↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current Video Large Language Models (Vid-LLMs) struggle with precise temporal localization in videos, a crucial aspect of Video Temporal Grounding (VTG). Existing methods often involve complex model modifications or extensive retraining, limiting their flexibility and applicability. The challenge lies in aligning visual content with temporal information accurately, hindering precise event timing identification.
This paper introduces Number-Prompt (NumPro), a simple yet highly effective method that significantly improves VTG. NumPro addresses the issue by adding unique numerical identifiers to each video frame, making temporal grounding as intuitive as ‘flipping through manga.’ This allows Vid-LLMs to easily link visual content with corresponding temporal information. The effectiveness is demonstrated through extensive experiments on multiple datasets and models, showcasing substantial performance improvements both in training-free scenarios and with fine-tuning (NumPro-FT).
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video understanding and large language models. It introduces a novel and effective method for improving video temporal grounding (VTG) in Vid-LLMs, a significant challenge in the field. NumPro’s simplicity and broad applicability across various models make it a valuable tool, opening new avenues for research in precise temporal localization and cross-modal understanding. Its potential impact extends to numerous applications relying on accurate video event timing.
Visual Insights#

🔼 Figure 1 demonstrates the impact of adding frame numbers to video frames for temporal grounding. In (a), without frame numbers, both humans and video large language models (Vid-LLMs) have difficulty accurately identifying specific timestamps. In contrast, (b) shows that adding frame numbers makes temporal grounding much more intuitive and efficient, similar to the ease of understanding the timeline of events in a manga comic book where panels are clearly numbered.
read the caption
Figure 1: Effectiveness of Adding Frame Numbers for Temporal Grounding: (a) Without numbered images or frames, both humans and Vid-LLMs struggle to locate specific timestamps accurately. (b) Once numbered, grounding temporal cues becomes as intuitive as flipping manga, where timestamps are accessible at a glance.
