↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) with increasingly larger context windows are becoming more prevalent. However, there’s limited understanding of how effectively they utilize this expanded context, particularly for complex information retrieval tasks. Existing benchmarks often fall short in assessing this capability thoroughly. This paper addresses this gap by proposing more rigorous evaluation methods, focusing on the ability of LLMs to ’thread’ through long contexts to retrieve specific pieces of information.
The researchers developed a novel suite of complex information retrieval tasks to test 17 LLMs. These tasks, involving ‘single needle’, ‘multiple needle’, ‘conditional needle’, and ’threading’ scenarios, were designed to push the boundaries of current LLM capabilities. They found that while many models perform well in simpler scenarios, their performance degrades significantly as context length increases. This emphasizes the distinction between supported and truly effective context limits, highlighting the need for more precise evaluation metrics.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it identifies a critical gap in current LLM evaluation: the inability to effectively assess their ability to navigate complex information scattered across long contexts. The work introduces challenging benchmarks and novel metrics to address this gap, directly impacting the design and development of future LLMs and their applications. This has implications for various domains requiring complex information retrieval and reasoning. The paper also highlights critical issues surrounding tokenization and context limits, thereby improving the comparability and reliability of future research.
Visual Insights#

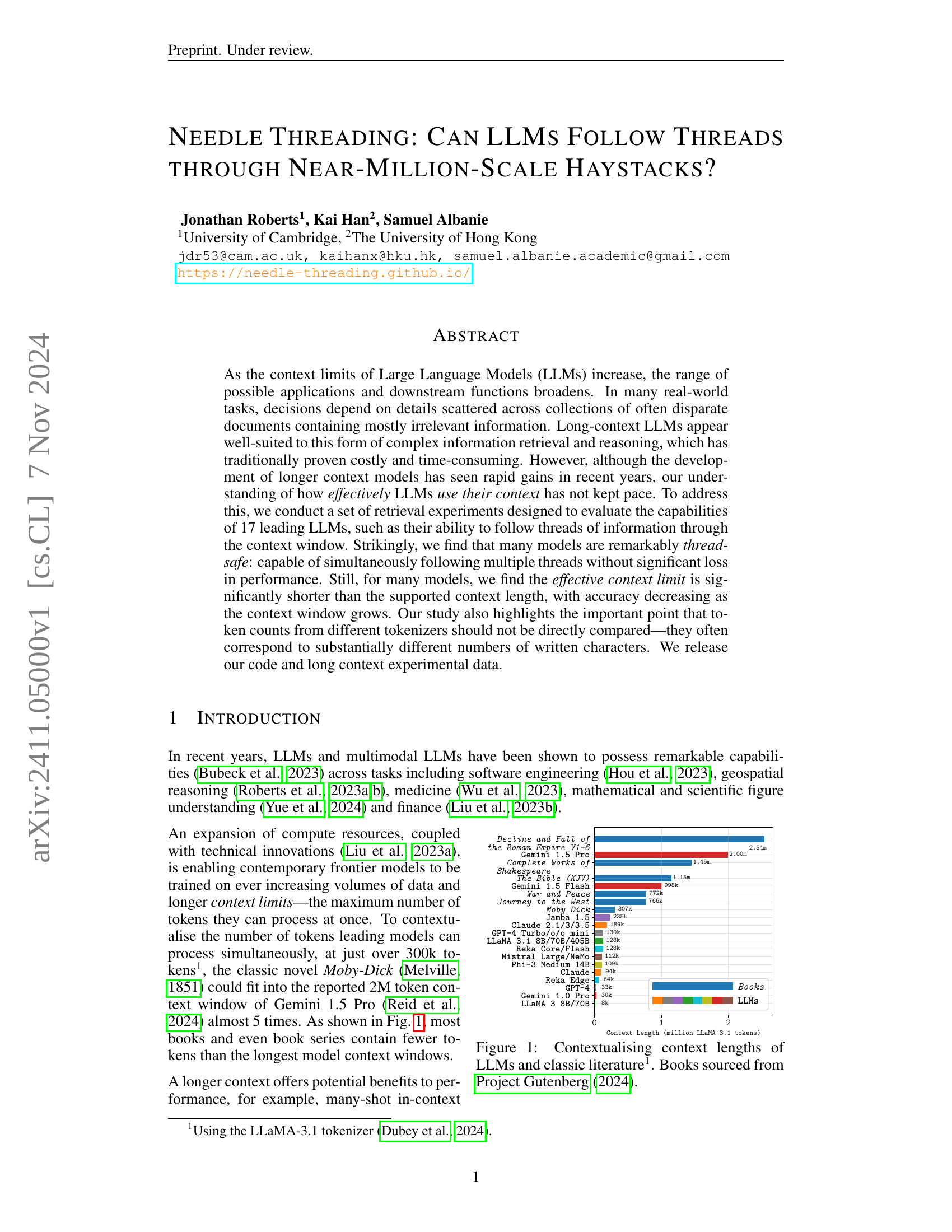
🔼 This figure compares the context window sizes of various large language models (LLMs) with the token counts of several classic books. The token counts are calculated using the LLaMA-3.1 tokenizer. The figure visually represents the relative capabilities of current LLMs to process information contained within works of literature, highlighting that many contemporary LLMs can now handle entire novels within their context window.
read the caption
Figure 1: Contextualising context lengths of LLMs and classic literature111Using the LLaMA-3.1 tokenizer (Dubey et al., 2024).. Books sourced from Project Gutenberg (2024).
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 87.7 | 81.1 | 76.7 | 78.6 | 74.8 | 72.7 | 69.2 | 65.2 | - | - | - | - |
| Gemini 1.5 Flash | 80.7 | 73.3 | 70.1 | 67.5 | 65.7 | 60.1 | 53.9 | 53.3 | 46.1 | 37.4 | 21.3 | 19.7 |
| Jamba 1.5 Large | 70.8 | 63.5 | 60.2 | 57.5 | 47.1 | 43.9 | 43.4 | 40.4 | - | - | - | - |
| Jamba 1.5 Mini | 55.4 | 50.4 | 44.8 | 39.0 | 33.3 | 30.4 | 27.2 | 20.4 | - | - | - | - |
| Claude 3.5 Sonnet | 91.5 | 88.7 | 84.9 | 80.9 | 79.4 | 75.9 | 63.2 | 50.6 | 48.0 | - | - | - |
| Claude 3 Sonnet | 82.0 | 73.7 | 67.9 | 52.0 | 44.6 | 44.7 | 39.9 | 38.8 | 37.6 | - | - | - |
| Claude 3 Haiku | 71.8 | 65.7 | 62.8 | 59.3 | 53.3 | 50.3 | 43.0 | 37.2 | 37.4 | - | - | - |
| GPT-4o | 93.2 | 86.1 | 81.6 | 74.1 | 71.9 | 68.6 | 64.9 | 60.9 | - | - | - | - |
| GPT-4o mini | 75.7 | 67.9 | 64.7 | 61.8 | 58.3 | 56.3 | 51.3 | 42.9 | - | - | - | - |
| Reka Core | 59.8 | 53.8 | 17.0 | 33.5 | 29.6 | 27.0 | 24.9 | - | - | - | - | - |
| Reka Flash | 58.8 | 43.5 | 31.2 | 29.8 | 26.8 | 25.4 | 20.4 | 14.1 | - | - | - | - |
| LLaMA 3.1 8b | 54.9 | 49.8 | 45.3 | 40.9 | 33.6 | 29.0 | 26.0 | 13.7 | - | - | - | - |
| LLaMA 3.1 70b | 78.1 | 68.9 | 66.0 | 61.9 | 57.1 | 52.5 | 38.5 | 4.5 | - | - | - | - |
| LLaMA 3.1 405b | 76.7 | 77.1 | 70.5 | 69.8 | 62.8 | 55.2 | 39.3 | 19.6 | - | - | - | - |
| Gemini 1.0 Pro | 59.7 | 46.9 | 42.5 | 40.9 | 27.8 | - | - | - | - | - | - | - |
🔼 This table presents the average performance across five different tasks (Single Needle, Multiple Needles, Conditional Needles, Threading, and Multi-threading) for seventeen large language models (LLMs). Each LLM’s accuracy is shown for various context sizes (1.2k, 2.5k, 5k, 10k, 20k, 32k, 64k, 128k, 180k, 250k, 500k, 630k tokens). The highest-performing model for each context length is highlighted in bold, allowing for easy comparison of model performance at different context sizes.
read the caption
Table 1: Overall results averaged across the Single Needle, Multiple Needles, Conditional Needles, Threading and Multi-threading tasks. The highest scoring models at each context size is bold.
In-depth insights#
LLM Context Limits#
LLM context limits represent a critical constraint in the capabilities of large language models. The maximum amount of text a model can process at once directly impacts performance on tasks requiring access to extensive information, such as complex reasoning, summarization of long documents, or maintaining conversational context over extended interactions. Exceeding these limits often leads to performance degradation, either through information loss or flawed reasoning. This constraint is not simply a matter of token count, as different tokenizers yield different numerical values for the same textual content, highlighting the need for a standardized and model-agnostic measure of effective context length. Research suggests that effective context windows are often significantly smaller than advertised limits, and the position of information within the window also influences performance. The impact of context length varies greatly across different tasks and models, emphasizing the need for task-specific evaluations and the development of methods for improving LLM performance when dealing with extended contexts. Exploring techniques for exceeding the context limit, such as efficient memory mechanisms or improved attention methods, is crucial for unlocking the full potential of LLMs and enabling them to tackle truly complex problems.
