↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods struggle with long, complex, multimodal documents. Humans take significant time to understand and answer questions about such documents. There’s a need for better automated methods.
The paper introduces M-LongDoc, a benchmark with 851 multimodal documents, each hundreds of pages long, requiring in-depth analysis. It proposes a novel retrieval-aware tuning framework that significantly improves open-source models for question answering about these documents. The automated evaluation avoids relying on human judges.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal document understanding. It introduces M-LongDoc, a new benchmark with long, complex documents, pushing the boundaries of current models. The retrieval-aware tuning framework offers a novel approach to improve model performance and addresses the challenges of lengthy documents and multimodal biases. This opens avenues for creating more robust and effective multimodal models, impacting various fields dealing with complex document analysis.
Visual Insights#

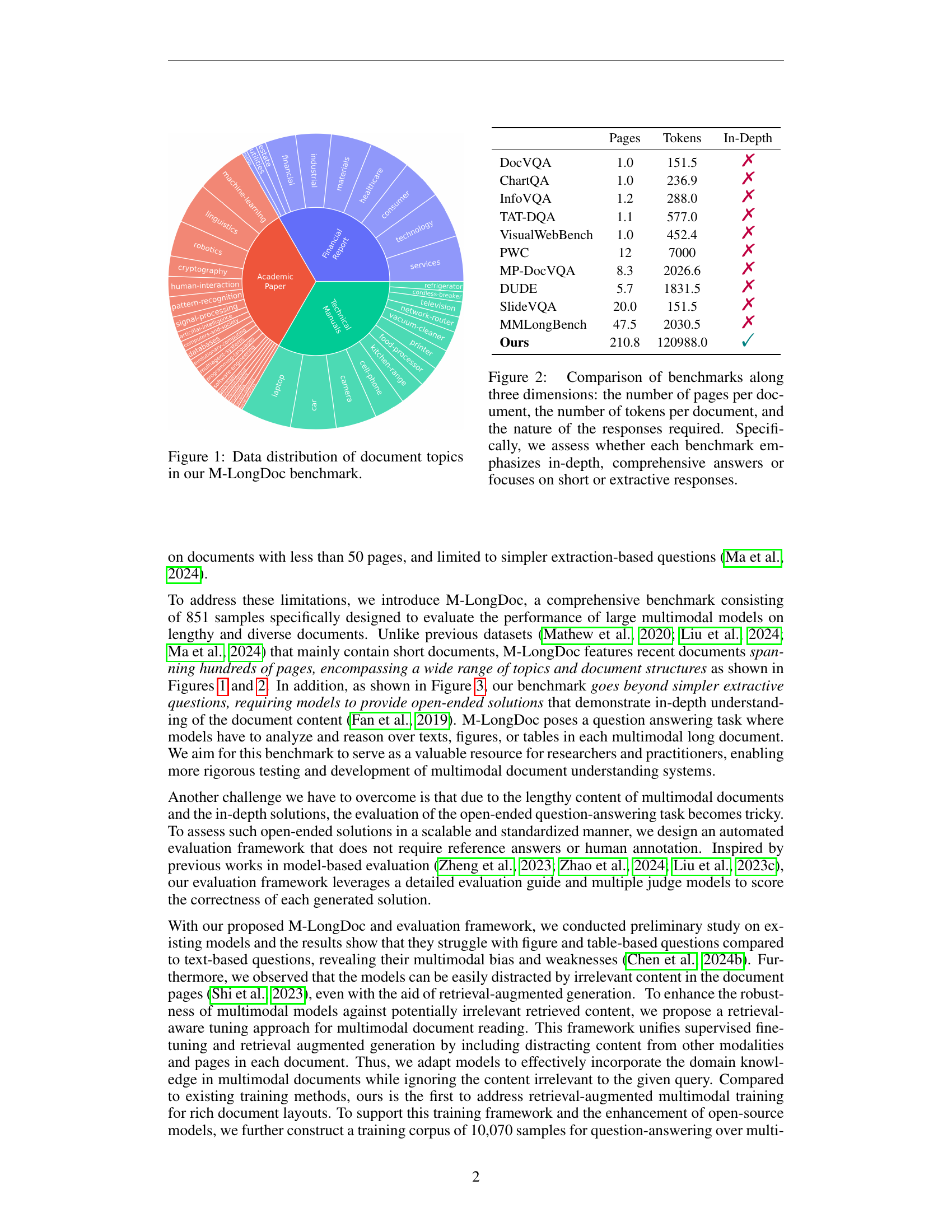
🔼 This figure shows the distribution of document topics within the M-LongDoc benchmark dataset. It visually represents the proportions of documents belonging to various categories or topics, providing an overview of the dataset’s diversity in terms of subject matter. The topics appear to be grouped into broader categories such as ‘Academic Papers’, ‘Technical Manuals’, and ‘Financial Reports,’ each with further subcategories. The size of each slice in the pie chart corresponds to the relative proportion of documents belonging to that specific topic within the entire M-LongDoc dataset.
