↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current instruction-guided image editing models struggle with limited capabilities, noisy data, and handling diverse image aspects. These limitations hinder real-world applications.
OmniEdit tackles these issues with a novel approach. It trains a generalist model using supervision from seven specialist models, each expert in a specific editing task, ensuring broad coverage. High-quality data is ensured by using large multimodal models for importance sampling instead of simpler methods, significantly reducing noise and artifacts. The model uses a new architecture (EditNet) to enhance editing success rates and handles images of various aspect ratios and resolutions. Evaluations demonstrate its superior performance over existing models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on image editing and generation because it directly addresses the limitations of existing methods. By introducing a novel training approach using specialist models and high-quality data, it significantly improves the capabilities of image editing models. This opens avenues for developing more robust and versatile image editing tools with real-world applications.
Visual Insights#

🔼 This figure showcases Omni-Edit’s ability to edit high-resolution images with various aspect ratios. It demonstrates the model’s versatility by accurately executing diverse editing instructions across different image sizes and orientations, while maintaining the original image quality. The example edits range from simple object replacements to complex scene modifications, highlighting Omni-Edit’s proficiency in instruction-based image manipulation. Zooming in on the images allows for a more detailed observation of the results.
read the caption
Figure 1: Editing high-resolution multi-aspect images with Omni-Edit. Omni-Edit is an instruction-based image editing generalist capable of performing diverse editing tasks across different aspect ratios and resolutions. It accurately follows instructions while preserving the original image’s fidelity. We suggest zooming in for better visualization.
| Property | InstructP2P | MagicBrush | UltraEdit | MGIE | HQEdit | CosXL | Omni-Edit |
|---|---|---|---|---|---|---|---|
| Training Dataset Properties | |||||||
| Real Image? | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| Any Res? | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| High Res? | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Fine-grained Image Editing Skills | |||||||
| Obj-Swap | ⭐⭐☆ | ⭐⭐☆ | ⭐⭐☆ | ⭐☆ ☆ | ⭐⭐☆ | ⭐ ☆ ☆ | ⭐⭐☆ |
| Obj-Add | ⭐☆☆ | ⭐⭐☆ | ⭐☆☆ | ⭐☆ ☆ | ⭐☆☆ | ⭐☆☆ | ⭐⭐☆ |
| Obj-Remove | ⭐☆☆ | ⭐⭐☆ | ⭐☆☆ | ⭐☆ ☆ | ⭐☆☆ | ⭐☆☆ | ⭐⭐☆ |
| Attribute | ⭐⭐☆ | ⭐☆☆ | ⭐⭐☆ | ⭐☆ ☆ | ⭐☆☆ | ⭐☆☆ | ⭐⭐☆ |
| Back-Swap | ⭐⭐☆ | ⭐⭐☆ | ⭐⭐☆ | ⭐☆ ☆ | ⭐⭐☆ | ⭐⭐☆ | ⭐⭐☆ |
| Environment | ⭐☆☆ | ⭐☆☆ | ⭐☆☆ | ⭐☆ ☆ | ⭐☆☆ | ⭐⭐☆ | ⭐⭐☆ |
| Style | ⭐⭐☆ | ⭐☆☆ | ⭐⭐☆ | ⭐☆ ☆ | ⭐☆☆ | ⭐⭐☆ | ⭐⭐☆ |
🔼 This table compares Omni-Edit to other state-of-the-art end-to-end image editing models. The comparison considers several key properties: whether the model is trained on real images, handles images of any resolution and high resolutions, and the model’s performance on several fine-grained image editing tasks (object swap, addition, removal, attribute modification, background swap, environment change, and style transfer). The scores are based on a preliminary evaluation using roughly 50 different prompts, and each task’s performance is qualitatively rated using a star system.
read the caption
Table 1: Comparison of Omni-Edit with all the existing end-to-end image editing models. The scores are based on a preliminary studies on around 50 prompts.
In-depth insights#
Specialist Supervision#
The concept of “Specialist Supervision” in the context of training image editing generalist models offers a compelling approach to overcome limitations of existing methods. Instead of relying on a single, broadly trained model, the approach advocates training several specialist models, each focusing on a specific editing task. This task-specific training allows each specialist to develop high-level expertise in its designated area (e.g., object removal, style transfer). The key innovation lies in leveraging these specialists to supervise the training of a generalist model. This means the generalist learns from the combined knowledge and skillsets of the various specialists, ultimately inheriting their strengths and achieving a broader editing capability. This strategy contrasts with previous approaches that mostly utilize synthetically generated datasets leading to a lack of skill diversity in trained models. The use of specialist supervision is a form of knowledge distillation, transferring the expertise of multiple models into a single, robust generalist, thereby potentially resulting in improved performance and generalization across a wide range of editing tasks and image types.
