↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-image synthesis methods often struggle with generating high-resolution, photorealistic images, especially when dealing with diverse applications. Existing pixel-space generators suffer from artifact accumulation during upsampling. This paper addresses these limitations by proposing a new approach.
The proposed method uses a cascaded pixel-space diffusion model with a novel Laplacian diffusion process. This process attenuates image signals at different frequencies at varying rates, significantly improving the precision and efficiency of the generation process. The model demonstrates strong performance across various tasks including text-to-image synthesis, 4K upsampling, ControlNets, and 360° HDR panorama generation. Furthermore, a finetuning method allows for easy customization.
Key Takeaways#
Why does it matter?#
This paper is significant as it introduces Edify Image, a novel family of diffusion models achieving pixel-perfect photorealistic image generation. Its multi-scale Laplacian diffusion process offers superior control and efficiency. The work’s exploration of 4K upsampling, ControlNets, and 360° HDR panoramas expands image generation capabilities and opens new avenues for research in these areas. The finetuning method allows for easy customization and opens up possibilities for personalized image generation.
Visual Insights#

🔼 The figure shows a photorealistic image of a couple engaging in pottery, set in a well-lit room. This exemplifies the model’s capability to generate high-quality images from text descriptions, a key feature of text-to-image generation.
read the caption
(a) Text-to-image generation
In-depth insights#
Laplacian Diffusion#
Laplacian diffusion, as a concept in image generation, presents a multi-scale approach to the diffusion process. Unlike traditional methods that treat all frequency bands equally, Laplacian diffusion attenuates different frequency bands at varying rates. This allows for more precise control over detail refinement, leading to pixel-perfect accuracy in generated images. The core idea lies in decomposing an image into its various frequency bands using a Laplacian pyramid, applying the diffusion process separately to each band, and then reconstructing the image. This cascaded approach, with its hierarchical structure, enables efficient training and generation of high-resolution images. The model’s ability to handle varied frequency bands effectively mitigates issues of artifact accumulation that often plague simple upsampling techniques in pixel-space diffusion models. Attenuation factors play a crucial role in this process, controlling how quickly each frequency band decays, and are strategically designed to ensure both high-frequency detail and low-frequency structural integrity. The result is a more efficient and robust diffusion model, particularly useful for generating photorealistic images with fine details.
Multi-scale EDM#
Multi-scale EDM, or multi-scale Energy-based Diffusion Models, represents a significant advancement in image generation. It leverages the power of diffusion models by applying them across multiple scales, rather than relying on a single resolution. This approach allows for more efficient processing by initially focusing on low-resolution details and then iteratively refining them at higher resolutions. The cascaded nature ensures that the model avoids problems associated with directly upsampling low-resolution images, such as the accumulation of artifacts. Key to this process is a multi-scale diffusion process, possibly utilizing a Laplacian diffusion process, where signals at different frequency bands are attenuated at varying rates. This enables the model to effectively capture and refine details across scales. The introduction of multi-scale EDM can lead to significant improvements in the quality and fidelity of generated images, while simultaneously reducing computational cost. The technique also allows for greater flexibility and control over the synthesis process, facilitating applications such as inpainting, 4K upsampling, and HDR panorama generation.
ControlNet Integration#
ControlNet integration enhances image generation models by incorporating additional control signals beyond text prompts. This allows for more precise manipulation of generated images, guiding the model’s output towards specific structural or stylistic features. The integration process typically involves adding a secondary network, or ControlNet, which processes these control signals (e.g., depth maps, sketches, edge information) and modulates the base diffusion model’s generation process. This results in images that adhere more closely to the desired structure while still exhibiting the semantic understanding provided by the text prompts. A key advantage is the increased flexibility and creativity it offers, empowering users to combine various control signals in novel ways to achieve complex or highly specialized visual outputs. However, effective integration requires careful consideration of the control signal’s representation, its compatibility with the base model’s architecture, and the training methodology used. Challenges may arise in ensuring the control signal appropriately guides the generation without negatively impacting the base model’s overall quality or semantic coherence. Furthermore, the complexity of the integrated system can impact computational resources and training time. Despite these potential challenges, ControlNet integration holds great promise for enhancing the capabilities of image generation models and enabling new creative avenues for users.
4K Upsampling#
The 4K upsampling method presented in the paper is a notable contribution, addressing the challenge of limited high-resolution training data. Instead of training a separate 4K model from scratch, which would require a massive dataset, the authors cleverly leverage a pre-trained 1K model. This approach is efficient and overcomes data scarcity issues. The method employs noise scaling and ControlNet techniques to refine the low-resolution images to a 4K resolution while maintaining fidelity and preventing content distortion. Fine-tuning the base model with the ControlNet on a smaller 4K dataset further improves the quality of upsampled images by incorporating crucial high-frequency details. The results presented show that the upsampler successfully adds fine-grained details to the 1K input images, demonstrating a significant improvement in image quality and detail without the need for extensive high-resolution training data. This clever strategy is particularly important for practical applications where access to large, high-quality datasets is limited.
HDR Panorama#
The research paper section on HDR panoramas presents a novel approach to generating high-dynamic range (HDR) 360-degree panoramas using a diffusion model. This is a significant advancement due to the limited availability of HDR panorama data for training traditional models. The method cleverly leverages a pre-trained text-to-image diffusion model to synthesize individual perspective images, which are then stitched together to create the panorama. The process addresses the challenge of data scarcity by relying on the text-to-image model for most of the image generation, with limited panorama data used to fine-tune the stitching and HDR tone mapping processes. A key aspect is the sequential inpainting technique, where images are generated with overlapping regions to ensure seamless transitions. The final step involves converting the low-dynamic range (LDR) output to HDR using a dedicated network, leading to photorealistic results with a wide dynamic range. The method demonstrates the potential for high-quality HDR panorama generation even with limited training data, potentially opening avenues for various applications such as virtual reality and image-based lighting.
More visual insights#
More on figures

