↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) struggle to accurately follow complex instructions, and existing methods are insufficient. This is problematic as agents and applications increasingly depend on LLMs to perform more complex tasks. There is a lack of large, high-quality datasets specifically designed for evaluating and training models on complex instructions. Furthermore, current alignment techniques do not adequately address the nuances of complex instruction following.
This research paper introduces TRACE, a new benchmark with 120K training and 1K evaluation data, to address the shortcomings of existing benchmarks. It also presents IOPO, a novel input-output preference optimization method. IOPO significantly enhances LLMs’ understanding of complex instructions by carefully considering both input and output preferences. The method shows substantial improvements compared to state-of-the-art techniques, highlighting its potential to advance the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because complex instruction following is a critical challenge in large language models (LLMs). The proposed IOPO method offers a novel approach to improving LLM performance, and the TRACE benchmark provides a valuable resource for evaluating complex instruction-following capabilities. This work directly addresses the current limitations of LLMs and opens new avenues for further research in alignment and instruction-following techniques.
Visual Insights#

🔼 This figure illustrates two different alignment paradigms for large language models (LLMs): Direct Preference Optimization (DPO) and the proposed Input-Output Preference Optimization (IOPO). Panel (a) shows the DPO approach, where the model generates two responses (Ywin and Yloose) to the same input instruction (X). Green arrows indicate correct alignment between input and output, while red arrows highlight mismatches. Panel (b) presents the IOPO method, which considers both input and output preferences. The model not only learns to align with preferred outputs (Y) but also explores the input instruction’s (X) preferences, refining alignment by considering subtle differences in input constraints that may lead to different desirable outputs. This allows for more nuanced and accurate alignment between the LLM’s understanding of complex instructions and the desired responses. The color-coding of the arrows remains consistent to signify correct and incorrect alignments.
read the caption
Figure 1: Alignment Paradigms (a) Existing DPO Series vs. (b) Proposed IOPO. The green arrow indicates that y𝑦yitalic_y matches x𝑥xitalic_x while the red one indicates a mismatch.
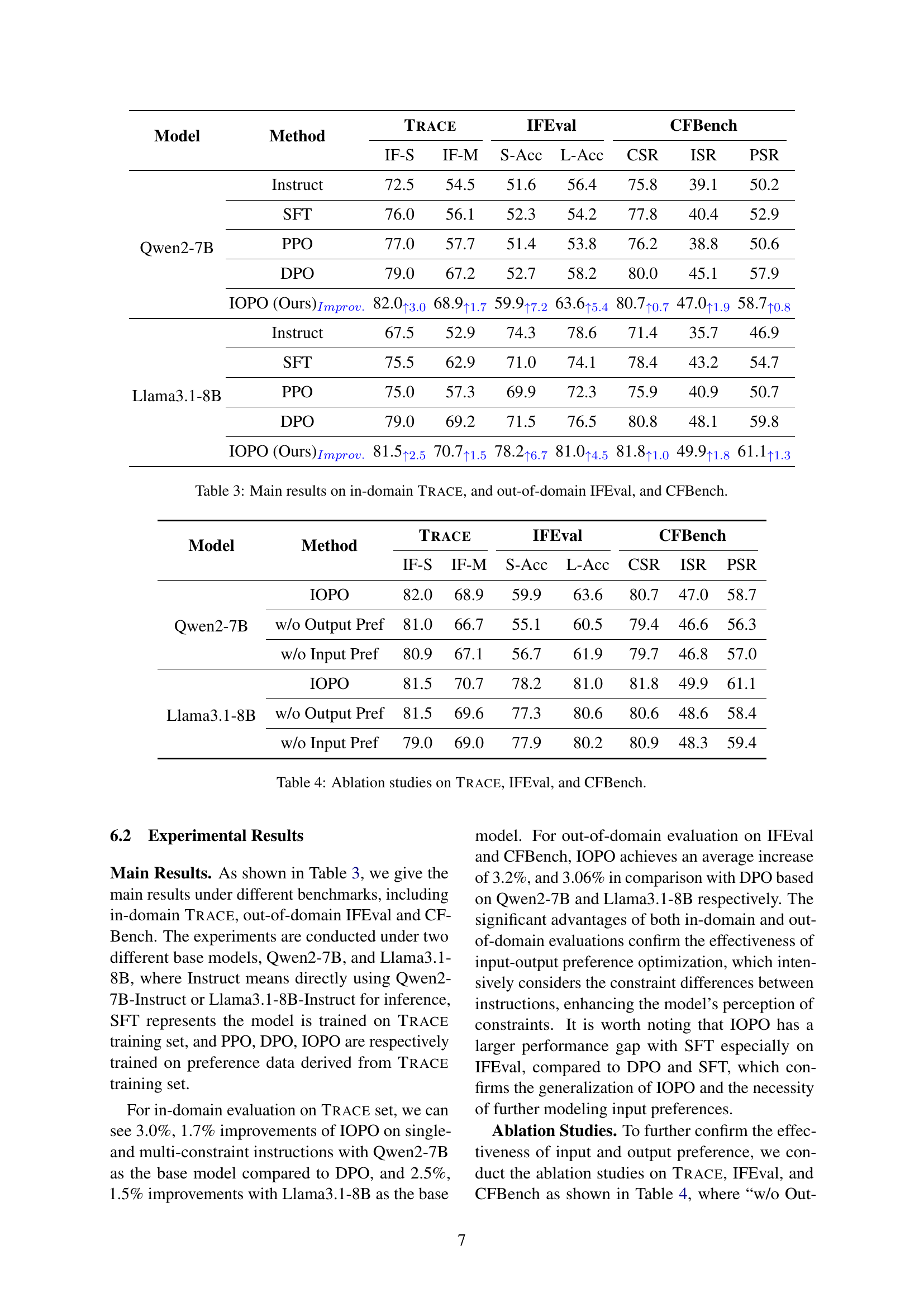
| #N | Min. | Max. | Avg. | |
|---|---|---|---|---|
| #Training | 119,345 | 1 | 15 | 4.36 |
| #Evaluation | 1,042 | 1 | 15 | 4.89 |
🔼 Table 1 presents a summary of the TRACE benchmark dataset’s characteristics. It shows the total number of instructions (#N), the minimum (Min.), maximum (Max.), and average (Avg.) number of constraints per instruction in both the training and evaluation sets of the benchmark.
read the caption
Table 1: The statistics of Trace benchmark. #N is the number of instructions; Min., Max., and Avg. mean the minimum, maximum, and average number of constraints per instruction.
In-depth insights#
Complex Instruction#
The concept of “Complex Instruction” in the context of large language models (LLMs) highlights the challenge of instructing LLMs to perform tasks that demand understanding and execution of multiple, interconnected constraints. It moves beyond simple, single-instruction prompts to scenarios where instructions may involve specifying multiple conditions, formats, styles, and levels of detail. Successful handling of complex instructions requires advancements beyond traditional fine-tuning methods. The difficulty stems from the need for LLMs to not only generate accurate responses but also reason about the relationships between multiple constraints and prioritize them appropriately. This necessitates sophisticated alignment techniques to ensure the model comprehends and adheres to all instruction facets, reflecting real-world task complexities. Benchmarking and evaluating LLMs’ complex instruction-following capabilities is also crucial, requiring datasets with diverse and intricate instructions for a thorough assessment of their capabilities and limitations. Developing novel algorithms for this is a critical area for future LLM research.