Importance Sampling#
Importance sampling, in the context of training a robust image editing model, addresses the challenge of low-quality synthetic training data. Standard methods for filtering training pairs often fail to adequately assess image quality, leading to models with limited capabilities. The innovative approach here leverages the power of large multimodal models (like GPT-4) to assign quality scores to synthesized image edits. This importance sampling allows for prioritization of high-quality data during training. However, directly using LMMs for scoring is computationally expensive. Therefore, the method incorporates a clever distillation strategy, transferring the scoring capability to a smaller, more efficient model (InternVL2), which then filters the dataset at scale. This ensures that the model is trained on a high-quality subset of the synthetic data, significantly improving its performance and ability to generalize to real-world image editing tasks.
EditNet Architecture#
The proposed EditNet architecture is a crucial innovation in OmniEdit, designed to address limitations of existing diffusion-based image editing methods. It enhances the interaction between control signals (from instructions) and the original diffusion process. Unlike parallel approaches like ControlNet, EditNet uses an adaptive adjustment of control signals via intermediate representations. This allows for a more nuanced understanding of instructions, leading to improved accuracy in complex edits. The key advantage is that EditNet’s interaction between the control branch (processing instructions) and the original branch (the diffusion model) allows the model to dynamically adapt its control signals. This adaptive mechanism is essential for tasks like object removal, where a precise understanding of the instruction is critical for successful execution. By leveraging this architecture, OmniEdit can perform diverse editing tasks with greater accuracy and fidelity than comparable models, highlighting the effectiveness of EditNet in handling high-resolution, multi-aspect ratio images, and achieving improved performance in both perceptual quality and semantic consistency.
Aspect Ratio Support#
The ability to handle images with diverse aspect ratios is a crucial factor for any practical image editing system. A model trained only on square images will likely struggle with non-square inputs, leading to distortions or poor results. Supporting arbitrary aspect ratios demonstrates robustness and generalizability, moving beyond the limitations of many existing methods which are often restricted to a single, fixed aspect ratio. This feature significantly increases the real-world applicability of the model, as it can process a wider variety of input images without requiring preprocessing steps like padding or cropping. The achievement of high-quality edits across different aspect ratios underscores the model’s superior adaptability and generalization capabilities. This is particularly important in real-world scenarios where images are rarely constrained to a specific format. Furthermore, training data that includes a wide range of aspect ratios is essential for this ability, highlighting the importance of dataset construction for achieving such model robustness.
Future Work#
Future research directions stemming from the OmniEdit paper could involve several key areas. Improving the quality and diversity of training data is crucial; exploring alternative data sources and augmentation techniques beyond the current methods would significantly enhance model capabilities. The development of more sophisticated scoring functions to assess the quality of image edits is necessary. Moving beyond simple metrics and incorporating human evaluation or more nuanced automated metrics would allow for better model training and evaluation. Expanding the range of supported image editing tasks is another important area of future work. OmniEdit excels in several tasks, but many more could be incorporated and generalized. Finally, investigating the computational efficiency of the proposed model and exploring methods for improving speed and reducing memory consumption is a critical consideration for real-world applications. These advancements would position OmniEdit as an even more versatile and practical tool for various image editing applications.
More visual insights#
More on figures

🔼 The Omni-Edit training pipeline consists of four stages. Stage 1 involves training seven specialist models, each focusing on a specific image editing task (object swap, removal, addition, attribute modification, background swap, environment change, style transfer). These specialists are trained using a combination of pre-trained text-to-image models and task-specific augmentations. Stage 2 uses these specialists to generate synthetic image editing datasets for each task. Stage 3 incorporates an importance sampling method using a large multimodal model (like GPT-4) to filter noisy or low-quality data from the synthetic datasets, ensuring high-quality training data. Finally, Stage 4 trains the Omni-Edit generalist model using the high-quality, multi-task data generated in the previous stages. The specialist models act as supervisors to guide the learning of the generalist model. This approach allows Omni-Edit to handle diverse and complex image editing instructions.
read the caption
Figure 2: Overview of the Omni-Edit training pipeline.

