↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the performance of CLIP, a foundational model in the multimodal domain, by integrating the capabilities of large language models (LLMs). This unlocks richer visual representation learning and opens new avenues for research in cross-modal tasks, particularly in handling longer and more complex text descriptions. The efficient training method ensures that the improvements come at minimal computational cost, making it highly relevant to the broader AI community.
Visual Insights#

🔼 LLM2CLIP uses a large language model (LLM) to improve CLIP’s ability to learn from image captions. First, the LLM undergoes contrastive fine-tuning to enhance its ability to distinguish between similar captions. This improved discriminability is crucial for effective CLIP training. Then, the fine-tuned LLM, with its open-world knowledge, processes dense image captions. This addresses the limited context window and understanding of the original CLIP text encoder. Finally, the improved textual supervision guides CLIP’s visual encoder, resulting in a richer, higher-dimensional multimodal representation. Experimental results show that LLM2CLIP significantly boosts the performance of state-of-the-art (SOTA) CLIP models.
read the caption
Figure 1: LLM2CLIP Overview. After applying caption contrastive fine-tuning to the LLM, the increased textual discriminability enables more effective CLIP training. We leverage the open-world knowledge and general capabilities of the LLM to better process dense captions, addressing the previous limitations of the pretrained CLIP visual encoder and providing richer, higher-dimensional textual supervision. Experimental results demonstrate that LLM2CLIP can make any SOTA CLIP model even more SOTA ever.
| Language Model | CRA |
|---|---|
| CLIP-L/14 | 66.6 |
| EVA02-L/14 | 69.8 |
| Llama3-8B | 18.4 |
| Llama3.2-1B | 18.3 |
| Llama3-8B-CC | 73.0 |
| Llama3.2-1B-CC | 72.8 |
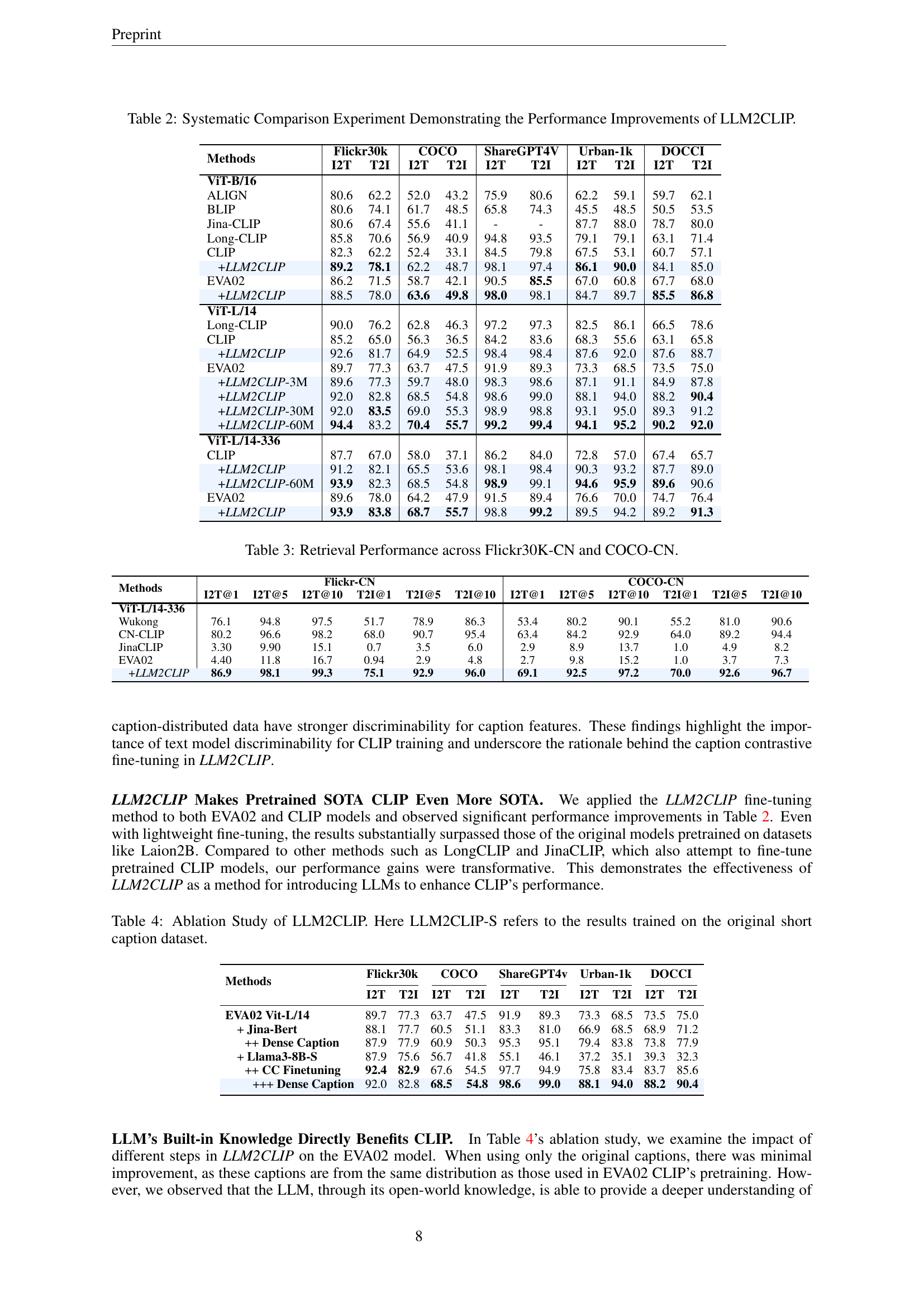
🔼 This table presents a comprehensive comparison of various methods for image-text retrieval and demonstrates the performance improvements achieved by LLM2CLIP. It compares the results of different CLIP models (ViT-B/16, ViT-L/14, ViT-L/14-336) with and without the LLM2CLIP enhancement on multiple benchmark datasets (Flickr30k, COCO, ShareGPT4V, Urban-1k, and DOCCI). Both image-to-text (I2T) and text-to-image (T2I) retrieval accuracy are shown, illustrating how LLM2CLIP consistently outperforms other methods. This showcases LLM2CLIP’s broad applicability across different model architectures and datasets.
