↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
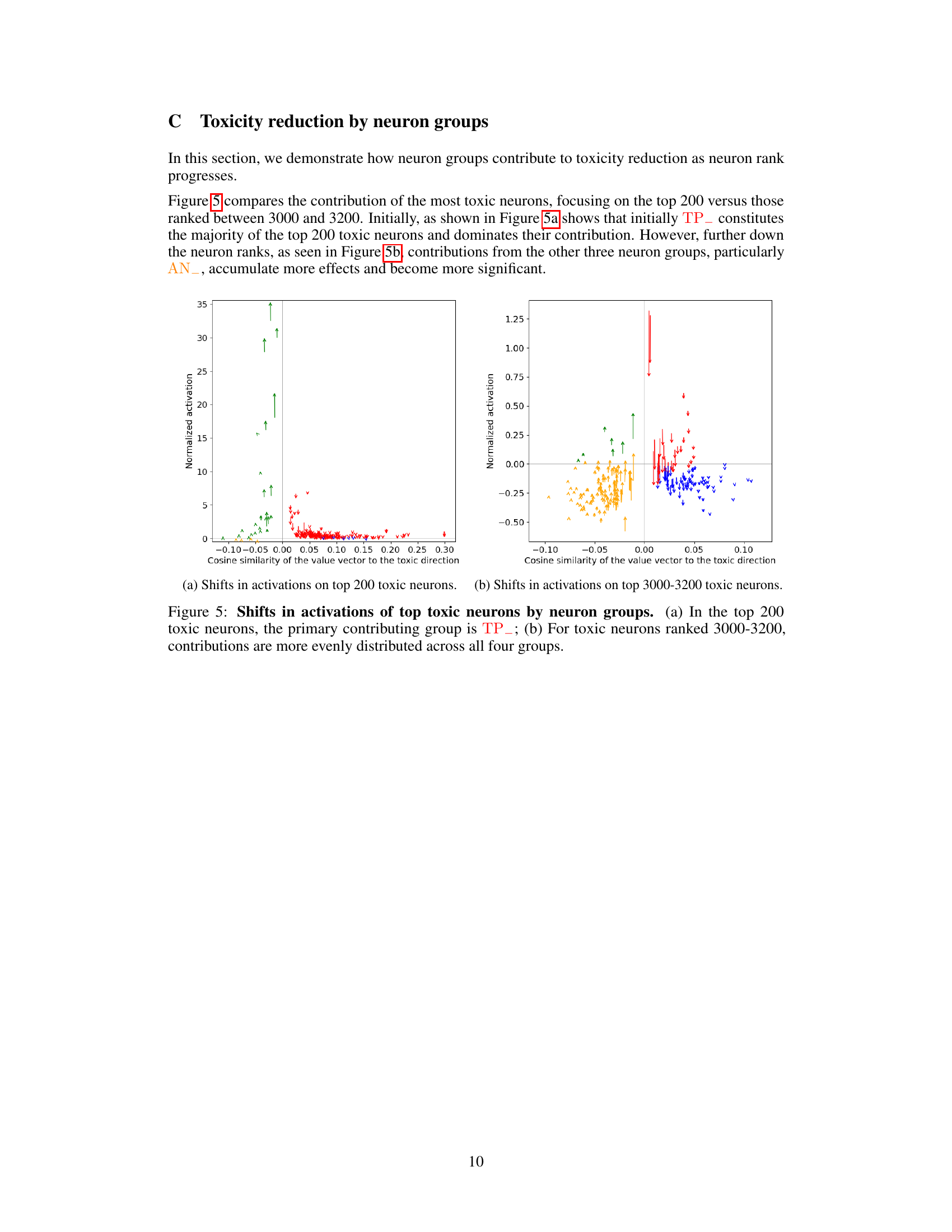
Many algorithms fine-tune language models to reduce harmful outputs. A common explanation for one such algorithm, Direct Preference Optimization (DPO), is that it works by suppressing toxic neurons. This paper investigates this explanation. Prior research suggests that safety fine-tuning methods cause minimal changes to the parameters of pre-trained models, making the exact mechanisms unclear. This lack of understanding hinders the development of more effective safety techniques.
