↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current Vision-Language Models (VLMs) struggle with complex visual question answering due to their inability to perform systematic and structured reasoning. Existing methods like chain-of-thought prompting often result in errors or hallucinated outputs. The paper highlights the need for VLMs to engage in autonomous multi-stage reasoning.
To address this, the paper introduces LLaVA-01, a novel VLM that independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach, combined with a novel inference-time stage-level beam search, allows LLaVA-01 to significantly outperform its base model and even larger, closed-source models on various multimodal reasoning benchmarks. The paper also introduces the LLaVA-01-100k dataset, which plays a key role in achieving these improvements.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces LLaVA-01, a novel visual language model that significantly improves upon existing models’ reasoning capabilities. Its structured reasoning approach and effective inference-time scaling methods offer a novel solution to challenges in visual question answering, opening avenues for future research in multimodal reasoning and large language model scaling. The release of the LLaVA-01-100k dataset further contributes to the field by providing a valuable resource for training and benchmarking.
Visual Insights#

🔼 This figure compares the performance of LLaVA-01 with several other vision-language models (VLMs) across six established multimodal reasoning benchmarks. Despite being fine-tuned from a smaller, less performant base model (Llama-3.2-11B-Vision-Instruct), LLaVA-01 achieves surprisingly high average scores. Notably, it surpasses numerous larger open-source VLMs and even some closed-source models, highlighting its effectiveness in complex reasoning tasks. For detailed numerical results, refer to Table 7 in the paper.
read the caption
Figure 1: Performance of LLaVA-o1 and other models across six multimodal reasoning benchmarks. Although LLaVA-o1 is fine-tuned from the Llama-3.2-11B-Vision-Instruct [40] model (which has the lowest average score), it outperforms many larger open-source models and even some closed-source models. Detailed benchmark results are shown in Table 7.
| Dataset | Type | Size |
|---|---|---|
| ShareGPT4V [8] | General VQA | 31.3k |
| ChartQA [38] | General VQA | 17.2k |
| A-OKVQA [45] | General VQA | 16.1k |
| AI2D [23] | Science-Targeted VQA | 11.4k |
| GeoQA+ [7] | Science-Targeted VQA | 11.4k |
| ScienceQA [34] | Science-Targeted VQA | 5.6k |
| DocVQA [39] | General VQA | 4.0k |
| PISC [28] | General VQA | 1.0k |
| CLEVR [22] | General VQA | 0.5k |
| CLEVR-Math [13] | Science-Targeted VQA | 0.5k |
🔼 This table details the composition of the LLAVA-01-100k dataset used in the paper. It lists the various visual question answering (VQA) datasets that were sampled from, categorizes them as either general-purpose VQA or science-focused VQA, and shows the number of samples taken from each dataset. The total number of samples in the LLAVA-01-100k dataset is 99,000.
read the caption
Table 1: The number of samples selected from each benchmark.
In-depth insights#
Step-by-Step VLM#
A Step-by-Step VLM (Vision-Language Model) signifies a paradigm shift in multimodal reasoning. Instead of directly generating answers, it breaks down complex tasks into sequential stages. This structured approach, often involving summarization, captioning (image description), detailed reasoning, and finally, conclusion generation, allows for more systematic and robust processing. Unlike simpler VLMs that might struggle with intricate visual question answering, a step-by-step VLM fosters better transparency and traceability of the reasoning process. The intermediate steps become valuable checkpoints, revealing the model’s thought process and allowing for easier error detection. Inference-time scaling becomes more efficient because the model can selectively refine intermediate outputs before reaching a final conclusion. This structured approach contrasts with traditional chain-of-thought prompting where the reasoning flow is less explicitly organized. The use of dedicated tags, denoting each reasoning stage, facilitates not only the model’s internal reasoning but also the understanding and analysis of its performance by researchers. Overall, the step-by-step VLM framework showcases a significant improvement in accuracy and interpretability compared to direct-prediction or less organized approaches. It lays the groundwork for future development of more sophisticated multimodal reasoning techniques.