read the caption
Table 2: Systematic Comparison Experiment Demonstrating the Performance Improvements of LLM2CLIP.
In-depth insights#
LLM-CLIP Synergy#
LLM-CLIP synergy explores the powerful combination of Large Language Models (LLMs) and CLIP (Contrastive Language-Image Pre-training). CLIP’s strength lies in aligning visual and textual data, enabling zero-shot capabilities. However, CLIP’s text encoder has limitations in handling long and complex text. LLMs excel at understanding nuanced language, offering a path to enhance CLIP. By integrating an LLM, the enriched textual understanding can improve CLIP’s visual representation learning and expand its application to more intricate tasks. A key challenge is the inherent autoregressive nature of LLMs, which can hinder direct integration with CLIP. Therefore, effective synergy requires careful methods for bridging the gap, such as contrastive fine-tuning, to enhance LLM output feature discriminability and align it effectively with CLIP’s visual features. Ultimately, the combined power of LLMs and CLIP unlocks richer visual representations and opens new possibilities for multimodal applications, improving performance on tasks involving complex textual descriptions and cross-lingual understanding.
Contrastive Fine-tuning#
Contrastive fine-tuning, in the context of multimodal learning, is a powerful technique to enhance the discriminative ability of language models, particularly when used with CLIP-like architectures. The core idea is to leverage contrastive learning to refine the LLM’s output embeddings, pushing representations of semantically similar captions closer together and dissimilar ones further apart. This process effectively addresses a critical limitation of directly using LLMs in CLIP: the poor discriminability of their output features. By fine-tuning the LLM on a caption contrastive learning task (using a loss function such as SimCSE), the model learns to generate more linearly separable features. This increased discriminability is crucial for effective feature alignment in the cross-modal contrastive learning framework of CLIP. The fine-tuned LLM then acts as a strong teacher model, guiding the visual encoder’s learning and enabling it to capture richer visual representations. The method not only improves performance on various downstream tasks but also enhances CLIP’s ability to handle longer and more complex captions, addressing a key limitation of the original architecture.
