↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Extracting user actions from desktop recordings is valuable for automating processes, creating personalized user experiences, and generating tutorials. However, this area has been largely unexplored. Existing video analysis methods often struggle with the complexities of desktop interfaces and the rich temporal dynamics of user interactions. This paper addresses this gap by proposing two methods to extract user action sequences from desktop recordings, using Vision-Language Models (VLMs).
The proposed methods are evaluated on two benchmark datasets, one self-curated and another adapted from prior work. The Direct Frame-Based Approach, which directly inputs video frames into VLMs, outperforms the Differential Frame-Based Approach, demonstrating the potential of VLMs for this task. The study also shows that the accuracy of user action extraction ranges from 70% to 80%, with the extracted action sequences being replayable through Robotic Process Automation (RPA). This work represents the first application of VLMs for extracting user action sequences from desktop recordings, paving the way for novel applications and research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the underexplored area of user action extraction from desktop recordings using Vision-Language Models (VLMs). It introduces novel methods, benchmarks, and insights that can significantly advance the field of Robotic Process Automation (RPA), personalized user experience design, and automated tutorial generation. The findings also open new avenues for future research into VLM applications in complex dynamic environments like desktop interfaces.
Visual Insights#

🔼 The Direct Frame-Based Approach (DFA) processes video frames directly using Vision-Language Models (VLMs). It consists of three modules: an Action Proposer that suggests actions from the input frames, an Action Corrector to filter out errors, and an Action Merger that combines action sequences from multiple frame batches. The figure illustrates the architecture of the DFA, showcasing the flow of data and operations through these three modules.
read the caption
(a) Direct Frame-Based Approach
| Dataset | Case | Domain | Total Videos | Frame Count | Action Count | Unique Action Type Count |
|---|---|---|---|---|---|---|
| ActOne | click | 14 | 276 | 1.7 | 1.1 | |
| select | 11 | 242 | 1.0 | 1.0 | ||
| scroll | 6 | 292 | 1.2 | 1.2 | ||
| drag | 5 | 285 | 1.4 | 1.4 | ||
| type | 4 | 255 | 1.5 | 1.3 | ||
| All | 40 | 1250 | 1.3 | 1.2 | ||
| ActReal | Software | 23 | 684 | 7.5 | 3.0 | |
| Website | 15 | 985 | 8.3 | 3.1 | ||
| Multi | 3 | 836 | 6.0 | 3.3 | ||
| All | 41 | 2505 | 7.7 | 3.1 |
🔼 This table presents a statistical overview of two benchmark datasets, ActOne and ActReal, used in the paper to evaluate the performance of Vision-Language Models (VLMs) in extracting user actions from desktop recordings. For each dataset, it shows the number of videos, the total number of actions across those videos, and the average number of actions per video. It further breaks down this information by the different types of actions (click, select, scroll, drag, type) present in each dataset. The average values presented are calculated separately for different domains or categories of actions within each dataset, offering more detailed insights into the data distribution.
read the caption
TABLE I: Statistics of benchmark datasets ActOne and ActReal. The numbers in the last three columns are the average values computed within each respective case domain.
In-depth insights#
VLM-based Action Extraction#
Vision-Language Models (VLMs) present a novel approach to user action extraction from desktop recordings. Direct Frame-Based (DF) approaches directly feed video frames to the VLM for action sequence generation, leveraging the model’s inherent ability to correlate visual information with actions. Differential Frame-Based (DiffF) methods, conversely, pre-process the video by detecting changes using computer vision, then inputting these differences to the VLM. While DiffF aims to improve performance by highlighting relevant changes, results suggest that DF generally outperforms DiffF, potentially because explicit UI change extraction can introduce noise that degrades VLM accuracy. This highlights the complexity of integrating computer vision with VLMs for this task. Benchmark datasets are crucial for evaluating these approaches and future research should focus on developing more realistic and diverse benchmarks to push the boundaries of VLM-based action extraction.
Benchmark Datasets#
The creation of robust benchmark datasets is crucial for evaluating the effectiveness of user action extraction methods from desktop recordings. A well-designed benchmark should consider diversity in terms of user actions, encompassing a range of interaction types (clicks, drags, scrolls, selections, typing) and varying levels of complexity. The datasets should also exhibit variations in UI design and application types, reflecting the heterogeneous nature of real-world desktop environments. Furthermore, data quality and annotation accuracy are paramount; inconsistencies or inaccuracies in the ground truth labels can significantly impact the reliability of the evaluation. Finally, the size of the dataset needs careful consideration, balancing the need for sufficient data to capture variability with the practical constraints of data collection and annotation effort. Ideally, the datasets should also have clearly defined metrics that align with the research goal. The use of multiple benchmark datasets—one focused on individual action types and another reflecting real-world scenarios—enhances the rigor of the evaluation process and helps identify the limitations of proposed methods in various contexts.
Method Comparison#
A robust method comparison necessitates a multi-faceted analysis. It should delve into the performance metrics achieved by each method, considering factors like accuracy, precision, recall, and F1-score. Furthermore, a thorough examination of the computational costs associated with each method is crucial. This includes assessing the required computational resources, processing time, memory usage, and overall efficiency. It is essential to compare methods on diverse datasets, ensuring the chosen datasets adequately represent real-world variability. A qualitative comparison also matters; aspects such as implementation complexity, model interpretability, and ease of generalization should be evaluated. Finally, a discussion of the strengths and weaknesses of each method, highlighting their suitability for various contexts, is critical for a complete comparison. This holistic approach will lead to a more informed decision on selecting the most appropriate method for any given task.
