↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for 3D mesh generation often involve complex processes, including separate tokenization for the 3D data and training separate models. This leads to increased computational costs and complexity. The task of unifying language understanding with 3D content creation within LLMs also presents significant challenges, mainly due to the difficulty of directly integrating these distinct modalities into a single model. Prior works often utilize additional components like autoencoders, which adds to the complexity and could introduce information loss.
LLaMA-Mesh overcomes these challenges by representing 3D meshes as plain text (using the OBJ file format), allowing for direct integration with LLMs. This approach avoids modifying the tokenizer or expanding the vocabulary, simplifying the model and improving efficiency. The researchers fine-tuned a pre-trained LLaMA model, demonstrating that LLMs can be successfully fine-tuned to acquire spatial knowledge for 3D mesh generation. The results show that LLaMA-Mesh achieves mesh generation quality comparable to models trained from scratch, all while maintaining strong text generation performance. This approach also allows for unified text and 3D mesh generation within a single model, leading to more intuitive and efficient workflows.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and 3D generation because it presents LLaMA-Mesh, a novel method that directly integrates 3D mesh generation into large language models (LLMs). This approach bridges the gap between text and 3D modalities, opening up new avenues of research in multi-modal AI, 3D content creation, and interactive design tools. The efficiency of the method, achieved by using pre-trained LLMs and a simple text-based representation, significantly impacts future research.
Visual Insights#

