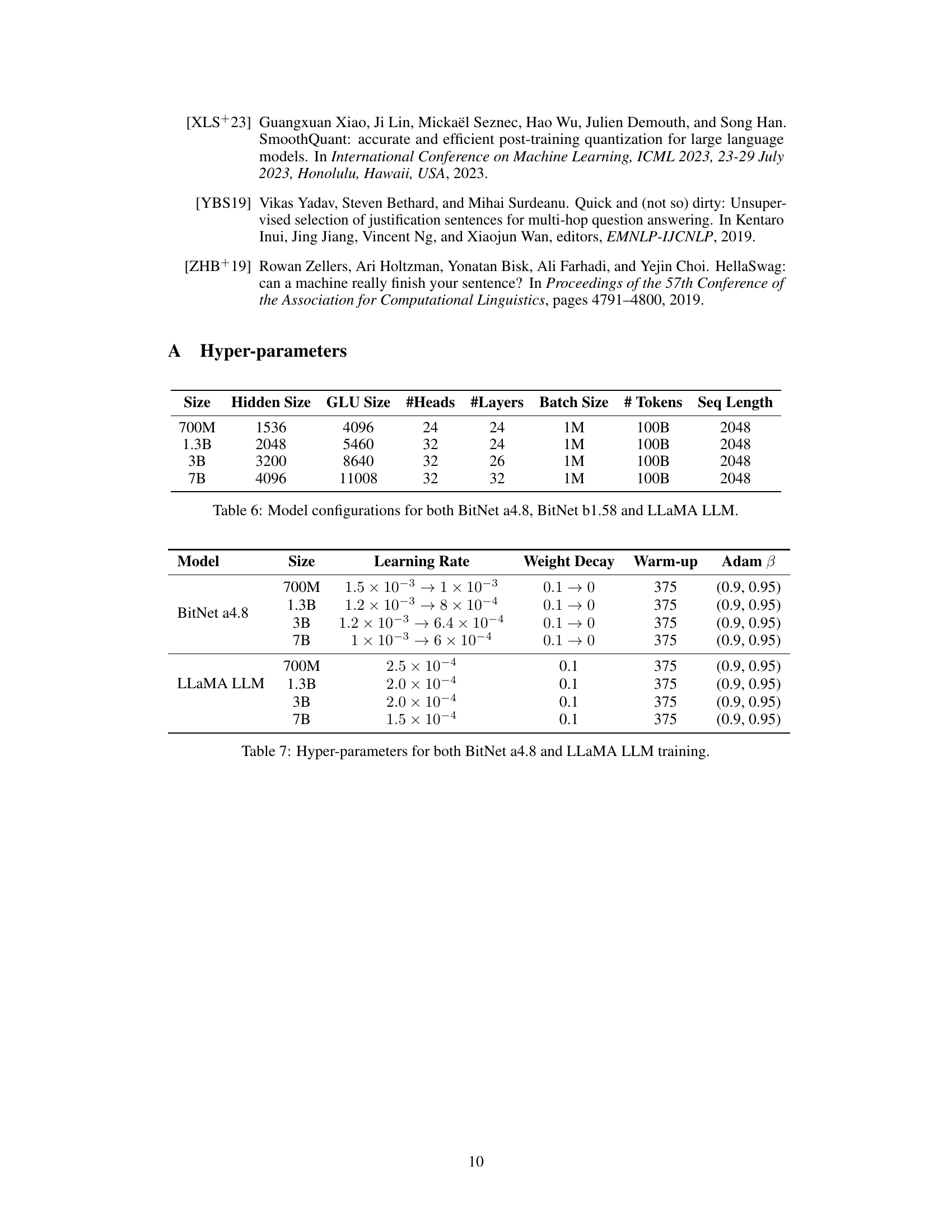
| Model | Size | Learning Rate | Weight Decay | Warm-up | Adam β |
|---|---|---|---|---|---|
| BitNet a4.8 | 700M | 1.5e-3→1e-3 | 0.1→0 | 375 | (0.9, 0.95) |
| 1.3B | 1.2e-3→8e-4 | 0.1→0 | 375 | (0.9, 0.95) | |
| 3B | 1.2e-3→6.4e-4 | 0.1→0 | 375 | (0.9, 0.95) | |
| 7B | 1e-3→6e-4 | 0.1→0 | 375 | (0.9, 0.95) | |
| LLaMA LLM | 700M | 2.5e-4 | 0.1 | 375 | (0.9, 0.95) |
| 1.3B | 2.0e-4 | 0.1 | 375 | (0.9, 0.95) | |
| 3B | 2.0e-4 | 0.1 | 375 | (0.9, 0.95) | |
| 7B | 1.5e-4 | 0.1 | 375 | (0.9, 0.95) |
🔼 This table details the hyperparameters used during the training process for both BitNet a4.8 and the LLaMA Large Language Model (LLM). It includes the model size, learning rate (with its decay schedule), weight decay, warmup steps, and Adam optimization parameters (beta1 and beta2). These hyperparameters are crucial for configuring the training process to optimize performance and stability for the respective models.
read the caption
Table 7: Hyper-parameters for both BitNet a4.8 and LLaMA LLM training.
Full paper#