↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
The increasing use of large language models (LLMs) in finance necessitates robust evaluation methods. Existing benchmarks, however, often suffer from limitations like limited language support, low-quality data, and inadequate task designs, making it difficult to accurately assess model performance. This problem is particularly acute for financial LLMs (FinLLMs), which require specialized datasets and tasks.
To overcome these limitations, the researchers introduce “Golden Touchstone,” the first comprehensive bilingual benchmark for financial LLMs. Golden Touchstone addresses the shortcomings of existing benchmarks by incorporating high-quality datasets from both Chinese and English across eight financial NLP tasks. It includes a variety of tasks covering key capabilities such as sentiment analysis, question answering, and stock price prediction, providing a holistic assessment of FinLLM performance. This benchmark facilitates fair comparisons between models and identifies areas needing improvements, guiding future research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for standardized evaluation of financial large language models (FinLLMs). Existing benchmarks suffer from limitations in language coverage, data quality, and task design, hindering comprehensive model assessment. This research directly tackles these issues, opening up new avenues for FinLLM development and optimization, and promoting fairer comparisons between models. Its open-sourced nature fosters collaboration and accelerates progress in the field.
Visual Insights#

🔼 This figure illustrates the workflow of financial large language models (FinLLMs) in performing specialized financial tasks. FinLLMs receive structured instructions and various input data (e.g., financial news articles, stock data, etc.) as input. They process this input to generate precise outputs, such as sentiment analysis results, summaries, stock price predictions, or answers to financial analyst-level questions. The diagram visually represents the input-processing-output pipeline of a FinLLM, highlighting its ability to handle complex financial information and produce tailored results.
read the caption
Figure 1: Financial large language models are designed to perform specialized tasks such as financial sentiment analysis, content analysis, stock movement prediction, and financial analyst level question answering by interpreting and processing structured instructions and various input data to generate precise outputs.
| Benchmarks | Sent. Anal. | Classif. | Ent. Extr. | Rel. Extr. | Multi. Choice | Summ. | Quest. Ans. | Stock Pred. |
|---|---|---|---|---|---|---|---|---|
| FinGPT-Bench [2023a] | ✓ | ✓ | ✓ | ✓ | ||||
| FinBen [2024] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| BBT-Fin [2023a] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Fin-Eval [2023] | ✓ | |||||||
| FinanceIQ [2023] | ✓ | |||||||
| CFBenchmark [2023] | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Golden-Touchstone | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares the features of various publicly available financial large language model (FinLLM) benchmarks. It shows which benchmarks include tasks focused on sentiment analysis, classification, entity extraction, relation extraction, multiple-choice questions, summarization, question answering, and stock price prediction. The table also indicates whether each benchmark supports English or Chinese language, helping to illustrate the range of capabilities present in existing FinLLM evaluation resources.
read the caption
Table 1: Diversity of Financial Analysis Tasks Across Different Financial Large Language Model Benchmarks
In-depth insights#
FinLLM Benchmarking#
FinLLM benchmarking is a critical area needing standardization and improvement. Current benchmarks suffer from limited language coverage, low-quality data, and inadequate task design, hindering comprehensive evaluation of financial large language models (FinLLMs). A key challenge is the lack of a unified, bilingual (English and Chinese) benchmark, impeding cross-lingual comparisons and limiting the development of truly robust FinLLMs. High-quality datasets are crucial, especially those tailored to specific financial tasks and avoiding biases toward certain model architectures. The ideal benchmark should also include a variety of tasks reflecting the nuances of financial language understanding and generation, including sentiment analysis, question answering, and complex financial reasoning. Furthermore, evaluating models on their performance across both NLU and NLG tasks is vital, enabling a more holistic assessment. Finally, the benchmark needs to be easily reproducible and accessible, fostering collaborative research and progress in the field. Addressing these shortcomings is essential for accelerating the development and deployment of reliable and trustworthy FinLLMs.
Bilingual FinLLM Eval#
A hypothetical heading, ‘Bilingual FinLLM Eval’, suggests a research focus on evaluating financial large language models (FinLLMs) that handle both English and another language, likely Chinese given the paper’s context. This signifies a significant advancement beyond monolingual evaluations, as it acknowledges the multilingual nature of global finance. A robust bilingual evaluation would require carefully selected datasets in both languages representing a diversity of financial tasks (sentiment analysis, news classification, entity recognition, etc.). The key challenge lies in ensuring data quality and consistency across languages, which can impact model performance comparisons. Further, the evaluation should consider aspects such as model adaptability, systematicity of the benchmark, and instruction tuning effectiveness in each language. Such an evaluation could lead to valuable insights into the strengths and weaknesses of FinLLMs in diverse linguistic contexts, potentially identifying language-specific biases or areas requiring further model development. Ultimately, a ‘Bilingual FinLLM Eval’ contributes to building more robust and globally applicable FinLLMs by fostering rigorous and comprehensive testing methodologies.