🔼 Llama-Mesh is a novel method that allows users to generate 3D meshes through conversational interaction with a language model. The user provides a text prompt describing the desired 3D object. The model then responds by generating both a textual description and the 3D mesh itself, directly in OBJ format. This seamless integration of text and 3D modalities within a single model is a key feature of Llama-Mesh, enabling interactive 3D content creation.
read the caption
Figure 1: An illustration of our method, Llama-Mesh, which enables the generation of 3D meshes from human instructions via a conversational interface. Users provide textual prompts, and the model responds with both text and 3D mesh outputs, facilitating interactive 3D content creation. Llama-Mesh allows large language models to generate and interpret 3D meshes from text directly, seamlessly unifying language and 3D modalities within a single model.
| Dataset | Items | # Turns | Prop. |
|---|---|---|---|
| Mesh Generation† | 125k | 8× | 40% |
| Mesh Understanding† | 125k | 4× | 20% |
| General Conversation [15] | 1M | 1× | 40% |
🔼 This table details the composition of the dataset used to fine-tune the LLAMA-MESH model. It breaks down the dataset into three parts: mesh generation, mesh understanding, and general conversation data. For each part, it provides the number of data items, the number of training turns per item, and the overall proportion of that data type within the whole dataset. The table clarifies that the training is done on a combined dataset where each data type’s contribution is weighted based on these proportions. It also notes that some datasets were specifically constructed for this research.
read the caption
Table 1: Dataset Statistics. We list each dataset’s number of items, number of training turns per item, and the total sample proportions. Training is performed on a combined dataset, with each dataset resampled according to the ratio. We use a mix of mesh generation, mesh understanding, and general conversation data to equip LLMs with 3D capabilities while maintaining their language abilities. Datasets marked with † are those we constructed.
In-depth insights#
LLM-Mesh: Unifying 3D#
LLaMA-Mesh presents a novel approach to unify 3D mesh generation with the capabilities of Large Language Models (LLMs). The core innovation lies in representing 3D mesh data (vertex coordinates and face definitions) as plain text, directly compatible with LLMs. This eliminates the need for complex tokenization methods that would require vocabulary expansion or information loss. The method leverages the spatial knowledge already implicitly embedded within pretrained LLMs, enabling them to generate and interpret 3D meshes through a conversational interface. Fine-tuning a pretrained LLaMA model on a supervised dataset of text-3D pairs and interleaved dialogues allows the model to learn complex spatial relationships, enabling it to generate high-quality 3D meshes from textual descriptions, engage in conversational mesh generation and understanding tasks, and maintain strong text generation performance. This approach offers significant advantages over existing methods that require training from scratch or rely on cumbersome tokenization techniques, leading to a more efficient and effective workflow for 3D content creation driven by natural language.
Mesh as Plain Text#
The concept of representing 3D meshes as plain text offers a groundbreaking approach to unifying 3D mesh generation with large language models (LLMs). Instead of relying on complex tokenization methods that require expanding the LLM’s vocabulary and potentially introducing information loss, this method leverages the OBJ file format. OBJ’s text-based nature allows direct integration with LLMs, bypassing the need for specialized encoders/decoders. This is crucial because it simplifies the process significantly, reduces computational costs, and preserves the spatial knowledge already embedded within pretrained LLMs. The numerical vertex coordinates and face definitions become a sequence of textual data, readily processed by LLMs. The simplicity is further enhanced by quantizing the floating-point coordinates into integers. Although this quantization introduces some loss of precision, it drastically reduces token count, enabling LLMs to handle longer sequences and more intricate mesh details. This text-based representation directly addresses the primary challenge of seamlessly integrating 3D data into LLMs, paving the way for more efficient and effective 3D mesh generation and interaction directly within the LLM framework.
3D-Task Finetuning#
The section on “3D-Task Finetuning” would detail the process of adapting a pre-trained large language model (LLM) to perform 3D mesh generation tasks. This involves creating a specialized dataset of text-3D mesh pairs, likely using the OBJ file format for its text-based nature and direct compatibility with LLMs. The dataset would be curated to enable the LLM to learn the mapping between textual descriptions and the corresponding numerical representations of vertices and faces within the meshes. A crucial aspect would be how the numerical values in the OBJ files are handled; likely they are processed as sequences of tokens by the LLM, instead of requiring a complex image-like tokenization. The fine-tuning process itself would likely involve supervised learning, adjusting the model’s parameters to minimize the discrepancy between its predictions and the actual 3D mesh data. Data augmentation techniques, potentially including geometric transformations or variations in textual descriptions, would likely be employed to enhance the robustness and generalization ability of the fine-tuned model. The effectiveness of this fine-tuning would be evaluated by assessing the model’s ability to generate high-quality 3D meshes from novel textual prompts, while simultaneously maintaining its original language understanding capabilities. A key challenge addressed in this section would be the balance between maintaining the LLM’s pre-existing linguistic skills and successfully adapting it for 3D mesh generation. The results may involve qualitative evaluations (visual assessment of generated meshes) and quantitative metrics (e.g., comparing the quality of generated meshes to those produced by methods trained specifically for 3D generation).
Qualitative Results#
A qualitative analysis of a research paper’s findings on a topic would delve into the nuanced observations and interpretations beyond mere statistics. It would explore the richness of the data to reveal patterns, themes, and underlying meanings that might not be apparent in quantitative summaries. For instance, in the context of 3D mesh generation from text, a qualitative assessment would go beyond metrics like accuracy and focus on the artistic merit and aesthetic qualities of the created meshes. The analysis would involve detailed descriptions of the generated meshes, examining their visual fidelity, level of detail, and overall realism. It would also consider the model’s ability to capture the essence of textual prompts, assessing whether it accurately represents the intended shapes and textures. Furthermore, the comparison of the model’s results with human-created works of similar nature is essential. This qualitative comparison can reveal insights into the model’s strengths and weaknesses in replicating human creativity. Investigating edge cases and failures could provide valuable information on the model’s limitations and potential areas for improvement. Detailed visual examples and comparisons are key to presenting the qualitative findings effectively, demonstrating the model’s capabilities and highlighting its subtle yet impactful aspects. Ultimately, such an analysis aims to reveal a deeper understanding of the generative model’s performance and its alignment with the nuances of human creativity and artistic judgment.
Future Work#
The authors’ suggestions for future work highlight several promising avenues. Improving the efficiency and scalability of the model is paramount; exploring alternative 3D data encoding methods beyond quantization to retain finer geometric details would significantly enhance the model’s capabilities. Expanding the context length of the LLM is also crucial, enabling generation of more intricate and complex 3D structures. Furthermore, incorporating other modalities like textures and physical properties will lead to more realistic and rich 3D outputs. The mention of integrating the model into interactive design tools unlocks significant potential for practical applications, facilitating intuitive 3D content creation. Finally, addressing the observed slight degradation in language capabilities after fine-tuning warrants investigation, perhaps through the use of more diverse and high-quality datasets. This multifaceted approach to future work demonstrates a clear understanding of the model’s current limitations and the potential for broader impact.
More visual insights#
More on figures

