↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-motion generation methods struggle with generating long and diverse human motion sequences, mainly due to issues like memory decay in models and insufficient alignment between text and motion. Existing approaches often rely on transformer-based architectures or diffusion models that have limitations when generating extended motions or understanding detailed directional instructions within prompts.
The paper proposes KMM, a novel method that addresses these issues. KMM uses a key frame masking strategy, based on local density and minimum distance to higher density, which helps Mamba focus on important actions and reduces memory decay. Further, it employs a contrastive learning paradigm to enhance the alignment between text and motion. Experiments on BABEL dataset show KMM’s superiority over state-of-the-art methods in terms of FID and parameter efficiency. The introduction of BABEL-D, a new benchmark focusing on directional instructions, further validates KMM’s improved text-motion alignment.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances extended motion generation, a crucial area in computer vision and animation. By addressing memory decay and improving text-motion alignment in the Mamba architecture, it paves the way for more realistic and nuanced human motion synthesis. The proposed KMM architecture and contrastive learning approach are valuable contributions that can be applied to other sequence modeling tasks. The introduction of a new benchmark dataset further enhances the value of this work.
Visual Insights#

🔼 This figure demonstrates the limitations of existing extended motion generation methods in handling directional instructions within text prompts. The top row shows examples of how previous models (PriorMDM, FlowMDM, TEACH) incorrectly interpret directional instructions like ‘raise left arm’ or ‘kick right leg,’ resulting in inaccurate or opposite movements. The bottom row shows the improved accuracy and correctness of the proposed KMM model under the same conditions. KMM’s enhanced text-motion alignment allows the model to better understand and respond correctly to these directions.
