↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current language agents for web-based tasks often use reactive approaches, which are limited and risky due to the irreversibility of actions on live websites. Advanced planning, like tree search, is hindered by these safety concerns and practicality. The challenge is creating a safe and effective way to enable language agents to perform complex multi-step actions.
This paper proposes WEB-DREAMER, a novel approach using large language models (LLMs) as world models to simulate the effects of actions before executing them on a real website. The LLM simulates possible outcomes for each action, allowing the agent to safely explore potential solutions and choose the optimal action. Their experiments demonstrated that WEB-DREAMER substantially outperforms reactive approaches, highlighting the potential of using LLMs as world models in complex and dynamic web environments.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on web agents and AI planning because it introduces a novel paradigm using LLMs as world models for efficient and safe web navigation. It opens avenues for optimizing LLMs for world modeling in complex environments and developing model-based speculative planning for language agents, significantly advancing automated web interaction research.
Visual Insights#

🔼 Figure 1 illustrates three different approaches for web agents to solve a problem framed as a search. Each node in the diagrams represents a webpage. (a) shows a reactive agent making locally optimal choices without any planning, often resulting in poor outcomes. (b) demonstrates a tree search agent using real website interactions. This approach allows exploration of multiple paths and backtracking (dashed lines), but this is often unrealistic on real websites due to irreversible actions like purchasing. (c) shows a model-based planning agent, which uses simulations (cloud-bordered nodes) to predict the outcomes of different actions before performing them. The simulation helps to find the best actions, reducing interactions and improving effectiveness. Only one level of simulations is shown for clarity. Light nodes represent unexplored pages, green checks indicate successful simulations, and red crosses show unsuccessful ones.
read the caption
Figure 1: Schematic illustration of different strategies for web agents formulated as a search problem. Each node represents a webpage. (a) Reactive: The agent selects locally optimal actions without forward planning, often leading to suboptimal outcomes. (b) Tree search with real interactions: The agent explores multiple paths through active website navigation and permits backtracking (indicated by dashed arrows). However, in real-world websites, backtracking is often infeasible due to the prevalence of irreversible actions. (c) Model-based planning: The agent simulates potential outcomes (illustrated by cloud-bordered nodes) to determine optimal actions prior to real-world execution, thus minimizing actual website interactions while maintaining effectiveness. For visual clarity, only one-step simulated outcomes are depicted. Faded nodes indicate unexplored webpages, while green checkmarks and red crosses denote successful and unsuccessful outcomes, respectively.
| Action Type | Description |
|---|---|
| click [] | Click on . |
| hover [] | Hover over . |
| type [] [] | Type into . |
| press [] | Press a key combo. |
| goto [] | Go to . |
| go_back | Click back. |
| go_forward | Click forward. |
| new_tab | Open a new tab. |
| tab_focus [] | Focus on the i-th tab. |
| tab_close | Close current tab. |
| scroll [] | Scroll up or down. |
| stop [] | End with an output. |
🔼 This table details the various actions a web agent can perform within the VisualWebArena environment, a benchmark used for evaluating web agents’ abilities. Each action is categorized and described, providing a comprehensive list of the agent’s interaction capabilities with web pages. Understanding this action space is essential for interpreting the results of experiments within VisualWebArena, as it defines the range of possible actions the agent can take to achieve a goal on a webpage.
read the caption
Table 1: Action space for web navigation defined in VisualWebArena (Koh et al., 2024a).