CLIP Enhancement#
CLIP Enhancement is a crucial area of research because of CLIP’s limitations in handling long and complex text descriptions. LLM2CLIP directly addresses this by integrating powerful LLMs, leveraging their superior text comprehension capabilities to unlock richer visual representations. This integration isn’t straightforward; naive attempts result in catastrophic performance drops. The solution presented in LLM2CLIP involves a critical fine-tuning step using contrastive learning, enhancing the discriminability of the LLM’s output features before integration. This process is essential to achieve effective multimodal learning. The method is particularly notable because it does not require significant changes to the CLIP architecture, making the enhancement computationally efficient while achieving a state-of-the-art performance boost. The synergistic effect of LLMs and CLIP is demonstrated through significant improvements across various benchmarks, including long-text and cross-lingual retrieval tasks, proving a significant CLIP enhancement.
Cross-lingual Transfer#
Cross-lingual transfer in multimodal models is a crucial area of research, especially considering the global nature of data. The ability of a model trained primarily on one language (e.g., English) to generalize to other languages without extensive retraining is highly desirable. LLM2CLIP’s success in zero-shot cross-lingual image retrieval showcases the potential of integrating powerful LLMs. The open-world knowledge and robust text understanding capabilities of LLMs seem to empower the visual encoder to better generalize across languages. This is a significant advantage over previous methods which often require language-specific fine-tuning or substantial data augmentation. The surprising success on Chinese datasets, despite the model’s training solely on English data, highlights the power of LLMs in bridging the semantic gap between languages. However, further research is needed to fully understand the mechanisms underlying this cross-lingual transfer, particularly regarding the interaction between the LLM and the vision encoder. Investigating the impact of different LLM architectures and sizes, as well as exploring techniques to optimize transfer performance, will be essential next steps. Addressing the limitations of relying on pretrained LLMs and investigating effective methods to fine-tune them specifically for cross-lingual tasks would be important. This would lead to potentially more efficient and robust cross-lingual transfer, paving the way for more universally accessible and impactful multimodal AI applications.
Future Research#
Future research directions stemming from the LLM2CLIP paper could explore several promising avenues. Improving the efficiency of LLM integration is crucial; while LLM2CLIP demonstrates effectiveness, exploring techniques beyond LoRA fine-tuning for better computational efficiency and scalability is warranted. Investigating different LLM architectures and their suitability for multimodal tasks is also key. The current work primarily focuses on autoregressive LLMs; exploring other architectures like bidirectional models might unlock further improvements. Addressing the data imbalance in current multimodal datasets is a critical need; future work should focus on creating more balanced datasets with diverse representations, especially focusing on handling long and complex image captions effectively. Finally, extending LLM2CLIP’s applicability to other modalities beyond vision and language, such as audio or sensor data, is a promising path for broader, more impactful multimodal research. This would involve adapting the contrastive learning framework to new data types and exploring the fusion of multiple modalities, potentially paving the way for advanced AI systems with rich, nuanced understandings of the world.