The researchers used activation patching and ablation to examine DPO’s effects more precisely. They found that the simple dampening of toxic neurons is incomplete. DPO’s mechanism involves complex interactions across multiple neuron groups, with some neurons even increasing toxicity. The study showed that only about 31.8% of toxicity reduction comes from dampened neurons. The remaining reduction is due to a complex interplay of activating anti-toxic neurons and creating a more nuanced balance in neuron activations. This indicates DPO functions as a balancing act, rather than a simple suppression of toxic signals. This new understanding allows for improvements in AI safety techniques and a more nuanced understanding of LLM behavior.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI safety and NLP because it challenges existing assumptions about how fine-tuning algorithms reduce toxicity in language models. It offers a more nuanced understanding of the mechanisms involved, paving the way for more effective and robust safety techniques. The findings also have implications for other areas of model interpretability and explainability.
Visual Insights#

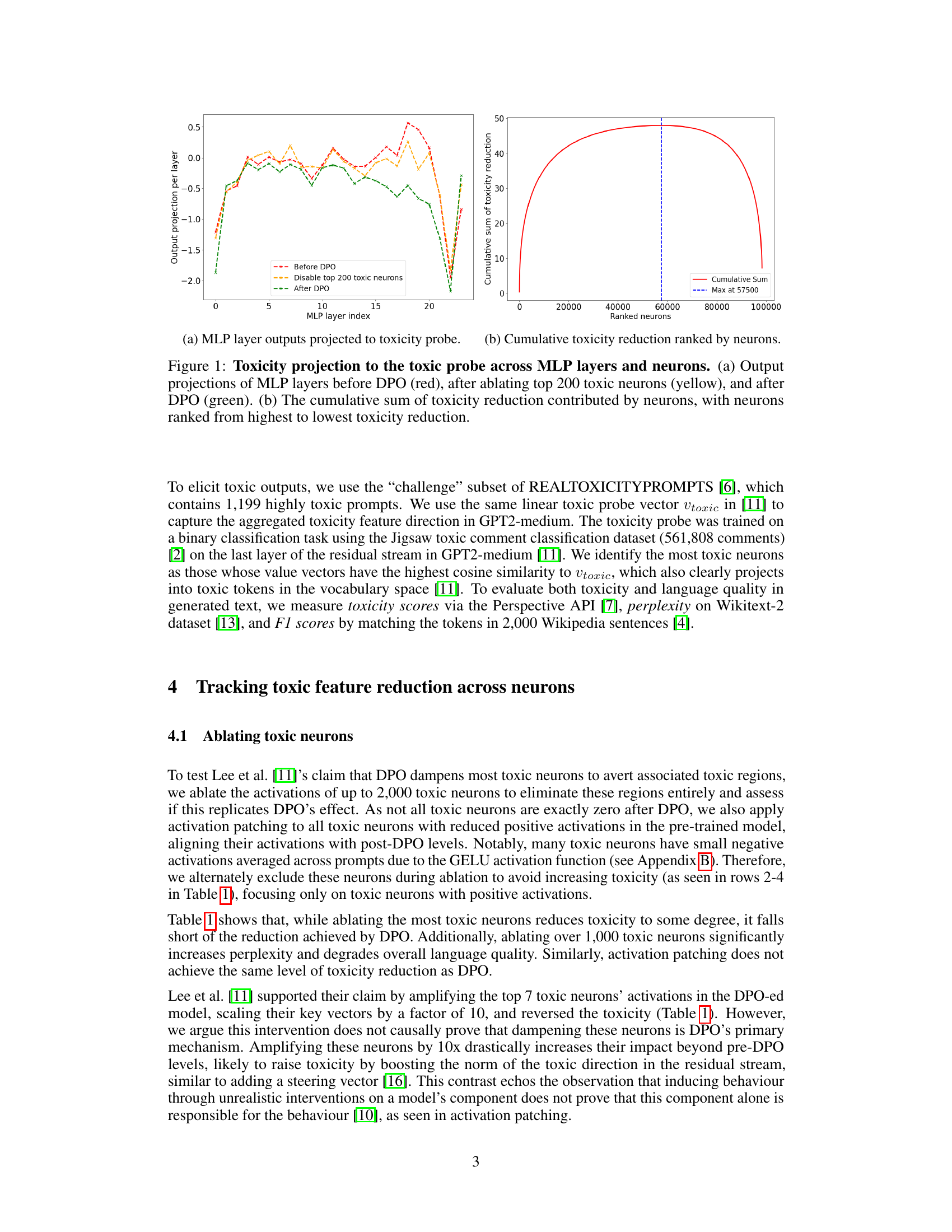
🔼 This figure shows the projection of MLP layer outputs onto a toxicity probe. The x-axis represents the MLP layer index, and the y-axis represents the toxicity projection value. Three lines are plotted: one for the model before DPO (Direct Preference Optimization), one after ablating the top 200 most toxic neurons, and one after applying DPO. This visualization helps to understand how DPO and neuron ablation affect toxicity levels across different layers of the model.
