↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current digital image editing tools often lack intuitive interfaces and struggle with precise, nuanced modifications. Users frequently face challenges in articulating their desired edits accurately, requiring repeated prompt adjustments or relying on complex techniques that demand significant expertise. This leads to an inefficient and often frustrating editing experience, especially for non-experts.
MagicQuill tackles this challenge with a novel approach that combines user-friendly brushstroke interactions with a powerful multimodal large language model (MLLM). The system uses three types of brushstrokes—add, subtract, and color—to allow for flexible and precise modifications. The MLLM dynamically anticipates user intent from these brushstrokes and generates appropriate prompts, streamlining the process. Through extensive evaluations, the paper demonstrates that MagicQuill significantly improves both the accuracy and efficiency of image editing compared to existing methods, offering a more intuitive and effective solution for users of all skill levels.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MagicQuill, a novel and user-friendly interactive image editing system. It addresses the limitations of existing systems by combining intuitive brushstroke-based interactions with a multimodal large language model (MLLM) for real-time intent prediction. This work offers a significant advancement in image editing, potentially impacting various fields and opening new avenues for research in user-centered AI.
Visual Insights#

🔼 MagicQuill is an intelligent interactive image editing system that uses diffusion models. Users can easily edit images using three brush types: add, subtract, and color. The system employs a large multimodal language model (MLLM) that understands the user’s brushstrokes and suggests relevant text prompts, improving efficiency. The figure shows examples demonstrating the system’s capabilities: generating a jacket from a clothing outline (B1), adding a flower crown from a sketch (B2), removing a background (B3), and changing hair and flower colors (B4).
read the caption
Figure 1: MagicQuill is an intelligent and interactive image editing system built upon diffusion models. Users seamlessly edit images using three intuitive brushstrokes: add, subtract, and color (A). A MLLM dynamically predicts user intentions from their brush strokes and suggests contextual prompts (B1-B4). The examples demonstrate diverse editing operations: to generate a jacket from clothing contour (B1), add a flower crown from head sketches (B2), remove background (B3), and apply color changes to the hair and flowers(B4).
In-depth insights#
Interactive Image Edit#
Interactive image editing, as a research area, is rapidly evolving, driven by the demand for intuitive and efficient tools. The core challenge lies in bridging the gap between user intent and precise image manipulation. Current approaches often rely on text prompts, which can be cumbersome and lack the nuanced control necessary for complex edits. The integration of multimodal large language models (MLLMs) shows significant promise, enabling systems to understand user actions (like brushstrokes) and translate them into effective image modifications. However, robustness and accuracy remain key hurdles. These systems must handle varied user skill levels and diverse editing tasks while maintaining fidelity and efficiency. Fine-grained control over specific image regions is crucial, requiring advanced mechanisms beyond basic tools. Therefore, future research should focus on improving MLLM interpretation of ambiguous user input, developing more robust and versatile interfaces, and enhancing control over both structural and color aspects of image edits.
Brushstroke Control#
The concept of “Brushstroke Control” in an intelligent interactive image editing system is crucial for achieving intuitive and precise modifications. It centers on how user interactions, specifically brushstrokes, are translated into meaningful edits within the digital image. This involves several key aspects: First, the system needs a robust mechanism to accurately capture and interpret the brushstrokes’ characteristics, such as position, pressure, size, and color. Second, sophisticated algorithms are required to translate these characteristics into actionable commands that can modify the image’s content, structure, and style. Third, a powerful generative model is necessary to execute these edits accurately and efficiently, ideally without introducing unwanted artifacts or distortions. Finally, seamless integration between the brushstroke input and the generative model is critical to ensure a smooth and responsive editing experience. Successful brushstroke control enables precise control over the level of detail, allowing for nuanced changes without the need for complex textual prompts or manual adjustments.
MLLM-based Prompting#
MLLM-based prompting represents a significant advancement in image editing, moving beyond the limitations of traditional, keyword-based prompting. By leveraging the contextual understanding and generation capabilities of large language models, MLLMs can dynamically create and refine prompts based on user interactions and image content. This eliminates the tedious and often ineffective process of manually crafting precise prompts. The real-time prediction of user intent, through analysis of brushstrokes or other input methods, makes the editing process significantly more efficient and intuitive. However, challenges remain in ensuring accurate prompt generation, especially when dealing with ambiguous user input, and in controlling for potential biases present in the underlying MLLM. Future research should focus on improving the robustness and accuracy of MLLM-based prompt prediction, mitigating potential biases, and exploring the integration of user feedback mechanisms for enhanced interactive control. Furthermore, efficient fine-tuning strategies for specific image editing tasks and broader investigation into the impact of different MLLM architectures on performance are essential.
System Evaluation#
A robust system evaluation is crucial for assessing the effectiveness of an intelligent interactive image editing system. It should go beyond simple qualitative observations and incorporate rigorous quantitative analysis using established metrics. This would involve comparing the system’s performance against existing methods across multiple dimensions. Specifically, the evaluation needs to address the precision and efficiency of the edits performed, focusing on metrics like edge alignment, color fidelity, and overall editing time. Furthermore, a user study with diverse participants is necessary to assess aspects like usability, intuitiveness, and overall satisfaction. The user study should collect both qualitative feedback and quantitative data through metrics such as task completion times, error rates, and user ratings. By combining both quantitative and qualitative data, a comprehensive understanding of the system’s strengths and limitations can be achieved. Addressing edge cases and failure scenarios during evaluation is also critical to identify potential areas for improvement and highlight the system’s robustness. Finally, the analysis should draw clear conclusions about the system’s overall performance and its contribution to the field of image editing.
Future Enhancements#
The section on “Future Enhancements” in a research paper on an intelligent interactive image editing system would ideally explore several key areas. Expanding editing capabilities beyond the current functionalities is crucial. This could involve incorporating advanced features such as reference-based editing, allowing users to guide image modifications using external reference images; and layered image generation, providing a more nuanced and flexible workflow. Improving the model’s understanding of user intent is also vital. Addressing the ambiguity inherent in brushstroke-based interactions is key, possibly through the development of more robust methods for interpreting user sketches or integrating alternative input modalities. Enhancing efficiency and scalability is another important area for future development. This might involve optimizing the speed of prompt generation and image processing for a more responsive user experience, and optimizing the model for deployment on various platforms, including mobile and embedded systems. Finally, the integration of additional features such as typography support for manipulating text within images and improving overall robustness and error handling would greatly benefit the system.
More visual insights#
More on figures