Needle Threading#
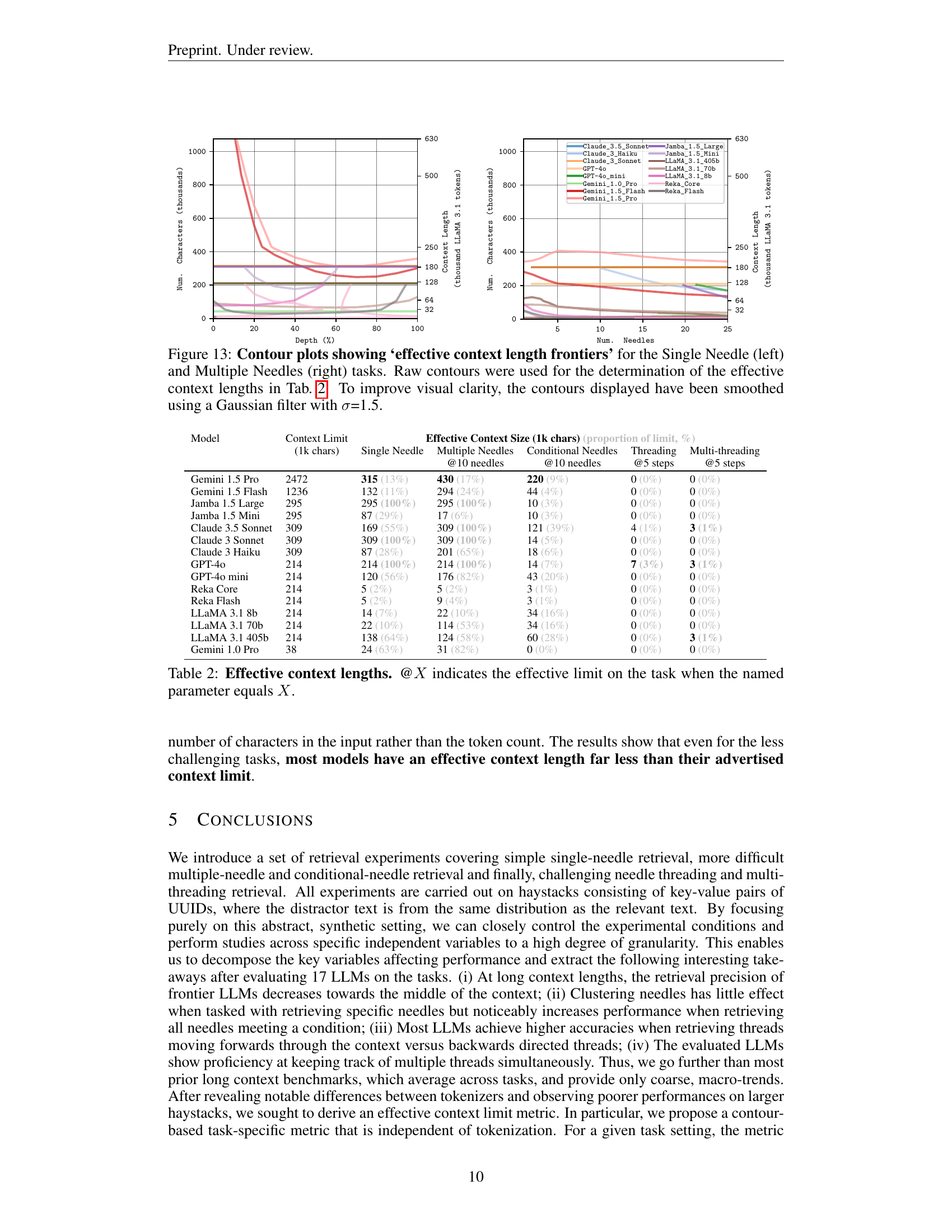
The concept of “Needle Threading” in the context of the research paper represents a novel approach to evaluating large language models (LLMs). It moves beyond simple keyword retrieval tasks by testing the ability of LLMs to follow chains of information, akin to threading a needle through a complex haystack of data. This multi-step process necessitates not only the retrieval of individual pieces of information but also the understanding of their relationships and order. The ingenuity of the “Needle Threading” task lies in its ability to expose limitations in LLMs’ contextual understanding that standard benchmark tests often miss. The challenge extends to multitasking, with multi-threading experiments adding another layer of complexity, requiring the simultaneous tracking of several independent information threads. The results highlight that effective context length, the amount of text an LLM can effectively process, is often significantly shorter than the model’s advertised context window. Moreover, the evaluation methodology emphasizes the importance of considering tokenization variations among different models and their impact on the measurement of effective context. This approach provides a more realistic and granular assessment of LLM capabilities in handling complex, interconnected information, thus advancing the evaluation of LLMs for real-world applications.
Multi-thread LLM#
The concept of “Multi-thread LLMs” introduces the fascinating possibility of concurrently processing multiple threads of information within a single large language model. This contrasts with traditional LLMs that typically process a single stream of text. The implications are significant, suggesting a potential leap in efficiency and complexity handling. A multi-thread LLM could tackle tasks requiring the simultaneous consideration of multiple sources, such as complex question-answering, where information is spread across diverse documents or multi-faceted decision-making, where multiple factors must be weighed. Effective context window management becomes crucial for these models, ensuring each thread maintains relevant context and doesn’t interfere with others. Challenges in developing this architecture would likely involve the design of internal mechanisms for managing multiple threads. This may require sophisticated resource allocation and context switching, potentially leading to new algorithmic developments and a deeper understanding of how LLMs process information. The exploration of the trade-offs between efficiency and complexity would also be essential in this area. It presents a significant area for research and innovation in the field of large language models.
Effective Context#
The concept of “Effective Context” in large language models (LLMs) is crucial because it reveals the discrepancy between the advertised context window and the model’s actual ability to utilize that information. While LLMs boast impressive context lengths (sometimes millions of tokens), their performance often degrades significantly before reaching that limit. This phenomenon suggests that an effective context limit exists, a point beyond which the model struggles to effectively process and integrate information. Factors influencing this effective limit include the complexity of the task, the position of relevant information within the context, and even the specific tokenizer used. Research on effective context helps refine our understanding of LLM capabilities, guiding the development of more efficient architectures and prompting strategies. Furthermore, understanding effective context is key to building more robust and reliable applications that can handle complex, real-world information retrieval tasks, especially those requiring multi-step reasoning and the integration of data from numerous sources. Measuring effective context requires careful experimentation and the development of benchmarks that go beyond simple retrieval tasks, exploring more nuanced aspects of long-context understanding such as thread following and concurrent query processing.
Future of LLMs#
The future of LLMs is incredibly promising, yet riddled with challenges. Continued advancements in model scale and architecture will likely lead to even more powerful and versatile models capable of complex reasoning and nuanced understanding. However, ethical concerns surrounding bias, misuse, and societal impact must be addressed proactively. Research into more efficient training methods and resource-conscious models is crucial to mitigate environmental concerns and broaden accessibility. Improved interpretability and explainability are also vital for building trust and fostering responsible development. Ultimately, the future of LLMs hinges on finding a balance between harnessing their potential for societal good and mitigating potential risks, requiring a collaborative effort between researchers, developers, and policymakers.