Error Analysis#
A dedicated ‘Error Analysis’ section in a research paper provides crucial insights into the limitations and potential improvements of proposed methods. It systematically examines instances where the model’s performance deviates from expectations. This involves identifying the types of errors, their frequency, and potential causes, such as visual hallucinations, where the model incorrectly interprets visual data, or reasoning failures, where the model’s logic breaks down. Analyzing error patterns helps to pinpoint weaknesses in the model’s architecture or training process. For example, frequently occurring visual hallucinations might suggest the need for improved data augmentation or more robust feature extraction techniques. Similarly, recurring reasoning failures might highlight the need for a more sophisticated reasoning module or a better understanding of the task’s underlying complexities. A thorough error analysis is critical for evaluating the reliability and robustness of a model and for guiding the development of more accurate and reliable systems. The analysis can also reveal unexpected model behaviors or highlight previously unconsidered factors influencing performance. Ultimately, this section provides valuable feedback, supporting future research directions and improving the overall trustworthiness of the findings.
Future Work#
Future research directions stemming from this work on VLM-based user action extraction from desktop recordings could focus on several key areas. Improving the robustness of the current methods to handle diverse recording conditions (e.g., varying video quality, different UI styles) is crucial for real-world applicability. Exploring more sophisticated VLM architectures or training strategies, possibly incorporating temporal modeling techniques more explicitly, could significantly enhance performance. Developing more comprehensive benchmark datasets with a wider range of user actions and interaction scenarios is vital to objectively evaluate future advancements. The integration of additional modalities, such as audio or mouse cursor data, presents a promising avenue to improve accuracy and contextual understanding. Finally, investigating applications beyond RPA such as automated tutorial generation, personalized user experience design, or anomaly detection in user behavior, warrants further exploration.
More visual insights#
More on figures

🔼 The figure illustrates the architecture of the Differential Frame-Based Approach (DiffF) for extracting user action sequences from desktop recordings. It shows the different processing stages involved: First, a Frame Difference Localizer identifies UI changes between consecutive frames. Then, a Frame Difference Descriptor generates textual descriptions of these changes. Finally, an Action Proposer and Action Corrector leverage vision-language models to interpret these descriptions and generate the final action sequence. The DiffF method differs from the Direct Frame-Based Approach by explicitly incorporating UI changes, enabling a comparison of the effectiveness of these different approaches.
read the caption
(b) Differential Frame-Based Approach

🔼 This figure illustrates the architectures of two proposed methods for extracting user action sequences from desktop recordings: the Direct Frame-Based Approach (DF) and the Differential Frame-Based Approach (DiffF). The DF approach directly inputs sampled video frames into Vision-Language Models (VLMs) to generate action sequences. The DiffF approach first detects frame differences using computer vision techniques before using VLMs to interpret the changes and generate sequences. Both architectures involve an Action Proposer, Action Corrector, and (for DF) an Action Merger to refine the action sequences.
read the caption
Figure 1: Architectures of Direct Frame-Based Approach (left) and Differential Frame-Based Approach (right).
More on tables
| Method | Model | Recall (Operation) | Precision (Operation) | Recall (All) | Precision (All) |
|---|---|---|---|---|---|
| DF | Gemini1.5-Pro | 0.71 | 0.73 | 0.49 | 0.51 |
| Gemini1.5-Flash | 0.69 | 0.59 | 0.30 | 0.26 | |
| GPT-4o | 0.83 | 0.81 | 0.71 | 0.68 | |
| GPT-4o-mini | 0.63 | 0.33 | 0.38 | 0.17 | |
| DiffF | Gemini1.5-Pro | 0.75 | 0.48 | 0.45 | 0.24 |
| Gemini1.5-Flash | 0.74 | 0.37 | 0.54 | 0.27 | |
| GPT-4o | 0.87 | 0.66 | 0.76 | 0.59 | |
| GPT-4o-mini | 0.59 | 0.26 | 0.45 | 0.19 |
🔼 This table presents the performance evaluation results on the ACTONE dataset for two proposed methods (Direct Frame-Based Approach and Differential Frame-Based Approach) using various Vision-Language Models (VLMs). It shows Precision and Recall scores for both overall action element accuracy and operation type accuracy. The results are broken down by the specific VLM used, enabling a comparison of model performance.
read the caption
TABLE II: Evaluation results for the ActOne dataset.
| Method | Model | Recall (Operation) | Precision (Operation) | Recall (All) | Precision (All) |
|---|---|---|---|---|---|
| DF Gemini1.5-Pro | Gemini1.5-Pro | 0.73 | 0.72 | 0.37 | 0.32 |
| Gemini1.5-Flash | 0.77 | 0.39 | 0.47 | 0.22 | |
| GPT-4o | 0.82 | 0.70 | 0.45 | ||
| GPT-4o-mini | 0.73 | 0.46 | 0.41 | 0.27 | |
| DiffF Gemini1.5-Pro | Gemini1.5-Pro | 0.64 | 0.79 | 0.22 | 0.26 |
| Gemini1.5-Flash | 0.59 | 0.43 | 0.26 | 0.16 | |
| GPT-4o | 0.38 | 0.27 | 0.78 | 0.54 | |
| GPT-4o-mini | 0.30 | 0.59 | 0.13 | 0.25 |
🔼 Table III presents the performance evaluation metrics for the ACTREAL dataset. It shows the Precision and Recall for both operation-level and all-element-level evaluations for different Vision-Language Models (VLMs) and the two proposed methods (DF and DiffF). The metrics indicate the accuracy of the VLMs in extracting user actions from desktop recordings in more complex, real-world scenarios.
read the caption
TABLE III: Evaluation results for the ActReal dataset.
