↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current research in multimodal AI struggles with creating unified systems for image understanding and generation. Existing approaches often involve complex architectures or suboptimal performance due to the separate handling of these two tasks. This separation can limit the model’s overall capabilities and efficiency.
JanusFlow, proposed in this paper, tackles this problem with a minimalist architecture that integrates autoregressive language models with rectified flow. By decoupling the understanding and generation encoders and aligning their representations during training, JanusFlow achieves state-of-the-art performance in both visual understanding and image generation. This work demonstrates a more efficient and versatile approach, surpassing existing unified models across multiple standard benchmarks. The results highlight the potential of JanusFlow for more efficient and versatile vision-language models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents JanusFlow, a novel and efficient approach to unifying multimodal understanding and generation. This addresses a key challenge in AI, paving the way for more versatile and efficient vision-language models. The results are significant, showing state-of-the-art performance across standard benchmarks, and the method is impactful due to its minimalist design and applicability to various tasks. Researchers in vision-language modeling can use this work to advance unified model design and training strategies.
Visual Insights#

🔼 This figure presents a comparison of JanusFlow’s performance against other state-of-the-art models on various benchmark datasets. The benchmark results cover both multimodal understanding (e.g., VQA, GQA, MMBench) and image generation (e.g., MJHQ FID, GenEval). The visualization allows for a direct comparison of JanusFlow’s performance relative to specialized models and other unified multimodal models, highlighting its competitive advantage in both multimodal understanding and image generation tasks.
read the caption
(a) Benchmark Performances.
| Stage 1 | Stage 2 | Stage 3 | |
|---|---|---|---|
| Learning Rate | 1.0e-04 | 1e-04 | 2.0e-05 |
| LR Scheduler | Constant | Constant | Constant |
| Weight Decay | 0.0 | 0.0 | 0.0 |
| Gradient Clip | 1.0 | 1.0 | 1.0 |
| Optimizer | AdamW (β₁=0.9,β₂=0.95) | AdamW (β₁=0.9,β₂=0.95) | AdamW (β₁=0.9,β₂=0.95) |
| Warm-up Steps | 2,000 | 0 | 1,000 |
| Training Steps | 10,000 | 380,000 | 26,000 |
| Batch Size | 512 | 512 | 256 |
| Data Ratio | 50:50:0 | 14:80:6 | 21:70:9 |
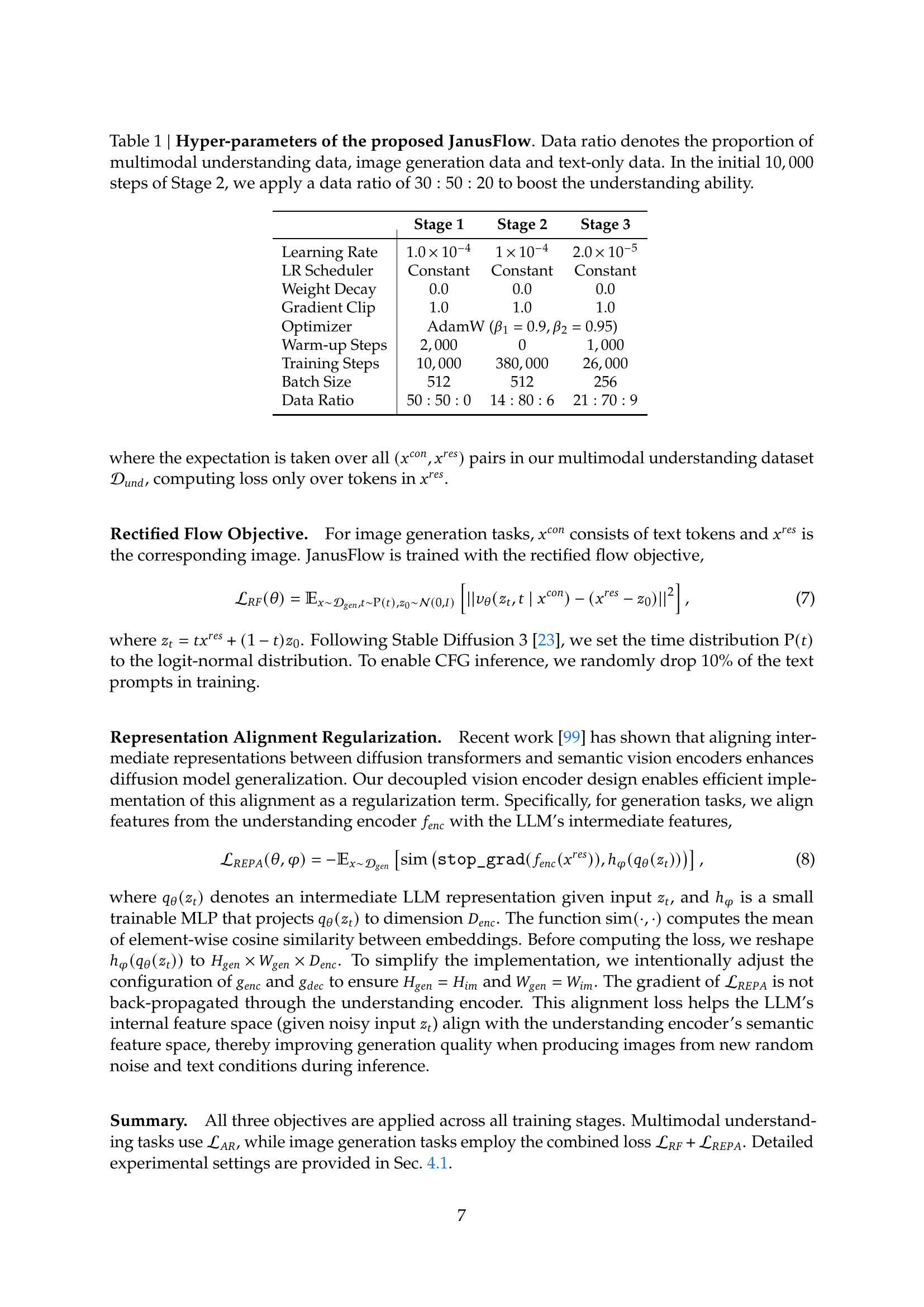
🔼 This table details the hyperparameters used during the three training stages of the JanusFlow model. It shows the learning rate, learning rate scheduler, weight decay, gradient clipping value, optimizer used, warm-up steps, total training steps, batch size, and the data ratio for each stage. The data ratio specifies the proportion of multimodal understanding data, image generation data, and text-only data used in each training stage. Note that the initial 10,000 steps of Stage 2 utilize a specific data ratio (30:50:20) to prioritize the model’s understanding capabilities before transitioning to a different ratio for the remainder of Stage 2.
