↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current open-vocabulary mobile manipulation systems struggle with dynamic real-world scenarios where environments frequently change. These systems usually assume static environments, limiting their applicability. The reliance on static maps restricts the robots’ ability to effectively adapt to changing object locations and the presence of new or removed objects, thus hindering their real-world performance.
To overcome this limitation, the researchers developed DynaMem, a dynamic spatio-semantic memory architecture. DynaMem uses a 3D voxel grid to represent the environment and updates this representation in real-time as the environment changes. This allows the robot to handle addition and removal of objects. The system uses multimodal LLMs or open-vocabulary features to answer object localization queries. Extensive experiments on real and offline scenes demonstrate a significant improvement (more than 2x) in pick-and-drop success rates for non-stationary objects compared to systems with static memory.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in current open-vocabulary mobile manipulation systems: the inability to handle dynamic environments. It introduces DynaMem, a novel spatio-semantic memory architecture that enables robots to effectively perceive, adapt to, and operate within environments that change over time. This is highly relevant to the advancement of robust and practical robots for real-world applications and opens new avenues for research in dynamic scene understanding and adaptive robot control.
Visual Insights#

🔼 Figure 1 illustrates DynaMem, an online dynamic spatio-semantic memory system. It shows how DynaMem responds to open-vocabulary queries in a dynamic environment by continuously updating its internal 3D representation. This representation is a voxelized point cloud that dynamically adapts to changes in the environment, such as objects moving, appearing, or disappearing. The figure shows a sequence of snapshots illustrating how the system updates its map, searches for objects, and performs actions based on natural language commands.
read the caption
Figure 1: An illustration of how our online dynamic spatio-semantic memory DynaMem responds to open vocabulary queries in a dynamic environment. During operation and exploration, DynaMem keeps updating its semantic map in memory. DynaMem maintains a voxelized pointcloud representation of the environment, and updates with dynamic changes in the environment by adding and removing points.
| Query type | Variant | Success rate |
|---|---|---|
| Human | (average over five participants) | 81.9% |
| VLM-feature | default (adding and removing points) | 70.6% |
| only adding points | 67.8% | |
| no OWL-v2 cross-check | 59.2% | |
| no similarity thresholding | 66.8% | |
| mLLM-QA | default (Gemini Pro 1.5) | 67.3% |
| Gemini Pro 1.5, no voxelmap filtering | 66.8% | |
| Gemini Flash 1.5 | 63.5% | |
| Hybrid | VLM-feature → mLLM (k=3) | 74.5% |
🔼 This table presents an ablation study on the design choices of DynaMem’s query methods, evaluated on the offline DynaBench benchmark. It compares the success rates of different variations of the VLM-feature and mLLM-QA based query methods, including variations in the point-adding/removing strategies, cross-checking with an object detector, and use of voxelmap filtering. For comparison, it also includes the average success rate achieved by five human participants on the same task. This allows for a quantitative analysis of the impact of each design choice on the overall performance of DynaMem.
read the caption
Table 1: Ablating the design choices for our query methods for DynaMem on the offline DynaBench benchmark. We also present results from five human participants to ground the performances.
In-depth insights#
Dynamic Spatio-Mem#
A Dynamic Spatio-Mem system, as conceived, would represent a significant advancement in robotics, particularly within the realm of open-vocabulary mobile manipulation. The core idea revolves around creating a dynamic 3D representation of the robot’s environment, constantly updating itself based on sensor input. This contrasts with static systems that assume unchanging environments. DynaMem would maintain a detailed spatio-semantic memory, storing not only spatial information (locations of objects and obstacles) but also semantic data (object identities and attributes). This rich representation enables robust object localization, using either vision-language models or multimodal LLMs, and allows the robot to handle environments that are constantly changing due to its own actions or external factors. A key aspect would be the system’s ability to efficiently handle the addition and removal of objects and obstacles, something static systems struggle with. This would require sophisticated algorithms for managing the dynamic memory, such as efficiently updating point clouds, managing object associations, and identifying outdated or irrelevant data. The success of a Dynamic Spatio-Mem system relies heavily on the performance of the underlying vision and language models, as their capabilities directly impact the accuracy of the spatio-semantic mapping and object localization. A final crucial element would be exploration strategies that guide the robot to effectively survey the environment, update its memory, and resolve uncertainties.
