↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current small language models (SLMs) show potential for mobile deployment, but their real-world performance and applications on smartphones remain underexplored. Existing research primarily focuses on developing smaller models without extensive real-device testing, leaving a gap in understanding their practical performance on high-end devices. There’s a need for in-depth studies to bridge this gap.
This paper introduces SlimLM, a series of SLMs optimized for mobile document assistance tasks. The researchers conducted extensive experiments on a Samsung Galaxy S24, identifying optimal trade-offs between model size, context length, and inference time. SlimLM was pre-trained and fine-tuned on a specific dataset. The results show that SlimLM models perform comparably or even better than existing SLMs of similar sizes and an Android application demonstrates real-world applicability.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates the feasibility of deploying advanced language models on mobile devices for document assistance. This addresses the limitations of cloud-based solutions by reducing server costs and enhancing user privacy. The findings provide valuable benchmarks and insights for future research in on-device language model optimization.
Visual Insights#

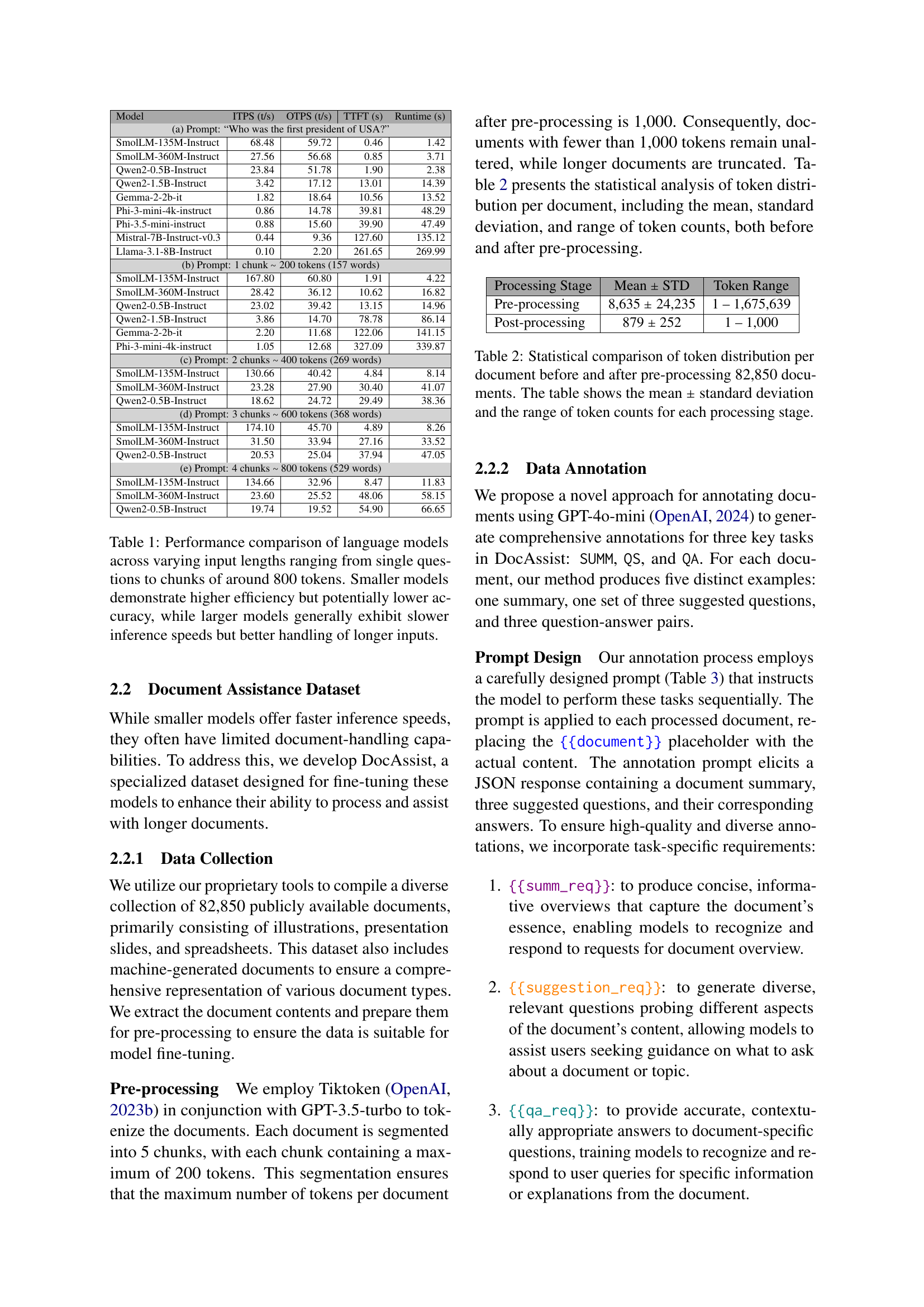
🔼 This figure shows an Android application demonstrating SlimLM’s capabilities for document assistance. The app allows users to load a document (such as a legal contract), receive a generated summary, suggest questions related to the document, and then obtain answers. This all happens on the device itself, without needing an internet connection, reducing server costs and privacy concerns.
