↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multimodal Large Language Models (MLLMs) are increasingly popular, but training a single model to handle various tasks (like image captioning and object detection) effectively is challenging. Simply combining datasets from different tasks often leads to a problem known as “multi-task conflict,” which significantly reduces performance across all tasks.
This paper introduces Awaker2.5-VL, a new model architecture designed to solve this problem. Awaker2.5-VL uses a Mixture of Experts (MoE) approach, where several specialized “expert” models handle different types of tasks. Importantly, it uses a parameter-efficient method to keep training costs low and achieved state-of-the-art results on various benchmarks. This shows that Awaker2.5-VL is an effective and scalable solution for training high-performing MLLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the multi-task conflict issue in Multimodal Large Language Models (MLLMs) by proposing a novel Mixture of Experts (MoE) architecture. This is a critical problem hindering the development of robust and efficient MLLMs for real-world applications. The research also introduces a parameter-efficient approach using low-rank adaptation, thus making it cost-effective to train and deploy large-scale multimodal models. The proposed Awaker2.5-VL achieved state-of-the-art results on various benchmarks, demonstrating its effectiveness and opening up new avenues for research in this exciting and rapidly developing field.
Visual Insights#

🔼 This figure illustrates the architecture of the Mixture of Experts (MoE) model used in Awaker2.5-VL. It shows the base model (with frozen parameters), multiple expert modules (each a LoRA structure), and a gating network that controls which experts are activated for each input. The input data (image and text) is processed by the base model, and the output is combined with outputs from the activated expert(s) to produce the final output. A global expert module is always active to ensure versatility and generalization. The gating network uses a softmax function and top-k selection to choose the most suitable experts. The figure also visually depicts the flow of information within the model.
read the caption
Figure 1: The Standard MoE Structure in Awaker2.5-VL.
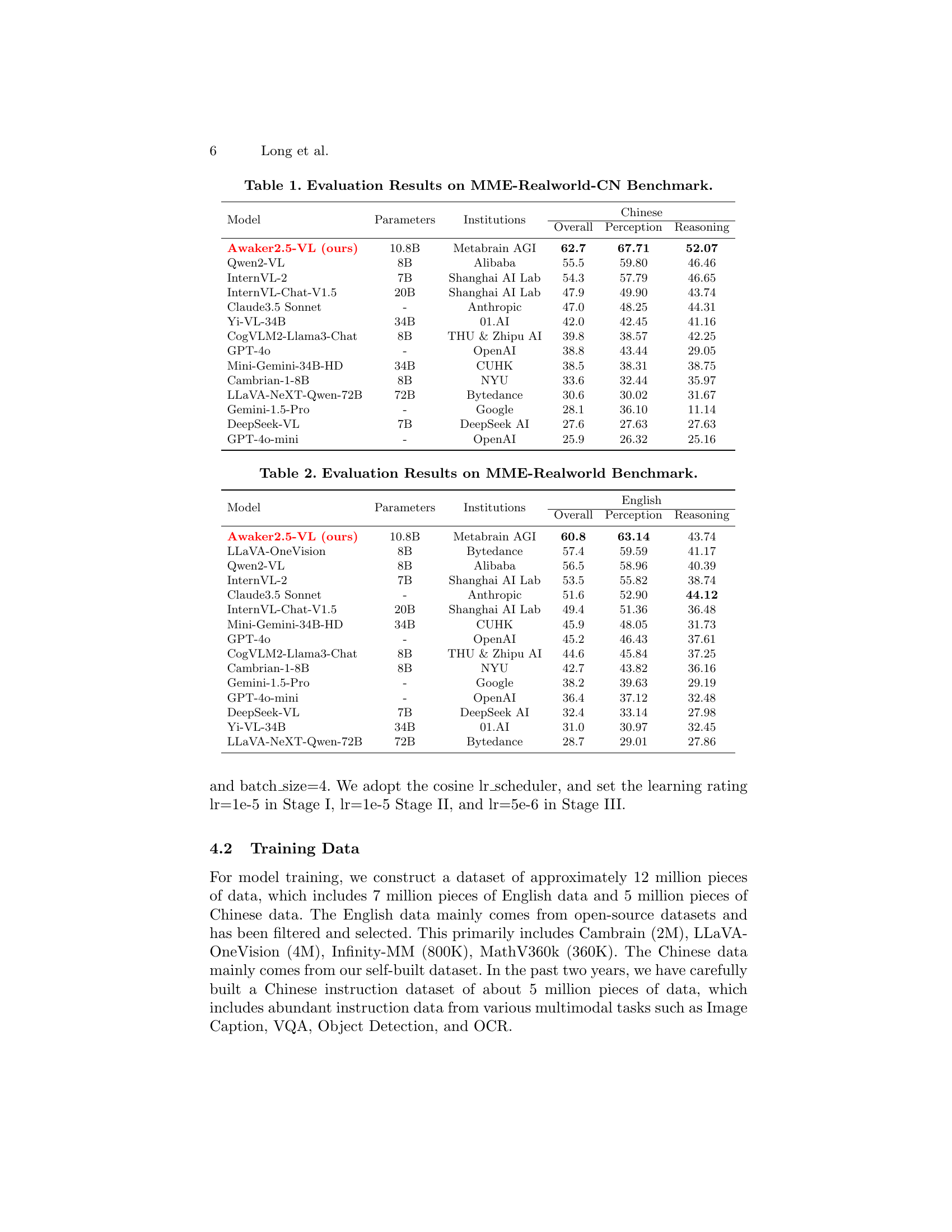
| Model | Parameters | Institutions | Chinese Overall | Chinese Perception | Chinese Reasoning |
|---|---|---|---|---|---|
| Awaker2.5-VL (ours) | 10.8B | Metabrain AGI | 62.7 | 67.71 | 52.07 |
| Qwen2-VL | 8B | Alibaba | 55.5 | 59.80 | 46.46 |
| InternVL-2 | 7B | Shanghai AI Lab | 54.3 | 57.79 | 46.65 |