read the caption
Figure 1: Data distribution of document topics in our M-LongDoc benchmark.
| Pages | Tokens | In-Depth | |
|---|---|---|---|
| DocVQA | 1.0 | 151.5 | ✗ |
| ChartQA | 1.0 | 236.9 | ✗ |
| InfoVQA | 1.2 | 288.0 | ✗ |
| TAT-DQA | 1.1 | 577.0 | ✗ |
| VisualWebBench | 1.0 | 452.4 | ✗ |
| PWC | 12 | 7000 | ✗ |
| MP-DocVQA | 8.3 | 2026.6 | ✗ |
| DUDE | 5.7 | 1831.5 | ✗ |
| SlideVQA | 20.0 | 151.5 | ✗ |
| MMLongBench | 47.5 | 2030.5 | ✗ |
| Ours | 210.8 | 120988.0 | ✓ |
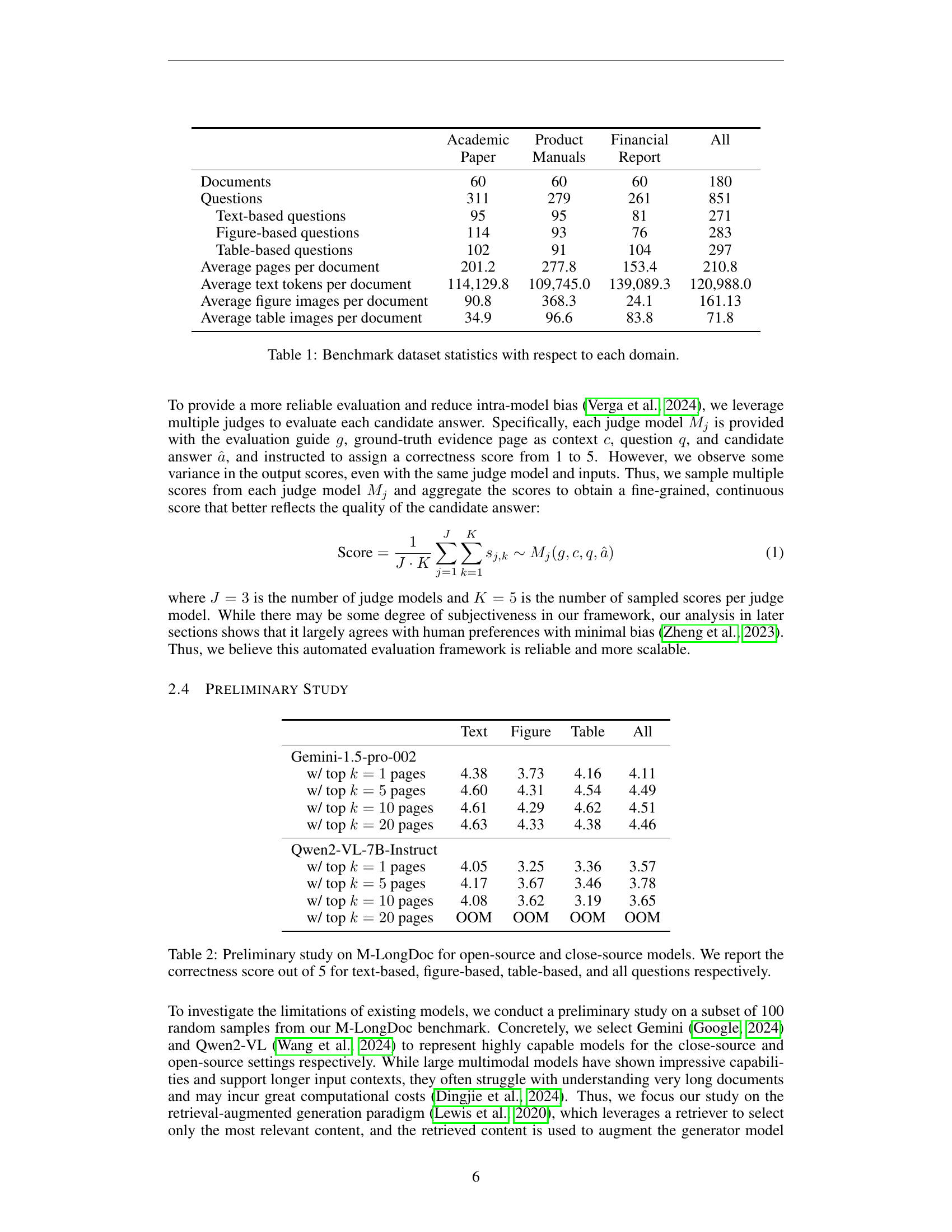
🔼 This table presents a quantitative overview of the M-LongDoc benchmark dataset, broken down by domain (Academic, Product, Financial). For each domain, it shows the number of documents, the total number of questions, a further breakdown of questions by type (text-based, figure-based, table-based), average number of pages per document, average number of text tokens per document, and the average number of figure and table images per document. This detailed breakdown allows for a comprehensive understanding of the dataset’s composition and characteristics across different domains.
read the caption
Table 1: Benchmark dataset statistics with respect to each domain.
In-depth insights#
Multimodal LongDocs#
The concept of “Multimodal LongDocs” points towards a significant advancement in document understanding. It suggests a move beyond traditional text-based analysis to encompass richer, more complex documents that integrate various modalities like text, images, tables, and figures. The “Long” aspect highlights the challenge of processing extensive documents, requiring methods capable of handling hundreds of pages. This necessitates innovative approaches to information retrieval and contextual understanding, moving beyond simple keyword searches towards more sophisticated semantic analysis. Efficient processing of these complex documents could revolutionize fields ranging from legal research