↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image-to-video generation methods often lack fine-grained control over video elements like object motion or camera movement, usually requiring multiple re-runs or computationally expensive fine-tuning. This necessitates datasets with annotated object motion, which are often difficult to obtain. This paper introduces a novel framework that overcomes these limitations.
The proposed framework, SG-I2V, offers zero-shot trajectory control. It leverages the knowledge inherent in a pre-trained image-to-video diffusion model to control object and camera motion. By intelligently manipulating feature maps within the model and applying a post-processing step to enhance visual quality, SG-I2V achieves precise control without requiring fine-tuning or external data. The zero-shot approach significantly reduces computational cost and dataset requirements, while demonstrating competitive performance compared to supervised methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SG-I2V, a novel framework for controllable image-to-video generation that achieves zero-shot trajectory control. This addresses a critical limitation in current image-to-video models, which often require tedious trial-and-error or computationally expensive fine-tuning. The self-guided nature of SG-I2V opens new avenues for research in controllable video generation, particularly in areas like animation and special effects creation, where precise control over object and camera movement is crucial.
Visual Insights#

🔼 This figure illustrates the image-to-video generation process using self-guided trajectory control. Input consists of an image and a set of bounding boxes, each with an associated trajectory indicating the desired movement of the object within that box. The model, leveraging a pre-trained image-to-video diffusion model, generates a video where objects and potentially the camera move according to the specified trajectories. This method is unique in its self-guided nature, achieving zero-shot trajectory control without any need for additional fine-tuning or external data.
read the caption
Figure 1: Image-to-video generation based on self-guided trajectory control. Given a set of bounding boxes with associated trajectories, we achieve object and camera motion control in image-to-video generation by leveraging the knowledge present in a pre-trained image-to-video diffusion model. Our method is self-guided, offering zero-shot trajectory control without fine-tuning or relying on external knowledge.
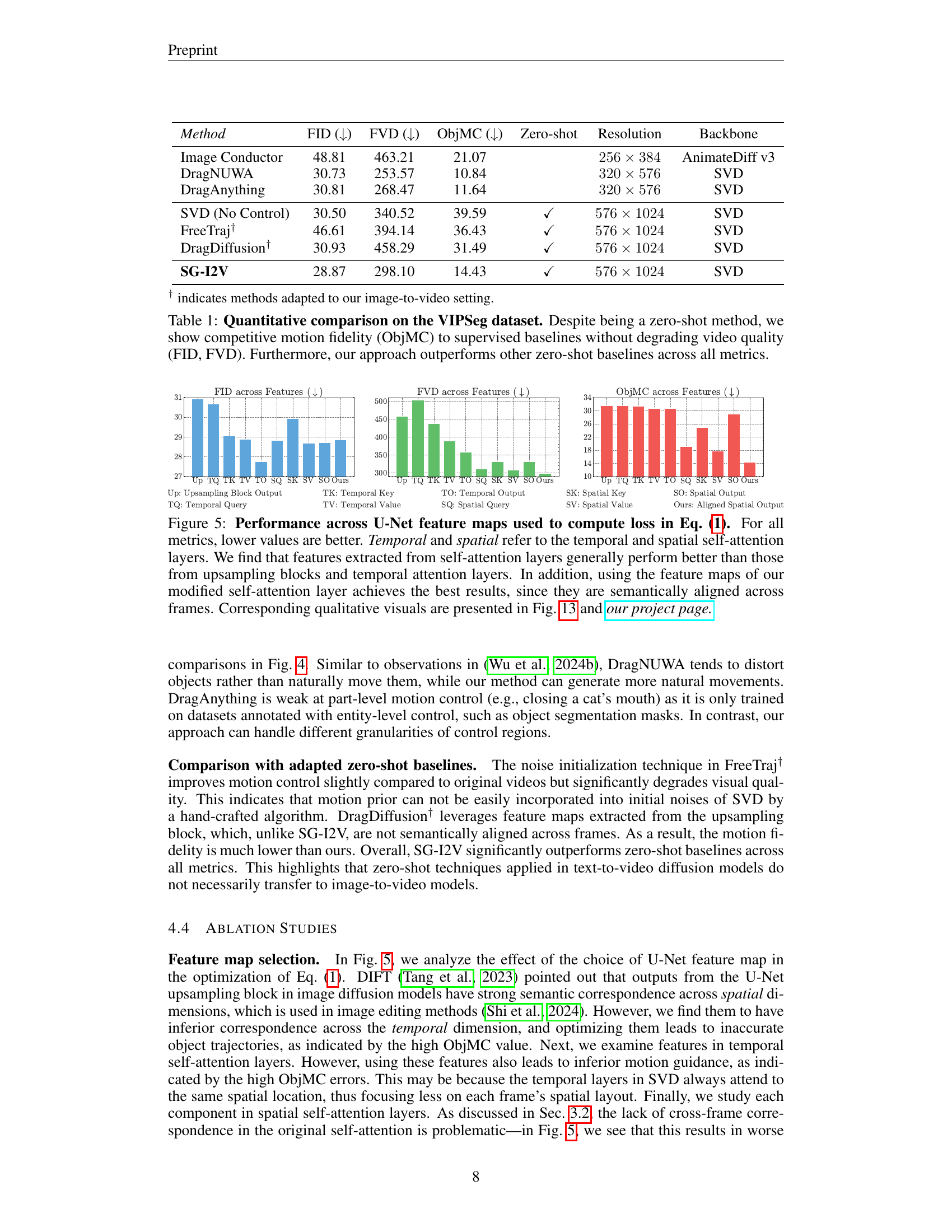
| Method | FID (↓) | FVD (↓) | ObjMC (↓) | Zero-shot | Resolution | Backbone |
|---|---|---|---|---|---|---|
| Image Conductor | 48.81 | 463.21 | 21.07 | 256×384 | AnimateDiff v3 | |
| DragNUWA | 30.73 | 253.57 | 10.84 | 320×576 | SVD | |
| DragAnything | 30.81 | 268.47 | 11.64 | 320×576 | SVD | |
| SVD (No Control) | 30.50 | 340.52 | 39.59 | ✓ | 576×1024 | SVD |
| FreeTraj† | 46.61 | 394.14 | 36.43 | ✓ | 576×1024 | SVD |
| DragDiffusion† | 30.93 | 458.29 | 31.49 | ✓ | 576×1024 | SVD |
| SG-I2V | 28.87 | 298.10 | 14.43 | ✓ | 576×1024 | SVD |
🔼 This table presents a quantitative comparison of different video generation methods on the VIPSeg dataset. The metrics used are FID (Frechet Inception Distance), FVD (Frechet Video Distance), and ObjMC (Object Motion Control). Lower scores are better for all three metrics. The results show that the proposed zero-shot method (SG-I2V) achieves competitive motion fidelity to the supervised methods, which required extensive fine-tuning, while maintaining comparable or better visual quality (FID and FVD). In addition, the zero-shot method significantly outperforms other zero-shot baselines.