🔼 MagicQuill’s system architecture integrates three core modules: an Editing Processor for high-quality, controllable image editing using dual-branch inpainting; a Painting Assistor that predicts user intent in real-time using a multimodal large language model (MLLM), eliminating the need for manual prompt entry; and an Idea Collector, providing an intuitive interface with versatile brush tools for seamless user interaction. This integrated approach enables intuitive and precise image editing via brushstrokes.
read the caption
Figure 2: System framework consisting of three integrated components: an Editing Processor with dual-branch architecture for controllable image inpainting, a Painting Assistor for real-time intent prediction, and an Idea Collector offering versatile brush tools. This design enables intuitive and precise image editing through brushstroke-based interactions.

🔼 This figure illustrates the data processing pipeline of the MagicQuill image editing system. The system begins with a raw input image. First, a Convolutional Neural Network (CNN) extracts edge information, creating an edge map. Simultaneously, the image undergoes downscaling to simplify its color information, creating color blocks. Then, based on the user’s brushstrokes (add, subtract, color), three key editing conditions are generated: 1) an editing mask highlighting the region to be modified, 2) an edge condition reflecting adjustments to the edge map based on the user’s intentions (adding or subtracting elements), and 3) a color condition indicating color changes within the selected area. These three conditions are combined to precisely guide the image inpainting process in the subsequent stages.
read the caption
Figure 3: Data processing pipeline. The input image undergoes edge extraction via CNN and color simplification through downscaling. Three editing conditions are then generated based on brush signals: editing mask, edge condition, and color condition, which together provide control for image editing.

🔼 The Editing Processor in MagicQuill enhances the latent diffusion UNet by incorporating two specialized branches. The inpainting branch refines per-pixel inpainting using content-aware guidance, while the control branch provides structural guidance for accurate edits. This dual-branch architecture enables precise brush-based image editing, ensuring high fidelity in both content and structure.
read the caption
Figure 4: Overview of our Editing Processor. The proposed architecture extends the latent diffusion UNet with two specialized branches: an inpainting branch for content-aware per-pixel inpainting guidance and a control branch for structural guidance, enabling precise brush-based image editing.