🔼 LLaMA-Mesh processes both text and 3D mesh data in a unified manner. Instead of using separate encodings, it represents the numerical vertex coordinates and face definitions of a 3D mesh as plain text. This allows for seamless integration with large language models (LLMs). The model is trained end-to-end on interleaved text and 3D mesh data, enabling it to generate both text and 3D mesh outputs from a single model. The figure visually depicts this process.
read the caption
Figure 2: Overview of our method. Llama-Mesh unifies text and 3D mesh in a uniform format by representing the numerical values of vertex coordinates and face definitions of a 3D mesh as plain text. Our model is trained using text and 3D interleaved data end-to-end. Therefore, with a single, unified model, we can generate both text and 3D meshes.

🔼 This figure showcases a variety of 3D models generated by the LLaMA-Mesh model. The models demonstrate the model’s ability to produce high-quality, diverse meshes with complex, artistic-style topologies, highlighting its advanced capabilities in 3D mesh generation. The examples illustrate the range of shapes and forms that the model can create, showcasing its versatility.
read the caption
Figure 3: Gallery of generations from Llama-Mesh. We can generate high-quality and diverse meshes with artist-like created topology.

🔼 This figure illustrates how the authors represent 3D mesh data as plain text for processing by large language models (LLMs). The left panel shows a snippet of an OBJ file (a common text-based 3D model format) which contains vertex coordinates (v) and face definitions (f). The numerical values are treated as text sequences. The right panel displays the 3D object that is rendered from this textual representation of the OBJ file. This demonstrates how the method converts mesh data into a format that LLMs can directly process, eliminating the need for complex tokenization schemes or vocabulary expansion.
read the caption
Figure 4: Illustration of our 3D representation approach. Left: A snippet of an OBJ file represented as plain text, containing vertex (v) and face (f) definitions. Right: The 3D object rendered from the OBJ file. We enable the LLM to process and generate 3D meshes by converting the mesh data into a textual format.

🔼 This figure illustrates the vertex quantization method used to improve the efficiency of processing 3D mesh data with LLMs. The top panel shows how vertex coordinates are originally represented as floating-point numbers in the OBJ file format, leading to long token sequences that are inefficient for LLMs. The bottom panel demonstrates that after quantization, the coordinates are represented as integers using fewer tokens, enabling more efficient processing by the LLM.
read the caption
Figure 5: Illustration of our vertex quantization method. Top: The original OBJ file represents vertex coordinates in decimal values, splitting a single coordinate into several tokens. Bottom: After quantization, we represent the vertices as integers containing fewer tokens and are processed by LLM more efficiently.

🔼 This figure demonstrates the zero-shot mesh generation capabilities of different pretrained LLMs. The left panel shows the output from ChatGPT 40, and the right panel shows the output from LLaMA 3.1 8B-Instruct. Both models were prompted to generate a 3D mesh in OBJ format without any prior fine-tuning on 3D data. While the LLMs can generate simple 3D objects, the results highlight limitations in terms of mesh quality and complexity, demonstrating the need for fine-tuning to achieve high-quality 3D mesh generation. The ellipsis (…) indicates that parts of the generated OBJ files have been omitted for brevity.
read the caption
Figure 6: Illustration of mesh generation capability from an LLM without finetuning. Left: results from ChatGPT-4o. Right: results from LLaMA 3.1 8B-Instruct. Pretrained LLMs can generate simple 3D objects in text format; however, mesh quality and complexity are often unsatisfactory. OBJ files from the internet may vary slightly in format. The […] indicates omitted text.