read the caption
Table 1: Hyper-parameters of the proposed JanusFlow. Data ratio denotes the proportion of multimodal understanding data, image generation data and text-only data. In the initial 10,0001000010,00010 , 000 steps of Stage 2, we apply a data ratio of 30:50:20:3050:2030:50:2030 : 50 : 20 to boost the understanding ability.
In-depth insights#
Unified MM Model#
A unified multimodal model (unified MM model) aims to seamlessly integrate different modalities, such as text and images, within a single framework. This approach contrasts with traditional methods that treat each modality separately, potentially leading to suboptimal performance and hindering the capture of complex intermodal relationships. The key benefits of a unified MM model include enhanced efficiency due to reduced computational overhead and improved performance stemming from the synergistic interplay of modalities. However, designing and training such a model presents considerable challenges, primarily in handling the diverse nature of different data types and ensuring effective representation learning. Effective architectural designs are crucial for achieving the optimal balance between simplicity and expressiveness. Moreover, appropriate training strategies are essential for efficient and comprehensive learning across modalities, particularly given the scale and complexity of multimodal data.
Rectified Flow Int.#
The heading ‘Rectified Flow Int.’ suggests a discussion of rectified flow within the context of an integrated system. Rectified flow, a generative modeling technique, is known for its efficiency and effectiveness in generating high-quality images and other data types. The integration aspect (‘Int.’) implies that the paper explores its incorporation into a larger architecture, likely a multimodal model or a unified framework for understanding and generation. This integration might involve seamlessly combining rectified flow’s generative capabilities with the strengths of another model, such as a large language model (LLM), for complex tasks like text-to-image synthesis. The authors likely detail how the rectified flow component interacts with other modules, addressing potential challenges in combining different model paradigms. Key aspects explored might include training strategies, architectural modifications, and the impact on the overall performance, perhaps showing improvements in efficiency or generation quality compared to using rectified flow in isolation. The ‘Rectified Flow Int.’ section would provide essential technical details, emphasizing the innovation and improvements achieved through this integration.
Decoupled Encoders#
The concept of “Decoupled Encoders” in the context of multimodal models, particularly those handling both visual understanding and generation, presents a compelling approach to enhancing performance. By separating the encoder pathways for these distinct tasks, the model avoids potential interference and allows for specialized feature extraction. This decoupling is crucial because visual understanding and image generation require different processing strategies. Understanding necessitates a focus on accurate and robust feature representation for semantic comprehension, potentially involving rich contextual information. Conversely, generation prioritizes manipulating latent representations for creative image synthesis. Using separate encoders tailored to these respective requirements enables greater specialization, leading to improved performance on both tasks. This strategy mitigates the risk of task interference, a common limitation in unified models, where a single encoder must effectively handle the divergent demands of comprehension and generation. The results demonstrate the benefits of this approach, suggesting that decoupling encoders is key for building more efficient and effective multimodal models that exhibit superior performance in both visual understanding and generation tasks. Further research could investigate the optimal design for decoupled encoders in various model architectures and their impact on different multimodal tasks.
Training Strategies#
The paper’s training regime is a crucial aspect, showing a three-stage approach. First, a stage for adapting randomly initialized components, primarily the generation encoder and decoder, to work effectively with the pre-trained LLM. This is a vital step to ensure smoother integration and prevent disruptive model interference. Second, unified pre-training combines multimodal understanding, image generation, and text-only data. The data ratio is adjusted to balance these aspects, prioritizing multimodal understanding initially before shifting focus towards generation data as training progresses. Finally, supervised fine-tuning on a diverse instruction dataset further refines the model’s capabilities. Separate encoders for understanding and generation are used, preventing task interference. Importantly, a representation alignment regularization strategy is implemented to improve semantic consistency between these tasks, and the use of classifier-free guidance in image generation is strategically employed to boost generation quality. The overall training methodology is carefully designed to balance model effectiveness, data diversity and resource efficiency.
Future Research#
Future research directions stemming from the JanusFlow paper could explore several promising avenues. Scaling to larger models and datasets is crucial to further enhance performance and generalization capabilities. Investigating alternative architectures that leverage the strengths of autoregressive and flow-based models more efficiently would also yield significant advancements. The authors suggest decoupling vision encoders, and this approach could be extended to other multimodal tasks. A key area for improvement is enhanced representation alignment techniques to ensure better cross-modal understanding. Finally, developing more efficient training strategies is important for wider adoption and practical applications, especially with the considerable computational resources required for training large multimodal models. Therefore, the core direction is improving both efficiency and effectiveness by refining existing components and exploring novel model designs.
More visual insights#
More on figures

🔼 This figure showcases examples of images generated by the JanusFlow model. The images demonstrate the model’s ability to generate high-quality images with a resolution of 384 x 384 pixels, based on textual descriptions or prompts. The variety of images presented highlights JanusFlow’s diverse capabilities in generating different styles, objects, and scenes.
read the caption
(b) Visual Generation Results.