Inference-Time Scaling#
Inference-time scaling tackles the challenge of improving large language models (LLMs) without requiring extensive retraining. The core idea is to enhance performance during the inference stage, the point where the model generates its response, rather than altering its core architecture through further training. The paper highlights that existing methods, like best-of-N sampling and sentence-level beam search, have limitations. Best-of-N is computationally expensive, while sentence-level beam search is too granular, potentially overlooking superior, higher-level choices. The authors introduce a novel stage-level beam search as a more effective solution. This method strategically generates multiple candidate responses at each stage of the reasoning process (summary, caption, reasoning, and conclusion) and selects the best performing option at each step before proceeding. This approach offers a more scalable and robust alternative, as it focuses on higher-level decision-making within a structured framework, unlike the previously mentioned methods. The results demonstrate that this stage-level approach significantly improves efficiency and overall performance.
Structured Reasoning#
The concept of structured reasoning, as explored in the context of vision-language models (VLMs), addresses the limitations of traditional methods that lack systematic and organized approaches. Structured reasoning enhances VLMs by breaking down complex tasks into sequential, manageable stages, such as summarization, visual interpretation, logical reasoning, and conclusion generation. This approach contrasts with the less effective direct prediction methods often employed in early VLMs. The benefits of this structured approach are evident in improved precision and a systematic workflow, mitigating errors and hallucinations commonly seen in unstructured reasoning. A key aspect is the independent engagement of the VLM in each stage, facilitating better organization and coherence in the overall reasoning process. This modularity is further enhanced by using stage-level beam search, which efficiently scales inference time by allowing the model to select the most promising response at each stage. This method outperforms other scaling approaches like best-of-N or sentence-level beam search, demonstrating its effectiveness and the importance of a structured approach for VLMs.
LLaVA-01 Dataset#
The LLaVA-01 dataset is a crucial component of the research, addressing a significant gap in existing VQA datasets. Its novelty lies in the inclusion of structured reasoning annotations, moving beyond simple question-answer pairs to provide a step-by-step breakdown of the thought process. This structured format, generated using GPT-4, includes stages for summarization, captioning (visual interpretation), detailed reasoning, and finally, the conclusion. This structured approach is vital for training the LLaVA-01 model to perform autonomous multistage reasoning, a key differentiator from previous VLMs. The dataset integrates samples from various sources, combining general VQA datasets with science-focused ones, resulting in a diverse and comprehensive collection. The release of this dataset will likely spur further research in structured reasoning within the VLM field, making it a valuable contribution to the community and a powerful tool for advancing multimodal reasoning capabilities. The size of the dataset (100k samples) is also noteworthy given its high quality and structured nature, highlighting a significant improvement over many existing datasets that lack the detailed reasoning annotations.
Benchmark Analysis#
A robust benchmark analysis is crucial for evaluating the performance of LLAVA-01 and comparing it against existing models. The choice of benchmarks is key, ensuring they assess various aspects of visual-language reasoning, including both general VQA and specialized tasks like scientific reasoning or mathematical problem-solving. The results should be presented clearly, showcasing not only overall performance scores but also a granular breakdown by task type. This allows for a more in-depth understanding of LLAVA-01’s strengths and weaknesses. Statistical significance testing should be applied to confirm that observed differences between LLAVA-01 and other models are not due to random chance. Finally, the analysis must consider the limitations of the benchmarks themselves, acknowledging any potential biases or shortcomings that could affect the interpretation of results. Careful consideration of these factors will ensure a thorough and credible benchmark analysis providing valuable insights into the capabilities of LLAVA-01.
More visual insights#
More on figures

🔼 This figure showcases a comparison between the reasoning capabilities of two models: Llama-3.2-11B-Vision-Instruct (the base model) and LLaVA-01. Two example problems are presented, each involving visual reasoning. The base model demonstrates significant flaws and errors in its reasoning process, often producing inaccurate or illogical steps. In contrast, LLaVA-01 exhibits a systematic and structured approach. It starts by summarizing the problem, then extracts relevant information from the image, meticulously outlines a step-by-step reasoning process, and finally arrives at a logically sound and well-supported conclusion. This highlights LLaVA-01’s superior ability to perform systematic and structured reasoning compared to the base model.
read the caption
Figure 2: Comparison of the base model and LLaVA-o1. As shown, the base model Llama-3.2-11B-Vision-Instruct exhibits obvious flaws in reasoning, with several errors occurring throughout the reasoning process. In contrast, LLaVA-o1 begins by outlining the problem, interprets relevant information from the image, proceeds with a step-by-step reasoning process, and ultimately reaches a well-supported conclusion.

