↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Adding objects to images based on text instructions is a difficult task that has yet to be fully solved. Prior methods either fail to properly integrate new objects into the scene or lack generalization capabilities. This paper introduces Add-it, a training-free method designed to address this issue.
Add-it uses a pretrained diffusion model and enhances its multi-modal attention mechanism to cleverly balance information from the scene image, text prompt, and generated image. This allows for the seamless integration of new objects into images while preserving the structural consistency and fine details of the original image. The paper demonstrates state-of-the-art results on various benchmarks, surpassing previous methods by a significant margin and even outperforming supervised approaches.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel training-free method for object insertion in images, surpassing existing methods. It addresses a key challenge in image editing by achieving a balance between preserving the original scene and seamlessly integrating new objects. The introduction of a new benchmark and evaluation protocol further contributes to the field’s advancement. Researchers can leverage this approach to improve their image editing techniques and explore new applications in computer graphics, content creation, and synthetic data generation.
Visual Insights#

🔼 Figure 1 presents pairs of images demonstrating the Add-it model’s object insertion capabilities. Each pair shows an input image (left) and the corresponding output image after Add-it has seamlessly added an object based on a simple text prompt. The top row displays examples with real input images, and the middle row uses generated input images. Add-it is shown to naturally integrate objects into the scene, preserving the existing image’s quality. This process can be iterated to construct intricate scenes step-by-step, without the usual need for optimization or pre-training.
read the caption
Figure 1: Given an input image (left in each pair), either real (top row) or generated (mid row), along with a simple textual prompt describing an object to be added Add-it seamlessly adds the object to the image in a natural way. Add-it allows the step-by-step creation of complex scenes without the need for optimization or pre-training.
| I-Pix2Pix | Erasedraw | Magicbrush | SDEdit | P2P | Ours | |
|---|---|---|---|---|---|---|
| Affordance | 0.276 | 0.341 | 0.418 | 0.397 | 0.474 | 0.828 |
🔼 This table presents a comparison of different image editing methods based on their performance on the Additing Affordance Benchmark. The Additing Affordance Benchmark specifically focuses on evaluating the plausibility of object placement in images after adding new objects. The table shows the Affordance scores achieved by several methods, including the authors’ proposed method (Ours), highlighting its superior performance in accurately and naturally placing objects within the context of the original image.
read the caption
Table 1: Comparison of methods based on Affordance score for the Additing Affordance Benchmark.
In-depth insights#
Add-it: Overview#
An overview of Add-it would highlight its core functionality as a training-free object insertion method for images, leveraging pretrained diffusion models. It avoids the limitations of training-based approaches by ingeniously extending the models’ attention mechanisms, allowing it to seamlessly integrate new objects into existing scenes guided by text prompts. A key innovation is its weighted extended-attention mechanism, which carefully balances information from the source image, the generated image, and the text prompt, ensuring both realism and adherence to instructions. This balance is crucial for achieving natural object placement and contextual integration, addressing a common weakness in prior methods. The system also incorporates structure transfer to maintain the integrity of the original scene, and subject-guided latent blending to preserve fine details. The result is an approach that exhibits state-of-the-art performance in object insertion while sidestepping the need for extensive training data, making it a powerful and efficient solution for image editing tasks.
Attention Mechanism#
The effectiveness of the Add-it model hinges on its novel attention mechanism, which cleverly integrates information from three key sources: the source image, the text prompt, and the generated image itself. This multi-modal approach goes beyond previous methods that only consider the image or the text prompt independently. The weighting of these three sources is crucial, dynamically adjusting based on the content to avoid overemphasizing any single component. This prevents the generated image from simply copying the source image or ignoring the text prompt completely. This weighted attention, combined with a structure transfer step and latent blending, ensures that both the textual instructions and the existing scene are faithfully represented in the final output. The ability to balance these sources dynamically is a significant advancement in open-world object insertion, allowing for more seamless and realistic results. This is especially noteworthy given the model’s training-free nature, showcasing a powerful application of existing diffusion model capabilities.
Affordance Metrics#
The concept of “Affordance Metrics” in evaluating object insertion models is crucial. It addresses the challenge of assessing whether an added object appears realistically placed within a scene, considering its interaction with the existing environment. Existing metrics often focus on visual fidelity and semantic correctness, neglecting the crucial aspect of object placement plausibility. A well-defined affordance metric should quantify how naturally an object fits into its environment, taking into account factors like spatial relationships, object size relative to surroundings, and contextual appropriateness. This could involve comparing the generated image against human annotations of plausible object placements, perhaps utilizing techniques like bounding box overlap or distance from semantically relevant objects. A robust affordance metric could significantly advance the field by enabling more nuanced comparisons between models, going beyond simple visual similarity scores and promoting the development of more intelligent and context-aware object insertion algorithms. Furthermore, it’s important to consider the cultural and context-dependent nature of affordances, ensuring that metrics are designed to capture the subjective perception of natural placement across diverse scenes and user groups.
Add-it Limitations#
The Add-it model, while demonstrating state-of-the-art performance in training-free object insertion, exhibits certain limitations. Bias inherited from pretrained diffusion models may lead to inaccuracies or unrealistic placements, particularly in complex or unusual scenes. The reliance on target prompts rather than explicit instructions necessitates careful prompt engineering to achieve desired results. Performance discrepancies between real and generated images highlight a need for improved inversion techniques to fully unlock Add-it’s potential with real-world imagery. Lastly, Add-it’s handling of already existing objects within the image is inconsistent; sometimes failing to add a new object of the same type or misinterpreting the prompt. Addressing these limitations through further research, such as exploring bias mitigation techniques, refining prompt interpretation, or improving inversion methods, would significantly enhance the method’s robustness and versatility.
Future Directions#
Future research directions for training-free object insertion in images using pretrained diffusion models could focus on several key areas. Improving affordance prediction is crucial, perhaps through incorporating more sophisticated scene understanding models or integrating 3D scene context. Addressing the limitations in handling complex scenes and diverse object types would involve developing more robust attention mechanisms or exploring alternative architectural designs. Enhancing the controllability of the insertion process, allowing users to fine-tune object size, position, and appearance more precisely, is also vital. Furthermore, reducing reliance on high-resolution images would broaden applicability, perhaps through upscaling or super-resolution techniques combined with the diffusion model. Finally, investigating the ethical implications of this technology and developing mitigation strategies for potential misuse, such as generating realistic but fake images, is crucial for responsible innovation.
More visual insights#
More on figures