IOPO Alignment#
The proposed IOPO (Input-Output Preference Optimization) alignment method offers a novel approach to enhance LLMs’ complex instruction-following capabilities. Unlike existing methods that primarily focus on response preference optimization, IOPO considers both input and output preferences, meticulously exploring instruction nuances alongside response preferences. This dual-focus addresses the challenge of complex instructions with multiple, fine-grained constraints, where solely optimizing outputs may not capture the full intent. By considering input preferences, IOPO facilitates a deeper understanding of constraints within the instructions, thus leading to more accurate and compliant responses. This innovative two-pronged approach is a significant step towards building more robust and reliable LLMs for sophisticated applications. The empirical results demonstrating improvement over prior methods like SFT and DPO strongly supports the effectiveness of IOPO’s dual-focus strategy.
TRACE Benchmark#
The heading ‘TRACE Benchmark’ strongly suggests a section dedicated to a novel benchmark dataset. This likely involves a detailed description of the dataset’s construction, including the methodology for generating complex instructions, its size (120K training + 1K evaluation samples), and the rationale behind its design. It is likely that multiple constraint types are incorporated, aiming to evaluate LLMs beyond simple instruction-following capabilities, possibly covering various constraint dimensions such as format, style, or content restrictions. The description will likely include statistical analyses of the dataset’s composition regarding constraint frequencies and distributions, demonstrating its comprehensiveness. The evaluation methodology for the benchmark would be explained, likely detailing the metrics used to assess LLMs’ performance on complex instructions. The authors probably highlight the benchmark’s advantages over existing datasets by showcasing its improved ability to evaluate more intricate instruction-following skills, potentially mentioning improvements in terms of difficulty and diversity of instructions.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a complex system. In the context of a research paper, an ablation study on a model would involve removing or altering specific features (e.g., layers in a neural network, specific data augmentation strategies, components of a training procedure) to observe the impact on overall performance. The primary goal is to isolate the effects of each component and demonstrate its necessity or importance. A well-designed ablation study provides crucial insights into the model’s inner workings, enabling researchers to understand not only what works but also why it works. Analyzing the results allows researchers to identify critical components, optimize the model’s architecture or training process, and ultimately improve its robustness and efficiency. Furthermore, ablation studies often reveal unexpected interactions between components, leading to a deeper understanding of the system’s behavior. By carefully designing the ablation experiments, comparing results against the baseline performance, and conducting thorough statistical analysis, researchers can build a strong case for the effectiveness of their proposed model or methodology. The findings may also suggest avenues for future research to further enhance the model or address any limitations uncovered during the ablation process.