read the caption
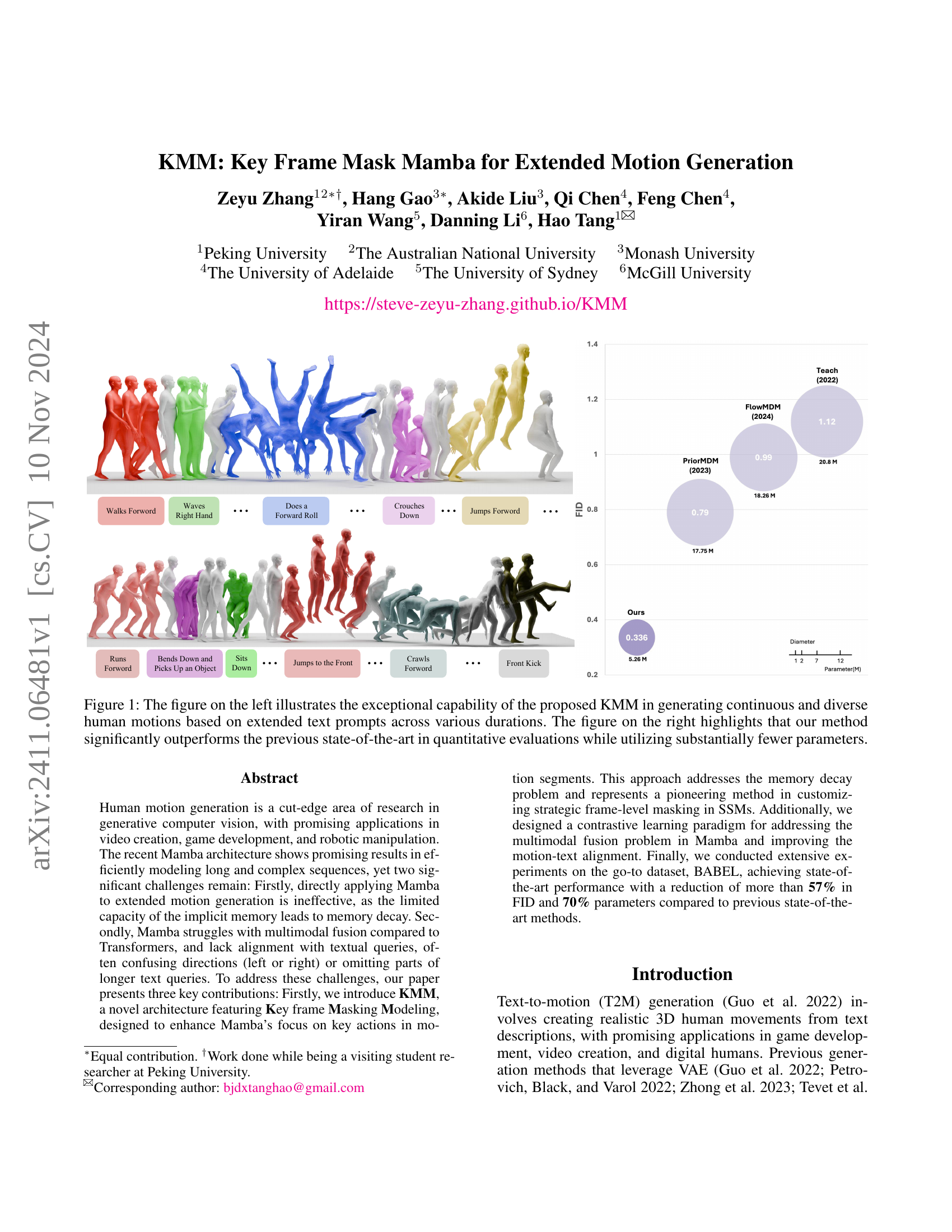
Figure 1: The figure illustrates that previous extended motion generation methods often struggle with directional instructions, leading to incorrect motions. In contrast, our proposed KMM, with enhanced text-motion alignment, effectively improves the model’s understanding of text queries, resulting in more accurate motion generation.
| Models | R-precision ↑ | FID ↓ | Diversity → | MM-Dist ↓ |
|---|---|---|---|---|
| Ground Truth | 0.715±0.003 | 0.00±0.00 | 8.42±0.15 | 3.36±0.00 |
| TEACH | 0.460±0.000 | 1.12±0.00 | 8.28±0.00 | 7.14±0.00 |
| TEACH w/o Spherical Linear Interpolation | 0.703±0.002 | 1.71±0.03 | 8.18±0.14 | 3.43±0.01 |
| TEACH∗ | 0.655±0.002 | 1.82±0.02 | 7.96±0.11 | 3.72±0.01 |
| PriorMDM | 0.430±0.000 | 1.04±0.00 | 8.14±0.00 | 7.39±0.00 |
| PriorMDM w/ Trans. Emb | 0.480±0.000 | 0.79±0.00 | 8.16±0.00 | 6.97±0.00 |
| PriorMDM w/ Trans. Emb & geo losses | 0.450±0.000 | 0.91±0.00 | 8.16±0.00 | 7.09±0.00 |
| PriorMDM∗ | 0.596±0.005 | 3.16±0.06 | 7.53±0.11 | 4.17±0.02 |
| PriorMDM w/ PCCAT and APE | 0.668±0.005 | 1.33±0.04 | 7.98±0.12 | 3.67±0.03 |
| MultiDiffusion | 0.702±0.005 | 1.74±0.04 | 8.37±0.13 | 3.43±0.02 |
| DiffCollage | 0.671±0.003 | 1.45±0.05 | 7.93±0.09 | 3.71±0.01 |
| T2LM | 0.589±0.000 | 0.66±0.00 | 8.99±0.00 | 3.81±0.00 |
| FlowMDM | 0.702±0.004 | 0.99±0.04 | 8.36±0.13 | 3.45±0.02 |
| Motion Mamba | 0.490±0.000 | 0.76±0.00 | 8.39±0.00 | 4.97±0.00 |
| KMM (Ours) | 0.666±0.001 | 0.34±0.01 | 8.67±0.14 | 3.11±0.01 |
🔼 Table 1 compares the performance of the proposed KMM method against several state-of-the-art long-motion generation techniques. The comparison uses the BABEL dataset and focuses on metrics such as R-precision (higher is better), FID (lower is better), diversity, and multi-modal distance (lower is better). The table highlights that KMM achieves the best performance across all metrics, indicating superior motion generation quality. Note that some prior results were reproduced by the FlowMDM method. The table also points out that the original papers for certain methods did not provide error bars (denoted by ±0.000 or ±0.00), making exact comparisons less precise in those cases.
