↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Aligning large language models (LLMs) with human preferences is crucial but challenging. Current methods like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) often suffer from computational inefficiencies and training instability. This limits their applicability, especially when dealing with large models and limited resources.
This paper introduces Feature-level constrained Preference Optimization (FPO), a novel method designed to address these issues. FPO uses pre-trained sparse autoencoders to create sparse feature representations. By imposing constraints at the feature level, FPO achieves efficient and stable alignment. Experiments show that FPO outperforms state-of-the-art methods by over 5% in win rate while significantly reducing computational cost, making it a promising solution for efficient and controllable LLM alignment.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel and efficient approach to aligning large language models with human preferences. It addresses the computational inefficiencies and training instability of existing methods by using sparse feature-level constraints, leading to improved accuracy and diversity. This work opens new avenues for research in efficient and controllable LLM alignment, particularly for resource-constrained settings. The findings also have implications for the interpretability of LLMs and the development of more robust and reliable AI systems.
Visual Insights#

🔼 Figure 1 illustrates the core concept of Direct Preference Optimization (DPO) and two of its main improvements, SimPO and TDPO, alongside the proposed Feature-level Preference Optimization (FPO). The left panel shows the DPO loss function which leverages a reference model to guide the alignment process. SimPO is depicted as simplifying the DPO process by removing the need for a reference model. TDPO is shown as focusing on controlling the alignment process at the token-level to improve generation diversity. The right panel details the FPO pipeline which uses sparse autoencoders to generate sparse feature representations that are then used to apply MSE (mean squared error) constraints for efficient and stable alignment.
read the caption
Figure 1: Left. The DPO objective loss function and its two main improvement directions: SimPO and TDPO. SimPO focuses on simplifying the reference model, while TDPO concentrates on controlling the alignment process to enhance generation diversity. Right. The pipeline of FPO consists of sparse autoencoders and the feature-level MSE constraints.
| Method | Reference | Efficiency | Constraint |
|---|---|---|---|
| SFT | Free | High | Weak |
| DPO | Offline | High | Weak |
| SimPO | Free | High | Weak |
| TDPO | Needed | Low | Strong / Dense |
| FPO(Ours) | Offline | High | Strong / Sparse |
🔼 This table details the specific mathematical formulas and parameters used in Direct Preference Optimization (DPO), Simple Preference Optimization (SimPO), Token-Level Direct Preference Optimization (TDPO), and the novel Feature-level Preference Optimization (FPO) method. It breaks down each method’s calculation of the log probability difference (LPD), margin, and constraint terms, illustrating their similarities and differences. The table highlights how FPO incorporates a novel feature-level constraint using sparse autoencoders and an offline reference margin, improving efficiency and stability compared to existing methods.
read the caption
Table 1: Specific implementations of Log Probability Difference (LPD), Margin, and Constraint in Equation 10 for DPO, its variants SimPO and TDPO, and the proposed FPO.
In-depth insights#
Sparse Feature Alignment#
Sparse feature alignment is a promising technique for improving the efficiency and effectiveness of aligning large language models (LLMs) with human preferences. By focusing on a sparse subset of the most informative features, rather than all of the model’s parameters, it offers several key advantages. Computational efficiency is significantly enhanced because only a small fraction of the model’s parameters are updated during training, thus reducing memory and time requirements. Training stability is improved because the fewer parameters are less prone to overfitting and instability. Furthermore, controllability is enhanced because the alignment process can be more precisely targeted to specific features, leading to better control over generation diversity and avoiding unintended changes in other aspects of the model’s behavior. Interpretability may also be enhanced, as the sparse features used often reflect a more meaningful and organized representation of the model’s internal knowledge. However, careful consideration must be given to the selection of features and the algorithm used to constrain them, to avoid potential limitations such as neglecting important features or introducing biases during the alignment process. Future research should focus on exploring more sophisticated feature selection methods, developing new and robust constraint algorithms, and evaluating the long-term effects on model behavior and performance.