and business intelligence to scientific literature review. A key focus would be on developing models robust enough to filter out irrelevant information, while still effectively extracting key insights from the diverse data sources. This is crucial given that the complexity and length of these documents inherently increase the risk of distracting content leading to reduced accuracy. Addressing this would involve advanced techniques in multimodal representation learning and potentially, fine-tuning models through retrieval-aware methods to prioritize relevant information. Ultimately, the successful development of such techniques would enable powerful tools with broad applications.
Retrieval-Aware Tuning#
Retrieval-aware tuning represents a significant advancement in multimodal document understanding. It directly addresses the challenges posed by the length and complexity of real-world documents, acknowledging that simply retrieving and presenting relevant content isn’t always sufficient. The core innovation lies in the training process. Instead of relying solely on perfectly curated gold-standard contexts, this approach incorporates both relevant and irrelevant information during training. This simulates the real-world scenario where models inevitably encounter distracting content. By exposing the model to both relevant and irrelevant information, it improves its ability to discern which aspects are essential for accurate comprehension, thereby enhancing its robustness and reducing the impact of noise. This method demonstrates a potential to greatly improve the accuracy and reliability of models compared to conventional retrieval-based strategies, potentially leading to more effective and robust document understanding systems. This approach is particularly valuable for open-ended questions, which require a more holistic understanding of the document, rather than just simple extractive answers.