OVMM in Dynamic Worlds#
Open-vocabulary mobile manipulation (OVMM) in dynamic worlds presents a significant challenge to current robotics research. Static environments assumed by most existing OVMM systems are unrealistic, limiting their real-world applicability. The ability to handle changes in the environment, such as objects moving, appearing, or disappearing, requires new techniques in object recognition, localization, and navigation. Dynamic spatio-semantic memory, as explored in papers like DynaMem, offers a promising approach, maintaining a constantly updated representation of the robot’s surroundings. Efficient exploration strategies become crucial in dynamic settings to discover and track changes. The development of new, robust dynamic benchmarks is also important for evaluating the performance of OVMM systems in realistic scenarios. Successfully addressing these challenges is key to building truly adaptable and robust mobile manipulation robots capable of operating in the unpredictable complexities of real-world environments.
DynaMem Architecture#
The DynaMem architecture is a novel approach to spatio-semantic memory for open-world mobile manipulation. Its core innovation lies in its dynamic 3D voxel map, which continuously updates based on new sensory information. This dynamic representation effectively handles changes in the environment by adding or removing points to represent the addition or removal of objects or obstacles, respectively. DynaMem is queryable in two main ways: through vision-language models (VLMs) which interpret feature vectors from point clouds within the voxels and through Multimodal Large Language Models (mLLMs) which understand natural language queries and use them to retrieve relevant information from the map. The architecture also includes a value-based exploration component that guides the robot toward unexplored, outdated, or query-relevant areas of the environment. This combination of dynamic map updates, multiple query mechanisms and an exploration strategy makes DynaMem particularly well-suited for complex, ever-changing real-world scenarios.
Benchmarking DynaMem#
Benchmarking DynaMem would require a multifaceted approach. Real-world testing, using robots in diverse, dynamic environments, is crucial to evaluate its practical effectiveness. A controlled offline benchmark, such as DynaBench, is also essential for systematic ablation studies isolating specific aspects, like query methods or memory updating strategies. Quantitative metrics such as pick-and-drop success rates, localization accuracy, and robustness to environmental changes must be established. Comparison to existing state-of-the-art methods, like OK-Robot, using the same evaluation criteria is important for demonstrating advancements. Analyzing failure modes, identifying common causes and exploring potential improvements, is a key component of a thorough benchmarking exercise. Finally, human evaluations, providing comparative human performance and subjective assessment of the system’s usability and intuitiveness, provide valuable context for interpreting the quantitative results.
Future of DynaMem#
The future of DynaMem hinges on addressing its current limitations and capitalizing on its strengths. Improving the robustness of object localization, particularly in cluttered scenes or with ambiguous object descriptions, is crucial. This could involve exploring more sophisticated methods for integrating visual and language information, potentially using more advanced multimodal LLMs or refining the hybrid VLM-mLLM approach. Extending DynaMem to handle more complex manipulation tasks, such as those involving interactions between multiple objects, assembly, or tool use, would significantly increase its practical value. Furthermore, enhancing the efficiency of the map update mechanism is vital for real-time performance in highly dynamic environments. Reducing computational costs associated with adding and removing voxels while maintaining accuracy is a key area for future work. Finally, developing standardized benchmarks for dynamic spatio-semantic memory systems would facilitate robust evaluation and comparison, encouraging the advancement of the field. The success of DynaMem ultimately depends on its adaptability, accuracy, and efficiency in handling the complex, ever-changing nature of real-world environments.