🔼 JanusFlow, a novel multimodal model, significantly outperforms existing unified models and several task-specific models in visual understanding benchmarks while producing high-quality images (384x384 resolution). The figure showcases both quantitative benchmark results and qualitative examples of generated images, demonstrating the model’s capabilities in both understanding and generation tasks.
read the caption
Figure 1: Multimodal understanding and image generation with JanusFlow. JanusFlow surpasses the state-of-the-art unified multimodal models and several task-specific understanding models on visual understanding benchmarks. It is also capable of generating high-quality images. The resolution of the images is 384×384384384384\times 384384 × 384.

🔼 JanusFlow uses a Large Language Model (LLM) for both visual understanding and image generation. In the visual understanding task (left panel), an understanding encoder processes the image and the text prompt, creating an input sequence for the LLM. The LLM then uses autoregressive prediction to generate a textual response. In the image generation task (right panel), a generation encoder processes a text prompt and Gaussian noise. The LLM iteratively updates the noise using rectified flow, predicting velocity vectors at each step until a complete image is generated in the latent space. A decoder then transforms this latent representation into a final image. The diagram simplifies the architecture by omitting details such as the VAE encoder and skip connections for clarity.
read the caption
Figure 2: Architecture of the proposed JanusFlow. For visual understanding, the LLM performs autoregressive next-token prediction to generate responses. For image generation, the LLM employs images with rectified flow. Starting from Gaussian noise at t=0𝑡0t=0italic_t = 0, the LLM iteratively updates ztsubscript𝑧𝑡z_{t}italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT by predicting velocity vectors until reaching t=1𝑡1t=1italic_t = 1. We omit the VAE encoder, the skip connection leveraged in generation and the linear layer after fencsubscript𝑓𝑒𝑛𝑐f_{enc}italic_f start_POSTSUBSCRIPT italic_e italic_n italic_c end_POSTSUBSCRIPT for simplicity.

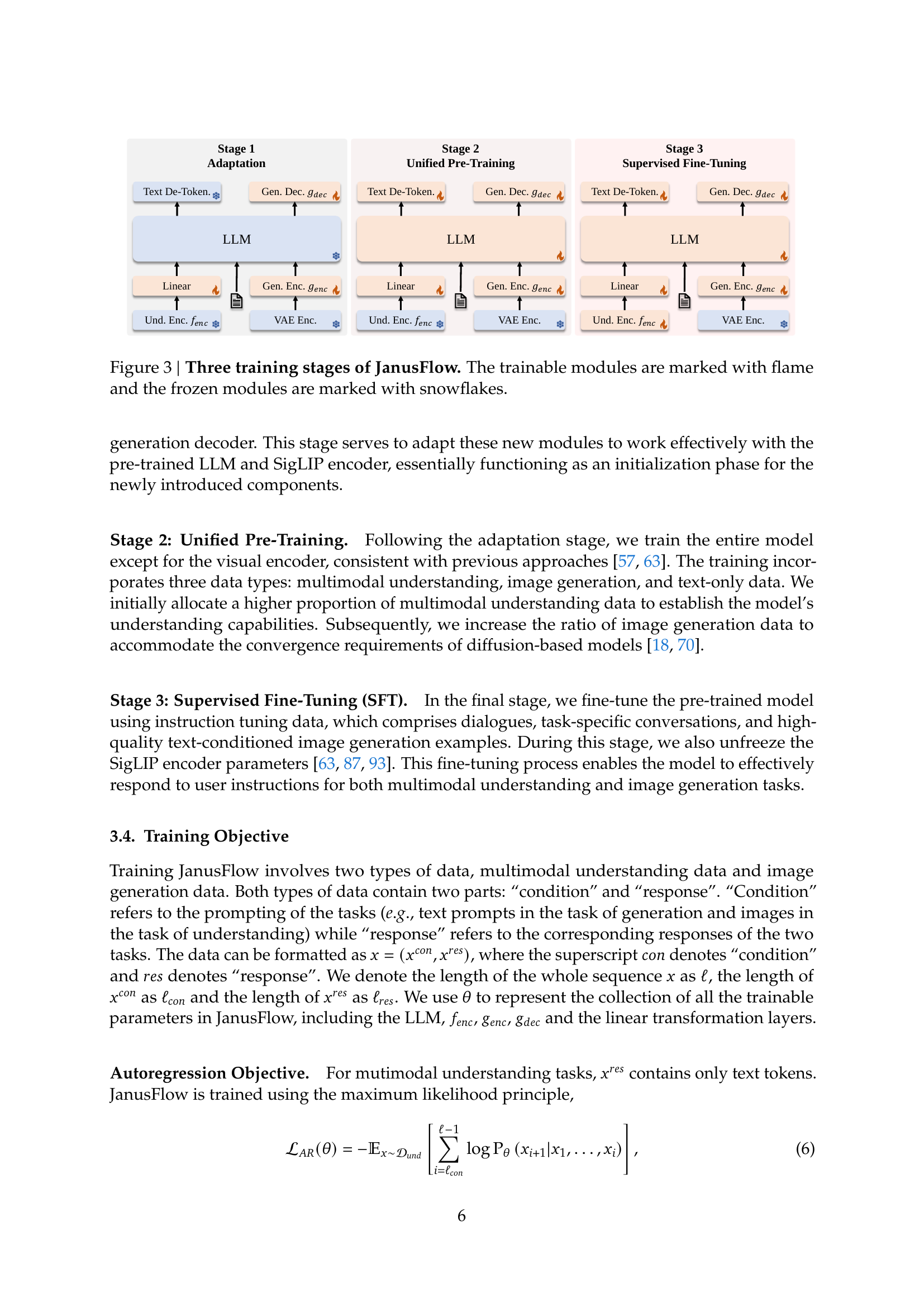
🔼 This figure illustrates the three-stage training process of the JanusFlow model. Stage 1 focuses on adapting newly initialized components (generation encoder and decoder) to work effectively with the pre-trained LLM and SigLIP encoder. Stage 2 involves unified pre-training of the entire model (except the visual encoder), using multimodal understanding, image generation, and text-only data. Finally, Stage 3 performs supervised fine-tuning using instruction tuning data to enhance the model’s ability to respond to user instructions for both multimodal understanding and image generation tasks. Trainable modules are highlighted with flames, while frozen modules are shown with snowflakes.
read the caption
Figure 3: Three training stages of JanusFlow. The trainable modules are marked with flame and the frozen modules are marked with snowflakes.