More visual insights#
More on figures

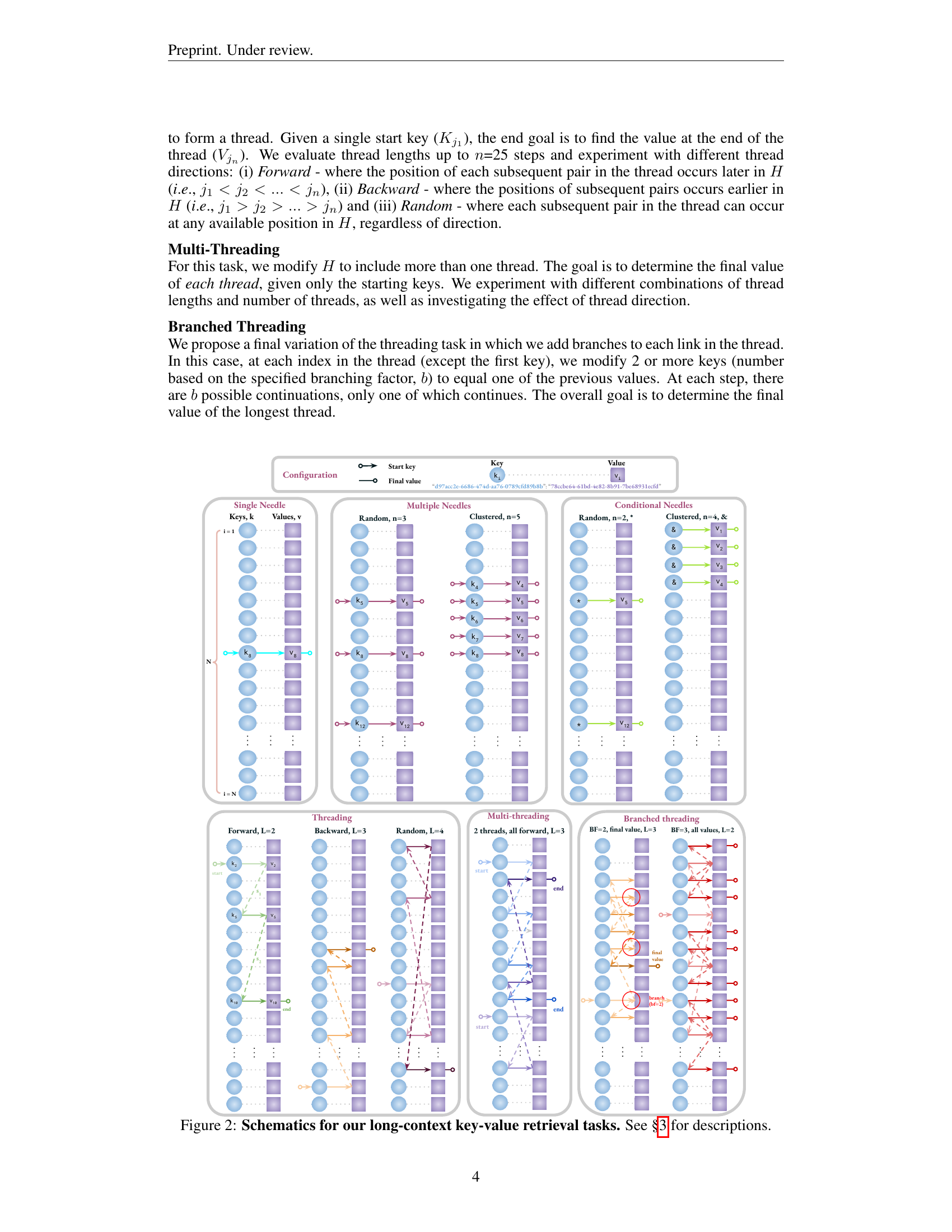
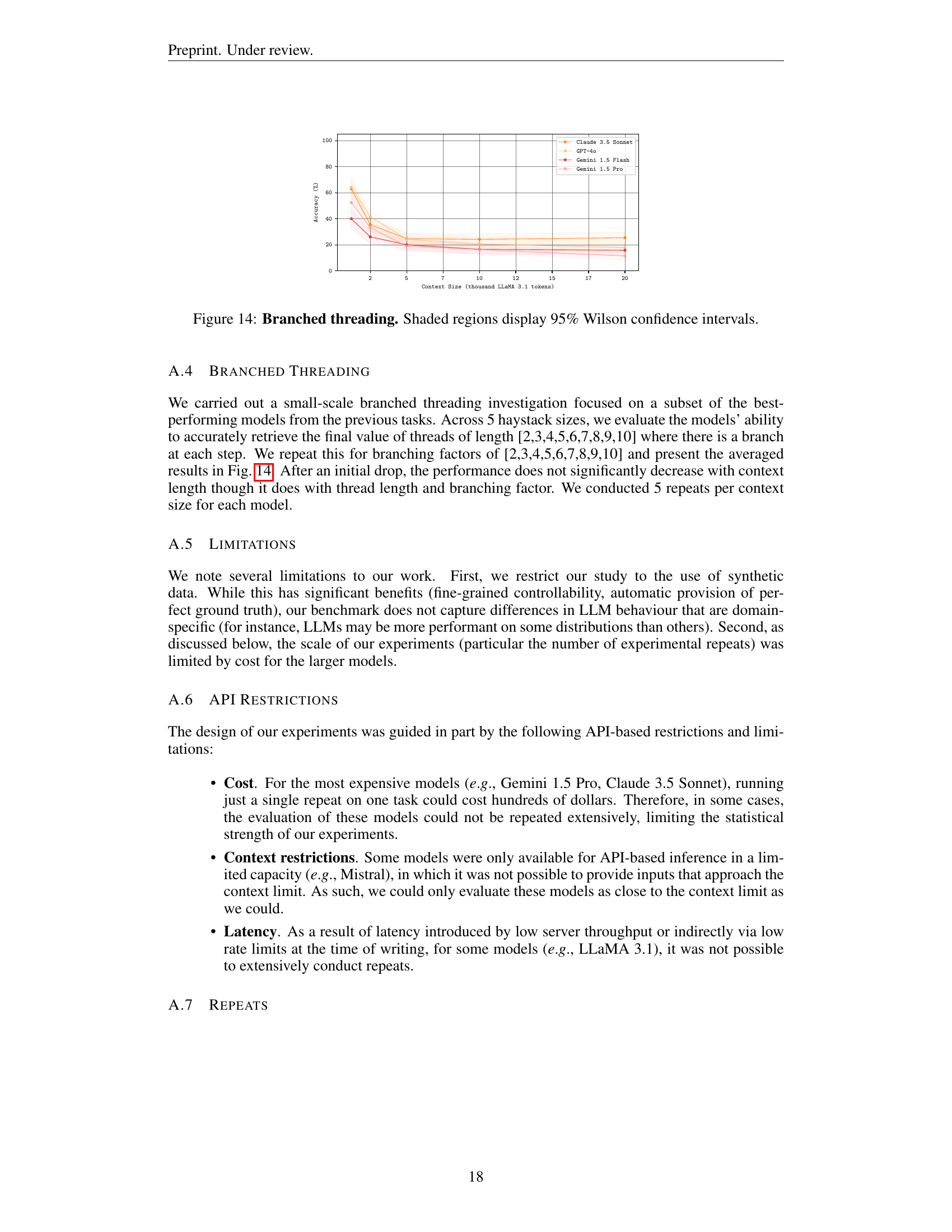
🔼 This figure provides a visual representation of the four key-value retrieval tasks used in the paper. Each task is illustrated using a schematic diagram showing the arrangement of keys and values within a haystack (a long sequence of data). The tasks vary in complexity, ranging from a simple single-needle retrieval (finding a single value corresponding to a given key) to more complex scenarios involving multiple needles (retrieving values for multiple keys simultaneously), conditional needles (retrieving values based on a specific condition), and threading (following a chain of linked keys and values). The diagrams clearly show the differences in the structures and processes of each task, making it easier to understand the experimental design.
read the caption
Figure 2: Schematics for our long-context key-value retrieval tasks. See §3 for descriptions.

🔼 Different large language models (LLMs) process the same text differently. This figure demonstrates that the tokenization of Universally Unique Identifiers (UUIDs) varies greatly between LLMs. UUIDs are frequently used in testing LLMs because they provide a consistent, easily measurable unit of text. The differences in tokenization highlight the need to be cautious when comparing context lengths reported in tokens across different models, as the actual amount of processed textual information might differ significantly.
read the caption
Figure 3: Tokenization. LLMs tokenize UUIDs at significantly different granularities.

