↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating high-quality, decomposable 3D characters from single images is challenging due to issues like occlusion and inconsistent interactions between components. Existing methods often struggle with limited decomposability, unsatisfactory quality, and long optimization times. They either focus on realistic human models or produce non-decomposable avatars, hindering usability.
StdGEN tackles this by introducing a novel pipeline featuring a Semantic-aware Large Reconstruction Model (S-LRM). This model efficiently reconstructs geometry, color, and semantics from multi-view images (generated from a single image via diffusion), allowing for the extraction of decomposed 3D surfaces. Further, an iterative multi-layer mesh refinement process enhances quality. Experiments demonstrate state-of-the-art performance, surpassing existing baselines in terms of geometry, texture, and decomposability. The decomposable nature of the generated characters enhances usability for various applications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient method for generating high-quality, semantically decomposed 3D characters from single images. This addresses a key challenge in 3D character creation, enabling easier editing, animation, and broader applications in various fields. The introduction of the Semantic-aware Large Reconstruction Model (S-LRM) and the multi-layer refinement method are significant contributions with the potential to influence future research in 3D generation and related areas.
Visual Insights#

🔼 This figure showcases the capabilities of the StdGEN model by presenting multiple 3D characters generated from single 2D reference images. The 3D models are high-quality and semantically decomposed, meaning that individual components like the body, clothes, and hair are separated. This decomposition is a key feature of StdGEN, facilitating easier editing and animation.
read the caption
Figure 1: Our StdGEN generates high-quality, decomposed 3D characters from a single reference image.
| A-pose Conditioned Input | Arbitrary-pose Conditioned Input | |||||||
|---|---|---|---|---|---|---|---|---|
| SSIM↑ | LPIPS↓ | FID↓ | CLIP Similarity↑ | SSIM↑ | LPIPS↓ | FID↓ | CLIP Similarity↑ | |
| 2D Multi-view Comparisons | 2D Multi-view Comparisons | |||||||
| SyncDreamer [31] | 0.870 | 0.183 | 0.223 | 0.864 | 0.845 | 0.217 | 0.328 | 0.839 |
| Zero-1-to-3 [29] | 0.865 | 0.172 | 0.500 | 0.885 | 0.842 | 0.209 | 0.481 | 0.878 |
| Era3D [26] | 0.876 | 0.144 | 0.095 | 0.908 | 0.842 | 0.195 | 0.094 | 0.900 |
| CharacterGen [40] | 0.886 | 0.119 | 0.063 | 0.928 | 0.871 | 0.139 | 0.056 | 0.919 |
| Ours | 0.958 | 0.038 | 0.004 | 0.941 | 0.920 | 0.071 | 0.014 | 0.935 |
| 3D Character Comparisons | 3D Character Comparisons | |||||||
| Magic123 [43] | 0.886 | 0.142 | 0.192 | 0.887 | 0.849 | 0.197 | 0.256 | 0.862 |
| ImageDream [60] | 0.856 | 0.171 | 0.846 | 0.836 | 0.823 | 0.218 | 0.875 | 0.818 |
| OpenLRM [14] | 0.889 | 0.151 | 0.406 | 0.878 | 0.863 | 0.191 | 0.707 | 0.844 |
| LGM [55] | 0.876 | 0.151 | 0.282 | 0.902 | 0.838 | 0.203 | 0.480 | 0.884 |
| InstantMesh [66] | 0.888 | 0.126 | 0.107 | 0.906 | 0.846 | 0.202 | 0.285 | 0.886 |
| Unique3D [65] | 0.889 | 0.136 | 0.030 | 0.919 | 0.856 | 0.190 | 0.042 | 0.903 |
| CharacterGen [40] | 0.880 | 0.124 | 0.081 | 0.905 | 0.869 | 0.134 | 0.119 | 0.901 |
| Ours | 0.937 | 0.066 | 0.010 | 0.941 | 0.916 | 0.084 | 0.011 | 0.936 |
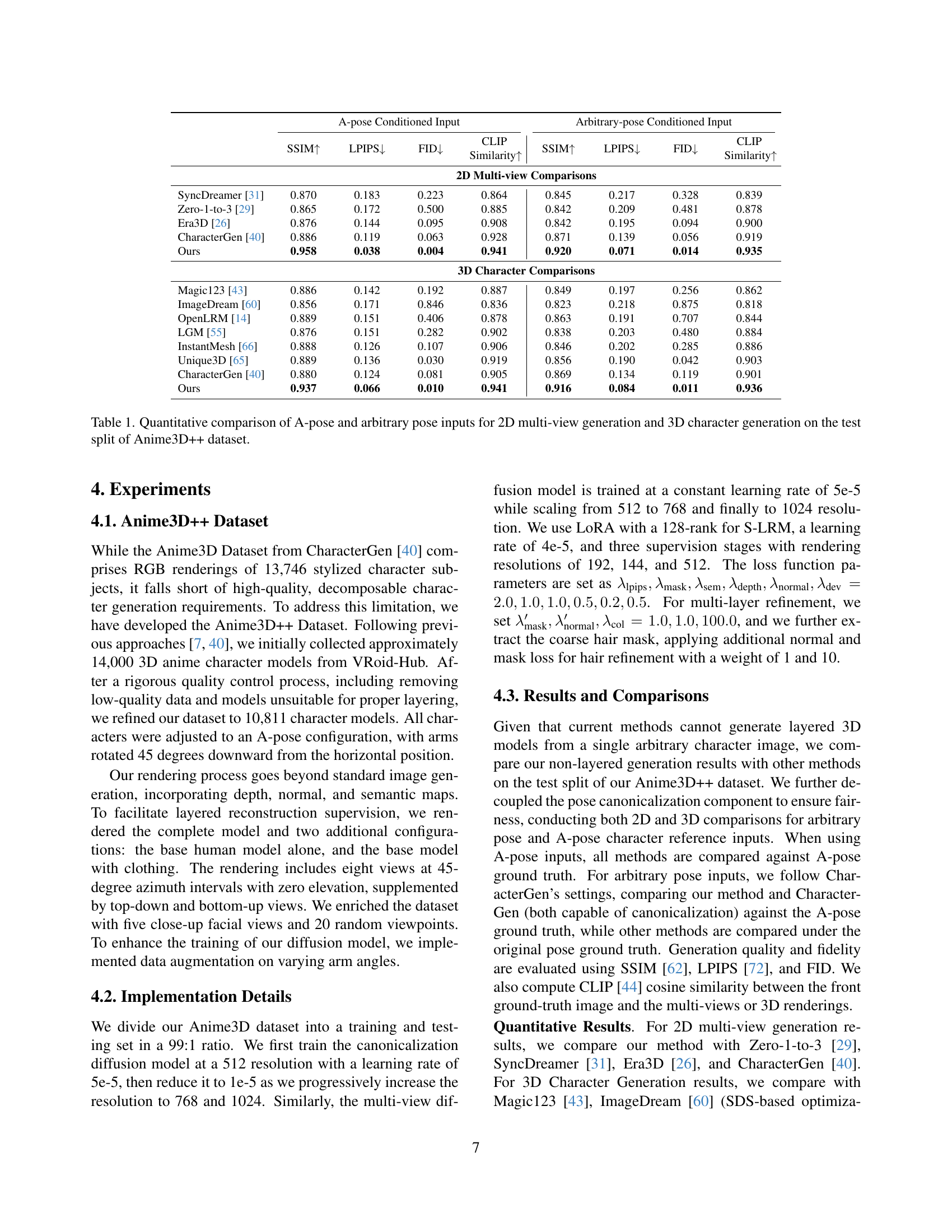
🔼 Table 1 presents a quantitative comparison of the performance of different methods for generating 2D multi-view images and 3D characters from both A-pose and arbitrary pose input images. The comparison uses metrics like SSIM, LPIPS, FID, and CLIP similarity to evaluate the quality and fidelity of the generated outputs. The results are shown for both 2D and 3D generation tasks, and are broken down by input pose type (A-pose vs. arbitrary pose). The Anime3D++ dataset is used for the evaluation.