Touchstone-GPT Model#
The research paper introduces Touchstone-GPT, a bilingual financial large language model (FinLLM) trained using a novel two-stage approach: continuous pre-training and financial instruction tuning. This model serves as a valuable resource and a strong baseline for future FinLLM research. The continuous pre-training phase leverages a massive 100-billion-token financial corpus, enhancing the model’s understanding of complex financial concepts and terminology in both English and Chinese. The subsequent financial instruction tuning refines the model’s ability to perform specific financial tasks effectively, drawing on a high-quality dataset of 300,000 instruction-response pairs. The results demonstrate that Touchstone-GPT exhibits strong performance on the Golden Touchstone benchmark, outperforming several other state-of-the-art FinLLMs in various tasks. However, the study also acknowledges that Touchstone-GPT, like other FinLLMs, shows limitations in certain tasks, particularly those involving intricate numerical computations or requiring nuanced understanding of specific financial products or regulations. The open-sourcing of this model aims to foster further collaboration and advancement in the field, prompting a valuable contribution to the ongoing evolution of FinLLMs and financial AI. The public availability of both the model weights and the Golden Touchstone benchmark itself promotes transparency and facilitates comprehensive model evaluation, ultimately fostering progress in this critical area.
Model Strengths/Limits#
Analysis of the provided research paper reveals varying model strengths and limitations across different financial NLP tasks. GPT-40 demonstrates strong performance in sentiment analysis and structured question answering, showcasing its robustness in understanding sentiment and handling structured queries. However, it struggles with detailed information extraction tasks, highlighting a potential weakness in complex relationship handling. FinMA excels in sentiment analysis but lacks versatility in broader tasks, indicating specialization in sentiment but limitations in handling diverse financial NLP challenges. Llama-3 shows strength in stock movement prediction but underperforms in other areas, suggesting specialized training for this specific task but a lack of broader capabilities. Qwen-2 and similar models demonstrate generally moderate performance across a range of tasks, highlighting the need for more specialized training in specific financial domains. Touchstone-GPT, a financially trained model, exhibits improved performance overall, showcasing the benefits of specialized training for enhancing capabilities in financial NLP. The findings highlight that while general-purpose models can handle simpler tasks, specialized models often outperform them in complex financial scenarios due to their more focused training. There is a need for further research and development of more sophisticated models capable of handling nuances and complexities of financial language, as well as higher-quality training data and benchmarks to properly assess model performance across a broader spectrum of financial tasks.
Future Research Needs#
Future research should prioritize expanding the benchmark’s scope to encompass a wider array of financial tasks and datasets, particularly those involving complex financial instruments and nuanced market dynamics. Addressing the limitations of current models in handling numerical reasoning and multi-step, multi-turn interactions is crucial. This involves developing more robust and sophisticated model architectures that effectively integrate numerical and textual information. Furthermore, research should focus on enhancing the quality and diversity of training datasets. This includes incorporating real-world financial data such as transaction records, market sentiment analysis from diverse sources, and incorporating visual information to bridge the gap between textual and visual data processing in financial contexts. Finally, a major thrust should be directed towards developing benchmarks and evaluation metrics that are better aligned with the practical needs of the financial industry. The focus should be on measuring not just accuracy but also aspects like explainability, fairness, and robustness, which are critical for the responsible deployment of financial LLMs in real-world scenarios. Developing and validating more sophisticated evaluation metrics beyond simple accuracy scores is key. This will require close collaboration between researchers and practitioners to ensure that evaluation strategies truly reflect the needs and challenges of using LLMs in finance.
More visual insights#
More on figures

🔼 Figure 2 presents a comprehensive overview of the Golden Touchstone benchmark’s organization. It visually depicts how the benchmark’s 22 datasets are categorized across eight core financial NLP tasks. The categorization uses two dimensions: the type of NLP task (Natural Language Understanding or Natural Language Generation) and the language (English or Chinese). This clear visual representation allows for easy comprehension of the benchmark’s structure and the diversity of tasks and languages covered.
read the caption
Figure 2: Financial NLP tasks are categorized along two dimensions: task types, divided into financial NLU (Natural Language Understanding) and financial NLG (Natural Language Generation), and language, categorized as English and Chinese. We organized the collected high-quality datasets along these axes.

🔼 This figure presents a comparative analysis of various large language models’ performance on the Golden Touchstone benchmark. It uses radar charts to visualize the average performance of each model across eight different financial NLP tasks, broken down by English and Chinese language datasets. The chart allows for a direct comparison of model strengths and weaknesses in specific tasks and across different languages, highlighting the relative performance of general-purpose LLMs versus those specifically trained for financial applications.
read the caption
Figure 3: Comparison of different models’ performance across tasks in the Golden Touchstone benchmark, illustrating average performance for English and Chinese tasks respectively.
More on tables
| Benchmarks | Language | Language | Systematicity | Adaptability | Model Training | Model Training |
|---|---|---|---|---|---|---|
| EN | CN | Cont. Pre-train | Instr. Tuning | |||
| FinGPT-Bench (Wang et al., 2023a) | ✓ | Medium | High | ✓ | ||
| FinBen (Xie et al., 2024) | ✓ | High | Medium | ✓ | ||
| BBT-Fin (Lu et al., 2023a) | ✓ | Medium | High | ✓ | ||
| Fin-Eval (Zhang et al., 2023) | ✓ | High | High | |||
| FinanceIQ (Zhang and Yang, 2023) | ✓ | Medium | High | ✓ | ✓ | |
| CFBenchmark (Lei et al., 2023) | ✓ | High | High | ✓ | ✓ | |
| Golden-Touchstone | ✓ | ✓ | High | High | ✓ | ✓ |
🔼 This table compares various financial benchmarks based on four key aspects: language coverage (English and/or Chinese), systematicity (whether the benchmark follows a well-defined standard), adaptability to large language models (LLMs), and the model training stage (whether continuous pre-training or instruction tuning is involved). Systematicity refers to the presence of a structured and comprehensive framework for creating the benchmark, while adaptability highlights whether the tasks included are appropriate for evaluating LLMs. This detailed comparison helps assess the strengths and limitations of existing financial benchmarks for LLMs.