read the caption
Table 1: This table presents a comparison between our method and previous long motion generation techniques on the BABEL dataset (Punnakkal et al. 2021). The results show that our method outperforms the others, demonstrating superior performance. The right arrow →→\rightarrow→ indicates that closer values to real motion are better. Bold and underline highlight the best and second-best results, respectively. Additionally, ∗*∗ denotes results reproduced by FlowMDM. For results with ±0.000plus-or-minus0.000\pm{0.000}± 0.000 or ±0.00plus-or-minus0.00\pm{0.00}± 0.00, the corresponding paper does not provide error bars.
In-depth insights#
KMM: Core Idea#
The core idea behind KMM revolves around addressing two critical limitations of the Mamba architecture in extended motion generation: memory decay and poor text-motion alignment. To tackle memory decay, KMM introduces key frame masking, a novel density-based method to strategically mask less important frames, allowing the model to focus on key actions and prevent information loss during long sequences. This contrasts with prior methods that used random masking, which is less efficient for long-term dependencies. Simultaneously, KMM improves text-motion alignment by employing contrastive learning to dynamically learn text embeddings, enhancing alignment between text and motion. This addresses Mamba’s inherent struggles with multimodal fusion and improves understanding of directional and nuanced instructions. Combining strategic key frame masking with contrastive learning forms the core innovation of KMM, enabling the generation of more accurate, diverse, and coherent extended motion sequences, significantly surpassing previous state-of-the-art methods.
KeyFrame Masking#
The proposed Key Frame Masking strategy tackles the challenge of memory decay in Mamba models for extended motion generation. Instead of random masking, it employs a density-based approach, identifying key frames within the latent motion space by calculating local density and minimum distances to higher density regions. This intelligent selection of frames ensures that the model focuses its learning on the most crucial motion information, thereby mitigating the memory constraints and enabling coherent generation of long sequences. The method’s effectiveness stems from its ability to selectively mask out less significant frames, allowing for more efficient learning and utilization of the implicit memory. This targeted masking approach, as opposed to random masking, is a key innovation, providing a more robust and effective solution for handling extended motions within the limitations of the Mamba architecture. Its effectiveness is demonstrated in comparison with other masking techniques such as random masking, significantly improving the model’s capability to generate high-quality, long sequences.
Text-Motion Alignment#
The research paper section on “Text-Motion Alignment” tackles a critical challenge in generating human motion from text descriptions: effectively bridging the semantic gap between text and motion representations. Existing methods often rely on frozen CLIP encoders, creating a mismatch between text features and the motion generation model’s latent space. This paper innovatively proposes a contrastive learning paradigm to directly learn this alignment, reducing the reliance on pre-trained encoders. By dynamically learning text embeddings, the approach improves text-motion coherence and ensures that generated motions accurately reflect the input text’s instructions, especially concerning directional cues often misinterpreted by previous models. This is a significant advancement, as it addresses a fundamental limitation impacting the realism and accuracy of text-driven motion synthesis. The approach is validated through experiments, showcasing improved performance in handling complex and directional prompts and a significant reduction in common misalignments between generated motion and the intended text description.