In-depth insights#
LLM as World Model#
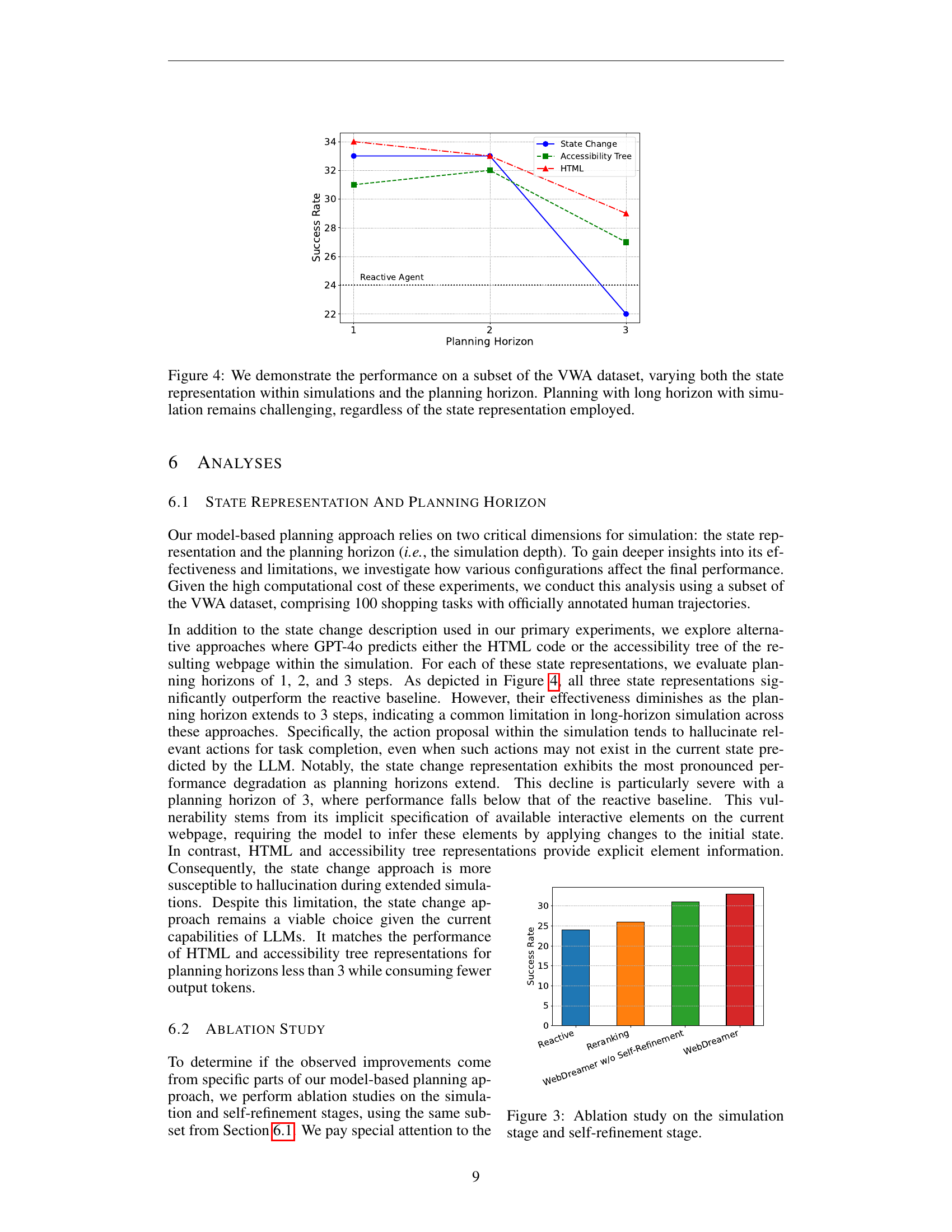
The core concept of employing LLMs as world models for complex tasks like web navigation presents a paradigm shift in AI planning. Instead of directly interacting with the often unpredictable and risky real-world web, the LLM simulates the environment, anticipating the consequences of actions before execution. This approach mitigates the inherent risks associated with live web interactions, such as irreversible actions or unintended consequences. The LLM’s vast pre-trained knowledge base, encompassing website structures and functionalities, proves crucial for accurate simulation. The method’s efficacy, as demonstrated by its improvements over reactive baselines, underscores the potential of this novel approach. However, limitations exist; long-horizon planning remains challenging, due to the complexities of the dynamic web environment and potential inaccuracies in multi-step simulations. Further research into optimizing LLMs specifically for world modeling in such environments and refining the planning algorithms are crucial next steps to overcome these limitations and fully unlock the potential of this innovative approach.