🔼 This figure shows an example of dataset construction for the Draw&Guess task within the Painting Assistor module. (a) displays the original image from the DCI dataset. (b) shows the edge map generated from the image using PiDiNet. (c) highlights the selected masks (in purple) from the image which have the highest edge density, the number is top 5. (d) shows the result of inpainting these masks using BrushNet with an empty prompt. (e) overlays the edge maps from (b) onto the inpainted masks from (d), simulating user brushstrokes that would be inputted to the model.
read the caption
a Original Image

🔼 This image shows edge maps generated from the original images in the DCI dataset. Edge maps highlight the boundaries and outlines of objects and regions within an image, providing a representation of the image’s structural information. These maps are useful for various computer vision tasks, including image segmentation and object recognition. They are particularly important in the context of this paper, as they serve as input to the system for guiding precise image editing operations.
read the caption
b Edge Map

🔼 This figure shows the process of selecting masks from the DCI dataset for use in training the Painting Assistor. Specifically, it displays (c) Chosen Masks from images, which are chosen based on edge density. These chosen masks represent the ground truth labels for the Draw&Guess task. The process begins with the original image (a) and the edge map (b).
read the caption
c Chosen Mask

🔼 This figure shows the inpainting result after applying the BrushNet model to augmented masked regions. The initial step involved selecting masks with the highest edge density from the DCI dataset and then generating edge maps. Following this, inpainting was performed on these masked regions using the BrushNet model. The final result displays the edge map overlaid onto the inpainted areas, simulating a user’s hand-drawn stroke on the image.
read the caption
d Inpainting Result

🔼 This figure demonstrates the dataset construction process for the Draw&Guess task in the Painting Assistor. (a) shows original images from the DCI dataset. (b) displays edge maps extracted from these images using PiDiNet. (c) highlights the top 5 masks with the highest edge density, selected as ground truths for the Q&A task. (d) shows the inpainting results from BrushNet on the augmented masks with empty prompts. (e) overlays edge maps onto the inpainted results, simulating real-world brush stroke editing scenarios. This process generates training data for the MLLM to understand and predict user editing intent.
read the caption
e Edge Overlay

🔼 This figure details the dataset creation process for training the Painting Assistor model. Starting with original images from the DCI dataset (a), edge maps are extracted (b). High-density edge regions are identified and masked (c). BrushNet inpainting is then applied to these masked areas (d), and finally, the original edge maps are overlaid to simulate user brush strokes (e), creating a dataset that mirrors real user interactions.
read the caption
Figure 5: Illustration of dataset construction process. (a) Original images from the DCI dataset; (b) Edge maps extracted from original images; (c) Selected masks (highlighted in purple) with highest edge density; (d) Results after BrushNet inpainting on augmented masked regions; (e) Final results with edge map overlay on selected areas. By overlaying edge maps on inpainted results, we simulate scenarios where users edit images with brush strokes, as the edge maps resemble hand-drawn sketches. The bounding box coordinates of the mask and labels are inherited from the DCI dataset.

🔼 Figure 6 compares the image editing results of different methods using edge and color conditions as input. SmartEdit, using natural language instructions, lacks precision, affecting areas outside the intended edit. SketchEdit, a GAN-based approach, struggles with open-domain image generation, and BrushNet, while proficient at inpainting, doesn’t precisely align edges and colors even with ControlNet. In contrast, the proposed Editing Processor adheres strictly to both edge and color conditions, resulting in high-fidelity edits.
read the caption
Figure 6: Visual result comparison. The first two columns present the edge and color conditions for editing, while the last column shows the ground truth image that the models aim to recreate. SmartEdit [20] utilizes natural language for guidance, but lacks precision in controlling shape and color, often affecting non-target regions. SketchEdit [64], a GAN-based approach [15], struggles with open-domain image generation, falling short compared to models with diffusion-based generative priors. Although BrushNet [23] delivers seamless image inpainting, it struggles to align edges and colors simultaneously, even with ControlNet [66] enhancement. In contrast, our Editing Processor strictly adheres to both edge and color conditions, achieving high-fidelity conditional image editing.