🔼 This figure demonstrates the improvement in InternVL2’s performance as a scoring function after fine-tuning with GPT-40 responses. The top-right panel shows the original InternVL2 failing to detect distortions or inconsistencies in an edited image, even when it does not adhere to instructions. The bottom-right panel shows the fine-tuned InternVL2 accurately identifying such issues, showcasing its enhanced ability to evaluate the quality of image edits. This improved scoring function is crucial for selecting high-quality training data.
read the caption
Figure 3: InternVL2 as a scoring function before (top right) and after (bottom right) fine-tuning on GPT-4o’s response. On the top right, the original InternVL2 fails to identify the unusual distortions in the edited image it also does not spot the error when the edited image fails to meet the specified editing instructions. On the bottom right, finetuned-InternVL2 successfully detects such failures and serve as a reliable scoring function.

🔼 Figure 4 compares the architecture of three different diffusion-based image editing models: EditNet (the authors’ model), ControlNet, and InstructPix2Pix. The figure highlights the key differences in how these models incorporate control signals (from text prompts and other conditioning information) to modify the image generation process. ControlNet uses parallel execution of a control branch alongside the main generation branch. In contrast, EditNet allows for a more dynamic and adaptive adjustment of control signals through an interaction between the control and main branches, facilitated by intermediate representations. This interaction allows for better understanding of the text prompt and thus, more effective editing. Finally, EditNet also updates the text representation itself, further enhancing task comprehension. InstructPix2Pix employs a simple channel-wise concatenation of control signals with the main image representation.
read the caption
Figure 4: Architecture Comparison between EditNet(ours), ControlNet and InstructPix2Pix(Channel-wise concatenation) for DiT models. Unlike ControlNet’s parallel execution, EditNet allows adaptive adjustment of control signals by intermediate representations interaction between the control branch and the original branch. EditNet also updates the text representation, enabling better task understanding.

🔼 Figure 5 presents a qualitative comparison of image editing results produced by OMNI-Edit and several baseline methods. The figure showcases examples from a subset of the test set, highlighting OMNI-Edit’s superior performance in various editing tasks. By directly comparing the visual outputs side-by-side, the reader can readily assess the differences in editing quality, accuracy, and adherence to instructions across the various models.
read the caption
Figure 5: Qualitative comparison between baselines and Omni-Edit on a subset of the test set.

🔼 Figure 6 presents a comparative analysis of three different models on an object removal task. The first model, Omni-Edit-ControlNet, demonstrates a failure to understand the task instructions, resulting in an unsuccessful edit. The second model, Omni-Edit-ControlNet-TextControl, which includes a text-updating component, correctly interprets the task; however, it struggles to fully remove the targeted object, leaving remnants. The third model, Omni-Edit, successfully executes the object removal task, completely eliminating the desired object.
read the caption
Figure 6: Omni-Edit-ControlNet fails to grasp the task intent, while Omni-Edit-ControlNet-TextControl—a variant with a text-updating branch—recognizes the intent but struggles with content removal. In contrast, Omni-Edit accurately removes content.

🔼 Figure 7 demonstrates a comparison of image editing results between Omni-Edit and Omni-Edit-Channel-Wise-Concatenation, highlighting Omni-Edit’s ability to maintain the original image generation capabilities of the base model (SD3) while performing edits. The experiment involves replacing a person in an image with Batman and adding a vintage car. Omni-Edit successfully integrates these edits while preserving image quality. In contrast, Omni-Edit-Channel-Wise-Concatenation shows a significant decline in image generation quality after edits, indicating a compromise in the base model’s generation capabilities.
read the caption
Figure 7: (a) shows the source image. (d) presents images generated by SD3 in response to prompts for “an upper body picture of Batman” and “a shiny red vintage Chevrolet Bel Air car.” We use the prompts “Replace the man with Batman” and “Add a shiny red vintage Chevrolet Bel Air car to the right” to Omni-Edit and Omni-Edit-Channel-Wise-Concatenation, which was trained on Omni-Edit training data. From (b) and (c), one can observe that Omni-Edit preserves the generation capabilities of SD3, while Omni-Edit-Channel-Wise-Concatenation exhibits a notable degradation in generation capability.

