TL;DR#
Technical debt (TD) detection traditionally relies heavily on textual cues like comments, but these can be outdated or inconsistent with the code. This paper addresses this limitation by focusing on a novel approach that integrates both comments and the associated source code. This is challenging because analyzing large codebases is computationally expensive and requires sophisticated methods. Existing datasets also lack this crucial code context.
The paper presents TESORO, a new dataset created using a pipeline that extracts self-admitted TD comments, links them to relevant code snippets, and has these annotations verified by human annotators. It then uses various machine learning models to demonstrate that incorporating code context greatly improves the accuracy of TD detection. Furthermore, the study investigates the effectiveness of different models for detecting TD directly from code, without relying on comments.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers because it introduces a novel dataset, TESORO, which is the first to combine self-admitted technical debt comments with their corresponding source code. This allows for more accurate and comprehensive analysis of technical debt and opens new avenues for research in this field. It also presents a comprehensive pipeline for data enrichment, enabling researchers to efficiently create similar datasets for different programming languages and software systems. The empirical evaluations using various machine learning models demonstrate that the dataset improves the performance of technical debt detection methods.
Visual Insights#

🔼 The Tesoro dataset creation pipeline consists of four main stages: 1. Code parsing: Java files from the Stack corpus are parsed to extract functions and associated comments. 2. SATD detection: A pre-trained classifier identifies comments potentially containing self-admitted technical debt (SATD). 3. Sampling: An algorithm selects high-quality samples for annotation, balancing informative examples and instances with high uncertainty scores. 4. Annotation: Human annotators classify selected comments and their corresponding source code snippets into specific technical debt categories (design, defect, documentation, requirement/implementation, testing). The output of the pipeline is the Tesoro dataset, containing labeled SATD comments and their associated source code, which can be used to train and evaluate models for detecting technical debt in Java source code.
read the caption
Figure 1: An Overview of the Tesoro Creation Pipeline.
In-depth insights#
Enriched TD Dataset#
The concept of an ‘Enriched TD Dataset’ for improving technical debt (TD) detection in Java source code is crucial for advancing research in this field. A simple dataset of comments alone is insufficient; an enriched dataset would integrate source code alongside self-admitted technical debt (SATD) comments, providing a richer context for analysis. This integration would allow researchers to move beyond relying solely on textual cues, which are often outdated or inaccurate, to identify deeper underlying code issues that constitute technical debt. The enrichment would provide a more robust and comprehensive representation of technical debt, enabling more accurate and effective machine learning models for TD detection and classification. Furthermore, an enriched dataset could facilitate more in-depth analysis of the relationship between comments and the corresponding code, revealing patterns and insights that might otherwise remain hidden. This would ultimately lead to better tools and strategies for managing technical debt and improving the quality of software development processes.
SATD Detection Tool#
The effectiveness of a SATD detection tool hinges on its ability to accurately identify comments containing technical debt. High precision is crucial to avoid overwhelming human annotators with false positives, thus optimizing labeling efficiency. The choice of model architecture (e.g., RoBERTa) and training data (e.g., Maldonado-62K dataset) significantly influence the tool’s performance. Fine-tuning parameters require careful consideration to balance speed and accuracy. The tool’s success directly impacts the downstream sampling strategy, affecting the overall quality and representativeness of the curated dataset. Therefore, rigorous evaluation and iterative refinement of the SATD detection tool are vital for ensuring a high-quality dataset for future research. Developing a robust tool is key to efficient data creation for SATD studies.
Code Context Impact#
The study explores how incorporating source code context surrounding comments impacts the accuracy of technical debt (TD) detection. Different integration techniques were tested, including simple string concatenation and attention mechanisms that weight the relevance of code tokens to comment tokens. The results reveal that including code context significantly improves performance across various models, demonstrating the value of multi-modal approaches. The optimal code context length wasn’t a fixed number; rather, the effectiveness depended on the model, with experiments showing that using either a concise surrounding code segment or the entire function provided benefits. An ensemble approach, combining predictions from models trained with various code context lengths, achieved the highest accuracy, indicating that leveraging both local and global code context is crucial. This highlights the need for future research exploring diverse methods to integrate code and comment data effectively for superior TD detection.
PLM Model Accuracy#
Analyzing the accuracy of various Pre-trained Language Models (PLMs) in detecting technical debt reveals significant discrepancies in performance. While some models, particularly those specifically trained on code (code-based PLMs), demonstrate relatively high accuracy, others, especially those primarily trained on natural language text (NL-based PLMs), show significantly lower performance. This suggests that the architecture and training data of the PLM are crucial factors influencing its ability to accurately identify and classify technical debt within source code. Furthermore, the integration method used to combine source code and comments with PLM input also plays a key role. Simply concatenating the text data may not capture the nuanced relationship between code and comments as effectively as methods which employ attention mechanisms to weight the importance of each part of the input. Therefore, selecting the most appropriate PLM architecture and input processing method is critical for optimizing the accuracy of technical debt detection.
Future Research#
Future research directions stemming from this work on technical debt detection could significantly enhance the field. Expanding the dataset to encompass a wider array of programming languages beyond Java is crucial for broader applicability. Further investigation into the effectiveness of various deep learning models, particularly exploring advanced architectures like LLMs and their potential in accurately identifying technical debt directly from source code, is warranted. Improving the integration techniques for combining source code and comment data could yield even more precise detection. This might involve exploring more sophisticated attention mechanisms or novel methods of data fusion. A key area for future work is developing more robust and efficient methods for dealing with the inherent class imbalance problem often found in technical debt datasets. Investigating techniques such as data augmentation or cost-sensitive learning could prove beneficial. Finally, evaluating the long-term implications of incorporating detected technical debt into software development lifecycle processes and measuring the impact on software quality and maintainability is needed to solidify the practical applications of this research.
More visual insights#
More on figures