🔼 This figure presents the results of a user study evaluating the Painting Assistor module. Participants rated the module’s prediction accuracy (how well it guesses the user’s intent from their brushstrokes) and efficiency enhancement (how much it speeds up the editing process). The ratings are displayed as a bar chart, showing the percentage of participants who gave each rating (1-5, 1 being very poor and 5 being excellent). The chart visualizes user satisfaction with the Painting Assistor’s performance in terms of both accuracy and efficiency.
read the caption
Figure 7: User ratings for the Painting Assistor, focusing on its prediction accuracy and efficiency enhancement capabilities.

🔼 This bar chart displays the results of a user study comparing MagicQuill to a baseline system across four key aspects of user experience: Complexity and Efficiency, Consistency and Integration, Ease of Use, and Overall Satisfaction. Each aspect is rated on a scale, and error bars represent the standard deviation of user ratings, indicating the variability in responses for each system. The chart visually demonstrates MagicQuill’s superiority across all four aspects.
read the caption
Figure 8: Comparative user ratings between our system and the baseline in four dimensions, with standard deviation shown as error bars.

🔼 Figure 9 shows how MagicQuill is integrated into ComfyUI as a custom node, enhancing its functionality and providing a seamless user experience. The illustration highlights the customizable widgets for parameter adjustments and the extensible architecture designed for future platform integrations.
read the caption
Figure 9: MagicQuill as a custom node in ComfyUI.

🔼 The figure shows an example of a user’s input in the form of brush strokes on an image. The brush strokes represent the user’s intent to modify the image; in this specific case, the user appears to be outlining or selecting a portion of the image for editing. This is one step in the interactive image editing process of the MagicQuill system, where users utilize brush strokes to guide the system in modifying the image, rather than relying solely on text prompts.
read the caption
a User’s Input

🔼 This figure demonstrates the impact of edge control strength on image generation quality. When the user’s brush strokes deviate significantly from the intended edit, a higher edge strength (0.6) results in an image that closely follows the strokes but lacks overall harmony. Lowering the edge strength (to 0.2, shown in another part of the figure) improves the balance between adherence to strokes and the overall coherence of the generated image.
read the caption
b Edge Strength: 0.6
🔼 This figure demonstrates the impact of edge control strength on image generation quality when user-provided brush strokes deviate from the intended semantic meaning. It shows that reducing edge control strength from 0.6 (image b) to 0.2 (image c) significantly improves the harmony between the generated image and the user’s semantic intent, addressing the ‘scribble-prompt trade-off’ discussed in the paper. A higher edge strength (0.6) results in an image that rigidly adheres to the sketch, creating disharmony with the textual prompt, whereas a lower edge strength (0.2) balances adherence to the sketch with alignment to the semantic meaning of the prompt.
read the caption
c Edge Strength: 0.2

🔼 This figure illustrates a trade-off encountered when using brush strokes for image editing. The user provides a sketch (a) with the text prompt ‘man’. The model then generates images using two different edge control strengths. (b) shows the result with a stronger edge control (0.6), which adheres closely to the sketch but may not accurately reflect the intended ‘man’ concept. (c) shows a result with weaker edge control (0.2), which may better represent the concept of a man but deviates more from the original sketch. This demonstrates a balance between precise stroke adherence and semantic accuracy.
read the caption
Figure 10: Illustration of the Scribble-Prompt Trade-Off. Given user-provided brush strokes (a) with the text prompt “man”, we show generation results with different edge control strengths: (b) with strength of 0.60.60.60.6 and (c) with strength of 0.20.20.20.2.

🔼 This figure shows an example of dataset construction for the Draw&Guess task. (a) displays the original image from the DCI dataset. (b) shows the edge map generated using PiDiNet from the original image. (c) highlights the selected masks with the highest edge densities, which will be used for prompt generation. (d) shows the results of inpainting using the BrushNet model on the augmented masks. Finally, (e) displays the final dataset example where edge maps are overlaid onto the inpainted results, simulating user hand-drawn editing strokes.
read the caption
a Original Image

🔼 This figure shows the result of using a color brush with an opacity (alpha) value of 1.0. It visually demonstrates the impact of the color brush stroke on the image, specifically highlighting how it alters the color of the target region with complete opacity. It is part of a discussion regarding the trade-off between precise color control and the level of detail preservation in the edited region.
read the caption
b Color brush, α𝛼\alphaitalic_α 1.0