🔼 This figure illustrates the Add-it model’s architecture. It begins with a source noise image (XsourceTsuperscriptsubscript𝑋𝑠𝑜𝑢𝑟𝑐𝑒𝑇X_{source}^{T}) and a target noise image (XtargetTsuperscriptsubscript𝑋𝑡𝑎𝑟𝑔𝑒𝑡𝑇X_{target}^{T}), along with a text prompt (Ptargetsubscript𝑃𝑡𝑎𝑟𝑔𝑒𝑡P_{target}). First, a ‘Structure Transfer’ step injects the source image’s structure into the target image. Next, the self-attention blocks are modified so the target noise image attends to both the text prompt and the source noise image, with their contributions weighted separately. Finally, ‘Subject Guided Latent Blending’ is used to preserve fine details from the original source image in the final output.
read the caption
Figure 2: Architecture outline: Given a tuple of source noise XsourceTsuperscriptsubscript𝑋𝑠𝑜𝑢𝑟𝑐𝑒𝑇X_{source}^{T}italic_X start_POSTSUBSCRIPT italic_s italic_o italic_u italic_r italic_c italic_e end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT, target noise XtargetTsuperscriptsubscript𝑋𝑡𝑎𝑟𝑔𝑒𝑡𝑇X_{target}^{T}italic_X start_POSTSUBSCRIPT italic_t italic_a italic_r italic_g italic_e italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT, and a text prompt Ptargetsubscript𝑃𝑡𝑎𝑟𝑔𝑒𝑡P_{target}italic_P start_POSTSUBSCRIPT italic_t italic_a italic_r italic_g italic_e italic_t end_POSTSUBSCRIPT, we first apply Structure Transfer to inject the source image’s structure into the target image. We then extend the self-attention blocks so that XtargetTsuperscriptsubscript𝑋𝑡𝑎𝑟𝑔𝑒𝑡𝑇X_{target}^{T}italic_X start_POSTSUBSCRIPT italic_t italic_a italic_r italic_g italic_e italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT pulls keys and values from both Ptargetsubscript𝑃𝑡𝑎𝑟𝑔𝑒𝑡P_{target}italic_P start_POSTSUBSCRIPT italic_t italic_a italic_r italic_g italic_e italic_t end_POSTSUBSCRIPT and XsourceTsuperscriptsubscript𝑋𝑠𝑜𝑢𝑟𝑐𝑒𝑇X_{source}^{T}italic_X start_POSTSUBSCRIPT italic_s italic_o italic_u italic_r italic_c italic_e end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT, with each source weighted separately. Finally, we use Subject Guided Latent Blending to retain fine details from the source image.