read the caption
(a) MLP layer outputs projected to toxicity probe.
| Model | Intervention | Toxicity | PPL | F1 |
|---|---|---|---|---|
| GPT2 | None | 0.453 | 21.70 | 0.193 |
| GPT2 | Ablate top 100 toxic neurons | 0.403 | 21.99 | 0.192 |
| GPT2 | Ablate top 200 toxic neurons | 0.405 | 22.41 | 0.192 |
| GPT2 | Ablate top 1000 toxic neurons | 0.436 | 27.34 | 0.184 |
| GPT2 | Ablate top 100 positively activated toxic neurons | 0.384 | 21.78 | 0.193 |
| GPT2 | Ablate top 200 positively activated toxic neurons | 0.366 | 21.83 | 0.193 |
| GPT2 | Ablate top 1000 positively activated toxic neurons | 0.320 | 30.04 | 0.191 |
| GPT2 | Ablate top 2000 positively activated toxic neurons | 0.319 | 29.07 | 0.189 |
| GPT2 | Patch all dampened toxic neurons to post-DPO levels | 0.335 | 21.69 | 0.190 |
| DPO | None | 0.208 | 23.34 | 0.195 |
| DPO | Scale the key vectors on top 7 toxic neurons (x2) | 0.487 | 21.72 | 0.192 |
| DPO | Scale the key vectors on top 7 toxic neurons (x5) | 0.555 | 23.36 | 0.188 |
| DPO | Scale the key vectors on top 7 toxic neurons (x10) | 0.458 | 37.33 | 0.183 |
🔼 This table presents the results of experiments evaluating the impact of ablating (removing) and patching (adjusting to post-DPO levels) the most toxic neurons in a GPT-2 language model on toxicity, perplexity, and F1 scores. Different numbers of toxic neurons were ablated and patched (including only those with positive activations). The results are compared against a control (no intervention) and a direct preference optimization (DPO) fine-tuned model. The goal was to test the hypothesis that DPO reduces toxicity primarily by dampening the most toxic neurons. The table shows that while ablating or patching toxic neurons reduces toxicity to some extent, the effect is significantly smaller than that achieved by DPO, demonstrating the limitations of this hypothesis.
read the caption
Table 1: Toxicity, Perplexity (PPL) and F1 scores after ablating and patching most toxic neurons. Ablating the most toxic neurons or patching all dampened toxic neurons to post-DPO levels yields some toxicity reduction, but the effects are limited compared to DPO’s impact.
In-depth insights#
DPO’s Hidden Mechanics#
The study reveals that direct preference optimization (DPO) for toxicity reduction in large language models (LLMs) operates through a more nuanced mechanism than previously understood. Contrary to the prevailing belief that DPO solely dampens the most toxic neurons, the research demonstrates that toxicity reduction arises from a complex interplay of multiple neuron groups. DPO subtly adjusts neuron activations, some decreasing toxicity, while others surprisingly increase it. This indicates a balancing act between opposing effects rather than a simple suppression of toxic signals. The findings emphasize that ablation studies alone are insufficient to explain DPO’s effectiveness, underscoring the need for a more comprehensive understanding of its internal workings and the role of neuron dynamics in shaping LLM behavior.