| InternVL-Chat-V1.5 | 20B | Shanghai AI Lab | 47.9 | 49.90 | 43.74 |
| Claude3.5 Sonnet | - | Anthropic | 47.0 | 48.25 | 44.31 |
| Yi-VL-34B | 34B | 01.AI | 42.0 | 42.45 | 41.16 |
| CogVLM2-Llama3-Chat | 8B | THU & Zhipu AI | 39.8 | 38.57 | 42.25 |
| GPT-4o | - | OpenAI | 38.8 | 43.44 | 29.05 |
| Mini-Gemini-34B-HD | 34B | CUHK | 38.5 | 38.31 | 38.75 |
| Cambrian-1-8B | 8B | NYU | 33.6 | 32.44 | 35.97 |
| LLaVA-NeXT-Qwen-72B | 72B | Bytedance | 30.6 | 30.02 | 31.67 |
| Gemini-1.5-Pro | - | 28.1 | 36.10 | 11.14 | |
| DeepSeek-VL | 7B | DeepSeek AI | 27.6 | 27.63 | 27.63 |
| GPT-4o-mini | - | OpenAI | 25.9 | 26.32 | 25.16 |
🔼 This table presents a comprehensive evaluation of various multimodal large language models (MLLMs) on the MME-Realworld-CN benchmark. The benchmark focuses on real-world Chinese scenarios, encompassing diverse tasks. The table shows the performance of each model across three key dimensions: Overall, Perception, and Reasoning. Model parameters, the institution responsible for the model, and the specific scores for each dimension are provided for comparison.
read the caption
Table 1: Evaluation Results on MME-Realworld-CN Benchmark.
In-depth insights#
MoE for MLLMs#
Mixture of Experts (MoE) presents a compelling approach for scaling Multimodal Large Language Models (MLLMs). The core idea is to distribute the computational load across multiple specialized expert networks, each focusing on a subset of tasks or data modalities, rather than relying on a single monolithic model. This offers significant advantages: improved efficiency by avoiding redundancy; enhanced scalability by allowing for larger models without proportionally increasing computational costs; and the capacity for handling diverse data distributions inherent in multimodal data (e.g., images, text, audio). However, effective implementation requires careful consideration of gating mechanisms to select appropriate experts for a given input, and efficient routing strategies to minimize latency. The effectiveness of MoE relies heavily on its ability to effectively distribute tasks and prevent interference between experts. Poorly designed gating or routing can lead to instability and suboptimal performance. Furthermore, while the reduced parameter count offers efficiency benefits, the overhead of managing multiple experts needs to be carefully accounted for. The success of MoE in MLLMs hinges on a robust architecture that balances expert specialization with efficient coordination, ensuring that the resulting model is not only efficient but also maintains performance and generalizability across diverse multimodal tasks.