More visual insights#
More on tables
| Methods | Flickr30k | COCO | ShareGPT4V | Urban-1k | DOCCI | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| I2T | I2T | T2I | I2T | T2I | I2T | T2I | I2T | T2I | I2T | T2I |
| ViT-B/16 | ||||||||||
| ALIGN | 80.6 | 62.2 | 52.0 | 43.2 | 75.9 | 80.6 | 62.2 | 59.1 | 59.7 | 62.1 |
| BLIP | 80.6 | 74.1 | 61.7 | 48.5 | 65.8 | 74.3 | 45.5 | 48.5 | 50.5 | 53.5 |
| Jina-CLIP | 80.6 | 67.4 | 55.6 | 41.1 | - | - | 87.7 | 88.0 | 78.7 | 80.0 |
| Long-CLIP | 85.8 | 70.6 | 56.9 | 40.9 | 94.8 | 93.5 | 79.1 | 79.1 | 63.1 | 71.4 |
| CLIP | 82.3 | 62.2 | 52.4 | 33.1 | 84.5 | 79.8 | 67.5 | 53.1 | 60.7 | 57.1 |
| +LLM2CLIP | 89.2 | 78.1 | 62.2 | 48.7 | 98.1 | 97.4 | 86.1 | 90.0 | 84.1 | 85.0 |
| EVA02 | 86.2 | 71.5 | 58.7 | 42.1 | 90.5 | 85.5 | 67.0 | 60.8 | 67.7 | 68.0 |
| +LLM2CLIP | 88.5 | 78.0 | 63.6 | 49.8 | 98.0 | 98.1 | 84.7 | 89.7 | 85.5 | 86.8 |
| ViT-L/14 | ||||||||||
| Long-CLIP | 90.0 | 76.2 | 62.8 | 46.3 | 97.2 | 97.3 | 82.5 | 86.1 | 66.5 | 78.6 |
| CLIP | 85.2 | 65.0 | 56.3 | 36.5 | 84.2 | 83.6 | 68.3 | 55.6 | 63.1 | 65.8 |
| +LLM2CLIP | 92.6 | 81.7 | 64.9 | 52.5 | 98.4 | 98.4 | 87.6 | 92.0 | 87.6 | 88.7 |
| EVA02 | 89.7 | 77.3 | 63.7 | 47.5 | 91.9 | 89.3 | 73.3 | 68.5 | 73.5 | 75.0 |
| +LLM2CLIP-3M | 89.6 | 77.3 | 59.7 | 48.0 | 98.3 | 98.6 | 87.1 | 91.1 | 84.9 | 87.8 |
| +LLM2CLIP | 92.0 | 82.8 | 68.5 | 54.8 | 98.6 | 99.0 | 88.1 | 94.0 | 88.2 | 90.4 |
| +LLM2CLIP-30M | 92.0 | 83.5 | 69.0 | 55.3 | 98.9 | 98.8 | 93.1 | 95.0 | 89.3 | 91.2 |
| +LLM2CLIP-60M | 94.4 | 83.2 | 70.4 | 55.7 | 99.2 | 99.4 | 94.1 | 95.2 | 90.2 | 92.0 |
| ViT-L/14-336 | ||||||||||
| CLIP | 87.7 | 67.0 | 58.0 | 37.1 | 86.2 | 84.0 | 72.8 | 57.0 | 67.4 | 65.7 |
| +LLM2CLIP | 91.2 | 82.1 | 65.5 | 53.6 | 98.1 | 98.4 | 90.3 | 93.2 | 87.7 | 89.0 |
| +LLM2CLIP-60M | 93.9 | 82.3 | 68.5 | 54.8 | 98.9 | 99.1 | 94.6 | 95.9 | 89.6 | 90.6 |
| EVA02 | 89.6 | 78.0 | 64.2 | 47.9 | 91.5 | 89.4 | 76.6 | 70.0 | 74.7 | 76.4 |
| +LLM2CLIP | 93.9 | 83.8 | 68.7 | 55.7 | 98.8 | 99.2 | 89.5 | 94.2 | 89.2 | 91.3 |
🔼 This table presents a detailed comparison of image-to-text (I2T) and text-to-image (T2I) retrieval performance across two Chinese datasets: Flickr30K-CN and COCO-CN. The metrics reported include retrieval accuracy at top-1, top-5, and top-10 ranks. Different methods are compared, allowing for assessment of their relative effectiveness in cross-lingual retrieval tasks using Chinese captions. This is particularly relevant given the common limitation of English-centric training data in many multimodal models.
read the caption
Table 3: Retrieval Performance across Flickr30K-CN and COCO-CN.