| Model | Charades-STA R@0.3 | Charades-STA R@0.5 | Charades-STA R@0.7 | Charades-STA mIoU | ActivityNet R@0.3 | ActivityNet R@0.5 | ActivityNet R@0.7 | ActivityNet mIoU | QVHighlights mAP | QVHighlights HIT@1 |
|---|---|---|---|---|---|---|---|---|---|---|
| VTG-Tuned Vid-LLMs | ||||||||||
| GroundingGPT [31] | - | 29.6 | 11.9 | - | - | - | - | - | - | - |
| LITA [22] | - | - | - | - | - | 25.9 | - | 28.6 | - | - |
| VTG-LLM [17] | 52.0 | 33.8 | 15.7 | - | - | - | - | - | 16.5 | 33.5 |
| TimeChat [44] | 47.7 | 22.9 | 12.5 | 30.6 | 30.2 | 16.9 | 8.2 | 21.8 | 14.5 | 23.9 |
| VTimeLLM [21] | 51.0 | 27.5 | 11.4 | 31.2 | 44.0 | 27.8 | 14.3 | 30.4 | - | - |
| Momentor [42] | 42.9 | 23.0 | 12.4 | 29.3 | 42.6 | 26.6 | 11.6 | 28.5 | 7.6 | - |
| HawkEye [52] | 50.6 | 31.4 | 14.5 | 33.7 | 49.1 | 29.3 | 10.7 | 32.7 | - | - |
| General Vid-LLMs | ||||||||||
| GPT-4o [41] | 55.0 | 32.0 | 11.5 | 35.4 | 33.3 | 21.2 | 10.4 | 23.7 | 39.5 | 68.7 |
| +NumPro | 57.1 | 35.5 | 13.5 | 37.6 | 45.5 | 30.8 | 18.4 | 33.6 | 40.5 | 70.7 |
| Qwen2-VL-7B [51] | 8.7 | 5.4 | 2.4 | 7.9 | 17.0 | 9.4 | 3.9 | 12.5 | 21.5 | 42.2 |
| +NumPro | 60.7 | 36.8 | 15.9 | 38.5 | 44.2 | 26.4 | 14.4 | 31.3 | 23.6 | 43.4 |
| LongVA-7B-DPO [65] | 22.6 | 10.1 | 2.2 | 14.6 | 11.8 | 5.3 | 1.9 | 8.2 | 14.2 | 20.4 |
| +NumPro | 27.2 | 10.3 | 2.9 | 18.9 | 20.1 | 10.8 | 5.4 | 15.2 | 15.3 | 24.3 |
| +NumPro-FT | 63.8 | 42.0 | 20.6 | 41.4 | 55.6 | 37.5 | 20.6 | 38.8 | 25.0 | 37.2 |
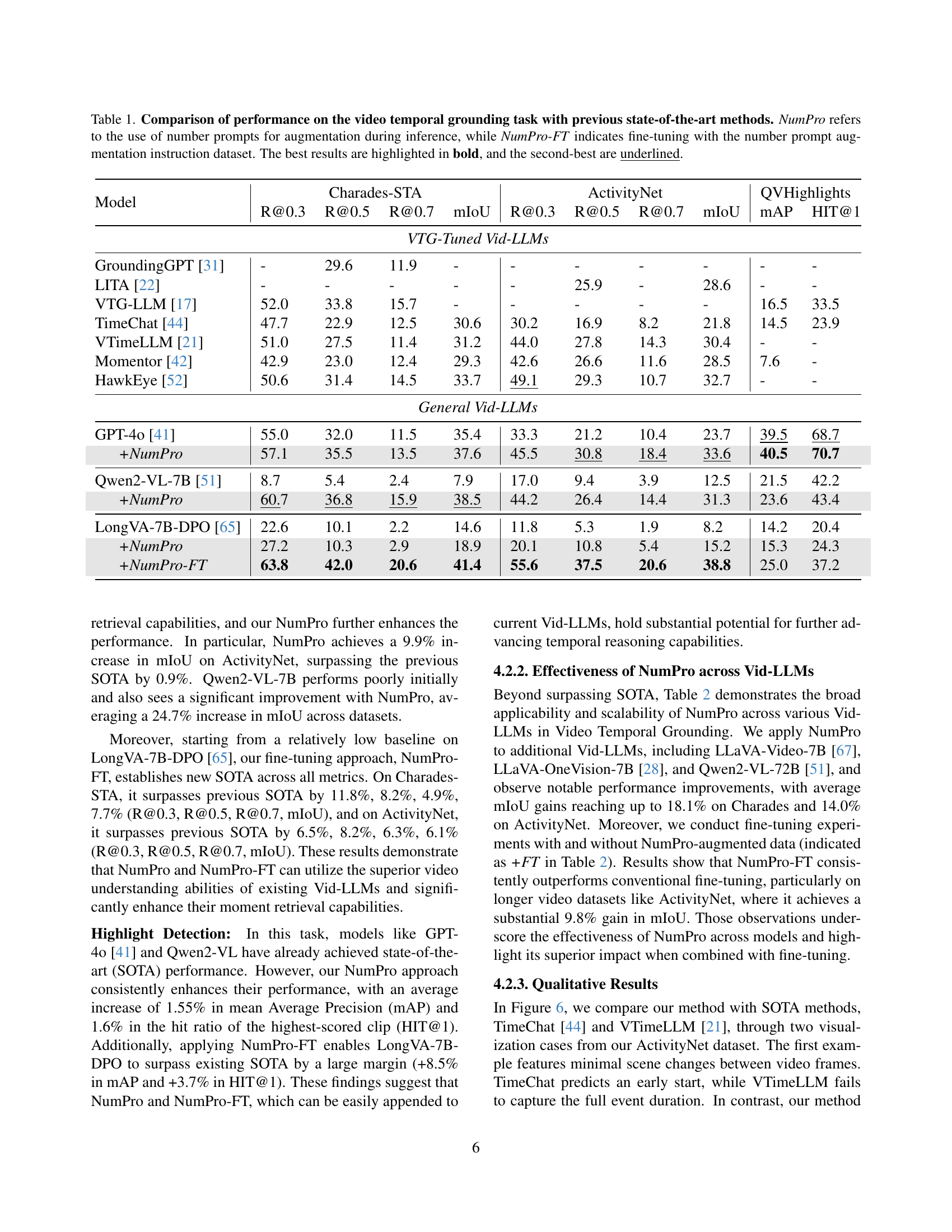
🔼 Table 1 compares the performance of various Video Temporal Grounding (VTG) models on two tasks: Moment Retrieval and Highlight Detection. It contrasts several state-of-the-art (SOTA) models against models enhanced by the NumPro method (with or without fine-tuning). The table presents several evaluation metrics for both tasks, including mIoU, recall@m (at different thresholds), mAP, and HIT@1. NumPro’s impact is shown by comparing the performance of models with and without NumPro integration (training-free) or fine-tuned with the NumPro dataset (NumPro-FT). Best and second-best results are highlighted.