Stable Scaling#
Stable scaling in large language models (LLMs) addresses the challenge of maintaining performance and efficiency as model size increases. Simply scaling up parameters doesn’t guarantee improved results, often leading to higher computational costs and potential instability. The concept of ‘stable scaling’ thus emphasizes methods to mitigate the multi-task conflict that can arise when combining various data sources. This involves using techniques such as Mixture of Experts (MoE) architectures to distribute tasks efficiently among specialized modules, and employing low-rank adaptation (LoRA) for parameter-efficient fine-tuning. Careful design of the routing strategy within MoE is crucial to ensure stable training and inference. A stable scaling approach ultimately aims to provide a balanced improvement in performance and resource utilization as the model grows in size and complexity.
LoRA Experts#
The concept of “LoRA Experts” suggests a novel approach to building efficient and effective multimodal large language models (MLLMs). It leverages the low-rank adaptation (LoRA) technique to create specialized expert modules within a Mixture of Experts (MoE) architecture. This is a significant improvement over traditional methods because it reduces computational costs associated with training and inference. By using LoRA, each expert model only requires learning a small set of parameters, rather than the entire model’s parameters. This parameter-efficient approach enables the stable scaling of MLLMs to handle diverse visual and textual tasks. The use of multiple LoRA experts allows the model to specialize in different aspects of multimodal understanding, improving overall performance and mitigating the “multi-task conflict” issue that plagues traditional MLLM approaches. The strategy shows promise for creating powerful yet resource-conscious AI systems, opening the door to more accessible and scalable MLLMs.
Multi-task conflict#
The concept of “multi-task conflict” in the context of Multimodal Large Language Models (MLLMs) highlights a critical challenge in training these models to handle diverse tasks simultaneously. Simply combining datasets from various tasks (like VQA, object detection, OCR) leads to performance degradation because the models struggle to reconcile the differing data representations and distributions. This conflict arises from the inherent differences in the tasks themselves, requiring distinct feature representations and prediction mechanisms. A single model architecture attempting to master all tasks at once can become inefficient and unstable, compromising its overall competence. The paper’s proposed solution, Awaker2.5-VL, leverages a Mixture of Experts (MoE) architecture to address this issue by using specialized expert networks for specific task types and enabling them to focus on their respective data distributions. This approach reduces the burden on each model and promotes specialization for improved performance, overcoming the inherent limitations of a monolithic model approach that struggles with the varied demands of multiple tasks.
Future Work#
The authors outline crucial future directions for enhancing Awaker2.5-VL. Improving prompt embeddings for routing is paramount, acknowledging limitations of shallow embeddings, especially for complex text prompts. Exploring richer representations will likely improve routing efficiency and model performance. Expanding the MoE architecture to the ViT side of the multimodal model is another key area. Currently, MoE is only applied to the LLM component; integrating it into the ViT would likely improve the handling of visual information and potentially lead to a more balanced and powerful multimodal understanding. Finally, applying the MoE routing strategy to the LLM side is a significant research gap to be addressed. These enhancements would contribute towards a more robust, efficient, and effective multimodal large language model.
More visual insights#
More on figures

🔼 This figure shows a simplified version of the Mixture of Experts (MoE) architecture used in the Awaker2.5-VL model. Unlike the standard MoE structure (shown in Figure 1), this simplified version removes the gate layer. Instead, it directly accepts the gate results (Gglobal and Gexperts) calculated in another MoE module for routing. This simplifies the architecture and improves training stability. The figure highlights the input (x), the MoE module, the gate result (Gglobal and Gmax), and the final output (y).
read the caption
Figure 2: The Simplified MoE Structure in Awaker2.5-VL.

🔼 This figure illustrates the three-stage training pipeline for the Awaker2.5-VL model. Stage I involves initializing the model by training only the LoRA parameters while keeping the base model frozen. Stage II trains the MoE module, replacing the LoRA module from Stage I and again freezing the base model. The MoE module includes the gate layer and all experts. Finally, Stage III performs instruction fine-tuning, focusing on training only the experts within the MoE module while keeping the gate layer frozen. Each stage builds upon the previous one, progressively enhancing the model’s capabilities.
read the caption
Figure 3: The Traing Pipeline of Awaker2.5-VL. From Left to Right: Stage I, Stage II, and Stage III.