Extended Motion#
The concept of “Extended Motion” in the context of this research paper likely refers to the generation of long, complex, and diverse human motion sequences. The paper tackles challenges associated with generating such motions, namely memory decay in recurrent models and poor text-motion alignment in multimodal models. Addressing these challenges is key to achieving realistic and coherent extended motion generation. The authors propose innovations like Key Frame Masking Modeling (KMM) to mitigate memory issues, and a contrastive learning paradigm for improved text-motion alignment. These techniques aim to enable more nuanced and accurate motion generation based on comprehensive text instructions, resulting in more versatile and robust outputs that surpass previous state-of-the-art methods. The focus on extended motion generation highlights the limitations of existing approaches when handling long-range dependencies and complex multimodal data, making the presented work a significant contribution towards realistic and controllable human animation.
Future of KMM#
The future of KMM hinges on addressing its current limitations and exploring new avenues for improvement. Extending the model’s capacity to handle even longer and more complex motion sequences is crucial. This could involve exploring more efficient memory management techniques or architectural modifications. Improving the model’s ability to understand nuanced and ambiguous textual instructions is another key area. This might involve integrating more advanced natural language processing (NLP) techniques or incorporating a larger, more diverse training dataset. Enhancing the model’s robustness to noisy or incomplete input data would also be beneficial, making it more practical for real-world applications. Finally, research into the explainability of KMM’s predictions is warranted. Understanding how the model arrives at its generated motions can lead to improvements in its accuracy and controllability. This combination of improvements to robustness, understanding, and explainability will greatly expand KMM’s potential applications.
More visual insights#
More on figures

🔼 This figure provides a detailed breakdown of the KMM method, showing its three key components: (a) Key Frame Mask Modeling, which uses local density and minimum distance calculations to strategically mask key frames, enhancing the model’s focus on crucial actions; (b) the overall architecture of the masked bidirectional Mamba, illustrating how the masking strategy is integrated into the model’s structure; and (c) Text-Motion Alignment, demonstrating the contrastive learning approach that enhances the model’s ability to align text and motion data, improving the accuracy and relevance of generated motions.
read the caption
Figure 2: The figure demonstrates our novel method from three different perspectives: (a) illustrates the key frame masking strategy based on local density and minimum distance to higher density calculation. (b) showcases the overall architecture of the masked bidirectional Mamba. (c) demonstrates the text-to-motion alignment, highlighting the process before and after alignment.

🔼 This figure depicts the user interface of a study involving 50 participants who assessed motion sequences generated by four different methods: TEACH, PriorMDM, FlowMDM, and the proposed KMM method. The participants evaluated the generated motions based on four criteria: text-motion alignment (how well the motion matched the text description), robustness (how realistic and natural the motion appeared), diversity (how varied and interesting the motions were), and usability (how suitable the motions would be for real-world applications, such as in video games or animation). The text prompts used to generate the motion sequences were randomly selected and combined from the HumanML3D (Guo et al., 2022) and BABEL (Punnakkal et al., 2021) datasets, ensuring a variety of motion types and descriptions.
read the caption
Figure 3: The figure shows the user study interface where 50 participants evaluated motion sequences generated by TEACH, PriorMDM, FlowMDM, and KMM, focusing on text-motion alignment, robustness, diversity, and usability. The text prompt are randomly extracted and combined from the HumanML3D (Guo et al. 2022) and BABEL (Punnakkal et al. 2021) test set.

🔼 Figure 5 presents a qualitative comparison of extended motion generation results between KMM and three state-of-the-art methods (TEACH, PriorMDM, and FlowMDM). Three example text prompts of varying complexity are used as input. For each prompt, the generated motion sequences from each method are displayed. The visualization clearly demonstrates KMM’s superior performance in accurately interpreting complex instructions and producing more realistic and nuanced motions compared to the other methods.
read the caption
Figure 4: The figure demonstrates a qualitative comparison between the previous state-of-the-art method in extended motion generation and our KMM. The qualitative results show that our method significantly outperforms others in handling complex text queries and generating more accurate corresponding motions.