FPO: Efficiency Gains#
The heading ‘FPO: Efficiency Gains’ suggests an examination of how the proposed Feature-level Preference Optimization (FPO) method improves efficiency compared to existing techniques for aligning large language models (LLMs). A deep dive would explore the computational cost reduction achieved by FPO, likely contrasting it against methods like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO). Key aspects to analyze would include memory usage, training time, and the computational complexity of the algorithm itself. The discussion should quantify these gains, possibly using benchmark datasets and presenting results showing the reduction in runtime or resource consumption. Furthermore, any trade-offs between efficiency and other desirable qualities, such as alignment accuracy or the diversity of generated outputs, should be thoroughly examined. The analysis should highlight the specific components of FPO responsible for the efficiency gains, such as the use of Sparse Autoencoders (SAEs) and offline computation of reference model outputs. Ultimately, the section should present a convincing argument that FPO offers a significant advantage in terms of efficiency without sacrificing performance or controllability, making it a practical solution for large-scale LLM alignment.
Offline Reference Use#
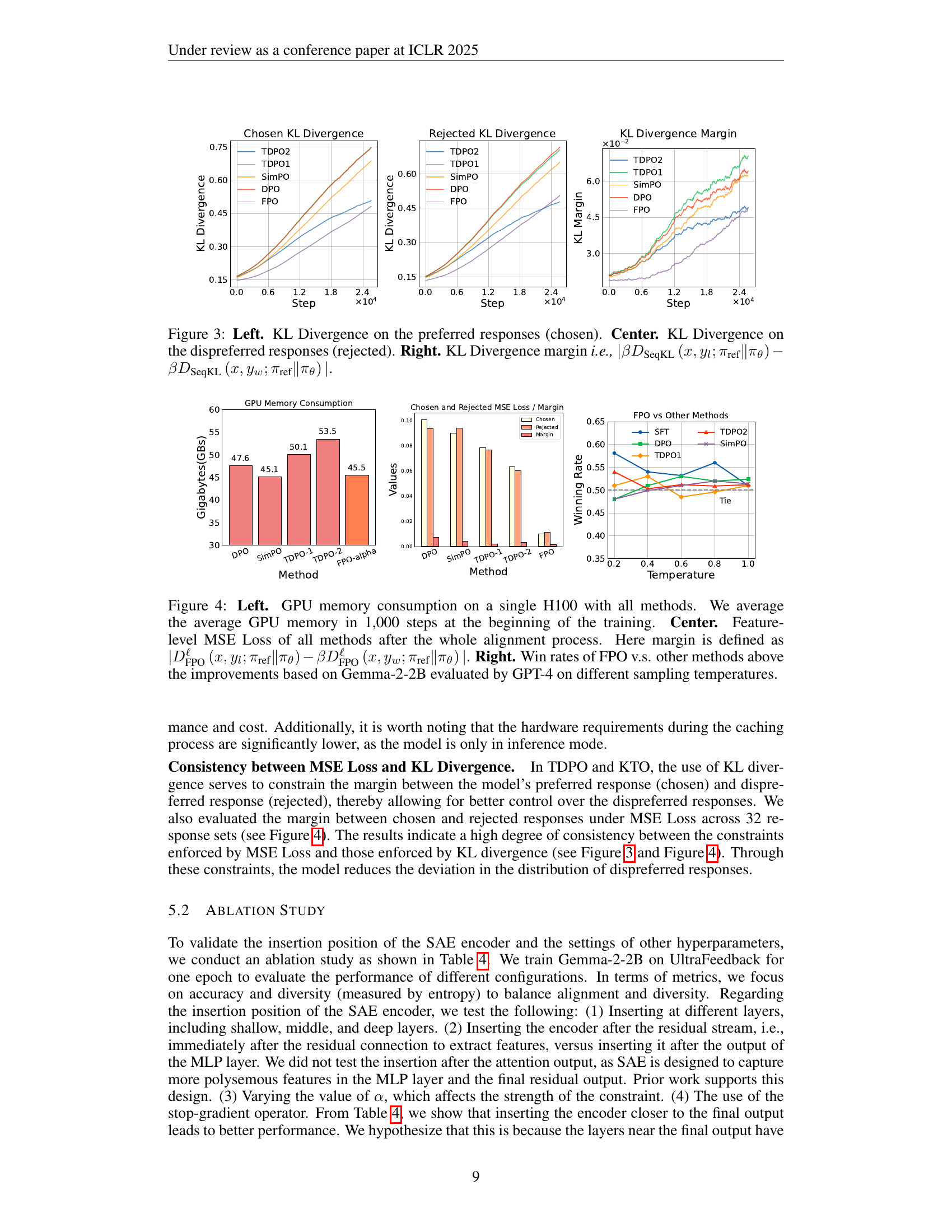
The concept of ‘Offline Reference Use’ in the context of preference optimization for LLMs offers a compelling solution to address computational efficiency and stability issues. By pre-computing and storing reference model outputs offline, the method bypasses the need to load and process this information during the computationally expensive training phase. This approach dramatically improves efficiency, particularly when using large models or datasets. The strategic caching of relevant reference data significantly reduces runtime memory consumption and training time. Furthermore, the decoupling of reference model computation from online training enhances stability and robustness, preventing the reference model from affecting the dynamics of the training loop. This technique is particularly beneficial for alignment methods based on KL divergence or other metrics that demand substantial computational resources. While the pre-computation step requires some upfront effort, the significant gains in efficiency and stability during online training significantly outweigh this initial investment. The effectiveness of ‘Offline Reference Use’ is also shown to be impactful for methods employing sparse representations, creating a synergy between efficiency and data sparsity. This approach successfully balances practicality with theoretical soundness, offering a highly promising pathway for efficient and scalable LLM alignment.