🔼 This figure shows the prompt used to evaluate the Semantic Consistency (SC) score in the OMNI-EDIT model’s performance. The prompt instructs an evaluator (acting as a professional digital artist) to assess two images: an original AI-generated image and an edited version. The evaluator must rate how well the edited image follows the given editing instructions on a scale of 0 to 10, with 0 representing complete failure and 10 representing perfect adherence. A second rating (also 0-10) assesses the degree of overediting in the image. The prompt provides detailed instructions for how to format the numerical scores and associated textual rationale.
read the caption
Figure 8: Prompt for evaluating SC score.

🔼 This figure shows the prompt used for human evaluators to assess the perceptual quality (PQ) of images generated by the OMNI-EDIT model and its baselines. The evaluators are instructed to act as professional digital artists, rating the image quality on a scale of 0-10, based solely on technical aspects like distortions, unnatural proportions, and artifacts. They are explicitly told to ignore contextual realism or the naturalness of the scene.
read the caption
Figure 9: Prompt for evaluating PQ score.
More on tables
| Editing Tasks | Definition | Instruction Example |
|---|---|---|
| Object Swap | c describes an object to replace by specifying both the object to remove and the new object to add, along with their properties such as appearance and location. | Replace the black cat with a brown dog in the image. |
| Object Removal | c describes which object to remove by specifying the object’s properties such as appearance, location, and size. | Remove the black cat from the image. |
| Object Addition | c describes a new object to add by specifying the object’s properties such as appearance and location. | Add a red car to the left side of the image. |
| Attribute Modification | c describes how to modify the properties of an object, such as changing its color and facial expression. | Change the blue car to a red car. |
| Background Swap | c describes how to replace the background of the image, specifying what the new background should be. | Replace the background with a space-ship interior. |
| Environment Change | c describes a change to the overall environment, such as the weather, lighting, or season, without altering specific objects. | Change the scene from daytime to nighttime. |