🔼 This figure presents the results of a user study comparing the performance of different image editing methods on real images from the Emu Edit Benchmark. The study involved human participants who were asked to evaluate the quality of image edits, considering factors such as realism, accuracy, and the preservation of the original image’s appearance. The results are shown in terms of win rates (percentage of times each method was preferred over its counterpart). This visual representation helps to assess the effectiveness of each method in adding objects into images naturally and seamlessly.
read the caption
Figure 3: User Study results evaluated on the real images from the Emu Edit Benchmark.

🔼 This figure presents the results of a user study comparing Add-it’s performance on generated images from the Image Additing Benchmark against other methods. The study measured user preference for the generated images produced by different methods in an A/B test. The chart likely visually displays a comparison, showing win rates or preference percentages across different methods, giving a clear picture of which method is preferred for generating images based on textual input within this specific benchmark.
read the caption
Figure 4: User Study results evaluated on the generated images from the Image Additing Benchmark.

🔼 Figure 5 presents a qualitative comparison of object insertion results on the Emu-Edit benchmark dataset. The benchmark involves adding objects to images based on textual instructions. The figure showcases that while other methods struggle to place the added objects in a natural and believable location within the scene, often resulting in awkward or unrealistic placements, the proposed method successfully integrates the new object into the image in a way that appears realistic and seamless. This illustrates the superior ability of the proposed approach to understand and address the complexities of object placement in image editing.
read the caption
Figure 5: Qualitative Results from the Emu-Edit Benchmark. Unlike other methods, which fail to place the object in a plausible location, our method successfully achieves realistic object insertion.

🔼 Figure 6 presents a qualitative comparison of object insertion results from different methods on the Additing Benchmark dataset. The top row shows the results for the task of adding a toy truck to a child’s hands. The middle row demonstrates the results for adding a shopping bag to a man. The bottom row shows the results for adding a microscope to a scene. The images reveal that Prompt-to-Prompt struggles to maintain consistency with the source image while SDEdit fails to accurately incorporate the text prompt’s specifications. In contrast, the proposed Add-it method successfully integrates the requested objects into the images while maintaining the original scene’s integrity and adhering to the textual instructions.
read the caption
Figure 6: Qualitative Results from the Additing Benchmark. While Prompt-to-Prompt fails to align with the source image, and SDEdit fails to align with the prompt, our method offers Additing that adheres to both prompt and source image.