Future Work#
Future work in complex instruction following for LLMs could explore several promising avenues. Improving the TRACE benchmark by incorporating more diverse and nuanced constraints is crucial for more robust evaluation. Developing more sophisticated alignment algorithms that go beyond simple preference optimization, perhaps integrating techniques from reinforcement learning or causal inference, could significantly enhance LLMs’ ability to understand and satisfy complex instructions. Investigating the interplay between instruction decomposition and model architecture would also be beneficial. For instance, are specialized architectures needed to handle multifaceted instructions? Furthermore, exploring the use of human-in-the-loop techniques for iterative refinement of complex instructions and model responses is vital for ensuring alignment with human values and preferences. Lastly, research into the generalizability of complex instruction following across diverse domains and languages would contribute towards building more versatile and reliable LLMs.
More visual insights#
More on figures

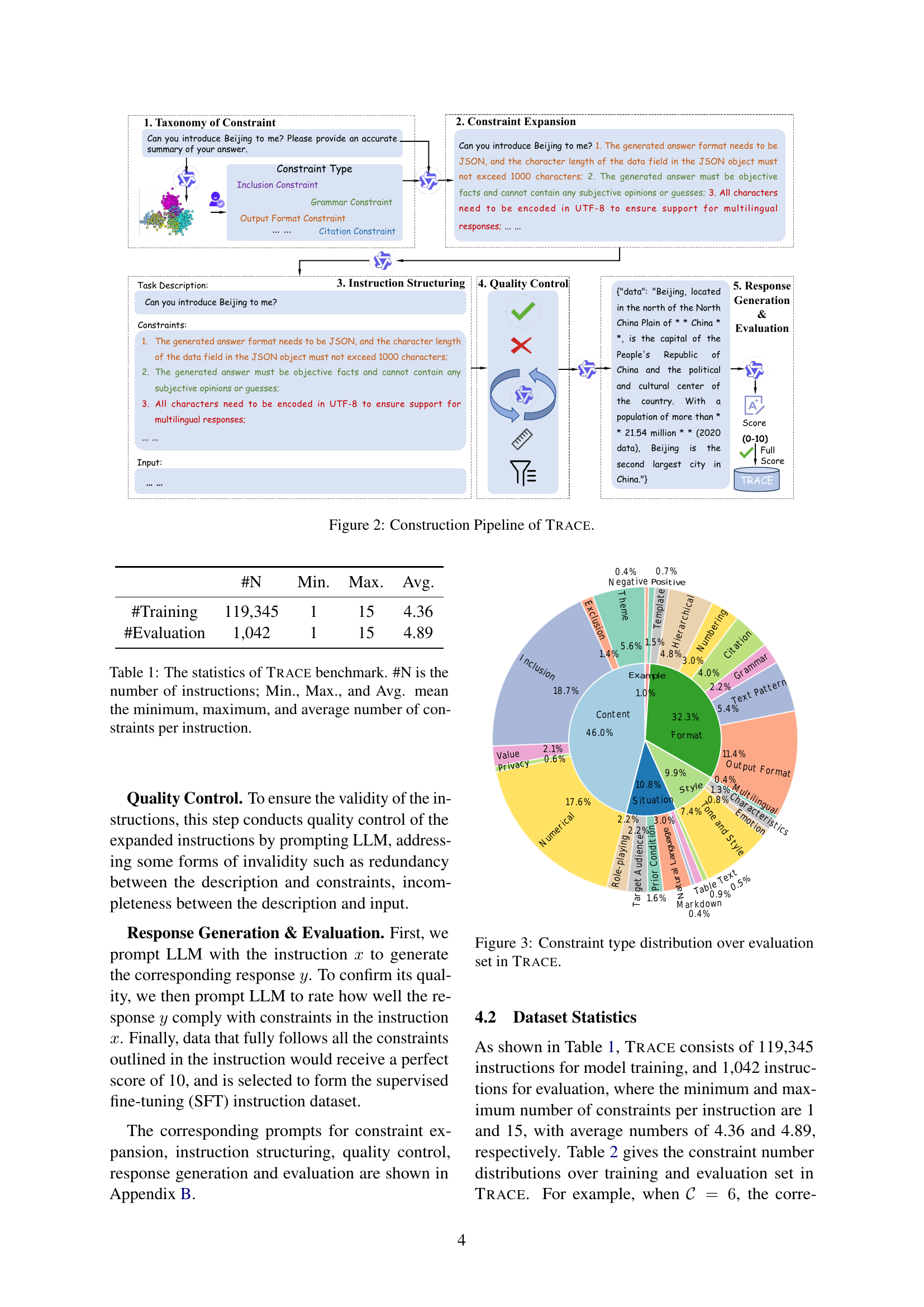
🔼 This figure illustrates the TRACE benchmark’s construction pipeline, detailing the five key stages: 1) Taxonomy of Constraint: establishes a comprehensive constraint type system; 2) Constraint Expansion: expands simple instructions into more complex ones; 3) Instruction Structuring: structures instructions into Task Description, Constraints, and Input; 4) Quality Control: ensures validity by checking for redundancy and incompleteness; 5) Response Generation & Evaluation: generates responses and evaluates their compliance with constraints, selecting high-quality data for training and evaluation.