Model-Based Planning#
Model-based planning, as discussed in the research paper, presents a significant advancement in the field of AI, especially for web agents. Traditional reactive and tree-search methods for web agents suffer from limitations such as safety risks (irreversible actions) and suboptimal outcomes. Model-based planning cleverly mitigates these issues by leveraging Large Language Models (LLMs) as world models. LLMs inherently possess vast knowledge about website structures and functionalities; WEB-DREAMER uses this capability to simulate the consequences of actions, evaluating potential outcomes before real-world interactions. This speculative planning significantly enhances safety and performance. The study highlights that while tree search strategies might be superior in controlled environments, model-based planning, using LLMs, offers a more practical and safer approach for complex, dynamic real-world web scenarios. The successful implementation of WEB-DREAMER on representative benchmarks like VisualWebArena and Mind2Web-live demonstrates the viability of LLMs as world models and opens exciting research avenues for optimizing LLMs for world modeling and expanding model-based planning for language agents.
WebAgent Benchmarks#
Web agent benchmarks are crucial for evaluating the progress and capabilities of AI-powered systems designed to interact with websites. A good benchmark should encompass a diverse range of tasks, websites, and interaction modalities, reflecting the complexities of real-world web navigation. This diversity is essential to assess the generalizability and robustness of web agents, ensuring they are not overly specialized to specific websites or tasks. Key aspects to consider include the complexity of the tasks, the variety of website structures (e.g., different layouts, navigation patterns, and dynamic content), and the types of user interactions involved (e.g., clicking buttons, filling forms, and processing visual information). The metrics employed for evaluation should align with the benchmarks’ goals, potentially including task success rate, efficiency (actions or time taken), and user experience. Furthermore, the benchmark design should prioritize safety, mitigating the risks of unintended actions on live websites. Ideally, benchmarks should offer controlled environments for testing and validation alongside real-world evaluations for better realism.
Simulation vs. Reality#
The core challenge addressed in this research is bridging the gap between simulated and real-world environments. A crucial aspect is evaluating the efficacy of Large Language Models (LLMs) as world models, particularly for complex tasks like web navigation. The “Simulation vs. Reality” comparison highlights the inherent limitations of relying solely on simulations. While simulations offer safety and control, allowing for extensive exploration without risk of irreversible actions, they inherently differ from the dynamic, unpredictable nature of live websites. Discrepancies between simulated and real outcomes arise from the imperfect nature of LLMs in predicting the consequences of actions in real-time. The authors address this by carefully comparing results obtained from simulation-based planning with those from direct interaction with real websites, providing a crucial benchmark for assessing the fidelity of the LLM world model. This comparison underscores the need for continuous refinement of LLMs to better reflect the complexity and unexpected behavior of real-world web environments. The research emphasizes that even the best simulations can’t fully replace real-world testing, but they provide a valuable tool for significantly enhancing safety and efficiency in the development of web agents.
Future Research#
Future research directions stemming from this LLM-based web agent work are plentiful. Improving LLM world models for complex, dynamic environments like the internet is crucial. Current LLMs struggle with long-horizon planning due to inaccuracies in simulating multi-step trajectories. Research should focus on improving LLMs’ ability to accurately predict the consequences of actions, potentially through techniques like fine-tuning on more relevant datasets or incorporating external knowledge bases. Exploring advanced planning algorithms, beyond the relatively straightforward MPC used here, such as Monte Carlo Tree Search (MCTS), would enhance performance and enable more sophisticated action selection. Additionally, investigating efficient methods for handling partial observability inherent in real-world web interaction is critical. The current reliance on visual cues and textual information is limited; more robust sensing mechanisms might improve the agent’s understanding of the environment. Finally, addressing the safety and ethical implications of deploying web agents is paramount. The potential for unintended actions and privacy violations necessitates careful consideration of robustness and safeguards, especially within the context of irreversible online actions.