read the caption
Table 1: Quantitative comparison of A-pose and arbitrary pose inputs for 2D multi-view generation and 3D character generation on the test split of Anime3D++ dataset.
In-depth insights#
Semantic Decomposition#
Semantic decomposition, in the context of 3D character generation, is a crucial technique for enhancing the usability and flexibility of generated models. It involves separating a 3D character into distinct semantic components such as body, clothing, and hair, which are then individually represented and manipulated. This disentanglement offers several key advantages: Firstly, it significantly simplifies the editing process, allowing for precise modifications to specific parts without affecting others. Secondly, it enables more realistic and nuanced animation by facilitating independent control over the movement and deformation of each component. Thirdly, it unlocks new possibilities for content creation by enabling the recombination of individual components to create novel character designs. However, achieving effective semantic decomposition presents significant challenges. Existing methods often struggle with occlusion, ambiguity, and inconsistent interactions between components, leading to unsatisfactory results. The successful approach described in the paper tackles these issues by introducing a novel Semantic-aware Large Reconstruction Model (S-LRM). This model jointly reconstructs geometry, color, and semantics from multi-view images, enabling a differentiable multi-layer semantic surface extraction. This approach is highlighted as superior because it produces high-quality, decomposable 3D character models from single images. By effectively disentangling the semantic parts, this method offers significant improvements over previous techniques for various downstream applications, allowing for more efficient and creative character design and animation.
Multi-view Diffusion#
Multi-view diffusion models represent a significant advancement in 3D character generation by addressing the limitations of single-view methods. They leverage the power of diffusion models to generate multiple consistent views of a 3D object from a single input image. This is crucial because it provides rich information about the object’s geometry, texture, and lighting conditions from various angles, which is often missing from single-view data. This richness is particularly critical for generating complex objects like 3D characters, where occlusion and intricate details are common. The multi-view approach allows the model to learn a deeper understanding of 3D structure, leading to more accurate and realistic 3D reconstructions. Furthermore, the inherent ability of diffusion models to generate diverse and high-quality samples enhances the quality and realism of the generated 3D models. Consistency across different views is key; this is ensured through clever techniques within the model’s architecture. However, challenges still exist. Generating high-resolution multi-view images can be computationally expensive and requires significant memory resources. The training process is complex and often requires extensive datasets and careful hyperparameter tuning. Despite these challenges, multi-view diffusion techniques are a promising avenue for producing high-quality and detailed 3D characters from limited input data. The resulting models are well-suited for applications requiring a rich representation of 3D scenes such as virtual reality, gaming, and animation.
S-LRM Architecture#