read the caption
Table 1: Comparison of performance on the video temporal grounding task with previous state-of-the-art methods. NumPro refers to the use of number prompts for augmentation during inference, while NumPro-FT indicates fine-tuning with the number prompt augmentation instruction dataset. The best results are highlighted in bold, and the second-best are underlined.
In-depth insights#
Bridging Vision & Time#
The concept of ‘Bridging Vision & Time’ in video analysis focuses on precisely linking visual information with its temporal context. This is crucial because while many models excel at understanding what happens in a video, they often struggle to determine when it happens accurately. This bridging requires sophisticated techniques that go beyond simple frame-level analysis, incorporating advanced methods like attention mechanisms to align visual features with temporal information extracted from language queries or other temporal cues. The challenge lies in the inherent complexity of video data, requiring models to effectively manage the multifaceted relationships between visual frames and the timing of events. Successful bridging is key to enabling more nuanced applications such as precise video summarization, detailed event retrieval, and high-accuracy temporal question answering. Therefore, solutions must efficiently handle temporal uncertainty and handle various levels of granularity. Advanced approaches may include exploiting video structure, specialized temporal embeddings, or training on curated datasets annotated with precise temporal information. Ultimately, effective bridging promises a profound leap in video understanding capabilities, paving the way for more robust and versatile video-based applications.
NumPro: Core Concept#
NumPro’s core concept centers on bridging the gap between visual understanding and precise temporal localization in video analysis using large language models (Vid-LLMs). It cleverly leverages the existing capabilities of Vid-LLMs by introducing unique numerical identifiers to each video frame, transforming the video into a sequence resembling a manga. This simple yet effective method allows Vid-LLMs to intuitively connect visual information with temporal context; the numbers act as direct visual cues for temporal grounding, making it as easy as ‘flipping through a manga’ to pinpoint events’ start and end times. NumPro’s strength lies in its simplicity and generality, requiring no significant model modifications or extensive retraining, thus enhancing existing Vid-LLM architectures without adding significant computational overhead. This approach transforms a complex temporal grounding task into a straightforward visual alignment problem, thereby significantly improving performance in moment retrieval and highlight detection tasks.
VTG: Enhanced LLMs#
The concept of “VTG: Enhanced LLMs” points towards significant advancements in video temporal grounding using large language models. The core challenge addressed is the precise localization of events within videos, a task where even sophisticated LLMs often struggle. The proposed approach likely involves innovative methods to improve temporal understanding and reasoning abilities of these models, perhaps through enhanced visual-temporal feature extraction, improved attention mechanisms, or novel training strategies. Effective solutions might include incorporating temporal context more explicitly during the training process, enabling more nuanced understanding of events’ durations and sequences. The integration of explicit numerical identifiers or timestamps directly into the video frames as a prompt could be a key element, creating a stronger link between visual information and temporal information. This technique potentially allows for intuitive processing of temporal cues, similar to how humans perceive a timeline using numbered chapters or scenes. Ultimately, these enhancements aim to bridge the gap between robust visual comprehension and precise temporal grounding capabilities, leading to more accurate and reliable temporal localization in a variety of video-based tasks, and ultimately enabling richer video-text interaction.
