↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current 3D content generation methods face challenges with input formats, latent space design, and output representations. Many use point clouds as input, limiting detail and dataset size, while others struggle with high-resolution rendering. Existing methods also lack 3D-aware latent spaces for intuitive editing. This limits the potential for interactive content creation and advanced applications.
This paper introduces GaussianAnything, which uses a novel framework that addresses these shortcomings. It utilizes multi-view RGB-D-N renderings as input, creating a point cloud-structured latent space that preserves 3D shape information and enables shape-texture disentanglement. This allows for multi-modal 3D generation with point clouds, captions, and images. A cascaded latent diffusion model improves shape-texture disentanglement and supports high-quality editable surfel Gaussians output. Experiments demonstrate its effectiveness, outperforming previous methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and effective framework for 3D content generation that addresses several limitations of existing methods. The interactive point cloud-structured latent space enables intuitive 3D editing, a significant advancement in the field. This work is highly relevant to current research trends in generative AI, especially in the area of 3D modeling, and opens up new avenues for research in multi-modal 3D generation, shape-texture disentanglement, and high-quality 3D model editing.
Visual Insights#

🔼 This figure illustrates the process of 3D object generation using the GAUSSIANANYTHING method. Starting from single-view images or text descriptions as input, the method employs a cascaded 3D diffusion pipeline to produce high-quality and editable surfel Gaussians. The pipeline involves several stages, shown in the image as a flow chart, that progressively refine the 3D representation, ultimately resulting in detailed and easily manipulated 3D models.
read the caption
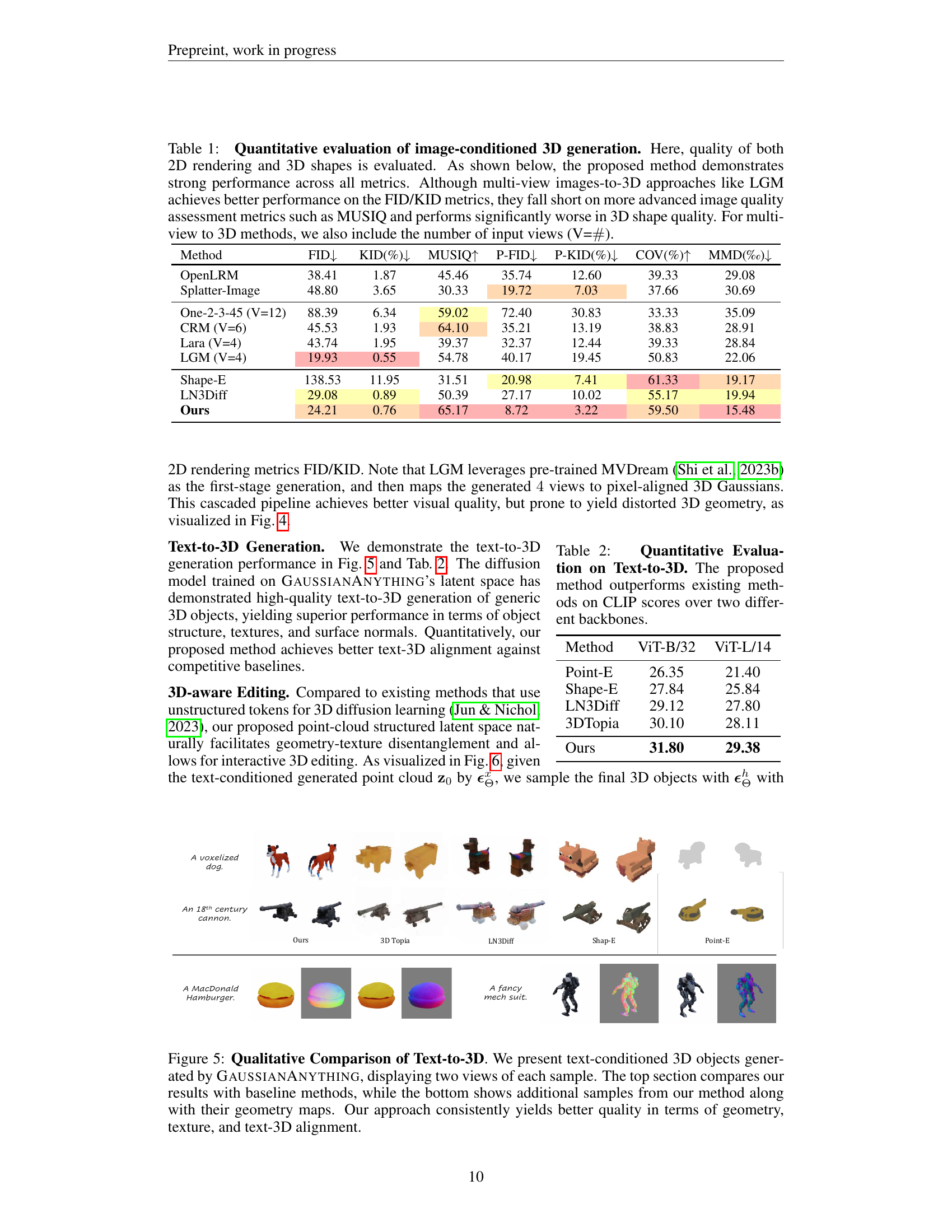