Controllable Alignment#
Controllable alignment in large language models (LLMs) is crucial for ensuring their safe and beneficial use. It focuses on developing techniques that allow for precise control over the LLM’s behavior, preventing unintended outputs or biases. Current methods often struggle with a trade-off between alignment effectiveness and the ability to finely tune the model’s responses. Sparse feature-level constraints offer a promising approach, allowing for targeted adjustments to the LLM’s latent representations, potentially leading to more efficient and stable alignment. Further research should explore methods that combine sparse feature constraints with other techniques, such as reward shaping or reinforcement learning, to achieve a more sophisticated level of control over the model’s outputs and behavior, ultimately ensuring that LLMs are reliable and aligned with human values. This requires addressing the challenge of interpretability, ensuring the model’s actions and reasoning are transparent and understandable. Furthermore, exploring methods that enable user-specified constraints and preferences would enhance controllability, allowing for customization and fine-tuning that fits specific applications.
Ablation Study Results#
An ablation study systematically removes components of a model or system to assess their individual contributions. In this context, an ‘Ablation Study Results’ section would detail the impact of removing specific features or constraints. Key insights would revolve around the relative importance of each component, showing which are crucial for performance and which have minimal effects. Quantifiable metrics, like accuracy, precision, recall, or efficiency, would be used to measure the impact of each ablation. The results might reveal unexpected interactions between components, indicating areas for improvement or simplification. A well-executed ablation study provides valuable insights into the model’s architecture and design choices, ultimately facilitating further development and optimization. A strong focus on both quantitative and qualitative analysis of the results is critical to paint a comprehensive picture. The analysis should highlight not just the performance changes, but also the implications for cost, complexity, and interpretability.