Benchmark Analysis#
A robust benchmark analysis is crucial for evaluating the performance of multimodal models in understanding super-long documents. It should involve a multifaceted comparison against existing benchmarks, highlighting improvements in handling document length and complexity. Key aspects to consider include the diversity of document types (academic papers, financial reports, technical manuals), question types, and the evaluation metrics used. Open-ended questions should be prioritized over extractive ones to better assess in-depth understanding. The analysis needs to demonstrate scalability and reproducibility, addressing the computational cost and feasibility of applying the benchmark to a wide array of models. Furthermore, a rigorous analysis should reveal the model’s strengths and weaknesses in handling various modalities (text, tables, figures), pointing to areas for future improvement. Finally, statistical significance of the results must be ensured, and the limitations of the chosen methodology should be clearly articulated.
Automated Evaluation#
Automating the evaluation process for complex tasks like multimodal document understanding presents significant challenges but offers crucial advantages. A well-designed automated evaluation system should minimize human bias, which can be a significant factor in subjective assessments. It is crucial to define clear and measurable criteria for evaluation that align with the objectives of the study. Multiple judge models can be used to enhance the reliability and robustness of the automated evaluation by reducing dependence on individual model strengths and weaknesses. The automated system should be scalable to handle large datasets without compromising efficiency. Furthermore, the framework needs to account for the nuances of different multimodal data types and potential model biases, while maintaining a standardized approach to ensure consistent and comparable results. Transparency is also key—the methods employed for automated evaluation must be clearly documented and reproducible to allow others to verify and validate the findings.
Future Directions#
Future research directions in multimodal long document understanding should prioritize scalable and robust evaluation frameworks. Current methods struggle with the inherent complexity and subjectivity of assessing open-ended responses to nuanced questions. Automated evaluation techniques, potentially incorporating multiple judge models or advanced similarity metrics, are crucial. Furthermore, addressing the multimodal bias exhibited by current models, which often favor textual information over visual or tabular data, requires further investigation and possibly novel training methodologies. Retrieval-aware training, enhancing the ability of models to selectively utilize pertinent information while ignoring irrelevant content, offers significant potential but needs refinement. Finally, exploring more diverse and challenging datasets covering diverse domains and document types is key to unlocking a more comprehensive and realistic understanding of multimodal document comprehension. Future work should also explore efficient model architectures and training methods to address the computational demands of handling such extensive datasets.
More visual insights#
More on figures

🔼 Figure 2 compares various question answering benchmarks across three key aspects: the average number of pages per document, the average number of tokens per document, and the type of answer expected. It highlights whether a benchmark prioritizes detailed, comprehensive answers or is satisfied with shorter, more extractive answers. This helps to illustrate the varying levels of complexity and the types of reasoning skills required by different datasets.
read the caption
Figure 2: Comparison of benchmarks along three dimensions: the number of pages per document, the number of tokens per document, and the nature of the responses required. Specifically, we assess whether each benchmark emphasizes in-depth, comprehensive answers or focuses on short or extractive responses.

🔼 Figure 3 compares example questions from various multimodal document question answering benchmarks, including DocVQA and MMLongBench, highlighting the complexity difference. M-LongDoc questions demand explanatory answers encompassing both image and textual semantics, unlike others requiring simple extractive answers. The figure shows that, in the M-LongDoc benchmark setting, the model is given access to the entire document, not just the relevant page.
read the caption
Figure 3: Example questions in different multimodal document question answering benchmarks. For illustration, we include content from the relevant page in the original document. The example question from M-LongDoc is more complex than those from other benchmarks, as it requires an explanatory answer rather than an extraction of a short text span. Furthermore, it requires the model to understand the semantics of both image and text. Please note that in our benchmark setting, the model is provided with all page contents from the document, and not only the relevant page.

