↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many French language models suffer from temporal concept drift, where outdated training data reduces their accuracy when dealing with new information. This is a serious problem because it limits their usefulness in real-world applications. This paper addresses this by introducing CamemBERTav2 and CamemBERTv2, two updated versions of a popular French language model.
The new models are trained on a much larger and more recent dataset, and they use an improved tokenizer that handles modern French better. The results show that the new models significantly outperform their predecessors on various NLP tasks and even work well on specialized tasks such as those in the medical field. The authors have made their models publicly available to support further research.
Key Takeaways#
Why does it matter?#
This paper is crucial because temporal concept drift significantly impacts the performance of language models. The proposed updated CamemBERT models offer a solution to this widespread issue, improving French NLP performance across various tasks. This work also highlights the need for continuous model updates and better data management in NLP research, opening avenues for new methodologies and benchmark improvements.
Visual Insights#
| Model | F1 | EM |
|---|---|---|
| CamemBERT | 80.98 ± 0.48 | 62.51 ± 0.54 |
| CamemBERTa | 81.15 ± 0.38 | 62.01 ± 0.45 |
| CamemBERTv2 | 80.39 ± 0.36 | 61.35 ± 0.39 |
| CamemBERTav2 | 83.04 ± 0.19 | 64.29 ± 0.31 |
🔼 This table presents the results of experiments evaluating Part-of-Speech (POS) tagging, dependency parsing, and Named Entity Recognition (NER) performance on four different French datasets (GSD, RHAPSODIE, SEQUOIA, FSMB, FTB-NER). For each task and dataset, the table shows the UPOS (Universal Part-of-Speech) tagging accuracy and the Labelled Attachment Score (LAS) for dependency parsing. For NER, the F1 score is reported. The table compares the performance of four different models: CamemBERT, CamemBERTa, CamemBERTv2, and CamemBERTav2, highlighting the improvements achieved by the updated versions.
read the caption
Table 1: POS tagging, dependency parsing and NER results on the test sets of our French datasets. UPOS (Universal Part-of-Speech) refers here to POS tagging accuracy, and LAS measures the overall accuracy of labeled dependencies in a parsed sentence.
In-depth insights#
French NLP Evolves#
The evolution of French NLP is marked by a transition from models like CamemBERT, which, while impactful, suffered from temporal concept drift, to newer, more robust versions like CamemBERTv2 and CamemBERTav2. These updates address the limitations of outdated training data by utilizing significantly larger and more recent datasets. The shift also reflects architectural improvements, with CamemBERTav2 adopting the DeBERTaV3 architecture and its RTD objective for enhanced contextual understanding, while CamemBERTv2 leverages RoBERTa and its MLM objective. The inclusion of an enhanced tokenizer better captures the nuances of modern French, handling emojis, newlines, and other evolving linguistic elements. The impressive results across diverse NLP tasks, including both general-domain and domain-specific applications like medical fields, showcase the success of this evolution. The versatility of these upgraded models underscores their broad applicability and highlights the importance of continuous adaptation in NLP to maintain relevance and accuracy in a constantly changing linguistic landscape.
Temporal Concept Drift#
The concept of “Temporal Concept Drift” is crucial in evaluating the long-term performance and relevance of language models. The core issue is that training data becomes outdated over time, leading to a decline in the model’s ability to handle newer concepts, terminology, and contextual nuances. This is especially problematic with models trained on data from a specific time period, such as CamemBERT’s 2019 training data. The emergence of events like COVID-19 highlighted this weakness, as these models struggled with language use changes and related concepts absent in their training set. Addressing this requires continuous model updates, using larger, more recent datasets that reflect current linguistic trends. Regular updates are essential to maintain accuracy and relevance in real-world applications where language and context are constantly evolving. Simply put, the longer a model goes without retraining, the greater the potential for temporal concept drift to negatively impact its performance.
DeBERTa & RoBERTa#
The choice between DeBERTa and RoBERTa for CamemBERT 2.0 reflects a key architectural decision impacting performance and efficiency. DeBERTa’s RTD objective, focusing on enhanced contextual understanding through replaced token detection, offers superior performance but potentially at a higher computational cost. RoBERTa’s MLM approach, using masked language modeling, provides a more established and computationally efficient alternative. The selection of DeBERTa for CamemBERTav2 and RoBERTa for CamemBERTv2 showcases a strategic approach—exploring both advanced techniques and a computationally efficient baseline. Ultimately, the evaluation’s comparative analysis demonstrates the advantages of both architectures, especially when considering factors beyond pure accuracy such as cost-effectiveness and computational resources. The superior performance of CamemBERTav2, despite higher computational demands, highlights DeBERTa’s potential for advanced applications while CamemBERTv2’s efficiency offers a practical alternative for resource-constrained environments. This careful selection underscores a comprehensive strategy for developing and deploying multilingual language models. The results show that carefully chosen architecture combined with a larger, higher-quality dataset, leads to significant improvements in model performance across various NLP tasks.
