↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Egocentric video generation, simulating human perspectives in virtual environments, is a promising area with limited high-quality data. Existing datasets lack sufficient action annotations, scene diversity, or are affected by excessive noise, hindering effective model training. The lack of suitable datasets limits progress in virtual and augmented reality, and gaming applications.
To address these limitations, the paper introduces EgoVid-5M, a meticulously curated dataset with 5 million high-quality egocentric video clips. It features comprehensive annotations (fine-grained kinematic control and high-level textual descriptions), robust data cleaning to ensure video quality, and a broad range of scenes. The authors also present EgoDreamer, a model that leverages both action descriptions and kinematic controls for egocentric video generation. Experiments demonstrate EgoVid-5M’s effectiveness in improving video generation accuracy and quality across different model architectures.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation and computer vision due to its introduction of EgoVid-5M, a high-quality, large-scale dataset specifically designed for egocentric video generation. This dataset addresses a critical gap in the field, enabling advancements in virtual and augmented reality, gaming, and other applications that leverage human-centric perspectives. The paper also proposes EgoDreamer, a novel model for action-driven egocentric video generation, further enhancing the research potential of the dataset. Researchers can leverage these resources to make significant strides in creating more realistic and immersive experiences.
Visual Insights#
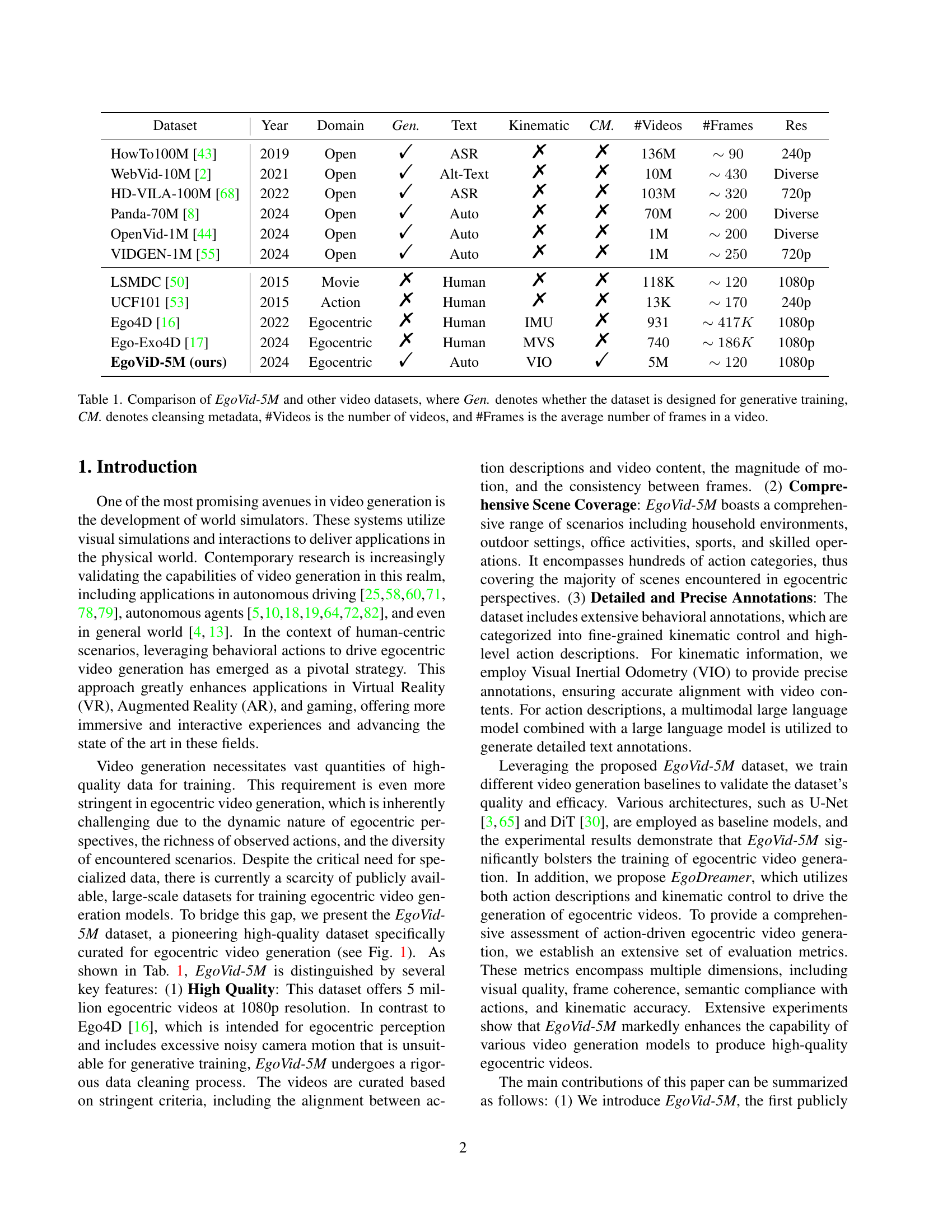
| Dataset | Year | Domain | Gen. | Text | Kinematic | CM. | #Videos | #Frames | Res |
|---|---|---|---|---|---|---|---|---|---|
| HowTo100M [43] | 2019 | Open | ✓ | ASR | ✗ | ✗ | 136M | ~90 | 240p |
| WebVid-10M [2] | 2021 | Open | ✓ | Alt-Text | ✗ | ✗ | 10M | ~430 | Diverse |
| HD-VILA-100M [68] | 2022 | Open | ✓ | ASR | ✗ | ✗ | 103M | ~320 | 720p |
| Panda-70M [8] | 2024 | Open | ✓ | Auto | ✗ | ✗ | 70M | ~200 | Diverse |
| OpenVid-1M [44] | 2024 | Open | ✓ | Auto | ✗ | ✗ | 1M | ~200 | Diverse |
| VIDGEN-1M [55] | 2024 | Open | ✓ | Auto | ✗ | ✗ | 1M | ~250 | 720p |
| LSMDC [50] | 2015 | Movie | ✗ | Human | ✗ | ✗ | 118K | ~120 | 1080p |
| UCF101 [53] | 2015 | Action | ✗ | Human | ✗ | ✗ | 13K | ~170 | 240p |
| Ego4D [16] | 2022 | Egocentric | ✗ | Human | IMU | ✗ | 931 | ~417K | 1080p |
| Ego-Exo4D [17] | 2024 | Egocentric | ✗ | Human | MVS | ✗ | 740 | ~186K | 1080p |
| EgoViD-5M (ours) | 2024 | Egocentric | ✓ | Auto | VIO | ✓ | 5M | ~120 | 1080p |