🔼 This figure details the semi-automated pipeline used to generate high-quality, challenging questions for the M-LongDoc benchmark. It starts with selecting a document page containing a specific content type (text, table, or figure). Multiple large language models then generate questions based on this page and its surrounding context. These questions undergo an automated verification process using a checklist to filter out unsuitable questions. Finally, human annotators perform a second verification step to ensure quality and relevance, resulting in a curated set of questions suitable for the benchmark. The checklist prompts shown are shortened; complete details can be found in Appendix A.1.
read the caption
Figure 4: Overview of our data construction process with question verification stages. For brevity, we shorten the checklist prompts and include the full details in Appendix A.1.

🔼 This figure illustrates the automated evaluation process used to assess the quality of open-ended responses generated by models for multimodal question answering tasks. The process involves multiple evaluation steps, including a thorough review of the provided multimodal document (text, figures, tables), comparison of the model’s response to the document’s information, and assessment of accuracy, comprehensiveness, and relevance to the question. Multiple judge models (e.g., large language models) are used to independently score the responses. These individual scores are then aggregated to provide a final, holistic correctness score for each response. The detailed evaluation guide used by the judge models is provided in Appendix A.3 of the paper.
read the caption
Figure 5: Our automated evaluation framework to assess the correctness of open-ended solutions for multimodal question answering. The full evaluation guide is included in Appendix A.3.
More on tables
| Academic | Product | Financial | All | |
|---|---|---|---|---|
| Paper | Manuals | Report | ||
| Documents | 60 | 60 | 60 | 180 |
| Questions | 311 | 279 | 261 | 851 |
| Text-based questions | 95 | 95 | 81 | 271 |
| Figure-based questions | 114 | 93 | 76 | 283 |
| Table-based questions | 102 | 91 | 104 | 297 |
| Average pages per document | 201.2 | 277.8 | 153.4 | 210.8 |
| Average text tokens per document | 114,129.8 | 109,745.0 | 139,089.3 | 120,988.0 |
