↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video generation methods often struggle with precise control, especially when integrating multiple control signals like text prompts, user annotations and camera movements. This leads to inconsistencies, flickering and poor video quality. Many existing approaches either rely solely on text, lacking detail, or focus only on specific aspects of control, ignoring the complex interplay between different control modalities.
AnimateAnything solves these issues with a two-stage process. First, it converts various control signals into a unified optical flow representation, enabling seamless integration of diverse inputs. Second, it employs a frequency-based stabilization module to improve temporal consistency. This leads to videos that are more coherent, stable, and high-quality than current methods, outperforming state-of-the-art approaches in experiments. The system excels in handling diverse inputs, showcasing enhanced controllability and video quality.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to controllable video generation, addressing the limitations of existing methods that struggle with precise control and consistency across various conditions. Its unified optical flow representation and frequency-based stabilization module significantly enhance video quality and stability. This work opens avenues for advancements in film production, virtual reality, and other applications demanding high-quality and controllable video content. The proposed approach is highly versatile, handling various control signals (text prompts, user annotations, camera trajectories) effectively, making it valuable for researchers seeking robust, versatile solutions in video generation.
Visual Insights#

🔼 This figure showcases the capabilities of the ‘AnimateAnything’ approach. It demonstrates consistent and controllable animation generation from various control signals (user prompts and a reference image). The animation maintains the appearance details of the reference object, producing clear, stable videos of animated characters, even with diverse control inputs.
read the caption
Figure 1: Animate anything. Consistent and controllable animation for different kinds of control signals. Given a reference image and corresponding user prompts, our approach can animate arbitrary characters, generating clear stable videos while maintaining consistency with the appearance details of the reference object.
| Basic Trajectory | Difficult Trajectory | |
|---|---|---|
| DUSt3R | VggSfM | |
| T-Err ↓ | R-Err ↓ | |
| CameraCtrl | 0.090 | 0.300 |
| MotionCtrl | 0.057 | 0.233 |
| Ours | 0.041 | 0.159 |
🔼 This table presents a quantitative comparison of camera trajectory estimation methods. It evaluates the accuracy of three different Structure-from-Motion (SfM) algorithms: DUSt3R, VggSfM, and ParticleSfM, in estimating camera poses. The comparison includes results from previous state-of-the-art methods (CameraCtrl and MotionCtrl), focusing on both basic (regularly sampled) and difficult (irregularly sampled) camera trajectories. The evaluation metrics used are translation error (T-Err) and rotation error (R-Err), which measure the deviation between the estimated and ground truth camera poses. Lower values for T-Err and R-Err indicate better accuracy.
read the caption
Table 1: Quantitative comparisons (Pose got by DUSt3R, VggSfM, and ParticleSfM). We compare against prior works on basic trajectory and random trajectory respectively. T-Err, R-Err represent translation error and rotation error.
In-depth insights#
Unified Flow Control#
The concept of “Unified Flow Control” in video generation aims to harmonize diverse control signals into a consistent representation to guide the video generation process. This addresses a key challenge in controllable video generation where different input modalities (text, user annotations, camera trajectories) often conflict, leading to unstable or inconsistent outputs. A unified representation, such as optical flow, facilitates this harmony by encapsulating various control signals into a common framework. This approach simplifies the process for users, reduces the need for complex parameter tuning, and improves the quality and coherence of generated videos. The key advantage is the ability to seamlessly combine local and global motion, resulting in more natural-looking and less jarring animations. By transforming disparate inputs into a single, interpretable form, the system achieves increased precision and control, surpassing the limitations of methods that treat each input modality in isolation.
Freq. Stabilization#
The research paper introduces a frequency-based stabilization module to address flickering issues and improve temporal coherence in generated videos. This is a crucial aspect, as large-scale motion often leads to inconsistencies in generated video frames. By analyzing the frequency domain of video features, the module identifies and suppresses instabilities effectively, enhancing the overall quality. The method uses FFT to transform temporal features into the frequency domain, applies a parameterized weight matrix to selectively modify these features, and then uses InvFFT to restore the modified temporal features. This targeted modification in the frequency domain ensures consistency across frames, resulting in smoother and more visually appealing videos. This approach is particularly innovative because it tackles a fundamental limitation of many video generation models, addressing a core challenge in achieving high-quality, stable video outputs. The efficacy of this frequency stabilization technique is demonstrated through experimental results, confirming its contribution to producing visually superior and temporally coherent videos. The module’s design highlights a shift from solely relying on temporal feature analysis to a more comprehensive approach that leverages both temporal and frequency-domain information for optimal video generation.
I2V Generation#
Image-to-video (I2V) generation is a rapidly evolving field aiming to synthesize realistic videos from still images. The core challenge lies in creating temporally coherent and visually plausible motion from a single static input. Existing methods often struggle with generating diverse and controlled motion, frequently resulting in unnatural or repetitive animations. Key advancements involve leveraging optical flow to guide motion generation, utilizing multi-modal conditioning (combining image information with text or other cues), and employing diffusion models for superior quality and controllability. The effectiveness of I2V generation is largely dependent on the quality and type of input image, the complexity of the desired motion, and the sophistication of the underlying model architecture. Future research should focus on handling more complex scenes and interactions, improving control over fine-grained details, and developing more efficient and scalable methods for generating high-quality, long-form videos.
Multi-Modal Control#
Multi-modal control in video generation aims to integrate diverse input modalities beyond text, such as image annotations, camera trajectories, and user-drawn sketches, to precisely manipulate video content. A key challenge lies in harmonizing these disparate signals, each possessing unique characteristics and levels of detail. Success hinges on finding a common representational space—like optical flow—that encapsulates the intent of all control inputs. Unified flow generation is crucial, requiring careful design of injection modules to handle explicit signals (easily converted to optical flow) and implicit ones (requiring complex interpretation). The effectiveness of multi-modal control also hinges on addressing inherent conflicts between local and global motions, and maintaining temporal coherence to avoid visual artifacts. Frequency-based stabilization techniques can be vital for achieving high-quality, consistent video outputs. The ultimate goal is intuitive, user-friendly control over dynamic video generation, bridging the gap between high-level creative intent and fine-grained visual manipulation.
Future of I2V#
The future of image-to-video (I2V) generation hinges on several key advancements. Improved controllability is paramount; current methods often struggle with precise manipulation of objects and camera movement. Future I2V models must seamlessly integrate diverse control signals (text, user annotations, reference videos) to enable highly nuanced video editing. Enhanced realism is another critical area, requiring better handling of complex interactions, such as lighting, shadows, and occlusions. This may involve leveraging physics-based simulations and advanced rendering techniques. Addressing temporal consistency remains challenging; future work should focus on techniques that prevent flickering and maintain smooth, coherent motion throughout the video. Finally, scalability and efficiency are crucial for broader applications. More efficient architectures and training methodologies are needed to enable I2V generation on consumer-grade hardware, opening up possibilities for real-time video creation and interactive editing experiences.
More visual insights#
More on figures