More visual insights#
More on figures

🔼 WebDreamer uses an LLM to simulate the consequences of different actions before executing them on a website. The figure shows three possible actions: clicking ‘Office Products’, clicking ‘Electronics’, and typing ‘Disk’ into a search bar. The LLM generates natural language descriptions of what would happen after each action (shown in dotted boxes), effectively creating simulated trajectories. These trajectories are then scored, and the action leading to the highest-scoring trajectory (in this case, clicking ‘Electronics’) is selected and performed. The example illustrates a two-step planning horizon, meaning the LLM simulates the outcome of the chosen action and then simulates the subsequent action.
read the caption
Figure 2: Illustration of WebDreamer using the LLM to simulate the outcome of each candidate action. The LLM simulates trajectories in natural language descriptions for three candidate actions: (1) Click “Office Products”, (2) Click “Electronics”, and (3) Type “Disk” into textbox. Through these simulations, each resulting trajectory is scored to identify the action most likely to succeed. In this case, the LLM selects Click Click “Electronics” as the optimal step and executes it. Each dotted box represents an LLM-generated state description after each simulated action. This example demonstrates a two-step planning horizon.

🔼 This figure shows a breakdown of the success rates of different web agents (Reactive, Tree Search, WEBDREAMER) across three different websites within the VisualWebArena benchmark. The purpose is to illustrate how the performance of each agent varies depending on the specific characteristics of the website.
read the caption
(a) Websites

🔼 This figure shows a breakdown of success rates for different task difficulties (easy, medium, hard) on the VisualWebArena benchmark. For each difficulty level, it compares the performance of three approaches: a reactive agent, a tree search agent, and the WEBDREAMER model. The numbers represent the percentage of successful task completions for each method at each difficulty level. The aim is to demonstrate the effectiveness of WEBDREAMER across varying task complexities compared to the baselines. ‘y’ represents the relative improvement of WEBDREAMER over the reactive agent, illustrating the degree to which WEBDREAMER closes the performance gap between the reactive and tree search methods.
read the caption
(b) Task Difficulty