🔼 JanusFlow generates high-quality, semantically consistent images from text prompts. The figure displays several example images generated by the model, showcasing its ability to accurately interpret and visualize a range of descriptive text inputs. The images demonstrate both the visual quality and semantic accuracy of the model’s image generation capabilities.
read the caption
Figure 4: Image generation results of JanusFlow. Our model can generate high-quality images that are semantically consistent with text prompts.

🔼 Figure 5 presents qualitative examples showcasing JanusFlow’s capabilities in visual understanding tasks. The examples demonstrate successful question answering, plot interpretation, and object counting. The figure visually shows how the model interacts with images and provides textual responses, illustrating its ability to process various forms of visual content and reason about them in natural language.
read the caption
Figure 5: Visual Understanding with JanusFlow. Our model effectively handles various visual understanding tasks, such as question answering, plot interpretation and object counting.

🔼 This figure shows the impact of varying classifier-free guidance (CFG) factors on the Fréchet Inception Distance (FID) and CLIP similarity scores during image generation. The number of sampling steps was held constant at 30. The x-axis represents the CFG factor, and the y-axis shows the FID score (lower is better) and CLIP similarity (higher is better). The plot illustrates the optimal CFG factor for achieving a balance between visual quality and semantic alignment.
read the caption
(a) Results of varying CFG Factors

🔼 This figure shows the impact of varying the number of sampling steps on the model’s performance, specifically measuring the Fréchet Inception Distance (FID) and CLIP similarity scores. The CFG factor is held constant at a value of 2. The x-axis represents the number of sampling steps, while the y-axis displays both the FID and CLIP similarity scores. The plot illustrates how the choice of the number of sampling steps affects the trade-off between generation quality and computational efficiency.
read the caption
(b) Results of Varying Numbers of Sampling Steps

🔼 This figure shows the impact of varying classifier-free guidance (CFG) factors and the number of sampling steps on the quality of generated images, measured by FID and CLIP similarity scores. The left subplot (a) shows the FID and CLIP similarity scores obtained by varying the CFG factor while keeping the number of sampling steps constant at 30. The right subplot (b) shows the FID and CLIP similarity scores obtained by varying the number of sampling steps while keeping the CFG factor constant at 2. The plots illustrate how different values for these hyperparameters affect the trade-off between image quality and computational cost.