🔼 This figure shows the result of applying a color brush with an opacity (α) of 1.0. The color brush allows users to change the color of specific image regions. An opacity of 1.0 means the new color completely replaces the original color in the designated area. The image demonstrates how effective and precise the color modification is when using the color brush with full opacity.
read the caption
c Result for α𝛼\alphaitalic_α 1.0

🔼 This figure shows the results of using a color brush with an opacity (alpha value) of 0.8. It demonstrates a comparison between using a higher opacity (alpha=1.0, shown in a previous figure) versus a lower opacity (alpha=0.8) in image editing. The lower opacity preserves more of the original image’s structural details while still applying color changes, whereas higher opacity may result in loss of detail.
read the caption
d Color brush, α𝛼\alphaitalic_α 0.8

🔼 This figure shows the result of applying a color brush with an opacity (alpha) value of 0.8. It demonstrates a trade-off between colorization accuracy and detail preservation. Using a lower alpha value (0.8 instead of 1.0) helps retain more of the original image’s structural details during the colorization process because it blends the new color more subtly with the existing colors.
read the caption
e Result for α𝛼\alphaitalic_α 0.8

🔼 This figure demonstrates the trade-off between colorization accuracy and detail preservation when using color brush strokes in image editing. Using a higher alpha value (1.0) leads to more vivid color changes, but it can compromise fine details in the edited area because the method uses downsampled color blocks and CNN-extracted edge maps as input. A lower alpha value (0.8) results in less intense color changes but better preserves the original image’s details.
read the caption
Figure 11: Illustration of the Colorization-Detail Trade-Off. Results of color brush strokes with different alpha values: (b, c) using alpha value 1.01.01.01.0, and (d, e) using alpha value 0.80.80.80.8, where the latter better preserves more structural details of the original image.

🔼 The figure shows an example of user input using the Idea Collector module in the MagicQuill system. The user is interacting with the system via brushstrokes to indicate their desired edits. This input is then used by the system to predict the user’s intentions and generate the corresponding edits on the image. The specific type of brushstroke (add, subtract, or color) would determine the type of edit being suggested. This example highlights the intuitive and interactive nature of the system, allowing users to effortlessly communicate their image editing desires through simple strokes.
read the caption
a User’s Input

🔼 This figure demonstrates an example of ambiguous interpretation by the Painting Assistor component. The user’s sketch, shown in subfigure (a), was intended to represent a raspberry. However, the model incorrectly interpreted the sketch as candy (b), resulting in a generation that does not match the user’s intention. Subfigure (c) shows the expected result if the model correctly identified the sketch as a raspberry. This highlights the limitations of relying solely on brush strokes for interpreting complex visual concepts and the need for further improvements in the model’s ability to resolve ambiguity.
read the caption
b Prompt: Candy

🔼 This figure illustrates an example of ambiguity in the Painting Assistor’s interpretation of user-provided brush strokes. A user intends to indicate a raspberry using a circular sketch (A). However, the Painting Assistor misinterprets the sketch as a candy (B) resulting in a misaligned generation. The correct interpretation and corresponding generation (C) is provided for comparison. This highlights a challenge in the system where simple sketches can be ambiguous, leading to incorrect predictions.
read the caption
c Prompt: Raspberry

🔼 The figure showcases the ambiguity in sketch interpretation that can occur in the Painting Assistor module. A user’s simple sketch, intended to represent a raspberry (A), is misinterpreted by the Draw&Guess model as a candy (B). This misinterpretation leads to an inaccurate generation. The correct generation based on the intended raspberry interpretation is shown in (C), highlighting the model’s limitations in handling ambiguous user inputs.
read the caption
Figure 12: Demonstration of semantic ambiguity in sketch interpretation. (A) User’s sketch intended to represent a raspberry; (B) Our Draw&Guess model incorrectly interprets the sketch as candy, leading to a misaligned generation; (C) The expected generation result with correct raspberry interpretation.