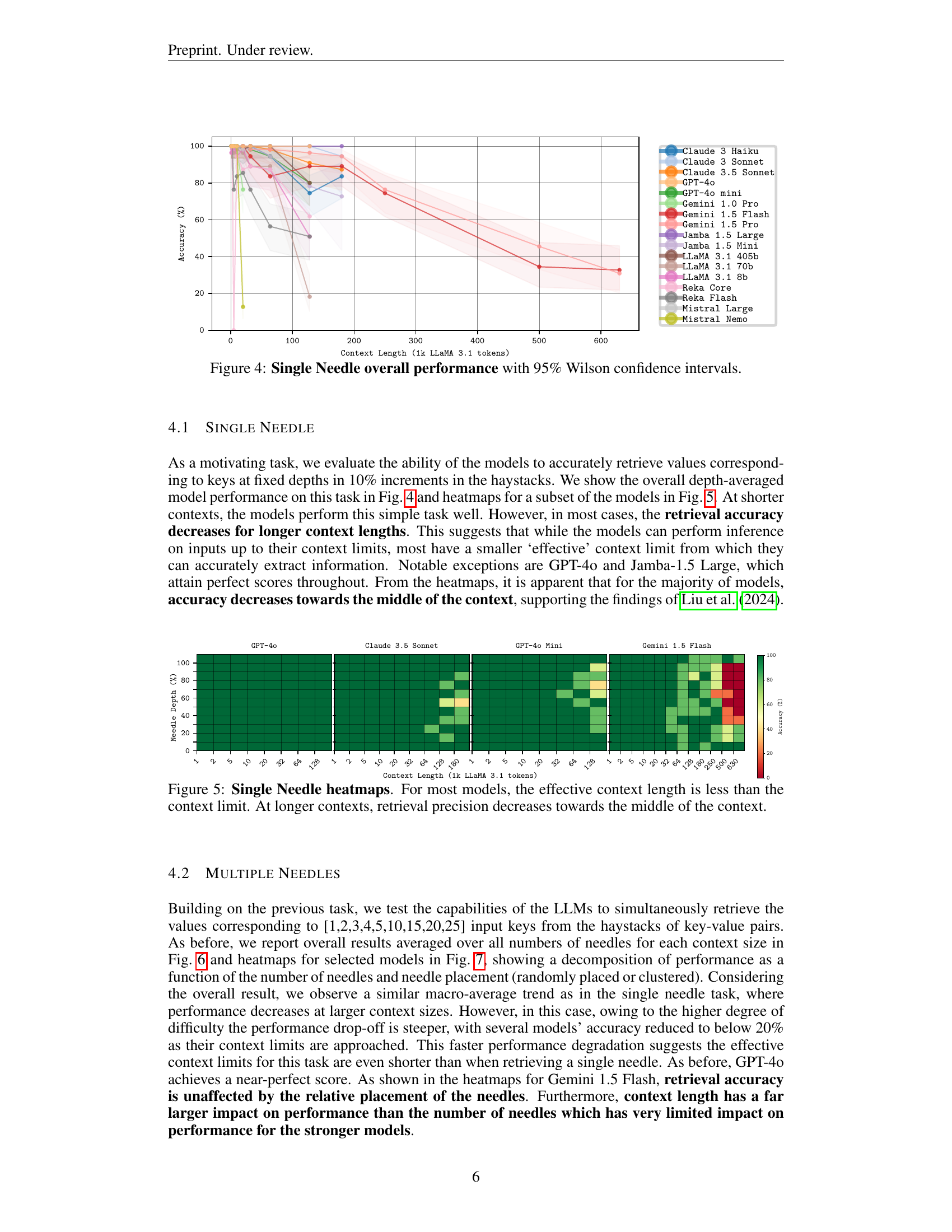
🔼 This figure displays the overall performance of 17 different Large Language Models (LLMs) on a single-needle retrieval task. The x-axis represents the context length (in thousands of LLaMA 3.1 tokens), and the y-axis shows the accuracy of the models in retrieving the correct value associated with a single key within that context. The plot includes 95% Wilson confidence intervals to show the uncertainty in the accuracy measurements. The results demonstrate how accuracy varies across different models and how it changes as the context length increases.
read the caption
Figure 4: Single Needle overall performance with 95% Wilson confidence intervals.

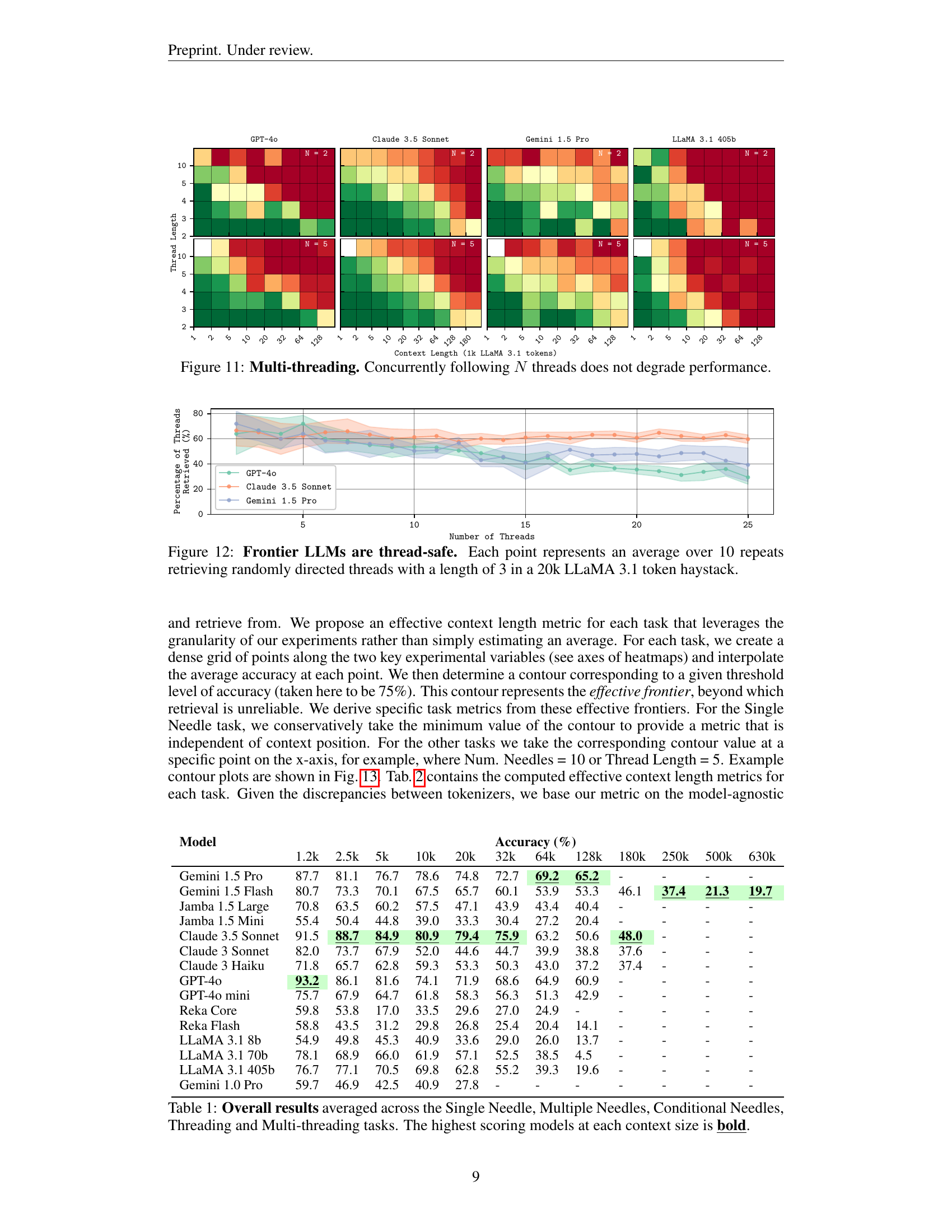
🔼 This figure visualizes the performance of different large language models (LLMs) on a single-needle retrieval task across varying context lengths. Each heatmap represents a model’s accuracy in retrieving a specific value (the ’needle’) from a large text (the ‘haystack’). The heatmaps show that the effective context length, i.e., the length of text within which the model can reliably find the needle, is considerably shorter than the maximum context window supported by the model. Furthermore, at longer contexts, the accuracy of retrieval decreases significantly in the middle of the haystack, while better accuracy is observed towards the beginning and end. This suggests that the position of the ’needle’ relative to the context start or end significantly impacts the accuracy.
read the caption
Figure 5: Single Needle heatmaps. For most models, the effective context length is less than the context limit. At longer contexts, retrieval precision decreases towards the middle of the context.

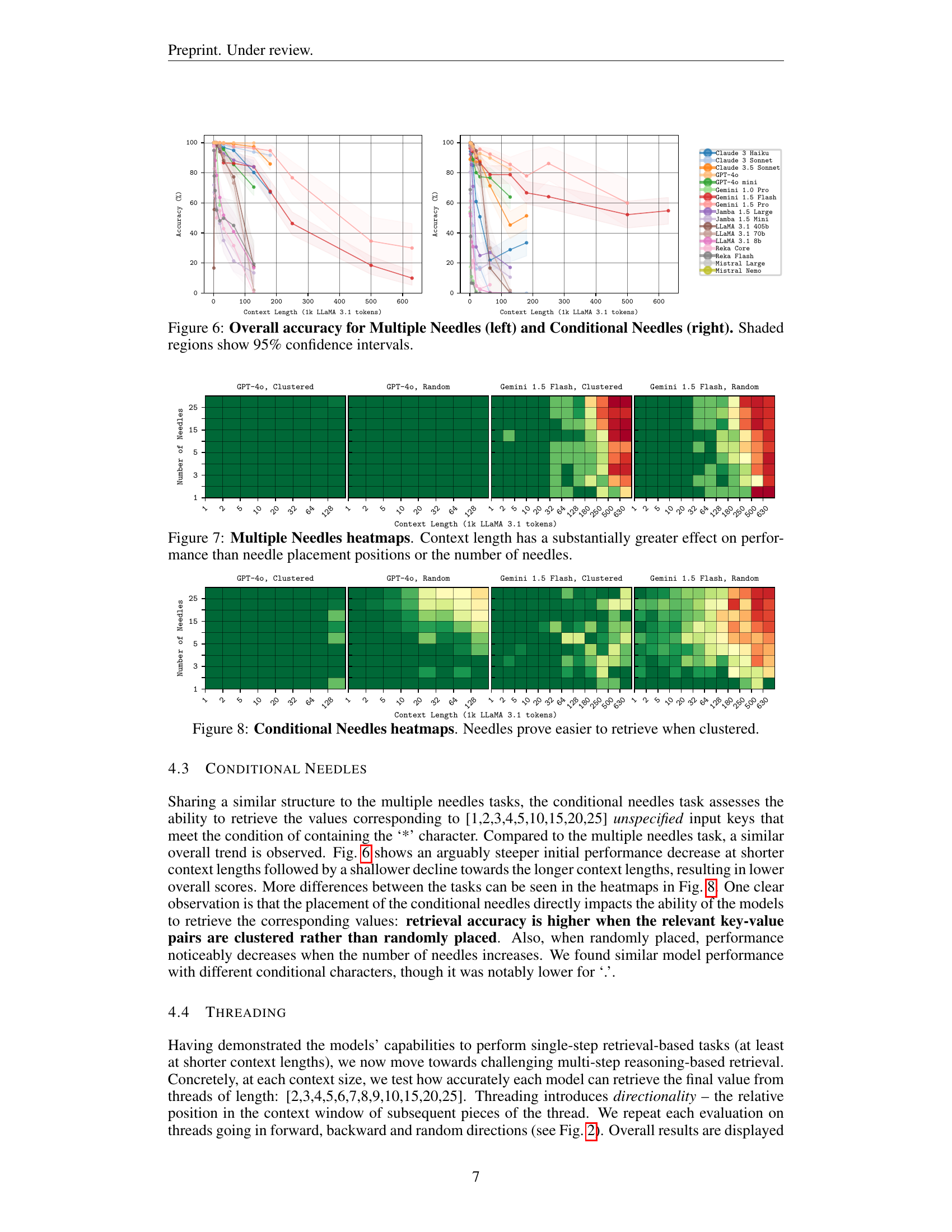
🔼 This figure displays the overall accuracy of various LLMs (Large Language Models) on two tasks: Multiple Needles and Conditional Needles. The left panel shows the accuracy for the Multiple Needles task, where the goal was to retrieve the values associated with multiple randomly selected keys from a large JSON dataset. The right panel presents the results for the Conditional Needles task, where the goal is to find values associated with keys containing a specific character. The performance of each LLM is shown across different context lengths. The shaded regions represent 95% confidence intervals, indicating the uncertainty associated with the accuracy measurements.