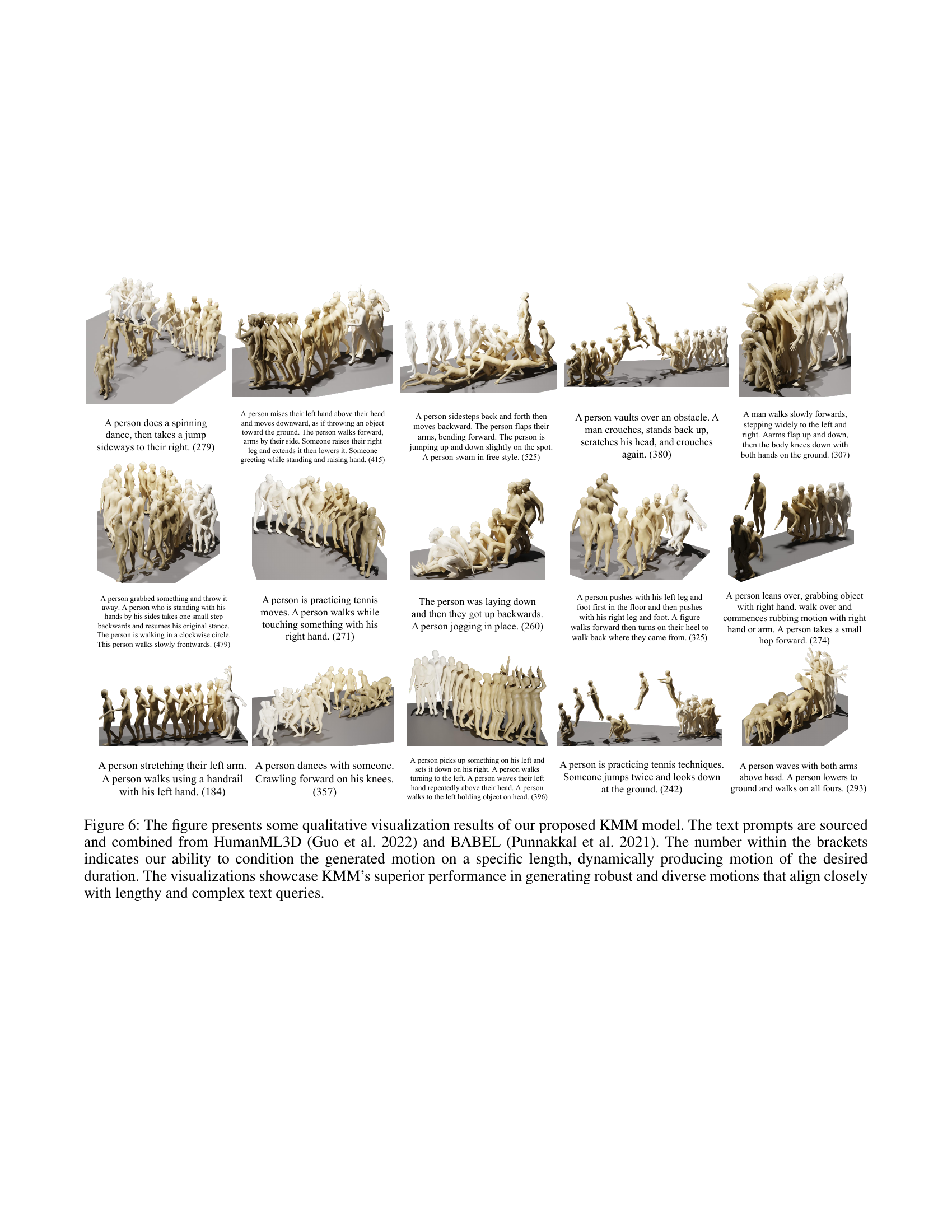
🔼 This figure showcases qualitative results from the KMM model, demonstrating its ability to generate diverse and robust motions from complex, lengthy text prompts. The prompts are sourced from the HumanML3D and BABEL datasets. The numbers in parentheses after each prompt indicate the length of the generated motion sequence (in frames), highlighting the model’s ability to produce motions of specified durations. The visualizations highlight KMM’s superior performance against other state-of-the-art methods in accurately and dynamically generating human motion that precisely aligns with the input text instructions.
read the caption
Figure 5: The figure presents some qualitative visualization results of our proposed KMM model. The text prompts are sourced and combined from HumanML3D (Guo et al. 2022) and BABEL (Punnakkal et al. 2021). The number within the brackets indicates our ability to condition the generated motion on a specific length, dynamically producing motion of the desired duration. The visualizations showcase KMM’s superior performance in generating robust and diverse motions that align closely with lengthy and complex text queries.