🔼 This figure shows the original image used in the dataset construction process for training the Painting Assistor model. The original image is part of the Densely Captioned Images (DCI) dataset. The image is a starting point; later steps involve generating edge maps, selecting masks, inpainting, and overlaying edges to simulate the appearance of user-drawn brush strokes for training purposes.
read the caption
a Original Image

🔼 This figure shows a user’s input in the form of a sketch. The sketch represents a brush stroke used within the MagicQuill system for image editing. The user’s sketch serves as input to the system to direct the modification of an image. The precise nature of the stroke dictates the specific changes applied to the image, either adding elements, removing sections, or changing color, depending on the type of brush used and the drawn pattern.
read the caption
b User’s Input

🔼 This figure shows the result of an image editing task performed using MagicQuill. The image is of a cake, and the user has used the add and subtract brushes to precisely cut a slice out of the cake. The system’s prediction of the user’s intention is displayed, and the output shows a clean, realistic result.
read the caption
c Editing Result

🔼 Figure 13 demonstrates the versatility of the proposed image editing method by showcasing its consistent performance across various pre-trained Stable Diffusion models. The top row displays results using the RealisticVision model, the middle row uses GhostMix, and the bottom row uses DreamShaper. Each row presents the same editing tasks applied to different images, highlighting that the method successfully applies edits to diverse image styles and maintains a high level of quality regardless of the underlying diffusion model.
read the caption
Figure 13: Demonstration of our method’s generalization capability across different fine-tuned Stable Diffusion models. Results shown using RealisticVision (top row), GhostMix (middle row), and DreamShaper (bottom row) as base models, all achieving consistent editing performance.

🔼 This figure illustrates the Painting Assistor’s ability to interpret user brushstrokes within context. A simple vertical line drawing is shown, but the model interprets this differently depending on its surroundings. Three examples are given: an antenna on a robot, a candle on a cake, and a column on ancient ruins. This demonstrates the model’s ability to understand user intent by considering surrounding visual cues.
read the caption
a Guess: Antenna

🔼 The figure illustrates the ambiguity in brush stroke interpretation that the Painting Assistor model faces. A simple vertical line sketch can be interpreted differently based on its context. The image shows three examples: a vertical line interpreted as an antenna on a robot’s head, a candle on a cake, and a column on ancient ruins. This highlights the challenge of achieving accurate interpretation of user sketches and the necessity for context awareness in the model.
read the caption
b Guess: Candle

🔼 This figure demonstrates the Painting Assistor’s ability to interpret brush strokes within context. A single vertical line is drawn, but the model interprets its meaning differently based on the surrounding image. (a) shows the vertical line interpreted as an antenna on a robot. (b) shows it interpreted as a candle on a cake. (c) shows it interpreted as a column in a scene of ruins. This highlights the model’s ability to incorporate contextual cues into its understanding of user input.
read the caption
c Guess: Column

🔼 This figure demonstrates the Painting Assistor’s ability to interpret the same simple sketch differently depending on its surrounding context. A single vertical line is interpreted as: (a) an antenna on a robot’s head, because of the robot head in the surrounding image; (b) a candle on a birthday cake, because of the cake in the surrounding image; and (c) a column amongst ancient ruins, because of the ruins in the surrounding image. This showcases the model’s ability to leverage contextual information for more accurate interpretation of user intentions.
read the caption
Figure 14: Examples of context-aware editing intention interpretation. The MLLM interprets the same vertical line sketch differently based on surrounding context: (a) as an antenna on a robot’s head, (b) as a candle on a birthday cake, and (c) as a column among ancient ruins.

🔼 Figure 15 shows the baseline system used for comparison in the user study. This baseline system was implemented within the ComfyUI framework, a popular open-source tool for image editing, but without the integrated features of the MagicQuill system being evaluated. This allows for a fair comparison, focusing specifically on the usability improvements provided by MagicQuill’s unique interface and functionalities.
read the caption
Figure 15: The baseline system implemented in ComfyUI.