read the caption
Figure 1: Results of varying CFG factors and numbers of sampling steps. In Fig. (a), the number of sampling steps is set to 30. In Fig. (b), the CFG factor is set to 2.

🔼 This figure showcases additional examples of JanusFlow’s multimodal understanding capabilities. It demonstrates the model’s ability to perform various tasks, such as generating Python code for a bar chart based on a visual input, interpreting the humor in an image of a dog depicted as the Mona Lisa, identifying a person in an image (George W. Bush), and summarizing a text passage. These examples highlight the model’s versatility and its capacity to effectively process both visual and textual information, enabling it to perform a range of complex understanding tasks.
read the caption
Figure 2: More multimodal understanding cases.
More on tables
| Type | Method | Params | Single Obj. | Two Obj. | Count. | Colors | Pos. | Color Attri. | Overall ↑ |
|---|---|---|---|---|---|---|---|---|---|
| Gen. Only | LlamaGen [83] | 0.8B | 0.71 | 0.34 | 0.21 | 0.58 | 0.07 | 0.04 | 0.32 |
| LDM [75] | 1.4B | 0.92 | 0.29 | 0.23 | 0.70 | 0.02 | 0.05 | 0.37 | |
| SDv1.5 [75] | 0.9B | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 | 0.43 | |
| PixArt-α [9] | 0.6B | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | 0.48 | |
| SDv2.1 [75] | 0.9B | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 | 0.50 | |
| DALL-E 2 [74] | 6.5B | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 | 0.52 | |
| Emu3-Gen [91] | 8B | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 | |
| SDXL [71] | 2.6B | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | 0.55 | |
| IF-XL [17] | 4.3B | 0.97 | 0.74 | 0.66 | 0.81 | 0.13 | 0.35 | 0.61 | |
| DALL-E 3 [6] | - | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 | 0.67 | |
| Unified | Chameleon [85] | 34B | - | - | - | - | - | - | 0.39 |
| LWM [58] | 7B | 0.93 | 0.41 | 0.46 | 0.79 | 0.09 | 0.15 | 0.47 | |
| SEED-X † [27] | 17B | 0.97 | 0.58 | 0.26 | 0.80 | 0.19 | 0.14 | 0.49 | |
| Show-o [96] | 1.3B | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 | |
| Janus [93] | 1.3B | 0.97 | 0.68 | 0.30 | 0.84 | 0.46 | 0.42 | 0.61 | |
| JanusFlow (Ours) | 1.3B | 0.97 | 0.59 | 0.45 | 0.83 | 0.53 | 0.42 | 0.63 |
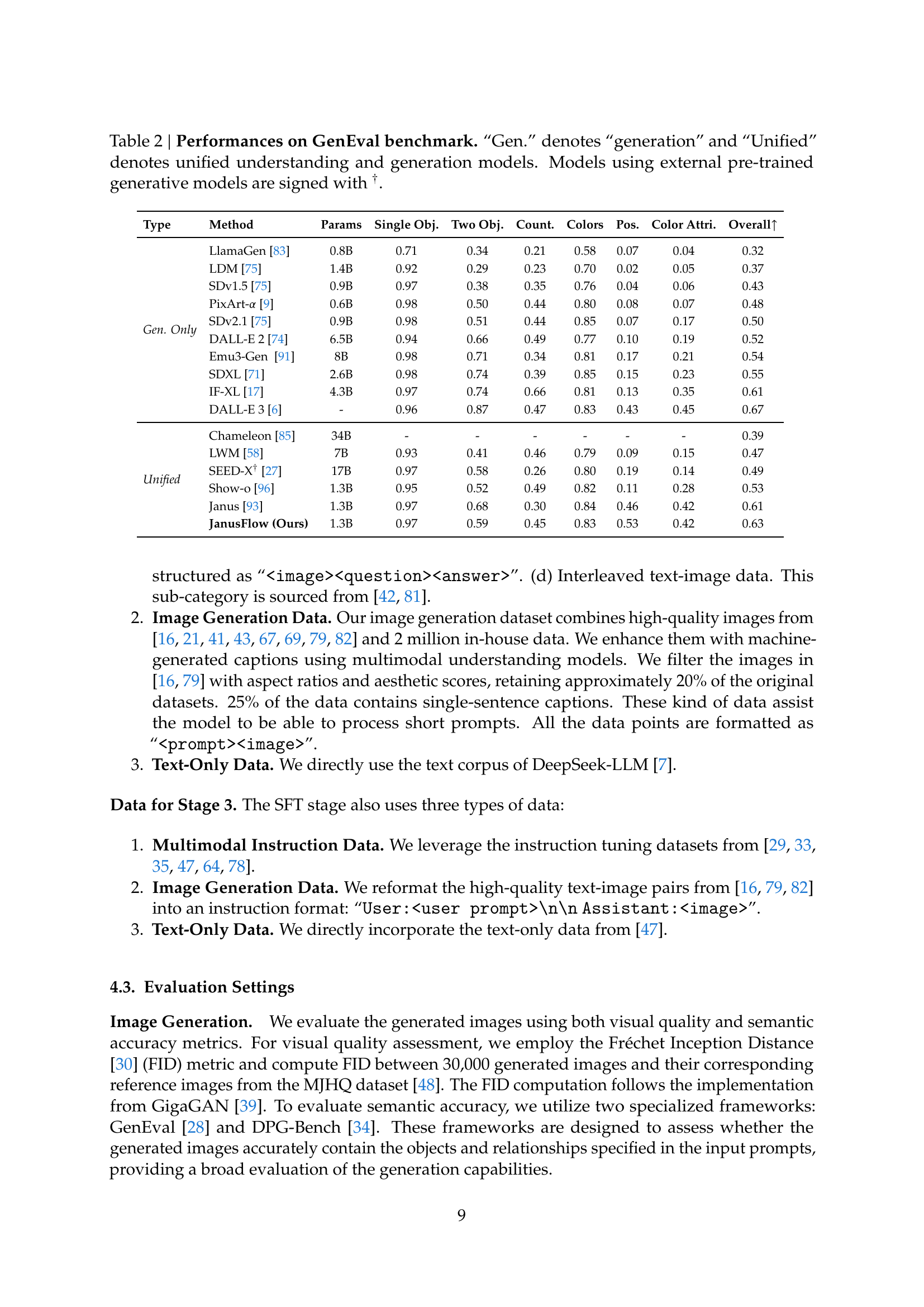
🔼 Table 2 presents the results of the GenEval benchmark, a test designed to evaluate the image generation capabilities of different models. It compares the performance of various models, categorized as either ‘generation-only’ or ‘unified’ (combining understanding and generation). The benchmark assesses generation quality across several sub-tasks: single object, two objects, counting, colors, position, color attributes, and an overall score. Models using external, pre-trained generative models are marked with a † symbol. The table allows for a direct comparison of specialized image generation models against unified multimodal models, highlighting the tradeoffs between specialized and general-purpose approaches.