read the caption
Table 2: Language Coverage, Systematicity, Adaptability, and Model Training Stage for Benchmarks. Systematicity refers to whether benchmarks are established according to a comprehensive system standard. Adaptability indicates whether the tasks are suitable for large language models.
| Task | Dataset | Train | Valid | Test | Metrics |
|---|---|---|---|---|---|
| Sentiment Analysis | FPB | 3100 | 776 | 970 | Weighted-F1, ACC |
| FiQA-SA | 750 | 188 | 235 | Weighted-F1, ACC | |
| Classification | Headlines | 71900 | 10300 | 20500 | Weighted-F1, ACC |
| FOMC | 1984 | - | 496 | Weighted-F1, ACC | |
| lendingclub | 9417 | 1345 | 2691 | Weighted-F1, MCC | |
| Entity Recognition | NER | 408 | 103 | 98 | Entity-F1 |
| Relation Extraction | FinRE | 27558 | - | 5112 | Relation-F1 |
| Multiple Choice | CFA | 1884 | 100 | 20 | Weighted-F1, ACC |
| Summarization | EDTSUM | 8000 | - | 2000 | ROUGE, BLEU |
| Question Answering | FinQa | 6251 | 883 | 1147 | RMACC |
| ConvfinQa | 8890 | 2210 | 1490 | RMACC | |
| Stock Movement Prediction | DJIA | 1591 | - | 398 | Weighted-F1, ACC |
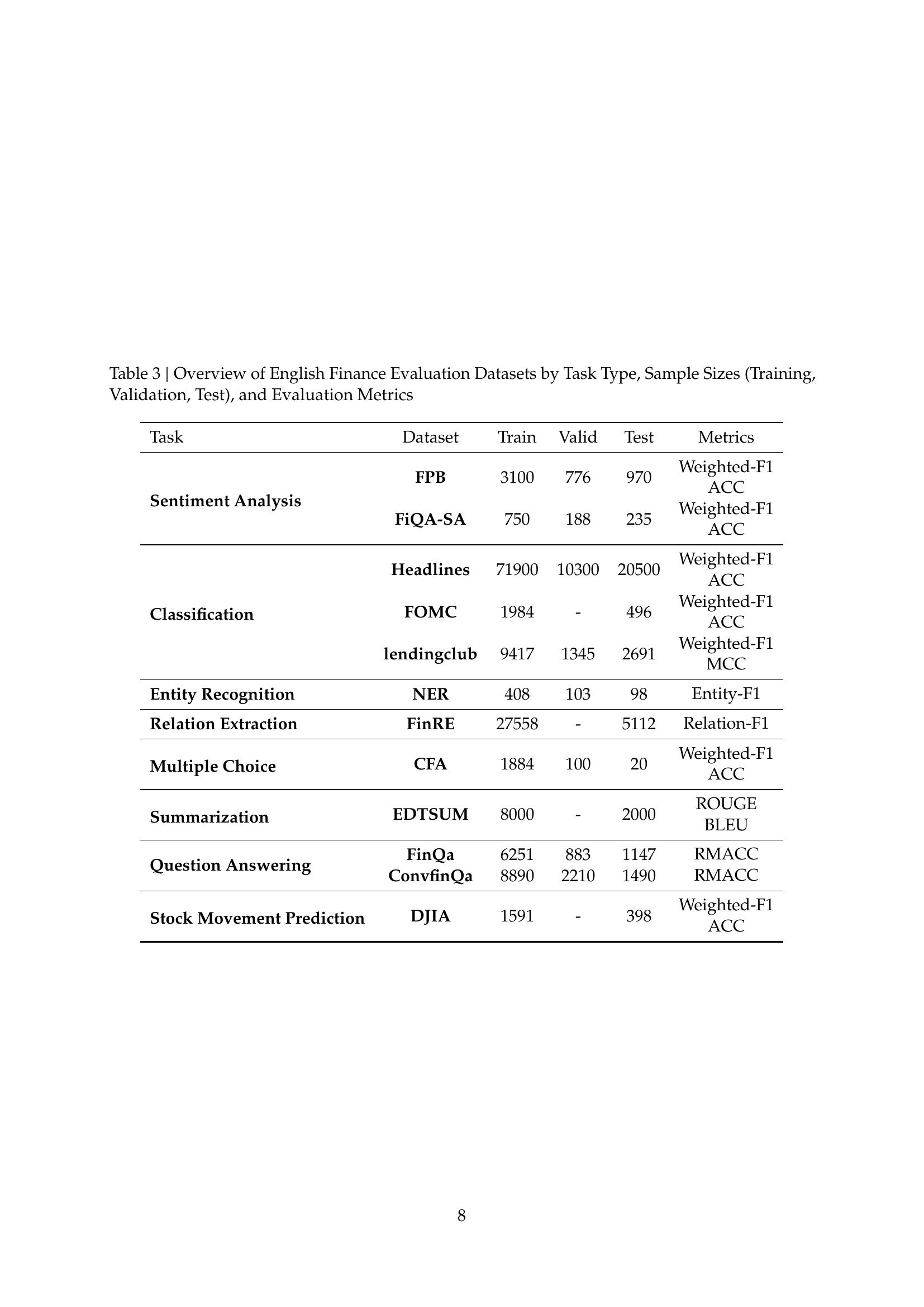
🔼 This table details the English financial datasets used in the Golden Touchstone benchmark. For each of the eight tasks (Sentiment Analysis, Classification, Entity Recognition, Relation Extraction, Multiple Choice, Summarization, Question Answering, and Stock Movement Prediction), it lists the specific dataset used, the number of samples in the training, validation, and test sets, and the evaluation metrics employed (e.g., Weighted-F1, Accuracy, ROUGE). This provides a comprehensive overview of the data used for evaluating financial LLMs in the English language portion of the benchmark.