| Method | Visual Hallucination | Visual Blindness | Inadequate Reasoning | Poor Instruction-Following |
|---|---|---|---|---|
| DF | 7 | 5 | 2 | 1 |
| DiffF | 8 | 7 | 17 | 4 |
🔼 This table presents a breakdown of the errors encountered when using the GPT-40 model on the ActOne dataset. It categorizes the failures into four main types: visual hallucination (the model incorrectly generates visual information), visual blindness (the model fails to detect real visual changes), inadequate reasoning (the model fails to use appropriate reasoning), and poor instruction following (the model does not follow instructions well). The numbers represent the count of each error type.
read the caption
TABLE IV: Count of failed cases when applying GPT-4o to the ActOne dataset.
| Method + Model + Dataset (Variation) | Recall (Operation) | Precision (Operation) | Recall (All) | Precision (All) |
|---|---|---|---|---|
| DF + GPT-4o + AO (w/o Action Corrector) | 0.83 (0.76↓) | 0.81 (0.63↓) | 0.68 (0.40↓) | 0.71 (0.48↓) |
| DiffF + GPT-4o + AO (w/o Action Corrector) | 0.87 (0.89↑) | 0.66 (0.46↓) | 0.59 (0.21↓) | 0.76 (0.35↓) |
| DF + Gemini1.5-Pro + AR (w/o Sliding Window) | 0.73 (0.51↓) | 0.72 (0.91↑) | 0.32 (0.36↑) | 0.37 (0.22↓) |
| DiffF + GPT-4o + AO (add frames to Proposer) | 0.87 (0.88↑) | 0.66 (0.69↑) | 0.59 (0.61↑) | 0.76 (0.76) |
| DF + GPT-4o + AO (w/ region diff annotation) | 0.83 (0.84↑) | 0.81 (0.61↓) | 0.68 (0.42↓) | 0.71 (0.60↓) |
🔼 This table presents the ablation study results for different variations of the proposed methods (DF and DiffF) on two datasets, ActOne (AO) and ActReal (AR). For each dataset and method, it shows the performance metrics (Precision and Recall) for evaluating all action elements and only operation types. The default method results (without variations) are presented outside the brackets, while the results for different variations (e.g., removing Action Corrector, using different model, etc.) are shown inside brackets.
read the caption
TABLE V: Ablation study results for several method variations on ActOne (AO) and ActReal (AR). Default method results are shown outside brackets (from Tables II and III), with corresponding variation results in brackets.
| Method | Model | Case Domain (Video Count) | Recall (Operation) | Precision (Operation) | Recall (All) | Precision (All) |
|---|---|---|---|---|---|---|
| DF | GPT-4o | click (14) | 0.94 | 0.88 | 0.90 | 0.81 |
select (11) | 1.00 | 0.95 | 0.64 | 0.64 | ||
scroll (6) | 0.75 | 0.75 | 0.75 | 0.75 | ||
drag (5) | 0.40 | 0.50 | 0.30 | 0.40 | ||
type (4) | 0.67 | 0.63 | 0.67 | 0.63 | ||
| Gemini1.5-Pro | click (14) | 0.85 | 0.87 | 0.63 | 0.65 | |
select (11) | 0.64 | 0.64 | 0.18 | 0.18 | ||
scroll (6) | 0.58 | 0.67 | 0.58 | 0.67 | ||
drag (5) | 0.70 | 0.63 | 0.50 | 0.43 | ||
type (4) | 0.67 | 0.75 | 0.67 | 0.75 | ||
| Diff | GPT-4o | click (14) | 0.82 | 0.71 | 0.82 | 0.71 |
select (11) | 1.00 | 0.77 | 0.82 | 0.64 | ||
scroll (6) | 0.83 | 0.41 | 0.67 | 0.37 | ||
drag (5) | 0.70 | 0.37 | 0.70 | 0.37 | ||
type (4) | 0.92 | 0.88 | 0.58 | 0.63 | ||
| Gemini1.5-Pro | click (14) | 0.69 | 0.49 | 0.36 | 0.18 | |
select (11) | 0.73 | 0.44 | 0.45 | 0.21 | ||
scroll (6) | 0.92 | 0.60 | 0.75 | 0.57 | ||
drag (5) | 0.80 | 0.33 | 0.60 | 0.22 | ||
type (4) | 0.67 | 0.55 | 0.08 | 0.13 |
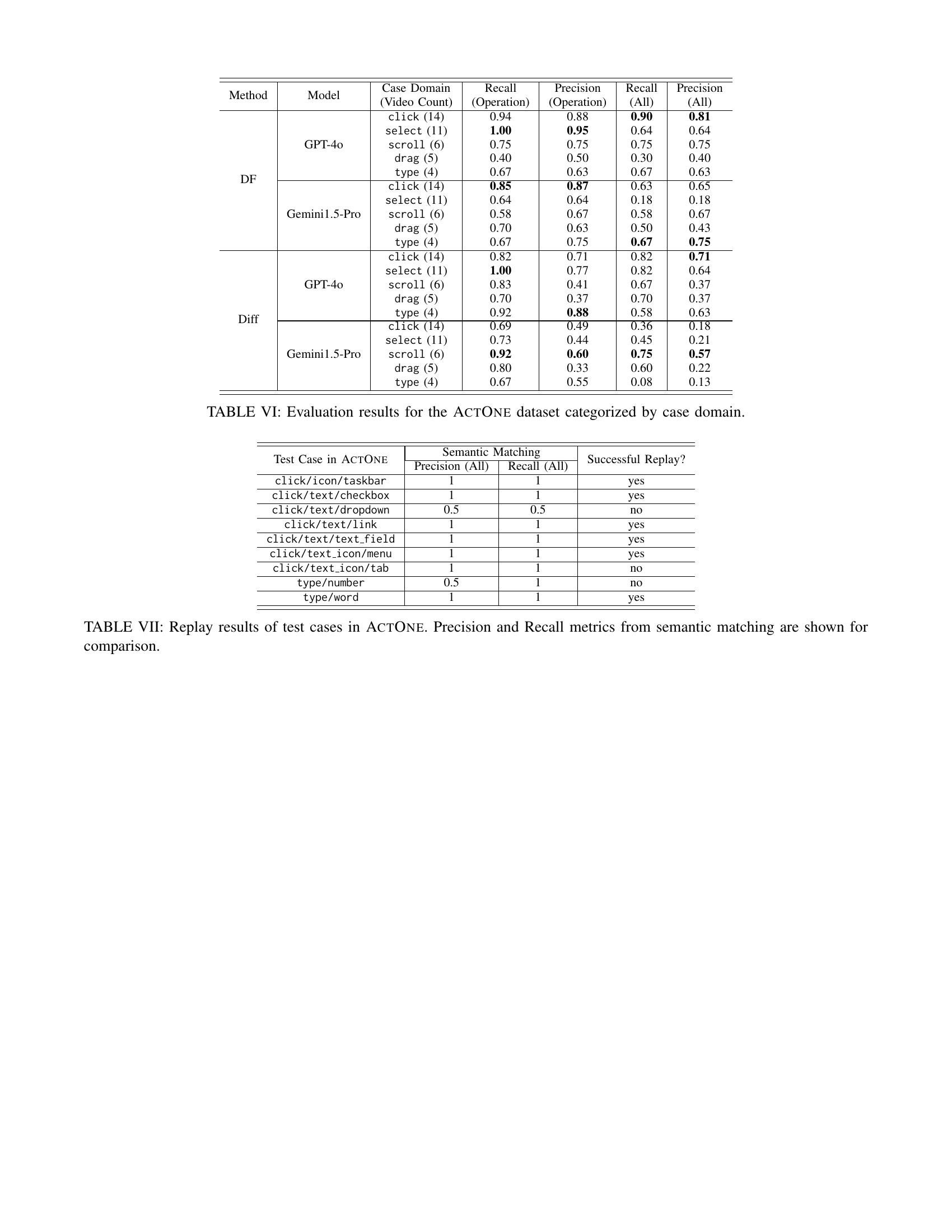
🔼 This table presents a detailed breakdown of the performance of different Vision-Language Models (VLMs) on the ActOne dataset. The ActOne dataset is a benchmark dataset specifically designed for evaluating VLM’s ability to extract user actions from desktop recordings, and contains five distinct operation types (click, select, scroll, drag, type). The table shows the precision and recall of each VLM for each operation type, providing a granular view of model performance across different user actions. This allows for a more nuanced understanding of the strengths and weaknesses of each model in various contexts.
read the caption
TABLE VI: Evaluation results for the ActOne dataset categorized by case domain.
| Test Case in ActOne | Semantic Matching | Semantic Matching | Successful Replay? |
|---|---|---|---|
| Precision (All) | Recall (All) | ||
click/icon/taskbar | 1 | 1 | yes |
click/text/checkbox | 1 | 1 | yes |
click/text/dropdown | 0.5 | 0.5 | no |
click/text/link | 1 | 1 | yes |
click/text/text_field | 1 | 1 | yes |
click/text_icon/menu | 1 | 1 | yes |
click/text_icon/tab | 1 | 1 | no |