🔼 This figure demonstrates the optical flow generated by the AnimateAnything model under various control conditions. The top row shows the optical flow generated when only camera trajectory is used as input. The middle row displays the optical flow resulting from arrow-based motion annotations alone. The bottom row illustrates the combined effect of both camera trajectory and arrow-based annotations on the generated optical flow. This highlights the model’s ability to integrate multiple types of control signals to produce a unified representation of motion.
read the caption
Figure 2: The generated optical flow by our method with different condition signals. Given a specific image, from top to bottom are optical flows generated with camera trajectory, arrow-based motion annotation, and both conditions, respectively.

🔼 AnimateAnything uses a two-stage pipeline for video generation. Stage 1, Unified Flow Generation, combines various control signals (camera trajectory, motion annotations, etc.) into a unified optical flow representation using two synchronized latent diffusion models: the Flow Generation Model (FGM) and the Camera Reference Model (CRM). The FGM handles sparse/coarse optical flows from sources except camera trajectory, while the CRM processes the encoded reference image and camera trajectory to generate multi-level reference features that guide FGM’s denoising process. Stage 2, Video Generation, takes this unified optical flow, compresses it with a 3D VAE encoder, integrates it with video latents from an image encoder via a ViT block, and combines it with text embeddings to generate the final video using DiT blocks.
read the caption
Figure 3: AnimateAnything Pipeline. The pipeline consists of two stages: 1) Unified Flow Generation, which creates a unified optical flow representation by leveraging visual control signals through two synchronized latent diffusion models, namely the Flow Generation Model (FGM) and the Camera Reference Model (CRM). The FGM accepts sparse or coarse optical flow derived from visual signals other than camera trajectory. The CRM inputs the encoded reference image and camera trajectory embedding to generate multi-level reference features. These features are fed into a reference attention layer to progressively guide the FGM’s denoising process in each time step, producing a unified dense optical flow. 2) Video Generation, which compresses the generated unified flow with a 3D VAE encoder and integrates it with video latents from the image encoder using a single ViT block. The final output is then combined with text embeddings to generate the final video using the DiT blocks.