read the caption
Figure 6: Overall accuracy for Multiple Needles (left) and Conditional Needles (right). Shaded regions show 95% confidence intervals.

🔼 This figure displays heatmaps illustrating the performance of different LLMs on a ‘Multiple Needles’ task, which involves retrieving multiple values from a haystack of key-value pairs. Each heatmap represents a single model’s performance across various context lengths (x-axis) and numbers of needles (y-axis). The color intensity reflects the accuracy of the retrieval task. The results reveal that context length has a significantly greater effect on performance than the number of needles or their placement within the context window. Stronger models exhibit more consistent performance across different numbers of needles, but all models show decreased accuracy as context length increases.
read the caption
Figure 7: Multiple Needles heatmaps. Context length has a substantially greater effect on performance than needle placement positions or the number of needles.

🔼 This figure displays heatmaps visualizing the performance of different LLMs on a conditional needle retrieval task. The task involves retrieving values associated with keys that contain a specific character. The heatmaps show accuracy as a function of context length and the number of needles. Different color shades represent different accuracy levels. The results show a clear trend: when the needles (keys with the specific character) are clustered together within the haystack, the models achieve higher accuracy compared to scenarios with randomly placed needles. This indicates that the proximity or clustering of relevant information in the context improves the models’ ability to retrieve the correct values.
read the caption
Figure 8: Conditional Needles heatmaps. Needles prove easier to retrieve when clustered.
More on tables
| Model | Context Limit | Single Needle | Multiple Needles | Conditional Needles | Threading | Multi-threading |
|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 2472 | 315 (13%) | 430 (17%) | 220 (9%) | 0 (0%) | 0 (0%) |
| Gemini 1.5 Flash | 1236 | 132 (11%) | 294 (24%) | 44 (4%) | 0 (0%) | 0 (0%) |
| Jamba 1.5 Large | 295 | 295 (100%) | 295 (100%) | 10 (3%) | 0 (0%) | 0 (0%) |
| Jamba 1.5 Mini | 295 | 87 (29%) | 17 (6%) | 10 (3%) | 0 (0%) | 0 (0%) |
| Claude 3.5 Sonnet | 309 | 169 (55%) | 309 (100%) | 121 (39%) | 4 (1%) | 3 (1%) |
| Claude 3 Sonnet | 309 | 309 (100%) | 309 (100%) | 14 (5%) | 0 (0%) | 0 (0%) |
| Claude 3 Haiku | 309 | 87 (28%) | 201 (65%) | 18 (6%) | 0 (0%) | 0 (0%) |
| GPT-4o | 214 | 214 (100%) | 214 (100%) | 14 (7%) | 7 (3%) | 3 (1%) |
| GPT-4o mini | 214 | 120 (56%) | 176 (82%) | 43 (20%) | 0 (0%) | 0 (0%) |
| Reka Core | 214 | 5 (2%) | 5 (2%) | 3 (1%) | 0 (0%) | 0 (0%) |
| Reka Flash | 214 | 5 (2%) | 9 (4%) | 3 (1%) | 0 (0%) | 0 (0%) |
| LLaMA 3.1 8b | 214 | 14 (7%) | 22 (10%) | 34 (16%) | 0 (0%) | 0 (0%) |
| LLaMA 3.1 70b | 214 | 22 (10%) | 114 (53%) | 34 (16%) | 0 (0%) | 0 (0%) |
| LLaMA 3.1 405b | 214 | 138 (64%) | 124 (58%) | 60 (28%) | 0 (0%) | 3 (1%) |
| Gemini 1.0 Pro | 38 | 24 (63%) | 31 (82%) | 0 (0%) | 0 (0%) | 0 (0%) |
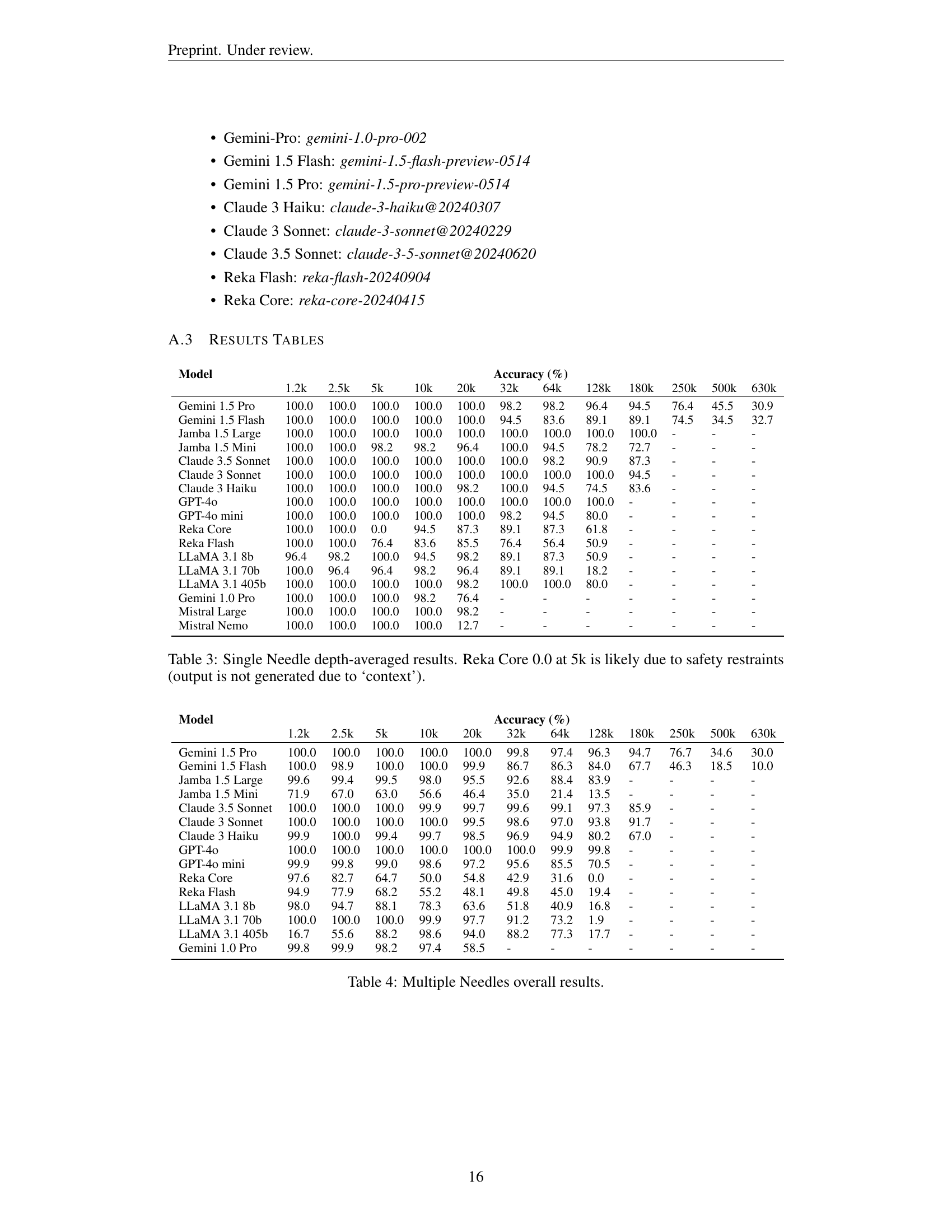
🔼 This table presents the effective context lengths for different LLMs across various tasks. The effective context length is defined as the maximum context size at which the model can perform accurately. The table shows this length, in thousands of characters, for each model and task (Single Needle, Multiple Needles, Conditional Needles, Threading, Multi-threading) at different parameter values (e.g., number of needles, thread length). The percentage of the advertised context limit is also shown, highlighting the difference between the theoretical limit and the actual effective limit where models perform reliably.
