↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current Image Quality Assessment (IQA) methods primarily focus on the overall image quality, neglecting the importance of region-level analysis. This limitation hinders progress in various applications, such as video optimization and image enhancement which require precise control over specific areas of an image. This paper introduces SEAGULL, a novel network designed to accurately assess the quality of Regions of Interest (ROIs). The lack of suitable datasets for this task is another major obstacle. Existing IQA datasets primarily provide overall quality scores. Thus, SEAGULL also introduces two new datasets to overcome this challenge.
SEAGULL incorporates a vision-language model (VLM), masks created by the Segment Anything Model (SAM) to specify ROIs, and a meticulously designed Mask-based Feature Extractor (MFE). This innovative approach enables accurate fine-grained IQA for ROIs. Extensive experiments demonstrate the superiority of SEAGULL over existing IQA methods, highlighting its significant advancement in the field of region-level image quality analysis. The new datasets also contribute substantially to future research by providing more accurate and comprehensive labeling of ROI quality.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical need for region-level image quality assessment, which is crucial for various applications like video optimization and image enhancement. The proposed SEAGULL model and datasets represent a significant advancement in the field, offering improved accuracy and interpretability. It also opens up exciting new avenues for research in fine-grained image quality analysis and the development of more sophisticated VLM-based methods for image processing.
Visual Insights#

🔼 Figure 1 illustrates the difference between traditional vision-based and vision-language model (VLM)-based image quality assessment (IQA) methods, and introduces the proposed SEAGULL model. Panel (A) shows that vision-based and VLM-based methods assess the overall image quality, lacking fine-grained analysis. Panel (B) demonstrates SEAGULL’s ability to perform fine-grained quality assessment for specified Regions of Interest (ROIs). ROIs are identified using segmentation masks generated by the Segment Anything Model (SAM), allowing for precise, localized quality analysis.
read the caption
Figure 1: (A) Illustrations of the typical Vision-based and VLM-based IQA. Both of them are designed to analyze the quality of overall image. (B) Our Seagull has the capability in fine-grained quality assessment for specified ROI. The mask-based ROI is extracted by SAM [30]. Best viewed in color.