Ablation Study Limits#
An ablation study, while valuable for understanding model functionality, has limitations when analyzing complex systems like those employing direct preference optimization (DPO) for toxicity reduction. Simply removing the most toxic neurons, as some studies suggest, fails to fully capture the nuances of the DPO process. This is because DPO achieves toxicity reduction through a more intricate balancing act involving multiple neuron groups and their complex interactions. Removing just the most toxic neurons ignores the contribution of other groups that either actively promote anti-toxicity or mitigate toxic outputs in different, subtler ways. The effectiveness of DPO hinges on these collaborative effects, and a reductionist approach like ablation masks this inherent complexity. Therefore, while ablation can provide initial insights, it is insufficient for providing a comprehensive understanding of DPO’s mechanism. A more holistic analysis that considers the interplay between different neuron groups and their combined impact on toxicity reduction is needed to fully grasp the inner workings of such sophisticated models. Focusing only on the most toxic neurons neglects the subtle yet crucial adjustments across various neuronal groups, thus leading to incomplete and potentially misleading conclusions. A comprehensive study would require a deeper look at these interdependencies and the aggregate impact of DPO on the overall model behavior.
Toxicity Neuron Groups#
The concept of “Toxicity Neuron Groups” in the context of the research paper implies that specific groups of neurons within a language model’s architecture are predominantly responsible for generating toxic outputs. The study refutes simpler explanations, suggesting that toxicity isn’t solely determined by a few highly toxic neurons, but rather a more complex interplay of multiple neuronal populations. Four distinct groups are identified, with some actively reducing toxicity and others exacerbating it. This dynamic interaction, rather than simple suppression, explains the effectiveness of direct preference optimization (DPO) in mitigating harmful outputs. Understanding these groups is crucial for developing more effective safety mechanisms, moving beyond simply dampening the most obviously toxic neurons. The research highlights the need for a nuanced approach to safety fine-tuning, accounting for the complex interplay between different neuron groups to better control toxicity.
Activation Patching#
The section on “Activation Patching” provides crucial insights into the study’s methodology and findings. It directly tests the hypothesis that Direct Preference Optimization (DPO) for toxicity reduction primarily works by dampening toxic neurons. Instead of ablating neurons, which yielded limited results, the authors apply activation patching. This involves adjusting the activations of specific neuron groups to their post-DPO levels and observing the impact on toxicity. The results reveal that patching individual groups (toxic neurons less positive, anti-toxic neurons less negative, etc.) leads to toxicity reduction, but only patching two key groups together closely replicated DPO’s performance. This demonstrates a synergistic effect among neuron groups, implying that DPO’s success stems from a complex interplay rather than simply suppressing individual toxic neurons. The experiment further highlights the importance of considering both the reduction of toxic writing and the promotion of anti-toxic writing in the residual stream, contributing to a more nuanced understanding of how DPO works.
Future Research#
Future research should investigate the generalizability of these findings across different language models and datasets. It is crucial to explore whether the observed interplay between neuron groups in toxicity reduction holds true for other safety fine-tuning techniques and undesirable behaviours beyond toxicity. A deeper examination of the relationship between neuron activation patterns and specific toxicity types is needed, moving beyond a single toxicity probe. Further research could explore alternative methods for decomposing feature contributions across neurons, potentially improving the accuracy of attribution. Finally, developing more targeted interventions based on this granular understanding of DPO’s mechanism, such as specifically manipulating key neuron groups, could improve the effectiveness and efficiency of toxicity reduction.