| Style Transfer | c describes how to apply a specific artistic style or visual effect to the image, altering its overall appearance while keeping the content the same. | Apply a watercolor painting style to the image. |
🔼 This table provides detailed definitions and illustrative examples for seven distinct image editing tasks. Each row defines a specific task, explaining the type of edits it involves, and provides a concise, illustrative example of the task. The table is crucial for understanding the scope and variety of image manipulations addressed in the research, including adding or removing objects, modifying object attributes, or making overall background or environmental changes.
read the caption
Table 2: Task Definitions and Examples
| Models | VIEScore (GPT4o) | VIEScore (Gemini) | Human Evaluation | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PQavg↑ | SCavg↑ | Oavg↑ | PQavg↑ | SCavg↑ | Oavg↑ | PQavg↑ | SCavg↑ | Oavg↑ | Accavg↑ | |
| — | — | — | — | — | — | — | — | — | — | — |
| Inversion-based Methods | ||||||||||
| DiffEdit | 5.88 | 2.73 | 2.79 | 6.09 | 2.01 | 2.39 | - | - | - | - |
| SDEdit | 6.71 | 2.18 | 2.78 | 6.31 | 2.06 | 2.48 | - | - | - | - |
| End-to-End Methods | ||||||||||
| InstructPix2Pix | 7.05 | 3.04 | 3.45 | 6.46 | 1.88 | 2.31 | - | - | - | - |
| MagicBrush | 6.11 | 3.53 | 3.60 | 6.36 | 2.27 | 2.61 | - | - | - | - |
| UltraEdit(SD-3) | 6.44 | 4.66 | 4.86 | 6.49 | 4.33 | 4.45 | 0.72 | 0.52 | 0.57 | 0.20 |
| HQ-Edit | 5.42 | 2.15 | 2.25 | 6.18 | 1.71 | 1.96 | 0.80 | 0.27 | 0.29 | 0.10 |
| CosXL-Edit | 8.34 | 5.81 | 6.00 | 7.01 | 4.90 | 4.81 | 0.82 | 0.56 | 0.59 | 0.35 |
| HIVE | 5.35 | 3.65 | 3.57 | 5.84 | 2.84 | 3.05 | - | - | - | - |
| Omni-Edit | 8.38 | 6.66 | 6.98 | 7.06 | 5.82 | 5.78 | 0.83 | 0.71 | 0.69 | 0.55 |
| Δ - Best baseline | +0.04 | +0.85 | +0.98 | +0.05 | +0.92 | +0.97 | +0.01 | +0.15 | +0.10 | +0.20 |
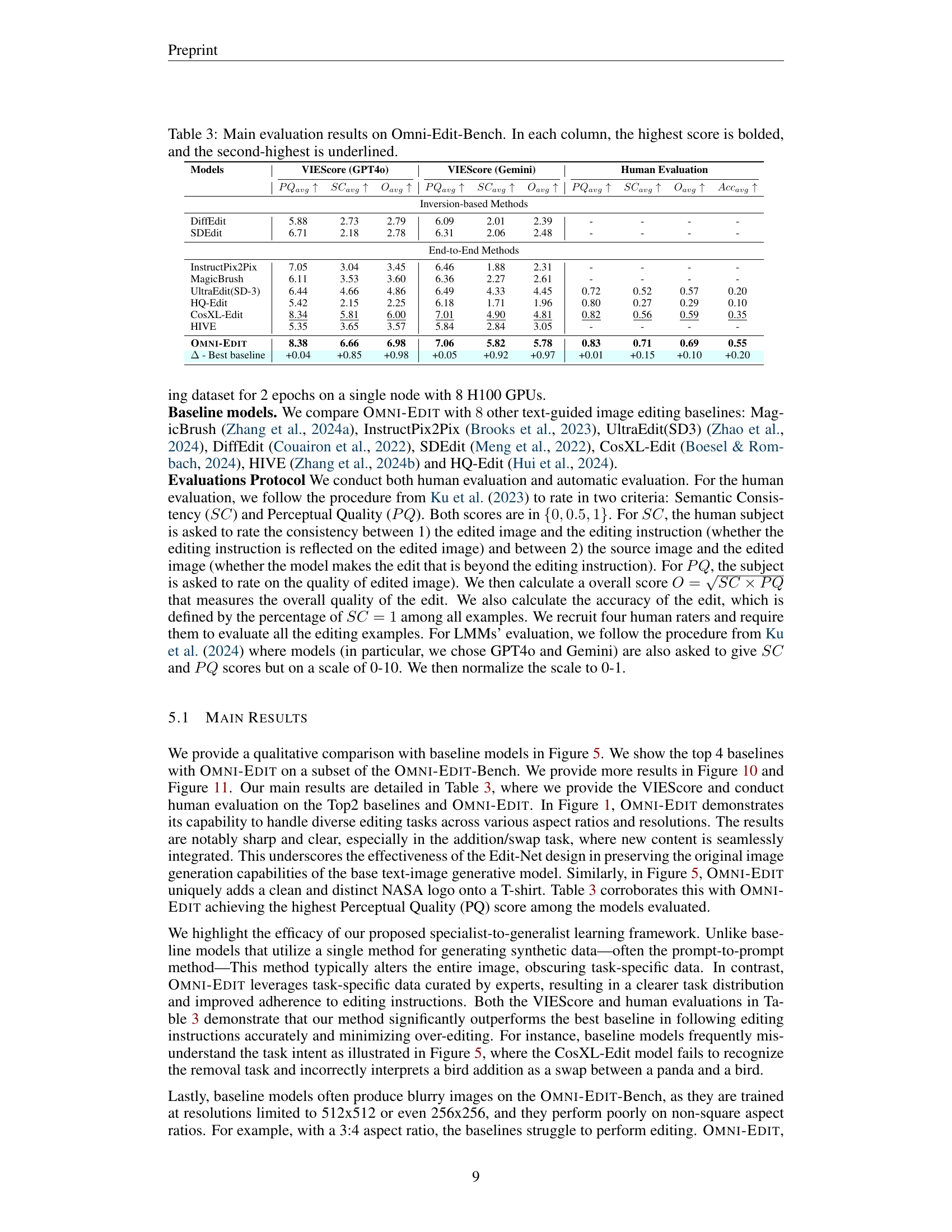
🔼 Table 3 presents a comprehensive evaluation of Omni-Edit and several baseline models on the Omni-Edit-Bench benchmark. The benchmark assesses performance across various image editing tasks, considering both automatic metrics (VIEScore using GPT-40 and Gemini) and human evaluation (Perceptual Quality, Semantic Consistency, Overall Score, and Accuracy). The table highlights the superior performance of Omni-Edit, with the highest scores bolded and the second-highest scores underlined for each evaluation metric, across all models tested. This demonstrates Omni-Edit’s effectiveness in handling diverse image editing challenges.