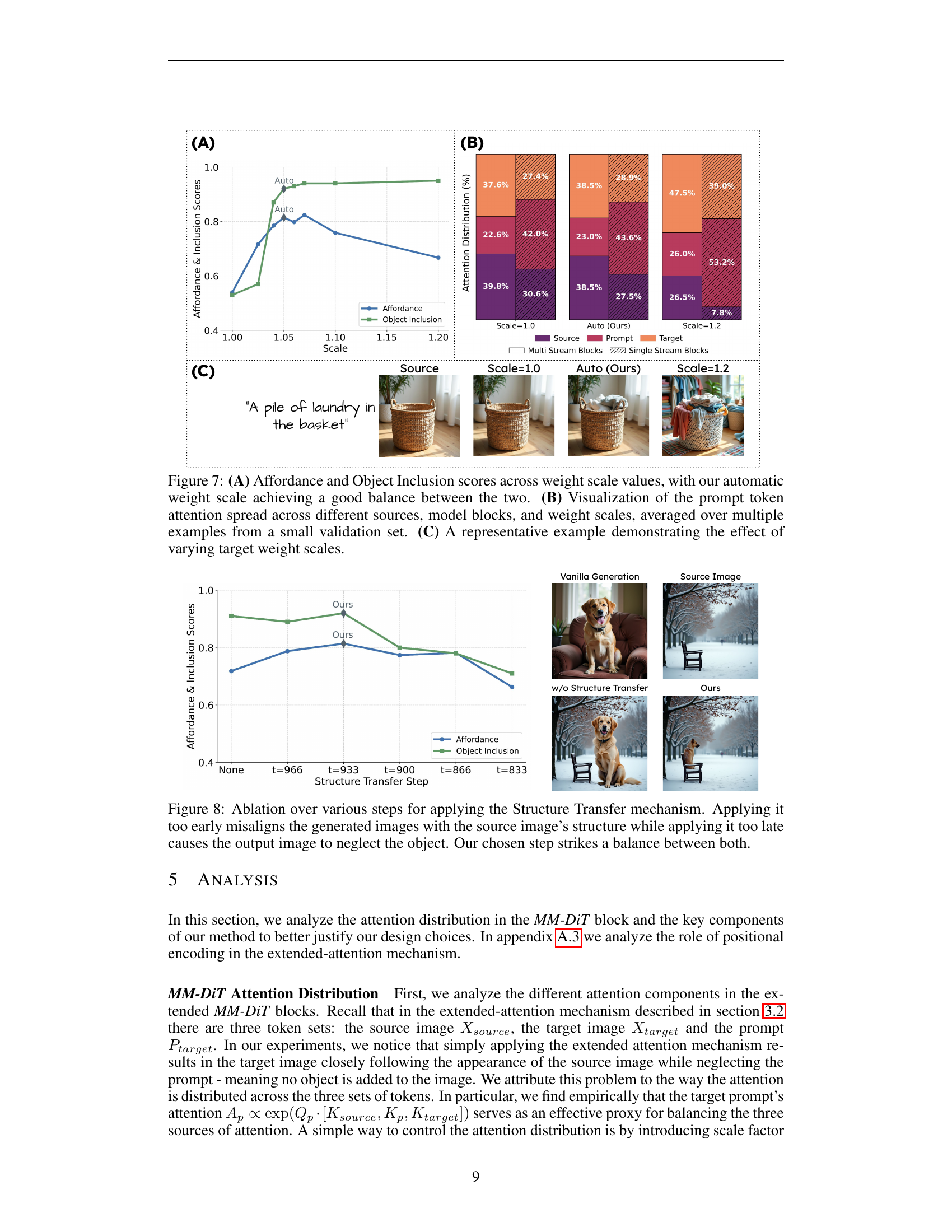
🔼 This figure analyzes the impact of different weight scales on the performance of the Add-it model. Panel (A) shows the Affordance and Object Inclusion scores across various weight scales, demonstrating that the automatically determined weight scale finds a balance between these two metrics. Panel (B) visualizes the distribution of attention from different sources (source image, prompt, target image) across different model blocks and weight scales. This visualization is an average across multiple examples from a validation set, showing how attention is weighted differently at various scales. Finally, panel (C) provides a specific example illustrating the effects of altering the target weight scale on the model’s output, highlighting how this parameter influences object insertion and the balance between the original image and the textual prompt.
read the caption
Figure 7: (A) Affordance and Object Inclusion scores across weight scale values, with our automatic weight scale achieving a good balance between the two. (B) Visualization of the prompt token attention spread across different sources, model blocks, and weight scales, averaged over multiple examples from a small validation set. (C) A representative example demonstrating the effect of varying target weight scales.

🔼 This figure shows an ablation study on the structure transfer step within the Add-it model. The study tests the impact of applying the structure transfer mechanism at different stages of the denoising process. Applying it too early leads to a mismatch between the generated image and the source image’s structure, while applying it too late leads to the generated image neglecting the object to be added. The figure shows that applying the structure transfer step at a specific stage (the chosen step) finds an optimal balance between preserving the source image structure and effectively adding the intended object.
read the caption
Figure 8: Ablation over various steps for applying the Structure Transfer mechanism. Applying it too early misaligns the generated images with the source image’s structure while applying it too late causes the output image to neglect the object. Our chosen step strikes a balance between both.

🔼 Figure 9 presents a comparison of images generated by the Add-it model, illustrating the impact of the latent blending step on image quality and detail preservation. The top row shows the original source image. The middle row displays images generated using Add-it without latent blending; these images show some discrepancies between the added object and the existing scene’s details. The bottom row shows images generated with latent blending; here, the fine details of the source image (such as the girl’s glasses and the shadows under the bicycles) are better preserved, leading to a more seamless and natural integration of the added object into the image. An affordance map is also provided, visually highlighting the areas where the model deems it plausible to add the specified object. This map provides insights into the model’s decision-making process, explaining how it considers the context of the scene while adding the new object.
read the caption
Figure 9: Images generated by Add-it with and without the latent blending step, along with the resulting affordance map. The latent blending block helps align fine details from the source image, such as removing the girl’s glasses or adjusting the shadows of the bicycles.