More visual insights#
More on tables
| Method | LPD | Margin | Constraint | Constraint Type | ||||
|---|---|---|---|---|---|---|---|---|
| DPO | (\beta\log\pi_{\theta}(y_{w} | x)-\beta\log\pi_{\theta}(y_{l} | x)) | (\gamma_{\text{ref}}) | 0 | |||
| SimPO | (\frac{\beta}{ | y_{w} | }\log\pi_{\theta}(y_{w} | x)-\frac{\beta}{ | y_{l} | }\log\pi_{\theta}(y_{l} | x)) | |
| TDPOi | (\beta\log\pi_{\theta}(y_{w} | x)-\beta\log\pi_{\theta}(y_{l} | x)) | (\gamma_{\text{ref}}) | (\delta_{\text{TDPO}{i}}(x,y{w},y_{l})) | |||
| FPO | (\frac{\beta}{ | y_{w} | }\log\pi_{\theta}(y_{w} | x)-\frac{\beta}{ | y_{l} | }\log\pi_{\theta}(y_{l} | x))) |
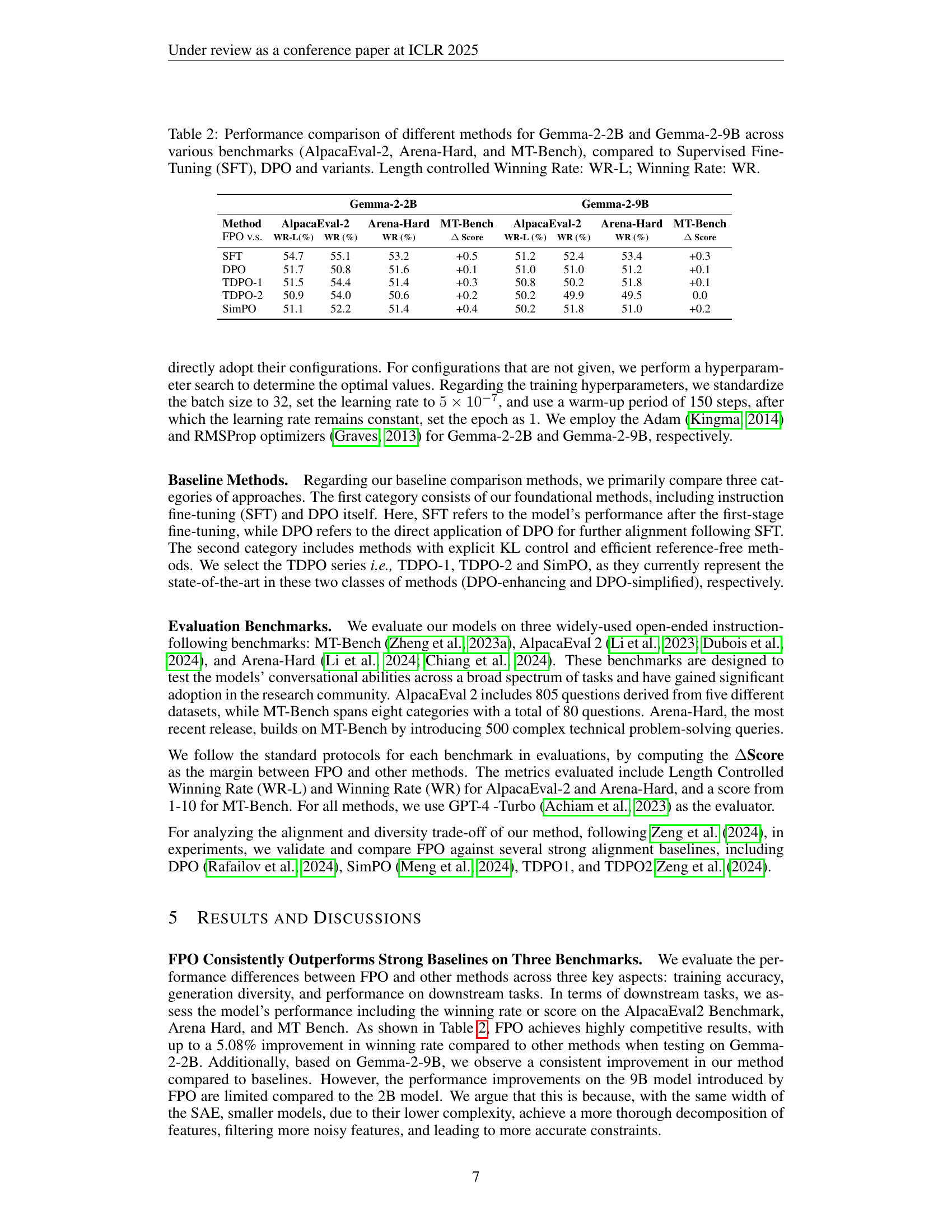
🔼 This table presents a performance comparison of several methods for aligning large language models (LLMs). It specifically uses the Gemma-2-2B and Gemma-2-9B models, evaluating their performance across three benchmark datasets: AlpacaEval-2, Arena-Hard, and MT-Bench. The results are compared against a supervised fine-tuning (SFT) baseline and several Direct Preference Optimization (DPO) variants. Key metrics include winning rates (WR), both with and without length control (WR-L), and a delta score indicating the improvement over the baselines. This allows for a comprehensive evaluation of the various methods’ effectiveness and efficiency in achieving LLM alignment.