Tokenization Enhancements#
The improved tokenization in CamemBERT 2.0 models represents a significant enhancement over previous versions. The updated tokenizer addresses limitations by including newline and tab characters, as well as support for emojis, which are normalized by removing zero-width joiner characters and splitting emoji sequences. This addresses the shortcomings of the previous tokenizer. Furthermore, the handling of numerical data is improved by splitting numbers into at most two-digit tokens which should improve processing of dates and allow for simpler arithmetic tasks. Finally, the inclusion of French and English elisions as single tokens streamlines the tokenization process. These enhancements contribute to improved tokenization performance, better capturing the complexities of the French language and leading to more accurate results on downstream NLP tasks. The changes improve efficiency and accuracy, benefiting several downstream tasks including text classification, POS tagging, and NER.
Future Directions#
Future research should prioritize expanding the pre-training dataset with continuously updated corpora to mitigate temporal concept drift. Addressing the limitations of current benchmarks by creating more dynamic evaluation sets that reflect evolving language is crucial. Exploring innovative architectures beyond the current transformer models could unlock significant performance gains. Further investigation into domain adaptation techniques that allow efficient fine-tuning for specialized NLP tasks while preserving generalizability is needed. Finally, research into multilingual models which can seamlessly handle multiple languages, while mitigating the risk of bias and incorporating cultural nuances, is highly important to further advance NLP in the French language and beyond.
More visual insights#
More on tables
| Model | CLS | PAWS-X | XNLI |
|---|---|---|---|
| CamemBERT | 94.62 ± 0.04 | 91.36 ± 0.38 | 81.95 ± 0.51 |
| CamemBERTa | 94.92 ± 0.13 | 91.67 ± 0.17 | 82.00 ± 0.17 |
| CamemBERTv2 | 95.07 ± 0.11 | 92.00 ± 0.24 | 81.75 ± 0.62 |
| CamemBERTav2 | 95.63 ± 0.16 | 93.06 ± 0.45 | 84.82 ± 0.54 |
🔼 This table presents the results of the Question Answering task, evaluated using the FQuAD 1.0 dataset. It shows the F1 score (harmonic mean of precision and recall) and the Exact Match (EM) score (the percentage of questions where the model’s answer exactly matches the ground truth answer) for each of the four different language models being compared: CamemBERT, CamemBERTa, CamemBERTv2, and CamemBERTav2.
read the caption
Table 2: Question Answering results on FQuAD 1.0.
| Model | Medical-NER | Counter-NER |
|---|---|---|
| CamemBERT | 70.96 ± 0.13 | 84.18 ± 1.23 |
| CamemBERTa | 71.86 ± 0.11 | 87.37 ± 0.73 |
| CamemBERT-bio | 73.96 ± 0.12 | - |
| CamemBERTv2 | 72.77 ± 0.11 | 87.46 ± 0.62 |
| CamemBERTav2 | 73.98 ± 0.11 | 89.53 ± 0.73 |
🔼 This table presents the accuracy scores achieved by four different French language models (CamemBERT, CamemBERTa, CamemBERTv2, and CamemBERTav2) on three text classification tasks within the FLUE benchmark: CLS (sentence classification), PAWS-X (paraphrase detection), and XNLI (natural language inference). It allows comparison of model performance across various tasks to highlight the relative strengths and weaknesses of each model.
read the caption
Table 3: Text classification results (Accuracy) on the FLUE benchmark.