🔼 This figure demonstrates a limitation of the Add-it model. When instructed to add an object that is already present in the image (a dog), instead of adding a second, distinct dog, the model duplicates the existing dog. However, the model correctly adds a new element that is not already in the image (a person standing behind the dog), highlighting the model’s ability to successfully introduce new objects but struggles with adding duplicates of existing objects.
read the caption
Figure 10: Add-it may fail to add a subject that already exists in the source image. When prompted to add another dog to the image, Add-it generates the same dog instead, though it successfully adds a person behind the dog.

🔼 Figure 11 presents a series of images demonstrating the step-by-step image generation capability of the Add-it model. It showcases how Add-it can iteratively build a complex scene by incorporating new elements based on sequential textual instructions. The process starts with a simple image and progressively adds more details with each new prompt, illustrating the model’s ability to adapt to user preferences and maintain coherence across the steps. This dynamic approach to image generation allows for more creative control and fine-grained adjustments.
read the caption
Figure 11: Step-by-Step Generation: Add-it can generate images incrementally, allowing it to better adapt to user preferences at each step.

🔼 Figure 12 presents qualitative examples from the Additing Affordance Benchmark. Each example shows a source image and its corresponding output after applying the Add-it method. The benchmark focuses on evaluating object insertion in plausible locations, and these results demonstrate the model’s ability to successfully add various objects naturally into the scenes, maintaining the contextual integrity of the original images.
read the caption
Figure 12: Qualitative results of our method on the Additing Affordance Benchmark show that our method successfully adds objects naturally and in plausible locations.

🔼 Figure 13 presents examples demonstrating Add-it’s ability to successfully integrate new objects into images that are not photorealistic, such as paintings and pixel art. This showcases the method’s adaptability and generalizability beyond typical photographic images. The results highlight the method’s robustness in handling diverse image styles while maintaining image quality and object placement consistency.
read the caption
Figure 13: Our method can operate on non-photorealistic images.

🔼 This figure demonstrates the inherent stochasticity of diffusion models. Despite using the same input image and prompt, Add-it produces diverse, yet equally plausible, outputs due to the variability introduced by different random noise initializations. This highlights Add-it’s ability to generate a range of natural-looking results while maintaining consistency with the source image and user instructions.
read the caption
Figure 14: Our method generates different outputs when given different starting noises. All the outputs remain plausible.

🔼 This figure demonstrates the impact of positional encoding on object placement within the Add-it model. By artificially shifting the positional encoding vectors of the source image, the model’s output shows a corresponding shift in the added object’s location. This highlights the model’s reliance on positional information for accurate object insertion, even overriding visual context.
read the caption
Figure 15: Positional Encoding Analysis: shifting the positional encoding of the source image results in a corresponding shift in the object’s location in the generated image.

🔼 Figure 16 presents three examples where the Add-it model fails. The first shows sunglasses added to a scene, but in an implausible location. The second shows a Pikachu added to a scene where it replaces an existing object, indicating the model’s bias toward adding objects instead of integrating them into the scene naturally. The third shows the model struggling with a complex scene (a woman cooking), suggesting that scene complexity limits Add-it’s performance.
read the caption
Figure 16: Failure cases: Add-it may fail generating the added object in the right location (sunglasses), it can be biased to replace existing object in the scene (Pikachu) and it can struggle with complicated scenes (woman cooking).

🔼 Figure 17 presents visual examples from the Additing Affordance Benchmark dataset. Each image showcases a scene with several potential locations for adding an object, indicated by bounding boxes. These boxes highlight the areas where an object can be naturally inserted without disrupting the image’s composition or context. The purpose is to evaluate the plausibility of object placement in image editing tasks.
read the caption
Figure 17: Visual examples from the Additing Affordance Benchmark. Each image is annotated with bounding boxes highlighting the plausible areas where the object can be added.

🔼 This figure shows the prompt given to ChatGPT to generate the Additing Affordance Benchmark dataset. The prompt instructs ChatGPT to create a JSON list of 300 data points. Each data point contains a source image prompt describing a scene, a target image prompt describing the same scene with an added object, the instruction for adding the object, and the name of the added object (the subject token). The prompt emphasizes the need for clear, unambiguous instructions and only includes examples with one plausible location for adding the object. This ensures high-quality annotations for the benchmark.
read the caption
Figure 18: The prompt provided to ChatGPT in order to generate the Affordance Benchmark.
Full paper#