read the caption
Table 2: Performances on GenEval benchmark. “Gen.” denotes “generation” and “Unified” denotes unified understanding and generation models. Models using external pre-trained generative models are signed with †.
| Method | Global | Entity | Attribute | Relation | Other | Overall ↑ |
|---|---|---|---|---|---|---|
| SDv1.5 [75] | 74.63 | 74.23 | 75.39 | 73.49 | 67.81 | 63.18 |
| PixArt-α [9] | 74.97 | 79.32 | 78.60 | 82.57 | 76.96 | 71.11 |
| Lumina-Next [105] | 82.82 | 88.65 | 86.44 | 80.53 | 81.82 | 74.63 |
| SDXL [71] | 83.27 | 82.43 | 80.91 | 86.76 | 80.41 | 74.65 |
| Playground v2.5 [48] | 83.06 | 82.59 | 81.20 | 84.08 | 83.50 | 75.47 |
| Hunyuan-DiT [54] | 84.59 | 80.59 | 88.01 | 74.36 | 86.41 | 78.87 |
| PixArt-Σ [10] | 86.89 | 82.89 | 88.94 | 86.59 | 87.68 | 80.54 |
| Emu3-Gen [91] | 85.21 | 86.68 | 86.84 | 90.22 | 83.15 | 80.60 |
| JanusFlow (Ours) | 87.03 | 87.31 | 87.39 | 89.79 | 88.10 | 80.09 |
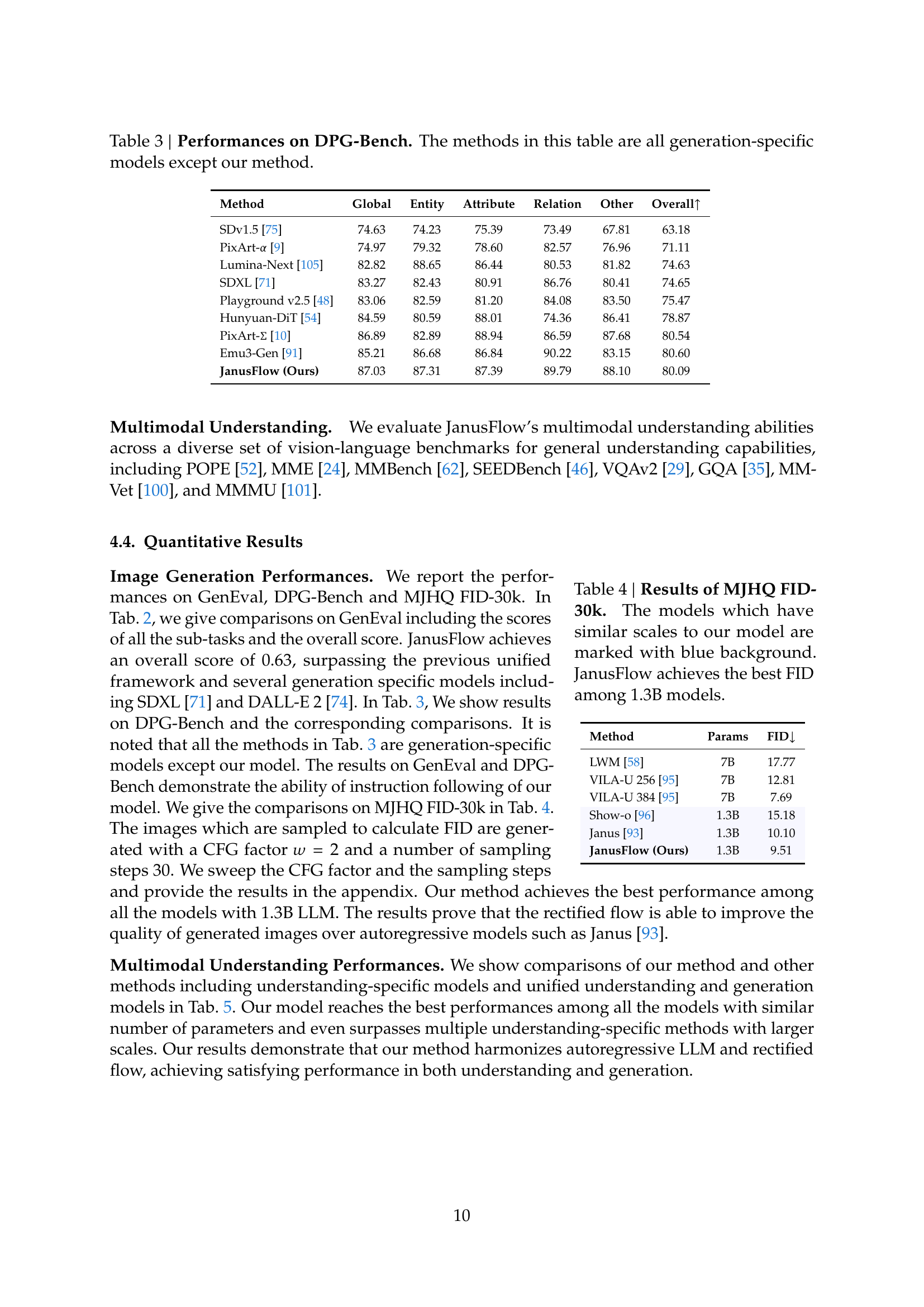
🔼 This table presents a comparison of performance scores on the DPG-Bench benchmark across various generation-specific models and the JanusFlow model. DPG-Bench is a metric that evaluates the quality of image generation, specifically focusing on aspects such as overall image quality, entity and attribute accuracy, relation accuracy, and handling of other scene elements. The table shows that JanusFlow, a unified multimodal model (capable of both image understanding and generation), outperforms most generation-specific models on this benchmark. This highlights JanusFlow’s ability to achieve competitive or superior results on generation tasks compared to models solely focused on that aspect.
read the caption
Table 3: Performances on DPG-Bench. The methods in this table are all generation-specific models except our method.
| Method | Params | FID↓ |
|---|---|---|
| LWM [58] | 7B | 17.77 |
| VILA-U 256 [95] | 7B | 12.81 |
| VILA-U 384 [95] | 7B | 7.69 |
| Show-o [96] | 1.3B | 15.18 |
| Janus [93] | 1.3B | 10.10 |
| JanusFlow (Ours) | 1.3B | 9.51 |
🔼 Table 4 presents the Fréchet Inception Distance (FID) scores on the MJHQ FID-30k benchmark. The FID score is a metric used to evaluate the quality of generated images, lower scores indicating better image quality. The table compares JanusFlow’s performance against other models with similar parameter counts (around 1.3 billion parameters), highlighting that JanusFlow achieves the lowest FID score among its peers, signifying superior image generation quality.
read the caption
Table 4: Results of MJHQ FID-30k. The models which have similar scales to our model are marked with blue background. JanusFlow achieves the best FID among 1.3B models.