type/number | 0.5 | 1 | no |
type/word | 1 | 1 | yes |
🔼 This table presents the results of a robotic process automation (RPA) replay experiment conducted to validate the semantic comparison metrics used in the paper. Nine test cases from the ActOne dataset were selected for the replay. The table shows whether each case was successfully replayed (yes/no) based on the predicted action sequences. Additionally, the table includes the Precision and Recall metrics obtained from the semantic comparison as a basis for comparison with the replay results.
read the caption
TABLE VII: Replay results of test cases in ActOne. Precision and Recall metrics from semantic matching are shown for comparison.
| - | ## click Description: - The user clicks on an interface element (e.g., a button, link, or icon), activating the element (e.g., button press effect), and triggering various events (e.g., opening a new window, expanding a menu, changing the state of an element). - If you think the user’s operation is “click”, you need to keep observing several frames to see if the operation is “drag” or “select”, which contains the “click” operation. Identification: - By the change of mouse: shape change: The mouse may change shape (e.g., pointing hand when clicking a link). - By the change of interface element: press effective: Buttons or other clickable elements display a press effect (e.g., changing color, showing a shadow, slightly changing shape, checkbox gets checked). - By the change of display: feedback message: The interface displays feedback messages or changes (e.g., new window opens, menu expands). ## select Description: - Text selection: The user selects text in a document, highlighting the selected text with a different background color. For example, select two sentences in Microsoft Word. - Icon selection: The user selects icons on a desktop or in an application, the selected icons should be enclosed within a blue rectangular box. For example, select two icons on the desktop. - Cell selection: The user selects cells in a spreadsheet or table, highlighting the selected cells with a different background color. For example, select three cells in Excel. Identification: - By the change of mouse: Text selection: mouse position: The position of the mouse indicates the start and end of the selection range. You should observe the mouse movement over the text to identify the selection. (e.g., from the beginning of the first sentence to the end of the second sentence) Icon selection: Mouse position: mouse move over the icons, and the selected icons should be enclosed within a blue rectangular box. You should observe the blue rectangular box region to identify the number of selected icons. - By the change of interface element: color change: The background color of the selected text or selected icons changes to indicate the selection. (e.g., from white to blue) ## type Description: - Text input: The user types text into a text field or document, entering characters, words, or sentences. For example, typing in a search bar, filling out a form, or writing an email. - Command input: The user types commands or inputs specific text strings to perform actions or trigger events. For example, typing commands in a terminal. Identification: - By the change of interface element: text change: The content of the text field changes as the user types, updating the displayed text. ## scroll Description: - Vertical scroll: The user scrolls vertically through a document or interface, moving the content up or down to view more information. - Horizontal scroll: The user scrolls horizontally through a document or interface, moving the content left or right to view more information. Identification: - By the change of mouse: mouse position: The mouse may move to the scroll bar or scroll area, indicating the intention to scroll. |
🔼 This table shows the first part of the prompt used in the Action Proposer module of the Direct Frame-Based Approach method. The prompt instructs a Vision-Language Model (VLM) on how to identify and describe user actions from a sequence of frames in a video recording. The detailed instructions specify the format of the response and include descriptions for various types of actions such as click, drag, select, type, and scroll. The prompt emphasizes prompt engineering techniques to ensure the VLM can extract actionable insights from the visual data.