read the caption
Table 3: Overview of English Finance Evaluation Datasets by Task Type, Sample Sizes (Training, Validation, Test), and Evaluation Metrics
| Task | Dataset | Train | Valid | Test | Metrics |
|---|---|---|---|---|---|
| Sentiment Analysis | FinFE-CN | 16157 | 2020 | 2020 | Weighted-F1 ACC |
| Classification | FinNL-CN | 7071 | 884 | 884 | ORMACC |
| Entity Extraction | FinESE-CN | 14252 | 1781 | 1782 | ORMACC |
| Relation Extraction | FinRE-CN | 13486 | 1489 | 3727 | RMACC |
| Multiple Choice | FinEval | 1071 | 170 | 3340 | Weighted-F1 ACC |
| CPA | 6268 | 1444 | 6 | Weighted-F1 ACC | |
| Summarization | FinNA-CN | 28800 | 3600 | 3600 | ROUGE BLEU |
| Question Answering | FinQa-CN | 19906 | 2469 | 2480 | RMACC |
| FincQa-CN | 21965 | 2741 | 2745 | RMACC | |
| Stock Movement Prediction | AStock | 11815 | 1477 | 1477 | Weighted-F1 ACC |
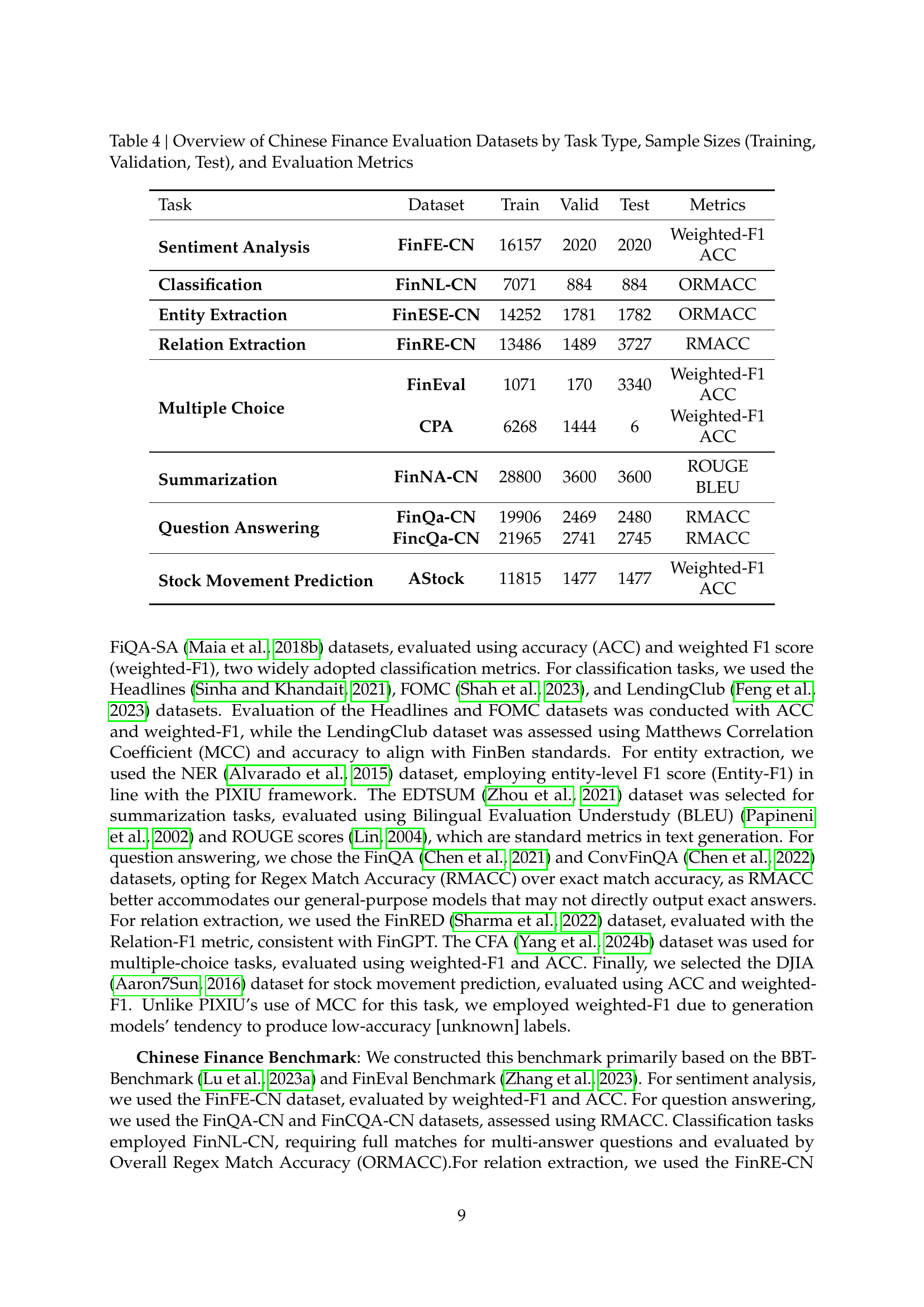
🔼 This table presents a detailed breakdown of the Chinese financial evaluation datasets used in the Golden Touchstone benchmark. It lists each dataset by its associated task type (e.g., sentiment analysis, classification), provides the sample sizes for training, validation, and testing sets, and specifies the evaluation metrics employed for each task (e.g., weighted F1 score, accuracy, ORMACC). This information is crucial for understanding the scale and characteristics of the data used to evaluate the performance of financial large language models (FinLLMs) in the benchmark.