read the caption
Table 3: Main evaluation results on Omni-Edit-Bench. In each column, the highest score is bolded, and the second-highest is underlined.
| Models | VIEScore (GPT4o) | VIEScore (Gemini) | ||||
|---|---|---|---|---|---|---|
| Omni-Edit | 8.38 | 6.66 | 6.98 | 7.06 | 5.82 | 5.78 |
| Omni-Edit w/o importance sampling | 6.20 | 2.95 | 3.30 | 6.40 | 1.80 | 2.25 |
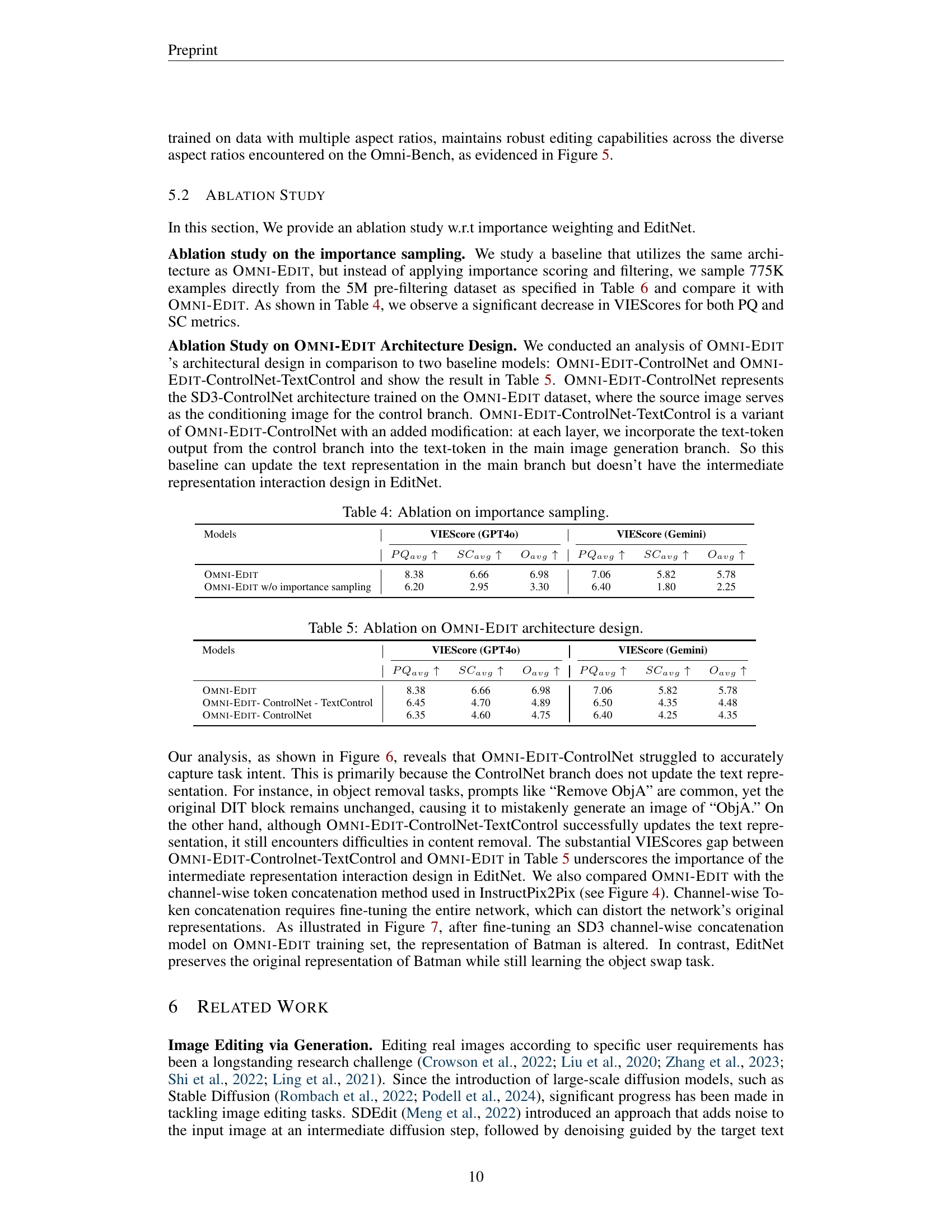
🔼 This table presents the results of an ablation study on the impact of importance sampling in the OMNI-EDIT model. It compares the performance of OMNI-EDIT with and without importance sampling, showing the effect this technique has on the perceptual quality (PQavg), semantic consistency (SCavg), and overall score (Oavg) using two different evaluation metrics: VIEScore (GPT40) and VIEScore (Gemini). This helps determine how crucial importance sampling is for the model’s accuracy and effectiveness.