read the caption
TABLE VIII: Prompt of action proposer of DF method: 1/3
| Operation Category | frame_total | frame_idx | mouse_position | element_state_pre_interaction | element_state_after_interaction | Thoughts | application |
|---|---|---|---|---|---|---|---|
| Scroll | 100 | [1,10] | Moved from top to bottom of the scrollbar | Scrollbar at the top, showing the beginning of the document | Scrollbar in the middle, showing middle portion of the document | User scrolled down by moving the scrollbar from top to bottom. | Web Browser: Chrome |
| Drag | 100 | [12,25] | Moved from one icon to another | Icon A is at position (10,10), Icon B at position (100,100) | Icon A is now at position (100,100), Icon B remains at position (100,100) | User dragged icon A from (10,10) to (100,100). | Windows OS: File Explorer |
| Click | 100 | [26,26] | Clicked on the ‘Save’ button | ‘Save’ button is enabled | ‘Save’ button is still enabled | User clicked the ‘Save’ button. This is not a drag operation as there is no movement of any element. | Microsoft Word: Document1 |
| Select | 100 | [27,35] | Dragged mouse to select multiple lines of text | No text is selected | Several lines of text is selected | User selected multiple lines of text by dragging the mouse over them. | Microsoft Word: Document1 |
| Type | 100 | [36,45] | Typed ‘Hello World!’ | Text field is empty | Text field contains ‘Hello World!’ | User typed ‘Hello World!’ into the text field. | Web Browser: Chrome |
🔼 This table provides the second part of the prompt used in the Action Proposer module of the Direct Frame-Based Approach method. It details instructions on how to identify various user operations (click, drag, scroll, select, type) based on changes in the user interface and mouse behavior. The prompt guides the VLM to analyze image sequences and generate a detailed description of the user actions. It specifies the required information to include in the output, such as operation type, target object, application, additional information and overall description.
read the caption
TABLE IX: Prompt of action proposer of DF method: 2/3
| - If category is "Web Browser", the identifier can be the name of the website (e.g., "Google", "YouTube", "Apple Music"). - if category is "Windows OS", the identifier can be the name of the window or the desktop (e.g., "Desktop", "Taskbar", "File Explorer", "Menu"). - If there is no specific identifier, leave it empty(e.g., "")." - "target_object": The object in "application" that the user interacted with, including the object category and identifier. - category: The object category can only be one of the following: "button", "text field", "icon", "dropdown", "list", "scroll bar", "document", "webpage", "dialog box", "menu", "file", "folder", "checkbox", "radio button", "search bar", "form", "email", "paragraph", "sentence", "word". - identifier: The identifier should be a description or name of the object (e.g., "Bold button", "Main Text Area", "File icon"). - If there is no specific identifier, leave it empty(e.g., "")." - For the "scroll bar" category, the identifier should be the direction of the scroll bar and the subject that the scroll bar control.(e.g. horizontal scroll bar of sheet1) - "additional_info": Any additional information related to the operation, such as the direction of scroll, the amount of scroll, the content typed, or the location of selected text or icons. - "additional_info" is optional and should be included only for the operation category "scroll", "type", and "select", for other categories, you can leave it empty(e.g., ""). - For the "scroll" operation, include the direction of scroll ("up" or "down", "left" or "right") and the amount of scroll (e.g., "half page", "two lines", "until that you can see the yellow icon in the dropdown list"). - For the "select" operation, include the content selected. - For text selection, include the specific text selected. The granularity of the selection can be at the paragraph, sentence, or word level. e.g., "hello" in world level, "Hello World" in sentence level, "Hello World, How are you?" in paragraph level. - For icon selection, include the selected icons. The granularity of the selection can be at the icon level. e.g., "google icon", "apple icon". - For cell selection, include the selected cells. The granularity of the selection can be at the cell level. e.g., "A1", "B2". - For the "type" operation, include the content typed. - If the user types character by character, concatenate multiple characters into one word.(e.g., concatenate "H", "e", "l", "l", "o" into "Hello"). - If the word typed is too long, only output the number of sentences or the first few words. For example, "the first sentence", "the first three words". - For the "drag" operation, include the initial and destination position of the object. For example, "from the right to left". - "abstract": The abstract description based on the above information, formatted as "operation_category" + "target_object" + "application" + "additional_info"(if needed), you should make it more fluent and readable. # Output format of <Operation Sequence>: - The output should be in JSON format. - The JSON object should contain an array of user operations, each represented as a JSON object containing the extracted information for that operation. - You should avoid redundancy and repetition in the response. - Example output format: { "user_operations": [ { "timestamp": "[1, 3]", "mouse_position": "near the text ’Hello World’", "element_state_pre_interaction": "Application window with text ’Hello World’", "element_state_after_interaction": "Application window with the text ’Hello World’ selected", "thoughts": "The mouse is near the ’hello world’ and the background the text changed", "operation_category": "select", "target_object": { "category": "text field", "identifier": "Main Text Area" }, "application": { "category": "Microsoft Word", "identifier": "" }, "additional_info": "Hello World", "abstract": "User selected ’Hello World’ in the Main Text Area in Microsoft Word" } ] } CONTINUE ON THE NEXT PAGE |
🔼 This table provides the prompt for the action proposer module in the Direct Frame-Based Approach (DF) method. It details the instructions given to the Vision-Language Model (VLM) for identifying user actions from desktop video recordings, including a detailed explanation of how to recognize different operation types (click, select, drag, scroll, type), how to handle the identification and description of UI elements, and the expected JSON output format.