read the caption
(a)
| Model | ITPS (t/s) | OTPS (t/s) | TTFT (s) | Runtime (s) |
|---|---|---|---|---|
| (a) Prompt: “Who was the first president of USA?” | ||||
| SmolLM-135M-Instruct | 68.48 | 59.72 | 0.46 | 1.42 |
| SmolLM-360M-Instruct | 27.56 | 56.68 | 0.85 | 3.71 |
| Qwen2-0.5B-Instruct | 23.84 | 51.78 | 1.90 | 2.38 |
| Qwen2-1.5B-Instruct | 3.42 | 17.12 | 13.01 | 14.39 |
| Gemma-2-2b-it | 1.82 | 18.64 | 10.56 | 13.52 |
| Phi-3-mini-4k-instruct | 0.86 | 14.78 | 39.81 | 48.29 |
| Phi-3.5-mini-instruct | 0.88 | 15.60 | 39.90 | 47.49 |
| Mistral-7B-Instruct-v0.3 | 0.44 | 9.36 | 127.60 | 135.12 |
| Llama-3.1-8B-Instruct | 0.10 | 2.20 | 261.65 | 269.99 |
| (b) Prompt: 1 chunk ~ 200 tokens (157 words) | ||||
| SmolLM-135M-Instruct | 167.80 | 60.80 | 1.91 | 4.22 |
| SmolLM-360M-Instruct | 28.42 | 36.12 | 10.62 | 16.82 |
| Qwen2-0.5B-Instruct | 23.02 | 39.42 | 13.15 | 14.96 |
| Qwen2-1.5B-Instruct | 3.86 | 14.70 | 78.78 | 86.14 |
| Gemma-2-2b-it | 2.20 | 11.68 | 122.06 | 141.15 |
| Phi-3-mini-4k-instruct | 1.05 | 12.68 | 327.09 | 339.87 |
| (c) Prompt: 2 chunks ~ 400 tokens (269 words) | ||||
| SmolLM-135M-Instruct | 130.66 | 40.42 | 4.84 | 8.14 |
| SmolLM-360M-Instruct | 23.28 | 27.90 | 30.40 | 41.07 |
| Qwen2-0.5B-Instruct | 18.62 | 24.72 | 29.49 | 38.36 |
| (d) Prompt: 3 chunks ~ 600 tokens (368 words) | ||||
| SmolLM-135M-Instruct | 174.10 | 45.70 | 4.89 | 8.26 |
| SmolLM-360M-Instruct | 31.50 | 33.94 | 27.16 | 33.52 |
| Qwen2-0.5B-Instruct | 20.53 | 25.04 | 37.94 | 47.05 |
| (e) Prompt: 4 chunks ~ 800 tokens (529 words) | ||||
| SmolLM-135M-Instruct | 134.66 | 32.96 | 8.47 | 11.83 |
| SmolLM-360M-Instruct | 23.60 | 25.52 | 48.06 | 58.15 |
| Qwen2-0.5B-Instruct | 19.74 | 19.52 | 54.90 | 66.65 |
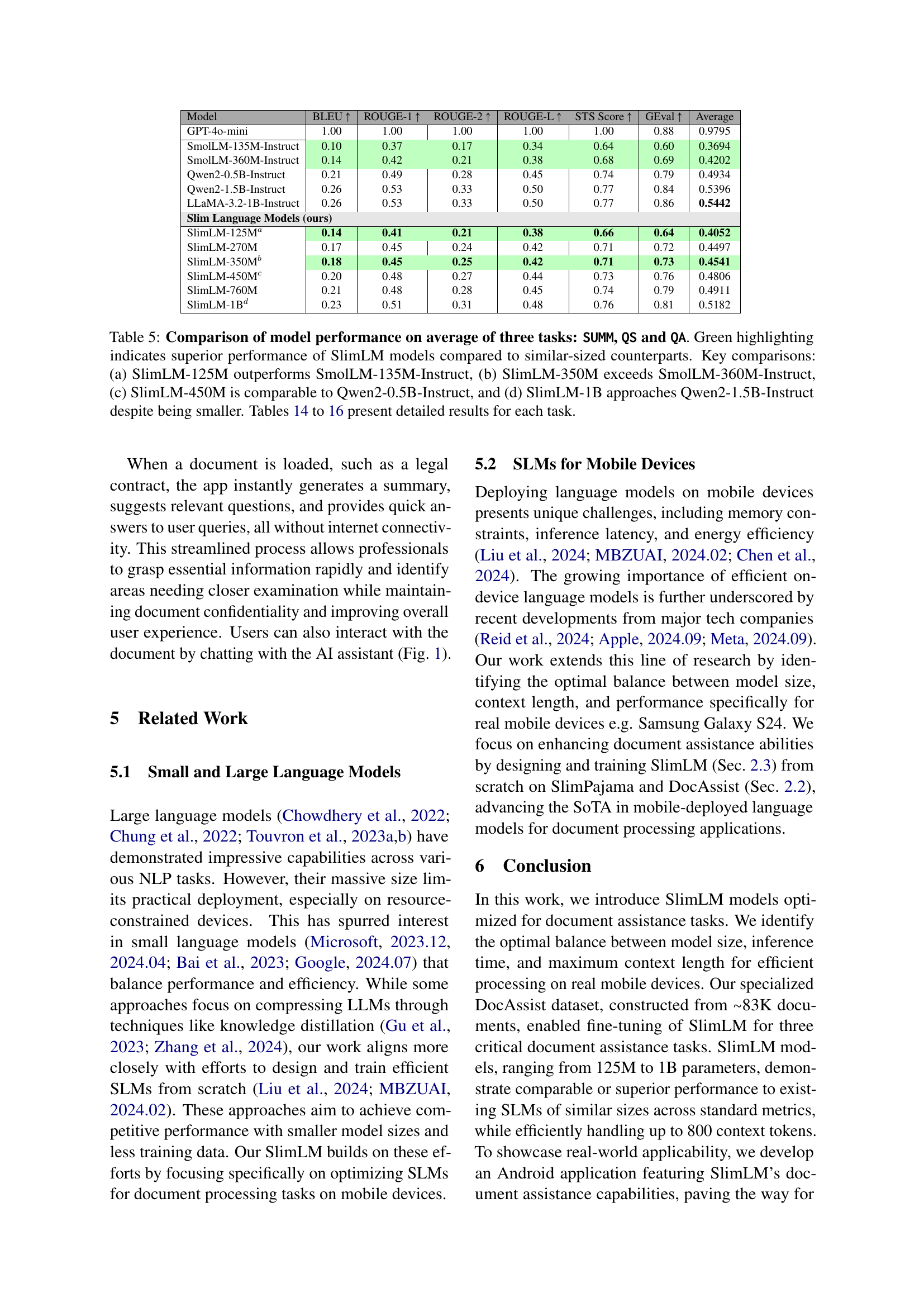