🔼 This figure demonstrates the finetuning capability of Edify Image. It shows an example of a finetuning image used to customize the model’s output, alongside the control input that was used during the finetuning process. The goal of finetuning is to adapt the pre-trained model to generate images with specific characteristics, such as a particular style or to generate images of specific individuals.
read the caption
(b) Finetuning
🔼 This image shows an example of Edify Image’s ability to generate images with additional control beyond just text prompts. The input image on the left shows a finetuning image used to customize the output, and the control input (a simple sketch) is shown in the bottom left corner. The generated image on the right illustrates how the model incorporates this additional control to produce a more tailored result.
read the caption
(c) Additional control

🔼 The image showcases the capability of Edify Image in generating photorealistic high-resolution panoramas. It highlights the model’s ability to create seamless, wide-angle views from a text prompt, demonstrating its potential in applications like virtual reality content creation and game development.
read the caption
(d) Panorama

🔼 This figure showcases the versatility of Edify Image in generating high-quality, photorealistic images from textual descriptions. It demonstrates four key capabilities: (a) direct text-to-image synthesis, producing detailed images from text prompts; (b) finetuning, where the model is adapted to generate images in a specific style or with particular characteristics using example images; (c) generation with additional control, allowing users to guide the image creation process using various parameters, such as depth of field and camera controls; and (d) the generation of interactive 360° panoramic HDR videos, offering dynamic visuals with high resolution and color accuracy. Examples of finetuning images and control inputs are included in the figure for better understanding. The best viewing experience is achieved with Acrobat Reader; a clickable panorama image initiates a video.
read the caption
Figure 1: Edify Image can generate photorealistic high-resolution images from text prompts. Our models support a range of capabilities, including (a) Text-to-image generation, (b) Finetuning, (c) Generation with additional control, and (d) Panorama generation. For (b) and (c), an example of a finetuning image and the control input are provided in the bottom left corner, respectively. Best viewed with Acrobat Reader. Click the panorama image to play the video clip.
🔼 Figure 2 illustrates the Laplacian diffusion process for multi-resolution image generation. The top panel shows the image Laplacian decomposition, breaking down an image into components representing different frequency bands (low, mid, high). The middle panel depicts the forward noise process where each frequency band is attenuated at a varying rate. Higher frequencies decay faster, reducing noise accumulation. The bottom panel shows the backward sampling process. Denoisers, trained at multiple stages, upsample lower-resolution noisy images and add noise to higher-frequency components, progressively generating higher-resolution outputs. At the lowest resolution, this process simplifies to standard energy-based diffusion models.
read the caption
Figure 2: Laplacian diffusion for multi-resolution image generation. (Top) Image Laplacian Decomposition. Each image sample 𝐱𝐱{\mathbf{x}}bold_x can be decomposed into a set of components. The example shows three components, 𝐱=𝐱(1)+up(𝐱(2))+up(up(𝐱(3)))𝐱superscript𝐱1upsuperscript𝐱2upupsuperscript𝐱3{\mathbf{x}}={\mathbf{x}}^{(1)}+\text{up}({\mathbf{x}}^{(2)})+\text{up}(\text{% up}({\mathbf{x}}^{(3)}))bold_x = bold_x start_POSTSUPERSCRIPT ( 1 ) end_POSTSUPERSCRIPT + up ( bold_x start_POSTSUPERSCRIPT ( 2 ) end_POSTSUPERSCRIPT ) + up ( up ( bold_x start_POSTSUPERSCRIPT ( 3 ) end_POSTSUPERSCRIPT ) ). This decomposition is implemented using basic upsampling and downsampling operations, where each component corresponds to different frequency bands. The function μ(𝐱,t)𝜇𝐱𝑡\mu({\mathbf{x}},t)italic_μ ( bold_x , italic_t ) represents a weighted sum of these components across different frequency spaces. (Middle) Forward Noising Process. Components are attenuated at different rates, with higher frequencies attenuated more rapidly than lower ones. We use the decaying background color in the top part of the figure to illustrate the attenuation factors. As a result, the signal-to-noise ratio (SNR) diminishes faster in the high-frequency components, allowing them to be discarded without significant loss of information once their attenuation coefficients approach zero. (Bottom) Backward Sampling Process. Denoisers are trained at multiple stages to generate images at various resolutions. We decompose the noise into a noise Laplacian pyramid. The Laplacian Diffusion process synthesizes higher-resolution images by first upsampling a lower-resolution noisy sample and then denoising it, with random noise injected into the corresponding components during upsampling. When operating solely at the lowest resolution, the process reduces to standard EDM.