More visual insights#
More on figures

🔼 Figure 2 is a two-part illustration detailing DynaMem’s architecture and update mechanism. The left panel shows DynaMem’s core structure: a sparse 3D voxel grid. Each occupied voxel stores multiple pieces of information including its 3D coordinates, a count of observations, the ID of the source image, a semantic feature vector (from a Vision-Language Model like CLIP), and the time of its last observation. The right panel illustrates how DynaMem updates when new points are detected. It shows the addition of new points to the voxel grid and the rules governing updates to the existing data within each voxel, including recalculating the feature vector and timestamp.
read the caption
Figure 2: (Left) DynaMem keeps its memory stored in a sparse voxel grid with associated information at each voxel. (Right) Updating DynaMem by adding new points to it, alongside the rules used to update the stored information.

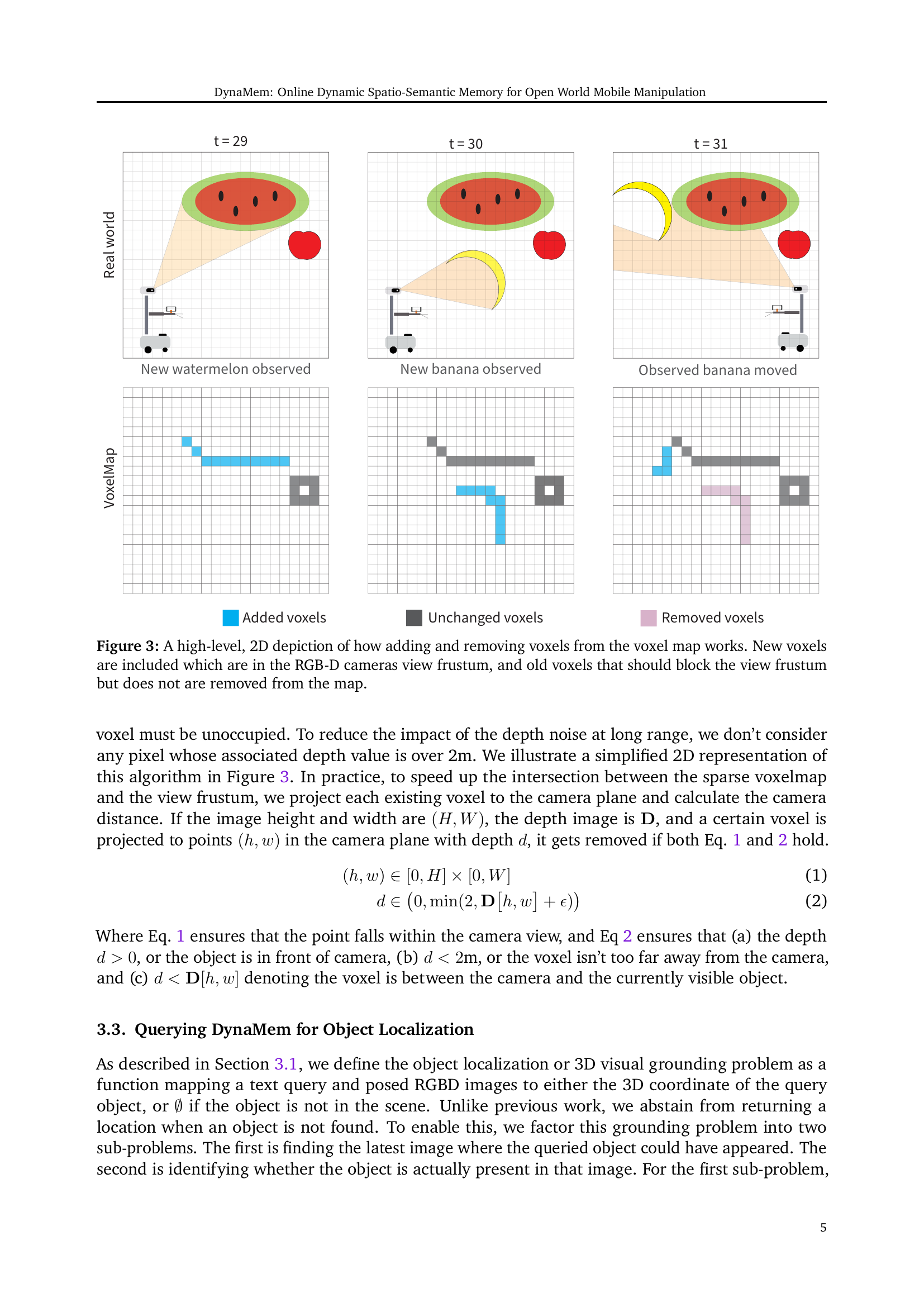
🔼 Figure 3 illustrates the dynamic update process of the 3D voxel map used in DynaMem. It shows how new voxels representing observed objects are added to the map, but only if they fall within the camera’s view frustum. Conversely, old voxels that are no longer observed, or that are obstructed by more recently observed objects which should block them from the view, are removed, reflecting changes in the environment over time. This dynamic update ensures that the map always reflects the current state of the environment, dealing effectively with object movement, occlusion and removal.