read the caption
Table 1: Quantitative comparison on the VIPSeg dataset. Despite being a zero-shot method, we show competitive motion fidelity (ObjMC) to supervised baselines without degrading video quality (FID, FVD). Furthermore, our approach outperforms other zero-shot baselines across all metrics.
In-depth insights#
Self-Guided Control#
The concept of “Self-Guided Control” in the context of image-to-video generation is a significant advancement, moving away from the need for extensive external data or fine-tuning. It suggests a system that can learn to control video generation parameters (like object motion or camera movement) using only the inherent knowledge within a pre-trained model. This eliminates the need for large, labeled datasets, which are often expensive and time-consuming to obtain. The “self-guidance” aspect implies that the model itself determines how to adjust its internal representations to achieve the desired control, rather than relying on explicit instructions from external sources. This approach is particularly valuable for zero-shot scenarios where the model needs to adapt to unseen trajectories without prior training. A crucial aspect to explore is how this self-guidance is implemented. It could involve internal attention mechanisms, learned control signals within the latent space, or perhaps a novel method of incorporating trajectory information directly into the generation process. Understanding the underlying mechanisms of self-guided control is key to assessing its robustness and scalability.
Zero-Shot Animation#
Zero-shot animation represents a significant advancement in AI-driven video generation, offering the capability to animate images or videos without the need for explicit training data for each specific animation task. This is achieved by leveraging the knowledge implicitly encoded within a pre-trained model. The implications are profound: reduced computational costs, faster processing times, and expanded accessibility to animation techniques. However, challenges remain. Zero-shot methods often rely on pre-trained models, which may constrain the range of possible animations and could compromise quality compared to tailored approaches. Ensuring control and accuracy in the resulting animations remains a key area of research, especially concerning intricate movements or complex interactions within a scene. The quality of zero-shot animations is highly dependent on the pre-trained model and its ability to generalize across different scenarios. Therefore, future research should focus on improving both the fidelity and controllability of zero-shot animation techniques to truly unlock their creative potential.
Feature Map Analysis#
The heading ‘Feature Map Analysis’ suggests a critical investigation into the intermediate representations within a neural network, specifically focusing on the spatial and semantic information encoded in feature maps. A thoughtful analysis would likely involve visualizing these maps to understand their content, perhaps using dimensionality reduction techniques like PCA or t-SNE to reduce the dimensionality and visualize patterns. The analysis would likely examine if the feature maps exhibit semantic alignment, meaning that pixels corresponding to the same object or region maintain consistency across different frames or time steps in video data. This alignment is crucial for