More on tables
| Models | R-precision ↑ | FID ↓ | Diversity → | MM-Dist ↓ |
|---|---|---|---|---|
| Ground Truth | 0.438±0.000 | 0.02±0.00 | 8.46±0.00 | 3.71±0.00 |
| PriorMDM | 0.334±0.015 | 6.82±0.76 | 7.27±0.33 | 7.44±0.12 |
| KMM w/o Alignment | 0.484±0.007 | 5.50±0.15 | 8.44±0.15 | 3.48±0.03 |
| KMM (Ours) | 0.538±0.009 | 3.86±0.14 | 8.04±0.14 | 2.72±0.03 |
🔼 Table 2 presents a comparison of the proposed KMM model against state-of-the-art methods on the BABEL-D benchmark dataset, focusing on extended motion generation tasks involving directional instructions. The BABEL-D dataset is specifically designed to evaluate performance on text prompts that include directional cues (like ’left’ or ‘right’). The table shows quantitative metrics (R-precision, FID, Diversity, MM-Dist) to assess the quality and alignment of the generated motions with the given text prompts. Higher R-precision and lower FID, Diversity, and MM-Dist indicate better results. The arrows next to each metric indicate the direction of improvement, with values closer to those of real human motions being preferred. The best and second-best results for each metric are highlighted in bold and underlined font, respectively, to clearly indicate the superior performance of the proposed KMM model in handling directional text instructions within extended motion generation scenarios.
read the caption
Table 2: This table compares our method with previous long motion generation techniques on the BABEL-D benchmark. The results demonstrate that our method excels in handling directional instructions, highlighting the advantages of our proposed text-motion alignment approach. The right arrow →→\rightarrow→ indicates that closer values to real motion are better. Bold and underline highlight the best and second-best results, respectively.
| Models | R-precision ↑ | FID ↓ | Diversity → | MM-Dist ↓ |
|---|---|---|---|---|
| Ground Truth | 0.715± 0.003 | 0.00± 0.00 | 8.42± 0.15 | 3.36± 0.00 |
| KMM w/ random masking | 0.649± 0.001 | 0.48± 0.01 | 8.80± 0.06 | 3.30± 0.01 |
| KMM w/o Alignment | 0.671± 0.001 | 0.40± 0.01 | 8.57± 0.05 | 3.21± 0.01 |
| KMM (Ours) | 0.666± 0.001 | 0.34± 0.01 | 8.67± 0.14 | 3.11± 0.01 |
🔼 Table 3 presents an ablation study assessing the impact of different components of the proposed KMM model on its performance. The study compares the full KMM model to versions that omit either the key frame masking or the text-motion alignment. The results demonstrate that both components are essential for achieving optimal performance in generating realistic and accurate human motion sequences. The table quantitatively evaluates these variations across metrics such as R-precision, FID (Frechet Inception Distance), Diversity, and MultiModal Distance, with higher values on R-precision and Diversity, and lower values on FID and MultiModal distance representing better results. Arrows indicate the direction of improvement, and bold/underlined values show the best and second-best performance, respectively.
read the caption
Table 3: This table illustrates the ablation results from different aspects of the proposed method. The results show that both the key frame masking strategy and text-motion alignment contribute to the overall performance. The right arrow →→\rightarrow→ indicates that closer values to real motion are better. Bold and underline highlight the best and second-best results, respectively.
Full paper#