The Semantic-aware Large Reconstruction Model (S-LRM) architecture is a crucial component, designed for efficient and effective reconstruction of 3D characters from multi-view images. Its core innovation lies in the integration of semantic attributes into a Large Reconstruction Model (LRM) framework, enabling the simultaneous reconstruction of geometry, color, and semantics. This differs from traditional LRMs that primarily focus on geometry and appearance. The use of a transformer-based architecture allows for the effective processing of multi-view image data, capturing contextual information and dependencies between different views. A differentiable multi-layer semantic surface extraction scheme is a key feature, enabling the separation of semantic components (body, clothes, hair) for easier editing and animation. This process uses a combination of NeRF and SDF representations, modified to handle semantic information, effectively enabling the system to extract meaningful parts. The model’s ability to jointly learn and reconstruct these features in a feed-forward manner is a significant improvement in efficiency compared to iterative optimization methods. The use of LoRA for efficient parameter adaptation makes the model more effective for training while keeping resource consumption down. The incorporation of these methods enhances the quality, decomposability, and efficiency of 3D character generation.
Mesh Refinement#
Mesh refinement in 3D character generation from a single image is crucial for achieving high-quality, detailed models. The process often involves iterative optimization techniques to enhance the mesh’s geometry and texture. Multi-layer refinement, as explored in StdGen, is particularly effective for decomposable characters, allowing for separate refinement of different semantic parts like clothing and hair. This approach avoids conflicts and inconsistencies during optimization. Differentiable surface extraction directly integrates into the optimization process, enabling smooth and efficient refinement of complex details. The effectiveness of the refinement process is further enhanced by the use of high-resolution multi-view RGBs and normals generated via a diffusion model. These provide accurate guidance for adjusting vertex positions and normals, producing realistic surface textures. Additionally, techniques like collision loss and explicit target optimization help to address common issues such as self-intersections and inconsistencies in mesh structure. The overall goal is to move beyond simple, coarse meshes towards intricate and accurate 3D representations, suitable for various downstream applications like animation and virtual reality.
Ablation Experiments#
Ablation experiments systematically remove components or features of a model to assess their individual contributions. In the context of a 3D character generation model, this might involve disabling specific modules, such as the semantic decomposition module, the multi-view diffusion model, or the multi-layer refinement module. By comparing the performance of the full model to variations with components removed, researchers can precisely identify the impact of each feature. A well-designed ablation study will reveal which components are critical for overall performance, which are less important, and potentially which components might be redundant or even detrimental. Key metrics to assess would include the quality of the generated meshes (geometric accuracy, texture detail), the speed of generation, and the degree of semantic decomposition. Analyzing the results across these metrics can reveal unexpected interactions between components. For instance, removing the semantic decomposition module might drastically reduce the quality of the output while simultaneously speeding up the generation process, implying a trade-off between detail and efficiency. A thoughtful ablation study provides valuable insights for model optimization and future development. It highlights areas for improvement, allowing developers to focus resources on the most crucial components and suggests potential avenues for simplifying the model without compromising performance. The results can also help to explain the underlying mechanisms of the model, revealing which parts are responsible for specific aspects of the generated output, providing evidence of its overall effectiveness.
More visual insights#
More on figures