| Methods | Flickr-CN I2T@1 | Flickr-CN I2T@5 | Flickr-CN I2T@10 | Flickr-CN T2I@1 | Flickr-CN T2I@5 | Flickr-CN T2I@10 | COCO-CN I2T@1 | COCO-CN I2T@5 | COCO-CN I2T@10 | COCO-CN T2I@1 | COCO-CN T2I@5 | COCO-CN T2I@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViT-L/14-336 | ||||||||||||
| Wukong | 76.1 | 94.8 | 97.5 | 51.7 | 78.9 | 86.3 | 53.4 | 80.2 | 90.1 | 55.2 | 81.0 | 90.6 |
| CN-CLIP | 80.2 | 96.6 | 98.2 | 68.0 | 90.7 | 95.4 | 63.4 | 84.2 | 92.9 | 64.0 | 89.2 | 94.4 |
| JinaCLIP | 3.30 | 9.90 | 15.1 | 0.7 | 3.5 | 6.0 | 2.9 | 8.9 | 13.7 | 1.0 | 4.9 | 8.2 |
| EVA02 | 4.40 | 11.8 | 16.7 | 0.94 | 2.9 | 4.8 | 2.7 | 9.8 | 15.2 | 1.0 | 3.7 | 7.3 |
| +LLM2CLIP | 86.9 | 98.1 | 99.3 | 75.1 | 92.9 | 96.0 | 69.1 | 92.5 | 97.2 | 70.0 | 92.6 | 96.7 |
🔼 This ablation study analyzes the impact of different components and training data variations within the LLM2CLIP framework on the performance of the EVA02 ViT-L/14 model. Specifically, it investigates the effects of using Jina-Bert instead of the original text encoder, incorporating dense captions, fine-tuning the Llama-3 model using contrastive learning (CC), and the influence of training solely on the original short caption dataset (LLM2CLIP-S). The results are evaluated across various benchmark datasets (Flickr30k, COCO, ShareGPT4V, Urban-1k, and DOCCI), comparing I2T (Image-to-Text) and T2I (Text-to-Image) retrieval performance.
read the caption
Table 4: Ablation Study of LLM2CLIP. Here LLM2CLIP-S refers to the results trained on the original short caption dataset.