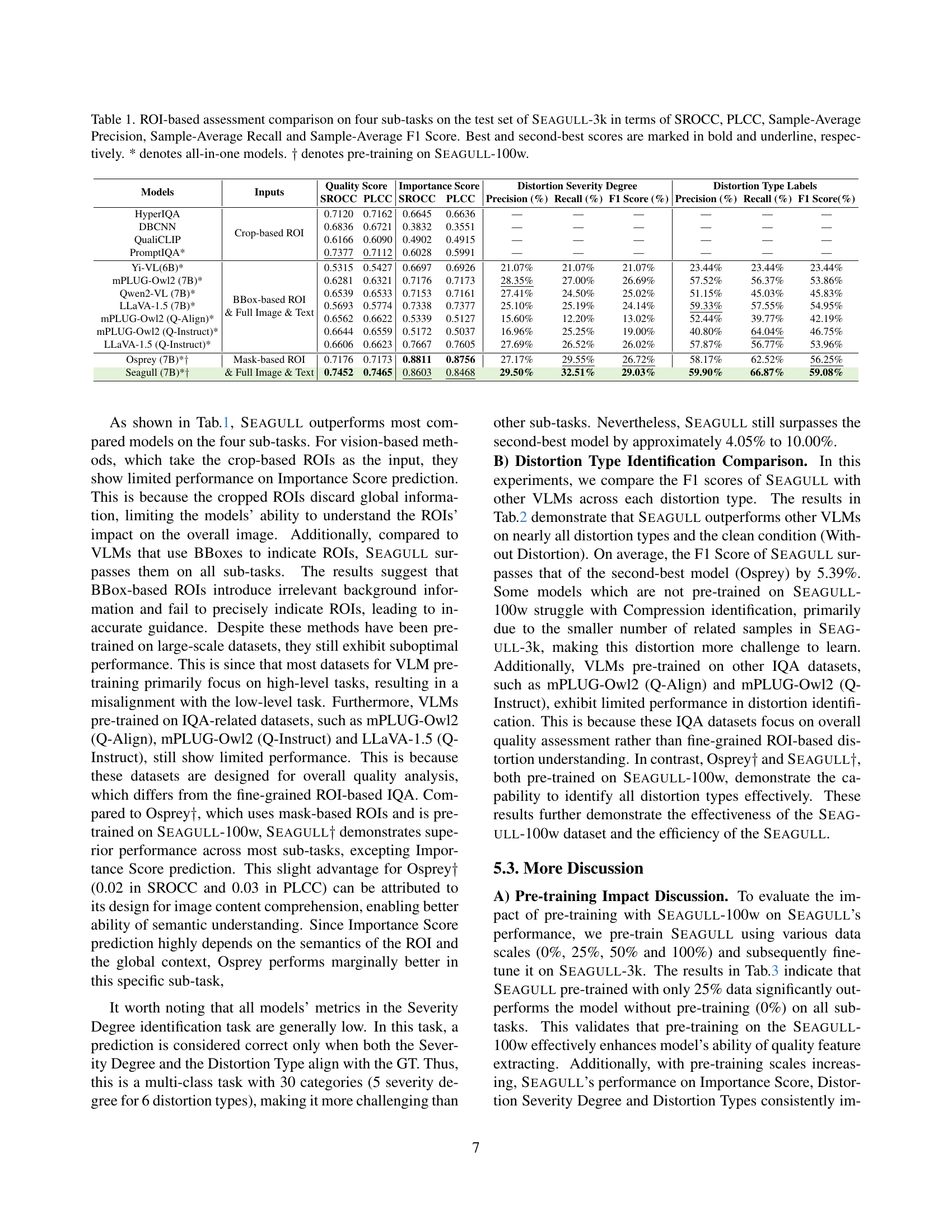
| Models | Inputs | Quality Score (SROCC) | Quality Score (PLCC) | Importance Score (SROCC) | Importance Score (PLCC) | Distortion Severity Degree (Precision (%)) | Distortion Severity Degree (Recall (%)) | Distortion Severity Degree (F1 Score (%)) | Distortion Type Labels (Precision (%)) | Distortion Type Labels (Recall (%)) | Distortion Type Labels (F1 Score (%)) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HyperIQA | 0.7120 | 0.7162 | 0.6645 | 0.6636 | — | — | — | — | — | — | |
| DBCNN | 0.6836 | 0.6721 | 0.3832 | 0.3551 | — | — | — | — | — | — | |
| QualiCLIP | 0.6166 | 0.6090 | 0.4902 | 0.4915 | — | — | — | — | — | — | |
| PromptIQA* | Crop-based ROI | 0.7377 | 0.7112 | 0.6028 | 0.5991 | — | — | — | — | — | — |
| Yi-VL (6B)* | 0.5315 | 0.5427 | 0.6697 | 0.6926 | 21.07% | 21.07% | 21.07% | 23.44% | 23.44% | 23.44% | |
| mPLUG-Owl2 (7B)* | 0.6281 | 0.6321 | 0.7176 | 0.7173 | 28.35% | 27.00% | 26.69% | 57.52% | 56.37% | 53.86% | |
| Qwen2-VL (7B)* | 0.6539 | 0.6533 | 0.7153 | 0.7161 | 27.41% | 24.50% | 25.02% | 51.15% | 45.03% | 45.83% | |
| LLaVA-1.5 (7B)* | 0.5693 | 0.5774 | 0.7338 | 0.7377 | 25.10% | 25.19% | 24.14% | 59.33% | 57.55% | 54.95% | |
| mPLUG-Owl2 (Q-Align)* | 0.6562 | 0.6622 | 0.5339 | 0.5127 | 15.60% | 12.20% | 13.02% | 52.44% | 39.77% | 42.19% | |
| mPLUG-Owl2 (Q-Instruct)* | 0.6644 | 0.6559 | 0.5172 | 0.5037 | 16.96% | 25.25% | 19.00% | 40.80% | 64.04% | 46.75% | |
| LLaVA-1.5 (Q-Instruct)* | BBox-based ROI & Full Image & Text | 0.6606 | 0.6623 | 0.7667 | 0.7605 | 27.69% | 26.52% | 26.02% | 57.87% | 56.77% | 53.96% |
| Osprey (7B)*† | Mask-based ROI | 0.7176 | 0.7173 | 0.8811 | 0.8756 | 27.17% | 29.55% | 26.72% | 58.17% | 62.52% | 56.25% |
| Seagull (7B)*† | & Full Image & Text | 0.7452 | 0.7465 | 0.8603 | 0.8468 | 29.50% | 32.51% | 29.03% | 59.90% | 66.87% | 59.08% |
🔼 Table 1 presents a comprehensive comparison of various models’ performance on four ROI-based image quality assessment sub-tasks using the Seagull-3k test dataset. The evaluation metrics include SROCC, PLCC, Sample-Average Precision, Sample-Average Recall, and Sample-Average F1 Score. The table highlights the best and second-best performing models for each sub-task. It also indicates whether models are ‘all-in-one’ (performing all sub-tasks with a single model) and if they underwent pre-training on the Seagull-100w dataset.