read the caption
Table 4: Overview of Chinese Finance Evaluation Datasets by Task Type, Sample Sizes (Training, Validation, Test), and Evaluation Metrics
| Task | Dataset | Metrics | GPT-4o | FinMA-7B | Qwen-2-7B | Llama-3-8B | FinGPT-8B | Touchstone | |
|---|---|---|---|---|---|---|---|---|---|
| Sentiment Analysis | FPB | Weighted-F1 | 0.8084 | 0.9400 | 0.7965 | 0.7631 | 0.2727 | 0.8576 | |
| ACC | 0.8093 | 0.9402 | 0.8000 | 0.7660 | 0.3072 | 0.8557 | |||
| Fiqa-SA | Weighted-F1 | 0.8106 | 0.8370 | 0.6726 | 0.7515 | 0.5885 | 0.8591 | ||
| ACC | 0.7702 | 0.8340 | 0.5957 | 0.7064 | 0.5872 | 0.8638 | |||
| Classification | Headlines | Weighted-F1 | 0.7857 | 0.9739 | 0.7278 | 0.7006 | 0.4516 | 0.9866 | |
| ACC | 0.7931 | 0.9739 | 0.7252 | 0.7004 | 0.4331 | 0.9866 | |||
| FOMC | Weighted-F1 | 0.6603 | 0.3988 | 0.6112 | 0.4904 | 0.2758 | 0.8788 | ||
| ACC | 0.6794 | 0.4274 | 0.6210 | 0.5625 | 0.2702 | 0.8790 | |||
| lendingclub | Weighted-F1 | 0.6730 | 0.1477 | 0.5938 | 0.5943 | 0.5480 | 0.9783 | ||
| MCC | 0.1642 | -0.6218 | 0.1714 | 0.1670 | -0.1120 | 0.9297 | |||
| Entity Extraction | NER | Entity-F1 | 0.1800 | 0.6200 | 0.2875 | 0.2973 | 0.0231 | 0.6993 | |
| Relation Extraction | FinRE | Relation-F1 | 0.1613 | 0.0054 | 0.1083 | 0.0540 | 0.0100 | 0.5331 | |
| Multiple Choice | CFA | Weighted-F1 | 0.7700 | 0.2200 | 0.6697 | 0.5800 | 0.3993 | 0.7497 | |
| ACC | 0.7700 | 0.2400 | 0.6700 | 0.5800 | 0.3800 | 0.7500 | |||
| Summarization | EDTSUM | Rouge-1 | 0.1675 | 0.1566 | 0.1466 | 0.1467 | 0.0622 | 0.5254 | |