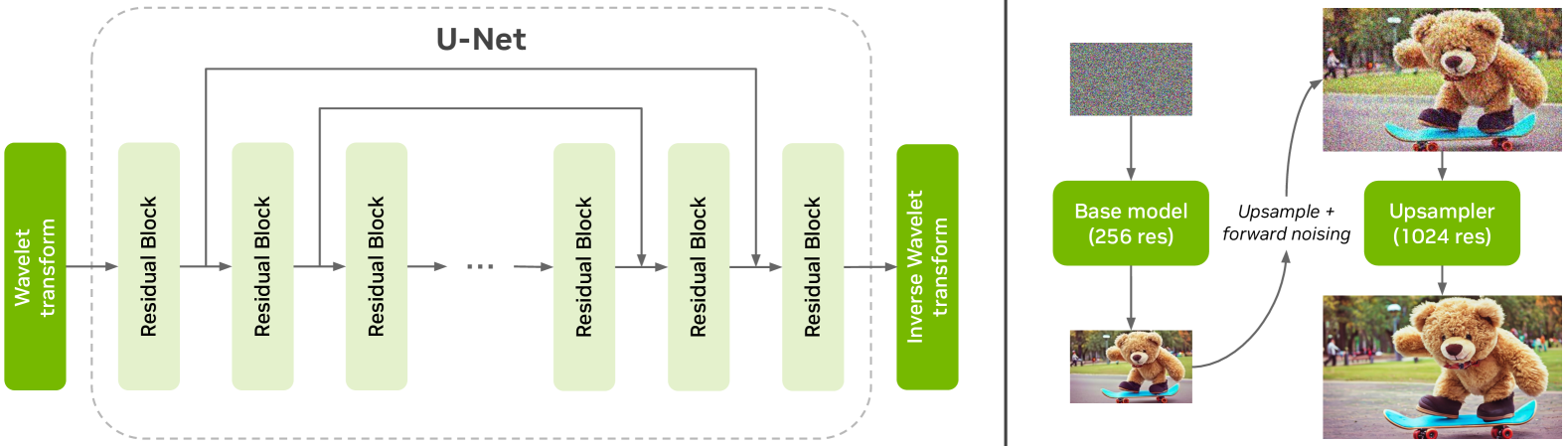
🔼 This figure illustrates the architecture of the Edify Image model. The left panel shows the U-Net based architecture used for both the base and upsampling models. This architecture consists of residual blocks with skip connections and employs wavelet and inverse wavelet transforms at the beginning and end of the network to reduce the spatial resolution of images, improving computational efficiency. The right panel details the two-stage cascade process used for generating 1024x1024 resolution images. First, a base model generates a 256x256 resolution image, which is then upsampled to 1024x1024 resolution by a second model.
read the caption
Figure 3: Model architecture. As shown in the left panel, our diffusion models use a U-Net based architecture with a sequence of residual blocks with skip connections. We use wavelet and Inverse wavelet transform at the beginning and end of the network to bring down the spatial resolution of the images. In the right panel, we show how the 256256256256 and 1K1𝐾1K1 italic_K-resolution models are combined in a 2-stage cascade to generate the 1024102410241024-resolution image.