read the caption
Table 2: Performance comparison of different methods for Gemma-2-2B and Gemma-2-9B across various benchmarks (AlpacaEval-2, Arena-Hard, and MT-Bench), compared to Supervised Fine-Tuning (SFT), DPO and variants. Length controlled Winning Rate: WR-L; Winning Rate: WR.
| Method | Accuracy (%) ↑ | Diversity (Entropy) ↑ |
|---|---|---|
| DPO | 59.9 | 1.66 |
| TDPO-1 | 63.2 | 1.65 |
| TDPO-2 | 64.2 | 1.68 |
| SimPO | 63.4 | 1.64 |
| FPO | 64.1 | 1.68 |
🔼 This table presents a comparison of the performance of FPO against other baseline methods. The comparison focuses on two key aspects: alignment (measured by accuracy) and diversity (measured by entropy). Accuracy represents how well the model aligns with human preferences. Higher accuracy indicates better alignment. Diversity (entropy) measures the variety of generated responses. Higher entropy indicates more diverse outputs. The results are evaluated using the UltraFeedback dataset, which is specifically designed to assess instruction-following abilities of LLMs. The table helps illustrate the trade-off between alignment and diversity, showing how FPO balances these two aspects.
read the caption
Table 3: Comparison of FPO and other baseline methods in terms of the trade-off between Alignment (accuracy) and Diversity (entropy) on the UltraFeedback dataset.
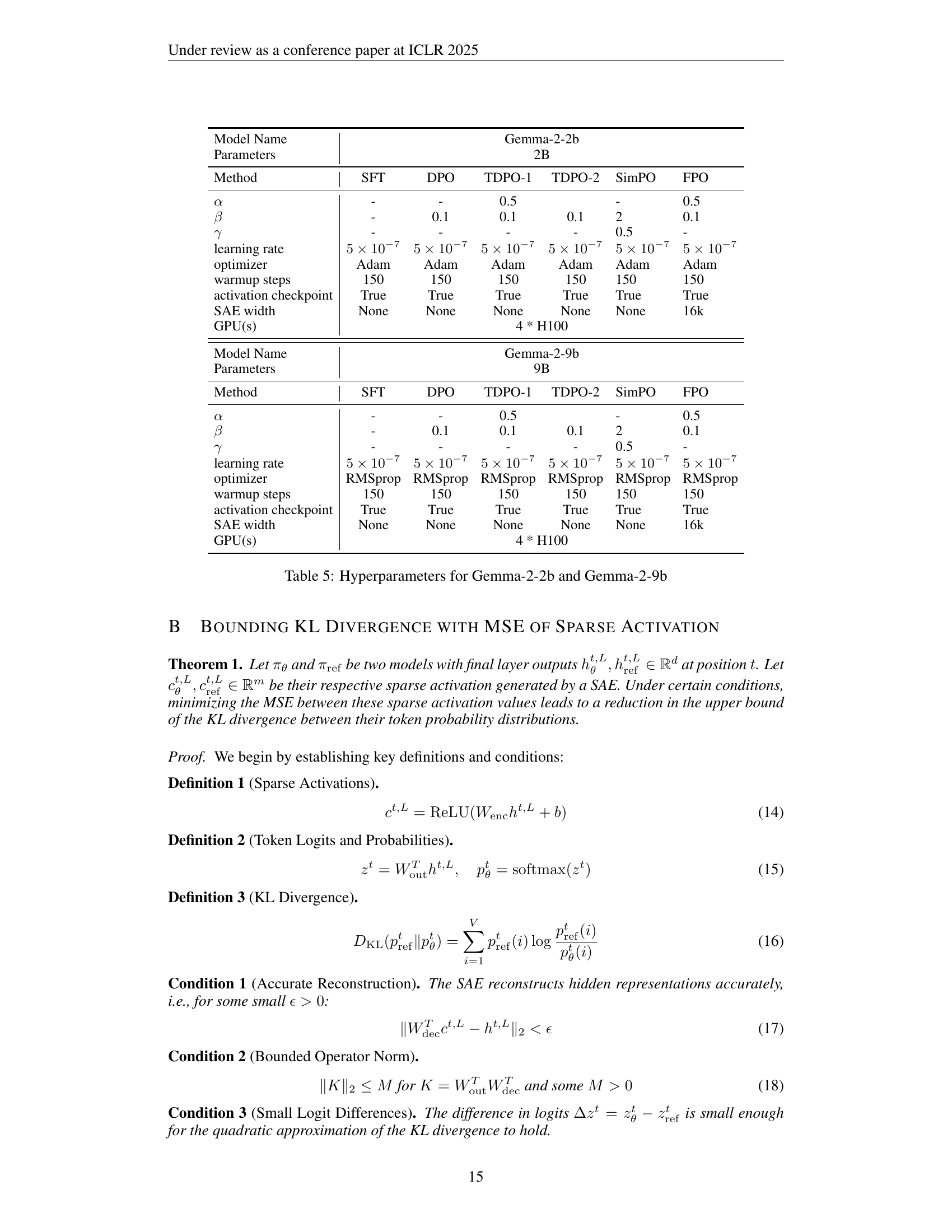
| Model Name | Parameters | Method | SFT | DPO | TDPO-1 | TDPO-2 | SimPO | FPO |
|---|---|---|---|---|---|---|---|---|
| Gemma-2-2b | 2B | SFT | - | - | 0.5 | - | 0.5 | |
| DPO | - | - | 0.1 | 0.1 | 2 | 0.1 | ||
| TDPO-1 | 0.5 | - | - | - | 0.5 | - | ||
| TDPO-2 | 0.1 | 0.1 | 0.1 | 2 | 0.1 | |||
| SimPO | - | - | - | - | 0.5 | - | ||
| FPO | 0.5 | - | - | - | - | 0.5 | ||