🔼 Figure 7 showcases Llama-Mesh’s expanded capabilities beyond the original LLaMA model. It demonstrates the model’s ability to perform novel tasks such as 3D mesh generation and understanding, in addition to maintaining its proficiency in tasks like text generation and mathematical problem-solving. Examples show interactive dialogues where users describe 3D objects, request mesh creation, ask for explanations of provided meshes, and even inquire about building a wooden house. The examples highlight the model’s capacity to seamlessly integrate 3D processing with its existing language and reasoning capabilities.
read the caption
Figure 7: More dialog results. Llama-Mesh achieves several new tasks, including mesh generation and understanding, while completing other tasks like the original LLM. […]: we omit some text to make the snippet fit into the page.

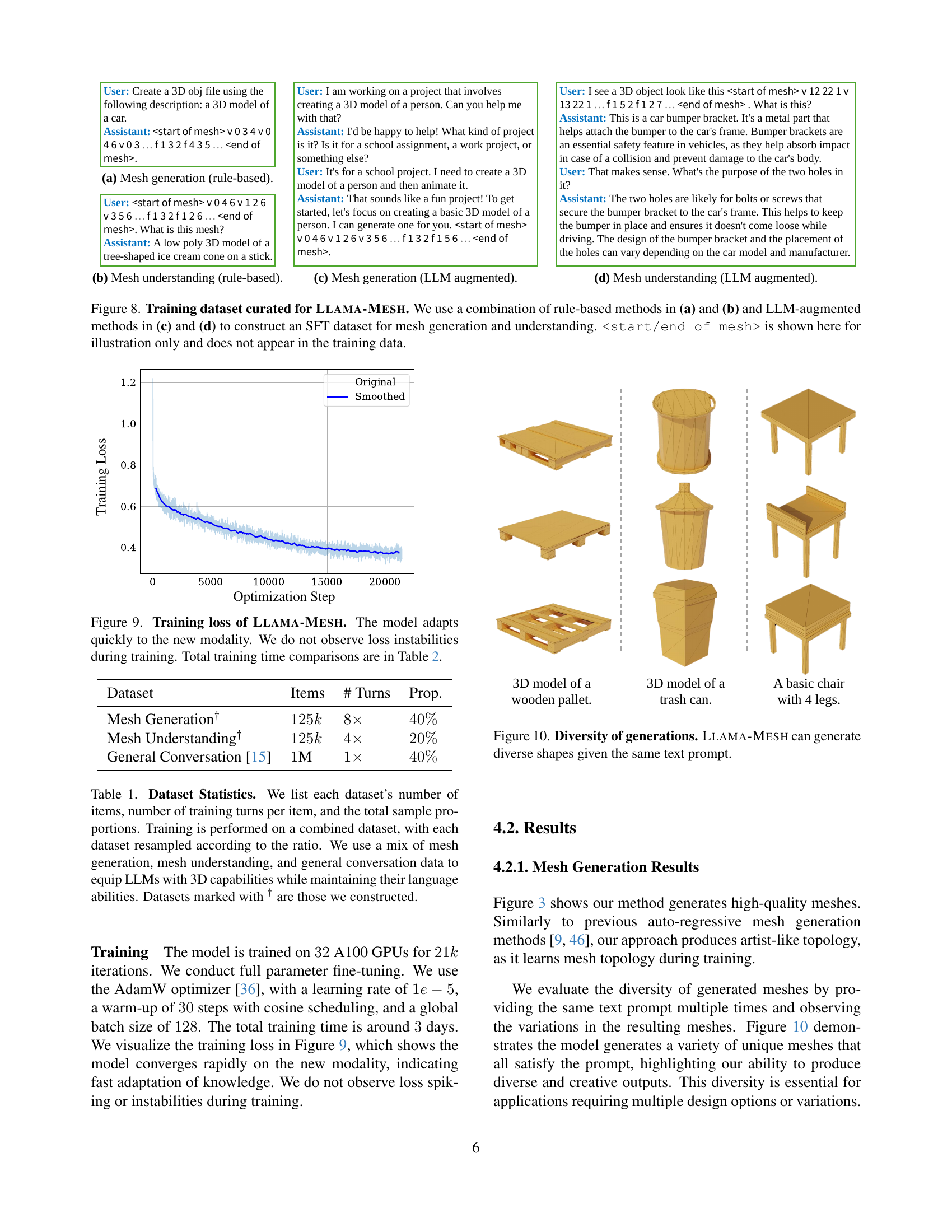
🔼 Figure 8 illustrates the dataset used to fine-tune the Llama-Mesh model. The dataset combines rule-based and LLM-augmented approaches to generate a supervised fine-tuning (SFT) dataset for both mesh generation and mesh understanding tasks. Rule-based methods are shown in (a) and (b), while LLM-augmented methods are in (c) and (d). Note that the ‘
’ and ‘ ’ tags are for illustrative purposes only and are not part of the actual training data. read the caption
Figure 8: Training dataset curated for Llama-Mesh. We use a combination of rule-based methods in (a) and (b) and LLM-augmented methods in (c) and (d) to construct an SFT dataset for mesh generation and understanding.is shown here for illustration only and does not appear in the training data.