| Rouge-2 | 0.0556 | 0.0491 | 0.0433 | 0.0429 | 0.0085 | 0.3446 | |||
| Rouge-L | 0.1069 | 0.1060 | 0.0857 | 0.0930 | 0.0412 | 0.4705 | |||
| BLEU | 0.1192 | 0.1361 | 0.0999 | 0.1085 | 0.0592 | 0.4512 | |||
| Question Answering | Finqa | RMACC | 0.1037 | 0.0497 | 0.0270 | 0.0470 | 0.0110 | 0.2258 | |
| Convfinqa | RMACC | 0.2540 | 0.0953 | 0.0644 | 0.1477 | 0.0772 | 0.5053 | ||
| Stock Movement Prediction | DJIA | Weighted-F1 | 0.4241 | 0.3211 | 0.2744 | 0.5116 | 0.2171 | 0.4396 | |
| ACC | 0.4648 | 0.3291 | 0.4372 | 0.5101 | 0.2211 | 0.4749 |
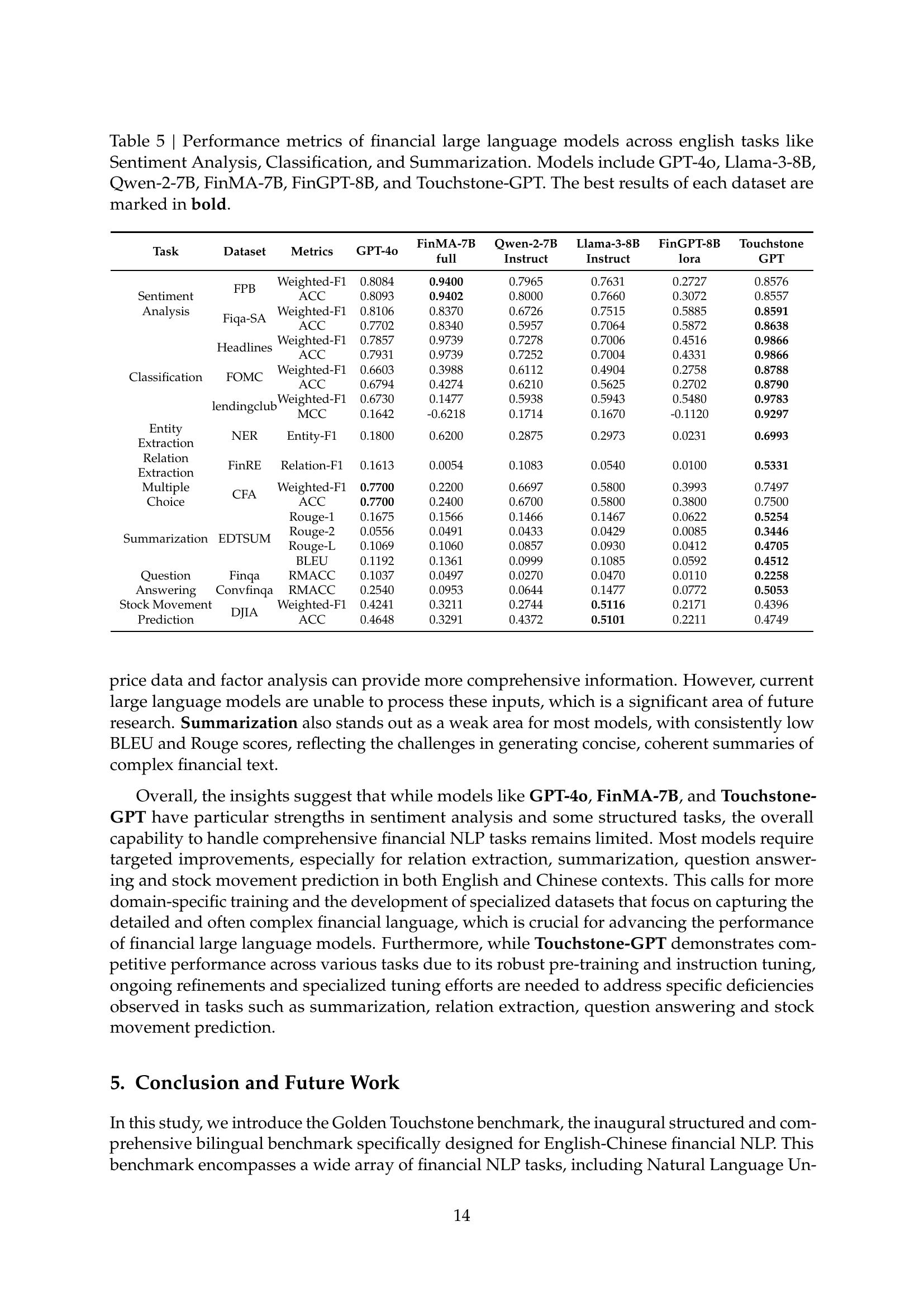
🔼 Table 5 presents a comprehensive comparison of various large language models’ performance on several English financial NLP tasks. The tasks assessed include Sentiment Analysis, Classification, Entity Recognition, Relation Extraction, Multiple Choice Question Answering, Summarization, and Stock Movement Prediction. Six prominent models are compared: GPT-40, Llama-3-8B, Qwen-2-7B, FinMA-7B, FinGPT-8B, and Touchstone-GPT. The table details the performance metrics (such as Weighted-F1, Accuracy, BLEU, ROUGE) for each model on each task and dataset. The best-performing model for each dataset is highlighted in bold, allowing for easy identification of relative strengths and weaknesses.
read the caption
Table 5: Performance metrics of financial large language models across english tasks like Sentiment Analysis, Classification, and Summarization. Models include GPT-4o, Llama-3-8B, Qwen-2-7B, FinMA-7B, FinGPT-8B, and Touchstone-GPT. The best results of each dataset are marked in bold.