Figure 1: Our method generates high-quality and editable surfel Gaussians through a cascaded 3D diffusion pipeline, given single-view images or texts as the conditions.
| Method | FID↓ | KID(%)↓ | MUSIQ↑ | P-FID↓ | P-KID(%)↓ | COV(%)↑ | MMD(‰)↓ |
|---|---|---|---|---|---|---|---|
| OpenLRM | 38.41 | 1.87 | 45.46 | 35.74 | 12.60 | 39.33 | 29.08 |
| Splatter-Image | 48.80 | 3.65 | 30.33 | 19.72 | 7.03 | 37.66 | 30.69 |
| One-2-3-45 (V=12) | 88.39 | 6.34 | 59.02 | 72.40 | 30.83 | 33.33 | 35.09 |
| CRM (V=6) | 45.53 | 1.93 | 64.10 | 35.21 | 13.19 | 38.83 | 28.91 |
| Lara (V=4) | 43.74 | 1.95 | 39.37 | 32.37 | 12.44 | 39.33 | 28.84 |
| LGM (V=4) | 19.93 | 0.55 | 54.78 | 40.17 | 19.45 | 50.83 | 22.06 |
| Shape-E | 138.53 | 11.95 | 31.51 | 20.98 | 7.41 | 61.33 | 19.17 |
| LN3Diff | 29.08 | 0.89 | 50.39 | 27.17 | 10.02 | 55.17 | 19.94 |
| Ours | 24.21 | 0.76 | 65.17 | 8.72 | 3.22 | 59.50 | 15.48 |
🔼 This table presents a quantitative comparison of image-conditioned 3D generation methods, evaluating both the quality of the 2D renderings and the 3D shapes. The metrics used include FID, KID, MUSIQ, P-FID, P-KID, Coverage Score, and Minimum Matching Distance. The results show that the proposed method outperforms existing techniques across all metrics. While some multi-view methods (like LGM) achieve better FID and KID scores, they perform poorly on higher-level image quality (MUSIQ) and 3D shape quality metrics. The table also indicates the number of input views used for multi-view methods.
read the caption
Table 1: Quantitative evaluation of image-conditioned 3D generation. Here, quality of both 2D rendering and 3D shapes is evaluated. As shown below, the proposed method demonstrates strong performance across all metrics. Although multi-view images-to-3D approaches like LGM achieves better performance on the FID/KID metrics, they fall short on more advanced image quality assessment metrics such as MUSIQ and performs significantly worse in 3D shape quality. For multi-view to 3D methods, we also include the number of input views (V=##\##).