More on tables
| Model | Parameters | Institutions | English Overall | English Perception | English Reasoning |
|---|---|---|---|---|---|
| Awaker2.5-VL (ours) | 10.8B | Metabrain AGI | 60.8 | 63.14 | 43.74 |
| LLaVA-OneVision | 8B | Bytedance | 57.4 | 59.59 | 41.17 |
| Qwen2-VL | 8B | Alibaba | 56.5 | 58.96 | 40.39 |
| InternVL-2 | 7B | Shanghai AI Lab | 53.5 | 55.82 | 38.74 |
| Claude3.5 Sonnet | - | Anthropic | 51.6 | 52.90 | 44.12 |
| InternVL-Chat-V1.5 | 20B | Shanghai AI Lab | 49.4 | 51.36 | 36.48 |
| Mini-Gemini-34B-HD | 34B | CUHK | 45.9 | 48.05 | 31.73 |
| GPT-4o | - | OpenAI | 45.2 | 46.43 | 37.61 |
| CogVLM2-Llama3-Chat | 8B | THU & Zhipu AI | 44.6 | 45.84 | 37.25 |
| Cambrian-1-8B | 8B | NYU | 42.7 | 43.82 | 36.16 |
| Gemini-1.5-Pro | - | 38.2 | 39.63 | 29.19 | |
| GPT-4o-mini | - | OpenAI | 36.4 | 37.12 | 32.48 |
| DeepSeek-VL | 7B | DeepSeek AI | 32.4 | 33.14 | 27.98 |
| Yi-VL-34B | 34B | 01.AI | 31.0 | 30.97 | 32.45 |
| LLaVA-NeXT-Qwen-72B | 72B | Bytedance | 28.7 | 29.01 | 27.86 |
🔼 This table presents a comprehensive evaluation of various multimodal large language models (MLLMs) on the MME-Realworld benchmark. The benchmark focuses on real-world image datasets and evaluates the models’ performance across three key aspects: overall accuracy, perception capabilities, and reasoning skills. The table includes the model name, its parameter count, the institution that developed it, and the quantitative results for each evaluation aspect.
read the caption
Table 2: Evaluation Results on MME-Realworld Benchmark.
| Model | Parameters | Institutions | Chinese Overall | Chinese MMBench_v1.1 | Chinese MMBench |
|---|---|---|---|---|---|
| Qwen2-VL-72B | 73.4B | Alibaba | 86.3 | 85.8 | 86.7 |
| InternVL2-40B | 40B | Shanghai AI Lab | 85.7 | 84.9 | 86.4 |
| InternVL2-Llama-76B | 76B | Shanghai AI Lab | 85.5 | 85.5 | - |
| Taiyi | - | Megvii | 85.2 | 85.0 | 85.4 |
| JT-VL-Chat-V3.0 | - | China Mobile | 84.7 | 83.5 | 85.8 |
| LLaVA-OneVision-72B | 73B | ByteDance | 84.6 | 83.9 | 85.3 |
| Step-1.5V | - | StepFun | 84.0 | 83.5 | 84.5 |
| Claude3.5-Sonnet-20241022 | - | Anthropic | 83.0 | 82.5 | 83.5 |
| Awaker2.5-VL (ours) | 10.8B | Metabrain AGI | 82.6 | 81.8 | 83.4 |
| GPT-4o (0513, detail-low) | - | OpenAI | 82.3 | 82.5 | 82.1 |
| LLaVA-OneVision-7B | 8B | ByteDance | 81.8 | 80.9 | 82.7 |
| GPT-4o (0513, detail-high) | - | OpenAI | 81.8 | 81.5 | 82.1 |
| InternVL2-26B | 26B | Shanghai AI Lab | 81.5 | 80.9 | 82.1 |
| CongROng | - | CloudWalk | 81.2 | 80.4 | 81.9 |
| MMAlaya2 | 26B | DataCanvas | 80.9 | 79.7 | 82.1 |
| Ovis1.6-Gemma2-9B | 10.2B | Alibaba | 80.8 | 79.5 | 82.0 |
| Qwen2-VL-7B | 8B | Alibaba | 80.5 | 80.3 | 80.6 |
| LLaVA-OneVision-72B (SI) | 73B | ByteDance | 80.0 | 81.9 | 78.0 |
| InternVL-Chat-V1.5 | 26B | Shanghai AI Lab | 79.9 | 79.1 | 80.7 |
| InternLM-XComposer2.5 | 8B | Shanghai AI Lab | 79.9 | 78.8 | 80.9 |
| GPT-4o (0806, detail-high) | - | OpenAI | 79.8 | 79.2 | 80.3 |
| GPT-4V (0409, detail-high) | - | OpenAI | 79.2 | 78.2 | 80.2 |
🔼 This table presents a comprehensive evaluation of various multimodal large language models (MLLMs) on the MMBench-CN benchmark. The benchmark focuses on evaluating the performance of these models across a range of visual and language understanding tasks within the Chinese language. The table lists each model, its number of parameters, the institution that developed it, and its performance scores across the overall benchmark and on two sub-benchmarks: MMBench_v1.1 and MMBench. The scores provide a comparative analysis of the models’ abilities in various visual and language understanding tasks.