🔼 The plot shows the training loss curve for the LLAMA-Mesh model. The rapid decrease in loss indicates that the model quickly learned to generate 3D meshes, adapting effectively to this new modality. Notably, there are no significant fluctuations or instabilities in the loss, suggesting a stable and consistent training process. Table 2 provides a quantitative comparison of the total training time taken by the model, compared to other approaches.
read the caption
Figure 9: Training loss of Llama-Mesh. The model adapts quickly to the new modality. We do not observe loss instabilities during training. Total training time comparisons are in Table 2.
More on tables
| Method | MeshXL [7] | MeshXL [7] | Llama-Mesh |
|---|---|---|---|
| Model Size | 350M | 1.3B | 8B |
| GPU hours | 6000 | 23232 | 2400 |
🔼 This table compares the training time and computational resources used by Llama-Mesh and MeshXL, highlighting Llama-Mesh’s efficiency despite having a larger model size. This efficiency is attributed to Llama-Mesh leveraging pre-trained large language model weights, significantly reducing the training time compared to MeshXL which trained from scratch.
read the caption
Table 2: Training time comparison. Compared to MeshXL [7], Llama-Mesh uses far fewer GPU hours despite its larger model size, benefiting from using pretrained LLM weights.
| Metric | LLaMA3.1 (8B) | Llama-Mesh (8B) | LLaMA3.2 (3B) | LLaMA3.2 (1B) |
|---|---|---|---|---|
| MMLU (5-shot) | 66.07 | 61.74 | 59.44 | 44.17 |
| PIQA (0-shot) | 81.01 | 79.16 | 75.52 | 74.10 |
| Hellaswag (0-shot) | 79.19 | 77.35 | 70.47 | 60.80 |
| GSM8K (8-shot) | 77.18 | 62.09 | 66.94 | 34.27 |
🔼 This table compares the performance of Llama-Mesh (8B) with several baseline LLMs of different sizes on various language understanding benchmarks. These benchmarks (MMLU, PIQA, HellaSwag, GSM8K) test general knowledge, common sense reasoning, and mathematical problem-solving skills. The results show that Llama-Mesh, despite being fine-tuned for 3D mesh generation, maintains comparable language understanding and reasoning abilities to the baseline models.
read the caption
Table 3: Does Llama-Mesh preserve language capabilities? We report the performance of Llama-Mesh (8B) and compare it with base models of different sizes: LLaMA3.1 (8B), LLaMA3.2 (3B), and LLaMA3.2 (1B). The metrics include MMLU (5-shot), PIQA (0-shot), HellaSwag (0-shot), and GSM8K (8-shot), which assess the model’s general knowledge, commonsense reasoning, and mathematical problem-solving abilities. Takeaway: Our method (in the blue column), after being fine-tuned to generate OBJ files, maintains language understanding and reasoning capabilities comparable to the base model while extending its functionality to 3D mesh generation.
Full paper#