| Methods | Flickr30k I2T | Flickr30k T2I | COCO I2T | COCO T2I | ShareGPT4v I2T | ShareGPT4v T2I | Urban-1k I2T | Urban-1k T2I | DOCCI I2T | DOCCI T2I |
|---|---|---|---|---|---|---|---|---|---|---|
| EVA02 Vit-L/14 | 89.7 | 77.3 | 63.7 | 47.5 | 91.9 | 89.3 | 73.3 | 68.5 | 73.5 | 75.0 |
| + Jina-Bert | 88.1 | 77.7 | 60.5 | 51.1 | 83.3 | 81.0 | 66.9 | 68.5 | 68.9 | 71.2 |
| ++ Dense Caption | 87.9 | 77.9 | 60.9 | 50.3 | 95.3 | 95.1 | 79.4 | 83.8 | 73.8 | 77.9 |
| + Llama3-8B-S | 87.9 | 75.6 | 56.7 | 41.8 | 55.1 | 46.1 | 37.2 | 35.1 | 39.3 | 32.3 |
| ++ CC Finetuning | 92.4 | 82.9 | 67.6 | 54.5 | 97.7 | 94.9 | 75.8 | 83.4 | 83.7 | 85.6 |
| +++ Dense Caption | 92.0 | 82.8 | 68.5 | 54.8 | 98.6 | 99.0 | 88.1 | 94.0 | 88.2 | 90.4 |
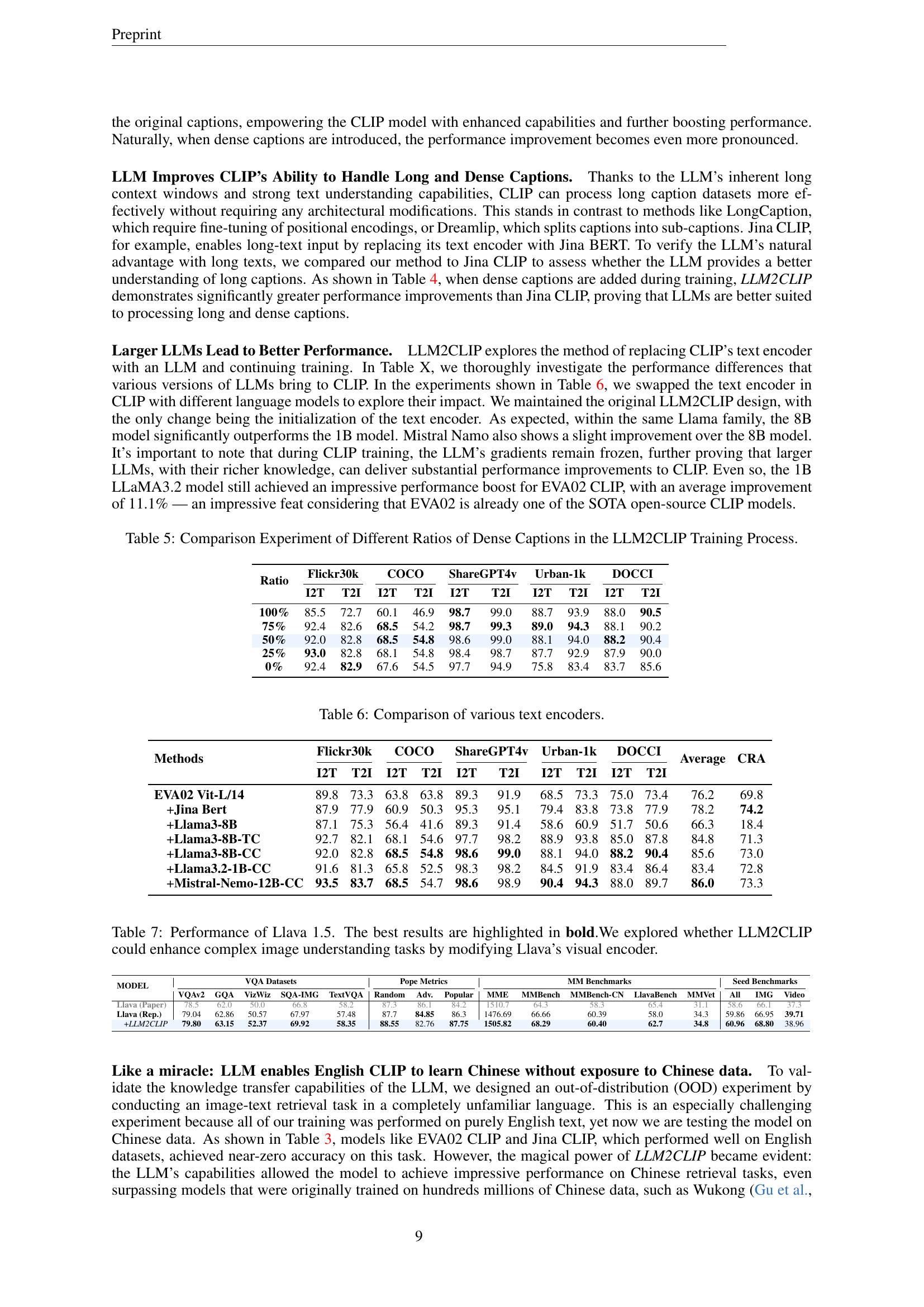
🔼 This table presents a comparison of the performance of the LLM2CLIP model trained with varying ratios of dense captions (longer, more detailed captions generated by ShareCaptioner) mixed with original captions. It showcases how different proportions of dense captions affect the model’s performance on various image-text retrieval benchmarks (Flickr30k, COCO, ShareGPT4V, Urban-1k, DOCCI). The results demonstrate the impact of dense caption data on the model’s ability to handle both short and long caption tasks, revealing an optimal ratio for achieving the best overall performance.
read the caption
Table 5: Comparison Experiment of Different Ratios of Dense Captions in the LLM2CLIP Training Process.