read the caption
Figure 2: Construction Pipeline of Trace.

🔼 This figure shows a pie chart and a ring chart visualizing the distribution of constraint types in the TRACE benchmark’s evaluation dataset. The inner pie chart displays the distribution of five main constraint types: Content, Situation, Style, Format, and Example. The outer ring chart further breaks down each main constraint type into its specific dimensions. This provides a detailed overview of the types and complexities of constraints present in the evaluation set, illustrating the diversity of the benchmark.
read the caption
Figure 3: Constraint type distribution over evaluation set in Trace.

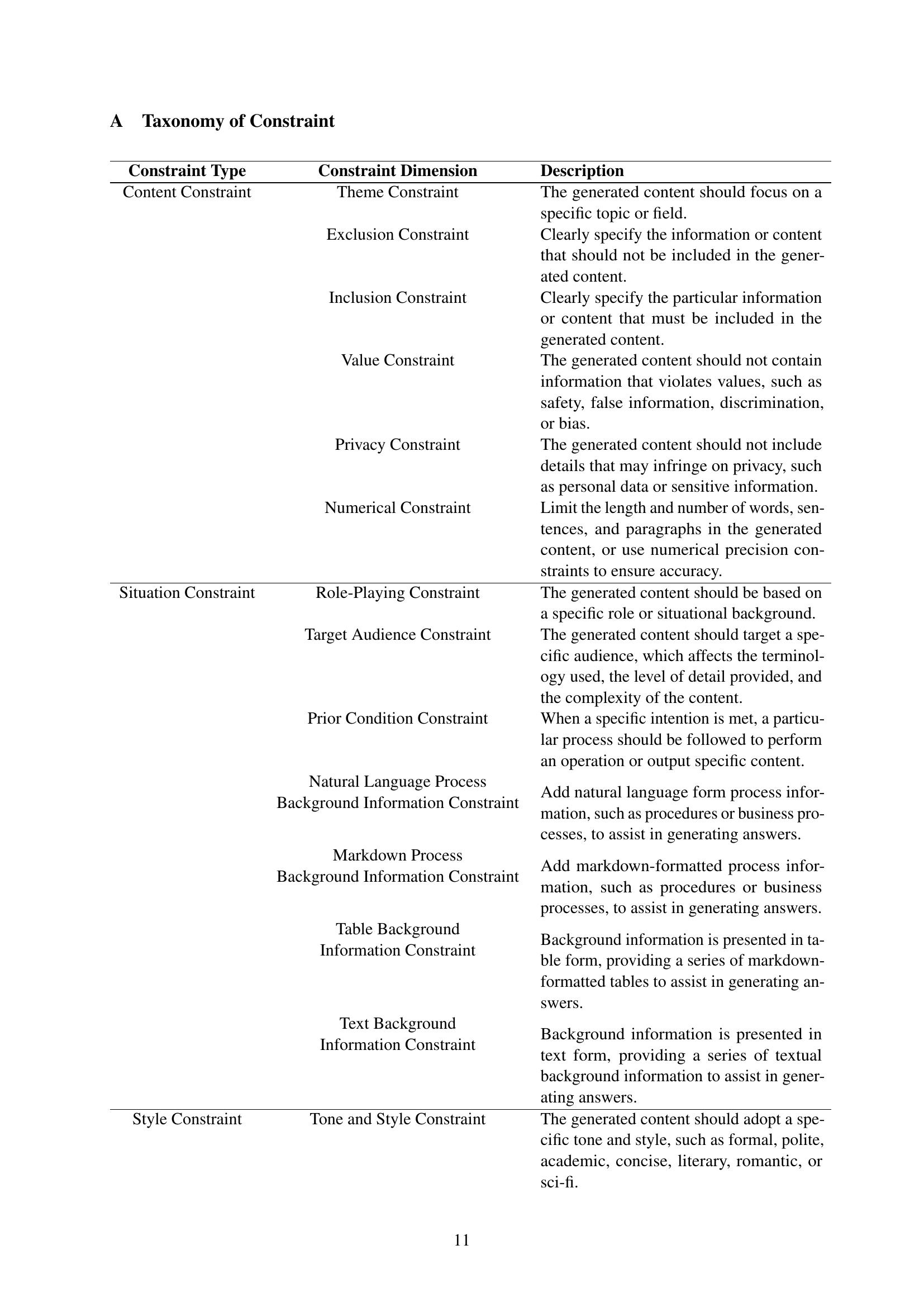
🔼 This figure displays a comparison of the performance of different instruction following methods (SFT, DPO, and IOPO) using the Qwen2-7B language model. The performance is measured across several metrics (IF-S, IF-M, S-Acc, L-Acc, CSR, ISR, PSR) and datasets (TRACE, IFEval, CFBench). The key aspect highlighted is that the comparison is done while maintaining the same quantity of tokens used for training, making it easier to understand the impact of each method independently of the training data size.