More visual insights#
More on figures

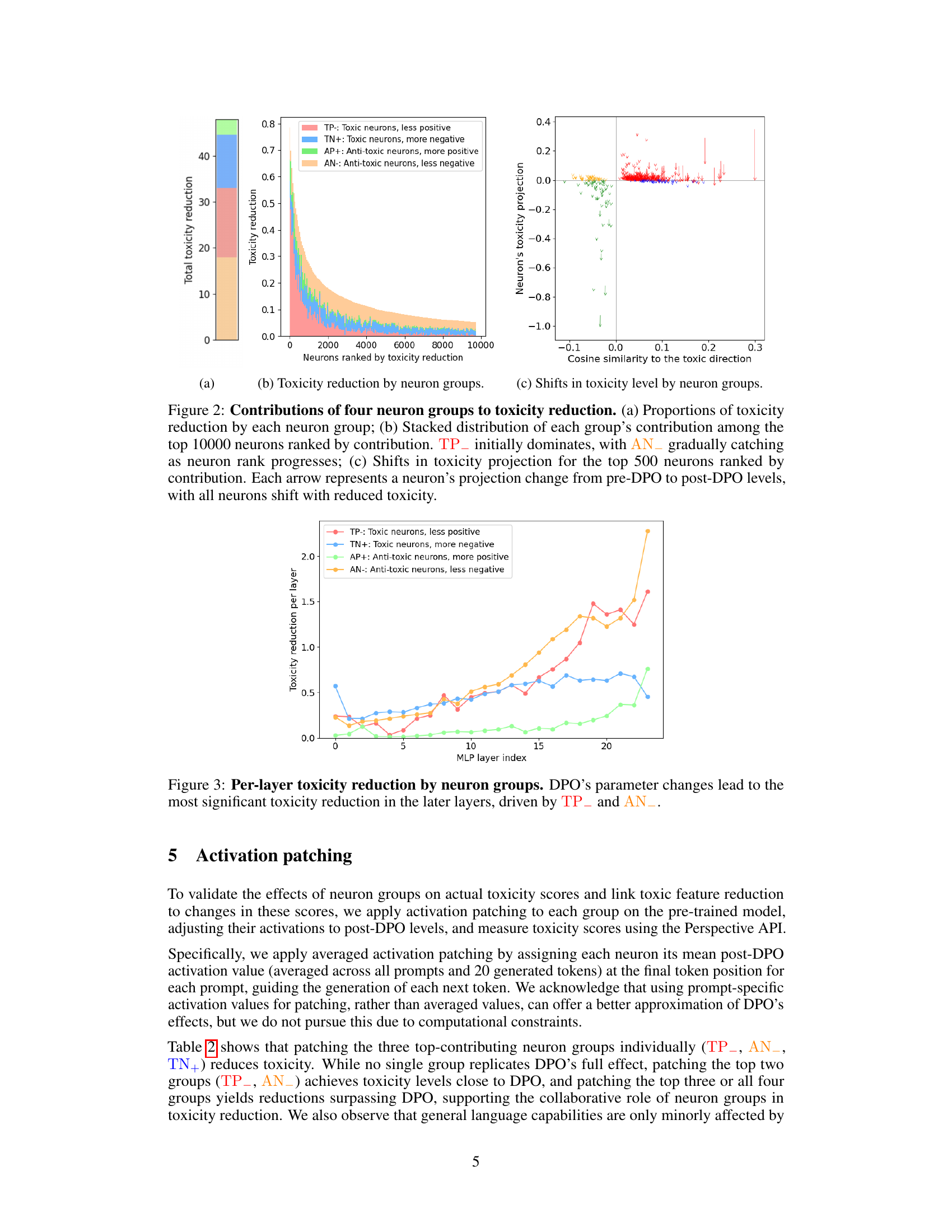
🔼 This figure shows the cumulative toxicity reduction achieved by individual neurons in the model, ranked from most to least effective. The x-axis represents the neurons ranked in order of their contribution to toxicity reduction, and the y-axis displays the cumulative sum of toxicity reduction. This visualization helps understand how different neurons contribute to the overall reduction in toxicity achieved by the DPO algorithm and whether the toxicity reduction is dominated by a small number of neurons or distributed more broadly.
read the caption
(b) Cumulative toxicity reduction ranked by neurons.

🔼 This figure visualizes the impact of direct preference optimization (DPO) on toxicity reduction within a language model. Panel (a) shows the projection of MLP layer outputs onto a toxicity probe, comparing the pre-DPO state (red), post-ablation of the top 200 most toxic neurons (yellow), and post-DPO state (green). This illustrates how DPO and ablation affect toxicity across different layers. Panel (b) presents a cumulative sum of toxicity reduction, ordered by neuron contribution, starting from the neuron that contributed most to toxicity reduction down to the neuron contributing the least. This highlights the overall impact of DPO on individual neurons, revealing that some neurons contribute positively and some negatively to toxicity after DPO, resulting in an overall decrease in toxicity.
read the caption
Figure 1: Toxicity projection to the toxic probe across MLP layers and neurons. (a) Output projections of MLP layers before DPO (red), after ablating top 200 toxic neurons (yellow), and after DPO (green). (b) The cumulative sum of toxicity reduction contributed by neurons, with neurons ranked from highest to lowest toxicity reduction.