| Ratio | Flickr30k I2T | Flickr30k T2I | COCO I2T | COCO T2I | ShareGPT4v I2T | ShareGPT4v T2I | Urban-1k I2T | Urban-1k T2I | DOCCI I2T | DOCCI T2I |
|---|---|---|---|---|---|---|---|---|---|---|
| 100% | 85.5 | 72.7 | 60.1 | 46.9 | 98.7 | 99.0 | 88.7 | 93.9 | 90.5 | 88.0 |
| 75% | 92.4 | 82.6 | 68.5 | 54.2 | 98.7 | 99.3 | 89.0 | 94.3 | 90.2 | 88.1 |
| 50% | 92.0 | 82.8 | 68.5 | 54.8 | 98.6 | 99.0 | 88.1 | 94.0 | 88.2 | 90.4 |
| 25% | 93.0 | 82.8 | 68.1 | 54.8 | 98.4 | 98.7 | 87.7 | 92.9 | 87.9 | 90.0 |
| 0% | 92.4 | 82.9 | 67.6 | 54.5 | 97.7 | 94.9 | 75.8 | 83.4 | 83.7 | 85.6 |
🔼 This table compares the performance of different text encoders in a caption retrieval task using the MS COCO dataset. Specifically, it contrasts the accuracy of various models, including a standard CLIP ViT-L, different versions of the Llama family of LLMs (with and without contrastive caption fine-tuning), and Jina-Bert. The comparison is crucial to demonstrating the effectiveness of the proposed LLM2CLIP method’s caption contrastive fine-tuning step, highlighting how it improves the discriminative capabilities of LLMs to the point where they can effectively guide the visual encoder training in CLIP.
read the caption
Table 6: Comparison of various text encoders.
| Methods | Flickr30k I2T | Flickr30k T2I | COCO I2T | COCO T2I | ShareGPT4v I2T | ShareGPT4v T2I | Urban-1k I2T | Urban-1k T2I | DOCCI I2T | DOCCI T2I | Average | CRA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EVA02 Vit-L/14 | 89.8 | 73.3 | 63.8 | 63.8 | 89.3 | 91.9 | 68.5 | 73.3 | 75.0 | 73.4 | 76.2 | 69.8 |
| +Jina Bert | 87.9 | 77.9 | 60.9 | 50.3 | 95.3 | 95.1 | 79.4 | 83.8 | 73.8 | 77.9 | 78.2 | 74.2 |
| +Llama3-8B | 87.1 | 75.3 | 56.4 | 41.6 | 89.3 | 91.4 | 58.6 | 60.9 | 51.7 | 50.6 | 66.3 | 18.4 |
| +Llama3-8B-TC | 92.7 | 82.1 | 68.1 | 54.6 | 97.7 | 98.2 | 88.9 | 93.8 | 85.0 | 87.8 | 84.8 | 71.3 |
| +Llama3-8B-CC | 92.0 | 82.8 | 68.5 | 54.8 | 98.6 | 99.0 | 88.1 | 94.0 | 88.2 | 90.4 | 85.6 | 73.0 |
| +Llama3.2-1B-CC | 91.6 | 81.3 | 65.8 | 52.5 | 98.3 | 98.2 | 84.5 | 91.9 | 83.4 | 86.4 | 83.4 | 72.8 |
| +Mistral-Nemo-12B-CC | 93.5 | 83.7 | 68.5 | 54.7 | 98.6 | 98.9 | 90.4 | 94.3 | 88.0 | 89.7 | 86.0 | 73.3 |
🔼 This table presents the performance comparison of Llava 1.5, a Vision-Language Large Model (VLLM), with and without the LLM2CLIP enhancement. LLM2CLIP modifies Llava’s visual encoder to improve its complex image understanding capabilities. The results are presented across various evaluation metrics and datasets, including VQA (Visual Question Answering) benchmarks like VQAv2, GQA, VizWiz, SQA-IMG, and TextVQA; and Multi-modal benchmarks, such as Random, Adv., Popular, MME, MMBench, MMBench-CN, and LlavaBench, to assess performance on image-only and image-video tasks. The best-performing results for each benchmark are highlighted in bold, demonstrating the significant improvements achieved by integrating LLM2CLIP into the Llava model.
read the caption
Table 7: Performance of Llava 1.5. The best results are highlighted in bold.We explored whether LLM2CLIP could enhance complex image understanding tasks by modifying Llava’s visual encoder.
Full paper#