In-depth insights#
3D Diffusion Advance#
Advances in 3D diffusion models represent a significant leap in the field of 3D content generation. Early methods often relied on 2D-lifting techniques, which suffered from limitations in scalability and view consistency. Native 3D diffusion models offer a more direct and efficient approach, learning directly from 3D data representations. However, challenges remain, particularly concerning the choice of input formats (point clouds versus multi-view images), the design of effective latent spaces that capture both geometry and texture, and the selection of suitable output representations (e.g., surfel Gaussians). Recent research focuses on addressing these challenges by incorporating more comprehensive 3D information (e.g., depth, normals) into the input, developing specialized latent spaces (like point cloud-structured spaces) that facilitate 3D-aware editing and high-quality output representations capable of handling high-resolution details, such as surfel Gaussians, for efficient rendering. The integration of techniques such as flow matching further enhances the fidelity and controllability of 3D generation. Future work is likely to focus on more robust latent space designs, efficient training procedures, and the development of more versatile input modalities.
Latent Space Design#
Effective latent space design is crucial for high-quality 3D generation. The choice of representation significantly impacts the model’s ability to capture and manipulate 3D shape and texture information. Point cloud-based latent spaces offer advantages in preserving 3D structure and enabling intuitive 3D editing, but careful consideration is needed to address the challenges posed by unordered point sets and the need for efficient encoding. Alternatively, volume-based representations offer dense 3D information but can be computationally expensive. Hybrid approaches, combining aspects of both point cloud and volume representations, may provide a balance between efficiency and expressiveness. Furthermore, disentangling shape and appearance in the latent space is critical to allow for independent control over these attributes, facilitating more creative and nuanced 3D content generation. The success of a latent space also depends heavily on the encoder’s capability to faithfully capture the input 3D data and the decoder’s ability to reconstruct high-fidelity 3D outputs from the latent representation. Therefore, a well-designed latent space is not merely a data structure, but a sophisticated engineering component that fundamentally determines the generative model’s capabilities.
Multimodal 3D Gen#
Multimodal 3D generation represents a significant advancement in artificial intelligence, aiming to create 3D models from diverse input modalities such as text, images, and point clouds. This approach offers enhanced flexibility and realism compared to unimodal methods, allowing for more nuanced and creative control over the 3D content generation process. The challenges lie in effectively integrating information from disparate sources, and in designing models capable of handling the inherent complexity and variability of 3D data. Successful multimodal models will need to address the semantic alignment between different input types, ensuring consistent and coherent 3D output. Furthermore, scalability and efficiency remain critical considerations, as 3D data is often computationally expensive to process. Ultimately, successful multimodal 3D generation promises to revolutionize fields such as computer-aided design, virtual reality, and video game development, enabling the creation of highly realistic and detailed 3D environments with reduced manual effort.
Interactive Editing#
Interactive editing in 3D content generation is a significant advancement, offering users the ability to directly manipulate generated models. The ease of editing is highly desirable, especially in applications like game development or virtual reality design, where iterative adjustments are commonplace. The paper’s approach leverages a point-cloud structured latent space, enabling intuitive manipulation of geometry and texture independently. This disentanglement of features empowers users to refine aspects of the model without affecting others, leading to increased efficiency and creative freedom. The interactive nature, combined with high-quality output, distinguishes this method from previous approaches, making it a more powerful and user-friendly tool. However, further investigation into the limitations and potential biases inherent in such systems is important, as interactive editing introduces a new level of control that could potentially be misused. The robustness and scalability of this approach, along with its ability to handle multi-modal input (text and images), warrant further exploration and development to unlock its full potential across many creative domains.
Future Work & Limits#
The authors acknowledge limitations, specifically mentioning texture blurriness in complex 3D objects and suggesting the incorporation of pixel-aligned features and rendering loss during training to address this. Improving the resolution and detail of generated textures is a significant area of future work, as is exploring alternative 3D representations for better handling of fine details. The use of additional real-world datasets is also proposed to further enhance model robustness and generalization. Moreover, expanding the model’s capabilities to incorporate more diverse conditional inputs and potentially introduce more control over the generative process are key aspects. Addressing the potential for misuse of this technology in creating deepfakes is also highlighted as an important consideration, emphasizing the need for ethical implications and responsible development.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the 3D Variational Autoencoder (VAE) within the GaussianAnything model. The VAE takes in multiple views (V) of posed RGB-D-N (Red-Green-Blue, Depth, Normal) renderings of a 3D object as input. These views are initially encoded into an unstructured set latent representation. A cross-attention block then projects this set latent onto a 3D manifold, creating a point-cloud structured latent code (z). A 3D-aware Diffusion Transformer (DiT) decodes this point-cloud latent code, producing an initial, coarse Gaussian prediction for the 3D object. To improve rendering quality, this coarse Gaussian prediction undergoes a series of cascaded upsampling operations (DUk), generating a dense Gaussian representation suitable for high-resolution rendering. The training objective for this VAE is detailed in Equation 9 of the paper.