🔼 This module enhances video stability by operating in the frequency domain. It takes input features, applies a Fast Fourier Transform (FFT) to convert them to the frequency domain, modifies these features using a parameterized weight matrix and an inverse FFT (InvFFT) to return to the time domain. This process helps to suppress instability and flickering by adjusting temporal frequency components. The architecture diagram shows the FFT, frequency adaptors, inverse FFT, and the subsequent application of the modified features via pixel-wise multiplication.
read the caption
Figure 4: Video stabilization Module

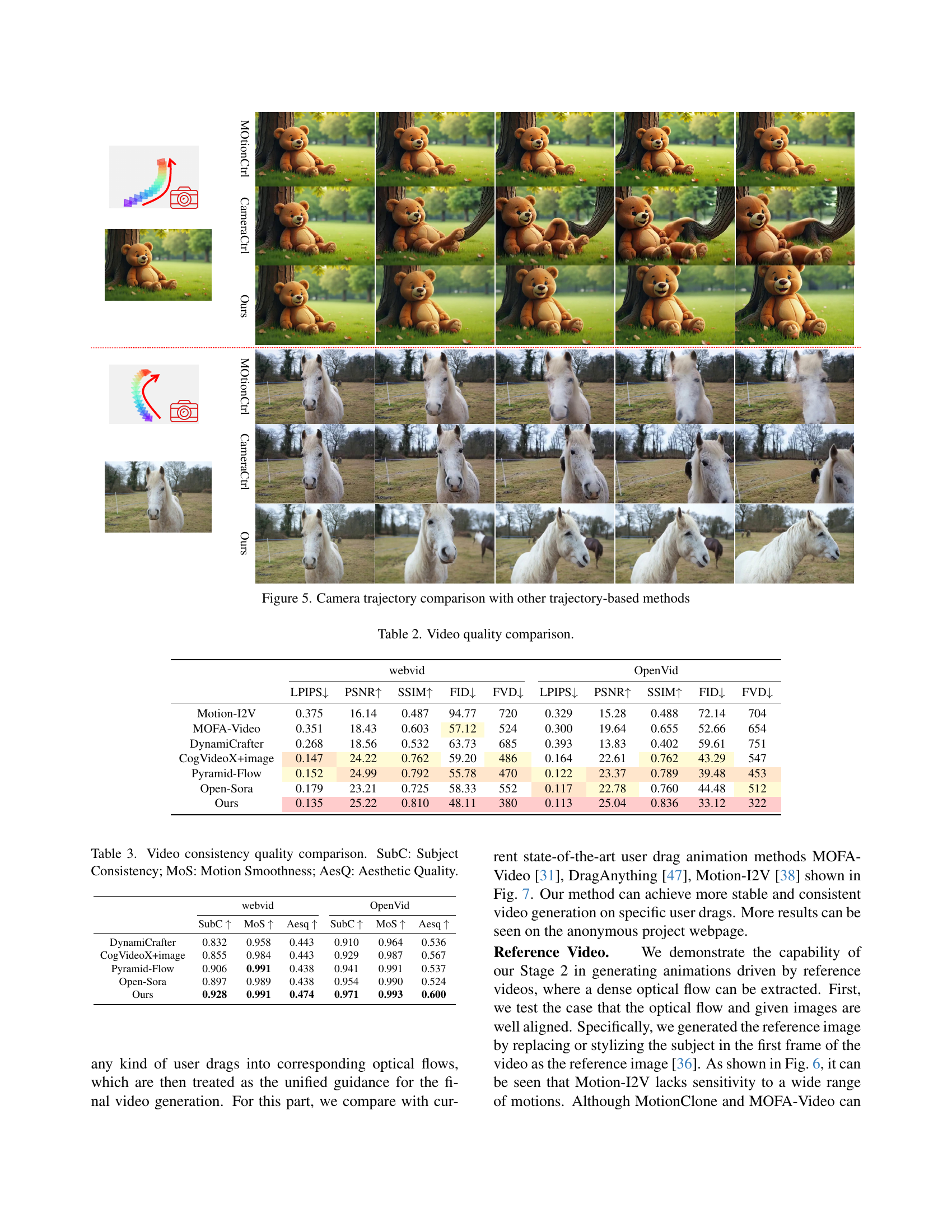
🔼 Figure 5 presents a comparison of camera trajectory estimations produced by different methods, including CameraCtrl, MotionCtrl, and the proposed method. It visualizes how accurately each method reconstructs the camera path from video frames. The figure aims to showcase the superiority of the proposed approach in terms of precision and consistency in estimating camera movements, which is a crucial aspect for high-quality video generation.
read the caption
Figure 5: Camera trajectory comparison with other trajectory-based methods

🔼 Figure 6 demonstrates the capability of the proposed method in motion transfer tasks by comparing it with several state-of-the-art approaches. The figure showcases examples of video generation guided by optical flow extracted from a reference video. It visually compares the results of the proposed method against those obtained using Motion-I2V, MOFA-Clone, and Motion-Videos, highlighting differences in motion consistency, style preservation, and artifact reduction. This comparison aims to show the superior performance of the proposed method in accurately transferring motion while maintaining the style and details of the original video.
read the caption
Figure 6: Motion Transfer comparison with state-of-the-art methods.