read the caption
Table 2: Effective context lengths. @X𝑋Xitalic_X indicates the effective limit on the task when the named parameter equals X𝑋Xitalic_X.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 98.2 | 98.2 | 96.4 | 94.5 | 76.4 | 45.5 | 30.9 |
| Gemini 1.5 Flash | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 94.5 | 83.6 | 89.1 | 89.1 | 74.5 | 34.5 | 32.7 |
| Jamba 1.5 Large | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | - | - | - |
| Jamba 1.5 Mini | 100.0 | 100.0 | 98.2 | 98.2 | 96.4 | 100.0 | 94.5 | 78.2 | 72.7 | - | - | - |
| Claude 3.5 Sonnet | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 98.2 | 90.9 | 87.3 | - | - | - |
| Claude 3 Sonnet | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 94.5 | - | - | - |
| Claude 3 Haiku | 100.0 | 100.0 | 100.0 | 100.0 | 98.2 | 100.0 | 94.5 | 74.5 | 83.6 | - | - | - |
| GPT-4o | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | - | - | - | - |
| GPT-4o mini | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 98.2 | 94.5 | 80.0 | - | - | - | - |
| Reka Core | 100.0 | 100.0 | 0.0 | 94.5 | 87.3 | 89.1 | 87.3 | 61.8 | - | - | - | - |
| Reka Flash | 100.0 | 100.0 | 76.4 | 83.6 | 85.5 | 76.4 | 56.4 | 50.9 | - | - | - | - |
| LLaMA 3.1 8b | 96.4 | 98.2 | 100.0 | 94.5 | 98.2 | 89.1 | 87.3 | 50.9 | - | - | - | - |
| LLaMA 3.1 70b | 100.0 | 96.4 | 96.4 | 98.2 | 96.4 | 89.1 | 89.1 | 18.2 | - | - | - | - |
| LLaMA 3.1 405b | 100.0 | 100.0 | 100.0 | 100.0 | 98.2 | 100.0 | 100.0 | 80.0 | - | - | - | - |
| Gemini 1.0 Pro | 100.0 | 100.0 | 100.0 | 98.2 | 76.4 | - | - | - | - | - | - | - |
| Mistral Large | 100.0 | 100.0 | 100.0 | 100.0 | 98.2 | - | - | - | - | - | - | - |
| Mistral Nemo | 100.0 | 100.0 | 100.0 | 100.0 | 12.7 | - | - | - | - | - | - | - |
🔼 This table presents the average accuracy of 17 different large language models (LLMs) across various context lengths in a single-needle retrieval task. The task involves retrieving a value corresponding to a given key from a haystack (a dataset of key-value pairs). The results are depth-averaged, meaning that the average performance across different key positions within the context window is reported. Note that Reka Core shows an accuracy of 0% at a context length of 5,000 tokens, likely due to safety or context limitations implemented by the model.
read the caption
Table 3: Single Needle depth-averaged results. Reka Core 0.0 at 5k is likely due to safety restraints (output is not generated due to ‘context’).
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 99.8 | 97.4 | 96.3 | 94.7 | 76.7 | 34.6 | 30.0 |
| Gemini 1.5 Flash | 100.0 | 98.9 | 100.0 | 100.0 | 99.9 | 86.7 | 86.3 | 84.0 | 67.7 | 46.3 | 18.5 | 10.0 |
| Jamba 1.5 Large | 99.6 | 99.4 | 99.5 | 98.0 | 95.5 | 92.6 | 88.4 | 83.9 | - | - | - | - |
| Jamba 1.5 Mini | 71.9 | 67.0 | 63.0 | 56.6 | 46.4 | 35.0 | 21.4 | 13.5 | - | - | - | - |
| Claude 3.5 Sonnet | 100.0 | 100.0 | 100.0 | 99.9 | 99.7 | 99.6 | 99.1 | 97.3 | 85.9 | - | - | - |
| Claude 3 Sonnet | 100.0 | 100.0 | 100.0 | 100.0 | 99.5 | 98.6 | 97.0 | 93.8 | 91.7 | - | - | - |
| Claude 3 Haiku | 99.9 | 100.0 | 99.4 | 99.7 | 98.5 | 96.9 | 94.9 | 80.2 | 67.0 | - | - | - |
| GPT-4o | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 99.9 | 99.8 | - | - | - | - |
| GPT-4o mini | 99.9 | 99.8 | 99.0 | 98.6 | 97.2 | 95.6 | 85.5 | 70.5 | - | - | - | - |
| Reka Core | 97.6 | 82.7 | 64.7 | 50.0 | 54.8 | 42.9 | 31.6 | 0.0 | - | - | - | - |
| Reka Flash | 94.9 | 77.9 | 68.2 | 55.2 | 48.1 | 49.8 | 45.0 | 19.4 | - | - | - | - |
| LLaMA 3.1 8b | 98.0 | 94.7 | 88.1 | 78.3 | 63.6 | 51.8 | 40.9 | 16.8 | - | - | - | - |
| LLaMA 3.1 70b | 100.0 | 100.0 | 100.0 | 99.9 | 97.7 | 91.2 | 73.2 | 1.9 | - | - | - | - |
| LLaMA 3.1 405b | 16.7 | 55.6 | 88.2 | 98.6 | 94.0 | 88.2 | 77.3 | 17.7 | - | - | - | - |
| Gemini 1.0 Pro | 99.8 | 99.9 | 98.2 | 97.4 | 58.5 | - | - | - | - | - | - | - |
🔼 This table presents the overall accuracy of 15 different large language models (LLMs) across various context lengths (1.2k to 630k tokens) on a multiple needles retrieval task. The task involves retrieving values corresponding to multiple keys simultaneously from a haystack of key-value pairs. The table shows the performance of each LLM in terms of accuracy for each context size. This allows for the analysis of how context length affects performance on a complex information retrieval task involving multiple simultaneous searches.
read the caption
Table 4: Multiple Needles overall results.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 98.6 | 98.3 | 95.2 | 97.3 | 93.6 | 95.7 | 92.4 | 85.6 | 77.9 | 86.2 | 59.9 | - |
| Gemini 1.5 Flash | 96.3 | 96.9 | 94.6 | 94.3 | 90.2 | 86.8 | 78.8 | 78.8 | 66.7 | 64.1 | 52.2 | 54.8 |
| Jamba 1.5 Large | 98.0 | 92.4 | 85.4 | 71.0 | 30.7 | 25.0 | 27.1 | 17.1 | - | - | - | - |
| Jamba 1.5 Mini | 80.5 | 66.3 | 46.0 | 30.7 | 19.6 | 15.9 | 20.3 | 10.6 | - | - | - | - |
| Claude 3.5 Sonnet | 88.9 | 92.2 | 89.8 | 88.3 | 87.1 | 87.7 | 71.4 | 45.3 | 51.4 | - | - | - |
| Claude 3 Sonnet | 99.9 | 99.9 | 98.1 | 45.0 | 16.1 | 17.0 | 0.0 | 0.1 | 0.0 | - | - | - |
| Claude 3 Haiku | 99.2 | 94.3 | 90.2 | 84.9 | 60.9 | 50.8 | 21.8 | 28.9 | 33.5 | - | - | - |
| GPT-4o | 100.0 | 99.8 | 99.2 | 97.5 | 91.2 | 92.8 | 89.9 | 82.3 | - | - | - | - |
| GPT-4o mini | 98.2 | 98.3 | 92.9 | 88.9 | 80.1 | 77.4 | 76.7 | 63.9 | - | - | - | - |
| Reka Core | 56.9 | 61.2 | 16.9 | 21.7 | 4.7 | 2.8 | 5.6 | - | - | - | - | - |
| Reka Flash | 68.8 | 37.7 | 6.7 | 6.6 | 0.2 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| LLaMA 3.1 8b | 52.9 | 51.2 | 34.1 | 31.0 | 4.9 | 2.5 | 0.4 | 0.0 | - | - | - | - |
| LLaMA 3.1 70b | 97.2 | 98.4 | 99.1 | 97.1 | 85.4 | 80.5 | 30.0 | 1.8 | - | - | - | - |
| LLaMA 3.1 405b | 100.0 | 100.0 | 99.8 | 98.5 | 94.7 | 85.6 | 16.7 | 0.2 | - | - | - | - |
| Gemini 1.0 Pro | 54.0 | 17.4 | 11.0 | 8.0 | 1.1 | - | - | - | - | - | - | - |
🔼 This table presents the overall accuracy of 17 different Large Language Models (LLMs) on the Conditional Needles task. The Conditional Needles task is a variation of the Multiple Needles task, in which the goal is to retrieve the values corresponding to keys containing a specific character (’*’ in this case). The table shows the accuracy of each model across various context lengths ranging from 1.2k to 630k tokens (measured in LLaMA 3.1 tokens). The accuracy is presented as a percentage for each model and context length.