read the caption
Figure 2: Pipeline of the 3D VAE of GaussianAnything. In the 3D latent space learning stage, our proposed 3D VAE ℰϕsubscriptℰbold-italic-ϕ\mathcal{E}_{\bm{\phi}}caligraphic_E start_POSTSUBSCRIPT bold_italic_ϕ end_POSTSUBSCRIPT encodes V−limit-from𝑉V-italic_V -views of posed RGB-D(epth)-N(ormal) renderings ℛℛ\mathcal{R}caligraphic_R into a point-cloud structured latent space. This is achieved by first processing the multi-view inputs into the un-structured set latent, which is further projected onto the 3D manifold through a cross attention block, yielding the point-cloud structured latent code 𝐳𝐳{\mathbf{z}}bold_z. The structured 3D latent is further decoded by a 3D-aware DiT transformer, giving the coarse Gaussian prediction. For high-quality rendering, the base Gaussian is further up-sampled by a series of cascaded upsampler 𝒟Uksuperscriptsubscript𝒟𝑈𝑘\mathcal{D}_{U}^{k}caligraphic_D start_POSTSUBSCRIPT italic_U end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT towards a dense Gaussian for high-resolution rasterization. The 3D VAE training objective is detailed in Eq. (9).

🔼 This figure illustrates the cascaded diffusion process within the GaussianAnything model for 3D generation. The process begins with a point cloud structured 3D Variational Autoencoder (VAE). Conditional inputs, either text or images, are fed into the DiT architecture (using AdaLN-single and QK-Norm for normalization), interacting via cross-attention blocks at different stages. 3D generation proceeds in two stages: (1) a point cloud diffusion model generates the 3D object’s layout (𝐳x,0), and (2) a texture diffusion model generates the corresponding point cloud features (𝐳h,0), given the initial layout. The combined latent code (𝐳0) is then decoded by the pre-trained VAE to produce the final 3D object.
read the caption
Figure 3: Diffusion training of GaussianAnything. Based on the point-cloud structure 3D VAE, we perform cascaded 3D diffusion learning given text (a) and image (b) conditions. We adopt DiT architecture with AdaLN-single (Chen et al., 2023) and QK-Norm (Dehghani et al., 2023; Esser et al., 2021). For both condition modality, we send in the conditional feature with cross attention block, but at different positions. The 3D generation is achieved in two stages (c), where a point cloud diffusion model first generates the 3D layout 𝐳x,0subscript𝐳𝑥0{\mathbf{z}}_{x,0}bold_z start_POSTSUBSCRIPT italic_x , 0 end_POSTSUBSCRIPT, and a texture diffusion model further generates the corresponding point-cloud features 𝐳h,0subscript𝐳ℎ0{\mathbf{z}}_{h,0}bold_z start_POSTSUBSCRIPT italic_h , 0 end_POSTSUBSCRIPT. The generated latent code 𝐳0subscript𝐳0{\mathbf{z}}_{0}bold_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT is decoded into the final 3D object with the pre-trained VAE decoder.

🔼 Figure 4 presents a qualitative comparison of different image-to-3D reconstruction methods on the unseen GSO dataset. Each method is given a single input image, and the results are shown as novel-view 3D reconstructions. The figure highlights the consistent, stable performance of the proposed method across various input images, in contrast to feed-forward methods that, while producing sharper textures, sometimes fail to generate complete and accurate 3D models, especially in challenging scenarios (such as the rhino in the second row). The figure visually demonstrates the superior performance of the proposed native 3D diffusion model in terms of overall 3D reconstruction accuracy.
read the caption
Figure 4: Qualitative Comparison of Image-to-3D. We showcase the novel view 3D reconstruction of all methods given a single image from unseen GSO dataset. Our proposed method achieves consistently stable performance across all cases. Note that though feed-forward 3D reconstruction methods achieve sharper texture reconstruction, these method fail to yield intact 3D predictions under challenging cases (e.g., the rhino in row 2). In contrast, our proposed native 3D diffusion model achieve consistently better performance. Better zoom in.