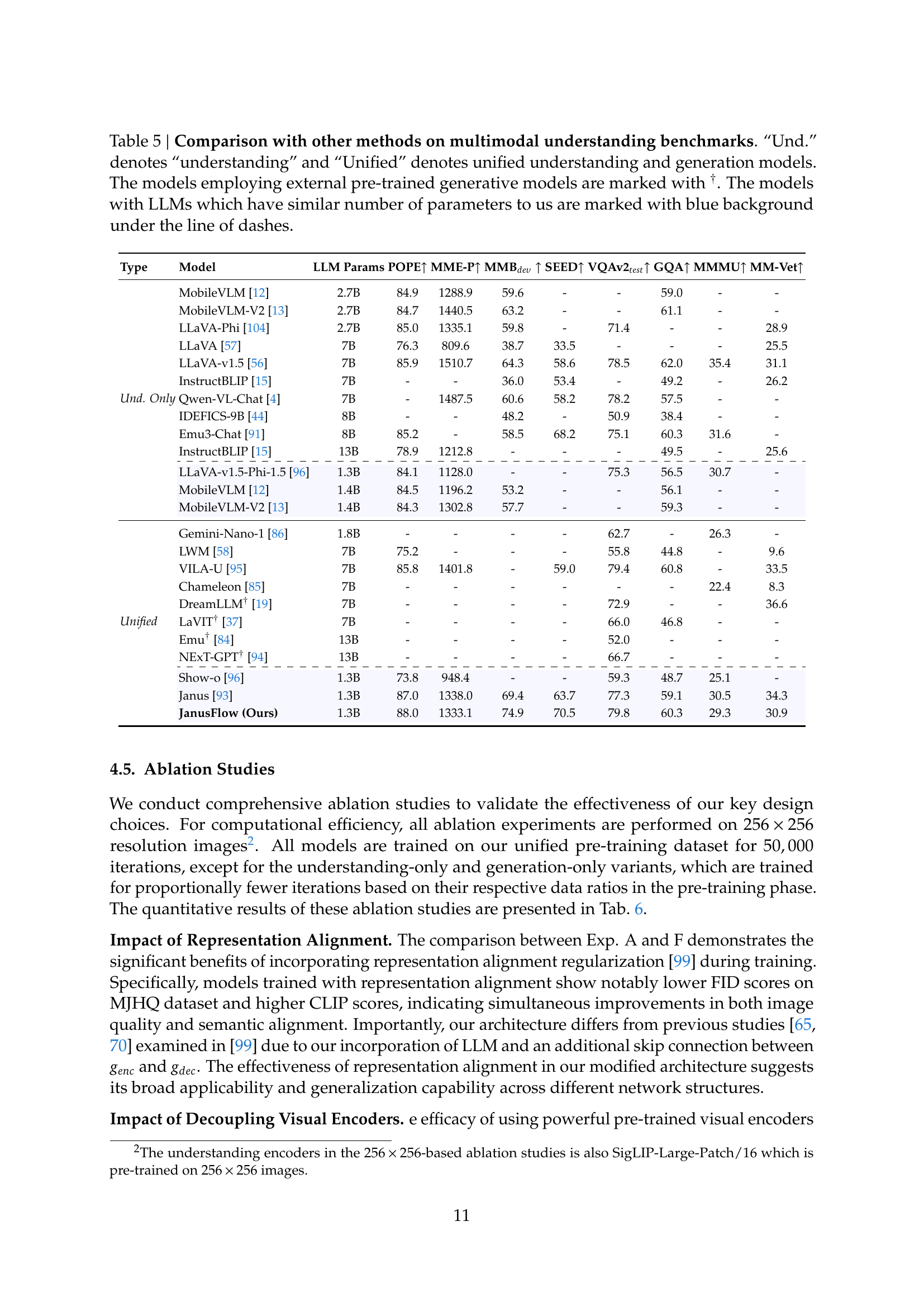
| Type | Model | LLM Params | POPE↑ | MME-P↑ | MMBdev↑ | SEED↑ | VQAv2test↑ | GQA↑ | MMMU↑ | MM-Vet↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Und. Only | MobileVLM [12] | 2.7B | 84.9 | 1288.9 | 59.6 | - | - | 59.0 | - | - |
| Und. Only | MobileVLM-V2 [13] | 2.7B | 84.7 | 1440.5 | 63.2 | - | - | 61.1 | - | - |
| Und. Only | LLaVA-Phi [104] | 2.7B | 85.0 | 1335.1 | 59.8 | - | 71.4 | - | 28.9 | - |
| Und. Only | LLaVA [57] | 7B | 76.3 | 809.6 | 38.7 | 33.5 | - | - | 25.5 | - |
| Und. Only | LLaVA-v1.5 [56] | 7B | 85.9 | 1510.7 | 64.3 | 58.6 | 78.5 | 62.0 | 35.4 | 31.1 |
| Und. Only | InstructBLIP [15] | 7B | - | - | 36.0 | 53.4 | - | 49.2 | - | 26.2 |
| Und. Only | Qwen-VL-Chat [4] | 7B | - | 1487.5 | 60.6 | 58.2 | 78.2 | 57.5 | - | - |
| Und. Only | IDEFICS-9B [44] | 8B | - | - | 48.2 | - | 50.9 | 38.4 | - | - |
| Und. Only | Emu3-Chat [91] | 8B | 85.2 | - | 58.5 | 68.2 | 75.1 | 60.3 | 31.6 | - |
| Und. Only | InstructBLIP [15] | 13B | 78.9 | 1212.8 | - | - | - | 49.5 | - | 25.6 |
| — | — | — | — | — | — | — | — | — | — | — |
| LLaVA-v1.5-Phi-1.5 [96] | 1.3B | 84.1 | 1128.0 | - | - | 75.3 | 56.5 | 30.7 | - | |
| MobileVLM [12] | 1.4B | 84.5 | 1196.2 | 53.2 | - | - | 56.1 | - | - | |
| MobileVLM-V2 [13] | 1.4B | 84.3 | 1302.8 | 57.7 | - | - | 59.3 | - | - | |
| Unified | Gemini-Nano-1 [86] | 1.8B | - | - | - | - | - | 62.7 | - | - |
| Unified | LWM [58] | 7B | 75.2 | - | - | - | 55.8 | 44.8 | - | 9.6 |
| Unified | VILA-U [95] | 7B | 85.8 | 1401.8 | - | 59.0 | 79.4 | 60.8 | - | 33.5 |
| Unified | Chameleon [85] | 7B | - | - | - | - | - | - | - | 22.4 |
| Unified | DreamLLM† [19] | 7B | - | - | - | - | 72.9 | - | - | 36.6 |
| Unified | LaVIT† [37] | 7B | - | - | - | - | 66.0 | 46.8 | - | - |
| Unified | Emu† [84] | 13B | - | - | - | - | 52.0 | - | - | - |
| Unified | NExT-GPT† [94] | 13B | - | - | - | - | 66.7 | - | - | - |
| Janus [93] | 1.3B | 87.0 | 1338.0 | 69.4 | 63.7 | 77.3 | 59.1 | 30.5 | 34.3 | |
| JanusFlow (Ours) | 1.3B | 88.0 | 1333.1 | 74.9 | 70.5 | 79.8 | 60.3 | 29.3 | 30.9 |
🔼 Table 5 presents a comparison of various multimodal understanding models’ performance across several benchmark datasets. It contrasts the performance of understanding-only models, unified (understanding and generation) models, and models that leverage externally pre-trained generative models. The table highlights the number of parameters in each model’s large language model (LLM), making it easier to compare models with similar computational complexity. Models using LLMs with a similar parameter count to the authors’ JanusFlow model are visually distinguished with a blue background.