read the caption
Table 4: Ablation on importance sampling.
| Models | VIEScore (GPT4o) | VIEScore (Gemini) | ||||
|---|---|---|---|---|---|---|
| $PQ_{avg} | ||||||
| ↑$ | $SC_{avg} | |||||
| ↑$ | $O_{avg} | |||||
| ↑$ | $PQ_{avg} | |||||
| ↑$ | $SC_{avg} | |||||
| ↑$ | $O_{avg} | |||||
| ↑$ | ||||||
| Omni-Edit | 8.38 | 6.66 | 6.98 | 7.06 | 5.82 | 5.78 |
| Omni-Edit- ControlNet - TextControl | 6.45 | 4.70 | 4.89 | 6.50 | 4.35 | 4.48 |
| Omni-Edit- ControlNet | 6.35 | 4.60 | 4.75 | 6.40 | 4.25 | 4.35 |
🔼 This table presents the results of an ablation study on the OMNI-EDIT architecture. Three model variations are compared against the full OMNI-EDIT model to assess the impact of specific architectural choices on performance. The models are evaluated using the VIEScore (GPT40 and Gemini) metrics and overall performance is also summarized. This allows for a quantitative analysis of the contribution of each component to OMNI-EDIT’s success.
read the caption
Table 5: Ablation on Omni-Edit architecture design.
| Task | Pre-Filtering Number | After-Filtering Number |
|---|---|---|
| Object Swap | 1,500,000 | 150,000 |
| Object Removal | 1,000,000 | 100,000 |
| Object Addition | 1,000,000 | 100,000 |
| Background Swap | 500,000 | 50,000 |
| Environment Change | 500,000 | 100,000 |
| Style Transfer | 250,000 | 25,000 |
| Object Property Modification | 450,000 | 250,000 |
| Total | 5,200,000 | 775,000 |
🔼 Table 6 presents a detailed breakdown of the Omni-Edit training dataset. It shows the number of image samples considered before and after applying an importance scoring and filtering process. The filtering step is crucial as it selects only high-quality samples with a score of 9 or above, ensuring superior model training. The table lists sample counts for each of the seven image editing tasks included in the dataset.
read the caption
Table 6: Omni-Edit training dataset statistics reflecting the number of samples before and after importance scoring and filtering with o-score ≥\geq≥ 9.
| VIEScore (GPT4o) | VIEScore (Gemini) | |||||
|---|---|---|---|---|---|---|
| $PQ_{avg}[\uparrow]$ | $SC_{avg}[\uparrow]$ | $O_{avg}[\uparrow]$ | $PQ_{avg}[\uparrow]$ | $SC_{avg}[\uparrow]$ | $O_{avg}[\uparrow]$ | |
| Obj-Remove-Specialist | 9.10 | 7.76 | 7.82 | 7.46 | 5.39 | 4.84 |
| Omni-Edit | 8.45 | 7.16 | 7.23 | 7.37 | 5.45 | 5.09 |
| Obj-Replacement-Specialist | 8.48 | 6.92 | 7.02 | 7.06 | 5.68 | 5.36 |
| Omni-Edit | 8.95 | 7.74 | 8.14 | 7.00 | 7.77 | 7.09 |
| Style-Transfer-Specialist | 8.08 | 7.47 | 7.37 | 7.97 | 6.61 | 6.76 |
| Omni-Edit | 7.98 | 5.77 | 6.16 | 8.24 | 5.24 | 6.08 |
🔼 This table presents a quantitative comparison of Omni-Edit’s performance against specialized models trained for individual editing tasks. It uses the VIEScore (a metric evaluating both perceptual quality and semantic consistency using GPT-40 and Gemini language models) to assess performance across different editing categories. The table highlights the differences in performance between the generalist Omni-Edit model and the specialized models to show the effectiveness and limitations of a generalist approach compared to specialized approaches.
read the caption
Table 7: Comparison between Omni-Edit and our specialist models.
Full paper#