NumPro Design Choices#
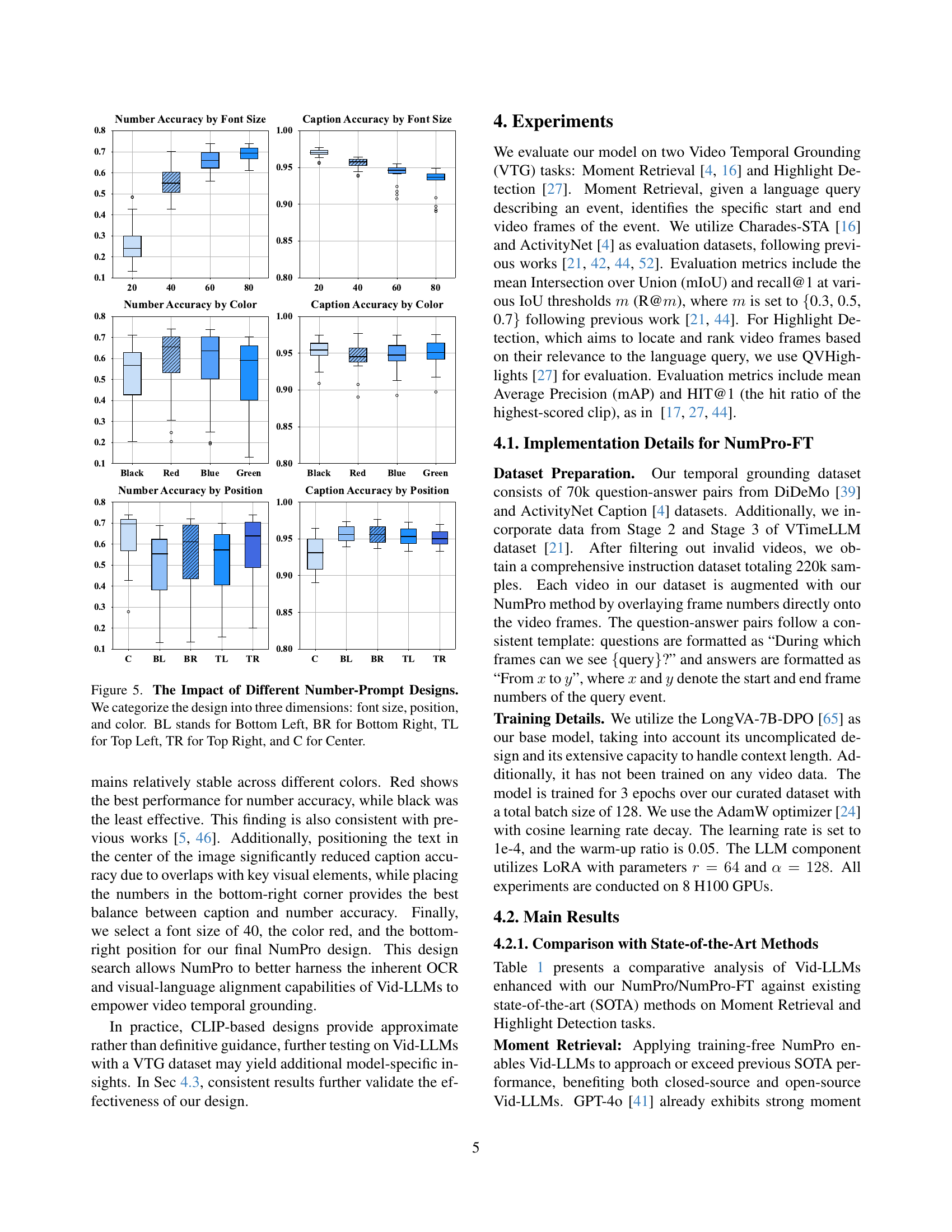
The effectiveness of NumPro hinges on thoughtful design choices for its numerical prompts. Optimal placement, color, and font size are crucial for maximizing both number recognition by the model and minimizing interference with the video’s visual content. The authors cleverly employ CLIP-based experiments on a subset of MSCOCO to assess these parameters, balancing Number Accuracy and Caption Accuracy metrics. This data-driven approach ensures the robustness of their design across various models and datasets, ultimately finding that a medium font size (40 or 60) in red, positioned in the bottom-right corner, provides the best balance between clear numerical identification and minimal visual disruption. This strategy enhances VTG capabilities without requiring additional vocabulary or modifying existing models’ architectures, making it a highly efficient method. Further investigation into sampling strategies for prompt application (e.g., labeling all frames or just a subset) reveals that even a sparse application of NumPro (20% of frames) significantly boosts performance, highlighting the method’s efficiency and adaptability.