read the caption
Figure 4: Performance comparisons under the same quantity of tokens with Qwen2-7B as the base model.

🔼 This figure compares the performance of different instruction following methods (SFT, DPO, IOPO) using the Llama 3.1-8B language model. The comparison is performed under the constraint that all methods use the same quantity of tokens during training. The performance is measured across multiple metrics relevant to instruction following tasks, including single-constraint and multi-constraint instruction following, showing improvements made by IOPO.
read the caption
Figure 5: Performance comparisons under the same quantity of tokens with Llama3.1-8B as the base model.

🔼 This figure illustrates the process of constructing the DPO (Direct Preference Optimization) training dataset. It shows how a worse response (Yloose) is generated alongside the preferred response (Ywin) for each instruction. This pair of responses is then used in the DPO training process to refine the model’s preference alignment. The example shows a prompt requesting information about Beijing with specific constraints. The model generates both a preferred JSON response and an inferior text-based response.
read the caption
Figure 6: DPO-series Data Construction.

🔼 This figure details the construction process of the IOPO (Input-Output Preference Optimization) training dataset. It illustrates how the dataset is built by first generating modified instructions (x2) with altered constraints from the original instruction (x1). Then, responses (y1 and y2) are generated for both the original and modified instructions. The process involves using an LLM to generate variations in the instructions’ constraints, ensuring that the generated response does not meet the new constraints. This ensures a diverse dataset representing a wider range of instruction complexities for training the IOPO model.
read the caption
Figure 7: IOPO Data Construction.
More on tables
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
| #Training | 991 | 8,003 | 26,421 | 34,155 | 26,327 | 13,858 | 5,882 | 2,185 | 999 | 464 | 8 | 20 | 20 | 8 |
| #Evaluation | 200 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 10 | 10 | 10 | 4 |
🔼 This table shows the distribution of the number of constraints in each instruction within the TRACE benchmark dataset. It breaks down the number of training and evaluation set instructions containing 1, 2, 3, …, up to 15 constraints. This helps in understanding the complexity of instructions in the benchmark and how it’s distributed.
read the caption
Table 2: Constraint number (𝒞𝒞\mathcal{C}caligraphic_C) distributions over training and evaluation set in Trace. 𝒞=i𝒞𝑖\mathcal{C}=icaligraphic_C = italic_i represents the number of instructions with i𝑖iitalic_i constraints.