read the caption
Table 1: ROI-based assessment comparison on four sub-tasks on the test set of Seagull-3k in terms of SROCC, PLCC, Sample-Average Precision, Sample-Average Recall and Sample-Average F1 Score. Best and second-best scores are marked in bold and underline, respectively. * denotes all-in-one models. ††\dagger† denotes pre-training on Seagull-100w.
In-depth insights#
ROI-based IQA#
The concept of ROI-based IQA presents a significant advancement in image quality assessment by moving beyond the limitations of evaluating overall image quality. Traditional IQA methods often fail to capture the nuanced quality variations within specific regions of interest (ROIs), leading to inaccurate assessments. ROI-based IQA directly addresses this issue by focusing on the quality of individual ROIs, enabling a more fine-grained and precise analysis. This is particularly important for applications where certain regions are more critical than others, such as medical imaging, video surveillance, and autonomous driving. The development of robust ROI-based IQA methods requires addressing two key challenges: the creation of datasets with detailed ROI-level annotations and the design of algorithms capable of accurately extracting and analyzing ROI quality from complex image data. This necessitates innovations in both data collection and model architecture. One promising approach leverages advances in vision-language models (VLMs) and accurate ROI extraction techniques like the Segment Anything Model (SAM). By combining these techniques, the system can better understand the content and quality of the targeted region, resulting in a more human-like perception of image quality within the defined ROI. Therefore, ROI-based IQA offers a powerful tool for enhancing image analysis and quality control, leading to significant improvements in various applications.
SEAGULL Network#
The SEAGULL network is a novel approach to no-reference image quality assessment (IQA) that focuses on regions of interest (ROIs). Its key innovation lies in the integration of a vision-language model (VLM) with a mask-based feature extractor (MFE). This combination allows SEAGULL to not only accurately assess ROI quality but also provide detailed descriptions of the quality issues. The MFE extracts both global and local view tokens from the ROI, providing a comprehensive understanding of the ROI’s context within the image. Furthermore, SEAGULL is trained on two datasets: SEAGULL-100w, a large synthetic dataset for pre-training to enhance quality perception and SEAGULL-3k, a real-world dataset for fine-tuning to improve the model’s ability to perceive authentic distortions. This dual-training strategy is critical to SEAGULL’s robust performance. The network’s ability to handle mask-based ROIs, generated by SAM, gives it superior accuracy compared to methods using cropping or bounding boxes, avoiding inclusion of irrelevant background information. Overall, SEAGULL represents a significant advancement in ROI-based IQA, offering improved accuracy, detailed descriptions, and robustness by cleverly leveraging VLMs and a carefully designed architecture.
Dataset Creation#
The creation of robust and representative datasets is crucial for training effective image quality assessment (IQA) models, especially for the novel task of region-of-interest (ROI) quality assessment. The paper cleverly addresses this need by constructing two datasets: SEAGULL-100w and SEAGULL-3k. SEAGULL-100w, a large-scale synthetic dataset, leverages RAW images and various distortions to generate a massive quantity of ROI samples (approximately 33 million), improving the model’s generalizability. Importantly, the dataset incorporates three crucial labels for each ROI: quality score, importance score, and distortion analysis, enabling comprehensive model training. Complementing SEAGULL-100w, the smaller, meticulously annotated SEAGULL-3k dataset comprises authentic real-world images, mitigating the domain gap between synthetic and real data. The manual annotation process, involving multiple annotators per ROI, ensures high-quality and reliable labels. This two-pronged approach of combining synthetic and real data allows for effective pre-training and fine-tuning, ultimately leading to enhanced model performance in real-world scenarios. The meticulous design of both datasets, with their detailed annotations, demonstrates a deep understanding of the challenges inherent in ROI-based IQA and positions this work as a significant contribution to the field.