read the caption
TABLE X: Prompt of action proposer of DF method: 3/3
🔼 This table details the prompt used for the Action Corrector module within the Direct Frame-Based Approach (DF) method. The prompt provides guidelines for identifying and correcting errors in the proposed action sequences generated by the Action Proposer. It outlines steps for checking for redundant actions, ensuring the reasonableness of actions, and verifying the completeness of action details. The prompt is structured to guide the correction process systematically, addressing various potential issues in the initially proposed action sequences.
read the caption
TABLE XI: Prompt of corrector of DF method
🔼 This table details the prompt given to the Action Merger module within the Direct Frame-Based Approach (DF) method. It outlines the guidelines for merging action sequences from overlapping sliding windows. This involves identifying and combining redundant or fragmented actions based on criteria such as temporal proximity and overlapping UI elements. The prompt aims to ensure that the final action sequence is accurate and coherent, effectively addressing challenges arising from the sliding window technique used in processing video frames.
read the caption
TABLE XII: Prompt of merger of DF method
| global_description | description | changed | old_cursor_shape | new_cursor_shape | changes | |
|---|---|---|---|---|---|---|
| The whole screenshot mainly contains an open Excel window, with a worksheet displayed. | The region contains an open Excel window, with a worksheet displayed. | true | null | null | [{“subject”: “window”, “type”: “appear”, “old”: “the region is part of the desktop background”, “new”: “the region contains an open Excel window”, “message”: “The Excel window has been opened or moved to the region, or changed from minimized to opened state”}] |
🔼 This table presents the prompt given to the Frame Difference Descriptor module, a component of the Differential Frame-Based Approach. The prompt instructs the model to analyze pairs of images representing a UI region before and after a potential change, identifying and describing the nature of any alterations (appearance, disappearance, movement, style changes, etc.). It requests a JSON output that includes a global description of the entire screenshot, a description of the change region, details on whether changes occurred, the cursor’s shape before and after the change, and a list of changes each containing the subject that changed, type of change, previous state, new state, and explanatory message. This detailed prompt ensures that the model can effectively extract fine-grained information about UI changes from desktop recordings.
read the caption
TABLE XIII: Prompt of Frame Difference Descriptor : 1/2
| Example Output | global_description | description | changed | old_cursor_shape | new_cursor_shape | changes |
|---|---|---|---|---|---|---|
| 2 | The whole screenshot mainly contains a Word document, with a paragraph of text displayed. | The region contains part of the blank area of the document. | true | null | normal | [{ “subject”: “cursor”, “type”: “move”, “old”: “the cursor is at the left of the region”, “new”: “the cursor is at the right of the region”, “message”: “The cursor has been moved from left to right”}] |
| 3 | The whole screenshot mainly contains a desktop with a few icons displayed. | The region contains part of the desktop background without any icons. | true | I-beam | null | [{ “subject”: “cursor”, “type”: “disappear”, “old”: “the cursor is present in the region”, “new”: “the cursor is absent in the region”, “message”: “The cursor has been hidden or moved out of the region”}] |
| 4 | The whole screenshot mainly contains a browser window, with a search bar displayed. | The region contains a search bar with the text ‘hello world’ displayed. | true | I-beam | null | [{ “subject”: “text”, “type”: “text_content_change”, “old”: “the text in the visible area is ‘hello’”, “new”: “the text in the visible area is ‘hello world’”, “message”: “More text has been added to the input field”}] |
| 5 | The whole screenshot mainly contains a text editor window, with some text displayed. | The region contains a line of text in yellow. | true | null | null | [{ “subject”: “text”, “type”: “style_change”, “old”: “the text in the region is black”, “new”: “the text in the region is yellow”, “message”: “the text color has changed”}] |
| 6 | false | [] |
🔼 This table provides example outputs of the Frame Difference Descriptor module, which is part of the Differential Frame-Based Approach method. Each example shows the module’s output for a different scenario, including the global description of the screenshot, a description of the changed region, whether changes occurred, the cursor shapes before and after the change, and the details of detected UI changes.