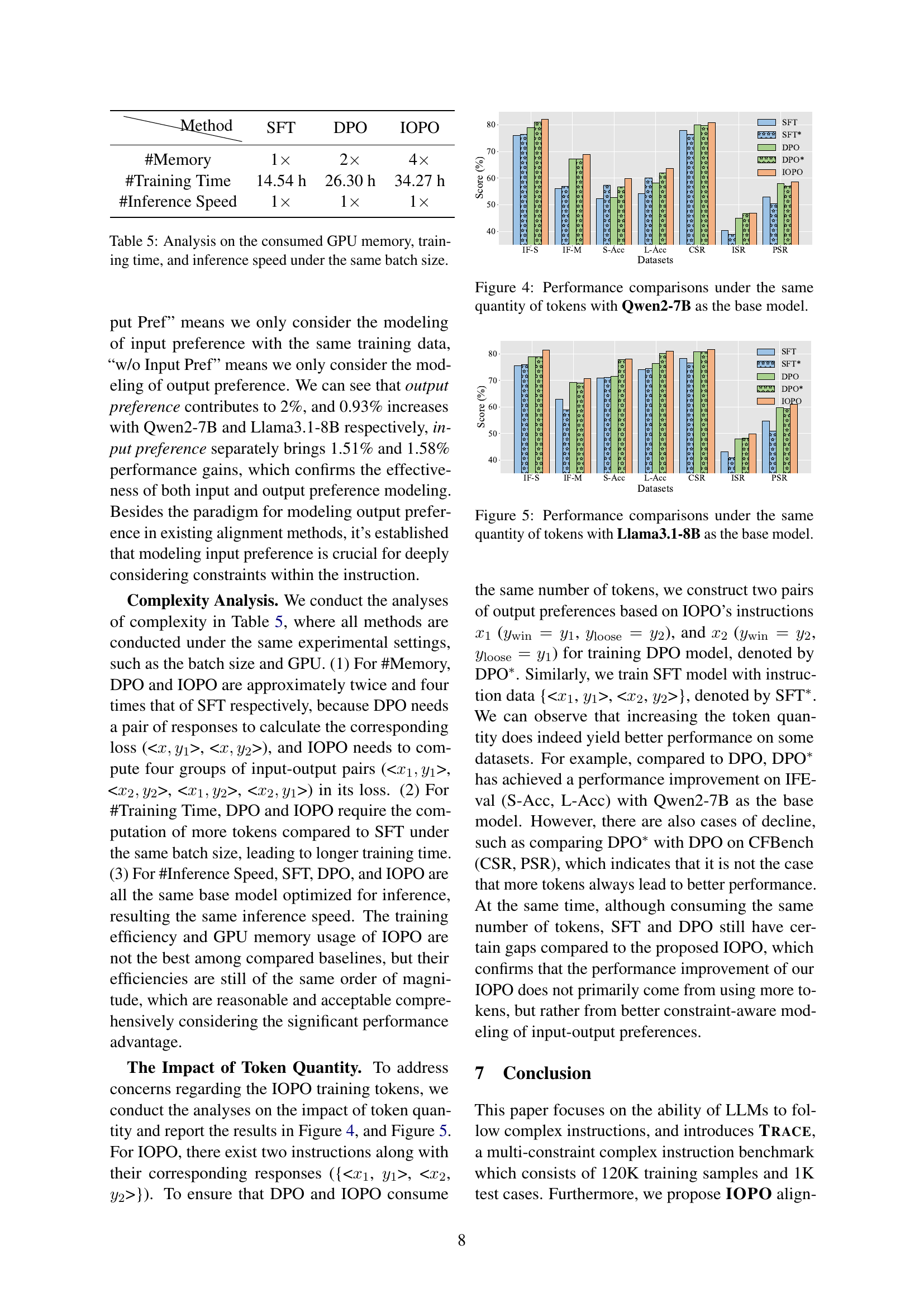
| Model | Method | Trace IF-S | Trace IF-M | IFEval S-Acc | IFEval L-Acc | CFBench CSR | CFBench ISR | CFBench PSR |
|---|---|---|---|---|---|---|---|---|
| Qwen2-7B | Instruct | 72.5 | 54.5 | 51.6 | 56.4 | 75.8 | 39.1 | 50.2 |
| SFT | 76.0 | 56.1 | 52.3 | 54.2 | 77.8 | 40.4 | 52.9 | |
| PPO | 77.0 | 57.7 | 51.4 | 53.8 | 76.2 | 38.8 | 50.6 | |
| DPO | 79.0 | 67.2 | 52.7 | 58.2 | 80.0 | 45.1 | 57.9 | |
| IOPO (Ours)Improv. | 82.0↑3.0 | 68.9↑1.7 | 59.9↑7.2 | 63.6↑5.4 | 80.7↑0.7 | 47.0↑1.9 | 58.7↑0.8 | |
| Llama3.1-8B | Instruct | 67.5 | 52.9 | 74.3 | 78.6 | 71.4 | 35.7 | 46.9 |
| SFT | 75.5 | 62.9 | 71.0 | 74.1 | 78.4 | 43.2 | 54.7 | |
| PPO | 75.0 | 57.3 | 69.9 | 72.3 | 75.9 | 40.9 | 50.7 | |
| DPO | 79.0 | 69.2 | 71.5 | 76.5 | 80.8 | 48.1 | 59.8 | |
| IOPO (Ours)Improv. | 81.5↑2.5 | 70.7↑1.5 | 78.2↑6.7 | 81.0↑4.5 | 81.8↑1.0 | 49.9↑1.8 | 61.1↑1.3 |
🔼 This table presents the main experimental results comparing different instruction following methods (SFT, PPO, DPO, and IOPO) across three benchmark datasets: TRACE (in-domain), IFEval, and CFBench (both out-of-domain). For each method and dataset, the table shows performance metrics relevant to the specific benchmark, such as IF-S, IF-M (for TRACE), S-Acc, L-Acc (for IFEval), and CSR, ISR, PSR (for CFBench). The results illustrate the improvements achieved by IOPO compared to other methods on both in-domain and out-of-domain data.
read the caption
Table 3: Main results on in-domain Trace, and out-of-domain IFEval, and CFBench.