🔼 This figure illustrates the process of creating the LLaVA-01-100k dataset. The process starts with a question and involves four stages: 1. Summary: GPT-40 summarizes the question and outlines the overall approach. 2. Caption: If an image is part of the question, GPT-40 describes the relevant visual elements. 3. Reasoning: GPT-40 outlines a step-by-step logical reasoning process to answer the question. 4. Conclusion: GPT-40 provides the final answer. The outputs from each stage are then filtered to ensure high quality before being included in the dataset.
read the caption
Figure 3: Process flow for generating the LLaVA-o1-100k dataset. We prompt GPT-4o to generate responses in separate stages, and filter its outputs to ensure quality.

🔼 Figure 4 illustrates three different inference time scaling methods: Best-of-N search, sentence-level beam search, and the proposed stage-level beam search. Best-of-N search generates multiple complete answers and selects the single best one. This approach is computationally expensive and may not be effective when responses vary widely in quality. Sentence-level beam search generates multiple options for each sentence and chooses the best among them. This approach is quite granular, focusing on small portions of the text and potentially missing important contextual relationships. In contrast, the paper’s proposed stage-level beam search generates candidates for each stage of the reasoning process (summary, caption, reasoning, and conclusion) and selects the best option at each stage. By focusing on the broader reasoning structure and checking the quality of each step, it offers a better balance between efficiency and accuracy. The figure highlights that the stage-level approach achieves superior performance compared to the other two methods due to its optimal granularity.
read the caption
Figure 4: An illustration of inference approaches. Best-of-N search generates N𝑁Nitalic_N complete responses and selects the best one among them; Sentence-level Beam Search generates multiple candidate options for each sentence and chooses the best one. In contrast, our Stage-level Beam Search generates candidates for each reasoning stage (e.g., summary, caption, reasoning, and conclusion) and selects the best option at each stage. Best-of-N search operates at a coarse level, while Sentence-level Beam Search is overly granular, and our method achieves an optimal balance and achieves the best performance.

🔼 The figure showcases a comparison of LLaVA-01’s performance on a visual question answering task, both with and without the application of a stage-level beam search. Two examples of question-answering tasks are presented: one involving a simple counting problem and another involving a physics problem that necessitates a step-by-step reasoning process. For each problem, the figure displays the base model’s answer (Llama-3.2-11B-Vision-Instruct) and LLaVA-01’s answer. LLaVA-01’s answer shows the model’s step-by-step reasoning process through four distinct stages: summarization, captioning, reasoning, and conclusion. The base model’s answer is presented as a single step without explicit reasoning, showing its limitations in handling complex reasoning tasks. In contrast, LLaVA-01 demonstrates more robust reasoning by outlining the problem, interpreting relevant information from the image, engaging in structured step-by-step reasoning, and finally, providing well-supported conclusions. The comparison highlights that the stage-level beam search in LLaVA-01 is crucial for effective inference, enabling more accurate and systematic solutions to complex problems.
read the caption
Figure 5: Comparison of LLaVA-o1 performance with and without stage-level beam search. Our stage-level beam search is effective in selecting better reasoning during model inference.