Future of VTG Research#
The future of Video Temporal Grounding (VTG) research hinges on bridging the gap between precise temporal localization and nuanced language understanding. Current Vid-LLMs excel at comprehending video content but struggle with accurate temporal grounding. Future work should explore more sophisticated methods for aligning visual features with temporal information, potentially incorporating advanced temporal modeling techniques or leveraging external knowledge bases for improved context. Combining symbolic reasoning with the strengths of deep learning will be crucial for creating robust and reliable VTG systems. This includes investigating new methods of handling uncertainty and ambiguity, particularly regarding temporally complex events with overlapping or ambiguous actions. Furthermore, developing more diverse and challenging benchmarks is essential for evaluating progress in VTG, particularly those that assess the system’s ability to reason about intricate temporal relationships and interactions between multiple agents or objects. Finally, research should focus on improving efficiency and scalability, enabling VTG to be applied to increasingly longer and more complex videos while maintaining acceptable processing times.
More visual insights#
More on figures

🔼 Figure 2 presents an attention map visualization that illustrates how a Video Large Language Model (Vid-LLM) processes a video in the context of an event query. The heatmap shows the model’s attention distribution across different frames of a video clip. The darker the color of a frame, the stronger the model’s attention. The model successfully focuses its attention on the relevant parts of the video where the queried event occurs. However, the key observation is that, despite accurately attending to relevant visual information, the model fails to precisely determine the start and end frames of the event, producing imprecise temporal boundaries in its response. This highlights a core challenge in Video Temporal Grounding (VTG) tasks.
read the caption
Figure 2: Attention Analysis between Video Frames and Event Query. Although the model accurately attends to regions of interest related to the query, it struggles to generate precise temporal boundaries in its response.

🔼 This figure illustrates the Number-Prompt (NumPro) approach for Video Temporal Grounding (VTG) in two scenarios. The first is a training-free setting where frame numbers are directly added to the video frames, allowing Vid-LLMs to perform temporal localization without additional training. The second involves fine-tuning a Vid-LLM using a dataset where frame numbers have been added, significantly enhancing the model’s VTG capabilities while avoiding any architectural changes to the model itself. The figure visually represents the workflow and components of both approaches.
read the caption
Figure 3: Framework of Our Approach in Two Settings: (1) Training-free VTG with NumPro, where frame numbers are directly added to video frames, enabling Vid-LLMs to locate events temporally without additional training, and (2) Fine-tuned VTG with NumPro-FT, which further improves VTG performance by fine-tuning Vid-LLMs on a dataset NumPro-enhanced with no architectural modifications.

🔼 This figure details the algorithm used to determine the optimal design for the Number-Prompt (NumPro) method. The process involves overlaying various numerical identifiers (numbers) onto images from the COCO dataset. CLIP encoders then generate visual and textual representations for each configuration. The algorithm computes ‘Number/Caption Similarity’ and ‘Number/Caption Accuracy’ metrics. The goal is to find the NumPro configuration that maximizes both the ease of number recognition and minimizes the visual interference of the numbers with the original image content.
read the caption
Figure 4: Illustration of Our NumPro Design Algorithm.We overlay different numbers onto COCO images and obtain visual and textual representations using CLIP encoders. For each configuration, we calculate Number/Caption Similarity and derive Number/Caption Accuracy, enabling us to identify the optimal NumPro design that balances recognizability and minimal disruption to the visual content.

🔼 This figure analyzes the impact of different Number-Prompt design choices on performance. Three design aspects are investigated: font size, position (Bottom Left, Bottom Right, Top Left, Top Right, and Center), and color (Black, Red, Blue, and Green). The results show how each design choice affects Number Accuracy (how well the model identifies the numbers) and Caption Accuracy (how accurately the original caption aligns with frame content after adding numbers). The goal is to find the Number-Prompt design that balances number readability with minimal disruption to the main video content.
read the caption
Figure 5: The Impact of Different Number-Prompt Designs. We categorize the design into three dimensions: font size, position, and color. BL stands for Bottom Left, BR for Bottom Right, TL for Top Left, TR for Top Right, and C for Center.