🔼 This table compares the EgoVid-5M dataset with other publicly available video datasets. It highlights key characteristics relevant to video generation tasks. The comparison includes the year the dataset was released, the domain of the videos (e.g., open-domain, egocentric), whether the dataset includes generated videos, the presence of text annotations, kinematic annotations (e.g., motion tracking data), cleansing metadata (information about data cleaning procedures), the number of videos, the average number of frames per video, and the resolution of the videos. This allows for an evaluation of EgoVid-5M’s size, quality, and suitability for various video generation tasks, particularly highlighting its unique features tailored for egocentric video generation.
read the caption
Table 1: Comparison of EgoVid-5M and other video datasets, where Gen. denotes whether the dataset is designed for generative training, CM. denotes cleansing metadata, #Videos is the number of videos, and #Frames is the average number of frames in a video.
In-depth insights#
EgoVid-5M Dataset#
The EgoVid-5M dataset represents a significant advancement in egocentric video generation. Its large scale (5 million clips) addresses a critical limitation of previous datasets, providing the volume of data needed to train robust models. The focus on high-quality 1080p videos, coupled with rigorous data cleaning, ensures superior training data compared to noisy alternatives. Detailed annotations, including fine-grained kinematic controls and high-level textual descriptions, offer unprecedented controllability for generative models. This is further enhanced by the introduction of EgoDreamer, showcasing the dataset’s potential for generating realistic and action-coherent egocentric videos. The meticulous curation, data cleaning pipeline, and comprehensive annotations make EgoVid-5M a powerful tool to push the boundaries of egocentric video generation research.
Action Annotations#
Action annotations in egocentric video datasets are crucial for enabling high-level understanding and generation of egocentric videos. High-quality annotations must be detailed and precise, capturing both fine-grained kinematic information (e.g., camera pose, velocity, and acceleration) and high-level semantic descriptions of actions. The annotations should seamlessly align with the video content, ensuring temporal consistency and accuracy. The challenge lies in the dynamic nature of egocentric viewpoints and the diversity of actions, requiring robust annotation strategies and potentially involving a combination of automatic methods and human labeling to maintain accuracy and consistency across the dataset. Careful consideration must be given to the granularity of annotations, balancing the need for detailed information with practicality and computational efficiency. A well-annotated dataset will significantly impact downstream tasks such as action recognition, video generation, and human behavior analysis, enabling researchers to build more robust and realistic models for egocentric video understanding and simulation.