🔼 This table compares the performance of several language models across different input lengths, ranging from short single questions to longer contexts of approximately 800 tokens. The comparison focuses on key metrics reflecting efficiency (tokens per second for input and output, time to first token, total runtime) and, implicitly, accuracy (through the trade-off presented). The results show a clear trend: smaller models process shorter inputs more quickly, but larger models may be better at handling longer inputs, though at the cost of slower processing. This suggests an important trade-off to consider when choosing a model for on-device applications depending on the expected input length and performance requirements.
read the caption
Table 1: Performance comparison of language models across varying input lengths ranging from single questions to chunks of around 800 tokens. Smaller models demonstrate higher efficiency but potentially lower accuracy, while larger models generally exhibit slower inference speeds but better handling of longer inputs.
In-depth insights#
On-Device SLMs#
On-device small language models (SLMs) represent a significant advancement in mobile computing. Reducing reliance on cloud servers offers benefits in terms of cost, latency, and user privacy. However, challenges remain. Optimal model size and context length must be carefully balanced for efficient performance without sacrificing accuracy. The trade-offs between inference speed, memory usage, and model capacity require in-depth analysis. Developing specialized datasets for fine-tuning SLMs on specific mobile tasks, like document assistance, proves crucial for practical application. Successfully deploying SLMs on mobile devices necessitates addressing these tradeoffs and optimizing for the hardware constraints of smartphones.