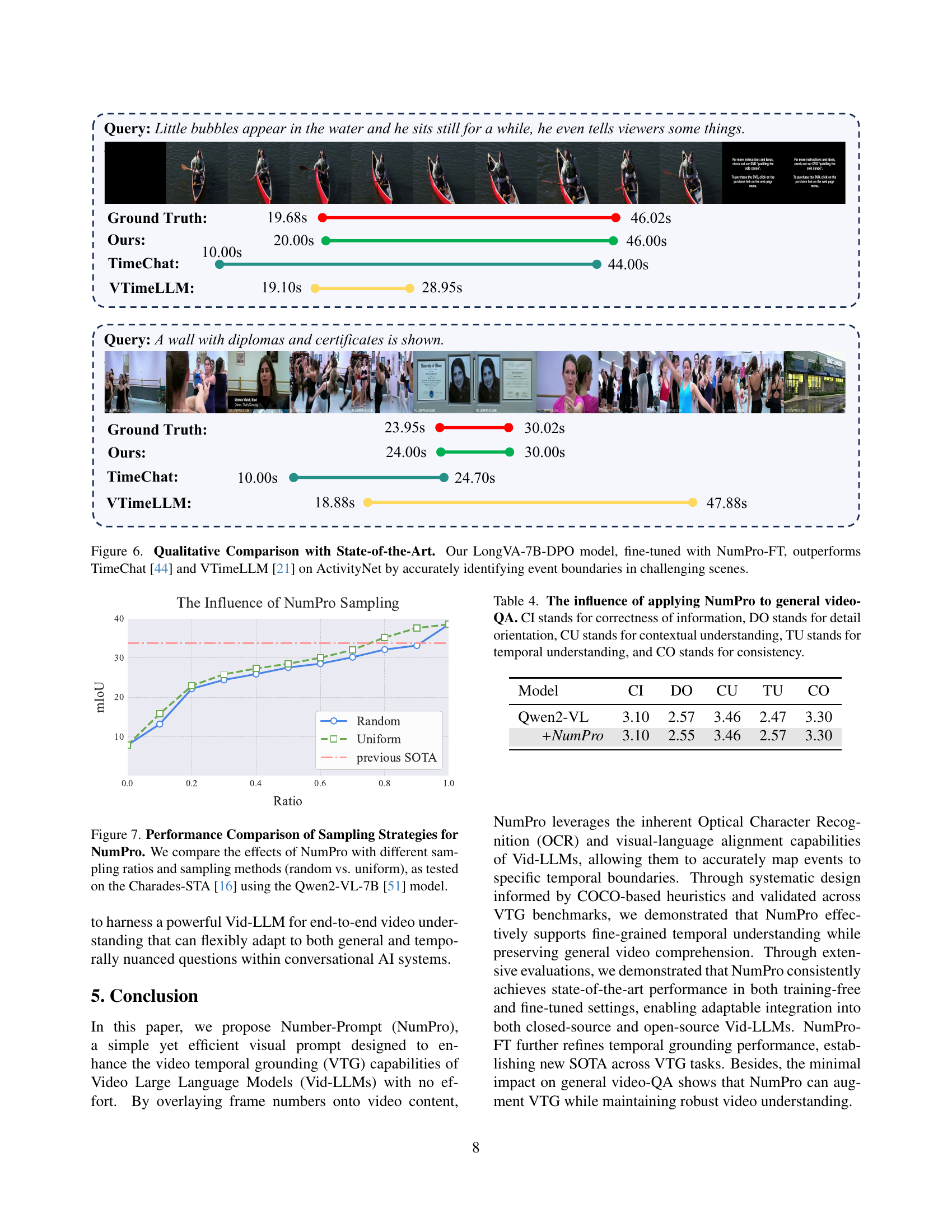
🔼 Figure 6 presents a qualitative comparison of video temporal grounding performance between the proposed method (LongVA-7B-DPO model fine-tuned with NumPro-FT), TimeChat [44], and VTimeLLM [21] on the ActivityNet dataset. Two example video clips with their corresponding ground truth event timestamps, along with the model-predicted timestamps, are shown. This demonstrates the superior accuracy of the proposed method in precisely identifying event boundaries, especially in complex scenes involving subtle changes or distractors. The figure highlights the challenge that existing models (TimeChat and VTimeLLM) face in accurately localizing events. The proposed approach greatly improves upon these methods, achieving more precise and accurate event boundary detection in challenging scenarios.
read the caption
Figure 6: Qualitative Comparison with State-of-the-Art. Our LongVA-7B-DPO model, fine-tuned with NumPro-FT, outperforms TimeChat [44] and VTimeLLM [21] on ActivityNet by accurately identifying event boundaries in challenging scenes.