| Dataset | Model | F1 |
|---|---|---|
| CAS1 | CamemBERT | 70.72 ± 1.47 |
| CamemBERTa | 71.96 ± 1.38 | |
| Dr-BERT | 62.76 ± 1.55 | |
| CamemBERT-Bio | 72.28 ± 1.46 | |
| CamemBERTv2 | 71.18 ± 1.62 | |
| CamemBERTav2 | 72.87 ± 2.29 | |
| CAS2 | CamemBERT | 78.43 ± 1.78 |
| CamemBERTa | 79.06 ± 0.68 | |
| Dr-BERT | 76.43 ± 0.49 | |
| CamemBERT-Bio | 82.50 ± 0.56 | |
| CamemBERTv2 | 81.87 ± 0.58 | |
| CamemBERTav2 | 81.85 ± 0.49 | |
| E3C | CamemBERT | 67.01 ± 2.13 |
| CamemBERTa | 67.01 ± 1.85 | |
| Dr-BERT | 56.99 ± 2.40 | |
| CamemBERT-Bio | 69.87 ± 1.21 | |
| CamemBERTv2 | 69.27 ± 0.90 | |
| CamemBERTav2 | 70.12 ± 0.87 | |
| EMEA | CamemBERT | 73.53 ± 2.04 |
| CamemBERTa | 75.99 ± 0.51 | |
| Dr-BERT | 71.33 ± 0.84 | |
| CamemBERT-Bio | 76.96 ± 2.00 | |
| CamemBERTv2 | 76.30 ± 1.00 | |
| CamemBERTav2 | 77.28 ± 0.57 | |
| MEDLINE | CamemBERT | 65.11 ± 0.56 |
| CamemBERTa | 65.33 ± 0.30 | |
| Dr-BERT | 58.90 ± 0.51 | |
| CamemBERT-Bio | 68.21 ± 0.91 | |
| CamemBERTv2 | 65.26 ± 0.33 | |
| CamemBERTav2 | 67.77 ± 0.44 | |
| Counter-NER | CamemBERT | 84.18 ± 1.23 |
| CamemBERTa | 87.37 ± 0.73 | |
| CamemBERTv2 | 87.46 ± 0.62 | |
| CamemBERTav2 | 89.53 ± 0.73 |
🔼 This table summarizes the F1 scores achieved by various CamemBERT models on several Named Entity Recognition (NER) tasks within specific domains. It presents a concise overview of the performance, showing how the updated CamemBERT models (CamemBERTv2 and CamemBERTav2) compare to previous versions and a specialized biomedical NER model (CamemBERT-bio) across different datasets. The full detailed results with individual scores for each task and model are provided in Table 5.
read the caption
Table 4: Summary of NER F1 scores on the domain-specific downstream tasks. Full scores are available in Table 5.
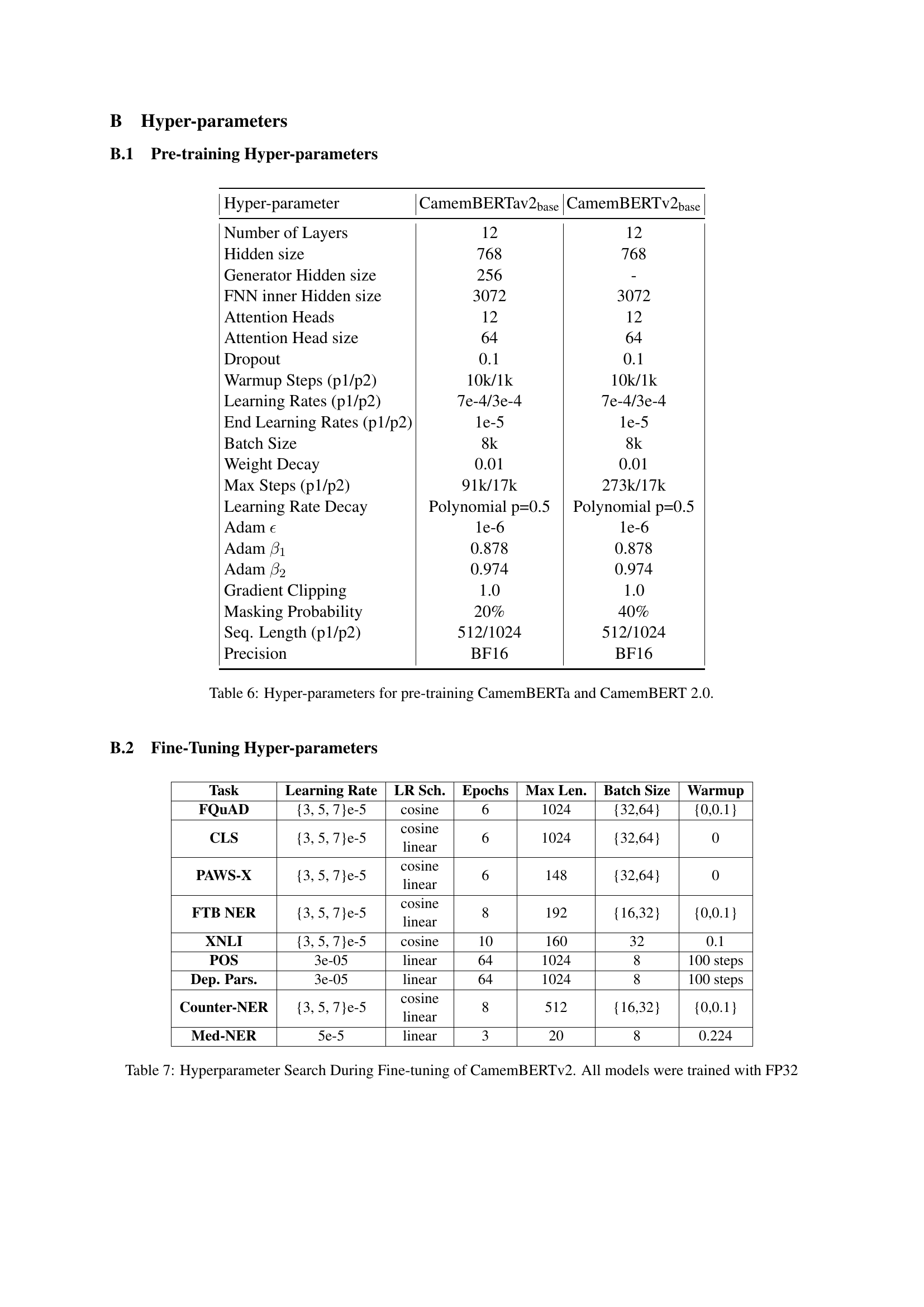
| Hyper-parameter | CamemBERTav2base | CamemBERTv2base |
|---|---|---|
| Number of Layers | 12 | 12 |
| Hidden size | 768 | 768 |
| Generator Hidden size | 256 | - |
| FNN inner Hidden size | 3072 | 3072 |
| Attention Heads | 12 | 12 |
| Attention Head size | 64 | 64 |
| Dropout | 0.1 | 0.1 |
| Warmup Steps (p1/p2) | 10k/1k | 10k/1k |
| Learning Rates (p1/p2) | 7e-4/3e-4 | 7e-4/3e-4 |
| End Learning Rates (p1/p2) | 1e-5 | 1e-5 |
| Batch Size | 8k | 8k |
| Weight Decay | 0.01 | 0.01 |
| Max Steps (p1/p2) | 91k/17k | 273k/17k |
| Learning Rate Decay | Polynomial p=0.5 | Polynomial p=0.5 |
| Adam ϵ | 1e-6 | 1e-6 |
| Adam β1 | 0.878 | 0.878 |
| Adam β2 | 0.974 | 0.974 |