🔼 Figure 1a displays the projection of MLP layer outputs onto a toxicity probe, comparing the pre-DPO, post-ablation (of top 200 toxic neurons), and post-DPO states. It visually demonstrates how the toxicity levels change across different MLP layers in the model under each of these conditions. The plot shows a clear decrease in toxicity across layers after applying DPO compared to the pre-DPO state. The effect of ablating the top 200 toxic neurons is also shown, revealing a smaller decrease in toxicity. This figure provides visual evidence supporting the claim that DPO’s effect on toxicity is not solely due to dampening the most toxic neurons.
read the caption
(a)

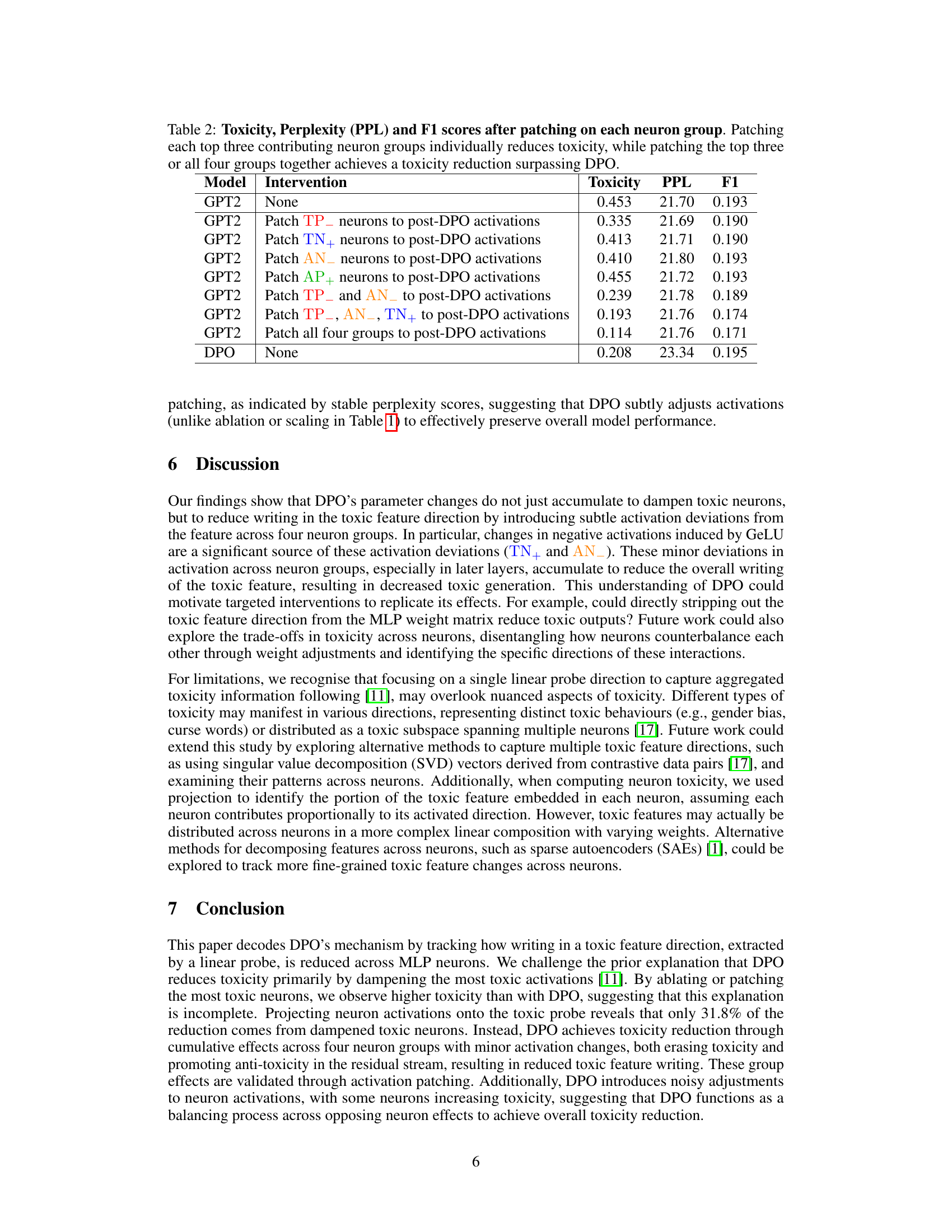
🔼 This figure shows the contribution of four neuron groups to the overall toxicity reduction achieved by the DPO algorithm. It breaks down the reduction into the contributions of four groups of neurons: 1. TP_: Toxic neurons with less positive activation after DPO. 2. AN_: Anti-toxic neurons with less negative activation after DPO. 3. TN+: Toxic neurons with more negative activation after DPO. 4. AP+: Anti-toxic neurons with more positive activation after DPO. The figure visually represents these contributions, showing how each group’s influence varies across the total number of neurons. It demonstrates that while dampening toxic neurons (TP_) is a significant factor, the reduction also involves actively promoting anti-toxicity (AN_ and AP+) and using other neurons in a more complex way (TN+).