🔼 This figure showcases example images generated by the Edify Image text-to-image model, demonstrating its ability to produce high-quality images at various aspect ratios. The model successfully generates photorealistic images for different scenarios, subjects, and styles, highlighting its versatility and adherence to input text prompts. The images represent three common aspect ratios: 16:9 (wide screen), 1:1 (square), and 9:16 (vertical).
read the caption
Figure 4: Samples generated by our text-to-image model with 16:9, 1:1 and 9:16 aspect ratios.

🔼 This figure showcases Edify Image’s ability to generate high-quality images from lengthy and detailed text descriptions. The examples demonstrate the model’s capacity to interpret and render complex scenes involving various elements, relationships, and attributes, highlighting its robustness in handling long-form textual input and producing faithful visual representations.
read the caption
Figure 5: Long prompt generation. Edify Image can faithfully generate images from long descriptive prompts.

🔼 Figure 6 showcases the model’s capability to generate diverse images, demonstrating good representation across various genders and races. The prompt used was a simple request for ‘A studio portrait of a smart CEO’, highlighting the model’s ability to generate realistic and inclusive results even with minimal instructions.
read the caption
Figure 6: Human diversity. Our model is able to generate images with good gender and race diversity. The prompt used is 'A studio portrait of a smart CEO'.

🔼 This figure demonstrates the impact of pitch control on image generation. Three images are shown, each representing a different camera pitch: descending, eye level, and ascending. The subject remains consistent across all three, highlighting how pitch adjustment changes the perspective and composition while maintaining scene consistency.
read the caption
Figure 7: Camera controls - Pitch.

🔼 This figure demonstrates the effect of controlling the depth of field during image generation. The top row shows images generated with a shallow depth of field, resulting in a blurred background that emphasizes the subject in the foreground. The bottom row shows images generated with a deep depth of field, where both the foreground and background elements are in sharp focus. This showcases the ability of the Edify Image model to control image focus.
read the caption
Figure 8: Camera controls - Depth of field.

🔼 This figure showcases the results of 4K upsampling performed on images initially generated at 1K resolution. The top row presents the full upsampled images at 4K resolution, demonstrating the overall enhancement in detail and clarity. The bottom row provides zoomed-in views of specific image sections, allowing for a closer examination of the added fine details and textures achieved through the upsampling process. This visual comparison effectively highlights the significant improvement in image quality and resolution resulting from the upscaling technique applied by the model.
read the caption
Figure 9: 4K4𝐾4K4 italic_K Upsampling results. Full (top) and zoomed-in images (bottom) show the additional details.

🔼 This figure showcases the results of 4K upsampling performed on images. The top row presents the full images after upsampling, highlighting their overall quality and detail. The bottom row provides zoomed-in sections of the same images, emphasizing the increased level of detail achieved through the upsampling process. This comparison effectively demonstrates the enhancement in resolution and clarity brought about by the upsampling technique, illustrating its effectiveness in generating high-resolution images.
read the caption
Figure 10: 4K4𝐾4K4 italic_K Upsampling results. Full (top) and zoomed-in images (bottom) show the additional details.