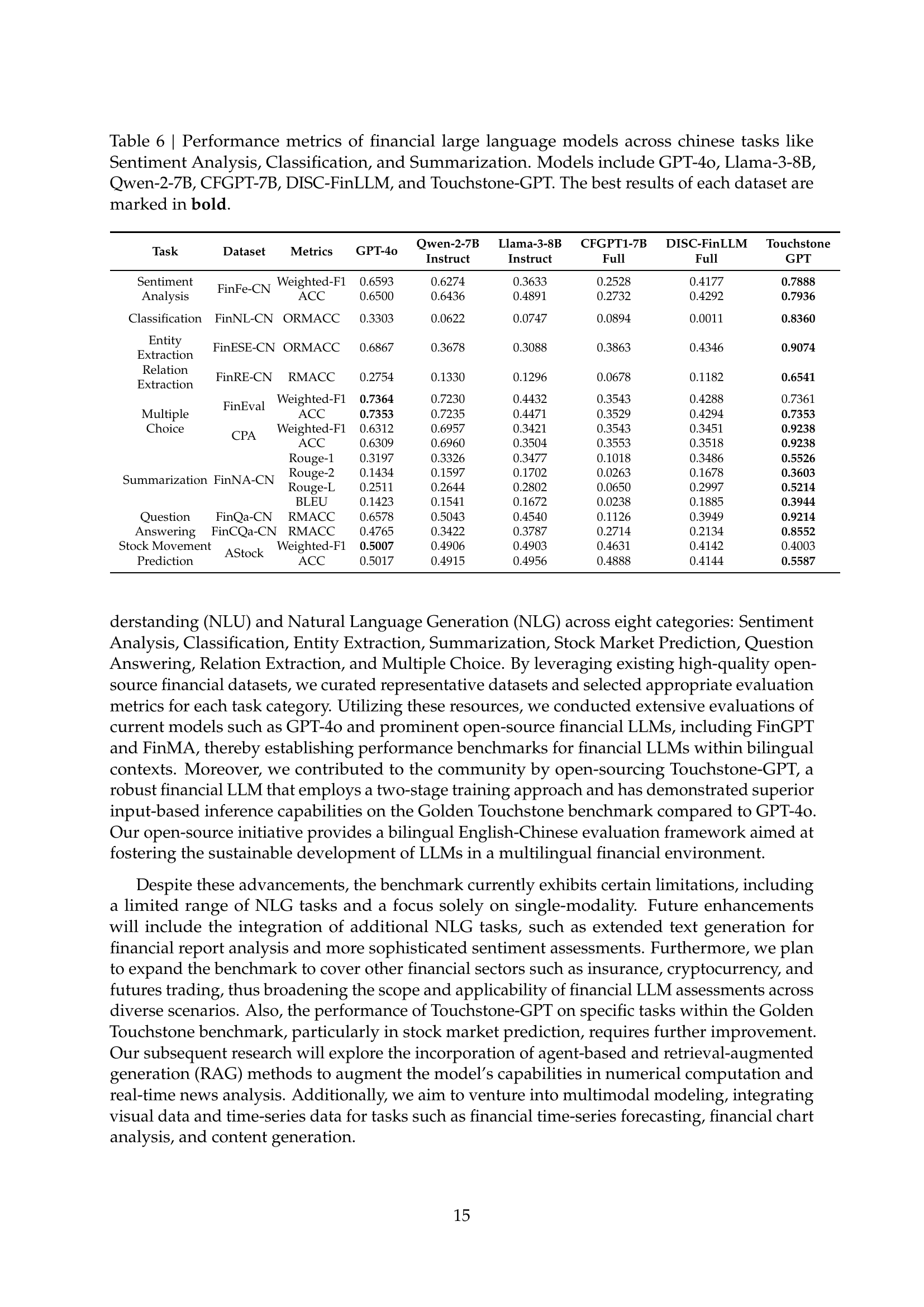
🔼 Table 6 presents a comprehensive evaluation of six different large language models (LLMs) on various Chinese financial tasks. These tasks include sentiment analysis, classification, entity extraction, relation extraction, multiple-choice question answering, summarization, and stock movement prediction. The models assessed are GPT-40, Llama-3-8B, Qwen-2-7B, CFGPT-7B, DISC-FinLLM, and Touchstone-GPT. The table displays performance metrics for each model on each task, with the best result for each dataset highlighted in bold. This allows for a direct comparison of the strengths and weaknesses of different LLMs in the context of Chinese financial language processing.
read the caption
Table 6: Performance metrics of financial large language models across chinese tasks like Sentiment Analysis, Classification, and Summarization. Models include GPT-4o, Llama-3-8B, Qwen-2-7B, CFGPT-7B, DISC-FinLLM, and Touchstone-GPT. The best results of each dataset are marked in bold.
| Task Type | Language | Instruction | Input | Output |
|---|---|---|---|---|
| Sentiment Analysis | English | What is the sentiment of the following financial post: Positive, Negative, or Neutral? | RT @tomhend777 $MU needs to hold here -Broken for now. Needs big flush. Still not technically oversold so now big bounce yet | neutral |
| Chinese | 以下是股民论坛中的一则股民评论,其中包含有感性的情感输出和理性的涨跌预测等内容…… | 判断的非常准确,几次T的相当稳妥! | 1 | |
| Classification | English | Review the sentence from a central bank’s communiqué…… | In their discussion of prices, participants indicated that data over the intermeeting period…… | neutral |
| Chinese | 把接下来输入的金融新闻分类为一个或多个与其描述内容相关的类别…… | 加拿大皇家银行:将Affirm Holdings(AFRM.O)目标价从175美元下调至127美元。 | 外国 公司 | |
| Entity Recognition | English | In the sentences extracted from financial agreements in U.S. SEC filings…… | There is a default in any agreement to which Borrower or any Guarantor is a party with a third party or parties…… | Borrower, PER |
| Chinese | 给定一段文本T,和文本所属的事件类型S,从文本T中抽取指定事件类型S的事件主体…… | 文本: 天龙新材关联担保事项未及时披露被监管佳士科技(300193)股东减持900万股 套现近2亿 事件类型: 信批违规 | 天龙新材 | |
| Relation Extraction | English | What is the relationship between Ivan Glasenberg and Glencore in the context of the input sentence…… | The persistent oversupply is “damaging the credibility of the industry,” Glencore CEO Ivan Glasenberg said in May. | owner_of |
| Chinese | 给定句子和其中的头尾实体,要求你预测头尾实体之间的关系…… | 头实体: ISIS 尾实体: 美军 句子: 美军已对ISIS发动<N>次空袭外资石油巨头欲撤离 | unknown |
🔼 This table presents examples of how instructions are constructed for various financial language tasks within the Golden Touchstone benchmark. Each example includes the task type, language (English or Chinese), the instruction given to the language model, the input data provided, and the expected output. This showcases the diversity of tasks and input formats used in the benchmark, and highlights the different complexities and nuances involved in each.