SlimLM: Design#
A thoughtful exploration of a hypothetical “SlimLM: Design” section in a research paper might delve into the model’s architecture, focusing on its efficiency and suitability for mobile devices. Key design choices would likely involve a compact model size, achieved perhaps through techniques like pruning or quantization, enabling faster inference times and reduced memory consumption. The design would also address context length limitations, a common constraint in mobile applications, discussing strategies to efficiently handle longer inputs without sacrificing performance. Pre-training and fine-tuning strategies would be crucial elements, detailing the datasets employed (possibly encompassing diverse document types for robustness) and the objective functions optimized. The design would likely incorporate mechanisms to ensure robustness and accuracy despite the size constraints, possibly involving architectural innovations or training techniques. Finally, considerations of deployment and integration into mobile platforms might be included, potentially mentioning API designs, resource management techniques, and any novel approaches for on-device processing.
DocAssist Dataset#
The creation of a specialized dataset, DocAssist, is a crucial contribution of this research. The dataset is not simply a collection of documents; it is meticulously curated and annotated for three specific document assistance tasks: summarization, question answering, and question suggestion. This targeted approach allows for a more accurate and relevant evaluation of the SlimLM models’ capabilities. The diversity of the documents included—spanning illustrations, presentations, spreadsheets, and machine-generated content—is essential in ensuring the models’ robustness. The use of GPT-40-mini for annotation is a smart approach, providing a standardized and efficient way to generate high-quality, task-specific data. However, the use of a proprietary tool for document collection and the reliance on GPT-40-mini raise concerns about reproducibility and potential bias. More details on data collection methods and the analysis of potential bias from GPT-40-mini would enhance the paper’s strength. Furthermore, the description of the annotation process itself is brief and lacks detail, leaving room for improvement in terms of transparency and clarity.
Empirical Findings#
An Empirical Findings section in a research paper would present the results of experiments or data analysis, providing strong evidence to support or refute the hypotheses. It would begin by clearly stating the research questions and the methodology used to gather data. Then, it should present the results in a clear and organized way, likely using tables, figures, and statistical analyses. Crucially, the discussion should focus on the significance of the results, highlighting any unexpected findings or limitations of the study. It’s important to connect the empirical findings back to the theoretical framework of the research to show how the results contribute to existing knowledge. A well-written section will clearly show the link between the research questions, the methodology, the results, and their implications, providing a solid foundation for the conclusions drawn in the paper. Finally, the presentation must be objective, avoiding subjective interpretation of data unless specifically discussed in the limitations section.
Mobile App Demo#
A ‘Mobile App Demo’ section in a research paper showcasing a new mobile-optimized language model would ideally demonstrate the model’s real-world usability and performance. It should go beyond simply showing the app’s interface; instead, it should focus on presenting compelling use cases that highlight the model’s capabilities. Concrete examples of document summarization, question answering, and suggestion tasks performed directly on a mobile device are crucial. The demo should also demonstrate the speed and efficiency of the model, comparing it to cloud-based alternatives or other on-device models, ideally with quantifiable results, like inference times and accuracy scores. Addressing potential limitations of the app and the model is also vital – acknowledging memory constraints, processing power limitations, or any accuracy trade-offs compared to larger models. Furthermore, showcasing the app’s potential impact on user experience and privacy, by illustrating the benefits of on-device processing, could significantly strengthen the paper’s impact and overall message. Finally, including user feedback or demonstrating iterative improvement based on user input could be highly effective.