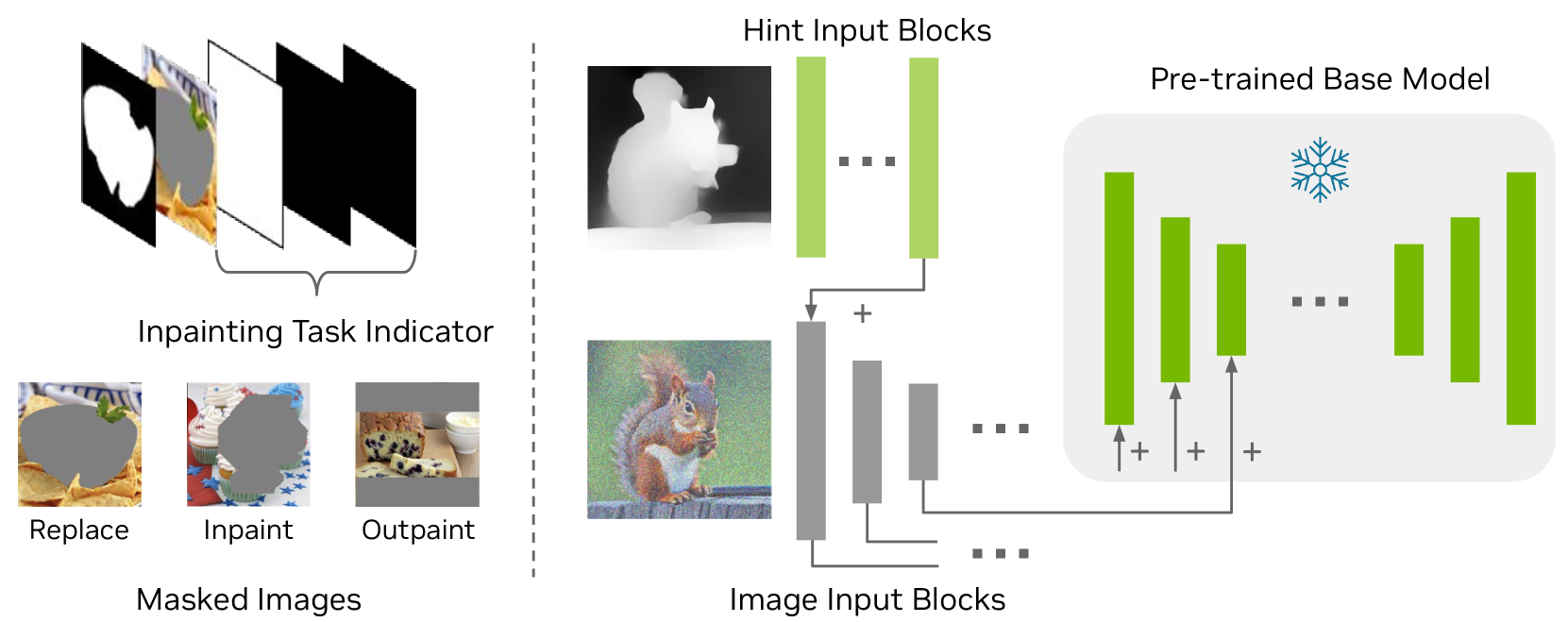
🔼 This figure illustrates the architecture of the Edify Image model enhanced with ControlNet. The original, pre-trained base model (a U-Net) remains frozen during ControlNet training. The ControlNet’s ‘Image Input Blocks’ receive initial values derived from the base U-Net’s parameters. This allows the ControlNet to leverage the knowledge learned by the base model. In contrast, the ‘Hint Input Blocks’, which process additional control inputs (like sketches, depth maps, or inpainting masks), start with randomly initialized weights. The combined outputs of these blocks influence the final image generation. This design ensures that the ControlNet effectively modifies the base model’s outputs without disrupting its pre-trained knowledge.
read the caption
Figure 11: Model architecture with additional control inputs. The base model is frozen when training the ControlNet encoders. The Image Input Blocks are initialized from the base model U-Net. The Hint Input Blocks are randomly initialized.

🔼 This figure demonstrates the effectiveness of Edify Image’s ControlNet in handling various control inputs, such as inpainting masks, depth maps, and edge maps. Each column represents a different type of control input, and for each control input, three rows of generated images are shown, each produced using different text prompts. This highlights the model’s ability to generate varied and high-quality images that precisely adhere to the provided controls and textual descriptions.
read the caption
Figure 12: Results with additional control inputs for inpainting, depth, and edge. For each input condition, we generate 3 variants using different text prompts.

🔼 This figure visualizes the impact of adjusting the control weight parameter on image generation using depth and edge control inputs. By varying the weight, the model’s adherence to the specified depth and edge cues is modified. Higher control weights result in more precise alignment with the input depth and edge information, while lower weights allow for greater stylistic freedom and less strict adherence to the controls.
read the caption
Figure 13: Results with different control weight values for depth-to-image and edge-to-image.
![]()
🔼 A panoramic landscape photo depicting a gravel parking lot at sunset. The scene includes a mostly clear blue sky, several autumn maple trees, and a range of smoky mountains in the background. The overall aesthetic aims for scenic beauty, and the intended mood is inspiring.
read the caption
(a) sunset at a lookout point in a gravel parking lot with blue sky and a few autumn maple trees and beautiful smokey mountains in the background, scenic nature, inspiring, landscape panoramic, mountains.

🔼 A panoramic view of a flat, sandy beach beside a lake. The lake is nestled in a valley surrounded by the majestic Swiss Alps, which are visible in the background. The scene is bathed in the bright sunlight of midday, with sunbeams (god rays) breaking through the atmosphere. The overall impression is one of serene, scenic natural beauty, inspiring awe and wonder.
read the caption
(b) flat sand beach by a lake in the swiss alps mountains at noon with beautiful swiss alps mountains in the background, god rays, scenic nature, inspiring, landscape panoramic.
Full paper#



