🔼 Figure 7 presents a comparison of animation results generated by different methods using user-provided drag annotations as input. It demonstrates the capability of various approaches to interpret user-drawn motion cues and produce realistic-looking animations, enabling a qualitative assessment of the precision and consistency of the different techniques. The figure likely showcases how accurately and smoothly each model translates the simplistic input of a drag to a more complex and nuanced animation. This comparison directly evaluates the effectiveness of different methods in handling user-specified motion control.
read the caption
Figure 7: Users drag animation comparison with other animation methods.

🔼 Figure 8 presents a comparison of human face animation results generated using different methods. The key aspect highlighted is the use of optical flow extracted from a reference video to drive the animation. The figure showcases the effectiveness of the proposed method in generating consistent and realistic facial expressions and lip movements, even when the input optical flow may not be perfectly aligned with the target image. This demonstrates the robustness and flexibility of the approach.
read the caption
Figure 8: Human face animation with optical flow extracted from reference video
More on tables
| webvid | OpenVid | |
|---|---|---|
| LPIPS ↓ | PSNR ↑ | |
| Motion-I2V | 0.375 | 16.14 |
| MOFA-Video | 0.351 | 18.43 |
| DynamiCrafter | 0.268 | 18.56 |
| CogVideoX+image | 0.147 | 24.22 |
| Pyramid-Flow | 0.152 | 24.99 |
| Open-Sora | 0.179 | 23.21 |
| Ours | 0.135 | 25.22 |
🔼 This table presents a quantitative comparison of video generation quality using various metrics across different models. It compares the performance of several state-of-the-art video generation methods, including Motion-I2V, MOFA-Video, DynamiCrafter, CogVideoX+image, Pyramid-Flow, Open-Sora, and the proposed model, on two datasets: Webvid and OpenVid. The metrics used are LPIPS (Learned Perceptual Image Patch Similarity), PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), FID (Fréchet Inception Distance), and FVD (Fréchet Video Distance). These metrics assess various aspects of video quality, such as perceptual similarity, noise level, and overall video coherence.
read the caption
Table 2: Video quality comparison.
| webvid | OpenVid | |||||
|---|---|---|---|---|---|---|
| SubC ↑ | MoS ↑ | Aesq ↑ | SubC ↑ | MoS ↑ | Aesq ↑ | |
| DynamiCrafter | 0.832 | 0.958 | 0.443 | 0.910 | 0.964 | 0.536 |
| CogVideoX+image | 0.855 | 0.984 | 0.443 | 0.929 | 0.987 | 0.567 |
| Pyramid-Flow | 0.906 | 0.991 | 0.438 | 0.941 | 0.991 | 0.537 |
| Open-Sora | 0.897 | 0.989 | 0.438 | 0.954 | 0.990 | 0.524 |
| Ours | 0.928 | 0.991 | 0.474 | 0.971 | 0.993 | 0.600 |
🔼 This table presents a quantitative comparison of video consistency metrics across different video generation methods. It evaluates three key aspects of video quality: Subject Consistency (SubC), which measures how well the subject’s appearance and motion are maintained throughout the video; Motion Smoothness (MoS), which assesses the fluidity and naturalness of movement; and Aesthetic Quality (AesQ), which evaluates the overall visual appeal of the generated video. Higher scores indicate better performance in each category.
read the caption
Table 3: Video consistency quality comparison. SubC: Subject Consistency; MoS: Motion Smoothness; AesQ: Aesthetic Quality.
🔼 This table presents the results of an ablation study conducted to evaluate the impact of different components of the AnimateAnything model on video generation quality and camera trajectory alignment. The study examines the effect of removing or modifying key elements, such as the camera embedding, a ControlNet-like module, frequency stabilization (FS), and the addition of noise during training. Quantitative metrics (LPIPS, PSNR, SSIM, FID, FVD, TransErr, RotErr) are used to assess the performance of each variant, providing insights into the contribution of each component to the overall system’s effectiveness.
read the caption
Table 4: Ablation study.
Full paper#