read the caption
Table 3: Evaluation Results on MMBench-CN Benchmark.
| Model | Parameters | Institutions | English Overall | English MMBench_v1.1 | English MMBench |
|---|---|---|---|---|---|
| Qwen2-VL-72B | 73.4B | Alibaba | 86.5 | 86.1 | 86.9 |
| InternVL2-40B | 40B | Shanghai AI Lab | 86.0 | 85.1 | 86.8 |
| Taiyi | - | Megvii | 85.7 | 84.7 | 86.7 |
| InternVL2-Llama-76B | 76B | Shanghai AI Lab | 85.5 | 85.5 | - |
| LLaVA-OneVision-72B | 73B | ByteDance | 85.4 | 85.0 | 85.8 |
| JT-VL-Chat-V3.0 | - | China Mobile | 84.5 | 83.6 | 85.4 |
| Awaker2.5-VL (ours) | 10.8B | Metabrain AGI | 83.7 | 82.5 | 84.9 |
| GPT-4o (0513, detail-high) | - | OpenAI | 83.2 | 83.0 | 83.4 |
| GPT-4o (0513, detail-low) | - | OpenAI | 83.2 | 83.1 | 83.3 |
| Step-1.5V | - | StepFun | 82.9 | 80.4 | 85.3 |
| InternVL2-26B | 26B | Shanghai AI Lab | 82.5 | 81.5 | 83.4 |
| Ovis1.6-Gemma2-9B | 10.2B | Alibaba | 82.5 | 81.5 | 83.4 |
| RBDash-v1.2-72B | 79B | DLUT | 82.5 | 81.7 | 83.2 |
| Qwen2-VL-7B | 8B | Alibaba | 82.4 | 81.8 | 83.0 |
| LLaVA-OneVision-7B | 8B | ByteDance | 82.1 | 80.9 | 83.2 |
| GPT-4o (0806, detail-high) | - | OpenAI | 82.0 | 81.8 | 82.1 |
| LLaVA-OneVision-72B (SI) | 73B | ByteDance | 81.9 | 83.3 | 80.5 |
| Qwen-VL-Plus-0809 | - | Alibaba | 81.9 | 81.1 | 82.7 |
| CongROng | - | CloudWalk | 81.9 | 80.9 | 82.8 |
| Claude3.5-Sonnet-20241022 | - | Anthropic | 81.8 | 80.9 | 82.6 |
| MMAlaya2 | 26B | DataCanvas | 81.6 | 80.6 | 82.5 |
| InternVL-Chat-V1.5 | 26B | Shanghai AI Lab | 81.3 | 80.3 | 82.3 |
| InternLM-XComposer2.5 | 8B | Shanghai AI Lab | 81.1 | 80.1 | 82.0 |
| GPT-4V (0409, detail-high) | - | OpenAI | 80.5 | 80.0 | 81.0 |
🔼 This table presents a comprehensive comparison of various multimodal large language models (MLLMs) on the MMBench benchmark. The benchmark assesses performance across multiple dimensions of visual-language understanding, including overall performance, MMBench v1.1, and MMBench. It provides parameters, institutions responsible for the models, and the scores for each model on each of the three dimensions for a set of models, including the model proposed in the paper.
read the caption
Table 4: Evaluation Results on MMBench Benchmark.
Full paper#