downstream tasks like trajectory control, as it enables tracking of objects based on their features, rather than on explicit bounding boxes alone. The absence of semantic alignment suggests potential limitations in existing models, prompting investigations into modifications to enhance the correspondence across frames. The research might compare feature maps from different layers of the network (e.g., early vs. late layers) to determine the best layer(s) for motion analysis and control. This might reveal a layer with more robust or better aligned features. Finally, the analysis likely investigates the relationship between feature map characteristics and the overall quality of video generation, examining aspects such as sharpness, detail preservation, and motion smoothness in relation to feature map properties. In conclusion, a thorough analysis would provide deep insights for model improvement and reveal critical information about the internal mechanisms of diffusion models for image-to-video generation.
Diffusion Model Control#
Diffusion models, known for generating high-quality images and videos, present a challenge in controlling the generation process. Controllability is crucial for practical applications, allowing users to guide the model towards specific desired outputs. Current approaches vary widely, from fine-tuning pre-trained models on specific datasets to modifying the model’s internal mechanisms, such as attention maps or latent representations. Fine-tuning methods often require extensive computational resources and large, labeled datasets, limiting their accessibility. Conversely, methods that manipulate internal states can be complex, requiring deep understanding of the model’s architecture. A key area of research focuses on achieving effective control without extensive retraining or complex modifications, seeking zero-shot or few-shot control methods. This involves leveraging pre-trained models’ inherent knowledge to guide generation based on user input. Self-guided approaches, that use knowledge present within the pre-trained models themselves, represent a promising path, eliminating the need for external data or extensive retraining. Further research will likely focus on refining these methods, aiming for greater flexibility and precision in directing the model’s output.
Future of SG-I2V#
The future of SG-I2V hinges on several key areas. Improving the quality and realism of generated videos is paramount; this might involve integrating advanced diffusion models, exploring alternative loss functions, or refining the high-frequency preservation techniques. Extending the range of controllable elements beyond bounding boxes and trajectories would expand applications, potentially incorporating semantic masks, point clouds, or even natural language descriptions for directing the video generation process. Addressing limitations in handling complex scenes and intricate object interactions is crucial. Current methods struggle with complex interactions or very fine-grained control. Future research should investigate enhanced feature alignment techniques and more sophisticated control mechanisms. Benchmarking against state-of-the-art methods and on a wider variety of datasets is necessary for objectively measuring progress and identifying areas for improvement. Finally, ethical considerations surrounding the potential for misuse of realistic video generation technology should guide future development, ensuring responsible application of this powerful technology.
More visual insights#
More on figures