🔼 This figure shows a comparison of the number of actions steps taken by different web agent strategies on the VisualWebArena benchmark. It breaks down the number of steps for each of three strategies: Reactive, Tree Search, and WebDreamer, across three different websites: Classifieds, Reddit, and Shopping. The data illustrates the relative efficiency of each approach in achieving task completion, highlighting the differences in the number of interactions needed with the websites.
read the caption
(a) Number of Action Steps

🔼 This figure shows the wall clock time taken to complete tasks in the VisualWebArena benchmark. It compares the time taken by three different web agent approaches: a reactive agent, a tree search agent, and the WEBDREAMER model-based planning agent. The results are broken down by website (Classifieds, Reddit, Shopping) to show the performance variation across different website structures and complexities.
read the caption
(b) Task Completion Wall Clock Time
More on tables
| Benchmark | Observation | Method | Completion Rate | Success Rate |
|---|---|---|---|---|
| VisualWebArena | Screenshot+SoM | Gemini-1.5-Pro + Reactive (Koh et al., 2024a) | - | 12.0% |
| GPT-4 + Reactive (Koh et al., 2024a) | - | 16.4% | ||
| GPT-4o + Reactive (Koh et al., 2024a) | - | 17.7%† | ||
| GPT-4o + Tree Search (Koh et al., 2024b) | - | 26.4% | ||
| GPT-4o + WebDreamer | - | 23.6% (\faArrowUp33.3%) | ||
| Mind2Web-live | HTML | GPT-4 + Reactive (Pan et al., 2024b) | 48.8% | 23.1% |
| Claude-3-Sonnet + Reactive (Pan et al., 2024b) | 47.9% | 22.1% | ||
| Gemini-1.5-Pro + Reactive (Pan et al., 2024b) | 44.6% | 22.3% | ||
| GPT-4-turbo + Reactive (Pan et al., 2024b) | 44.3% | 21.1% | ||
| GPT-3.5-turbo + Reactive (Pan et al., 2024b) | 40.2% | 16.5% | ||
| GPT-4o + Reactive (Pan et al., 2024b) | 47.6% | 22.1% | ||
| GPT-4o + WebDreamer | 49.9% | 25.0% (\faArrowUp13.1%) |
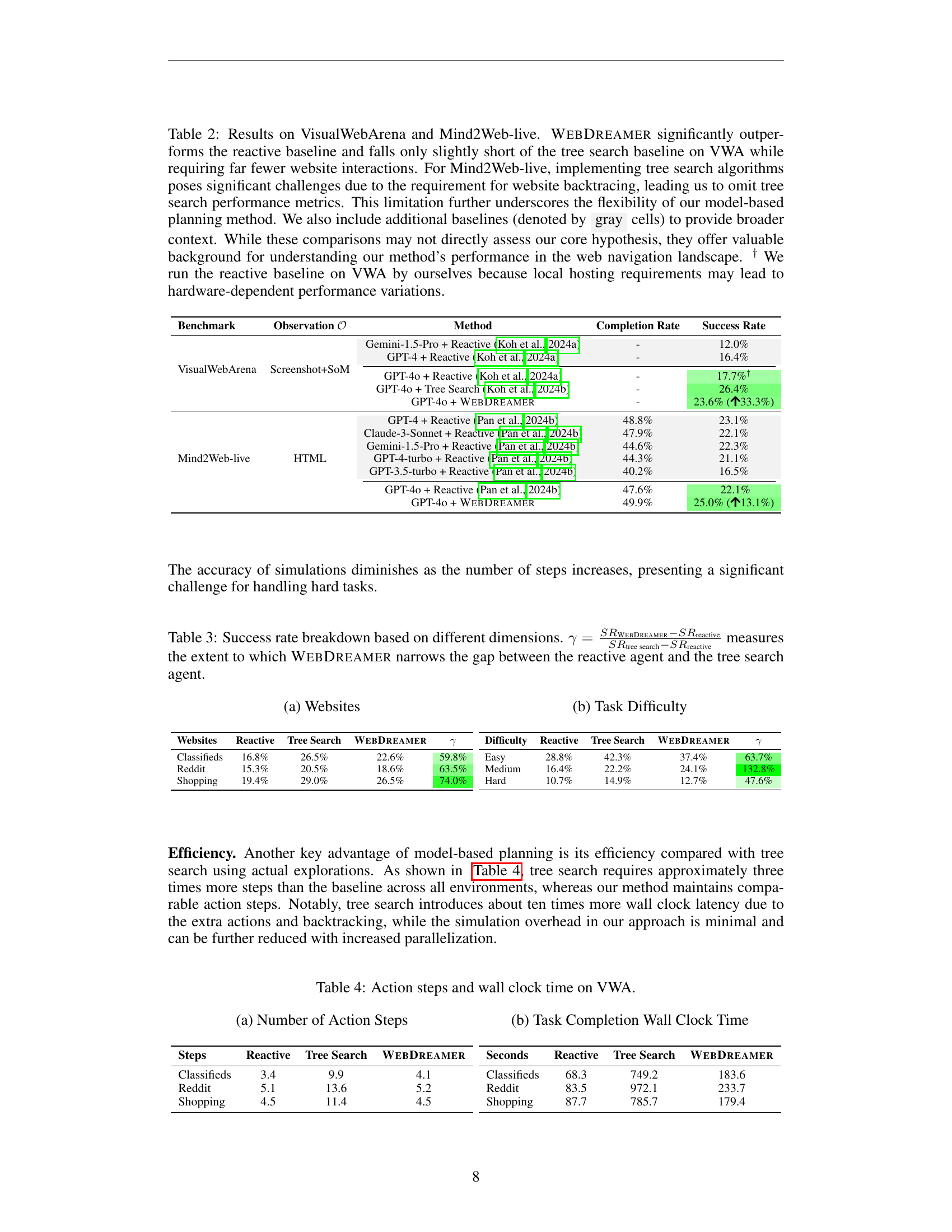
🔼 Table 2 presents a comparison of the performance of three web agent approaches (WebDreamer, reactive agent, and tree search) on two benchmark datasets: VisualWebArena (VWA) and Mind2Web-live. WebDreamer demonstrates significantly better performance than the reactive agent in both datasets, achieving a substantial improvement on VWA (33.3% relative gain in success rate) and a more modest improvement on Mind2Web-live (13.1% relative gain). While WebDreamer performs slightly below the tree search method on VWA, this is expected because tree search is not practical on live websites due to the difficulty of backtracking. Additional baselines are included for broader context; however, these may not directly test the main hypothesis. Note that the reactive baseline for VWA was run independently due to variations caused by local hardware.