| learning rate | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | |
| optimizer | Adam | Adam | Adam | Adam | Adam | Adam | ||
| warmup steps | 150 | 150 | 150 | 150 | 150 | 150 | ||
| activation checkpoint | True | True | True | True | True | True | ||
| SAE width | None | None | None | None | None | 16k | ||
| GPU(s) | 4 * H100 | |||||||
| Gemma-2-9b | 9B | SFT | - | - | 0.5 | - | 0.5 | |
| DPO | - | 0.1 | 0.1 | 0.1 | 2 | 0.1 | ||
| TDPO-1 | 0.5 | - | - | - | 0.5 | - | ||
| TDPO-2 | 0.1 | 0.1 | 0.1 | 2 | 0.1 | |||
| SimPO | - | - | - | - | 0.5 | - | ||
| FPO | 0.5 | - | - | - | - | 0.5 | ||
| learning rate | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | $5\times 10^{-7}$ | ||
| optimizer | RMSprop | RMSprop | RMSprop | RMSprop | RMSprop | RMSprop | ||
| warmup steps | 150 | 150 | 150 | 150 | 150 | 150 | ||
| activation checkpoint | True | True | True | True | True | True | ||
| SAE width | None | None | None | None | None | 16k | ||
| GPU(s) | 4 * H100 |
🔼 This ablation study investigates the impact of different SAE layers, hyperparameters (alpha), and the use of a stop-gradient operator on the performance of the model. The experiments were conducted using the Gemma-2-2b model, focusing on the 25th layer’s residual SAE. The goal was to find the optimal settings that balance model accuracy (alignment) and the diversity of generated outputs (entropy).
read the caption
Table 4: Ablation Study on SAE layer selection, hyperparameters α𝛼\alphaitalic_α and stop-gradient operator (Grad. sg. for short). We perform experiments on Gemma-2-2b, with the 25th layer’s residual SAE used to evaluate the effects of varying α𝛼\alphaitalic_α and applying a stop-gradient. We search for the best settings considering the trade-off between Alignment (accuracy) and Diversity (entropy).
Full paper#