🔼 This figure visualizes the semantic alignment of feature maps in the Stable Video Diffusion (SVD) model across different layers and frames. Three example video sequences are shown (Row 1). PCA is used to visualize features extracted at timestep 30 of 50 from the upsampling block (Row 2), the self-attention layer (Row 3), and the modified self-attention layer (Row 4) using the authors’ alignment method. The visualization shows that while upsampling blocks in image diffusion models typically exhibit strong semantic alignment, this is weak in SVD across frames. Therefore, the authors focus on modifying the self-attention layers to improve cross-frame semantic alignment.
read the caption
Figure 2: Semantic correspondences in video diffusion models. We analyze feature maps in the image-to-video diffusion model SVD (Blattmann et al., 2023a) for three generated video sequences (row 1). We use PCA to visualize the features at diffusion timestep 30 (out of 50) at the output of an upsampling block (row 2), a self-attention layer (row 3), and the same self-attention layer after our alignment procedure (row 4). Although output feature maps of upsampling blocks in image diffusion models are known to encode semantic information (Tang et al., 2023), we only observe weak semantic correspondences across frames in SVD. Thus, we focus on the self-attention layer and modify it to produce feature maps that are semantically aligned across frames.

🔼 This figure illustrates the SG-I2V framework for controllable image-to-video generation. It details the process of manipulating a pre-trained video diffusion model to control object motion within a video generated from a single input image. The process begins by extracting semantically aligned feature maps from the model’s U-Net to understand the video’s layout. These feature maps are then used to guide the optimization of the latent representation (z_t) at key denoising steps, ensuring consistency in object movement along predefined trajectories. Finally, a post-processing step refines the resulting video’s visual quality by selectively preserving high-frequency components of the original latent representation, leading to a more natural-looking and artifact-free video. The updated latent representation (~z_t) is then used in the next denoising step of the video generation process.
read the caption
Figure 3: Overview of the controllable image-to-video generation framework. To control trajectories of scene elements, we optimize the latent 𝒛tsubscript𝒛𝑡\bm{z}_{t}bold_italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT at specific denoising timesteps t𝑡titalic_t of a pre-trained video diffusion model. First, we extract semantically aligned feature maps from the denoising U-Net to estimate the video layout. Next, we enforce cross-frame feature similarity along the bounding box trajectory to drive the motion of each region. To preserve the visual quality of the generated video, a frequency-based post-processing method is applied to retain high-frequency noise of the original latent 𝒛tsubscript𝒛𝑡\bm{z}_{t}bold_italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. The updated latent 𝒛~tsubscript~𝒛𝑡\tilde{\bm{z}}_{t}over~ start_ARG bold_italic_z end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is input to the next denoising step.

🔼 Figure 4 presents a qualitative comparison of video generation results between the proposed SG-I2V model and existing supervised baselines (DragNUWA and DragAnything). The comparison highlights the differences in how each method handles object motion. DragNUWA is shown to distort objects instead of smoothly moving them, while DragAnything struggles with fine-grained, part-level control because it is primarily designed for controlling entire objects. In contrast, SG-I2V is demonstrated to produce videos with natural object and camera movements across a variety of scenarios.
read the caption
Figure 4: Qualitative comparison with supervised baselines. We observe that DragNUWA tends to distort objects rather than move them, and DragAnything is weak at part-level control as it is designed for entity-level control. In contrast, our method can generate videos with natural motion for diverse object and camera trajectories. Please see our project page for more comparisons.

🔼 Figure 5 investigates the performance of using different feature maps from the U-Net architecture of the Stable Video Diffusion model for computing the loss function in Equation 1. The goal is to find which feature maps are most effective for controlling object trajectories in image-to-video generation. The figure shows three metrics (lower values are better): FID (visual quality), FVD (motion consistency), and ObjMC (motion accuracy). Results reveal that self-attention layers generally outperform upsampling blocks and temporal attention layers. The modified self-attention layer, which ensures semantic alignment across frames, yields the best results across all three metrics. Qualitative examples corresponding to this analysis are provided in Figure 13 and the project’s webpage.
read the caption
Figure 5: Performance across U-Net feature maps used to compute loss in Eq. 1. For all metrics, lower values are better. Temporal and spatial refer to the temporal and spatial self-attention layers. We find that features extracted from self-attention layers generally perform better than those from upsampling blocks and temporal attention layers. In addition, using the feature maps of our modified self-attention layer achieves the best results, since they are semantically aligned across frames. Corresponding qualitative visuals are presented in Fig. 13 and our project page.