read the caption
TABLE XIV: Prompt of Frame Difference Descriptor : 2/2 (continued)
| Operation | Description | Identification |
|---|---|---|
| click | The user clicks on an interface element, activating the element and triggering events. If you think user’s operation is “click”, you need to keep observing several frames to see if the operation is “drag” or “select”, which contains the “click” operation. | By the change of mouse: shape change. By the change of interface element: press effective. By the change of display: feedback message. |
| select | Text selection: The user selects text in a document, highlighting the selected text with a different background color. Icon selection: The user selects icons on a desktop or in an application, the selected icons should be enclosed within a blue rectangular box. Cell selection: The user selects cells in a spreadsheet or table, highlighting the selected cells with a different background color. | By the change of mouse: Text selection - mouse position. Icon selection - mouse position. By the change of interface element: color change. |
🔼 This table presents the prompt used for the Action Proposer module in the Direct Frame-Based Approach method. It details the instructions given to the Vision-Language Model (VLM) to identify and describe user actions from video frames. The prompt includes guidelines on how to identify various actions like click, select, scroll, drag, and type, along with specific instructions on formatting the output for each action.
read the caption
TABLE XV: Prompt of Action Proposer : 1/3
🔼 This table provides the prompt for the action proposer module in the Direct Frame-Based Approach (DF) method. It details instructions for identifying user actions from video frames, focusing on five operation types: click, drag, scroll, select, and type. The prompt guides the agent through steps to identify these actions, paying close attention to UI changes and mouse behavior. It includes descriptions for each action type, guidelines for differentiating between actions, and an explanation of the required output format. The prompt explicitly defines the JSON format expected for the extracted action sequence and includes several examples to illustrate various aspects of the expected output.
read the caption
TABLE XVI: Prompt of Action Proposer : 2/3 (continued)
| app | element | action | region | evidences |
|---|---|---|---|---|
| “Microsoft Excel” | “cell A1” | “click” | “1_0” | [[“1_0”, “cursor is in this region, and a bounding box appears around cell A1”], [“1_1”, “The row A is highlighted”], [“1_2”, “The column 1 is highlighted”], [“1_3”, “The cell reference changed to A1”]] |
| “Microsoft Excel” | “cell A2” | “type” | “3_1” | [[“3_1”, “cursor is in this region, and text in it changed”], [“3_2”, “text in this region changed”]] |
| “Microsoft Word” | “main text area” | “type” | “5_1” | [[“5_1”, “text changed from ‘Hello’ to ‘Hello, World!’”]] |
🔼 This table presents the third part of the prompt for the Action Proposer module in the Direct Frame-Based Approach. It provides detailed instructions and examples for identifying user actions such as click, select, scroll, drag, and type from desktop recording videos. This comprehensive prompt guides the Vision-Language Model (VLM) on how to interpret various UI changes and mouse/keyboard operations to extract accurate action sequences.
read the caption
TABLE XVII: Prompt of Action Proposer : 3/3 (continued)
| Task | Description | Instructions |
|---|---|---|
| <TASK 1> | correct “action” field | Revise the “action” field. Correct actions that are not one of the five types [’click’, ’type’, ’scroll’, ’select’, ’drag’]. Pick one of the above 5 verbs that best describes the action. Don’t duplicate actions. Keep actions without error intact. First, write down your thoughts. Then, generate a JSON object with the “action” field corrected and all correct actions intact. |
| <TASK 2> | correct “app” field | Revise the “app” field. Avoid vague terms like “Windows.” Use format of “ |
| <TASK 3> | correct “element” field for “select” actions | Revise the “element” field for “select” action triples only. If text is selected, the “element” field should contain the selected text in single quotes, instead of the UI element. Leave correct values and other fields intact. If no correction is needed, output the previous JSON object exactly as it is. |
| <TASK 4> | correct “element” field for “scroll” actions | Instructions not provided in the document. |
| <TASK 5> | correct “element” field for “type” actions | Instructions not provided in the document. |
| <TASK 6> | correct “element” field for “drag” actions | Instructions not provided in the document. |
| <TASK 7> | correct the “click” actions by analyzing their “evidences” | Instructions not provided in the document. |
| <TASK 8> | merge actions | Instructions not provided in the document. |
🔼 This table presents the first part of the detailed instructions for the Action Corrector module in the proposed methodology. The Action Corrector is designed to refine the user action sequences extracted from the desktop recordings by identifying and correcting potential errors or redundancies. The table outlines a series of tasks to be performed sequentially, each focused on a specific aspect of error correction: verifying action types, checking application names, verifying the descriptions of selected items, correcting descriptions of scroll actions, descriptions of typing actions, and descriptions of drag actions. The prompts guide the correction process through several stages of refinement.
read the caption
TABLE XVIII: Prompt of Action Corrector : 1/4
| Task | Description |
|---|---|
| <TASK 4>: correct “element” field for “scroll” actions | Now you have to revise the “element” field of the action triples you just wrote. Consider the “scroll” action triples only, leaving all other actions intact. For each scroll action in a web browser tab, output “element” as “<vertical/horizontal> scroll bar of |
| <TASK 5>: correct “element” field for “type” actions | Now you have to revise the “element” field of the action triples you just wrote. Consider the “type” action triples only, leaving all other actions intact. The typed content might be either text or other content: If text was typed: the “element” field should contain the typed text in single quotes (WITHOUT extra explanatory words like “text”), instead of the UI element like “textbox”; Make sure to summarize the complete typed text, by reviewing the “region” and “evidences” events that support the “type” action; It may happen that the text you found from the UI events are still incomplete due to missing keyframes, so you should also take a look of the regions AFTER the “region” and “evidences” events (region ids are in form of “_ |
| <TASK 6>: correct “element” field for “drag” actions | Now you have to revise the “element” field of the action triples you just wrote. Consider the “drag” action triples only, leaving all other actions intact. The typed content might be either text or other content: CONTINUE ON THE NEXT PAGE |
| } |
🔼 This table displays the prompt used in the Action Corrector module, a key component of the proposed method for extracting user actions from desktop recordings. The prompt guides a post-processing agent to refine user action sequences by addressing errors or redundancies, with specific instructions provided for correcting fields like ‘action’, ‘app’, and ’element’ for different action types (click, type, scroll, select, drag). The prompt is broken down into a series of tasks, each with detailed guidelines, ensuring correctness and logical consistency in the output. The structure of the prompt facilitates a step-by-step refinement process, increasing the accuracy of the extracted action sequences.