read the caption
Table 2: Results on VisualWebArena and Mind2Web-live. WebDreamer significantly outperforms the reactive baseline and falls only slightly short of the tree search baseline on VWA while requiring far fewer website interactions. For Mind2Web-live, implementing tree search algorithms poses significant challenges due to the requirement for website backtracing, leading us to omit tree search performance metrics. This limitation further underscores the flexibility of our model-based planning method. We also include additional baselines (denoted by gray cells) to provide broader context. While these comparisons may not directly assess our core hypothesis, they offer valuable background for understanding our method’s performance in the web navigation landscape. † We run the reactive baseline on VWA by ourselves because local hosting requirements may lead to hardware-dependent performance variations.
| Websites | Reactive | Tree Search | WebDreamer | \gamma |
|---|---|---|---|---|
| Classifieds | 16.8% | 26.5% | 22.6% | 59.8% |
| 15.3% | 20.5% | 18.6% | 63.5% | |
| Shopping | 19.4% | 29.0% | 26.5% | 74.0% |
🔼 Table 3 breaks down the success rates of three web agent approaches (WebDreamer, reactive agent, and tree search agent) across different websites and task difficulties within the VisualWebArena benchmark. The gamma (γ) value quantifies how effectively WebDreamer closes the performance gap between the reactive and tree search agents. A higher gamma indicates that WebDreamer more effectively bridges the performance difference between these two extremes.
read the caption
Table 3: Success rate breakdown based on different dimensions. γ=SRWebDreamer−SRreactiveSRtree search−SRreactive𝛾𝑆subscript𝑅WebDreamer𝑆subscript𝑅reactive𝑆subscript𝑅tree search𝑆subscript𝑅reactive\gamma=\frac{SR_{\text{{WebDreamer}}}-SR_{\text{reactive}}}{SR_{\text{tree % search}}-SR_{\text{reactive}}}italic_γ = divide start_ARG italic_S italic_R start_POSTSUBSCRIPT WebDreamer end_POSTSUBSCRIPT - italic_S italic_R start_POSTSUBSCRIPT reactive end_POSTSUBSCRIPT end_ARG start_ARG italic_S italic_R start_POSTSUBSCRIPT tree search end_POSTSUBSCRIPT - italic_S italic_R start_POSTSUBSCRIPT reactive end_POSTSUBSCRIPT end_ARG measures the extent to which WebDreamer narrows the gap between the reactive agent and the tree search agent.
| Difficulty | Reactive | Tree Search | WebDreamer | γ |
|---|---|---|---|---|
| Easy | 28.8% | 42.3% | 37.4% | 63.7% |
| Medium | 16.4% | 22.2% | 24.1% | 132.8% |
| Hard | 10.7% | 14.9% | 12.7% | 47.6% |
🔼 This table presents a comparison of the number of action steps and the wall clock time taken by three different web agent strategies on the VisualWebArena (VWA) benchmark. The strategies are: a reactive agent, a tree search agent, and the proposed WEBDREAMER model. The data is broken down by website (Classifieds, Reddit, Shopping) to show performance variations across different website structures. This allows for a detailed analysis of the efficiency and time complexity of each approach in navigating real-world websites.
read the caption
Table 4: Action steps and wall clock time on VWA.
Full paper#