| Model | Method | Trace IF-S | Trace IF-M | IFEval S-Acc | IFEval L-Acc | CFBench CSR | CFBench ISR | CFBench PSR |
|---|---|---|---|---|---|---|---|---|
| Qwen2-7B | IOPO | 82.0 | 68.9 | 59.9 | 63.6 | 80.7 | 47.0 | 58.7 |
| Qwen2-7B | w/o Output Pref | 81.0 | 66.7 | 55.1 | 60.5 | 79.4 | 46.6 | 56.3 |
| Qwen2-7B | w/o Input Pref | 80.9 | 67.1 | 56.7 | 61.9 | 79.7 | 46.8 | 57.0 |
| Llama3.1-8B | IOPO | 81.5 | 70.7 | 78.2 | 81.0 | 81.8 | 49.9 | 61.1 |
| Llama3.1-8B | w/o Output Pref | 81.5 | 69.6 | 77.3 | 80.6 | 80.6 | 48.6 | 58.4 |
| Llama3.1-8B | w/o Input Pref | 79.0 | 69.0 | 77.9 | 80.2 | 80.9 | 48.3 | 59.4 |
🔼 This table presents the results of ablation experiments conducted on three benchmark datasets: TRACE, IFEval, and CFBench. The experiments analyze the impact of removing either input preference optimization or output preference optimization from the IOPO (Input-Output Preference Optimization) method. By comparing the performance of IOPO with variants that exclude either input or output preference, the table clarifies the relative contributions of each component to the overall performance improvements.
read the caption
Table 4: Ablation studies on Trace, IFEval, and CFBench.
| Method | SFT | DPO | IOPO |
|---|---|---|---|
| #Memory | 1× | 2× | 4× |
| #Training Time | 14.54 h | 26.30 h | 34.27 h |
| #Inference Speed | 1× | 1× | 1× |
🔼 This table presents a comparison of the GPU memory consumption, training time, and inference speed for three different instruction following methods (SFT, DPO, and IOPO) using the same batch size. It helps to understand the computational resource requirements of each method.
read the caption
Table 5: Analysis on the consumed GPU memory, training time, and inference speed under the same batch size.
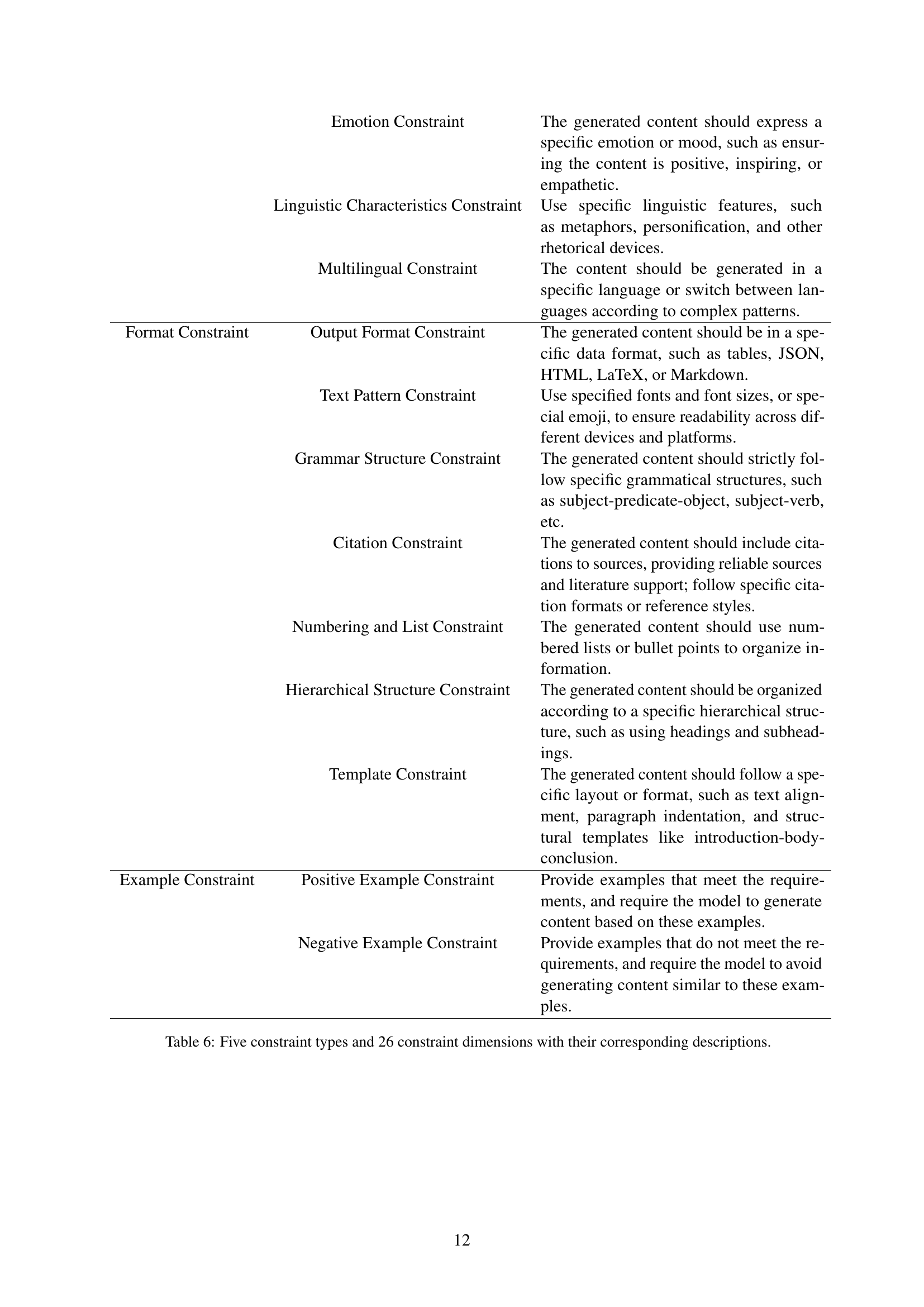
| Constraint Type | Constraint Dimension | Description |
|---|---|---|
| Content Constraint | Theme Constraint | The generated content should focus on a specific topic or field. |
| Exclusion Constraint | Clearly specify the information or content that should not be included in the generated content. | |
| Inclusion Constraint | Clearly specify the particular information or content that must be included in the generated content. | |
| Value Constraint | The generated content should not contain information that violates values, such as safety, false information, discrimination, or bias. | |
| Privacy Constraint | The generated content should not include details that may infringe on privacy, such as personal data or sensitive information. | |
| Numerical Constraint | Limit the length and number of words, sentences, and paragraphs in the generated content, or use numerical precision constraints to ensure accuracy. | |
| Situation Constraint | Role-Playing Constraint | The generated content should be based on a specific role or situational background. |
| Target Audience Constraint | The generated content should target a specific audience, which affects the terminology used, the level of detail provided, and the complexity of the content. | |
| Prior Condition Constraint | When a specific intention is met, a particular process should be followed to perform an operation or output specific content. | |