🔼 The figure illustrates how comments and functions are extracted from Java source code. It shows a Java code snippet with several comments, some single-line and some multi-line. The process involves parsing the code to identify function blocks and associating any comments located within or immediately preceding those blocks with the corresponding function. This is crucial for associating technical debt, which might be indicated in comments, with the relevant parts of the code.
read the caption
Figure 2: Extraction of comments and functions.

🔼 This figure shows the overlap ratios between categories predicted by multiple binary classifiers for a single comment. Each classifier is trained to identify a specific type of technical debt (TD). The figure helps visualize which TD types tend to be confused or predicted together by the models, providing insights into the complexities and ambiguities in classifying comments into various TD categories.
read the caption
Figure 3: Overlap categories ratio from multiple binary classifiers prediction on a comment.

🔼 This figure displays the distribution of technical debt (TD) categories in the TESOROcomment dataset. The left panel shows the proportion of each TD type (Design, Implementation, Defect, Test, Documentation) within comments that have been identified as containing self-admitted technical debt (SATD). The right panel presents the overall distribution of comments in the dataset, highlighting the percentage of comments containing SATD versus those without SATD. This provides a comprehensive overview of the dataset’s composition and the prevalence of SATD.
read the caption
Figure 4: Category distribution in Tesorocomment. Left: distribution of TD categories within comments containing SATD. Right: percentage of comments that contain versus those that do not contain SATD.

🔼 This figure presents a statistical overview of the TESOROcode dataset, focusing on the distribution of comments and technical debt (TD) types within the functions. The left panel displays the distribution of the number of comments per function, showing the frequency of functions containing different numbers of comments. The right panel illustrates the distribution of the number of TD types per function, revealing the frequency of functions containing various combinations of TD types. Together, these visualizations provide insights into the dataset’s characteristics, such as the average number of comments per function and the complexity of TD instances within each function.
read the caption
Figure 5: Statistics of Tesorocode. Left: Distribution of the number of comments per function. Right: Distribution of the number of TD types within a function.