🔼 Figure 5 showcases a qualitative comparison of text-to-3D generation results achieved by GaussianAnything and several baseline methods. The figure presents two views of 3D objects generated from text prompts. The top section provides a direct comparison between GaussianAnything and baseline methods, demonstrating the superior quality of GaussianAnything’s output. The bottom section presents additional examples generated by GaussianAnything, alongside their corresponding geometry maps, further highlighting the model’s ability to generate high-quality 3D shapes with accurate textures and strong alignment between the generated content and the input text prompt.
read the caption
Figure 5: Qualitative Comparison of Text-to-3D. We present text-conditioned 3D objects generated by GaussianAnything, displaying two views of each sample. The top section compares our results with baseline methods, while the bottom shows additional samples from our method along with their geometry maps. Our approach consistently yields better quality in terms of geometry, texture, and text-3D alignment.

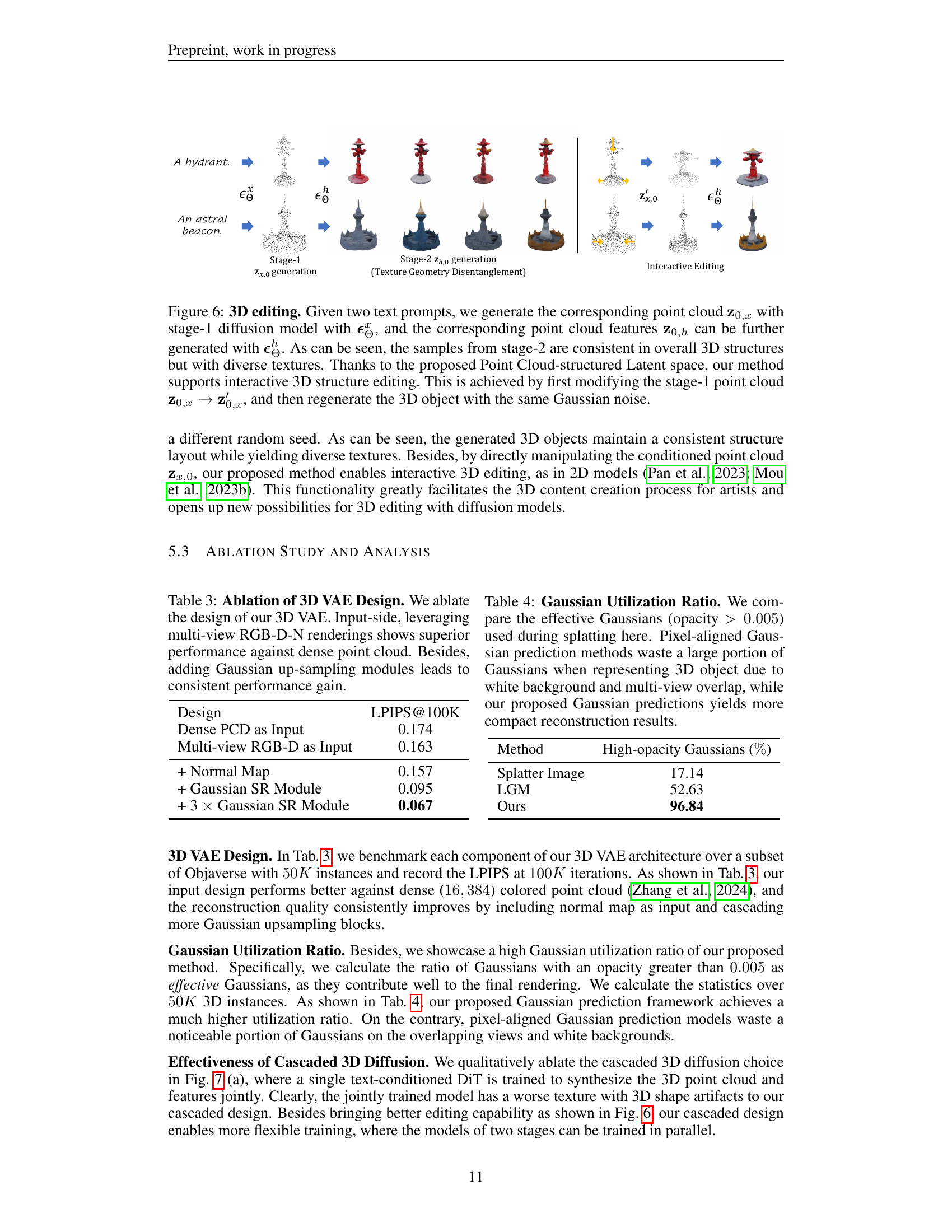
🔼 This figure demonstrates the 3D editing capabilities of the GAUSSIANANYTHING model. Two text prompts are used to generate a point cloud representing the 3D object’s structure (z0,x) using a stage-1 diffusion model and its corresponding features (z0,h) using a stage-2 diffusion model. The stage-2 samples maintain consistent 3D structure but offer diverse textures. The point cloud-structured latent space allows for interactive 3D editing. This is shown by modifying the stage-1 point cloud (z0,x) to (z0,x’) and then regenerating the 3D object using the same Gaussian noise, highlighting the disentanglement of geometry and texture.
read the caption
Figure 6: 3D editing. Given two text prompts, we generate the corresponding point cloud 𝐳0,xsubscript𝐳0𝑥{\mathbf{z}}_{0,x}bold_z start_POSTSUBSCRIPT 0 , italic_x end_POSTSUBSCRIPT with stage-1 diffusion model with ϵΘxsuperscriptsubscriptbold-italic-ϵΘ𝑥\bm{\epsilon}_{\Theta}^{x}bold_italic_ϵ start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_x end_POSTSUPERSCRIPT, and