read the caption
Figure 3: A high-level, 2D depiction of how adding and removing voxels from the voxel map works. New voxels are included which are in the RGB-D cameras view frustum, and old voxels that should block the view frustum but does not are removed from the map.

🔼 This figure illustrates the process of querying DynaMem, a dynamic spatio-semantic memory, using a natural language query. The system first identifies the voxel in its 3D voxel grid that best matches the query. Then, it retrieves the most recent image associated with that voxel. Finally, an open-vocabulary object detector is used on that image to verify the presence of the queried object and provide its 3D coordinates or abstain if the object isn’t found. This process demonstrates how DynaMem handles object localization requests in a dynamic environment by combining voxel-based spatial information with image-based object detection.
read the caption
Figure 4: Querying DynaMem with a natural language query. First, we find the voxel with the highest alighnment to the query. Next, we find the latest image of that voxel, and query with an open-vocabulary object detector to confirm the object location or abstain.

🔼 Figure 5 illustrates the process of querying a multimodal large language model (LLM), such as GPT-4 or Gemini-1.5, to identify the index of the image containing a target object. The prompt carefully instructs the LLM to focus solely on providing the image index without adding any extraneous information or context. If the model cannot locate the object in any of the provided images, it is prompted to return only the object name and the word ‘None’ for the image index. The figure shows an example prompt and response, emphasizing the structure and clarity needed for effective LLM interaction in this specific task of visual grounding.
read the caption
Figure 5: The prompting system for querying multimodal LLMs such as GPT-4o or Gemini-1.5 for the image index for an object query.

🔼 Figure 6 shows three real-world environments used for robotic manipulation experiments: a kitchen, a game room, and a meeting room. In each setting, the researchers altered the environment’s arrangement three times, and during each alteration, they conducted ten object pick-and-drop tasks using the robot. This setup allowed them to evaluate the robot’s ability to perform manipulation tasks in dynamic environments. The image provides a panoramic view of each environment.
read the caption
Figure 6: Real robot experiments in three different environments: kitchen, game room, and meeting room. In each environment, we modify the environment thrice and run 10 pick-and-drop queries.