🔼 This figure analyzes the performance of using feature maps from different layers of the U-Net in a video diffusion model for trajectory control in image-to-video generation. The U-Net’s upsampling path has three resolution levels (bottom, mid, top), each with three self-attention layers (1, 2, 3). The experiment tests using features from various combinations of these layers (e.g., ‘M2-3’ means using layers 2 and 3 from the mid-resolution level). The results show that mid-resolution feature maps are best for trajectory guidance, with the best performance achieved by combining layers 2 and 3 of the mid-resolution level. The figure uses FID, FVD, and ObjMC to measure performance; lower scores are better. For detailed visualizations, refer to the project webpage.
read the caption
Figure 6: Performance across U-Net layers used to extract feature maps. Lower is better for all metrics. Bottom, mid, and top indicate the three resolution levels in the U-Net’s upsampling path, each containing three self-attention layers numbered 1, 2, and 3. for example “M2-3” means applying the loss to features from both mid-resolution layers 2 and 3. We observe that mid-resolution feature maps perform best for trajectory guidance. In addition, using features from both M2 and M3 leads to the best result. See our project page for visualizations.

🔼 This figure demonstrates the effectiveness of the high-frequency preservation post-processing step used in the SG-I2V framework. The left column shows video frames generated without the post-processing step, exhibiting noticeable oversmoothing and artifacts. In contrast, the right column shows video frames generated with the post-processing step. These frames retain sharp details and significantly reduce artifacts, demonstrating a clear improvement in visual quality.
read the caption
Figure 7: Effect of high-frequency preservation in post-processing. Videos without post-processing tend to demonstrate oversmoothing and have artifacts. In contrast, our post-processing technique retains videos with sharp details and eliminates most of the artifacts. See our project page for more examples.

🔼 Figure 8 shows the impact of the cut-off frequency (γ) used in a post-processing step designed to enhance the quality of generated videos. The graph displays FID, FVD, and ObjMC values as a function of γ. A γ value of 1 represents no filtering (fully keeping the optimized latent), which leads to high FID and FVD (indicating poor visual quality). As γ decreases, less of the high-frequency components are preserved; while this improves visual quality, it also negatively affects motion control (increased ObjMC). The optimal γ balances these competing factors for best overall video quality.
read the caption
Figure 8: Study of the cut-off frequency in post-processing. Lower is better for all metrics. The value γ𝛾\gammaitalic_γ indicates the cut-off frequency. Fully keeping the optimized latent (γ=1𝛾1\gamma=1italic_γ = 1) results in degraded video quality, as shown by high FID and FVD values. On the other hand, replacing too many frequency components diminishes motion control, as indicated by the increasing ObjMC.

🔼 This ablation study investigates the impact of different learning rates on the optimization process for controllable image-to-video generation. The results show a trade-off between visual quality (measured by FID and FVD) and motion fidelity (measured by ObjMC). Higher learning rates improve motion fidelity at the cost of visual quality, indicated by increased FID and FVD scores. Conversely, lower learning rates prioritize visual quality, leading to better FID and FVD scores but reduced motion fidelity (higher ObjMC). The optimal learning rate is selected to balance these competing factors for the best overall performance.
read the caption
Figure 9: Ablation on optimization learning rates. Larger learning rates lead to video quality degradation (i.e., higher FID and FVD), while smaller learning rates result in lower motion fidelity (i.e., higher ObjMC). We choose the learning rate considering this tradeoff.