More visual insights#
More on tables
| Processing Stage | Mean ± STD | Token Range |
|---|---|---|
| Pre-processing | 8,635 ± 24,235 | 1 – 1,675,639 |
| Post-processing | 879 ± 252 | 1 – 1,000 |
🔼 This table presents a statistical analysis of token distribution in a dataset of 82,850 documents, comparing the token counts before and after a pre-processing step. The pre-processing likely involved tasks such as tokenization and potentially truncation to a maximum length. The table shows the mean and standard deviation of token counts for both the raw and pre-processed data, along with the range (minimum and maximum) of observed token counts. This allows for an understanding of the effect the pre-processing had on the distribution of document lengths in terms of tokens.
read the caption
Table 2: Statistical comparison of token distribution per document before and after pre-processing 82,850 documents. The table shows the mean ±plus-or-minus\pm± standard deviation and the range of token counts for each processing stage.
| Token Type | Mean ± STD | Token Range |
|---|---|---|
| Prompt Tokens | 2,126.04 ± 260.81 | 1,273 – 2,617 |
| Completion Tokens | 169.07 ± 17.61 | 107 – 312 |
🔼 This table describes the prompt used to generate annotations for the DocAssist dataset. The prompt instructs a language model (specifically GPT-40-mini) to perform three tasks sequentially on a given document: summarization (SUMM), question suggestion (QS), and question answering (QA). The {{document}} placeholder in the prompt is replaced with the actual document text during annotation. For a complete view of the prompt and detailed instructions for each subtask, refer to Tables 9, 10, 11, and 12 in the paper.
read the caption
Table 3: A prompt designed to annotate data for three tasks given a document in DocAssist: SUMM, QS and QA. {{document}} is replaced with each pre-processed document. Please see the complete prompt with in-context examples and requirements for each task {{summ_req}}, {{suggestion_req}} and {{qa_req}} in Tables 12, 9, 10 and 11, respectively.
| Model | BLEU ↑ | ROUGE-1 ↑ | ROUGE-2 ↑ | ROUGE-L ↑ | STS Score ↑ | GEval ↑ | Average |
|---|---|---|---|---|---|---|---|
| GPT-4o-mini | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.88 | 0.9795 |
| SmolLM-135M-Instruct | 0.10 | 0.37 | 0.17 | 0.34 | 0.64 | 0.60 | 0.3694 |
| SmolLM-360M-Instruct | 0.14 | 0.42 | 0.21 | 0.38 | 0.68 | 0.69 | 0.4202 |
| Qwen2-0.5B-Instruct | 0.21 | 0.49 | 0.28 | 0.45 | 0.74 | 0.79 | 0.4934 |
| Qwen2-1.5B-Instruct | 0.26 | 0.53 | 0.33 | 0.50 | 0.77 | 0.84 | 0.5396 |
| LLaMA-3.2-1B-Instruct | 0.26 | 0.53 | 0.33 | 0.50 | 0.77 | 0.86 | 0.5442 |
| Slim Language Models (ours) | |||||||
| SlimLM-125Ma | 0.14 | 0.41 | 0.21 | 0.38 | 0.66 | 0.64 | 0.4052 |
| SlimLM-270M | 0.17 | 0.45 | 0.24 | 0.42 | 0.71 | 0.72 | 0.4497 |
| SlimLM-350Mb | 0.18 | 0.45 | 0.25 | 0.42 | 0.71 | 0.73 | 0.4541 |
| SlimLM-450Mc | 0.20 | 0.48 | 0.27 | 0.44 | 0.73 | 0.76 | 0.4806 |
| SlimLM-760M | 0.21 | 0.48 | 0.28 | 0.45 | 0.74 | 0.79 | 0.4911 |
| SlimLM-1Bd | 0.23 | 0.51 | 0.31 | 0.48 | 0.76 | 0.81 | 0.5182 |
🔼 This table presents a statistical analysis of the token usage by the GPT-40-mini model during the annotation of 82,850 documents for the DocAssist dataset. It shows the average and standard deviation of prompt tokens and completion tokens generated by the model, along with the range of token counts. This data provides insights into the consistency and efficiency of the annotation process.
read the caption
Table 4: Token usage statistics for GPT-4o-mini model in annotating 82,850 documents.