🔼 StdGEN pipeline starts with a single reference image. A diffusion model generates multiple views (RGB and normal maps) of the image in a canonical A-pose. This is fed into the Semantic-aware Large Reconstruction Model (S-LRM), which outputs color, density, and semantic field data for 3D reconstruction. The model then performs semantic decomposition to separate parts like body, clothes, and hair. Finally, a multi-layer refinement process refines the mesh quality to produce the final, high-quality, decomposed 3D character model.
read the caption
Figure 2: The overview of our StdGEN pipeline. Starting from a single reference image, our method utilizes diffusion models to generate multi-view RGB and normal maps, followed by S-LRM to obtain the color/density and semantic field for 3D reconstruction. Semantic decomposition and part-wise refinement are then applied to produce the final result.

🔼 This figure illustrates the architecture and data flow of the Semantic-aware Large Reconstruction Model (S-LRM). The model takes image tokens as input, processes them through a Vision Transformer (ViT) encoder and a tri-plane decoder. The decoder then generates tri-plane tokens, which are further processed to create geometry, color, and semantic information. The figure highlights the intermediate outputs at various stages of the process, showing how these individual components are combined to reconstruct a 3D character with semantically distinct parts. The use of LoRA (Low-Rank Adaptation) for efficient training is also shown.
read the caption
Figure 3: Demonstration of the structure and intermediate outputs of our semantic-aware large reconstruction model (S-LRM).

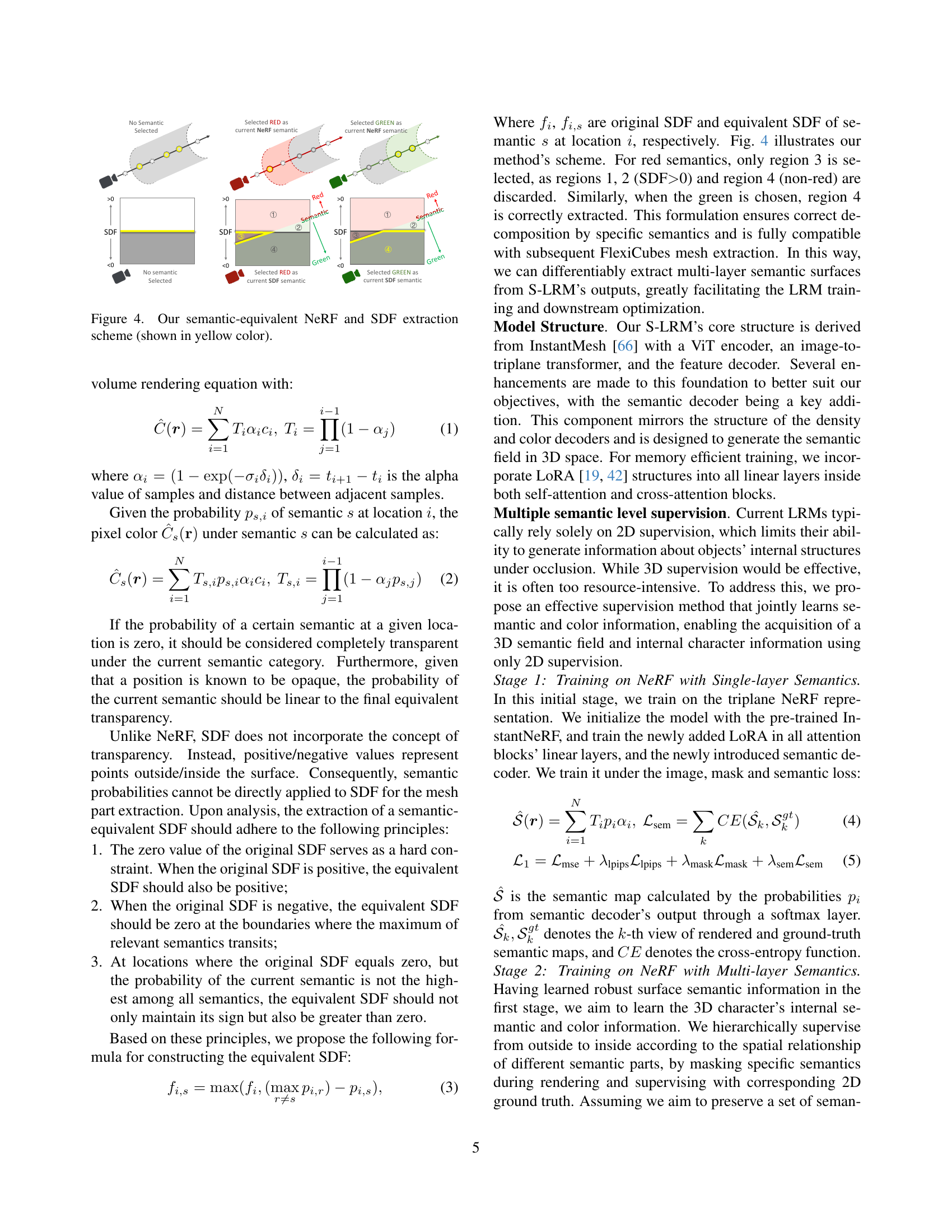
🔼 This figure illustrates the process of extracting semantic information from both Neural Radiance Fields (NeRF) and Signed Distance Fields (SDF) representations. It highlights how semantic probabilities are used to extract specific layers (such as ‘red’ and ‘green’ semantic layers shown in the example) from the combined NeRF and SDF representations, separating different semantic components in a differentiable manner. This ensures that individual semantic parts can be extracted from the implicit surface for high-quality, semantic-decomposed mesh generation.
read the caption
Figure 4: Our semantic-equivalent NeRF and SDF extraction scheme (shown in yellow color).