🔼 This figure analyzes the impact of optimizing the latent representation at different denoising timesteps during video generation. It evaluates the trade-off between visual quality and motion fidelity by optimizing the latent at various steps in the denoising process, using a single timestep at a time. The results show that optimizing at intermediate timesteps (around t=30) yields the best balance, producing high-fidelity motion without compromising visual quality. The figure presents quantitative results (FID, FVD, ObjMC) for different timesteps. Additional results involving optimization over multiple timesteps are provided in Figure 16. Qualitative comparisons are available in Figure 15 and on the project website.
read the caption
Figure 10: Effect of optimizing latent at individual denoising timesteps. For all metrics, lower values are better. Here, we optimize Eq. 1 on a single denoising timestep (t=50𝑡50t=50italic_t = 50 corresponds to standard Gaussian noise), and we find middle timesteps (e.g. t=30𝑡30t=30italic_t = 30) achieve the best motion fidelity while maintaining visual quality. More results on optimizing the latent at multiple timesteps can be found in Fig. 16. See Fig. 15 and our project page for qualitative comparisons.

🔼 This figure visualizes feature maps from different layers of a video diffusion model at various diffusion timesteps. The top rows show the outputs from upsampling blocks, which lack consistent semantic relationships across frames (meaning the features representing the same object don’t consistently align across different frames in the video sequence). The bottom rows depict the output from the authors’ modified self-attention layers. These layers show strong semantic correspondence, meaning features related to a given object remain consistently aligned throughout the video sequence.
read the caption
Figure 11: Semantic correspondences in video diffusion models across timesteps. Output feature maps of upsampling blocks have limited semantic correspondences across frames. In contrast, our modified self-attention layers produce semantically aligned feature maps across all the timesteps.

🔼 This figure visualizes the semantic alignment of features extracted from different layers of a video diffusion model. The analysis compares features from upsampling blocks, standard self-attention layers, and temporal attention layers. PCA is used to visualize these features across different frames of a generated video. The results show that features from self-attention layers exhibit stronger semantic alignment than those from upsampling blocks and temporal attention layers. Notably, a modified self-attention layer, where the key and value tokens are replaced with those from the first frame, demonstrates significantly improved semantic alignment across frames. This improved alignment is attributed to the explicit modification of the self-attention mechanism to attend to the first frame.
read the caption
Figure 12: Semantic correspondences of different features in video diffusion models. We find features from self-attention layers to be more semantically aligned than that of temporal attention layers and upsampling layers, while our modified self-attention layer produces the most aligned results due to its explicit formulation to attend to the first frame.