More on tables
| Model | MMStar | MMBench | MMVet | MathVista | AI2D | Hallusion | Average |
|---|---|---|---|---|---|---|---|
| Base Model | |||||||
| Llama-3.2-11B-Vision-Instruct | 49.8 | 65.8 | 57.6 | 48.6 | 77.3 | 40.3 | 56.6 |
| Our Models | |||||||
| LLaVA-o1 (with Direct Training) | 54.3 | 76.2 | 49.9 | 49.5 | 91.4 | 42.9 | 60.7 |
| LLaVA-o1 (w/o Structured Tags) | 55.7 | 74.2 | 57.0 | 54.1 | 87.2 | 45.0 | 62.2 |
| LLaVA-o1 | 57.6 | 75.0 | 60.3 | 54.8 | 85.7 | 47.8 | 63.5 |
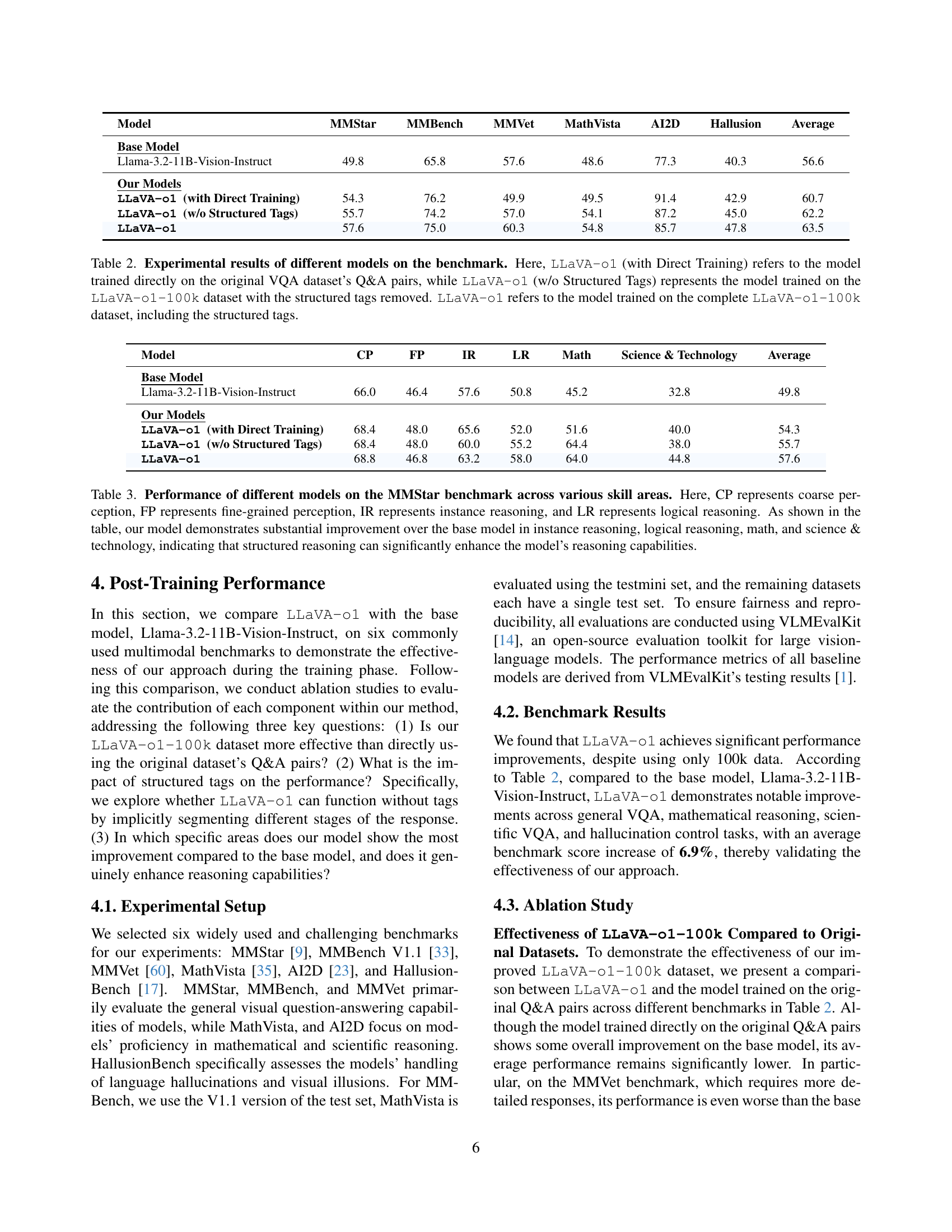
🔼 This table presents a comparison of the performance of different models on a multimodal reasoning benchmark. Three variations of the LLaVA-01 model are included: one trained directly on the original VQA dataset (without the structured reasoning stages), one trained on the LLaVA-01-100k dataset but without the structured tags used to denote reasoning stages, and a final version trained on the complete LLaVA-01-100k dataset with the structured tags. A baseline model (Llama-3.2-11B-Vision-Instruct) is also included for comparison. The results highlight the impact of the structured training data and tags on the model’s performance.