read the caption
Table 5: Comparison with other methods on multimodal understanding benchmarks. “Und.” denotes “understanding” and “Unified” denotes unified understanding and generation models. The models employing external pre-trained generative models are marked with †. The models with LLMs which have similar number of parameters to us are marked with blue background under the line of dashes.
| Exp. ID | REPA | Und. Modules | Gen. Modules | Type | Train. Iter. | POPE↑ | VQAv2val↑ | GQA↑ | FID↓ | CLIP ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| A | × | SigLIP | VAE†+ConvNeXt | Unified | 50,000 | 82.40 | 69.62 | 54.43 | 19.84 | 24.94 |
| B | ✓ | Shared VAE†+ConvNeXt | Unified | 50,000 | 78.13 | 53.94 | 44.04 | 18.05 | 26.38 | |
| C | ✓ | VAE+ConvNeXt | VAE†+ConvNeXt | Unified | 50,000 | 75.30 | 55.41 | 44.44 | 17.53 | 26.32 |
| D | ✓ | SigLIP | - | Und. Only | 13,000 | 85.03 | 69.10 | 54.23 | - | - |
| E | ✓ | - | VAE†+ConvNeXt | Gen. Only | 37,000 | - | - | - | 16.69 | 26.89 |
| F | ✓ | SigLIP | VAE†+ConvNeXt | Unified | 50,000 | 84.73 | 69.20 | 54.83 | 17.61 | 26.40 |
🔼 This ablation study analyzes the impact of different model components and training strategies on JanusFlow’s performance. It compares various configurations, including whether certain modules are frozen during training, and uses different visual encoders. The results, measured by MJHQ FID-10k (a visual quality metric) and CLIP similarity (a semantic similarity metric), demonstrate the effectiveness of key design choices like representation alignment and decoupled encoders. The CFG (classifier-free guidance) factor is fixed at 7.5, and 30 sampling steps are used for all FID calculations. Experiment F represents the final, optimal configuration used for JanusFlow.
read the caption
Table 6: Ablation studies. The weights of the modules with † are frozen during training. “Exp.” denotes “experiment”. “FID” in this table is MJHQ FID-10k with CFG factor w=7.5𝑤7.5w=7.5italic_w = 7.5 and 30 steps. “CLIP” denotes CLIP similarity with the backbone of CLIP-ViT-Large-Patch/14. Exp. F is the final configuration for training JanusFlow.
| Model | LLM Params | POPE↑ | MME-P↑ | MMBdev↑ | SEED↑ | VQAv2test↑ | GQA↑ | MM-Vet↑ |
|---|---|---|---|---|---|---|---|---|
| JanusFlow 256 | 1.3B | 85.3 | 1203.0 | 71.9 | 67.6 | 76.3 | 58.4 | 27.4 |
| JanusFlow 384 | 1.3B | 88.0 | 1333.1 | 74.9 | 70.5 | 79.8 | 60.3 | 30.9 |
🔼 This table presents a quantitative evaluation of the JanusFlow model’s performance on various visual understanding tasks. It shows the model’s scores across multiple benchmarks, comparing its capabilities to those of other state-of-the-art models in the field. Each column represents a different benchmark, measuring aspects such as image captioning, question answering, visual reasoning, etc., reflecting the model’s ability to comprehend and interact with visual information in diverse scenarios.
read the caption
Table 1: Results on visual understanding tasks.
| Method | LLM Params | Single Obj. | Two Obj. | Count. | Colors | Pos. | Color Attri. | Overall↑ |
|---|---|---|---|---|---|---|---|---|
| JanusFlow 256 | 1.3B | 0.98 | 0.73 | 0.54 | 0.83 | 0.63 | 0.53 | 0.70 |
| JanusFlow 384 | 1.3B | 0.97 | 0.59 | 0.45 | 0.83 | 0.53 | 0.42 | 0.63 |
🔼 This table presents a comparison of JanusFlow’s performance on the GenEval benchmark [28] against other state-of-the-art models for image generation. GenEval assesses image generation quality across various aspects including object presence, attribute accuracy, color fidelity, counting accuracy and scene composition. The table shows the performance of different models across these subtasks and provides an overall score. It allows for a comprehensive comparison of JanusFlow’s capabilities with respect to both generation-only models and unified models.
read the caption
Table 2: Results on GenEval [28].
| Method | Global ↑ | Entity ↑ | Attribute ↑ | Relation ↑ | Other ↑ | Overall ↑ | MJHQ FID-30k ↓ |
|---|---|---|---|---|---|---|---|
| JanusFlow 256 | 91.20 | 88.83 | 88.00 | 87.60 | 89.53 | 81.23 | 12.70 |
| JanusFlow 384 | 87.03 | 87.31 | 87.39 | 89.79 | 88.10 | 80.09 | 9.51 |
🔼 This table presents a quantitative comparison of JanusFlow’s performance against other state-of-the-art image generation models on two key benchmarks: DPG-Bench and MJHQ FID-30k. DPG-Bench assesses the model’s ability to generate images that accurately reflect the attributes, relationships, and overall composition described in a textual prompt, while MJHQ FID-30k measures the visual fidelity of generated images by comparing them against a database of high-quality images. The table highlights JanusFlow’s performance metrics on each benchmark, providing granular scores for attributes like global consistency, entity accuracy, attribute precision, and relationship accuracy, and a final overall score. This allows for a detailed assessment of JanusFlow’s strengths and weaknesses in image generation compared to existing methods.
read the caption
Table 3: Results on DPG-Bench [34] and MJHQ FID-30k [48].
Full paper#