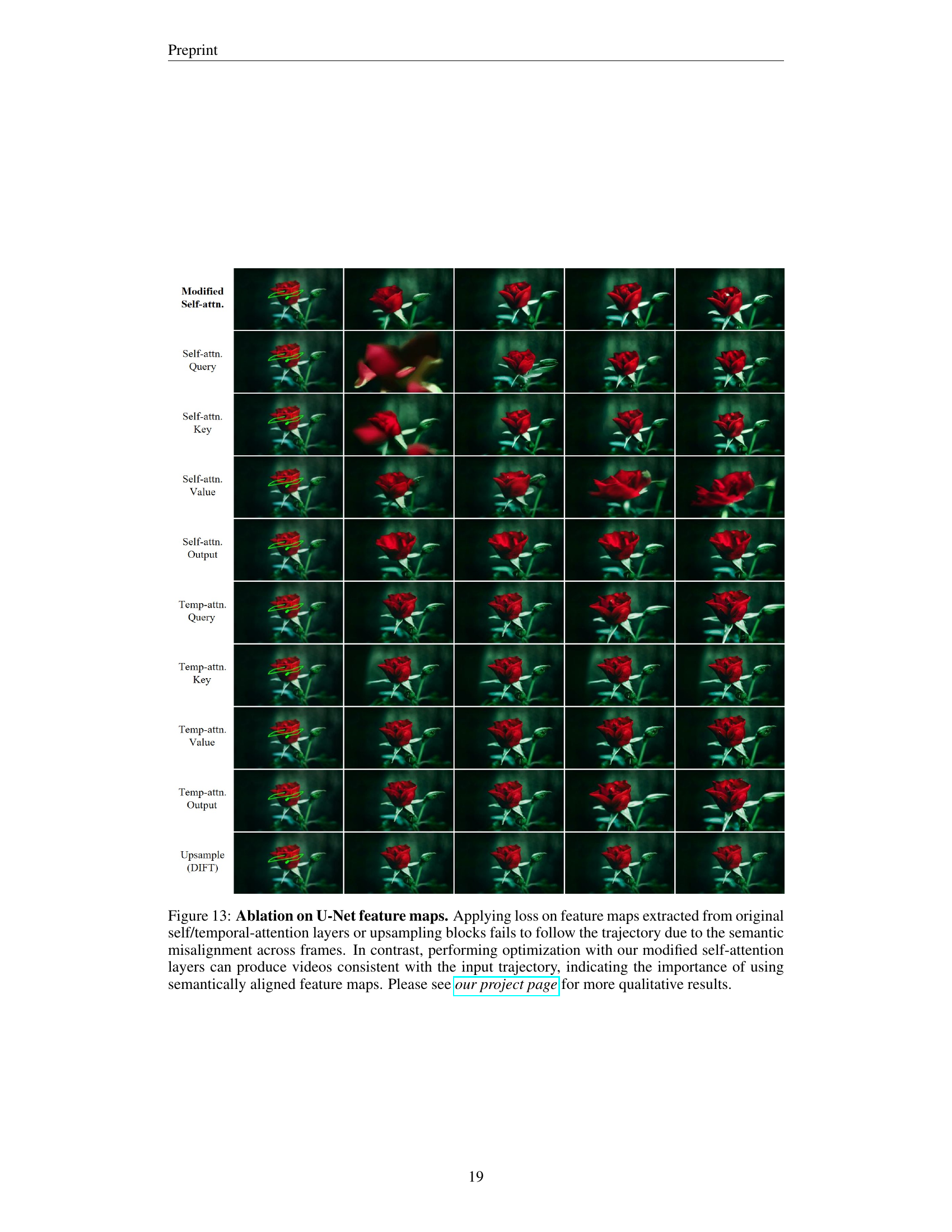
🔼 This ablation study compares the effectiveness of using different feature maps from the U-Net in a video diffusion model for trajectory control in image-to-video generation. Using features from the original self-attention, temporal-attention layers, or upsampling blocks resulted in poor trajectory following due to a lack of semantic alignment across video frames. Only when using the modified self-attention features (as described in the paper) did the model generate videos that accurately followed the specified object trajectories. This highlights the importance of using semantically aligned features for successful trajectory control. For a visual comparison of the results, refer to the project website.
read the caption
Figure 13: Ablation on U-Net feature maps. Applying loss on feature maps extracted from original self/temporal-attention layers or upsampling blocks fails to follow the trajectory due to the semantic misalignment across frames. In contrast, performing optimization with our modified self-attention layers can produce videos consistent with the input trajectory, indicating the importance of using semantically aligned feature maps. Please see our project page for more qualitative results.

🔼 This ablation study investigates the impact of using feature maps from different U-Net layers in the optimization process for trajectory control in video generation. The results show that feature maps from the middle resolution level of the U-Net’s upsampling path are most effective for guiding the generation of realistic videos with accurate object motion. Using feature maps from other layers (bottom or top resolution levels) leads to videos that are less realistic and exhibit noticeably poor motion fidelity.
read the caption
Figure 14: Ablation on U-Net layer to extract feature maps. Consistent with the quantitative results in Fig. 6, feature maps extracted from the middle resolution level are most useful for trajectory guidance. Optimizing on other feature maps may generate unrealistic videos with low motion fidelity.

🔼 This figure shows a visual comparison of videos generated by optimizing latent representations at different denoising timesteps during the image-to-video generation process. Each column represents a different starting timestep for optimization (50, 40, 30, 20, 10), with 50 being the noisiest. The last frame of each generated video is displayed. The results demonstrate that optimizing the latent at later timesteps (i.e., those closer to the original image) leads to a degradation in the quality of the generated video and the introduction of severe artifacts. Conversely, optimizing earlier in the process results in visually cleaner frames.
read the caption
Figure 15: Visual comparison of different denoising timesteps. Here we show the last frame of the generated video. Optimizing latent at later denoising process leads to severe artifacts.
Full paper#