| Model | Accuracy (%) |
|---|---|
| GPT-4o-mini | 100.00 |
| SmolLM-135M-Instruct | 99.86 |
| SmolLM-360M-Instruct | 99.81 |
| Qwen2-0.5B-Instruct | 100.00 |
| Qwen2-1.5B-Instruct | 100.00 |
| SlimLM-125M | 100.00 |
| SlimLM-270M | 100.00 |
| SlimLM-350M | 100.00 |
| SlimLM-450M | 100.00 |
| SlimLM-760M | 99.95 |
| SlimLM-1B | 99.90 |
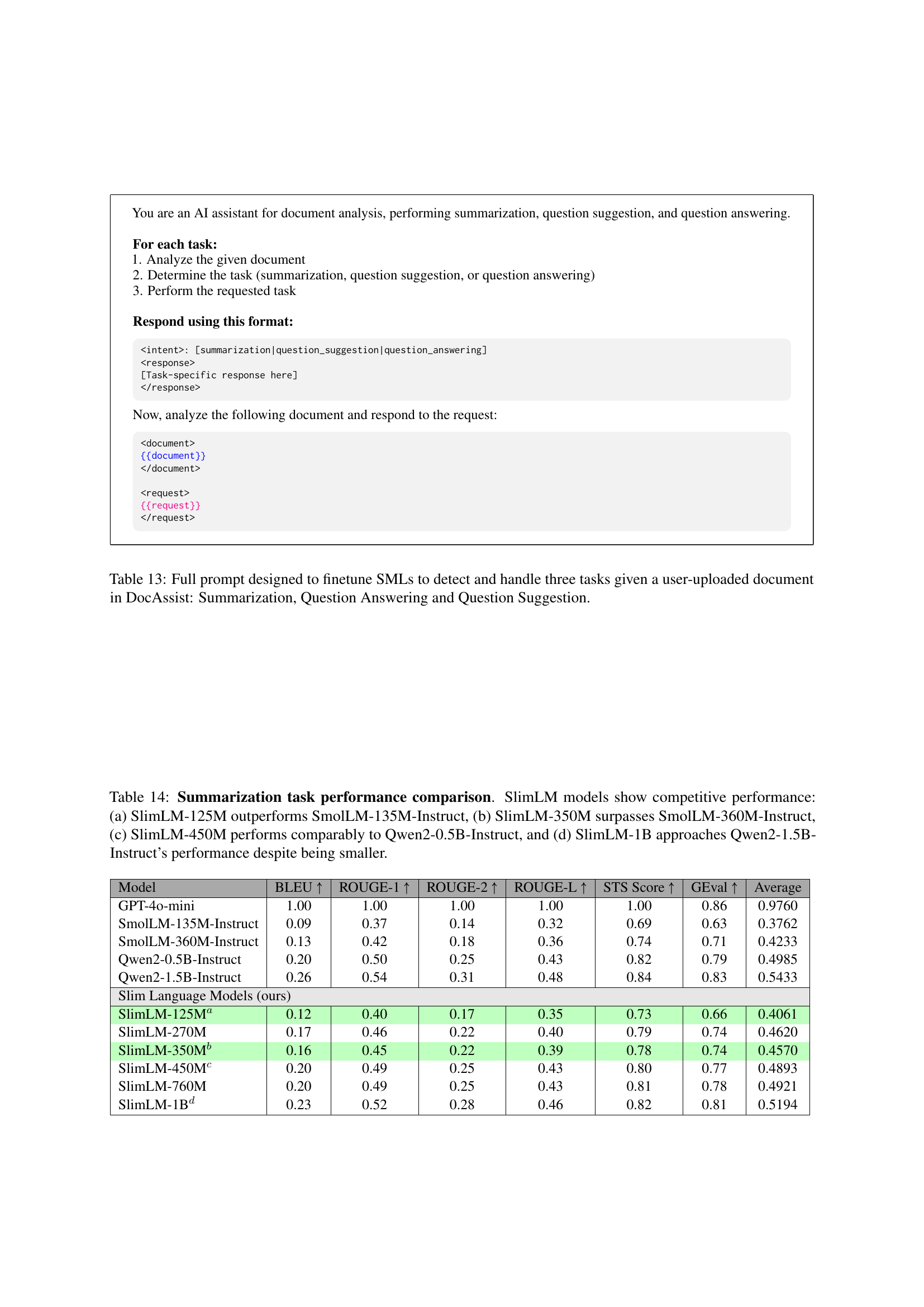
🔼 This table compares the performance of various small language models (SLMs) on three document assistance tasks: summarization (SUMM), question suggestion (QS), and question answering (QA). The models are evaluated using several metrics (BLEU, ROUGE, STS, GEval) to assess the quality and accuracy of their outputs. The table highlights the performance of the SlimLM models (a series of SLMs specifically designed for mobile devices) and compares them to other state-of-the-art SLMs of similar sizes. Green highlighting emphasizes where SlimLM models outperform their counterparts. Key comparisons are explicitly noted, indicating instances where SlimLM models show superior performance (SlimLM-125M > SmolLM-135M-Instruct, SlimLM-350M > SmolLM-360M-Instruct, SlimLM-450M ≈ Qwen2-0.5B-Instruct, SlimLM-1B ≈ Qwen2-1.5B-Instruct), demonstrating their efficiency and effectiveness. More detailed task-specific results can be found in Tables 14, 15, and 16.