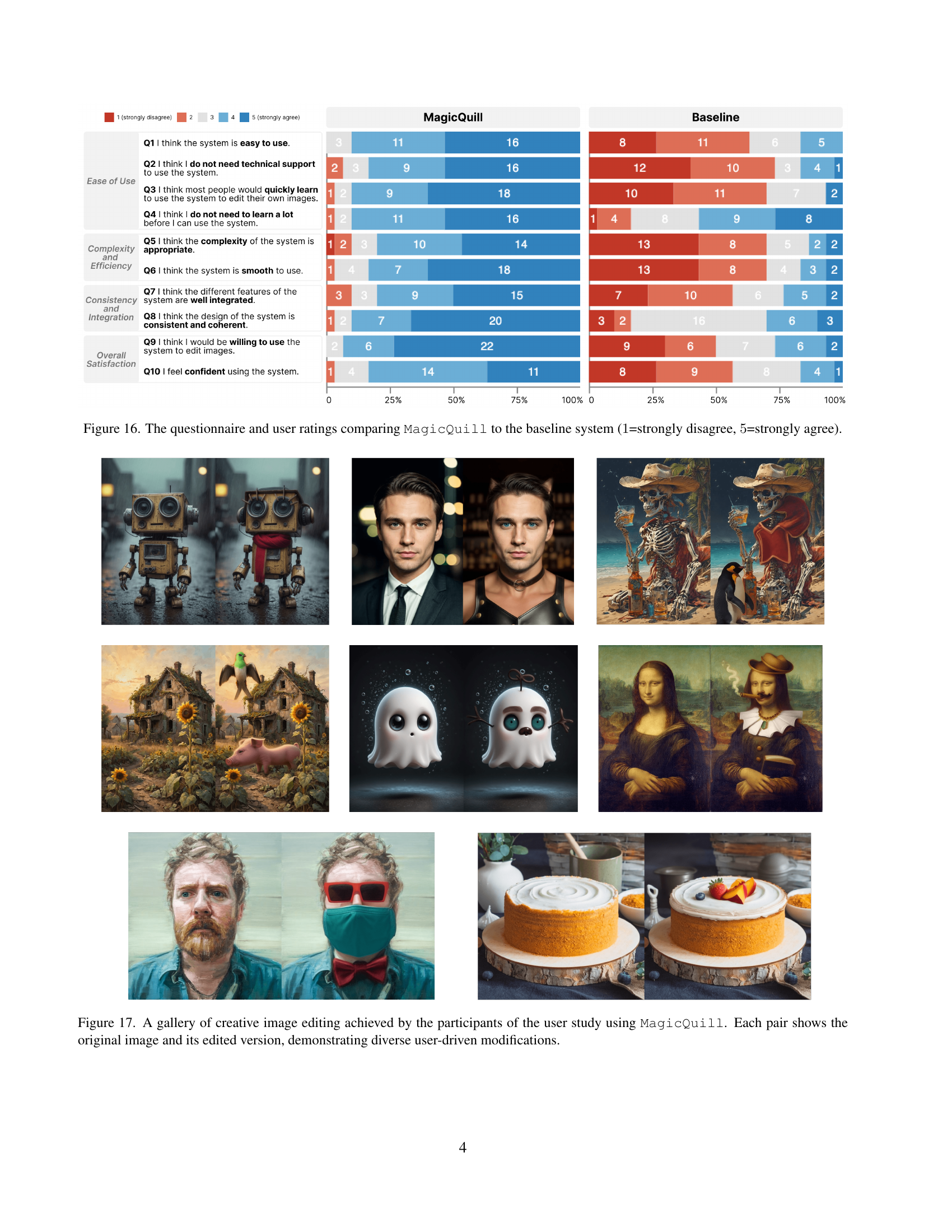
🔼 Figure 16 presents a detailed comparison of user feedback on MagicQuill and a baseline system. Participants rated both systems across four key aspects: ease of use, complexity and efficiency, consistency and integration, and overall satisfaction. Each aspect was assessed using a 5-point Likert scale (1 = strongly disagree to 5 = strongly agree). The figure visually displays the average scores for each aspect and system, providing a clear and concise summary of user preferences.
read the caption
Figure 16: The questionnaire and user ratings comparing MagicQuill to the baseline system (1111=strongly disagree, 5555=strongly agree).

🔼 This figure showcases a selection of images edited by participants in a user study using the MagicQuill system. Each pair of images displays the original image alongside its edited counterpart, highlighting the diverse range of creative modifications achieved through user interaction with the MagicQuill’s intuitive interface and tools. The edits demonstrate the system’s capabilities in tasks such as adding elements, removing objects, altering colors, and making structural changes, showcasing the system’s versatility and effectiveness.
read the caption
Figure 17: A gallery of creative image editing achieved by the participants of the user study using MagicQuill. Each pair shows the original image and its edited version, demonstrating diverse user-driven modifications.
Full paper#