read the caption
Table 7: Examples of Instruction Construction for Various Financial Language Tasks, Categorized by Task Type and Language
| Task Type | Language | Instruction | Input | Output |
|---|---|---|---|---|
| Stock Movement Prediction | English | Please predict the next rise or fall of DJIA Adj based on the next input of the day’s 25 most popular news items…… | Top1:WikiLeaks demands answers after Google hands staff emails to US government…… | 1 |
| Chinese | 在考量了公司的相关公告之后,请根据新闻对股票数据的影响对该公司股票的表现进行分类…… | 公司董事长车成聚承诺自本公告日起未来六个月拟增持价值0.5-1.0亿公司股份…… | 0 | |
| Multiple Choice | English | Given a text T, and several options, according to the question posed in the text T…… | The inventory/sales ratio is most likely to be rising…… | C |
| Chinese | 给定一段文本T,和四个选项ABCD,根据文本T中提出的问题从四个选项中选择合适的多个选项作为答案…… | 下列选项中责任中心判断一项成本是否可控的条件有( )…… | A,B,D | |
| Summarization | English | You are given a text that consists of multiple sentences…… | PORTLAND, Ore., Feb. 17, 2021 /PRNewswire/ – Allied Market Research published a report, titled,“Matcha Tea Market By Product Type…… | Matcha Tea Market to Reach $4.48 Bn, Globally, by 2027 at 7.1%…… |
| Chinese | 请对根据接下来的输入的中文短新闻进行摘要总结,请直接开始总结,不需要输出任何解释 | 美港电讯APP 13日讯,法航荷航集团(Air France-KLM)已开始与波音(BA.N)和空客就可能成为该集团有史以来最大的飞机订单进行谈判…… | 波音空客将竞争法航荷航集团史上最大订单 | |
| Question Answering | English | Please answer the given financial question based on the context…… | on november 18 , 2014 , the company entered into a collateralized reinsurance agreement with kilimanjaro…… | The answer is:0.26685 |
| Chinese | 请根据下面提出的一个问题,问题后的材料内会有相应的答案…… | 江苏金沙地理信息股份有限公司公司上市事件对应的证券代码是什么?挖贝网10月9日,全国中小企业股转系统公告显示…… | 873361 |
🔼 This table compares the input formats or templates used by different large language models (LLMs) when processing data for evaluation on a financial benchmark. Different LLMs may require different input structures for optimal performance. The table shows the specific template for each model, highlighting variations in formatting for system prompts, user instructions, and model responses.
read the caption
Table 8: Comparison of Inference Templates Across Different Models for Dataset Evaluation
| Model | Template |
| GPT-4o | "<|im_start|>system{{system_prompt}}<|im_end|>\n" |
| "<|im_start|>user{{instruction}}{{input}}<|im_end|>\n" | |
| "<|im_start|>assistant\n" | |
| Qwen-2 | "<|im_start|>system{{system_prompt}}<|im_end|>\n" |
| "<|im_start|>user{{instruction}}{{input}}<|im_end|>\n" | |
| "<|im_start|>assistant\n" | |
| Llama-3 | "<|start_header_id|>system<|end_header_id|>" |
| "{{system_prompt}}<|eot_id|>\n" | |
| "<|start_header_id|>user<|end_header_id|>" | |
| "{{instruction}}{{input}}<|eot_id|>\n" | |
| "<|start_header_id|>assistant<|end_header_id|>\n" | |
| FinGPT | "Instruction:{{instruction}}" |
| "Input{{input}}\nAnswer:" | |
| FinMA | "Human:{{instruction}}{{input}}\n" |
| "Assistant:\n" | |
| CFGPT | "{{instruction}}{{input}}\n" |
| DISC-FinLLM | "<reserved_102> {{instruction}}{{input}}<reserved_103>" |
| Touchstone | "<|im_start|>system{{system_prompt}}<|im_end|>\n" |
| "<|im_start|>user{{instruction}}{{input}}<|im_end|>\n" | |
| "<|im_start|>assistant\n" |
🔼 This table presents a detailed analysis of four different financial NLP tasks: financial sentiment analysis using the FiQA-SA dataset; financial text classification using the LendingClub dataset; financial entity extraction using the NER dataset; and stock movement prediction using the DJIA dataset. For each task, it shows example inputs, labels (where applicable), and predictions made by several different large language models (LLMs), including GPT-40, Qwen-2, Llama-3, FinGPT, FinMA, and Touchstone-GPT. The purpose is to illustrate the strengths and weaknesses of various LLMs on these tasks, highlighting the differences in their performance and ability to handle nuanced financial language.
read the caption
Table 9: Detailed Case Study Analysis of Financial Sentiment Analysis on the FiQA-SA dataset, Financial Text Classification on the LendingClub dataset, Financial Entity Extraction on NER dataset, Stock Movement Prediction on DJIA dataset.
Full paper#