the corresponding point cloud features 𝐳0,hsubscript𝐳0ℎ{\mathbf{z}}_{0,h}bold_z start_POSTSUBSCRIPT 0 , italic_h end_POSTSUBSCRIPT can be further generated with ϵΘhsuperscriptsubscriptbold-italic-ϵΘℎ\bm{\epsilon}_{\Theta}^{h}bold_italic_ϵ start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_h end_POSTSUPERSCRIPT. As can be seen, the samples from stage-2 are consistent in overall 3D structures but with diverse textures. Thanks to the proposed Point Cloud-structured Latent space, our method supports interactive 3D structure editing. This is achieved by first modifying the stage-1 point cloud 𝐳0,x→𝐳0,x′→subscript𝐳0𝑥superscriptsubscript𝐳0𝑥′{\mathbf{z}}_{0,x}\rightarrow{{\mathbf{z}}_{0,x}^{\prime}}bold_z start_POSTSUBSCRIPT 0 , italic_x end_POSTSUBSCRIPT → bold_z start_POSTSUBSCRIPT 0 , italic_x end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT, and then regenerate the 3D object with the same Gaussian noise.

🔼 This figure demonstrates the benefits of the two-stage cascaded diffusion process and the advantages of latent space editing. Subfigure (a) compares the results of a single-stage diffusion model (generating both geometry and texture at once) with the two-stage approach (geometry first, then texture) from Figure 5. The single-stage method shows inferior texture quality and structural fidelity compared to the cascaded method, highlighting the effectiveness of the two-stage design. Subfigure (b) shows that editing in the point cloud latent space (before decoding to surfel Gaussians) produces cleaner and more realistic results than directly editing the surfel Gaussians themselves. The comparison showcases a reduced chance of introducing artifacts or inconsistencies during the editing process.
read the caption
Figure 7: Qualitative ablation of Cascaded diffusion and latent space editing. We first show the effectiveness of our two-stage cascaded diffusion framework in (a). Compared to Fig. 5, the single-stage 3D diffusion yields worse texture details and 3D structure intactness. In (b), we validate the latent point cloud editing yields less 3D artifacts compared to direct 3D editing on the 3D Gaussians.
Full paper#