VLM-based IQA#
Vision-Language Model (VLM)-based Image Quality Assessment (IQA) represents a significant advancement in the field. Unlike traditional vision-based methods that rely solely on visual features, VLMs leverage the power of both visual and textual information, leading to more comprehensive and interpretable quality evaluations. By incorporating textual prompts and descriptions, VLMs can go beyond simple numerical scores to provide detailed explanations about perceived quality, identifying specific issues such as blur, noise, or color distortion. This improved interpretability is highly valuable, enabling a deeper understanding of image quality defects and guiding targeted improvements. However, current VLMs show limitations in effectively extracting low-level image features crucial for accurate quality assessment, often focusing on high-level tasks. Furthermore, a lack of suitable training datasets specifically designed for ROI-based IQA is a significant challenge. Existing datasets generally focus on overall image quality, hindering the development of robust and accurate VLM-based IQA systems for regions of interest. Future research should concentrate on creating more comprehensive datasets and refining VLM architectures to effectively capture low-level image details to achieve reliable and nuanced fine-grained quality assessment.
Future of IQA#
The future of Image Quality Assessment (IQA) is ripe with exciting possibilities. Advancements in deep learning and large language models (LLMs) will likely drive more accurate and robust no-reference IQA (NR-IQA) methods, capable of handling diverse image content and distortion types more effectively. Fine-grained IQA, such as assessing quality at the region-of-interest (ROI) level, will gain prominence, leading to more targeted image enhancement and compression techniques. Explainable IQA, providing clear insights into why a specific quality score is assigned, is another crucial direction. This could involve combining visual features with natural language descriptions, enabling more effective human-computer interaction in image analysis. Moreover, integration with other image processing tasks, such as image enhancement and restoration, will be critical, creating integrated workflows capable of providing an end-to-end image quality pipeline. Finally, the development of more comprehensive and diverse IQA datasets is also essential to address the challenges of bias, generalizability, and representing the rich variety of real-world images and distortions.
More visual insights#
More on figures

🔼 This figure illustrates the automated process of creating the SEAGULL-100w dataset. It begins with collecting distorted images through an Image Signal Processor (ISP). These images are then processed using a mask-based ROI collection method. Finally, labels are generated for the ROIs, providing quality scores, importance scores, and distortion analysis for each ROI. This entire pipeline is automated to generate a large-scale dataset for training a vision-language model for image quality assessment.
read the caption