| Average figure images per document | 90.8 | 368.3 | 24.1 | 161.13 |
| Average table images per document | 34.9 | 96.6 | 83.8 | 71.8 |
🔼 This table presents the results of a preliminary study conducted on the M-LongDoc benchmark, evaluating the performance of both open-source and closed-source models on various question types. The correctness scores, ranging from 1 to 5, are reported for text-based, figure-based, table-based, and all question types, providing a comprehensive assessment of each model’s strengths and weaknesses in handling different modalities within long documents.
read the caption
Table 2: Preliminary study on M-LongDoc for open-source and close-source models. We report the correctness score out of 5 for text-based, figure-based, table-based, and all questions respectively.
| Model | Text | Figure | Table | All |
|---|---|---|---|---|
| Gemini-1.5-pro-002 | ||||
| w/ top k=1 pages | 4.38 | 3.73 | 4.16 | 4.11 |
| w/ top k=5 pages | 4.60 | 4.31 | 4.54 | 4.49 |
| w/ top k=10 pages | 4.61 | 4.29 | 4.62 | 4.51 |
| w/ top k=20 pages | 4.63 | 4.33 | 4.38 | 4.46 |
| Qwen2-VL-7B-Instruct | ||||
| w/ top k=1 pages | 4.05 | 3.25 | 3.36 | 3.57 |
| w/ top k=5 pages | 4.17 | 3.67 | 3.46 | 3.78 |
| w/ top k=10 pages | 4.08 | 3.62 | 3.19 | 3.65 |
| w/ top k=20 pages | OOM | OOM | OOM | OOM |
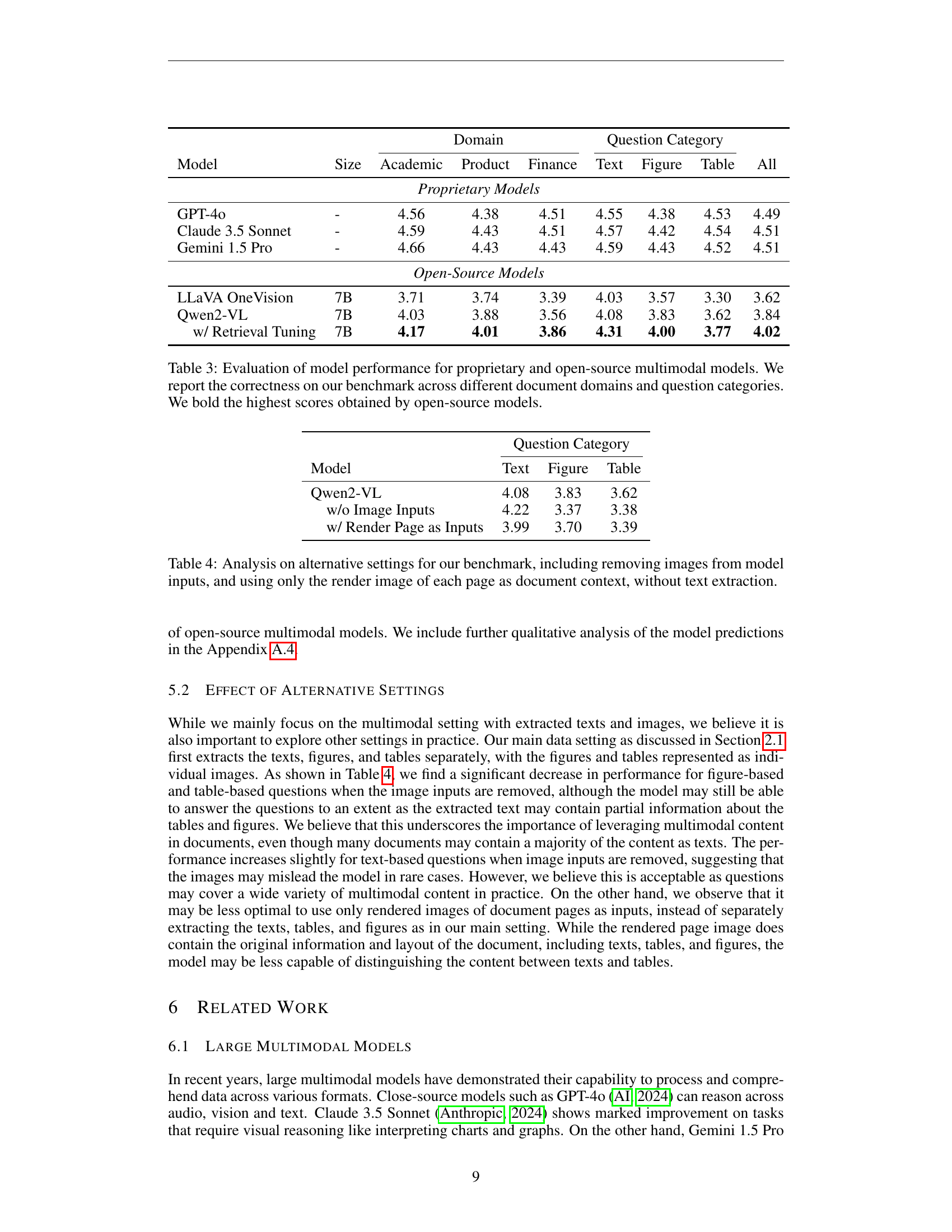
🔼 This table presents a comparative analysis of various proprietary and open-source multimodal models’ performance on a document question answering task. The evaluation is performed across three different domains (Academic, Product, Finance) and three question categories (Text, Figure, Table), reflecting the diverse nature of the questions and the multimodal documents. The ‘Correctness’ score, ranging from 1 to 5, indicates the accuracy and completeness of the model’s answers. The highest correctness scores achieved by open-source models are highlighted in bold, facilitating a direct comparison between the performance of these two types of models.
read the caption
Table 3: Evaluation of model performance for proprietary and open-source multimodal models. We report the correctness on our benchmark across different document domains and question categories. We bold the highest scores obtained by open-source models.