More on tables
| Model | Charades-STA | ActivityNet |
|---|---|---|
| R@0.3 | R@0.5 | R@0.7 |
| LLaVA-OneVision-7B [28] | 22.3 | 7.9 |
| +NumPro | 42.9( +20.6) | 19.4( +11.5) |
| LLaVA-Video-7B [67] | 11.8 | 2.7 |
| +NumPro | 56.7( +44.8) | 25.6( +22.9) |
| Qwen2-VL-72B [51] | 0.0 | 0.0 |
| +NumPro | 25.8( +25.8) | 9.9( +9.9) |
| LongVA-7B-DPO [65] | 22.6 | 10.1 |
| +FT | 62.0 | 41.6 |
| +NumPro-FT | 63.8( +41.2) | 42.0( +31.9) |
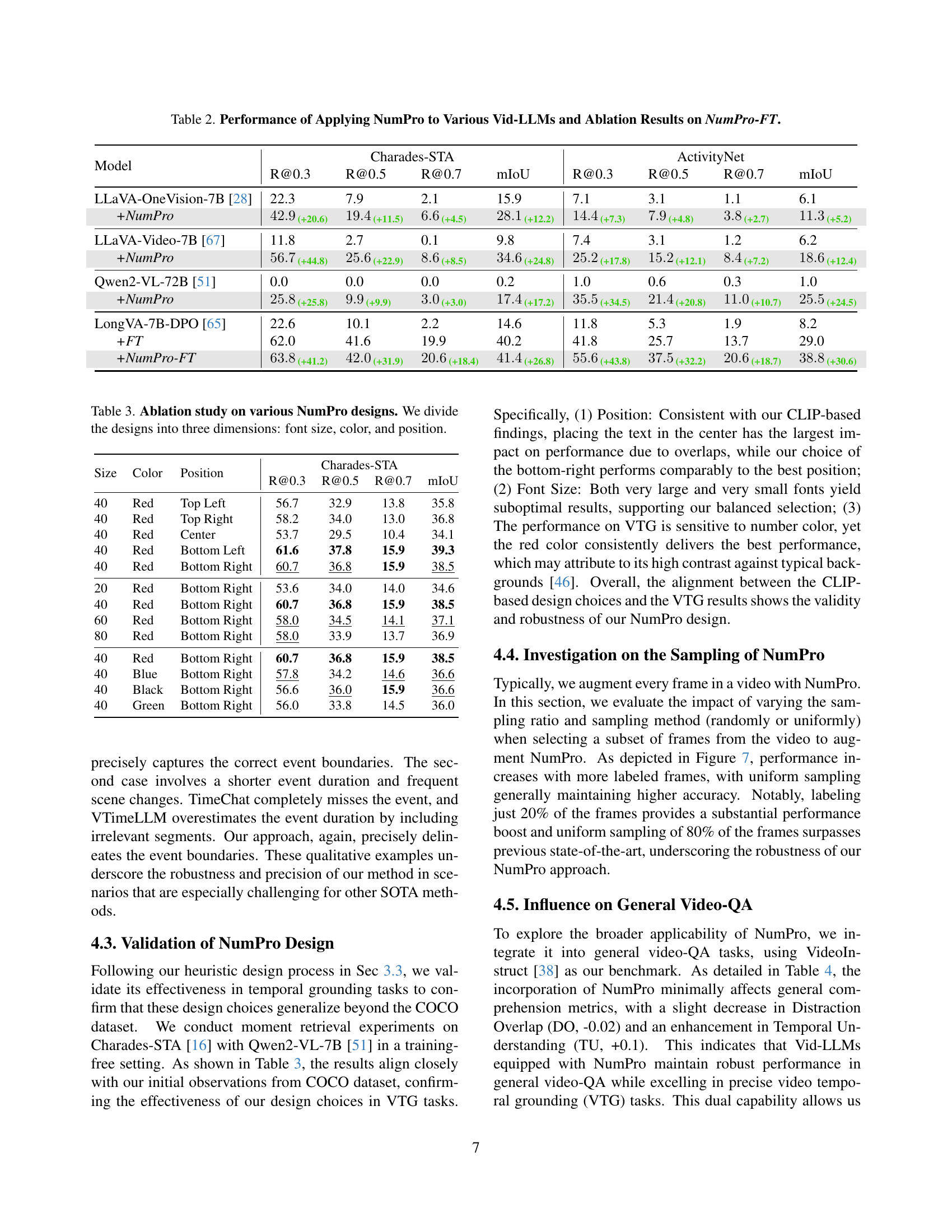
🔼 This table presents the performance of several Video Large Language Models (Vid-LLMs) on video temporal grounding tasks, both with and without the Number-Prompt (NumPro) method. It shows the impact of NumPro on various models across two datasets: Charades-STA and ActivityNet. The results are broken down by different metrics (R@0.3, R@0.5, R@0.7, mIoU, mAP, HIT@1) for both training-free and fine-tuned settings (with NumPro-FT). It demonstrates the effectiveness of NumPro and NumPro-FT in enhancing the performance of multiple different Vid-LLMs.
read the caption
Table 2: Performance of Applying NumPro to Various Vid-LLMs and Ablation Results on NumPro-FT.
| Size | Color | Position | Charades-STA | |||
|---|---|---|---|---|---|---|
| 40 | Red | Top Left | 56.7 | 32.9 | 13.8 | 35.8 |
| 40 | Red | Top Right | 58.2 | 34.0 | 13.0 | 36.8 |
| 40 | Red | Center | 53.7 | 29.5 | 10.4 | 34.1 |
| 40 | Red | Bottom Left | 61.6 | 37.8 | 15.9 | 39.3 |
| 40 | Red | Bottom Right | 15.9 | |||
| 20 | Red | Bottom Right | 53.6 | 34.0 | 14.0 | 34.6 |
| 40 | Red | Bottom Right | 60.7 | 36.8 | 15.9 | 38.5 |
| 60 | Red | Bottom Right | ||||
| 80 | Red | Bottom Right | 33.9 | 13.7 | 36.9 | |
| 40 | Red | Bottom Right | 60.7 | 36.8 | 15.9 | 38.5 |
| 40 | Blue | Bottom Right | 34.2 | |||
| 40 | Black | Bottom Right | 56.6 | 15.9 | ||