Figure 2: The automatic pipeline for generating the Seagull-100w dataset.

🔼 This figure provides a detailed illustration of the SEAGULL architecture, focusing on two key components: the overall network architecture (left panel) and the Mask-based Feature Extractor (MFE) (right panel). The left panel shows the flow of image and text inputs through the image encoder, mask-based feature extractor, and large language model to produce final quality assessments. The right panel illustrates the MFE in detail, showing how global and local view tokens are extracted from the input image and mask, combined, and fed into the LLM. Color is important for differentiating various aspects of the network and data flow in this diagram.
read the caption
Figure 3: Overview of the Seagull (left) and the Mask-based Feature Extractor (right). Best viewed in color.

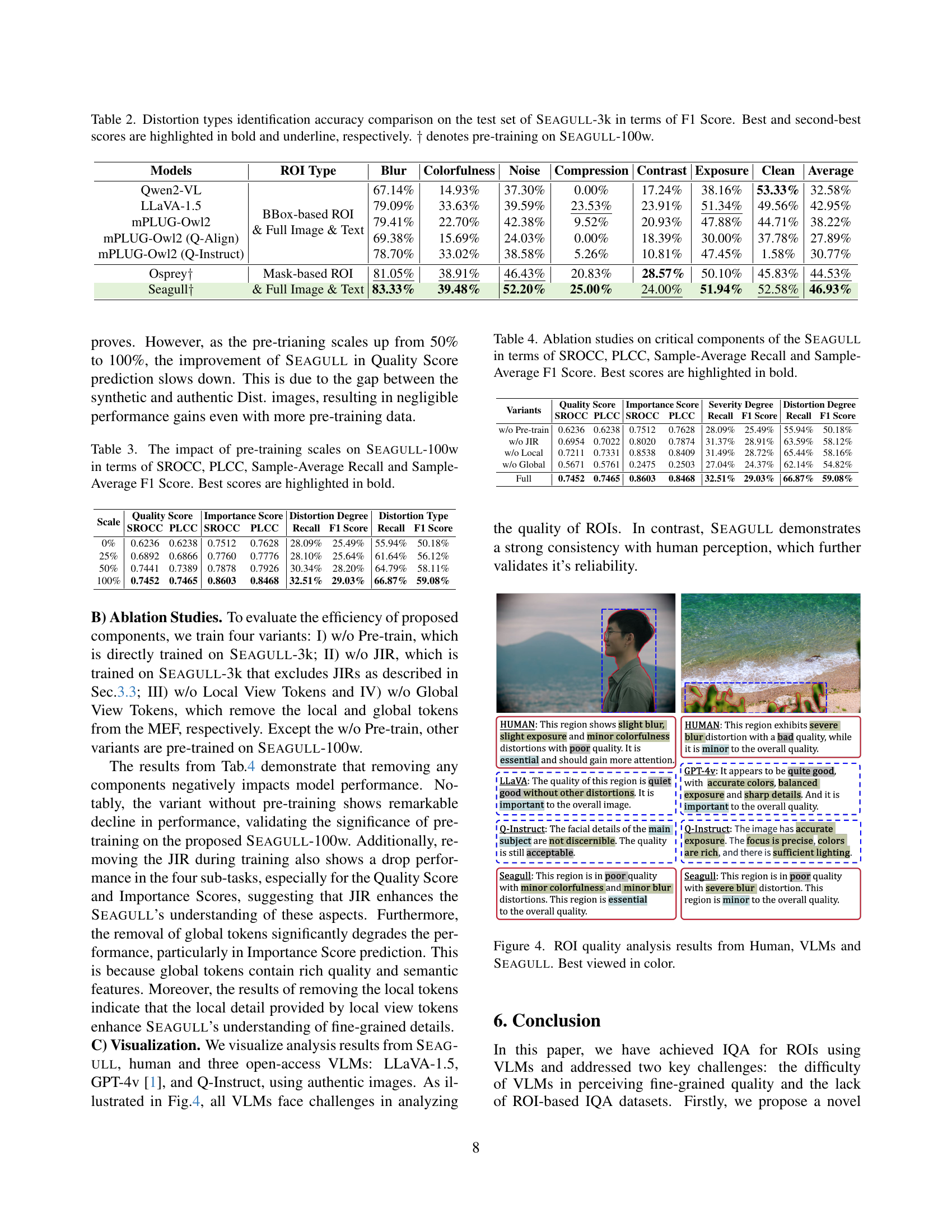
🔼 Figure 4 presents a comparative analysis of Region of Interest (ROI) quality assessment results. It contrasts the assessments provided by humans, various Vision-Language Models (VLMs), and the proposed SEAGULL model. The figure visually demonstrates the differences in how these methods perceive and describe the quality of the ROIs, including details about blur, exposure, and color distortions, and their importance to the overall image quality. This comparison highlights the strengths and weaknesses of each approach in fine-grained quality assessment of image regions.
read the caption
Figure 4: ROI quality analysis results from Human, VLMs and Seagull. Best viewed in color.
More on tables
| Models | ROI Type | Blur | Colorfulness | Noise | Compression | Contrast | Exposure | Clean | Average |
|---|---|---|---|---|---|---|---|---|---|
| Qwen2-VL | 67.14% | 14.93% | 37.30% | 0.00% | 17.24% | 38.16% | 53.33% | 32.58% | |
| LLaVA-1.5 | 79.09% | 33.63% | 39.59% | 23.53% | 23.91% | 51.34% | 49.56% | 42.95% | |
| mPLUG-Owl2 | 79.41% | 22.70% | 42.38% | 9.52% | 20.93% | 47.88% | 44.71% | 38.22% | |
| mPLUG-Owl2 (Q-Align) | 69.38% | 15.69% | 24.03% | 0.00% | 18.39% | 30.00% | 37.78% | 27.89% | |
| mPLUG-Owl2 (Q-Instruct) | BBox-based ROI & Full Image & Text | 78.70% | 33.02% | 38.58% | 5.26% | 10.81% | 47.45% | 1.58% | 30.77% |
| Osprey† | Mask-based ROI | 81.05% | 38.91% | 46.43% | 20.83% | 28.57% | 50.10% | 45.83% | 44.53% |
| Seagull† | & Full Image & Text | 83.33% | 39.48% | 52.20% | 25.00% | 24.00% | 51.94% | 52.58% | 46.93% |
🔼 This table presents a comparison of the accuracy of different models in identifying various distortion types within images, specifically focusing on the regions of interest (ROIs). The accuracy is measured using the F1 score, a metric that considers both precision and recall. The table includes results from vision-based methods and vision-language models (VLMs), highlighting the impact of different ROI indication methods (crop-based, bounding box, and mask-based) and pre-training strategies. The best and second-best F1 scores for each distortion type are emphasized to easily compare model performances. The models that underwent pre-training on the SEAGULL-100w dataset are denoted by the symbol †.