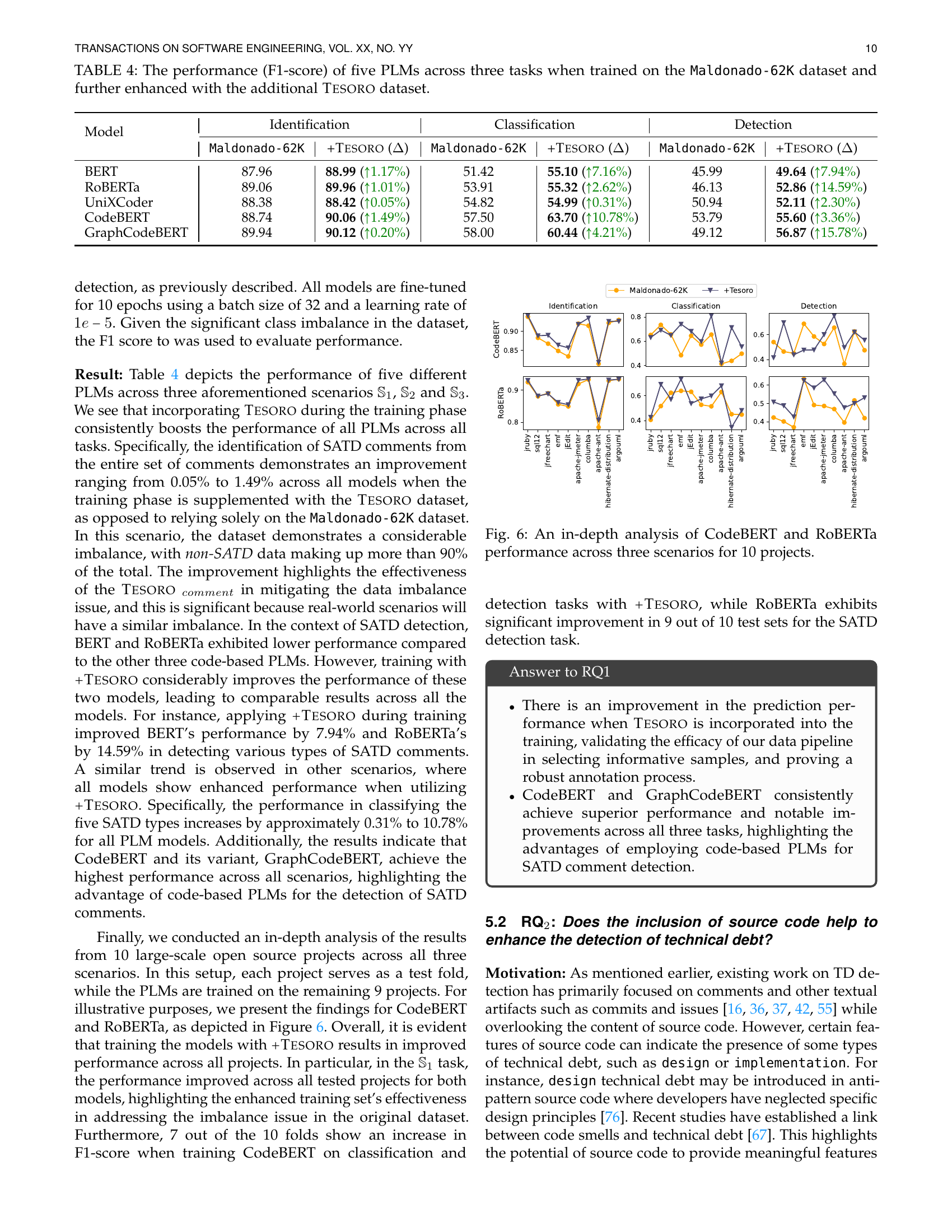
🔼 This figure presents a detailed comparison of CodeBERT and RoBERTa model performance across three different tasks (SATD identification, classification, and detection) when evaluated on ten distinct open-source projects. Each project serves as a separate test set, and the models are trained on the remaining nine. The graph visually represents the F1-score achieved by each model on each task for each project, allowing for a direct comparison of their performance under various conditions and highlighting relative strengths and weaknesses.
read the caption
Figure 6: An in-depth analysis of CodeBERT and RoBERTa performance across three scenarios for 10 projects.

🔼 Figure 7 illustrates the F1-scores achieved by various pretrained language models (PLMs) when tasked with identifying technical debt solely from Java source code. The models are categorized into three groups based on their architecture: encoder-based, encoder-decoder-based, and decoder-based. The x-axis represents the model size (in billions of parameters), and the y-axis shows the F1-score, a measure of the model’s performance. Different symbols distinguish between natural language (NL)-based PLMs and code-based PLMs. This visualization allows for comparison of model performance across varying architectures and scales, providing insights into the effectiveness of different approaches for detecting technical debt directly from code.
read the caption
Figure 7: F1-score of various PLMs on Tesorocode across different model sizes, types, and pretraining datasets. ◆◆\blacklozenge◆ denotes NL-based PLMs; \filledstar\filledstar\filledstar represents code-based PLMs.
Full paper#