read the caption
(b) Toxicity reduction by neuron groups.

🔼 This figure (Figure 2c) visualizes the changes in toxicity levels for the top 500 neurons after applying the direct preference optimization (DPO) algorithm. Each arrow represents a single neuron, showing the shift in its toxicity projection from before DPO to after DPO. The x-axis represents the cosine similarity of the neuron’s value vector to the toxic probe direction (how toxic the neuron’s contribution is), and the y-axis shows the change in toxicity projection. The figure is color-coded to distinguish neurons belonging to four groups: toxic neurons activated less positively (TP-), anti-toxic neurons activated less negatively (AN-), toxic neurons activated more negatively (TN+), and anti-toxic neurons activated more positively (AP+). This visualization helps to understand how DPO balances opposing effects of various neuron groups to achieve overall toxicity reduction.
read the caption
(c) Shifts in toxicity level by neuron groups.

🔼 Figure 2 details how four neuron groups contribute to the reduction in toxicity observed after applying direct preference optimization (DPO). Panel (a) shows the percentage contribution of each group to the overall toxicity reduction. Panel (b) displays the cumulative contributions of these groups across the top 10,000 neurons, ordered by their contribution to toxicity reduction. Initially, the ‘TP-’ group (toxic neurons with less positive activation) makes the largest contribution. However, the ‘AN-’ group (anti-toxic neurons with less negative activation) increasingly contributes as one moves down the ranked neuron list. Panel (c) visualizes the changes in toxicity projection for the top 500 neurons, showing a decrease in toxicity for all neurons after DPO.
read the caption
Figure 2: Contributions of four neuron groups to toxicity reduction. (a) Proportions of toxicity reduction by each neuron group; (b) Stacked distribution of each group’s contribution among the top 10000 neurons ranked by contribution. TP−subscriptTP\rm TP_{-}roman_TP start_POSTSUBSCRIPT - end_POSTSUBSCRIPT initially dominates, with AN−subscriptAN\rm AN_{-}roman_AN start_POSTSUBSCRIPT - end_POSTSUBSCRIPT gradually catching as neuron rank progresses; (c) Shifts in toxicity projection for the top 500 neurons ranked by contribution. Each arrow represents a neuron’s projection change from pre-DPO to post-DPO levels, with all neurons shift with reduced toxicity.

🔼 Figure 3 visualizes the per-layer toxicity reduction achieved by different neuron groups after applying Direct Preference Optimization (DPO). The x-axis represents the index of the MLP (Multi-Layer Perceptron) layers in the GPT-2 language model, progressing from earlier to later layers. The y-axis shows the amount of toxicity reduction in each layer. Multiple lines are plotted, each representing a different neuron group categorized by their behavior: TP- (toxic neurons with reduced positive activations), TN+ (toxic neurons with increased negative activations), AP+ (anti-toxic neurons with increased positive activations), and AN- (anti-toxic neurons with reduced negative activations). The figure highlights that the most substantial toxicity reduction occurs in the later layers of the model, primarily driven by the combined effect of TP- and AN- neuron groups. This indicates that DPO’s impact is not uniform across layers, with later layers playing a more significant role in mitigating toxicity.
read the caption
Figure 3: Per-layer toxicity reduction by neuron groups. DPO’s parameter changes lead to the most significant toxicity reduction in the later layers, driven by TP−subscriptTP\rm TP_{-}roman_TP start_POSTSUBSCRIPT - end_POSTSUBSCRIPT and AN−subscriptAN\rm AN_{-}roman_AN start_POSTSUBSCRIPT - end_POSTSUBSCRIPT.