read the caption
Table 2: Distortion types identification accuracy comparison on the test set of Seagull-3k in terms of F1 Score. Best and second-best scores are highlighted in bold and underline, respectively. ††\dagger† denotes pre-training on Seagull-100w.
| Scale | Quality Score | Importance Score | Distortion Degree | Distortion Type | |||||
|---|---|---|---|---|---|---|---|---|---|
| 0% | 0.6236 | 0.6238 | 0.7512 | 0.7628 | 28.09% | 25.49% | 55.94% | 50.18% | |
| 25% | 0.6892 | 0.6866 | 0.7760 | 0.7776 | 28.10% | 25.64% | 61.64% | 56.12% | |
| 50% | 0.7441 | 0.7389 | 0.7878 | 0.7926 | 30.34% | 28.20% | 64.79% | 58.11% | |
| 100% | 0.7452 | 0.7465 | 0.8603 | 0.8468 | 32.51% | 29.03% | 66.87% | 59.08% |
🔼 This table presents the results of an experiment evaluating the effect of varying the size of the pre-training dataset (SEAGULL-100w) on the performance of the SEAGULL model. The model was pre-trained using different percentages of the SEAGULL-100w dataset (0%, 25%, 50%, and 100%) before being fine-tuned on the SEAGULL-3k dataset. The table displays the model’s performance metrics on four sub-tasks of ROI quality assessment: Quality Score prediction (SROCC and PLCC), Importance Score prediction (SROCC and PLCC), Distortion Severity Degree prediction (Recall and F1 Score), and Distortion Type identification (Recall and F1 Score). The best performance for each metric, indicating the optimal pre-training dataset size, is highlighted in bold.
read the caption
Table 3: The impact of pre-training scales on Seagull-100w in terms of SROCC, PLCC, Sample-Average Recall and Sample-Average F1 Score. Best scores are highlighted in bold.
| Variants | Quality Score | Importance Score | Severity Degree | Distortion Degree | ||||
|---|---|---|---|---|---|---|---|---|
| SROCC | PLCC | SROCC | PLCC | Recall | F1 Score | Recall | F1 Score | |
| — | — | — | — | — | — | — | — | — |
| w/o Pre-train | 0.6236 | 0.6238 | 0.7512 | 0.7628 | 28.09% | 25.49% | 55.94% | 50.18% |
| w/o JIR | 0.6954 | 0.7022 | 0.8020 | 0.7874 | 31.37% | 28.91% | 63.59% | 58.12% |
| w/o Local | 0.7211 | 0.7331 | 0.8538 | 0.8409 | 31.49% | 28.72% | 65.44% | 58.16% |
| w/o Global | 0.5671 | 0.5761 | 0.2475 | 0.2503 | 27.04% | 24.37% | 62.14% | 54.82% |
| Full | 0.7452 | 0.7465 | 0.8603 | 0.8468 | 32.51% | 29.03% | 66.87% | 59.08% |
🔼 This table presents the results of ablation studies conducted on the SEAGULL model. It evaluates the impact of removing or altering key components of the model on its performance across four metrics: Spearman’s Rank Order Correlation Coefficient (SROCC), Pearson’s Linear Correlation Coefficient (PLCC), Sample-Average Recall, and Sample-Average F1-Score. The metrics assess the model’s accuracy in predicting ROI Quality Scores, Importance Scores, Distortion Severity Degrees, and Distortion Types. The different model variants compared include a version without pre-training, a version without judgment instruction-responses, a version without local view tokens extracted from the mask-based feature extractor, and a version without global view tokens. The table helps to demonstrate the contribution of each component to the overall performance of SEAGULL.
read the caption
Table 4: Ablation studies on critical components of the Seagull in terms of SROCC, PLCC, Sample-Average Recall and Sample-Average F1 Score. Best scores are highlighted in bold.
Full paper#