🔼 This figure presents a qualitative comparison of 3D character generation results from different methods. It visually demonstrates the differences in geometry and overall appearance of 3D characters produced by StdGEN (the proposed method), CharacterGen, Unique3D, and InstantMesh. The comparison highlights StdGEN’s superiority in generating high-quality, detailed 3D characters.
read the caption
Figure 5: Qualitative comparisons on geometry and appearance of generated 3D characters.

🔼 Figure 6 showcases the decomposable nature of the 3D character generation model. It presents the results in three parts: the texture view showing the appearance of the character with distinct components (body, clothing, hair), a mesh view highlighting the geometric structure of the separated components and their spatial relationships, and cross-sectional views providing insights into the internal structure of the generated components. This visual representation demonstrates the model’s ability to generate intricately detailed and semantically decomposed 3D characters.
read the caption
Figure 6: Decomposed outputs of our method, presented in texture, mesh, and cross-section.

🔼 This ablation study compares the results of StdGEN with and without semantic decomposition. The leftmost image shows a 3D character generated without decomposition. Note the fusion of hair, clothing, and body, highlighting the limitations of this approach. The rightmost image shows a character generated using semantic decomposition; individual components (body, clothes, hair) are distinctly separated. This demonstrates the effectiveness of semantic decomposition in generating high-quality and easily editable 3D characters. The visualization clearly shows that separate parts maintain high geometric fidelity without visual artifacts or intersections.
read the caption
Figure 7: Ablation study on character decomposition.

🔼 Figure 8 shows the results of an ablation study on the multi-layer refinement process used in StdGEN. The left image displays the output of the S-LRM model before the refinement process, showing that while the model successfully decomposes the character into different parts, certain details and precision are lacking. The image on the right shows that the multi-layer refinement significantly improves the quality of the generated mesh and addresses the issues present in the original output. By zooming in on the images, one can appreciate the improvement in detail and accuracy that multi-layer refinement provides. This demonstrates the effectiveness of this stage in enhancing the overall quality of the 3D character generation.
read the caption
Figure 8: Ablation study on multi-layer refinement. Zoom in for better details.

🔼 This figure compares the rigging and animation capabilities of the proposed StdGEN method against the CharacterGen method. It visually demonstrates that StdGEN-generated 3D characters exhibit more realistic and natural-looking movements and physical behavior compared to those from CharacterGen. This difference is primarily attributed to StdGEN’s semantic decomposition, enabling easier editing and more accurate control of individual parts during rigging and animation. The improved accuracy in depicting physical characteristics, such as correct cloth deformation and realistic physics, highlights the superiority of StdGEN for applications requiring high-quality animations.
read the caption
Figure 9: Rigging and animation comparisons on 3D character generation. Our method demonstrates superior performance in human perception and physical characteristics.
Full paper#