| 40 | Green | Bottom Right | 56.0 | 33.8 | 14.5 | 36.0 |
🔼 This ablation study investigates the impact of different Number-Prompt (NumPro) design choices on video temporal grounding performance. Three key design aspects were varied: font size, color, and position of the overlaid numbers on the video frames. The table presents the results of these variations, measured using Number Accuracy and Caption Accuracy metrics on the Charades-STA dataset. These metrics help to understand the balance between the clear visibility and recognition of the numbers (Number Accuracy) and the degree to which the numbers disrupt or interfere with the main visual content of the video frames (Caption Accuracy).
read the caption
Table 3: Ablation study on various NumPro designs. We divide the designs into three dimensions: font size, color, and position.
| Model | CI | DO | CU | TU | CO |
|---|---|---|---|---|---|
| Qwen2-VL | 3.10 | 2.57 | 3.46 | 2.47 | 3.30 |
| +NumPro | 3.10 | 2.55 | 3.46 | 2.57 | 3.30 |
🔼 Table 4 presents the results of applying the Number-Prompt (NumPro) method to general video question-answering (VQA) tasks, evaluating its impact on various aspects of model performance. It assesses whether NumPro affects the model’s ability to provide correct information (CI), focus on details (DO), understand context (CU), grasp temporal information (TU), and maintain consistency (CO) in its responses. The table shows the scores for each of these aspects, both with and without the NumPro technique, to demonstrate how the addition of NumPro impacts overall VQA performance.
read the caption
Table 4: The influence of applying NumPro to general video-QA. CI stands for correctness of information, DO stands for detail orientation, CU stands for contextual understanding, TU stands for temporal understanding, and CO stands for consistency.
Full paper#