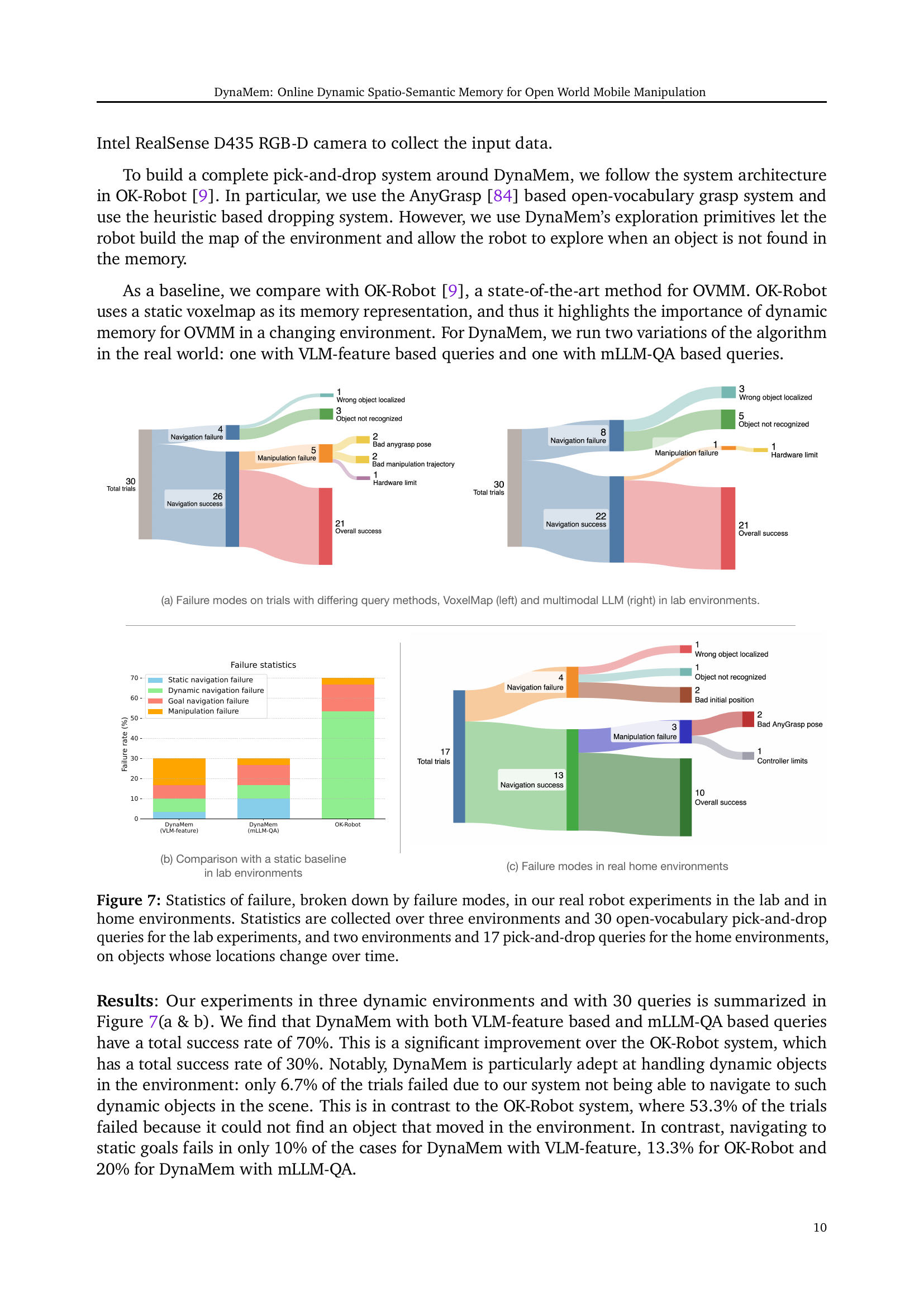
🔼 Figure 7 presents a detailed breakdown of the failure modes encountered during real-world experiments using the DynaMem system for open-vocabulary mobile manipulation. The experiments were conducted in both lab and home environments. The lab experiments involved three different environments and 30 open-vocabulary pick-and-drop queries, while the home experiments used two environments and 17 queries. Crucially, all experiments tested the system’s ability to handle objects whose locations changed over time. The figure visually represents the frequency of each failure type, offering insights into the system’s weaknesses and areas for potential improvement. This allows for a precise quantitative analysis of the system’s reliability and robustness in dynamic real-world settings.
read the caption
Figure 7: Statistics of failure, broken down by failure modes, in our real robot experiments in the lab and in home environments. Statistics are collected over three environments and 30 open-vocabulary pick-and-drop queries for the lab experiments, and two environments and 17 pick-and-drop queries for the home environments, on objects whose locations change over time.
Full paper#