| Gradient Clipping | 1.0 | 1.0 |
| Masking Probability | 20% | 40% |
| Seq. Length (p1/p2) | 512/1024 | 512/1024 |
| Precision | BF16 | BF16 |
🔼 This table presents the NER F1 scores achieved by various models on several domain-specific downstream tasks. These tasks are categorized into different domains like medical (EMEA, MEDLINE, CAS1, CAS2, E3C) and radicalization (Counter-NER). The models compared include CamemBERT, CamemBERTa, DrBERT, CamemBERT-bio, CamemBERTv2, and CamemBERTav2, allowing for a comprehensive analysis of performance across different models and specific domains.
read the caption
Table 5: NER F1 scores on the domain-specific downstream tasks.
| Task | Learning Rate | LR Sch. | Epochs | Max Len. | Batch Size | Warmup |
|---|---|---|---|---|---|---|
| FQuAD | {3, 5, 7}e-5 | cosine | 6 | 1024 | {32,64} | {0,0.1} |
| CLS | {3, 5, 7}e-5 | cosine linear | 6 | 1024 | {32,64} | 0 |
| PAWS-X | {3, 5, 7}e-5 | cosine linear | 6 | 148 | {32,64} | 0 |
| FTB NER | {3, 5, 7}e-5 | cosine linear | 8 | 192 | {16,32} | {0,0.1} |
| XNLI | {3, 5, 7}e-5 | cosine | 10 | 160 | 32 | 0.1 |
| POS | 3e-05 | linear | 64 | 1024 | 8 | 100 steps |
| Dep. Pars. | 3e-05 | linear | 64 | 1024 | 8 | 100 steps |
| Counter-NER | {3, 5, 7}e-5 | cosine linear | 8 | 512 | {16,32} | {0,0.1} |
| Med-NER | 5e-5 | linear | 3 | 20 | 8 | 0.224 |
🔼 This table lists the hyperparameters used during the pre-training phase for both CamemBERTa and the two new CamemBERT 2.0 models (CamemBERTav2 and CamemBERTv2). It details settings for various aspects of the training process, including network architecture (number of layers, hidden size, attention heads), optimization (learning rate, weight decay, Adam parameters), and training data specifics (batch size, sequence length, masking probability). These hyperparameters significantly influence the models’ performance and characteristics.
read the caption
Table 6: Hyper-parameters for pre-training CamemBERTa and CamemBERT 2.0.
| Method |
|---|
| cosine |
| linear |
🔼 This table details the hyperparameters explored during the fine-tuning process for CamemBERTv2 on various downstream tasks. It shows the learning rate schedule, number of epochs, maximum sequence length, batch size, and warmup steps used for each task (FQuAD, CLS, PAWS-X, FTB NER, XNLI, POS, Dependency Parsing, Counter-NER, and Med-NER). All models were trained using FP32 precision.
read the caption
Table 7: Hyperparameter Search During Fine-tuning of CamemBERTv2. All models were trained with FP32
Full paper#