read the caption
Table 2: Experimental results of different models on the benchmark. Here, LLaVA-o1 (with Direct Training) refers to the model trained directly on the original VQA dataset’s Q&A pairs, while LLaVA-o1 (w/o Structured Tags) represents the model trained on the LLaVA-o1-100k dataset with the structured tags removed. LLaVA-o1 refers to the model trained on the complete LLaVA-o1-100k dataset, including the structured tags.
| Model | CP | FP | IR | LR | Math | Science & Technology | Average |
|---|---|---|---|---|---|---|---|
| Base Model | |||||||
| Llama-3.2-11B-Vision-Instruct | 66.0 | 46.4 | 57.6 | 50.8 | 45.2 | 32.8 | 49.8 |
| Our Models | |||||||
| LLaVA-o1 (with Direct Training) | 68.4 | 48.0 | 65.6 | 52.0 | 51.6 | 40.0 | 54.3 |
| LLaVA-o1 (w/o Structured Tags) | 68.4 | 48.0 | 60.0 | 55.2 | 64.4 | 38.0 | 55.7 |
| LLaVA-o1 | 68.8 | 46.8 | 63.2 | 58.0 | 64.0 | 44.8 | 57.6 |
🔼 Table 3 presents a detailed comparison of different models’ performance on the MMStar benchmark, broken down by specific skill areas: Coarse Perception (CP), Fine-grained Perception (FP), Instance Reasoning (IR), Logical Reasoning (LR), Math, and Science & Technology. The results highlight LLAVA-01’s significant improvement over the baseline model, particularly in the more complex reasoning tasks (IR, LR, Math, and Science & Technology), demonstrating the effectiveness of its structured reasoning approach in enhancing overall reasoning capabilities.
read the caption