| Model | Size | Domain:Academic | Domain:Product | Domain:Finance | Question Category:Text | Question Category:Figure | Question Category:Table | Question Category:All |
|---|---|---|---|---|---|---|---|---|
| Proprietary Models | ||||||||
| GPT-4o | - | 4.56 | 4.38 | 4.51 | 4.55 | 4.38 | 4.53 | 4.49 |
| Claude 3.5 Sonnet | - | 4.59 | 4.43 | 4.51 | 4.57 | 4.42 | 4.54 | 4.51 |
| Gemini 1.5 Pro | - | 4.66 | 4.43 | 4.43 | 4.59 | 4.43 | 4.52 | 4.51 |
| Open-Source Models | ||||||||
| LLaVA OneVision | 7B | 3.71 | 3.74 | 3.39 | 4.03 | 3.57 | 3.30 | 3.62 |
| Qwen2-VL | 7B | 4.03 | 3.88 | 3.56 | 4.08 | 3.83 | 3.62 | 3.84 |
| Qwen2-VL w/ Retrieval Tuning | 7B | 4.17 | 4.01 | 3.86 | 4.31 | 4.00 | 3.77 | 4.02 |
🔼 This table presents a comparative analysis of the model’s performance on the M-LongDoc benchmark under different input configurations. It explores the impact of removing image inputs and using only rendered images (without extracted text) as the document context on the model’s ability to answer questions across various categories (text, figure, table). This allows for an assessment of the model’s reliance on visual information versus textual information and the effect of different input representation methods on its performance.
read the caption
Table 4: Analysis on alternative settings for our benchmark, including removing images from model inputs, and using only the render image of each page as document context, without text extraction.
| Model | Question Category | |||
|---|---|---|---|---|
| Text | Figure | Table | ||
| Qwen2-VL | 4.08 | 3.83 | 3.62 | |
| w/o Image Inputs | 4.22 | 3.37 | 3.38 | |
| w/ Render Page as Inputs | 3.99 | 3.70 | 3.39 |
🔼 This table presents a comparison of the performance of four different retrieval methods in retrieving relevant pages for a document question answering task. The methods compared are BM25, JINA-CLIP, BGE-M3, and ColPali. Performance is evaluated using Mean Reciprocal Rank (MRR) scores, broken down by question type (Text, Figure, Table) and overall.
read the caption
Table 5: Retriever performance comparison.
| Retriever | Text | Figure | Table | All |
|---|---|---|---|---|
| BM25 | 56.2 | 31.2 | 42.0 | 43.1 |
| CLIP | 57.1 | 37.9 | 50.4 | 48.5 |
| BGE-M3 | 66.4 | 36.4 | 53.6 | 52.1 |
| ColPali | 68.7 | 67.5 | 65.9 | 67.4 |
🔼 Table 6 presents a challenging question from the M-LongDoc benchmark dataset. This question necessitates that the model not only understands the individual charts, but also analyzes and compares the trends displayed within two different charts to formulate a comprehensive answer. The charts visualize the relationship between reference length percentile and the percentage of empty modes, and the relationship between reference sentence length percentile and the probability of empty context. The question demands a nuanced understanding of these relationships and their differences. The table showcases a realistic and complex scenario from the benchmark, highlighting the challenges posed by multi-modal long documents.
read the caption
Table 6: An example of a challenging question from M-LongDoc that requires the model to compare the trends of two charts in a document.
| Question | Relevant page (truncated) |
|---|---|
| How does the relationship between reference length percentile and the percentage of empty modes differ from the relationship between reference sentence length percentile and the probability of empty context? Explain the key differences in the trends shown by these two graphs. | https://arxiv.org/html/2411.06176/two_charts_understanding_example.png |
🔼 This table presents a comparative analysis of the outputs generated by two different models: Qwen2-VL and Qwen2-VL with Retrieval-aware Tuning. The table showcases how the models respond to a specific question, illustrating their strengths and weaknesses in understanding and processing multimodal data. The comparison highlights the impact of the Retrieval-aware Tuning technique on the model’s response accuracy and quality, in terms of how well the generated answer reflects the information presented in the multimodal document.
read the caption
Table 7: Sample answers generated by Qwen2-VL and Qwen2-VL w/ Retrieval-aware Tuning, respectively.
Full paper#