read the caption
Table 5: Comparison of model performance on average of three tasks: SUMM, QS and QA. Green highlighting indicates superior performance of SlimLM models compared to similar-sized counterparts. Key comparisons: (a) SlimLM-125M outperforms SmolLM-135M-Instruct, (b) SlimLM-350M exceeds SmolLM-360M-Instruct, (c) SlimLM-450M is comparable to Qwen2-0.5B-Instruct, and (d) SlimLM-1B approaches Qwen2-1.5B-Instruct despite being smaller. Tables 14, 15 and 16 present detailed results for each task.
| Model | BLEU ↑ | ROUGE-1 ↑ | ROUGE-2 ↑ | ROUGE-L ↑ | STS Score ↑ | GEval ↑ | Average |
|---|---|---|---|---|---|---|---|
| GPT-4o-mini | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.86 | 0.9760 |
| SmolLM-135M-Instruct | 0.09 | 0.37 | 0.14 | 0.32 | 0.69 | 0.63 | 0.3762 |
| SmolLM-360M-Instruct | 0.13 | 0.42 | 0.18 | 0.36 | 0.74 | 0.71 | 0.4233 |
| Qwen2-0.5B-Instruct | 0.20 | 0.50 | 0.25 | 0.43 | 0.82 | 0.79 | 0.4985 |
| Qwen2-1.5B-Instruct | 0.26 | 0.54 | 0.31 | 0.48 | 0.84 | 0.83 | 0.5433 |
| Slim Language Models (ours) | |||||||
| SlimLM-125Ma | 0.12 | 0.40 | 0.17 | 0.35 | 0.73 | 0.66 | 0.4061 |
| SlimLM-270M | 0.17 | 0.46 | 0.22 | 0.40 | 0.79 | 0.74 | 0.4620 |
| SlimLM-350Mb | 0.16 | 0.45 | 0.22 | 0.39 | 0.78 | 0.74 | 0.4570 |
| SlimLM-450Mc | 0.20 | 0.49 | 0.25 | 0.43 | 0.80 | 0.77 | 0.4893 |
| SlimLM-760M | 0.20 | 0.49 | 0.25 | 0.43 | 0.81 | 0.78 | 0.4921 |
| SlimLM-1Bd | 0.23 | 0.52 | 0.28 | 0.46 | 0.82 | 0.81 | 0.5194 |
🔼 This table displays the accuracy of various language models in classifying the intent of user requests after fine-tuning on the DocAssist dataset. The models were evaluated on their ability to correctly identify whether a user’s input was a summarization, question, suggestion, or answer request. Higher accuracy indicates better performance in intent classification.
read the caption
Table 6: Intent Classification accuracy of various language models after fine-tuning on DocAssist dataset.
| Model | BLEU ↑ | ROUGE-1 ↑ | ROUGE-2 ↑ | ROUGE-L ↑ | STS Score ↑ | GEval ↑ | Average |
|---|---|---|---|---|---|---|---|
| GPT-4o-mini | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.90 | 0.9830 |
| SmolLM-135M-Instruct | 0.18 | 0.45 | 0.26 | 0.42 | 0.72 | 0.56 | 0.4300 |
| SmolLM-360M-Instruct | 0.22 | 0.49 | 0.31 | 0.46 | 0.76 | 0.67 | 0.4860 |
| Qwen2-0.5B-Instruct | 0.30 | 0.57 | 0.39 | 0.54 | 0.81 | 0.79 | 0.5687 |
| Qwen2-1.5B-Instruct | 0.36 | 0.62 | 0.44 | 0.59 | 0.84 | 0.85 | 0.6157 |
| Slim Language Models (ours) | |||||||
| SlimLM-125Ma | 0.22 | 0.49 | 0.30 | 0.46 | 0.75 | 0.62 | 0.4731 |
| SlimLM-270M | 0.24 | 0.52 | 0.33 | 0.49 | 0.78 | 0.69 | 0.5077 |
| SlimLM-350Mb | 0.26 | 0.53 | 0.35 | 0.50 | 0.78 | 0.72 | 0.5246 |
| SlimLM-450Mc | 0.29 | 0.56 | 0.37 | 0.53 | 0.80 | 0.75 | 0.5491 |
| SlimLM-760Mc | 0.30 | 0.57 | 0.39 | 0.54 | 0.81 | 0.79 | 0.5679 |
| SlimLM-1Bd | 0.32 | 0.60 | 0.41 | 0.57 | 0.83 | 0.81 | 0.5907 |
🔼 This table presents five simple fact-checking questions used to evaluate the efficiency of language models on mobile devices. The questions cover a variety of topics and lengths, allowing for a comprehensive assessment of inference speed and resource usage on mobile hardware. The simplicity of the questions ensures that differences in performance are primarily due to the model’s efficiency, rather than the complexity of the question itself.