Table 3: Performance of different models on the MMStar benchmark across various skill areas. Here, CP represents coarse perception, FP represents fine-grained perception, IR represents instance reasoning, and LR represents logical reasoning. As shown in the table, our model demonstrates substantial improvement over the base model in instance reasoning, logical reasoning, math, and science & technology, indicating that structured reasoning can significantly enhance the model’s reasoning capabilities.
| Model | MMStar | MMBench | MMVet | MathVista | AI2D | Hallusion | Average |
|---|---|---|---|---|---|---|---|
| Base Model | |||||||
| Llama-3.2-11B-Vision-Instruct | 49.8 | 65.8 | 57.6 | 48.6 | 77.3 | 40.3 | 56.6 |
| Our Models | |||||||
| LLaVA-o1 | 57.6 | 75.0 | 60.3 | 54.8 | 85.7 | 47.8 | 63.5 |
| LLaVA-o1 (BS = 2) | 58.1 | 75.6 | 61.7 | 56.1 | 87.5 | 48.2 | 64.5 |
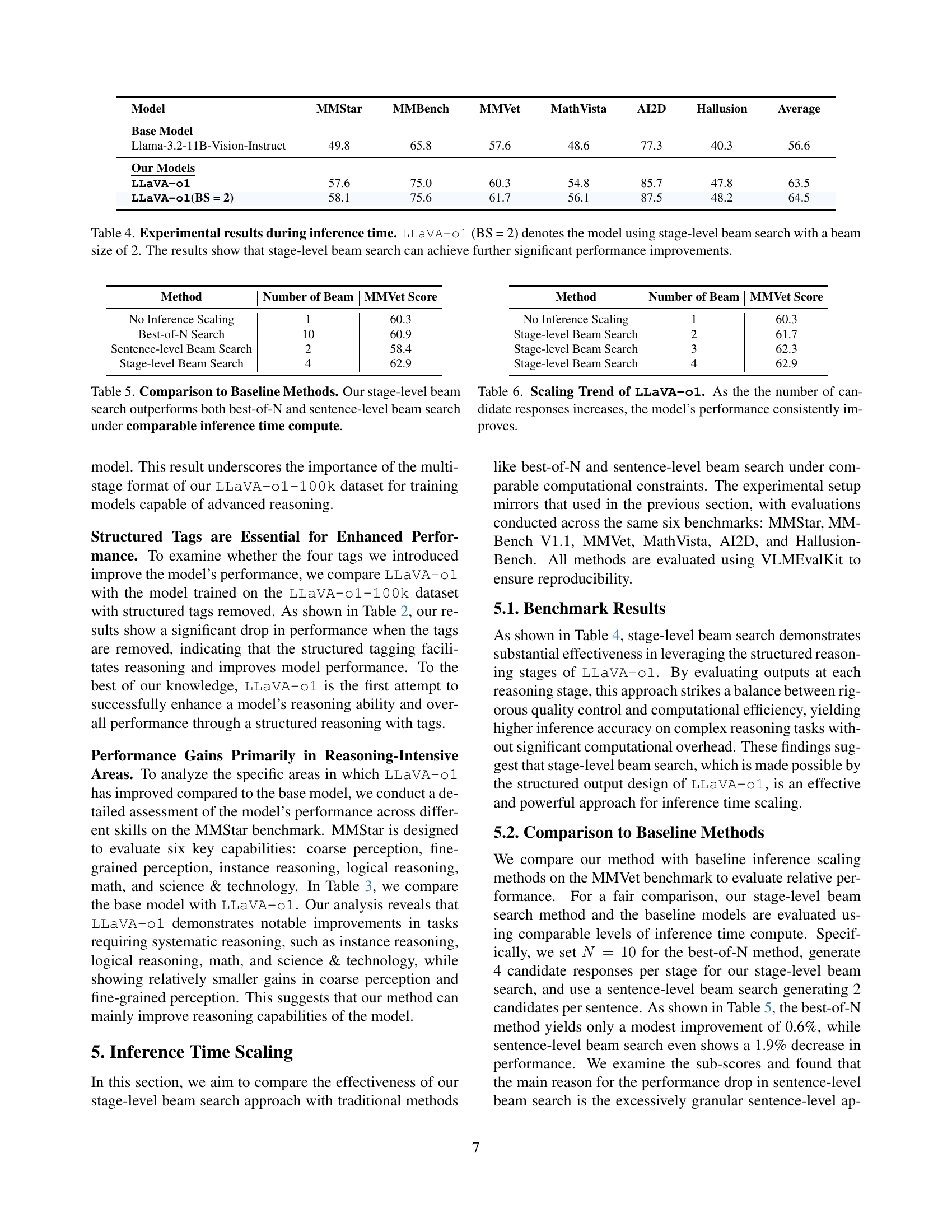
🔼 This table presents the performance comparison of different models during inference time. Specifically, it contrasts the performance of the LLaVA-01 model without any inference-time scaling techniques, against the same model using a stage-level beam search with a beam size of 2 (LLaVA-01 (BS=2)). The results highlight the significant performance gains achieved by employing the stage-level beam search method, demonstrating its effectiveness in improving the model’s reasoning capabilities during inference.
read the caption
Table 4: Experimental results during inference time. LLaVA-o1 (BS = 2) denotes the model using stage-level beam search with a beam size of 2. The results show that stage-level beam search can achieve further significant performance improvements.