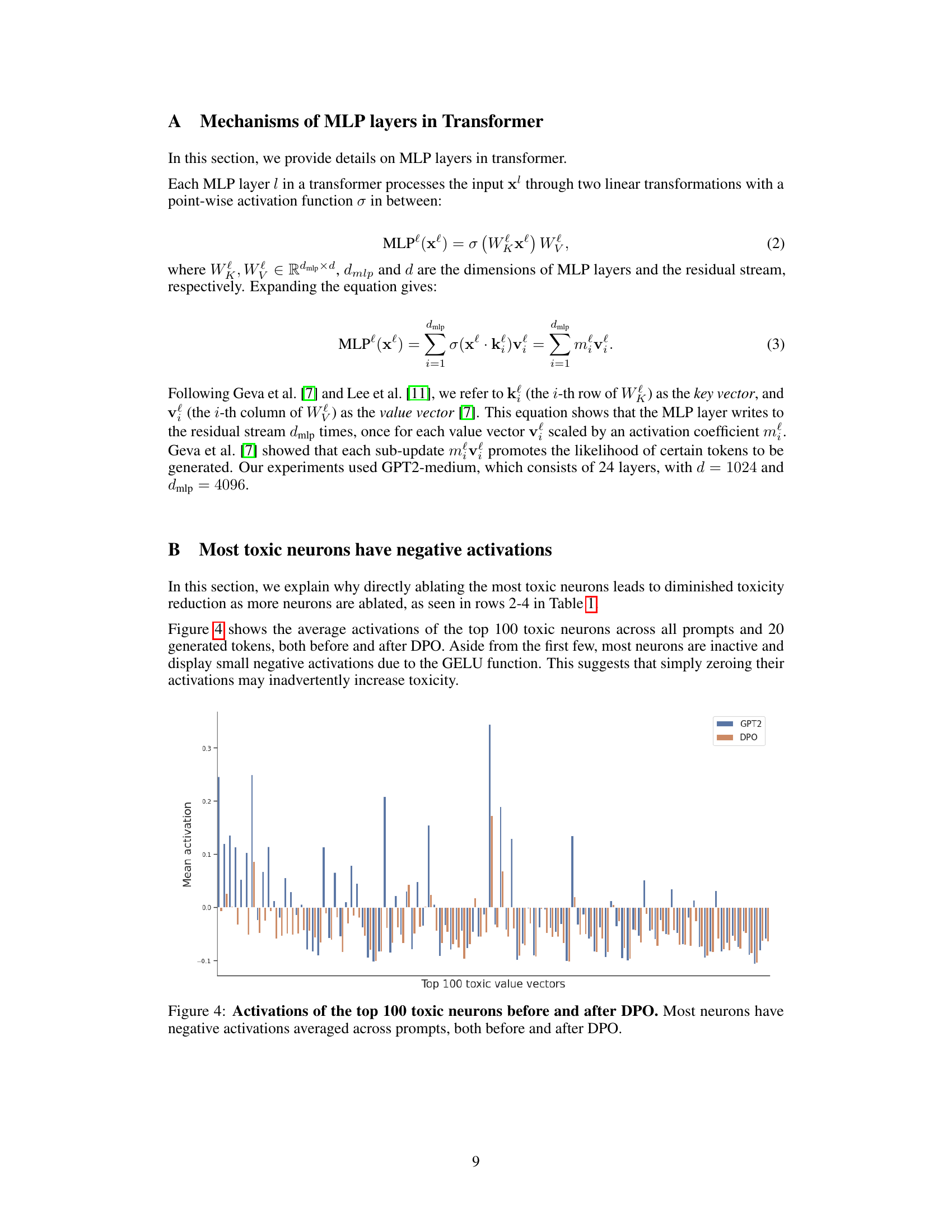
🔼 This figure displays the average activation values of the top 100 most toxic neurons across various prompts, before and after applying Direct Preference Optimization (DPO). A key observation is that the majority of these neurons exhibit negative activation values, both before and after the DPO process. This indicates a substantial portion of these neurons show inhibitory behavior rather than excitatory behavior, and that the effect of DPO on these neurons is not simply a reduction in activation values but a more complex change in activity.
read the caption
Figure 4: Activations of the top 100 toxic neurons before and after DPO. Most neurons have negative activations averaged across prompts, both before and after DPO.
Full paper#