read the caption
Table 7: Fact-checking questions asked to measure a model’s efficiency on real mobile devices.
| Model | BLEU ↑ | ROUGE-1 ↑ | ROUGE-2 ↑ | ROUGE-L ↑ | STS Score ↑ | Diversity ↓ | Average |
|---|---|---|---|---|---|---|---|
| GPT-4o-mini | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.04 | 1.0000 |
| SmolLM-135M-Instruct | 0.04 | 0.29 | 0.11 | 0.29 | 0.49 | 0.05 | 0.2434 |
| SmolLM-360M-Instruct | 0.07 | 0.34 | 0.15 | 0.33 | 0.53 | 0.03 | 0.2837 |
| Qwen2-0.5B-Instruct | 0.12 | 0.39 | 0.20 | 0.38 | 0.59 | 0.02 | 0.3381 |
| Qwen2-1.5B-Instruct | 0.16 | 0.44 | 0.25 | 0.43 | 0.63 | 0.02 | 0.3837 |
| Slim Language Models (ours) | |||||||
| SlimLM-125Ma | 0.07 | 0.33 | 0.14 | 0.32 | 0.52 | 0.04 | 0.2754 |
| SlimLM-270M | 0.10 | 0.37 | 0.18 | 0.36 | 0.56 | 0.03 | 0.3122 |
| SlimLM-350Mb | 0.10 | 0.36 | 0.18 | 0.35 | 0.56 | 0.03 | 0.3109 |
| SlimLM-450Mc | 0.11 | 0.39 | 0.20 | 0.38 | 0.59 | 0.02 | 0.3326 |
| SlimLM-760Mc | 0.12 | 0.39 | 0.20 | 0.38 | 0.59 | 0.02 | 0.3389 |
| SlimLM-1Bd | 0.15 | 0.43 | 0.24 | 0.42 | 0.62 | 0.02 | 0.3713 |
🔼 This table presents five different summarization prompts used to evaluate the efficiency of language models when processing varying lengths of input text on mobile devices. Each prompt instructs the model to summarize a given document excerpt, with the number of tokens (words) in the excerpt increasing across the prompts (approximately 200, 400, 600, and 800 tokens). The purpose is to observe how model performance (speed and accuracy) changes with increasing input context length, reflecting a typical real-world scenario of handling documents of various sizes on mobile devices.
read the caption
Table 8: Summarizing requests used to measure a model’s efficiency with different input contexts on real mobile devices.
| Model | # Layers | # Heads | Model Dimension | Learning Rate | Global Batch Size | # Trained Tokens (billions) |
|---|---|---|---|---|---|---|
| SlimLM-125M | 12 | 12 | 2,048 | 3e-4 | 2,048 | 627 |
| SlimLM-270M | 16 | 64 | 2,048 | 4e-4 | 2,048 | 627 |
| SlimLM-350M | 24 | 16 | 2,048 | 3e-4 | 2,048 | 627 |
| SlimLM-450M | 20 | 64 | 2,048 | 3e-4 | 2,048 | 627 |
| SlimLM-760M | 24 | 12 | 2,048 | 3e-4 | 2,048 | 627 |
| SlimLM-1B | 24 | 16 | 2,048 | 2e-4 | 2,048 | 627 |
🔼 This table presents the prompt used to instruct GPT-40-mini on how to generate summaries for documents. The prompt specifies the task as summarizing and provides instructions to ensure the summary is concise, covers the main topic and key points, and avoids including minor details. This is a crucial part of creating the dataset used to fine-tune the SlimLM model, ensuring the model learns to generate accurate and informative document summaries.
read the caption
Table 9: {{summ_req}}. Instructional prompt designed to guide GPT-4o-mini how to summarize the document contents.
Full paper#