read the caption
TABLE XIX: Prompt of Action Corrector : 2/4 (continued)
🔼 Table XX provides the continuation of instructions for the Action Corrector task within the methodology section of the paper. This part focuses on correcting the ’element’ field for drag actions, handling multiple drag events and ensuring accuracy. It details steps to validate if the app allows multiple item dragging and to identify the actual items dragged, emphasizing the need to consider only items moving consistently with the cursor and in a parallel manner. It includes instructions for handling incomplete information by reviewing supporting events, and lastly, instructions for merging actions of the same type.
read the caption
TABLE XX: Prompt of Action Corrector : 3/4 (continued)
| Step | Description |
|---|---|
| 1 | Write down what is expected to happen if the click action was actually performed and walk through ALL UI events after the frame where the click supposedly happened (not only the evidences of the action) to check if the expected UI change actually happened. For example: Clicking on a taskbar icon should open the corresponding app window, or display it if already open. Clicking on a dropdown menu should open the dropdown menu, or close it if it was already open. |
| 2 | Distinguish between “click” and “hover”: Some style changes happen on “hover”, and UI events would have been different than if it was a “click”. For example, most slight text/background color change would likely be caused by “hover”. |
| 3 | Indicator of “hover”: the cursor moved over the element and then quickly moved out. After moving out, the element’s looking changes back to the original state (the looking before cursor coming acrossing the element). Make sure to check a few frames before and after the evidence of this action to see if it’s the case. |
| 4 | After the above steps, write down the updated list of evidences for this action, taking your above thoughts into account. Keep the evidences that support the “click” action, and remove the evidences that indicate a “hover” action or another action type or no action at all. |
| 5 | After your thinking, output the complete and valid JSON object of actions with each of “click” action corrected and all other actions intact. For each “click” action, if the new “evidences” list is non-empty, then keep the action item with updated “evidences” and all other fields unchanged. If the new “evidences” list is empty, then remove the action item from the list of actions. |
| 6 | merge actions: Now you have to revise the actions of type “type”, “select”, “drag”, “click” you just wrote to see any of the same type actions are mergeable, leaving all the other actions intact. |
| 7 | Identify all groups of actions that should have been merged, output one single merged action where: “action” is the common action type of the actions being merged; “element” is a summary of “element” fields of all actions being merged, which contains all information of each individual “element”. If “element” is in form of a set (e.g. set of icons, text as set of characters), use the “element” of the latest action (latest means greatest frame id); “app” is the common app shared by all actions being merged; “evidences” is the union of “evidences” fields of all actions being merged; “region” is the region of the latest action (latest means greatest frame id); all other fields are the same as the latest action (latest means greatest frame id). |
| 8 | Indicators of actions of same type: The actions happen in same app (necessary but not sufficient condition); The actions have overlapping evidences or evidences that interleave or are close in time (in terms of id; evidences close in time must differ at most by 2 in frame id); For “type” actions, earlier action “element” (in terms of frame id) is a prefix of later action “element”, since text is typed in a sequence; For “select” actions, earlier action “element” (in terms of frame id) is a subset OR superset of later action “element”, since more or less text/items are selected during these frames. |
| 9 | Remember to leave the correct actions intact in your output JSON object. If no merging is needed, simply output your previous JSON object EXACTLY as it is, so that the downstream system can notice that no correction is made. |
| 10 | To complete your task, first write down your step-by-step thoughts on how to merge the actions. For each of the groups of actions that should have been merged, based on the above indicators of actions of same type, your thoughts must include the following steps: Find all groups of actions that should have been merged, based on the above indicators of actions of same type; make sure their action type is the same and one of “type”, “select”, “drag”, “click”. Otherwise they should not be merged; make sure they are in same app, otherwise they should not be merged; If the action type to merge is “type”: is earlier action “element” (in terms of frame id) a prefix of immediate later action “element”?; If the action type to merge is “select”: is earlier action “element” (in terms of frame id) a subset OR superset of immediate later action “element”?; Does this group of actions needs further correction by removing some actions and/or adding more actions? Make sure to go back to the supporting UI change events (find them by ids indicated in “evidences” and “region” fields) of each action under consideration to see if it’s to be added or removed from the group; Avoid “over-merging”: do not merge actions into one while they actually represent more than one action. Check the supporting UI events of each action in the group to see if they are one or more actions in reality; If the group leads to an “over-merging” the number of true actions is still less than the number of actions in the group, then remember to reason in the same step-by-setp fashion later on each of these subgroups, each corresponding to a true action; write down a conclusion: is this group indeed to merge? |
| 11 | After your thinking, output the complete and valid JSON object of actions with each of identified group merged, and all other action intact. |
🔼 This table presents the fourth and final part of the prompt given to the Action Corrector, a post-processing module in the proposed method. It details instructions for merging actions of the same type (’type’, ‘select’, ‘drag’, ‘click’) that should have been grouped together in the initial action sequence. The guidelines emphasize identifying groups of actions with overlapping or interleaved evidences (indicating close temporal proximity) and matching action types. Additional criteria are provided for handling ’type’ and ‘select’ actions based on the order of operation and content. The output should be a valid JSON object with merged actions and the original structure maintained for the unchanged actions.
read the caption
TABLE XXI: Prompt of Action Corrector : 4/4 (continued)
Full paper#