| Natural Language Process Background Information Constraint | Add natural language form process information, such as procedures or business processes, to assist in generating answers. | |
| Markdown Process Background Information Constraint | Add markdown-formatted process information, such as procedures or business processes, to assist in generating answers. | |
| Table Background Information Constraint | Background information is presented in table form, providing a series of markdown-formatted tables to assist in generating answers. | |
| Text Background Information Constraint | Background information is presented in text form, providing a series of textual background information to assist in generating answers. | |
| Style Constraint | Tone and Style Constraint | The generated content should adopt a specific tone and style, such as formal, polite, academic, concise, literary, romantic, or sci-fi. |
| Emotion Constraint | The generated content should express a specific emotion or mood, such as ensuring the content is positive, inspiring, or empathetic. | |
| Linguistic Characteristics Constraint | Use specific linguistic features, such as metaphors, personification, and other rhetorical devices. | |
| Multilingual Constraint | The content should be generated in a specific language or switch between languages according to complex patterns. | |
| Format Constraint | Output Format Constraint | The generated content should be in a specific data format, such as tables, JSON, HTML, LaTeX, or Markdown. |
| Text Pattern Constraint | Use specified fonts and font sizes, or special emoji, to ensure readability across different devices and platforms. | |
| Grammar Structure Constraint | The generated content should strictly follow specific grammatical structures, such as subject-predicate-object, subject-verb, etc. | |
| Citation Constraint | The generated content should include citations to sources, providing reliable sources and literature support; follow specific citation formats or reference styles. | |
| Numbering and List Constraint | The generated content should use numbered lists or bullet points to organize information. | |
| Hierarchical Structure Constraint | The generated content should be organized according to a specific hierarchical structure, such as using headings and subheadings. | |
| Template Constraint | The generated content should follow a specific layout or format, such as text alignment, paragraph indentation, and structural templates like introduction-body-conclusion. | |
| Example Constraint | Positive Example Constraint | Provide examples that meet the requirements, and require the model to generate content based on these examples. |
| Negative Example Constraint | Provide examples that do not meet the requirements, and require the model to avoid generating content similar to these examples. |
🔼 This table presents a taxonomy of constraints used in complex instruction following. It categorizes 26 individual constraint dimensions into five main constraint types: Content, Situation, Style, Format, and Example constraints. For each dimension, a detailed description is provided to clarify its meaning and application in instruction design.
read the caption
Table 6: Five constraint types and 26 constraint dimensions with their corresponding descriptions.
Full paper#