| Method | Number of Beam | MMVet Score |
|---|---|---|
| No Inference Scaling | 1 | 60.3 |
| Best-of-N Search | 10 | 60.9 |
| Sentence-level Beam Search | 2 | 58.4 |
| Stage-level Beam Search | 4 | 62.9 |
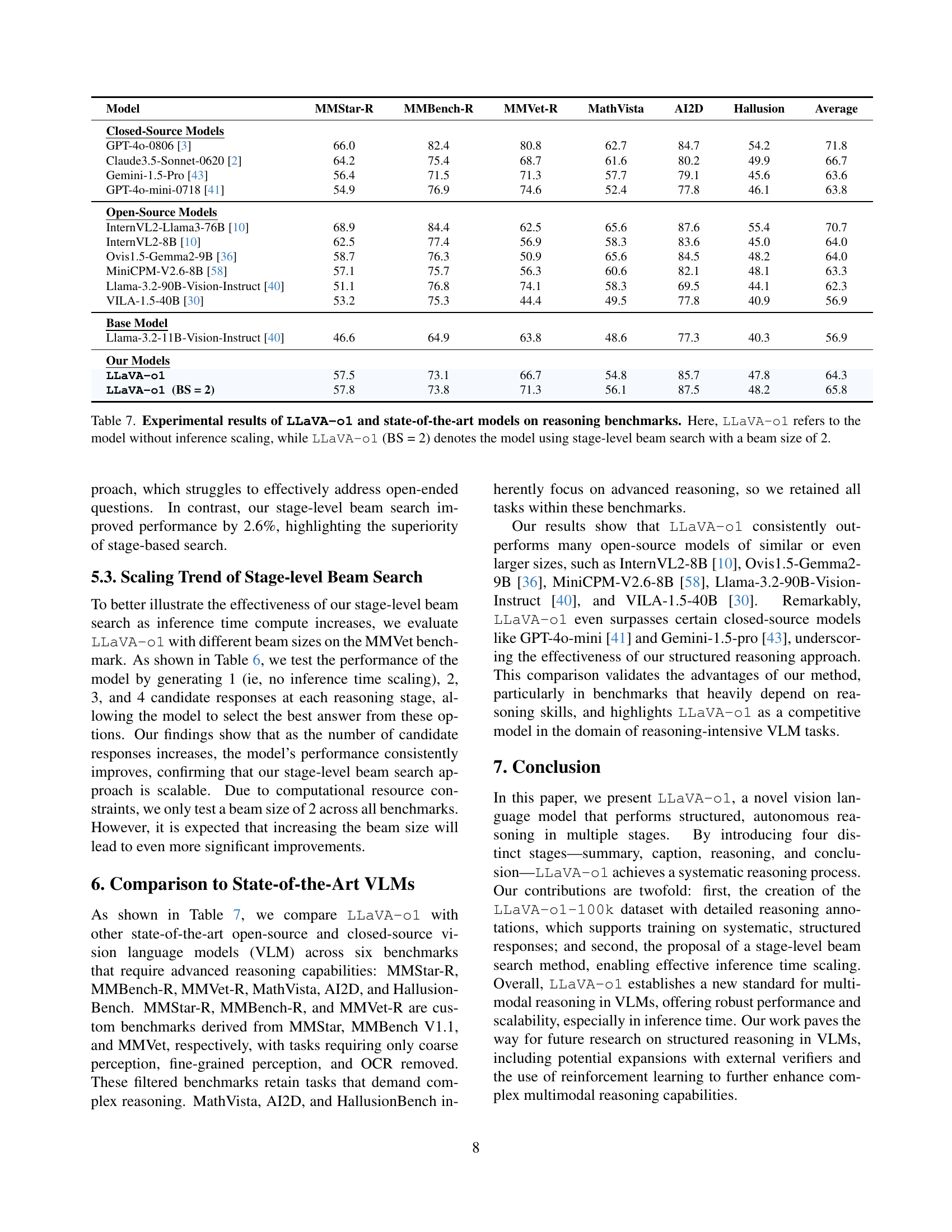
🔼 Table 7 presents a comparative analysis of the performance of LLaVA-01 and other state-of-the-art vision-language models (VLMs) across six reasoning benchmarks. These benchmarks assess various reasoning capabilities, including general visual question answering, mathematical reasoning, scientific reasoning, and handling of hallucinations and visual illusions. The table specifically contrasts the performance of LLaVA-01 without inference-time scaling and LLaVA-01 with a stage-level beam search (using a beam size of 2). This comparison highlights the impact of the proposed inference-time scaling technique on the overall performance of the model.
read the caption
Table 7: Experimental results of LLaVA-o1 and state-of-the-art models on reasoning benchmarks. Here, LLaVA-o1 refers to the model without inference scaling, while LLaVA-o1 (BS = 2) denotes the model using stage-level beam search with a beam size of 2.
Full paper#