Data Cleaning#
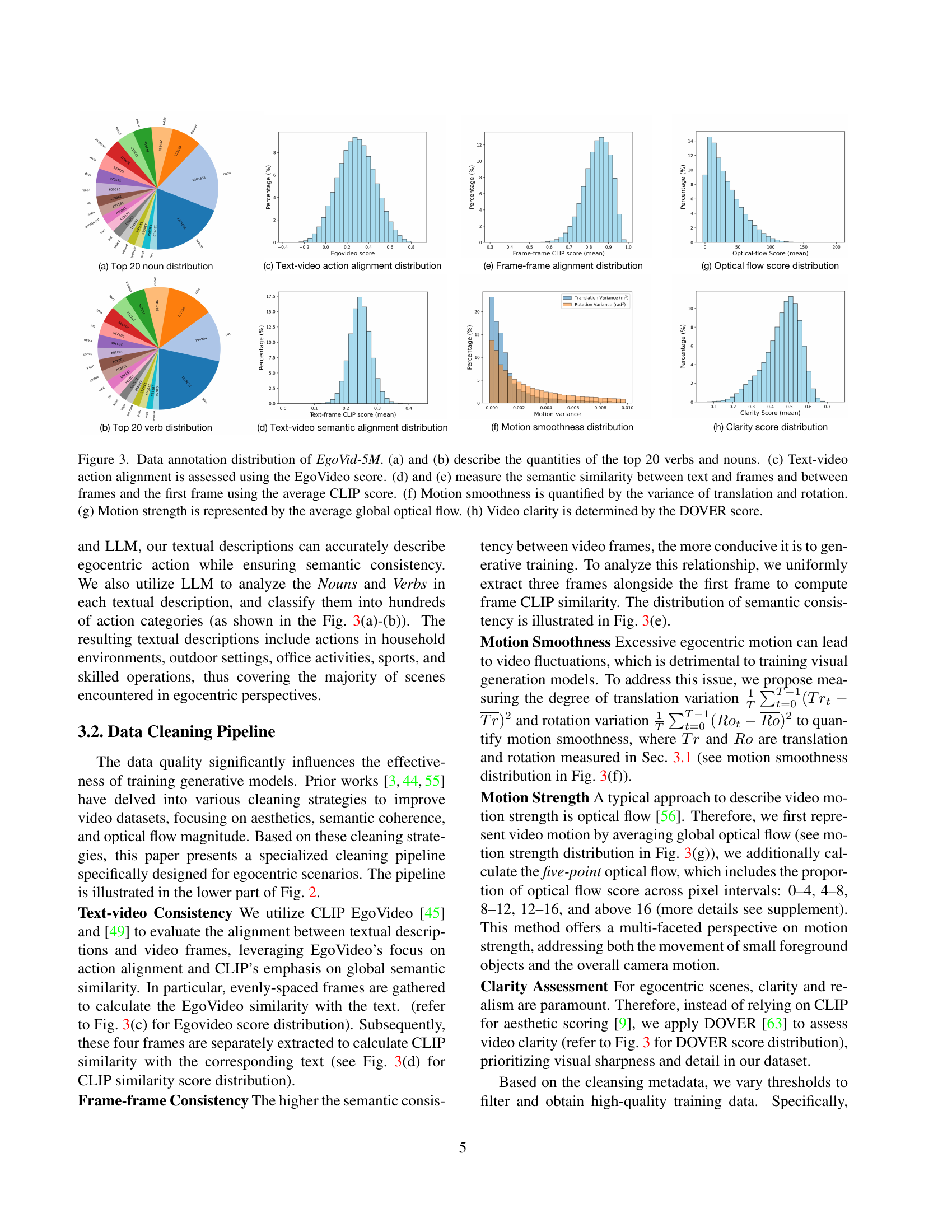
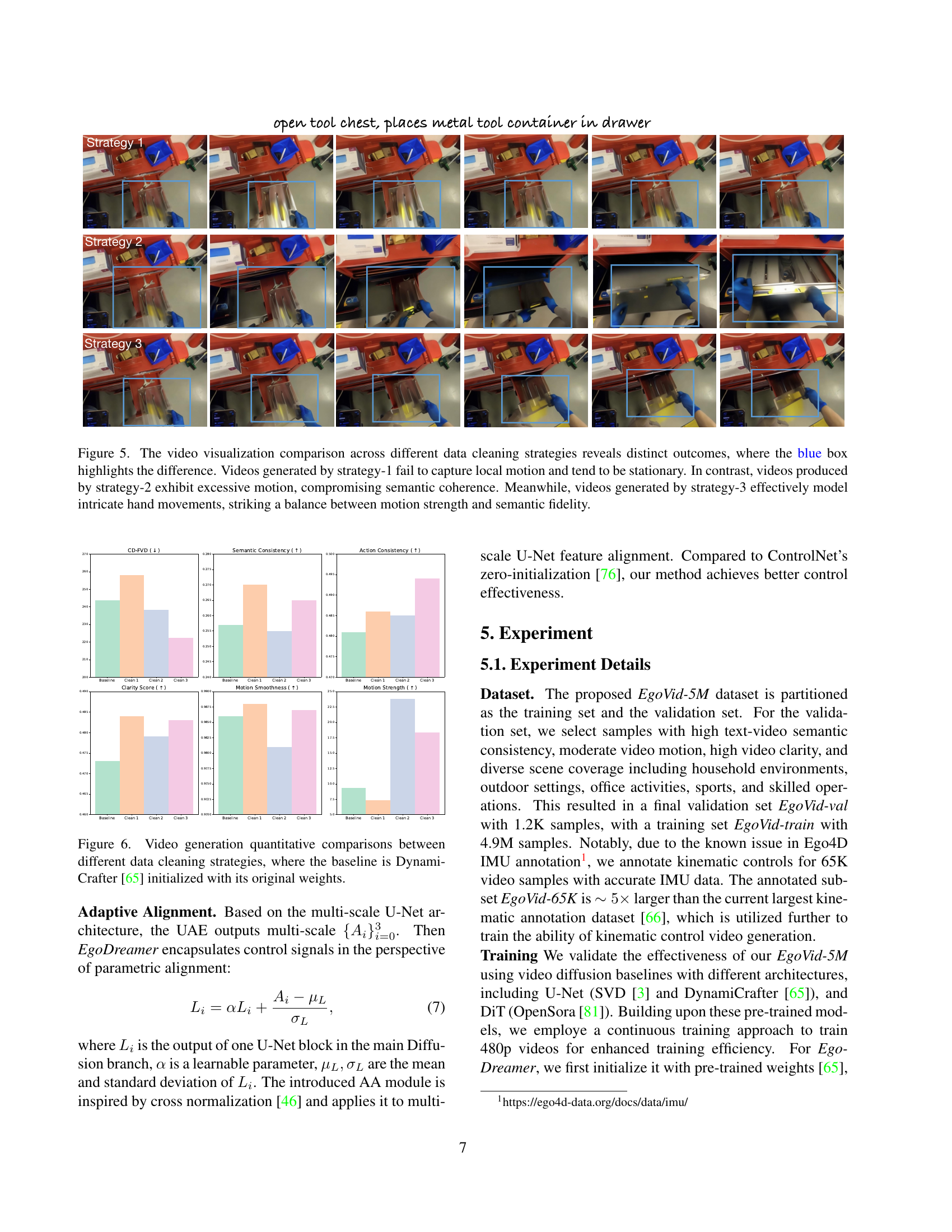
The data cleaning pipeline is a crucial aspect of the EgoVid-5M dataset creation, directly impacting the quality and usability of the dataset for egocentric video generation. The paper highlights a multi-faceted approach, addressing issues such as text-video consistency, frame-frame consistency, motion smoothness, and video clarity. Specific metrics like CLIP and EgoVideo scores are employed to quantify semantic alignment between video and textual descriptions. A sophisticated method of optical flow analysis, including five-point optical flow, is utilized to assess the balance of movement while avoiding over- or under-representation of motion. Furthermore, the cleaning process doesn’t just focus on motion quality but also on visual quality using the DOVER score, ensuring that only high-quality, visually clear videos are retained. This careful and multi-pronged approach ensures that the final dataset is suitable for training high-quality egocentric video generation models, minimizing artifacts that would otherwise hinder performance. The authors emphasize the significance of data cleaning to counteract the inherent challenges of egocentric video data, where noise and inconsistencies are more prevalent, and offer a comprehensive strategy that may be beneficial to future work in the field.