read the caption
Table 5: Conditional Needles overall results.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 57.8 | 42.2 | 35.0 | 37.8 | 29.4 | 25.0 | 23.3 | 23.3 | - | - | - | - |
| Gemini 1.5 Flash | 46.7 | 33.9 | 25.6 | 18.3 | 16.7 | 13.9 | 10.0 | 6.7 | 2.8 | 0.0 | 1.1 | 0.6 |
| Jamba 1.5 Large | 23.9 | 12.2 | 8.3 | 5.6 | 5.6 | 0.6 | 1.1 | 0.0 | - | - | - | - |
| Jamba 1.5 Mini | 5.6 | 7.8 | 3.3 | 1.7 | 1.7 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| Claude 3.5 Sonnet | 78.3 | 72.2 | 61.7 | 53.3 | 52.2 | 43.9 | 13.3 | 5.6 | 4.4 | - | - | - |
| Claude 3 Sonnet | 40.0 | 26.7 | 17.2 | 7.2 | 6.7 | 2.8 | 1.1 | 0.0 | 0.0 | - | - | - |
| Claude 3 Haiku | 25.6 | 10.0 | 7.2 | 3.3 | 1.7 | 0.0 | 1.7 | 0.6 | 1.1 | - | - | - |
| GPT-4o | 75.0 | 61.1 | 51.1 | 30.0 | 23.3 | 16.1 | 14.4 | 7.2 | - | - | - | - |
| GPT-4o mini | 37.2 | 22.8 | 14.4 | 8.3 | 5.0 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| Reka Core | 27.8 | 22.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | - | - | - | - | - |
| Reka Flash | 19.4 | 0.0 | 2.8 | 2.8 | 0.0 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| LLaMA 3.1 8b | 13.2 | 1.4 | 0.7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| LLaMA 3.1 70b | 38.0 | 21.3 | 13.0 | 7.4 | 1.9 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| LLaMA 3.1 405b | 75.0 | 58.3 | 20.8 | 29.2 | 12.5 | 0.0 | 0.0 | 0.0 | - | - | - | - |
| Gemini 1.0 Pro | 23.3 | 8.9 | 2.2 | 0.6 | 1.1 | - | - | - | - | - | - | - |
| Mistral Large | 68.9 | 45.0 | 31.1 | 10.6 | 1.1 | - | - | - | - | - | - | - |
| Mistral Nemo | 12.2 | 7.2 | 2.2 | 0.0 | 0.0 | - | - | - | - | - | - | - |
🔼 This table presents the overall accuracy of 17 different Large Language Models (LLMs) on a Threading task. The Threading task involves retrieving a value by following a chain of linked keys and values within a large context. The table shows the accuracy for each model across different context lengths, ranging from 1.2k to 630k tokens (based on the LLaMA 3.1 tokenizer). The accuracy represents the percentage of correctly retrieved final values in the chain. This helps to understand the models’ ability to perform multi-step reasoning and follow information threads within long contexts.
read the caption
Table 6: Threading overall results.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 82.2 | 65.1 | 53.2 | 57.9 | 50.7 | 44.9 | 34.6 | 24.6 | - | - | - | - |
| Gemini 1.5 Flash | 60.5 | 36.9 | 30.4 | 25.1 | 21.9 | 18.5 | 10.5 | 7.8 | 4.0 | 2.2 | 0.3 | 0.5 |
| Jamba 1.5 Large | 32.5 | 13.5 | 8.0 | 13.0 | 3.8 | 1.2 | 0.6 | 1.2 | - | - | - | - |
| Jamba 1.5 Mini | 18.9 | 10.8 | 13.6 | 7.9 | 2.5 | 1.0 | 0.0 | 0.0 | - | - | - | - |
| Claude 3.5 Sonnet | 90.1 | 79.1 | 72.8 | 62.8 | 58.2 | 48.5 | 33.9 | 13.8 | 11.1 | - | - | - |
| Claude 3 Sonnet | 69.9 | 42.1 | 24.2 | 7.6 | 1.0 | 5.1 | 1.5 | 0.0 | 1.6 | - | - | - |
| Claude 3 Haiku | 34.1 | 24.2 | 17.4 | 8.7 | 7.4 | 4.0 | 2.3 | 1.6 | 1.6 | - | - | - |
| GPT-4o | 90.9 | 69.5 | 57.5 | 42.9 | 44.9 | 34.1 | 19.9 | 15.2 | - | - | - | - |
| GPT-4o mini | 43.0 | 18.6 | 17.3 | 13.1 | 9.3 | 10.3 | 0.0 | 0.0 | - | - | - | - |
| Reka Core | 16.8 | 2.9 | 3.5 | 1.5 | 1.3 | 0.0 | 0.2 | - | - | - | - | - |
| Reka Flash | 11.1 | 1.7 | 2.0 | 0.7 | 0.2 | 0.6 | 0.8 | 0.0 | - | - | - | - |
| LLaMA 3.1 8b | 14.0 | 3.3 | 3.5 | 0.9 | 1.1 | 1.5 | 1.6 | 0.6 | - | - | - | - |
| LLaMA 3.1 70b | 55.1 | 28.3 | 21.6 | 6.7 | 4.1 | 1.8 | 0.3 | 0.4 | - | - | - | - |
| LLaMA 3.1 405b | 91.6 | 71.5 | 43.7 | 22.7 | 14.5 | 2.2 | 2.4 | 0.3 | - | - | - | - |
| Gemini 1.0 Pro | 21.6 | 8.2 | 1.3 | 0.3 | 1.9 | - | - | - | - | - | - | - |
| Mistral Large | 71.3 | 49.2 | 34.9 | 14.4 | 8.7 | - | - | - | - | - | - | - |
| Mistral Nemo | 19.0 | 14.4 | 9.7 | 7.7 | 3.1 | - | - | - | - | - | - | - |
🔼 This table presents the overall accuracy results for the Multi-Threading task. The task involves evaluating the models’ ability to simultaneously retrieve the final values from multiple threads, where each thread is a sequence of linked pieces of information. The results are broken down by model, context length (in thousands of LLaMA 3.1 tokens), and thread length. The accuracy represents the percentage of correctly retrieved values. The table allows comparison of model performance across various context lengths and shows how the models perform under the added complexity of multiple concurrent threads.
read the caption
Table 7: Multi-Threading overall results.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Gemini 1.5 Flash | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Jamba 1.5 Large | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 1 | - | - | - |
| Jamba 1.5 Mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 1 | - | - | - |
| Claude 3.5 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Haiku | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| GPT-4o | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| GPT-4o mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Reka Core | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Reka Flash | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| LLaMA 3.1 8b | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| LLaMA 3.1 70b | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| LLaMA 3.1 405b | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Gemini 1.0 Pro | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
| Mistral Large | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
| Mistral Nemo | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
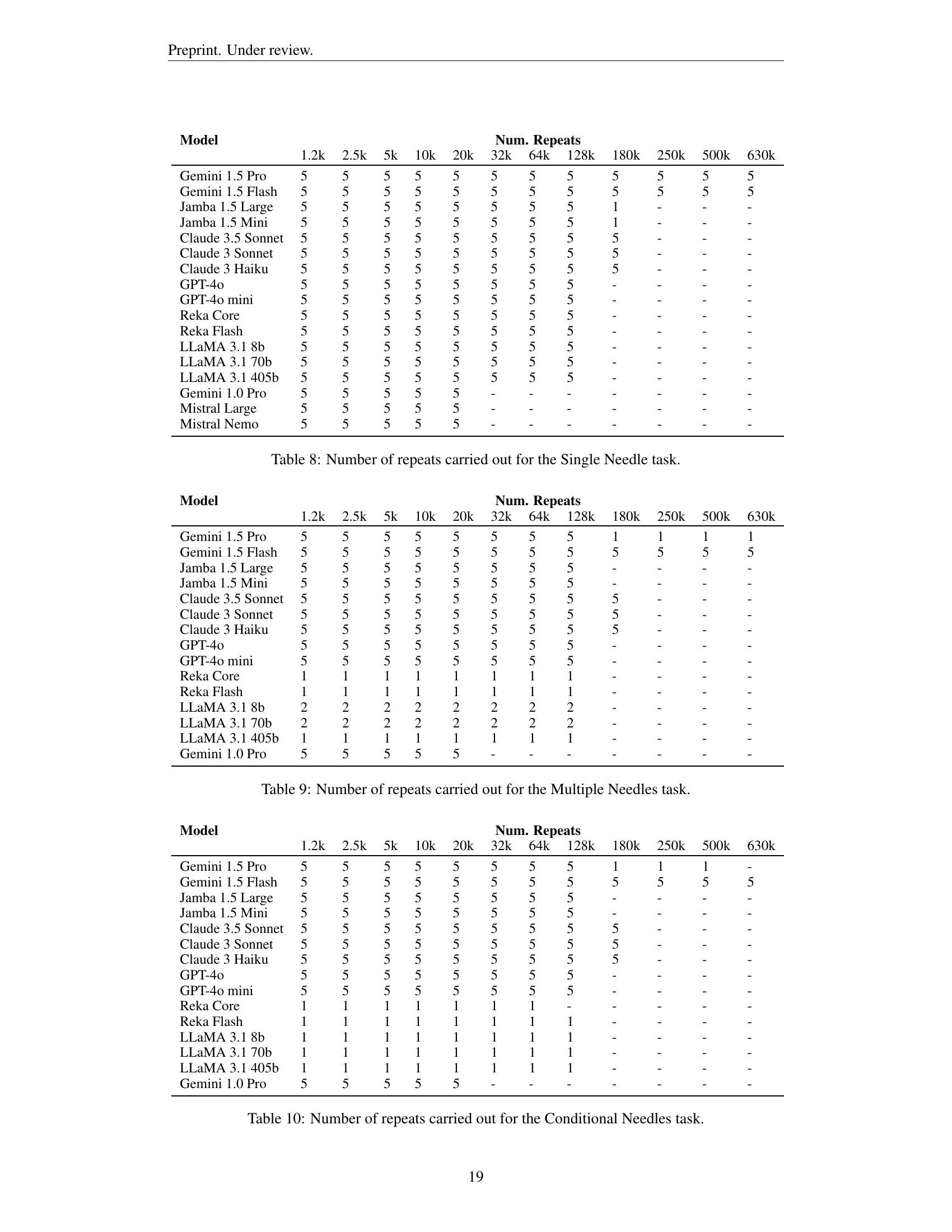
🔼 This table details the number of times each experiment was repeated for the Single Needle task. The rows represent the different Large Language Models (LLMs) tested, and the columns indicate the number of repeats for each context size (measured in thousands of LLaMA 3.1 tokens). The context sizes range from 1.2k to 630k tokens.