EgoDreamer Model#
The EgoDreamer model is a novel architecture designed for high-quality egocentric video generation. It cleverly addresses the challenges of this domain by integrating both high-level action descriptions and low-level kinematic control signals. This dual-input approach is facilitated by a Unified Action Encoder (UAE), allowing for a more nuanced representation of ego-movements. The UAE simultaneously processes these disparate input types, overcoming limitations of previous models that treated them separately. Furthermore, the model’s Adaptive Alignment (AA) mechanism seamlessly integrates these action signals into the video generation process, enabling greater precision and control. This results in egocentric videos which exhibit increased realism, semantic consistency, and intricate action details. EgoDreamer’s superior performance is validated by experiments comparing it to other state-of-the-art egocentric video generation models, demonstrating its ability to generate high-quality videos driven by both textual action descriptions and precise kinematic information.
Future Directions#
Future research directions stemming from this work could explore improving the diversity and realism of generated egocentric videos. This could involve incorporating more sophisticated models of human behavior and interaction, and integrating diverse environmental contexts. Additionally, researchers could focus on enhancing controllability. Currently, control is achieved through high-level descriptions and low-level kinematic signals, but finer-grained control over specific aspects of the generated videos would be highly desirable. Addressing limitations in data quality remains an important direction; while the dataset is significant, improvements in annotation accuracy and coverage are always beneficial. Finally, investigating the potential biases present in the dataset and how they might affect downstream tasks is crucial. Ensuring fairness and mitigating bias through careful dataset curation and model training techniques should be prioritized.
More visual insights#
More on tables
| Method | w. EgoVid | CD-FVD ↓ | Semantic Consistency ↑ | Action Consistency ↑ | Clarity Score ↑ | Motion Smoothness ↑ | Motion Strength ↑ |
|---|---|---|---|---|---|---|---|
| SVD [3] | ✗ | 591.61 | 0.258 | 0.465 | 0.479 | 0.971 | 18.897 |
| SVD [3] | ✓ | 548.32 | 0.266 | 0.471 | 0.485 | 0.974 | 21.032 |
| DynamiCrafter [65] | ✗ | 243.63 | 0.257 | 0.481 | 0.473 | 0.986 | 9.357 |
| DynamiCrafter [65] | ✓ | 236.82 | 0.265 | 0.494 | 0.483 | 0.987 | 18.329 |
| OpenSora [81] | ✗ | 809.46 | 0.260 | 0.489 | 0.520 | 0.983 | 7.608 |
| OpenSora [81] | ✓ | 718.32 | 0.266 | 0.494 | 0.528 | 0.986 | 15.871 |
🔼 This table presents a quantitative comparison of the performance of three different video generation models (SVD, DynamiCrafter, and OpenSora) trained with and without the EgoVid-5M dataset. Six metrics are used to evaluate the generated videos: CD-FVD (measuring spatial and temporal quality), Semantic Consistency, Action Consistency, Clarity Score, Motion Smoothness, and Motion Strength. The results demonstrate that fine-tuning these models with EgoVid-5M consistently improves performance across all six metrics, showcasing the dataset’s effectiveness in improving egocentric video generation.
read the caption
Table 2: EgoVid significantly enhances egocentric video generation. Experimental results demonstrate that training with EgoVid improves performance across all three baselines on six metrics.
| w. EgoVid | ControlNet | ControlNeXt | AA | UAE | CD-FVD ↓ | Semantic Consistency ↑ | Action Consistency ↑ | Rot Err ↓ | Trans Err ↓ |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | 241.90 | 0.263 | 0.490 | 5.32 | 9.27 | ||||
| ✓ | ✓ | 238.87 | 0.266 | 0.493 | 4.01 | 8.66 | |||
| ✓ | ✓ | ✓ | 239.01 | 0.268 | 0.494 | 3.58 | 8.41 | ||
| ✓ | ✓ | ✓ | 234.13 | 0.269 | 0.497 | 3.59 | 7.93 | ||
| ✓ | ✓ | ✓ | 229.82 | 0.268 | 0.498 | 3.28 | 7.62 |
🔼 This ablation study analyzes the impact of different training strategies and components of the EgoDreamer model on egocentric video generation. It compares the performance of various configurations, including different cleaning strategies for the training data, the use of ControlNet and ControlNeXt for kinematic control, the Unified Action Encoder (UAE) for multimodal action input, and the Adaptive Alignment (AA) module. The results are evaluated based on several key metrics, including CD-FVD (lower is better), Semantic Consistency, Action Consistency, rotation and translation errors. This table helps determine the optimal combination of techniques for generating high-quality egocentric videos.
read the caption
Table 3: Ablation study on training strategy and different components of EgoDreamer.
Full paper#