read the caption
Table 8: Number of repeats carried out for the Single Needle task.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 1 | 1 | 1 | 1 |
| Gemini 1.5 Flash | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Jamba 1.5 Large | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Jamba 1.5 Mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Claude 3.5 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Haiku | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| GPT-4o | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| GPT-4o mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Reka Core | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Reka Flash | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 8b | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | - | - | - | - |
| LLaMA 3.1 70b | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | - | - | - | - |
| LLaMA 3.1 405b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Gemini 1.0 Pro | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
🔼 This table details the number of times each experiment was repeated for the Multiple Needles task in the study. It shows how many repetitions were performed for each model at various context lengths (1.2k, 2.5k, 5k, 10k, 20k, 32k, 64k, 128k, 180k, 250k, 500k, and 630k tokens). The number of repetitions varies depending on the model and context length, often due to cost and API limitations.
read the caption
Table 9: Number of repeats carried out for the Multiple Needles task.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 1 | 1 | 1 | - |
| Gemini 1.5 Flash | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Jamba 1.5 Large | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Jamba 1.5 Mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Claude 3.5 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Haiku | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| GPT-4o | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| GPT-4o mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Reka Core | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - | - |
| Reka Flash | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 8b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 70b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 405b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Gemini 1.0 Pro | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
🔼 This table details the number of times each experiment was repeated for the Conditional Needles task across various context lengths and models. The number of repeats may vary depending on the model and context length due to limitations in API access or cost constraints.
read the caption
Table 10: Number of repeats carried out for the Conditional Needles task.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Gemini 1.5 Flash | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Jamba 1.5 Large | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Jamba 1.5 Mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Claude 3.5 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| Claude 3 Haiku | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| GPT-4o | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| GPT-4o mini | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - | - |
| Reka Core | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - | - |
| Reka Flash | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 8b | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | - | - | - | - |
| LLaMA 3.1 70b | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | - | - | - | - |
| LLaMA 3.1 405b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Gemini 1.0 Pro | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
| Mistral Large | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
| Mistral Nemo | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
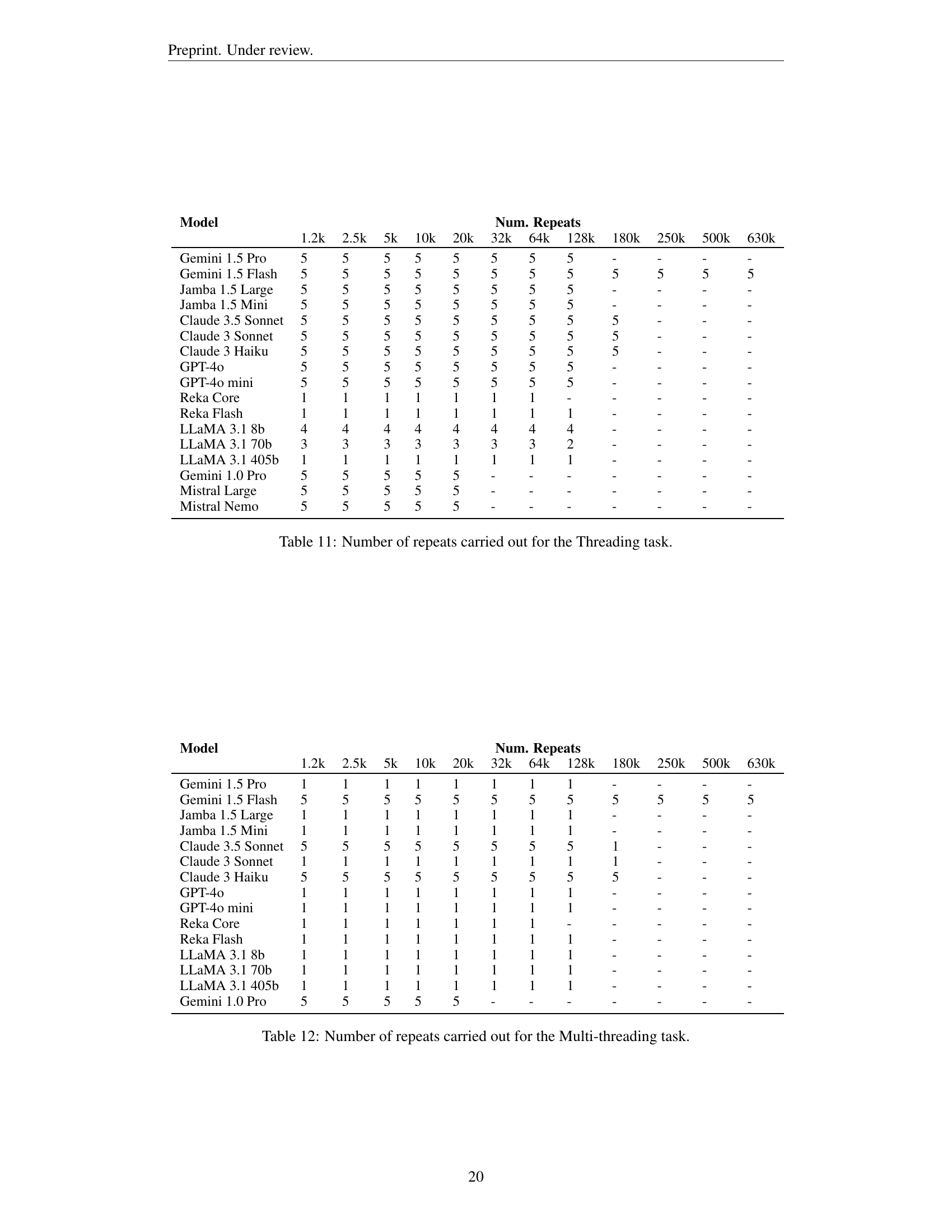
🔼 This table details the number of times each experiment was repeated for the Threading task, categorized by model and context length (in thousands of LLAMA 3.1 tokens). The context lengths are 1.2k, 2.5k, 5k, 10k, 20k, 32k, 64k, 128k, 180k, 250k, 500k, and 630k. The number of repeats for each model and context length reflects the constraints of the experiment, with some models and longer contexts having fewer repeats due to resource limitations.
read the caption
Table 11: Number of repeats carried out for the Threading task.
| Model | 1.2k | 2.5k | 5k | 10k | 20k | 32k | 64k | 128k | 180k | 250k | 500k | 630k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 1.5 Pro | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Gemini 1.5 Flash | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Jamba 1.5 Large | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Jamba 1.5 Mini | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Claude 3.5 Sonnet | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 1 | - | - | - |
| Claude 3 Sonnet | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - |
| Claude 3 Haiku | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | - | - | - |
| GPT-4o | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| GPT-4o mini | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Reka Core | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - | - |
| Reka Flash | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 8b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 70b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| LLaMA 3.1 405b | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | - | - | - | - |
| Gemini 1.0 Pro | 5 | 5 | 5 | 5 | 5 | - | - | - | - | - | - | - |
🔼 This table details the number of times each experiment was repeated for the multi-threading task across different models and context lengths. The number of repeats varies depending on model and context length due to cost and API limitations.
read the caption
Table 12: Number of repeats carried out for the Multi-threading task.
Full paper#